En mai de cette année, j'ai participé en tant que joueur à l'
événement MMO KatherineOfSky . J'ai remarqué que lorsque le nombre de joueurs atteint un certain nombre, toutes les quelques minutes, certains «tombent». Heureusement pour vous (mais pas pour moi), je faisais partie de ces joueurs qui se déconnectaient à
chaque fois , même avec une bonne connexion. J'ai pris cela comme un défi personnel et j'ai commencé à chercher les causes du problème. Après trois semaines de débogage, de test et de correction, l'erreur a finalement été corrigée, mais ce voyage n'a pas été aussi simple.
Les problèmes des jeux multijoueurs sont très difficiles à repérer. Habituellement, ils surviennent dans des conditions très spécifiques de paramètres de réseau et dans des conditions très spécifiques du jeu (dans ce cas, la présence de plus de 200 joueurs). Et même lorsqu'il est possible de reproduire le problème, il ne peut pas être correctement débogué, car l'insertion de points de contrôle arrête le jeu, perturbe les temporisateurs et conduit généralement à la fin de la connexion en raison du dépassement du temps d'attente. Mais grâce à l'entêtement et au merveilleux outil appelé
maladroit, j'ai réussi à comprendre ce qui se passait.
En bref: en raison d'une erreur et d'une implémentation incomplète de la simulation de l'état de retard, le client se retrouve parfois dans une situation où il doit envoyer un paquet réseau en un cycle d'horloge, qui consiste en des actions du joueur pour sélectionner environ 400 entités de jeu (nous l'appelons un «mégapacket»). Après cela, le serveur doit non seulement recevoir correctement toutes ces actions d'entrée, mais également les envoyer à tous les autres clients. Si vous avez 200 clients, cela devient rapidement un problème. Le canal vers le serveur est rapidement obstrué, ce qui entraîne une perte de paquets et une cascade de paquets redemandés. Le report des actions d'entrée conduit alors au fait que de plus en plus de clients commencent à envoyer des mégapaquets, et leur avalanche devient encore plus forte. Les clients qui réussissent parviennent à récupérer, tout le reste «tombe».
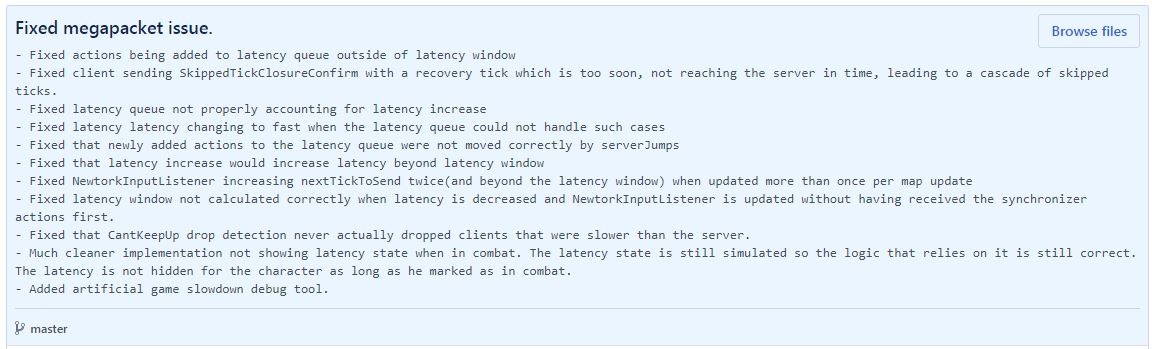
Le problème était assez fondamental et il m'a fallu 2 semaines pour le résoudre. C'est assez technique, donc ci-dessous j'expliquerai les détails techniques juteux. Mais vous devez d'abord savoir que depuis la version 0.17.54, publiée le 4 juin, face à des problèmes de connexion temporaires, le multijoueur est devenu plus stable, et masquer les retards est beaucoup moins bogué (moins de freinage et de téléportation). De plus, j'ai changé la façon de cacher les retards de combat et j'espère que grâce à cela ils seront un peu plus fluides.
Megapack multi-utilisateurs - Détails techniques
En termes simples, le multijoueur dans le jeu fonctionne comme suit: tous les clients simulent l'état du jeu, ne recevant et n'envoyant que les entrées du joueur (appelées «Actions d'entrée»,
Actions d'entrée ). La tâche principale du serveur est de transmettre les
actions d'entrée et de contrôler que tous les clients effectuent les mêmes actions en un seul cycle. En savoir plus à ce sujet dans le post
FFF-149 .
Étant donné que le serveur doit prendre des décisions sur les actions à effectuer, les actions du joueur évoluent le long de ce chemin: action du joueur -> client de jeu -> réseau -> serveur -> réseau -> client de jeu. Cela signifie que l'action de chaque joueur n'est effectuée qu'après avoir effectué un trajet aller-retour à travers le réseau. Pour cette raison, le jeu semble terriblement lent, donc presque immédiatement après l'apparition du multijoueur dans le jeu, un mécanisme permettant de masquer les retards a été introduit. Masquer un retard imite l'entrée d'un joueur sans tenir compte des actions des autres joueurs et des décisions du serveur.
Factorio a un état de jeu appelé
Game State - c'est l'état complet de la carte, du joueur, des entités et de tout le reste. Il est simulé de manière déterministe dans tous les clients en fonction des actions reçues du serveur. L'état du jeu est sacré et s'il commence à différer du serveur ou de tout autre client, la désynchronisation se produit.
En plus de
Game State , nous avons un
état de latence
Latency State . Il contient un petit sous-ensemble de l'état fondamental.
L'état de latence n'est pas sacré et présente simplement une image de l'état du jeu à l'avenir sur la base des
actions d'entrée introduites par le joueur.
Pour ce faire, nous stockons une copie des
actions d'entrée créées dans la file d'attente de retard.
Autrement dit, à la fin du processus côté client, l'image ressemble à ceci:
- Appliquez les actions d'entrée de tous les joueurs à l' état du jeu car ces actions d'entrée ont été reçues du serveur.
- Nous supprimons de la file d'attente des retards toutes les actions d'entrée qui, selon le serveur, ont déjà été appliquées à Game State .
- Supprimez l' état de latence et réinitialisez-le afin qu'il ressemble exactement à l'état du jeu .
- Appliquez toutes les actions de la file d'attente de retard à l' état de latence .
- Sur la base des données de l' état du jeu et de l' état de latence, nous rendons le jeu au joueur.
Tout cela se répète dans toutes les mesures.
Trop compliqué? Ne vous détendez pas, ce n'est pas tout. Pour compenser les connexions Internet peu fiables, nous avons créé deux mécanismes:
- Tiques manquées: lorsque le serveur décide que les actions d'entrée seront effectuées dans le rythme du jeu, puis s'il ne reçoit pas les actions d'entrée de certains joueurs (par exemple, en raison de l'augmentation du délai), il n'attendra pas, mais dira à ce client: «Je n'ai pas pris en compte vos actions d'entrée , je vais essayer de les ajouter à la prochaine mesure. " Ceci est fait pour que, en raison de problèmes de connexion (ou avec l'ordinateur) d'un joueur, la mise à jour de la carte ne ralentisse pas pour tout le monde. Il convient de noter que les actions d'entrée ne sont pas ignorées, mais simplement reportées.
- Délai d'aller-retour: le serveur tente de deviner quel est le délai d'aller-retour entre le client et le serveur pour chaque client. Toutes les 5 secondes, si nécessaire, il discute avec le client d'un nouveau délai (en fonction de la façon dont la connexion s'est comportée dans le passé), et augmente ou diminue en conséquence le délai de transfert de données dans les deux sens.
En eux-mêmes, ces mécanismes sont assez simples, mais lorsqu'ils sont utilisés ensemble (ce qui arrive souvent avec des problèmes de connexion), la logique du code devient difficile à gérer et avec un tas de cas limites. De plus, lorsque ces mécanismes entrent en
jeu , le serveur et la file d'attente de retard doivent implémenter correctement une
action d'entrée spéciale appelée
StopMovementInTheNextTick . Pour cette raison, avec des problèmes de connexion, le personnage ne fonctionnera pas seul (par exemple, sous le train).
Vous devez maintenant vous expliquer comment fonctionne la sélection d'entités. L'un des types d'
actions d'entrée réussies est le changement d'état de la sélection d'entité. Il indique à tout le monde sur quelle entité le joueur a plané. Comme vous pouvez le comprendre, il s'agit de l'une des actions d'entrée les plus fréquentes envoyées par les clients, donc pour économiser la bande passante, nous l'avons optimisée afin qu'elle occupe le moins d'espace possible. Ceci est implémenté comme suit: lors du choix de chaque entité, au lieu de conserver les coordonnées absolues et de haute précision de la carte, le jeu conserve un déplacement relatif à faible courant par rapport au choix précédent. Cela fonctionne bien car la sélection de la souris se produit généralement très près de la sélection précédente. Pour cette raison, deux exigences importantes se posent:
Les actions d'entrée ne doivent jamais être ignorées et doivent être exécutées dans le bon ordre. Ces conditions sont remplies pour
Game State . Mais puisque la tâche de l'
état de latence est de «paraître assez bien» pour le joueur, ils ne sont pas satisfaits de l'état des retards.
L'État de latence ne prend pas en compte de
nombreux cas limites associés aux cycles de sauts et à la modification des délais d'aller-retour.
Vous pouvez déjà deviner où tout se passe. Enfin, nous commençons à voir les causes du problème du mégapaquet. La racine du problème est qu'en décidant de passer ou non l'action du changement de sélection, la logique de sélection d'entité s'appuie sur l'
état de latence , et cet état ne contient pas toujours les informations correctes. Par conséquent, un mégapaquet est généré comme ceci:
- Le lecteur a un problème de connexion.
- Les mécanismes de saut d'horloges et de régulation du délai d'aller-retour entrent en jeu.
- La mise en file d'attente des retards d'état ne tient pas compte de ces mécanismes. Cela entraîne la suppression prématurée de certaines actions ou leur exécution dans le mauvais ordre, ce qui entraîne un état de latence incorrect.
- Le joueur a un problème de connexion et lui, pour rattraper le serveur, simule jusqu'à 400 cycles d'horloge.
- Dans chaque cycle d'horloge, une nouvelle action, modifiant la sélection d'une entité, est générée et préparée pour être envoyée au serveur.
- Le client envoie au serveur un mégapacket de plus de 400 changements dans le choix des entités (et avec d'autres actions: l'état de tir, de marche, etc., a également souffert de ce problème).
- Le serveur reçoit 400 actions d'entrée. Puisqu'il n'est pas autorisé à ignorer une seule action d'entrée, il ordonne à tous les clients d'effectuer ces actions et les envoie sur le réseau.
L'ironie est qu'un mécanisme conçu pour économiser la bande passante du canal a créé d'énormes paquets réseau en conséquence.
Nous avons résolu ce problème en corrigeant tous les cas limites de mise à jour et en prenant en charge la file d'attente des retards. Bien que cela ait pris un certain temps, au final, cela valait la peine de tout mettre en œuvre correctement et de ne pas compter sur des hacks rapides.