Comparaison de différents outils (RabbitMQ, Crossbar.io, Nats.io, Nginx, etc.) pour organiser RPC entre microservices.
Utilisation de la mémoire Utilisation du processeur Article mis à jour 2019-12-15Résumé . La mise en œuvre d'appels RPC synchrones via le système MQ classique n'est pas efficace - elle réduit les performances et les effets secondaires qui doivent être enroulés manuellement (ou avec des outils supplémentaires).
Inverted Json est un serveur de tâches léger qui vous permet de faire des appels RPC synchrones «honnêtes» (le client et le serveur se connectent via Inverted Json pour envoyer des informations), ce qui garantit des performances élevées (7 fois plus rapides que RabbitMQ), et la communication se fait via http , qui vous permet d'utiliser tous les outils http, même les boucles depuis la console.
1. Tests
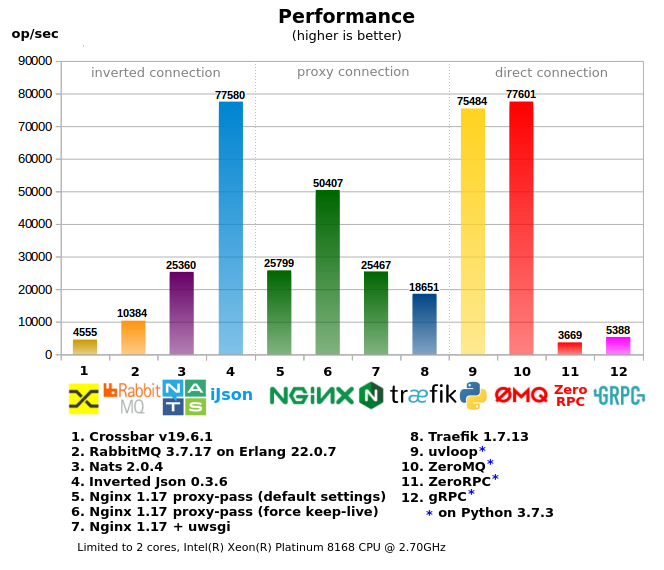
Tous les outils sont divisés en 3 groupes:
- «Connexion directe» - lorsque le client s'adresse directement au travailleur, dans les projets avec un grand nombre de travailleurs / services, il est le plus difficile à configurer, il nécessite un «client intelligent», c'est-à-dire lors de l'appel, le client doit avoir des informations sur comment et où envoyer la demande (ou un proxy local supplémentaire est nécessaire), en règle générale, il produit la moindre charge sur le réseau.
- «Connexion proxy» - une variante avec un point d'entrée unique, un client simple, mais en même temps des difficultés subsistent du côté des travailleurs / publications en série - transfert et allocation de ports, enregistrement d'adresses pour les proxys, paramètres de pare-feu plus compliqués, des outils supplémentaires sont souvent utilisés pour gérer l'ensemble de la batterie de serveurs .
- «Connexion inversée» - un point d'entrée unique pour les clients et les travailleurs (peut être considéré comme un ESB), la configuration réseau la plus simple.
- Utilisation de la mémoire et du processeur tirée des «statistiques du docker»
- Dans le test «2 cœurs», le serveur et les clients avec disjoncteurs sont divisés en différents cœurs afin de réduire l'influence les uns sur les autres, donc le serveur est limité à 2 cœurs via le jeu de tâches (test multicœur sans restrictions)
Quelques réflexions sur le benchmark ci-dessous.
2. MQ ou RPC
Bien que ces 2 méthodes de communication soient différentes, parfois la première est utilisée à la place de la seconde et vice versa.
Si vous essayez de définir les limites, quand utiliser quoi, vous pouvez obtenir quelque chose comme ceci:
- RPC (appel de procédure synchrone) - lorsque le client a besoin d'une réponse immédiatement (dans un court laps de temps), lorsque le travailleur doit répondre pendant que le client attend une réponse, et si le client est parti (par timeout), cette réponse n'est plus nécessaire (c'est pourquoi vous n'avez pas besoin de sauvegarder " demande ”, comme cela se fait souvent dans les systèmes MQ).
Par exemple, lorsque vous effectuez une requête dans la base de données - vous effectuez RPC, vous ne voudrez pas utiliser MQ pour cela. - MQ (appel de procédure asynchrone) - lorsque la réponse n'est pas nécessaire (immédiatement), lorsque vous avez juste besoin de terminer une sorte de tâche à la fin ou simplement de transférer des données.
Par exemple, pour envoyer des lettres, vous pouvez envoyer une tâche via MQ
3. RPC sur RabbitMQ
RabbitMQ est souvent utilisé pour organiser les RPC, mais comme les systèmes MQ similaires, il crée une surcharge supplémentaire, c'est pourquoi son utilisation n'est pas très productive.
Si vous utilisez la "file d'attente" pour RPC, vous devez nettoyer les canaux, car si le travailleur est tombé pendant un certain temps, après le redémarrage, il peut obtenir un tas de tâches non pertinentes, car les clients ont envoyé des demandes tout ce temps et, en outre, ont attendu en vain une réponse. le travailleur n'était pas actif. Au total, le travailleur recevra la tâche même si le client est parti avant, la même chose avec le client, si le canal du client n'est pas compté, alors il peut se boucher avec des réponses non reçues du travailleur, bien que dans RabbitMQ il soit possible de fermer le canal client, mais en même temps les performances seront considérablement réduites.
Vous devez également faire un travailleur du porc pour savoir s'il est vivant.
De plus, les ressources sont dépensées pour travailler avec les canaux, alors que dans les systèmes RPC, les données sont simplement envoyées au travailleur et vice versa.
4. Json inversé
Il existe de nombreux systèmes MQ différents, mais peu de Job Servers (RPC) tels que Gearman / Crossbar.io sont de très petits choix, donc les développeurs prennent souvent des systèmes MQ pour les RPC.
Par conséquent, le
JSON inversé (iJson) a été créé - un serveur proxy avec une interface http où les clients et les travailleurs se connectent en tant que client réseau: [client] -> [Json inversé] <- [travailleur], écrit en C / C ++, utilise epoll, des machines d'état pour le routage, l'analyseur de streaming json, les tranches au lieu des chaînes *, etc. des moyens pour de meilleures performances.
Avantages du JSON inversé par rapport à RabbitMQ:- Pas besoin de nettoyer les canaux client et travailleur des messages non reçus
- Il n'est pas nécessaire d'envoyer une requête ping au travailleur, le client recevra immédiatement une erreur si le travailleur se déconnecte (avec une connexion permanente)
- API plus simple - juste une requête http (en règle générale, elle est déjà prise en charge par tous les langages et frameworks)
- Fonctionne plus rapidement et consomme moins de mémoire
- Un moyen plus simple d'envoyer des commandes à un travailleur spécifique (par exemple, s'il y a plusieurs travailleurs dans la file d'attente, mais que vous devez travailler avec un seul)
Autres informations Json inversées- La possibilité de transférer des données binaires (pas seulement json, comme son nom l'indique)
- Il n'est pas nécessaire de spécifier l'id si le travailleur est connecté en tant que keep-alive, Inverted Json connecte simplement le client et le travailleur directement.
- La possibilité de "s'abonner" à plusieurs commandes (canaux), de s'abonner à un pattern (par exemple commande / *) sans perdre en performance.
- L'image Docker ne fait que 2,6 Mo (version slim)
- Kernel Inverted Json seulement ~ 1400 lignes de code (v0.3), moins de code - moins de bugs;)
- Le JSON inversé ne modifie pas le corps de la demande (corps), mais l'envoie tel quel.
5. Essayez Json inversé en 3 minutes
Vous pouvez essayer Inverted Json dès maintenant si vous avez
Docker et
curl :

Description de l'image:
1) Lancement de l'image docker de
Json inversé sur le port 8001, --log 47 enregistre les demandes entrantes, etc.:
$ docker run -it -p 8001:8001 lega911/ijson --log 47
2) Enregistrez le travailleur pour la tâche «calc / sum» et attendez la tâche, demandez le type «get», c.-à-d. - obtenez la tâche:
$ curl localhost/calc/sum -H 'type: get'
3) Le client fait une demande de calcul / somme RPC:
$ curl localhost/calc/sum -d '{"id": 15, "data": "2+3"}'
4) Le travailleur reçoit la tâche `{" id ": 15," data ":" 2 + 3 "}` - les données sont inchangées, vous devez maintenant envoyer le résultat au même id, le type de demande est "result":
$ curl localhost -H 'type: result' -d '{"id": 15, "result": 5}'
... et le client obtient le résultat tel qu'il est
`{"id": 15, "result": 5}`5.1. Jsonrpc
JsonRPC 2 n'est pas pris en charge, mais il y a quelques rudiments, par exemple, le client peut envoyer des requêtes comme (url / rpc / call):
{"jsonrpc": "2.0", "method": "calc/sum", "params": [42, 23], "id": 1}
accepter des erreurs comme:
{"jsonrpc": "2.0", "error": {"code": -32601, "message": "Method not found"}, "id": null}
Cependant, en cas de demande, la prise en charge de JsonRPC peut être améliorée.
5.2. Exemple de client et de travailleur Python
Et ici, vous pouvez trouver un exemple dans le "mode travailleur", qui est plus productif et plus compact.
6. Quelques réflexions sur le résultat de référence
- Crossbar.io : est basé sur python, il n'est donc pas si rapide et ne peut pas utiliser plusieurs cœurs en raison du GIL.
- RabbitMQ : RPC au-dessus de MQ, ce qui impose une surcharge supplémentaire. Une baisse rapide des performances avec une charge croissante (non reflétée dans le test).
- Nats : pas un mauvais, bien que inférieur à Json inversé, comme RPC sur MQ aura également les mêmes problèmes.
- Json inversé : a atteint la limite du réseau (c'est-à-dire que le lancement de plusieurs copies de tests sur différents cœurs ne donne pas un meilleur résultat au total), a montré l'utilisation la plus efficace de la mémoire et du processeur par rapport aux performances.
- Nginx : lorsque proxy-pass, les performances chutent rapidement si le mode Keep-Alive n'est pas activé (désactivé par défaut), car Linux ne permet pas d'ouvrir / fermer de nombreux sockets dans un court laps de temps (cela ne se reflète pas dans le test).
- Traefik : très vorace, utilisé 600% du CPU au pic, inférieur à nginx en vitesse
- uvloop (sous asyncio) - donne de très bonnes performances, car la plupart écrites en C / C ++, pour RPC est plus préférable que ZeroMQ
- ZeroMQ - le travailleur lui-même est écrit en Python, donc il a fonctionné dans le noyau, bien que le test multiprocesseur consomme plus de 100% de CPU, cela est dû au fait que zeromq lui-même est écrit en C / C ++ sans capture GIL. Il donne de grandes performances, mais d'un autre côté, si le travailleur ne se contente pas de a + b, toute complication entraînera une réduction significative du RPC, car frappera le noyau encore plus tôt.
- ZeroRPC : déclaré comme un wrapper léger sur ZeroMQ, en réalité, 95% des performances de ZeroMQ sont perdues, il semble que ce ne soit pas si léger.
- GRPC : l'option pour python produit beaucoup de code python standard, c'est-à-dire le processeur s'avère lourd et repose rapidement sur le CPU, pour les langages compilés il n'y a probablement pas un tel problème.
- Tests 2 cœurs et multicœurs, en multicœur, certains indicateurs ont diminué, car vous devez rivaliser pour les ressources CPU avec le code de test client, par contre, certains tests ont donné de grandes performances, par exemple Traefik, qui a mangé 600% CPU
7. Conclusion
Si vous avez une grande entreprise et de nombreux employés, vous pouvez vous permettre de prendre en charge divers outils complexes pour organiser des connexions directes entre microservices, qui peuvent fournir une communication efficace.
Et pour les petites entreprises et les startups, où une petite équipe doit résoudre des problèmes dans divers domaines, Inverted Json peut économiser du temps et des ressources.
Pour le développement d'Inverted Json, les plans incluent un support pour pubsub, kubernetes et d'autres idées intéressantes.
Si vous êtes intéressé par le projet ou si vous souhaitez simplement aider l'auteur, vous pouvez mettre un astérisque sur le
projet github , merci.
PS:
- Il a fallu plus de temps pour créer cet article incluant des tests que pour créer Json inversé lui-même
- Des prototypes Json inversés ont également été écrits en 1. python + asyncio + uvloop, 2. en GoLang
- Les tests ont été examinés par différents experts.
- «Tranches au lieu de chaînes» - dans la plupart des cas, lors de l'analyse de http / json, les données ne sont pas copiées dans des chaînes, mais le lien vers les données source est utilisé, il n'y a donc pas d'allocation et de copie inutiles de la mémoire.
- Si vous allez tester - n'utilisez pas de requêtes en python, c'est très lent, mieux que pycurl, ce wrapper est utilisé dans les tests.
- La référence est ici
- Sources ici