Salut tout le monde, quelques informations "sous le capot" sont la date de l'atelier d'ingénierie d'Alfastrakhovaniya - qui excite nos esprits techniques.

Apache Spark est un merveilleux outil qui vous permet de traiter rapidement et facilement de grandes quantités de données sur des ressources informatiques assez modestes (je veux dire le traitement en cluster).
Traditionnellement, le cahier jupyter est utilisé dans le traitement de données ad hoc. En combinaison avec Spark, cela nous permet de manipuler des trames de données à longue durée de vie (Spark traite de l'allocation des ressources, les trames de données vivent quelque part dans le cluster, leur durée de vie est limitée par la durée de vie du contexte Spark).
Après le transfert du traitement des données vers Apache Airflow, la durée de vie des trames est considérablement réduite - le contexte Spark «vit» dans la même instruction Airflow. Comment contourner cela, pourquoi se déplacer et qu'est-ce que Livy a à voir avec cela - lire sous la coupe.
Regardons un exemple très, très simple: supposons que nous devons dénormaliser les données dans une grande table et enregistrer le résultat dans une autre table pour un traitement ultérieur (un élément typique du pipeline de traitement des données).
Comment ferions-nous cela:
- données chargées dans la trame de données (sélection à partir d'une grande table et de répertoires)
- regardé avec des "yeux" le résultat (cela a-t-il fonctionné correctement)
- trame de données enregistrée dans la table Hive (par exemple)
Sur la base des résultats de l'analyse, il se peut que nous devions insérer dans la deuxième étape un traitement spécifique (remplacement de dictionnaire ou autre). En termes de logique, nous avons trois étapes
- étape 1: télécharger
- étape 2: traitement
- étape 3: enregistrer
Voici comment cela fonctionne dans le cahier jupyter - nous pouvons traiter les données téléchargées pendant une durée arbitraire, ce qui donne le contrôle des ressources Spark.
Il est logique de s'attendre à ce qu'une telle partition puisse être transférée vers Airflow. Autrement dit, pour avoir un graphique de ce genre

Malheureusement, cela n'est pas possible lorsque vous utilisez la combinaison Airflow + Spark: chaque instruction Airflow est exécutée dans son propre interpréteur python, par conséquent, entre autres, chaque instruction doit en quelque sorte "persister" les résultats de ses activités. Ainsi, notre traitement est «compressé» en une seule étape - «dénormaliser les données».
Comment ramener la flexibilité du notebook jupyter à Airflow? Il est clair que l'exemple ci-dessus «n'en vaut pas la peine» (peut-être, au contraire, il s'avère une bonne étape de traitement claire). Mais encore - comment faire exécuter des instructions Airflow dans le même contexte Spark sur un espace de trame de données commun?
Bienvenue Livy
Un autre produit de l'écosystème Hadoop vient à la rescousse - Apache Livy.
Je n'essaierai pas de décrire ici de quel genre de «bête» il s'agit. S'il est très bref et noir et blanc - Livy vous permet "d'injecter" du code python dans un programme que le pilote exécute:
- nous créons d'abord une session Livy
- après cela, nous avons la possibilité d'exécuter du code python arbitraire dans cette session (très similaire à l'idéologie jupyter / ipython)
Et pour tout cela, il y a une API REST.
Revenons à notre tâche simple: avec Tite-Live, nous pouvons sauvegarder la logique d'origine de notre dénormalisation
- dans la première étape (la première instruction de notre graphique), nous chargerons et exécuterons le code de chargement des données dans la trame de données
- dans la deuxième étape (deuxième instruction) - exécuter le code pour le traitement supplémentaire nécessaire de cette trame de données
- dans la troisième étape - le code pour enregistrer la trame de données dans la table
À quoi pourrait ressembler Airflow:
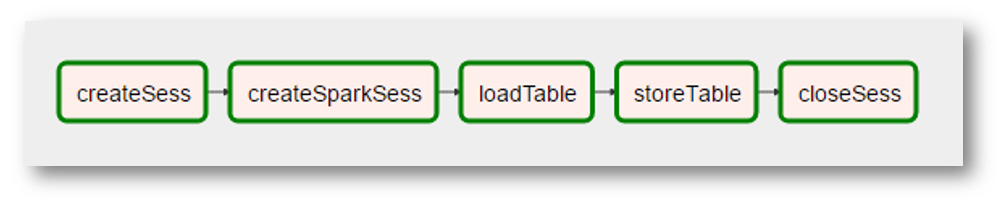
(puisque l'image est une capture d'écran très réelle, des «réalités» supplémentaires ont été ajoutées - la création du contexte Spark est devenue une opération distincte avec un nom étrange, le «traitement» des données a disparu car il n'était pas nécessaire, etc.)
Pour résumer, nous obtenons
- déclaration de flux d'air universel qui exécute du code python dans une session Livy
- la possibilité d '"organiser" le code python en graphiques assez complexes (Airflow pour cela)
- la capacité de s'attaquer aux optimisations de niveau supérieur, par exemple, dans quel ordre devons-nous effectuer nos transformations afin que Spark puisse conserver les données générales dans la mémoire du cluster aussi longtemps que possible
Un pipeline typique pour préparer des données pour la modélisation contient environ 25 requêtes sur 10 tables, il est évident que certaines tables sont utilisées plus souvent que d'autres (les mêmes "données générales") et il y a quelque chose à optimiser.
Et ensuite
La capacité technique a été testée, nous pensons plus loin - comment traduire plus technologiquement nos transformations dans ce paradigme. Et comment aborder l'optimisation mentionnée ci-dessus. Nous sommes encore au début de cette partie de notre voyage - quand il y a quelque chose d'intéressant, nous le partagerons certainement.