Dans cet article, je souhaite envisager une approche pour diviser les tâches en sous-tâches lors de l'utilisation de Clean Architecture.
Le problème de décomposition a été rencontré par l'équipe de développement mobile NullGravity et ci-dessous comment nous l'avons résolu et ce qui s'est finalement produit.

Contexte
C'était à l'automne 2018, nous développions la prochaine application pour un opérateur télécom. Mais cette fois, c'était différent. Les conditions étaient assez strictes et liées à la campagne marketing du client. L'équipe Android est passée de 3 à 6-7 développeurs. Plusieurs tâches ont été prises dans le sprint et la question était de savoir comment les décomposer efficacement.
Que voulons-nous dire lorsque nous parlons efficacement:
- Le nombre maximum de tâches parallèles.
Cela permet d'occuper toutes les ressources disponibles. - Réduction de la taille des demandes de fusion.
Ils ne seront pas surveillés pour l'émission, et vous pouvez toujours détecter les problèmes potentiels au stade de la révision du code. - Réduisez le nombre de conflits de fusion.
Les tâches se dérouleront plus rapidement et il n'est pas nécessaire de basculer le développeur vers la résolution des conflits. - La possibilité de collecter des statistiques sur l'emploi du temps.
- Automatisez la création de tâches dans Jira.
Comment avons-nous résolu le problème?
Nous divisons toutes les sous-tâches dans les types suivants:
- Les données
- Domaine
- Vide
- UI
- Objet
- Personnalisé
- Intégration
Les données et le domaine correspondent aux couches de l'architecture propre.
Vide, UI, Item et Custom font référence à la couche de présentation.
L'intégration s'applique aux couches de domaine et de présentation.
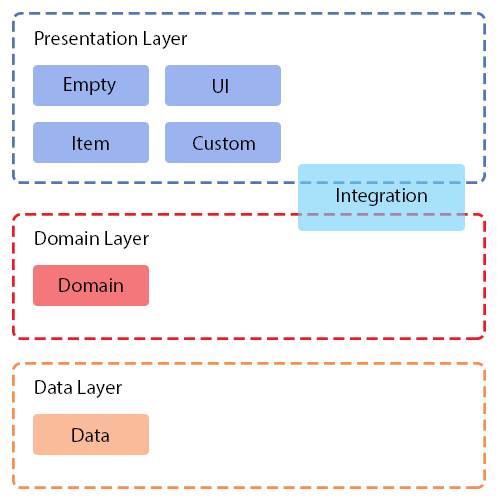 Figure 1. Emplacement des tâches par rapport aux couches Clean Architecture
Figure 1. Emplacement des tâches par rapport aux couches Clean ArchitectureExaminons chaque type individuellement.
Les données
Description du DTO, de l'API, du travail avec la base de données, la source de données, etc.
Domaine
Interface de référentiel, description des modèles d'affaires, interacteurs.
L'interface de référentiel dans la couche de données est également implémentée.
Une telle séparation quelque peu illogique, à première vue, a permis d'isoler autant que possible les tâches des types de données et de domaines.
UI
Création d'une disposition d'écran de base et d'états supplémentaires, le cas échéant.
Objet
Si l'écran est une liste d'éléments, alors pour chaque type, vous devez créer un modèle - Article. Pour mapper Item à la mise en page, vous avez besoin de AdapterDelegate. Nous utilisons le concept d'
adaptateur délégué , mais avec quelques
modifications .
Ensuite, créez un exemple d'utilisation d'un élément de liste dans PresentationModel.
Vide
Classes de base requises pour des tâches telles que l'interface utilisateur ou l'élément: PresentationModel, Framgent, layout, DI module, AdapterDelagate factory. Liaisons d'interfaces et d'implémentations. Créez un point d'entrée sur l'écran.
Le résultat de la tâche est l'écran de l'application. Il contient la barre d'outils, RecyclerView, ProgressView, etc. c'est-à-dire des éléments d'interface communs, dont l'ajout pourrait être dupliqué par différents développeurs et entraînerait des conflits de fusion inévitables.
Personnalisé
Implémentation d'un composant d'interface utilisateur non standard.
Un type supplémentaire est nécessaire pour séparer le développement d'un nouveau composant d'une tâche de type UI.
Intégration
Intégration des couches domaine et présentation.
En règle générale, c'est l'une des tâches les plus longues. Il est nécessaire de réduire les deux couches et d'affiner les points qui auraient pu être manqués aux étapes précédentes.
Ordre des tâches
Des tâches telles que les données, vides et personnalisées peuvent être démarrées immédiatement après le démarrage du sprint. Ils sont indépendants des autres tâches.
La tâche de domaine est exécutée après la tâche de données.
Les tâches d'interface utilisateur et d'élément après la tâche vide.
La tâche d'intégration est la dernière à être terminée car elle nécessite l'achèvement de toutes les tâches précédentes.
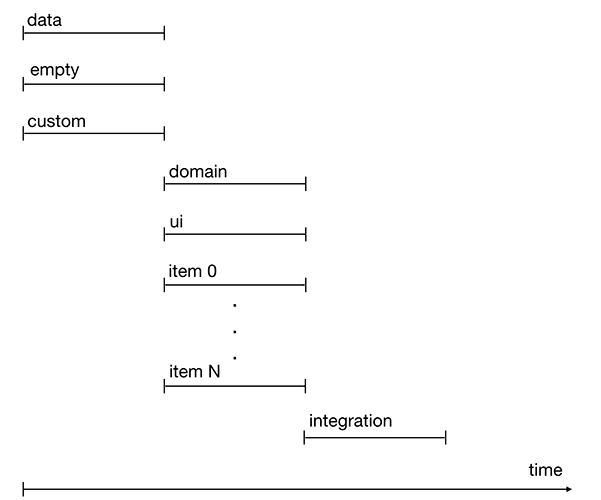 Figure 2. Exécution des tâches de la chronologie
Figure 2. Exécution des tâches de la chronologieBien que certaines tâches soient bloquées par d'autres tâches, elles peuvent être démarrées en même temps ou avec un léger retard. Ces tâches incluent le domaine, l'interface utilisateur et l'élément. Ainsi, le processus de développement est accéléré.
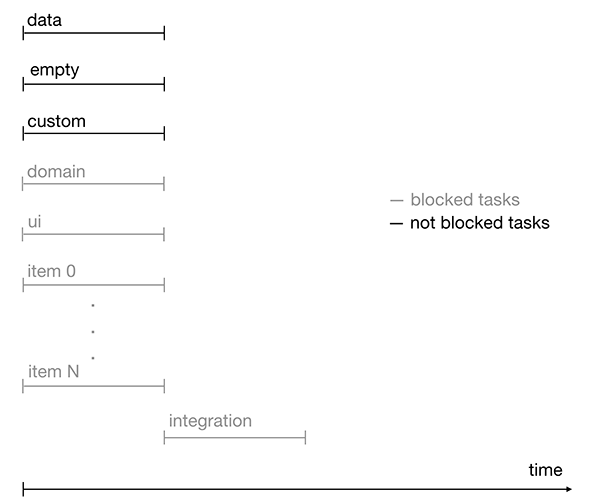 Figure 3. Chronologie d'exécution des tâches avec des verrous
Figure 3. Chronologie d'exécution des tâches avec des verrousPour chaque fonctionnalité spécifique, l'ensemble des tâches peut varier.
Il peut y avoir un nombre différent de tâches vides, interface utilisateur, élément et intégration, et certains types peuvent simplement être absents.
Automatisation des processus et collecte de statistiques
Pour collecter des statistiques lors de la création d'une tâche, une étiquette lui est affectée. Ce mécanisme vous permettra à l'avenir d'analyser le temps passé sur chaque type, et de former les coûts moyens. Les informations collectées peuvent être appliquées lors de l'évaluation d'un nouveau projet.
Pour l'automatisation, nous avons également réussi à trouver une solution. Étant donné que les tâches sont typiques, pourquoi leur description dans Jira devrait être différente. Nous avons développé des modèles de résumé et de description. Au début, ce n'était qu'un fichier json, l'analyseur Python de ce fichier, et l'API Jira REST était connectée pour générer des tâches.
Sous cette forme, le script a duré près d'un an. Aujourd'hui, il est devenu une application de bureau à part entière écrite en Python en utilisant l'architecture PyQt et MVP.
Peut-être que MVP était en surcharge, mais lorsque la première version de Tkinter a planté la version 10.14.6 de MacOS et que toutes les équipes n'ont pas pu utiliser l'application, nous avons facilement réécrit la vue pour PyQt en une demi-journée et cela a fonctionné. Encore une fois, nous étions convaincus que l'utilisation d'approches architecturales, même pour des tâches aussi simples, avait ses avantages. Une capture d'écran de JiraSubTaskCreator est illustrée à la figure 4.
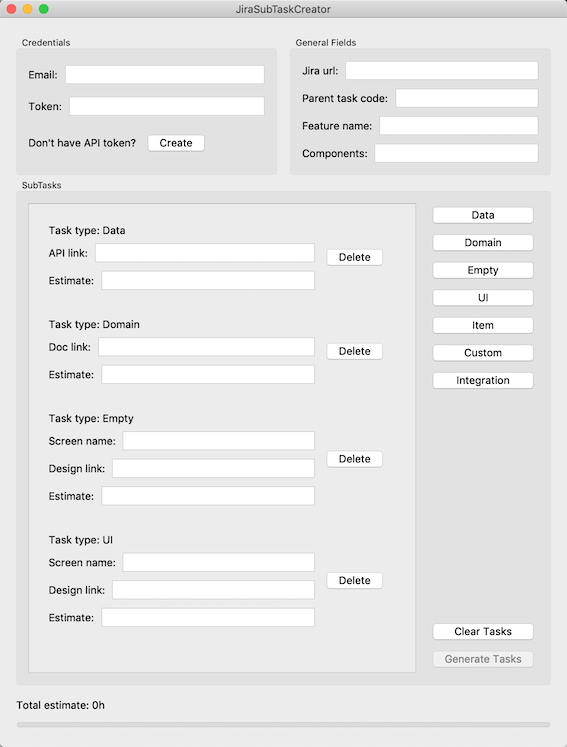 Figure 4. L'écran principal de JiraSubTaskCreator
Figure 4. L'écran principal de JiraSubTaskCreatorConclusions
- Nous avons développé une approche de la décomposition des tâches en sous-tâches dépendant le moins possible les unes des autres;
- Modèles générés pour décrire les tâches;
- Nous avons reçu de petites demandes de fusion, ce qui permet d'examiner attentivement et de modifier le code isolément
- Réduction du nombre de conflits avec les demandes de fusion;
- Nous avons eu l'occasion d'évaluer et d'analyser plus précisément le temps passé sur chaque type de tâche;
- Partie automatisée du travail de routine.