Dans les grandes architectures ou microservices, le service le plus important n'est pas toujours le plus productif et n'est parfois pas destiné à une charge élevée. Nous parlons du backend. Il fonctionne lentement - il perd du temps sur le traitement des données et l'attente d'une réponse entre celui-ci et le SGBD, et n'est pas évolutif. Même si l'application elle-même évolue facilement, ce goulot d'étranglement ne se modifie pas du tout. Comment résoudre ce problème et garantir des performances élevées? Comment fournir une réponse système lorsque des sources d'informations importantes sont silencieuses?

Si votre architecture est entièrement conforme au manifeste réactif, les composants de l'application évoluent indéfiniment avec une charge croissante indépendamment les uns des autres et résistent à la chute de n'importe quel nœud - vous connaissez la réponse.
Sinon ,
Oleg Nizhnikov (
Odomontois ) expliquera comment le problème d'évolutivité a été résolu chez Tinkoff en construisant son cache de secours indolore sur Scala sans réécrire l'application.
Remarque L'article aura un minimum de code Scala et un maximum de principes et d'idées générales.Backend instable ou lent
Lors de l'interaction avec le backend, l'application moyenne est rapide. Mais le backend fait la majeure partie du travail et broie la plupart des données en interne - cela prend plus de temps. Du temps supplémentaire est perdu à attendre une réponse du backend et du SGBD. Même si l'application elle-même évolue facilement, ce goulot d'étranglement ne se modifie pas du tout. Comment alléger la charge sur le backend et résoudre le problème?
Cache intégré
La première idée est de prendre des données à lire, des requêtes qui reçoivent des données et de configurer le cache au niveau de chaque nœud en mémoire.
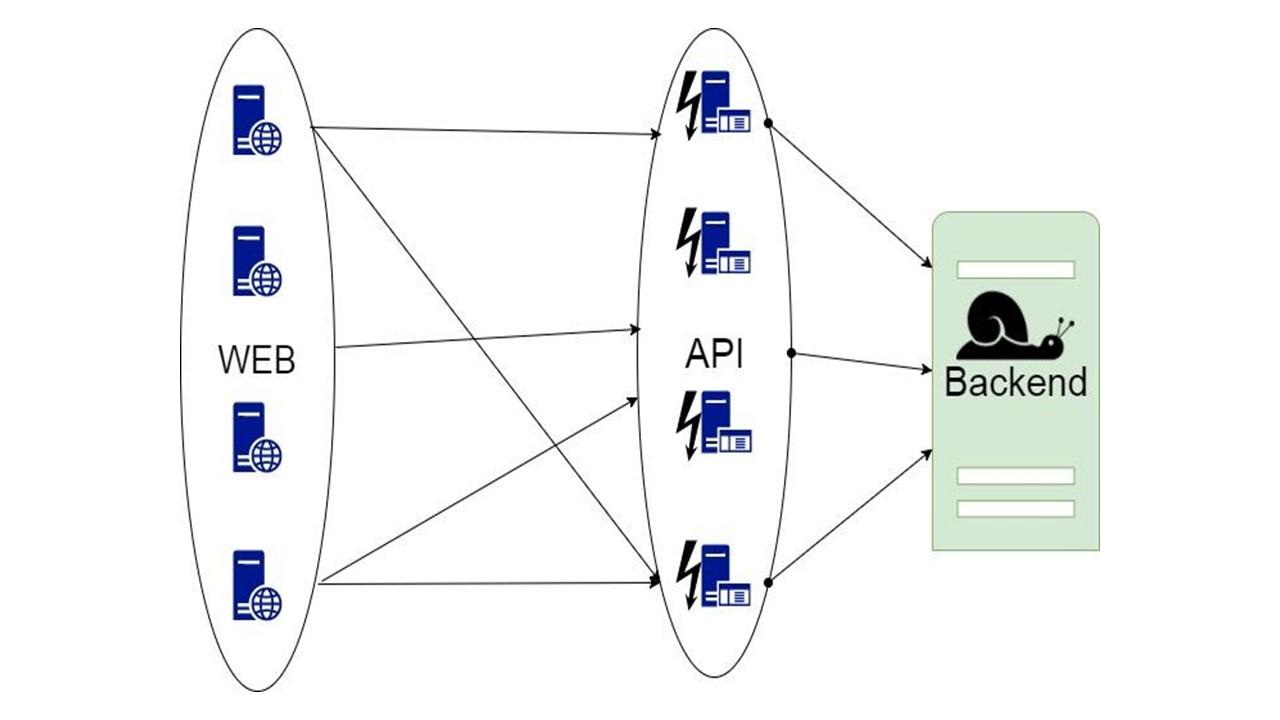
Le cache dure jusqu'à ce que le nœud redémarre et stocke uniquement la dernière donnée. Si l'application se bloque et que de nouveaux utilisateurs qui n'ont pas été dans la dernière heure, le jour ou la semaine arrivent, l'application ne peut rien y faire.
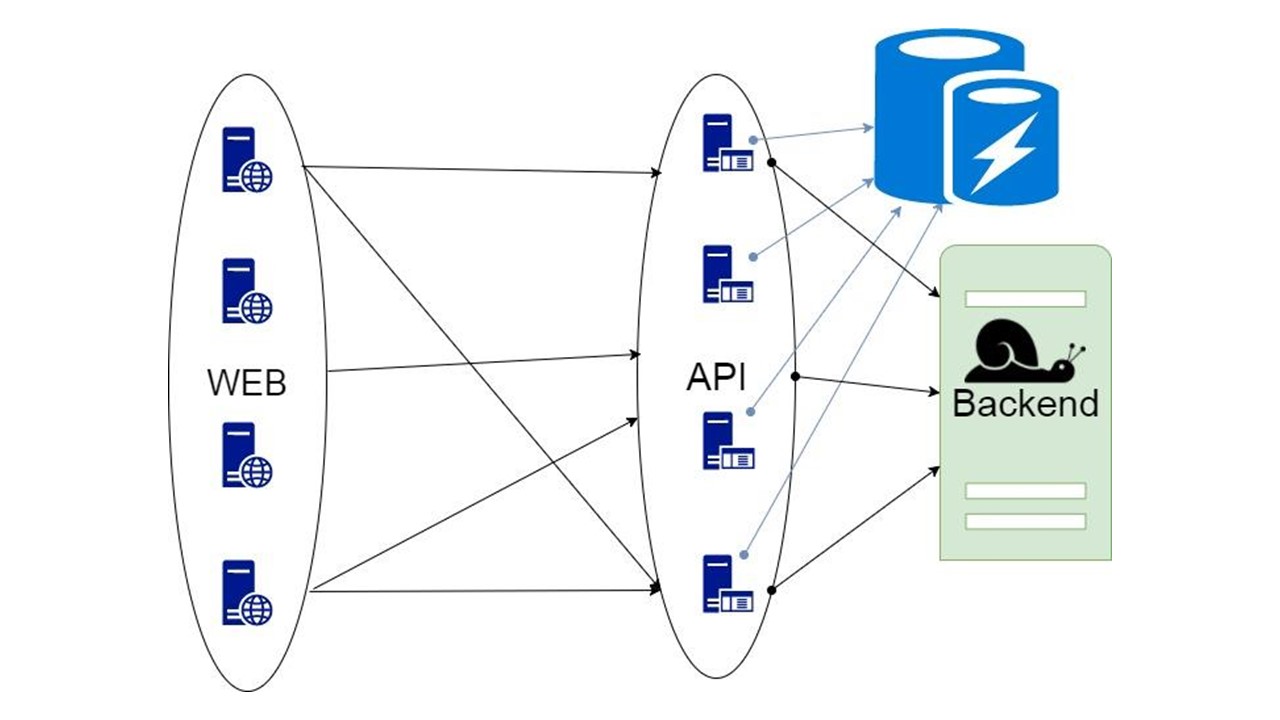
Proxy
La deuxième option est un proxy, qui prend en charge une partie des demandes ou modifie l'application.
Mais par proxy, vous ne pouvez pas faire tout le travail pour l'application elle-même.
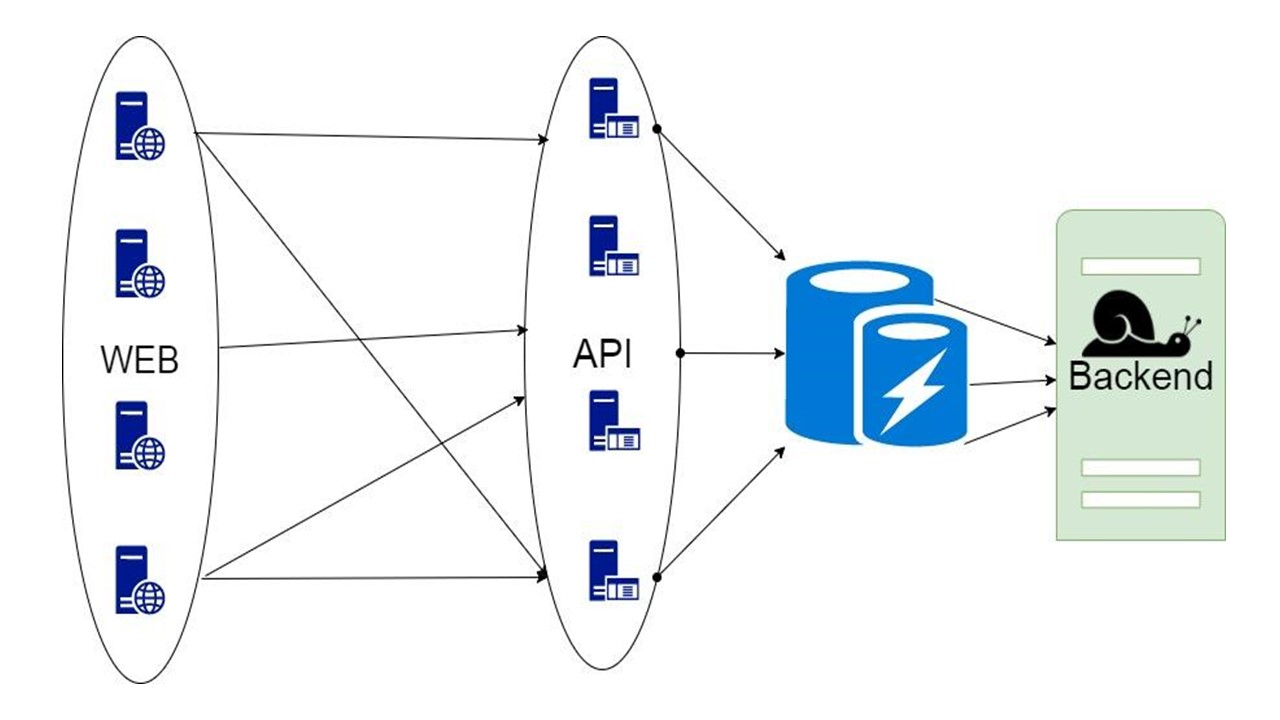
Base de données de mise en cache
La troisième option est délicate lorsque la partie des données renvoyées par le backend peut être stockée pendant une longue période. Lorsqu'elles sont nécessaires, nous montrons le client, même si elles ne sont plus pertinentes. C'est mieux que rien.
Cette décision sera discutée.
Cache de secours
Voici notre bibliothèque. Il est intégré à l'application et communique avec le backend. Avec un raffinement minimal, il analyse la structure des données, génère des formats de sérialisation et, à l'aide de l'algorithme du disjoncteur, augmente la tolérance aux pannes. Une sérialisation efficace peut être implémentée dans n'importe quelle langue où les types peuvent être analysés à l'avance s'ils sont définis de manière suffisamment stricte.
Composants
Notre bibliothèque ressemble à ceci.

La partie gauche est consacrée à l'interaction avec ce référentiel, qui comprend deux composants importants:
- le composant qui est responsable du processus d'initialisation - actions préliminaires avec le SGBD avant d'utiliser Fallback Cache;
- module de génération de sérialisation automatique.
Le côté droit est la fonctionnalité générale qui se rapporte à Fallback.
Comment ça marche? Il existe des requêtes au milieu de l'application et des types intermédiaires pour le stockage de l'état. Ce formulaire exprime les données que nous avons reçues du backend pour une ou plusieurs demandes. Nous envoyons les paramètres à notre méthode et nous en obtenons les données. Ces données doivent être sérialisées d'une manière ou d'une autre pour être stockées, nous les enveloppons donc dans du code. Un module distinct en est responsable. Nous avons utilisé le modèle de disjoncteur.
Exigences de stockage
Longue durée de conservation - 30-500 jours . Certaines actions peuvent prendre du temps et pendant tout ce temps, il est nécessaire de stocker des données. Par conséquent, nous voulons un stockage capable de stocker des données pendant une longue période. En mémoire ne convient pas pour cela.
Grand volume de données - 100 Go-20 To . Nous voulons stocker des dizaines de téraoctets de données dans le cache, et encore plus en raison de la croissance. Garder tout cela en mémoire est inefficace - la plupart des données ne sont pas constamment demandées. Ils mentent depuis longtemps, attendant leur utilisateur, qui entrera et demandera. En mémoire ne relève pas de ces exigences.
Haute disponibilité des données . Tout peut arriver au service, mais nous voulons que le SGBD reste disponible tout le temps.
Coûts de stockage réduits . Nous envoyons des données supplémentaires au cache. En conséquence, des frais généraux se produisent. Lors de la mise en œuvre de notre solution, nous voulons la minimiser.
Prise en charge des requêtes à intervalles . Notre base de données aurait dû être en mesure d'extraire une donnée non seulement dans son intégralité, mais à intervalles réguliers: une liste d'actions, l'historique d'un utilisateur pendant une certaine période. Par conséquent, une valeur de clé pure ne convient pas.
Hypothèses
Les exigences réduisent la liste des candidats. Nous supposons que nous avons implémenté le reste et faisons les hypothèses suivantes, sachant exactement pourquoi nous avons besoin de Fallback Cache.
L'intégrité des données entre deux demandes GET différentes n'est pas requise . Par conséquent, s'ils affichent deux états différents qui ne sont pas cohérents l'un avec l'autre, nous accepterons cela.
La pertinence et l'invalidation des données ne sont pas nécessaires . Au moment de la demande, il est supposé que nous avons la dernière version que nous montrons.
Nous envoyons et recevons des données du backend.
La structure de ces données est connue à l'avance .
Sélection de stockage
Comme alternatives, nous avons considéré trois options principales.
Le premier est
Cassandra . Avantages: haute disponibilité, évolutivité facile et mécanisme de sérialisation intégré avec la collection UDT.
UDT ou
User Defined Types , signifie un certain type. Ils vous permettent d'empiler efficacement les types structurés. Les champs de type sont connus à l'avance. Ces champs de sérialisation sont marqués avec des balises distinctes comme dans les tampons de protocole. Après avoir lu cette structure, il est possible de comprendre quels champs y sont basés sur des balises. Assez de métadonnées pour connaître leur nom et leur type.
Un autre avantage de Cassandra est qu'en plus de la clé de partition, il a une
clé de clustering supplémentaire. Il s'agit d'une clé spéciale, grâce à laquelle les données sont ordonnées sur un nœud. Cela vous permet d'implémenter une option telle que les requêtes d'intervalle.
Cassandra existe depuis relativement longtemps, il existe de
nombreuses solutions de surveillance pour elle , et
un inconvénient est la JVM . Ce n'est pas l'option la plus productive pour les plates-formes sur lesquelles vous pouvez écrire un SGBD. La machine virtuelle Java a des problèmes avec la récupération de place et la surcharge.
La deuxième option est
CouchBase . Avantages: accessibilité des données, évolutivité et Schemaless.
Avec CouchBase, vous devez penser moins à la sérialisation. C'est à la fois un plus et un moins - nous n'avons pas besoin de contrôler le schéma de données. Il existe des index globaux qui vous permettent d'exécuter des requêtes d'intervalle globalement sur un cluster.
CouchBase est un hybride où
Memcache est ajouté à un
cache SGBD habituel
- rapide . Il vous permet de mettre automatiquement en cache toutes les données sur le nœud - les plus chaudes, avec une très haute disponibilité. Grâce à son cache, CouchBase peut être rapide si les mêmes données sont demandées très souvent.
Schemaless et
JSON peuvent également être un inconvénient. Les données peuvent être stockées si longtemps que l'application a le temps de changer. Dans ce cas, la structure de données que CouchBase va stocker et lire changera également. La version précédente n'est peut-être pas compatible. Vous ne l'apprendrez que lors de la lecture, et non lors du développement des données, quand elles se situent quelque part dans la production. Nous devons penser à une migration appropriée, et c'est exactement ce que nous ne voulons pas faire.
La troisième option est
Tarantool . Il est célèbre pour sa super vitesse. Il a un merveilleux moteur LUA qui vous permet d'écrire un tas de logique qui s'exécutera directement sur le serveur sur LuaJit.
En revanche, il s'agit d'une valeur de clé modifiée. Les données sont stockées dans des tuples. Nous devons penser par nous-mêmes à la sérialisation correcte, ce n'est pas toujours une tâche évidente. Tarantool a également une approche spécifique de l'
évolutivité . Ce qui ne va pas avec lui, nous en discuterons plus loin.
Partage / réplication
Peut-être que notre application aura besoin de
Sharding / Replication . Trois référentiels les implémentent différemment.
Cassandra suggère une structure qui est généralement appelée un «anneau».
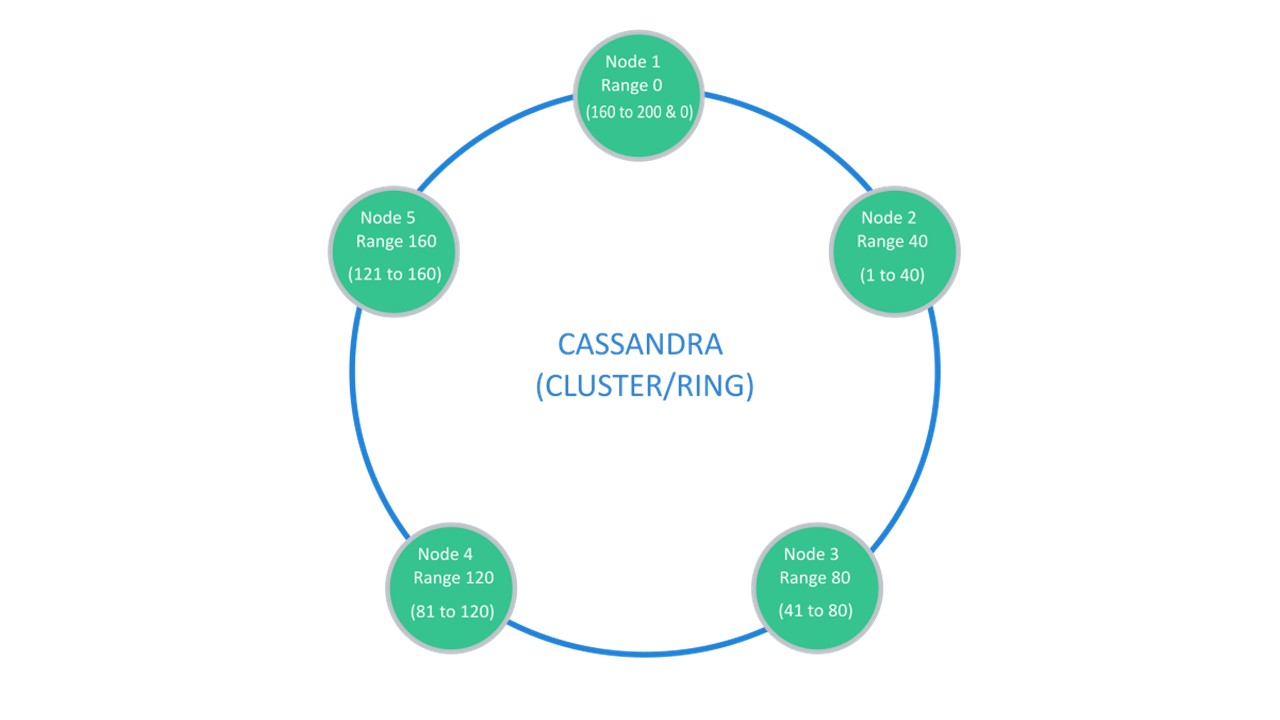
De nombreux nœuds sont disponibles. Chacun d'entre eux stocke ses données et les données des nœuds les plus proches sous forme de répliques. Si l'un abandonne, les nœuds à côté de lui peuvent servir une partie de ses données jusqu'à ce que le décrochage augmente.
Sharding \ Replication est responsable de la même structure. Pour décompresser en 10 pièces et facteur de réplication 3, 10 nœuds suffisent. Chacun des nœuds stockera 2 répliques des voisins.
Dans CouchBase, la structure d'interaction entre les nœuds est structurée de manière similaire:
- il existe des données marquées comme actives, dont le nœud lui-même est responsable;
- Il existe des répliques de nœuds voisins que CouchBase stocke.
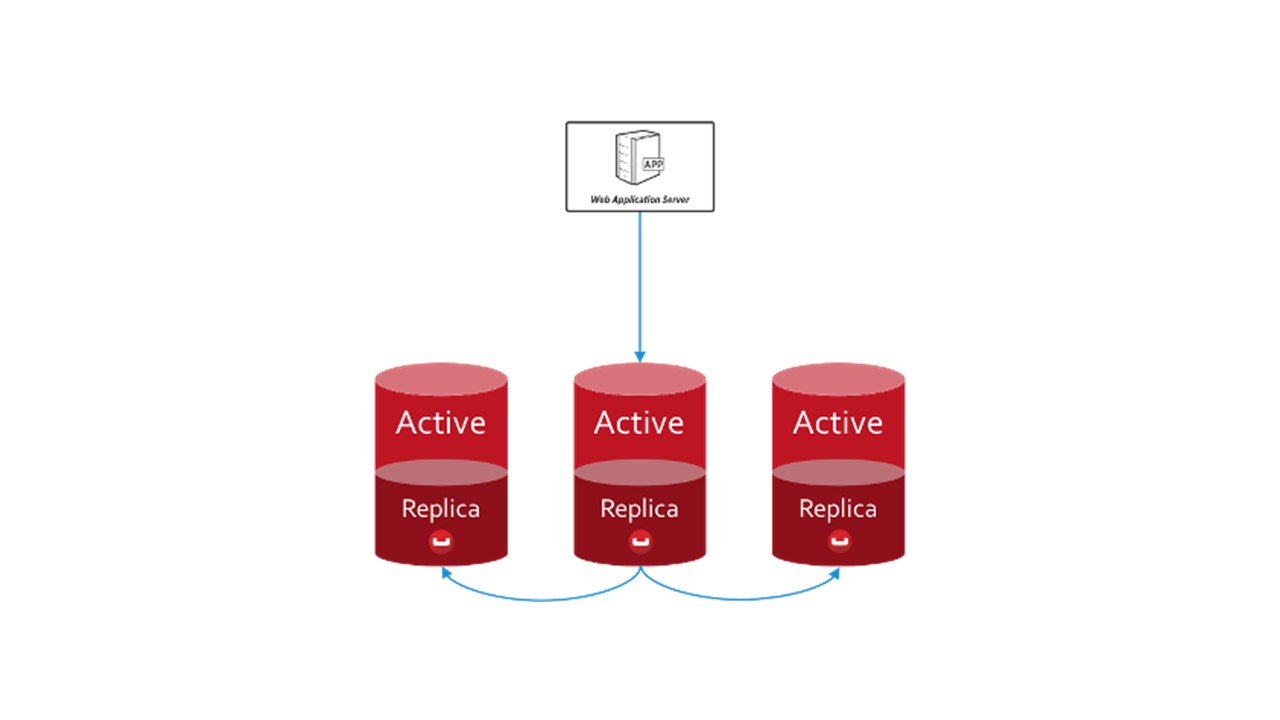
Si un nœud tombe en panne, les voisins, partagés, prennent la responsabilité de la maintenance de cette partie des clés.
Dans Tarantool, l'architecture est similaire à MongoDB. Mais avec une nuance: il existe des groupes de partitionnement qui sont répliqués les uns avec les autres.
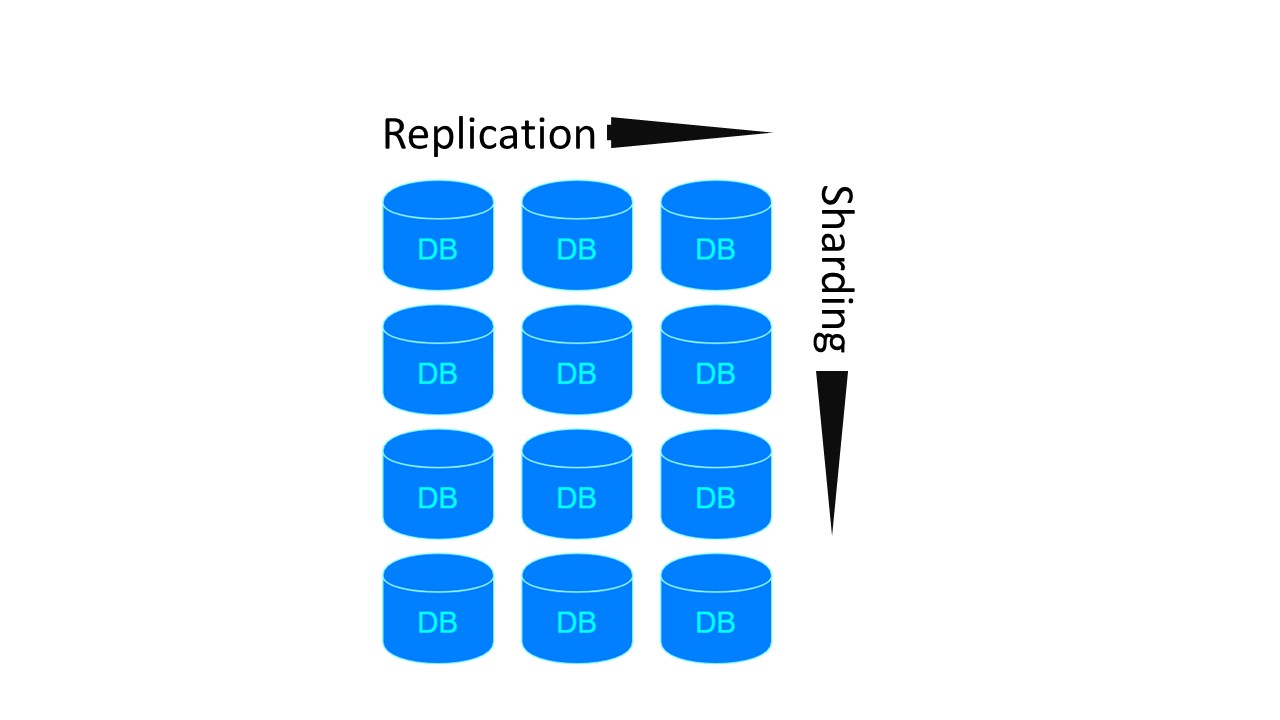
Pour les deux architectures précédentes, si nous voulons créer 4 fragments et le facteur de réplication 3, 4 nœuds sont nécessaires. Pour Tarantool - 12! Mais l'inconvénient est compensé par la vitesse garantie par Tarantool.
Cassandra
Des modules optionnels pour le sharding dans Tarantool sont apparus récemment. Par conséquent, nous avons choisi le SGBD Cassandra comme candidat principal. Rappelons que nous avons parlé de sa sérialisation spécifique.
Sérialisation automatique
Le protocole SQL suppose que vous définissez le schéma de données assez librement.
Vous pouvez utiliser cela comme un avantage. Par exemple, sérialisez les données afin que les noms de champs longs de nos structures feuillues ne soient pas stockés à chaque fois dans nos valeurs. Dans ce cas, nous aurons des métadonnées qui décrivent le périphérique de données. Les UDT eux-mêmes indiquent également quels champs correspondent aux étiquettes et aux balises.
Par conséquent, la sérialisation générée automatiquement se déroule approximativement de la même manière. Si nous avons l'un des types de base qui peut correspondre au type de la base de données un à un, nous le faisons. Un ensemble de types Int, Long, String, Double est également dans Cassandra.
Si un champ facultatif est rencontré dans une certaine structure, nous ne faisons rien de plus. Nous lui indiquons le type vers lequel ce champ doit se transformer. La structure stockera null. Si nous trouvons nul dans la structure au niveau de la désérialisation, nous supposons que c'est l'absence de valeur.
Tous les types de collection de la collection dans Scala sont convertis en liste de types. Ce sont des collections ordonnées qui ont un élément correspondant à un index.
Les collections Set non ordonnées garantissent qu'il y a exactement un élément avec chaque valeur. Cassandra a également un type de jeu spécial pour eux.
Très probablement, nous aurons beaucoup de mapping (), en particulier avec les clés de chaîne. Cassandra a un type de carte spécial pour eux. Il est également tapé et possède deux paramètres de type. Afin que nous puissions créer un type approprié pour n'importe quelle clé
Il existe des types de données que nous définissons nous-mêmes dans notre application. Dans de nombreuses langues, ils sont appelés
types de données algébriques . Ils sont définis en définissant un produit nommé de types, c'est-à-dire une structure. Nous attribuons cette structure au type défini par l'utilisateur. Chaque champ de la structure correspondra à un champ de l'UDT.
Le deuxième type est la
somme algébrique des types . Dans ce cas, le type correspond à plusieurs sous-types ou sous-espèces précédemment connus. Aussi, d'une certaine manière, nous lui attribuons une structure.
Type de données abstrait traduit en UDT
Nous avons une structure que nous affichons une à une - pour chaque champ, nous définissons le champ dans l'UDT créé à Cassandra:
case class Account ( id: Long, tags: List[String], user: User, finData: Option[FinData] ) create type account ( id bigint, tags: frozen<list<text>>, user frozen<user>, fin_data frozen<fin_data> )
Les types primitifs se transforment en types primitifs. Un lien vers un type prédéfini avant qu'il ne soit gelé. Il s'agit d'un emballage spécial dans Cassandra, ce qui signifie que vous ne pouvez pas lire ce champ morceau par morceau. L'encapsuleur est «figé» dans cet état. Nous pouvons uniquement lire ou enregistrer l'utilisateur, ou la liste, comme dans le cas des tags.
Si nous rencontrons un champ facultatif, nous rejetons cette caractéristique. Nous prenons uniquement le type de données correspondant au type de champ qui le sera. Si nous rencontrons non ici - l'absence de valeur - nous écrivons null dans le champ correspondant. Lors de la lecture, nous prendrons également la correspondance non nulle.
Si nous rencontrons un type qui a plusieurs alternatives pré-connues, nous définissons également un nouveau type de données dans Cassandra. Pour chaque alternative, un champ dans notre type de données en UDT.
Par conséquent, dans cette structure, un seul des champs à un moment donné ne sera pas nul. Si vous avez rencontré un type d'utilisateur et qu'il s'est avéré être une instance d'un modérateur lors de l'exécution, le champ modérateur contiendra une valeur, le reste sera nul. Pour admin - admin, le reste - null.
Cela vous permet d'encoder la structure comme suit: nous avons 4 champs optionnels, nous garantissons qu'un seul sera écrit à partir d'eux. Cassandra utilise une seule balise pour identifier la présence d'un champ particulier dans la structure. Grâce à cela, nous obtenons une structure de stockage sans frais généraux.
En fait, pour enregistrer le type d'utilisateur, s'il s'agit d'un modérateur, il faudra le même nombre d'octets nécessaires pour stocker le modérateur. Plus un octet pour montrer quelle alternative particulière est présente ici.
Initialisation
L'initialisation est une procédure préliminaire qui doit être terminée avant de pouvoir utiliser notre solution de repli.
Comment fonctionne ce processus?
- Sur chaque nœud, nous générons des définitions de tables, de types et de textes de requête en fonction des types présentés.
- Lisez le schéma actuel du SGBD. À Cassandra, cela est facile à faire en se connectant simplement à elle. Lorsqu'il est connecté, dans presque tous les pilotes, l'objet «session» proprement dit pompe les métadonnées de l'espace clé auxquelles il est connecté. Ensuite, vous pouvez voir ce qu'ils ont.
- Nous parcourons les métadonnées, comparons et vérifions que tout ce que nous voulons créer est autorisé et qu'une migration incrémentielle est possible.
- Si tout est normal et que l'initialisation est possible, nous effectuons la migration.
- Nous préparons des demandes.
sealed trait User case class Anonymous extends User case class Registered extends User case class Moderator extends User case class Admin extends User create type user ( anonymous frozen<anonymous>, registered frozen<registered>, moderator frozen<moderator>, admin frozen<admin> )
Ça se passe comme ça. Nous avons des
types , des
tables et des
requêtes . Les types dépendent d'autres types, ceux des autres. Les tableaux dépendent de ces types. Les requêtes dépendent déjà des tables à partir desquelles elles lisent les données. L'initialisation vérifiera toutes ces dépendances et créera dans le SGBD tout ce qu'il peut créer, selon certaines règles.
Type de migration
Comment déterminer qu'un type peut être migré de manière incrémentielle?
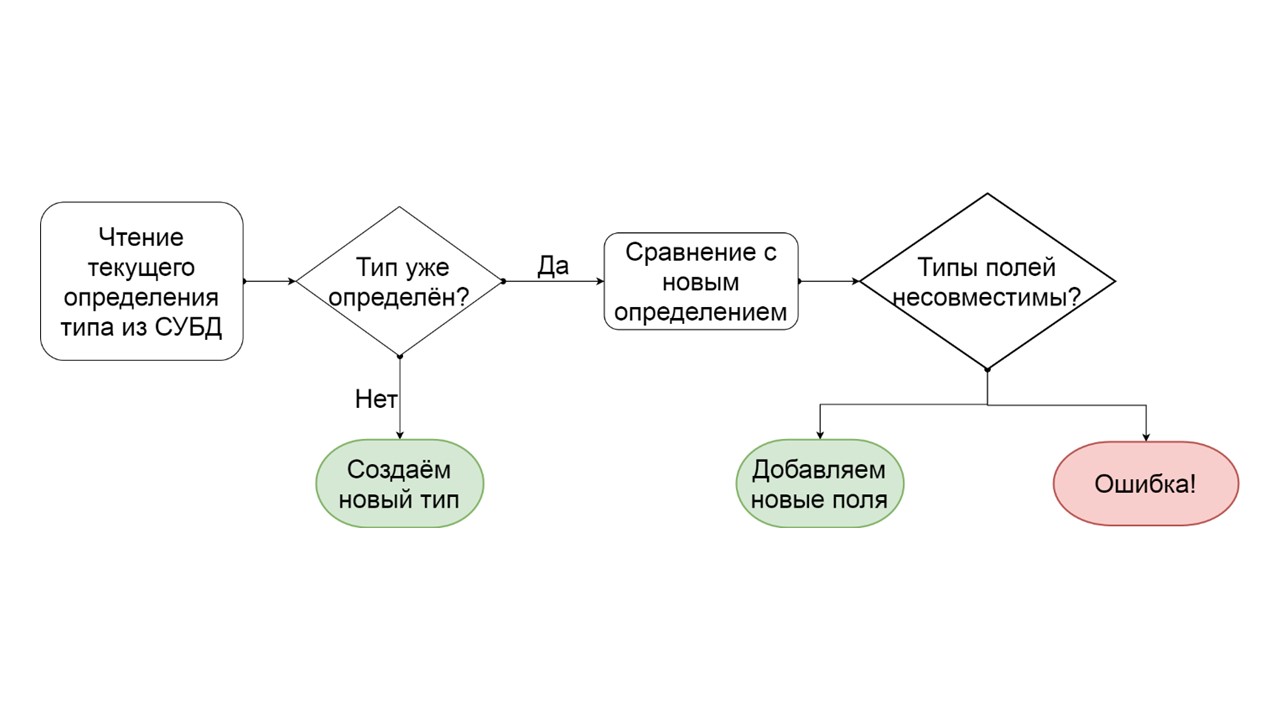
- Nous lisons comment ce type est défini dans le SGBD.
- S'il n'y a pas un tel type, c'est que nous en avons trouvé un nouveau - nous le créons.
- Si un tel type existe déjà, nous essayons de comparer champ par champ la définition existante avec celle que nous voulons donner à ce type.
- S'il s'avère que nous voulons ajouter seulement quelques champs qui n'existent plus, nous le faisons. Créez une liste d'opérations ALTER TYPE en mutation et lancez-les.
- S'il s'avère que nous avons une sorte de champ qui était d'un type différent - nous générons une erreur. Par exemple, il y avait list - est devenu map, ou il y avait un lien vers un type défini par l'utilisateur, et nous essayons de le rendre différent.
Le développeur peut voir cette erreur avant même de commencer la fonctionnalité en production. Je suppose que le même schéma de données exact est dans son environnement de développement. Il voit qu'il a en quelque sorte créé un schéma de données non migrable, et pour éviter ces erreurs, il peut remplacer la sérialisation générée automatiquement, ajouter des options, renommer des champs ou tous les types et tables dans leur ensemble.
Initialisation: types
Imaginez qu'il existe plusieurs types de définitions:
case class Product (id: Long, name: ctring, price: BigDecimal) case class UserOffers (valiDate: LocalDate, offers: Seq[Products]) case class UserProducts (user User, products: Map[Date, Product]) case class UserInfo: UserOffers, products: UserProducts)
Classe de cas - une classe qui contient un ensemble de champs. Il s'agit d'un analogue de struct dans Rust.
Nous générerons approximativement de telles définitions de données pour chacun des 4 types - ce que nous voulons éventuellement augmenter:
CREATE TYPE product (id bigint, name text, price decimal); CREATE TYPE user_offers (valid_date date, offers frozen<list<frozen<offer>>>); CREATE TYPE user_products (user frozen<user>, products frozen<map<date, frozen<product>>); CREATE TYPE user_jnfo (offers: frozen<user_offers>, products: frozen<user_products>);
Le type de user_offers dépend du type d'offre, user_products dépend du type de produit, user_info sur les deuxième et troisième types.

Nous avons une telle dépendance entre les types et nous voulons l'initialiser correctement. Le diagramme montre que nous initialiserons en parallèle user_offers et user_products. Cela ne signifie pas que nous lancerons deux opérations parallèles. Non, nous démarrons toutes les instructions, toutes les analyses de manière séquentielle, afin de ne pas créer accidentellement le même type dans deux threads parallèles.
Mais il existe un certain parallélisme au niveau de la correction d'erreur. Si une erreur de type se produit, tout ce qui en dépend extraira l'erreur d'origine.
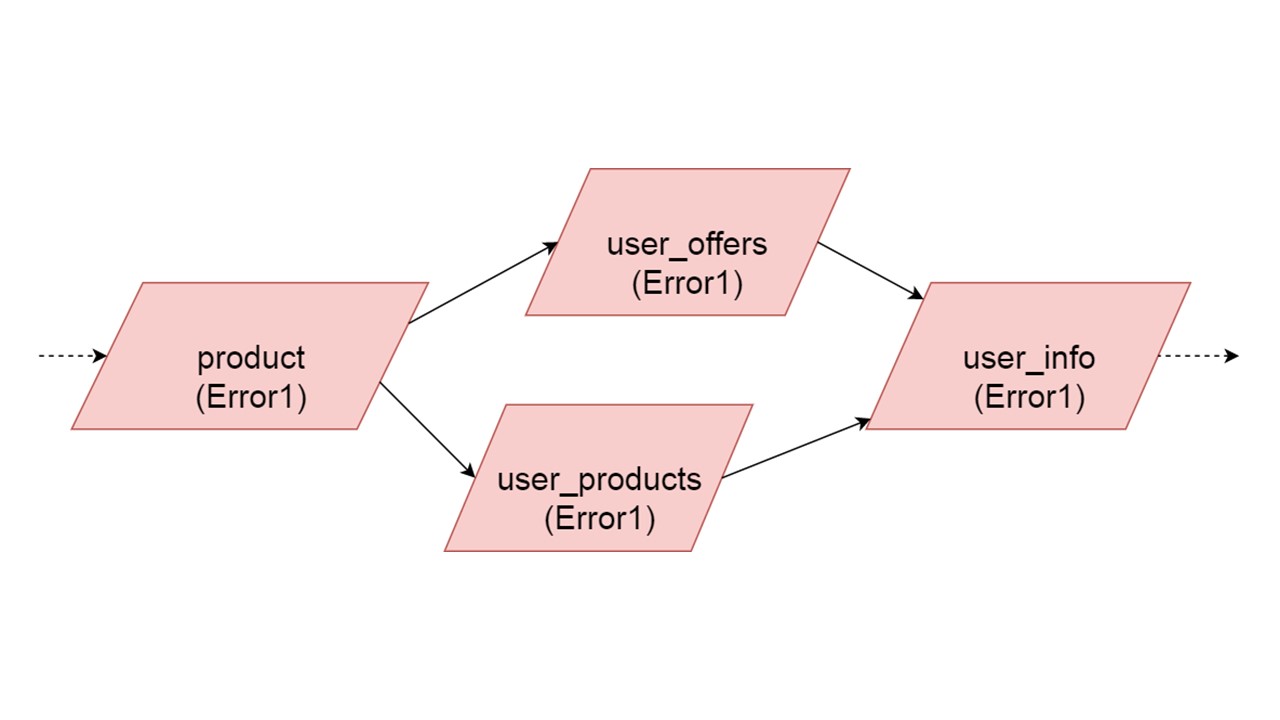
Si une erreur est générée par l'une des branches parallèles, tout ce qui dépend des données normalement migrées sera généré sans erreur. S'il existe d'autres définitions de tables, des instructions préparées à partir de celles-ci, nous pouvons initialiser en toute sécurité cette partie de notre cache de secours. La communication sera perdue uniquement avec une partie des backends ou avec certaines fonctionnalités. Les restes sont initialisés.
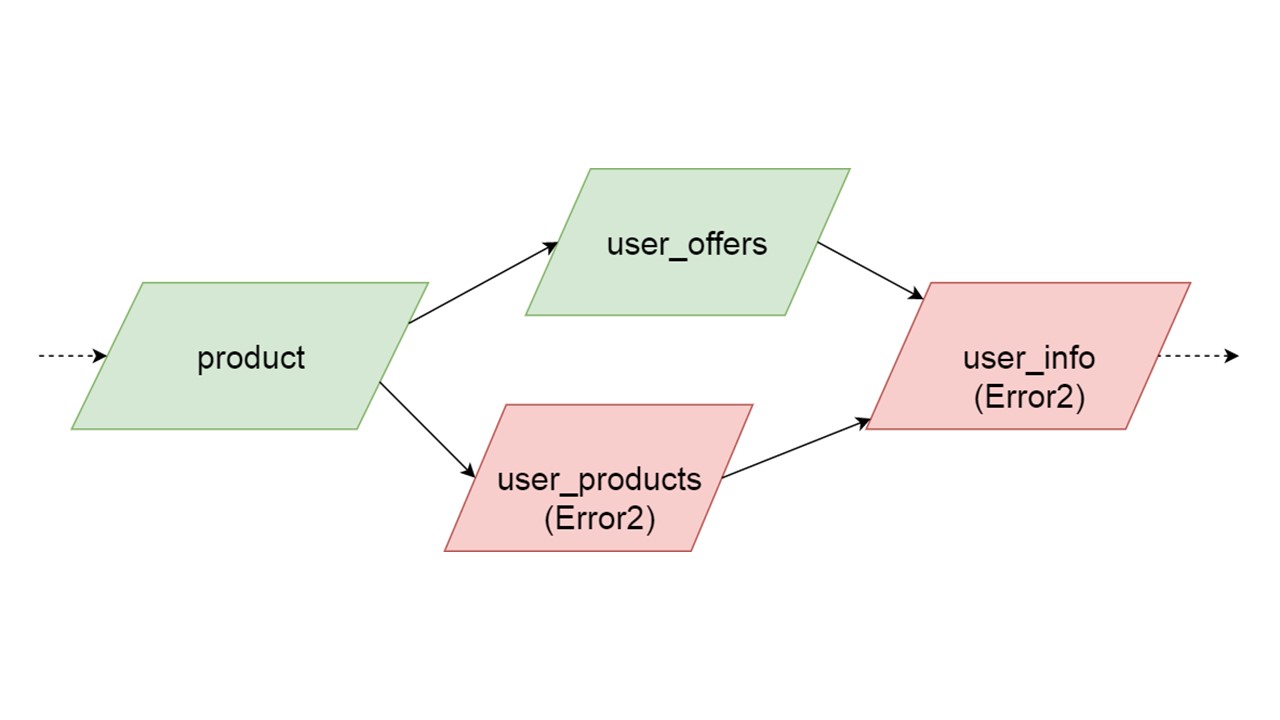
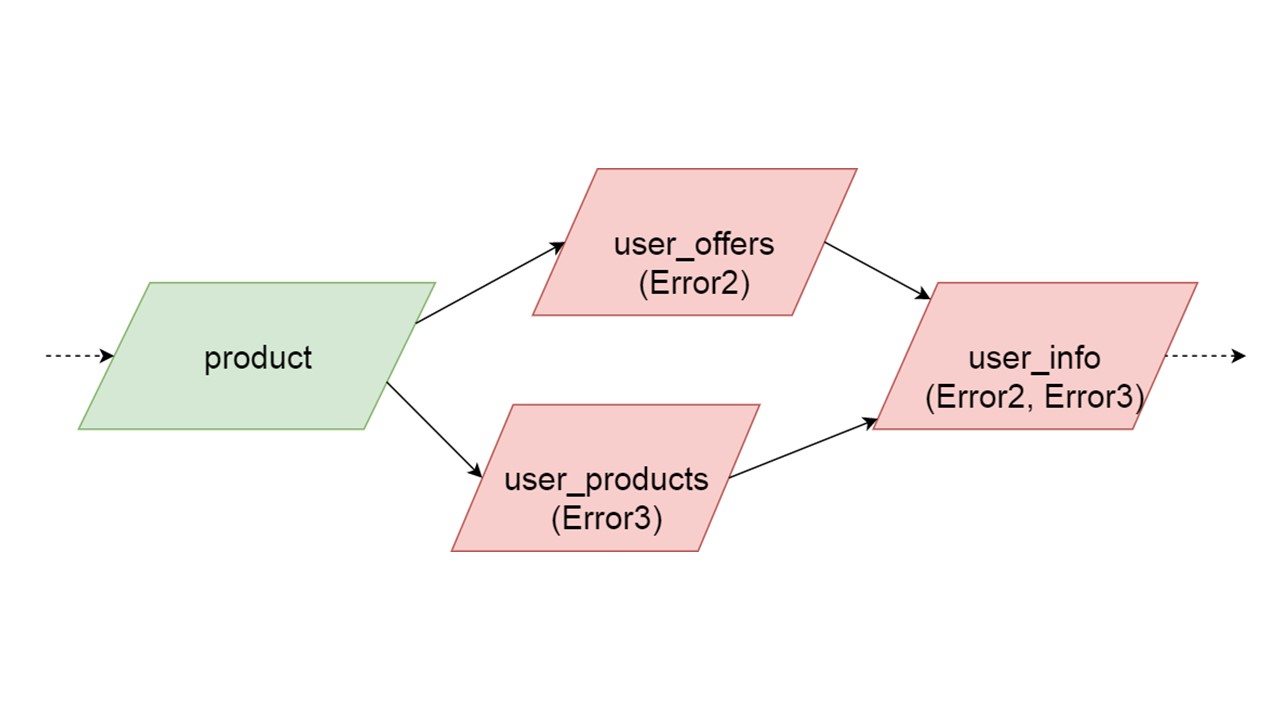
Il peut arriver que deux types initialisés simultanément génèrent des erreurs différentes. Dans ce cas, une fonctionnalité qui dépend des deux types produira un type d'erreur de sommation. Le développeur, initialisant son Fallback dans l'environnement de développement, recevra une liste complète des données avec des erreurs. Naturellement, il peut le corriger ici et aller plus loin. Mais il ne sera pas tel qu'une branche complètement indépendante ferme les erreurs que nous pourrions obtenir, quelle que soit cette branche.
Initialisation: tableaux
Ensuite, nous créons les tables.
def getOffer (user: User, number: Long): Future[OfferData] create table get_offer( key frozen<tuple<frozen<user>, bigint>>PRIMARY KEY, value frozen<friend_data> )
Une telle demande peut lancer directement une demande REST ou SOAP, créer des opérations supplémentaires à l'intérieur ou même exécuter plusieurs demandes. Tout dépend de votre code - comment vous avez organisé le code. Fallback n'analyse pas complètement ce qui se passe à l'intérieur de la méthode à laquelle vous accrochez un tel talon.
La méthode doit être asynchrone, car Fallback est identique.
À Scala, cela est étiqueté avec un type spécial de Future. Cela signifie que le résultat reviendra un jour. Quand exactement - c'est inconnu: peut-être tout de suite, ou peut-être pas.
Pour la méthode, créez une table. La clé du tableau est un tuple de tous types correspondant aux paramètres de cette méthode. La valeur non clé est le résultat, qui est renvoyé de manière asynchrone. Pour chacune de ces tables, nous préparons à l'avance deux requêtes paramétriques: insérer des données et lire des données.
insert into get_offer(key, value) values (?key, ?value); select value from get_offer where key = ?key;
Tout est prêt à interagir avec le SGBD. Reste à savoir comment nous lirons les données de Fallback.
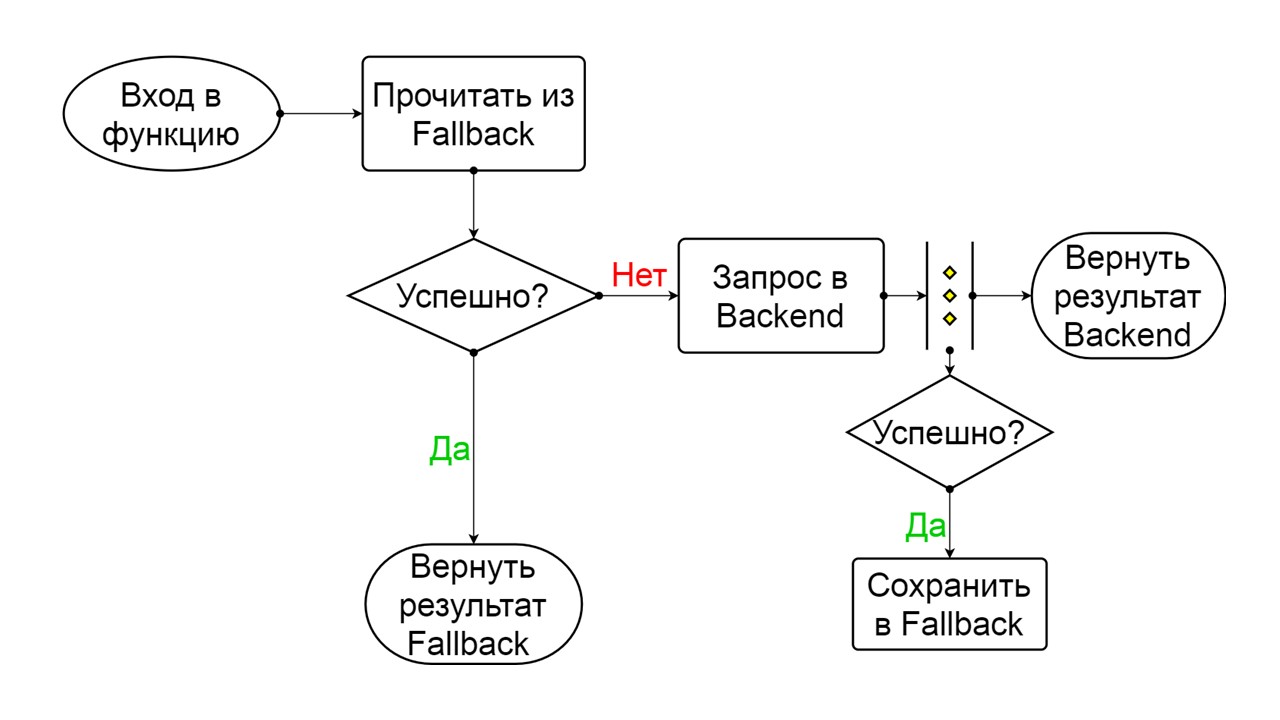
Disjoncteur
Ici, la responsabilité passe dans la zone du fameux modèle de disjoncteur.
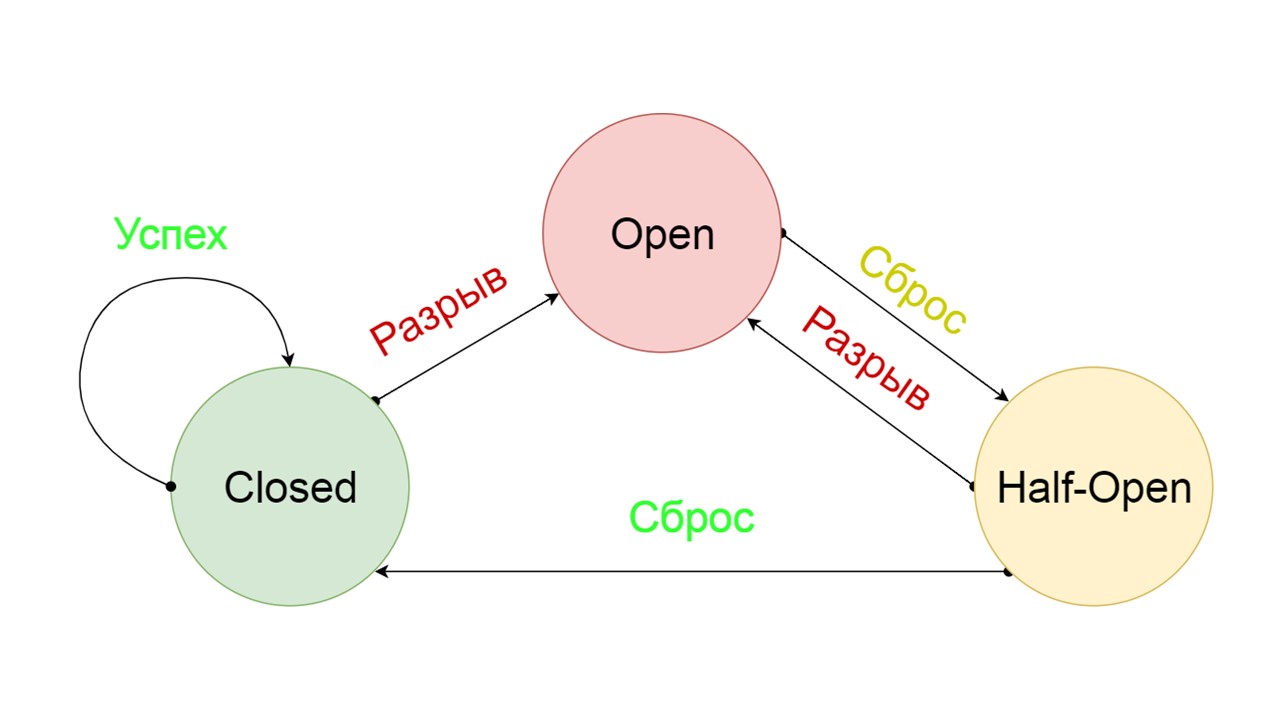
Un disjoncteur typique comprend trois états.
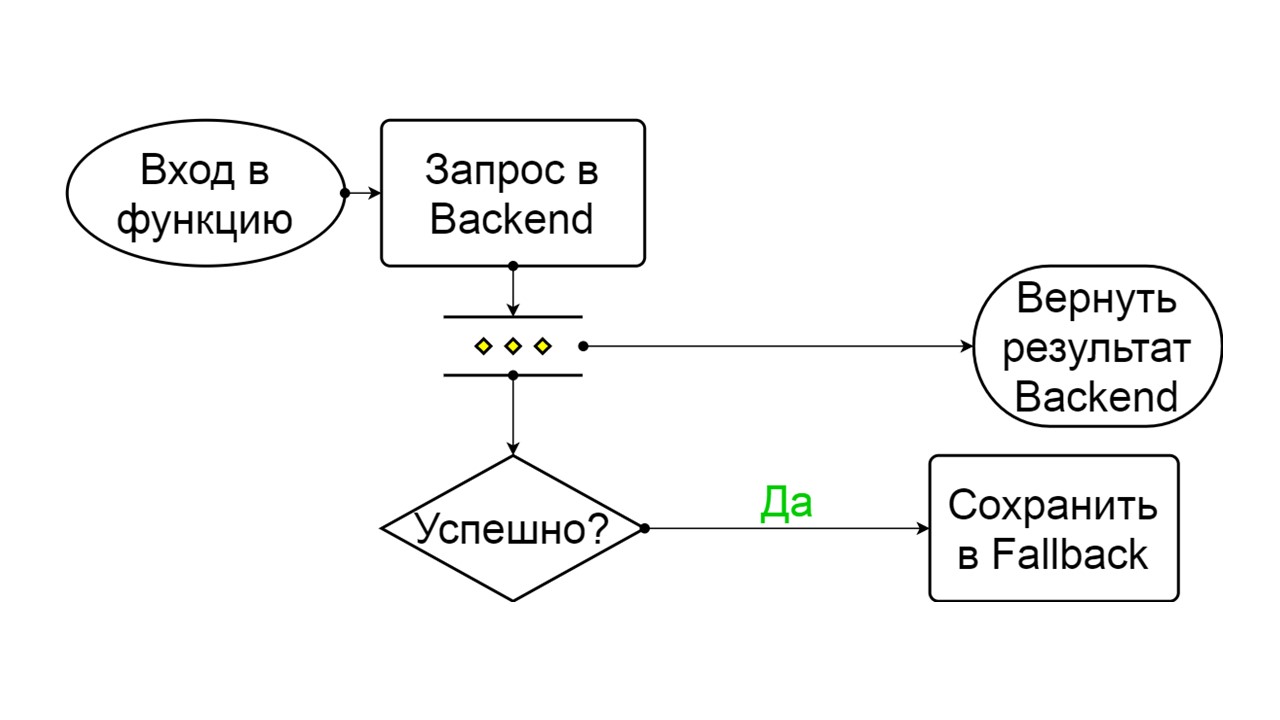
Closed - l'état fermé par défaut qui ferme notre backend. Le principe est que nous lisons d'abord les données depuis le backend, et seulement si nous ne pouvons pas les obtenir, allez à Fallback. Si nous avons réussi à obtenir les données, nous ne regardons pas dans Fallback, mais nous y enregistrons les données et rien ne se passe.
Si les problèmes se succèdent, nous supposons que le backend ment. Afin de ne pas le spammer avec une quantité gigantesque de nouvelles requêtes, nous passons à
Open - dans un état déchiré . Dans ce document, nous essayons de lire uniquement les données de Fallback. Si cela ne fonctionne pas, nous renvoyons immédiatement une erreur et ne touchons même pas le backend principal.
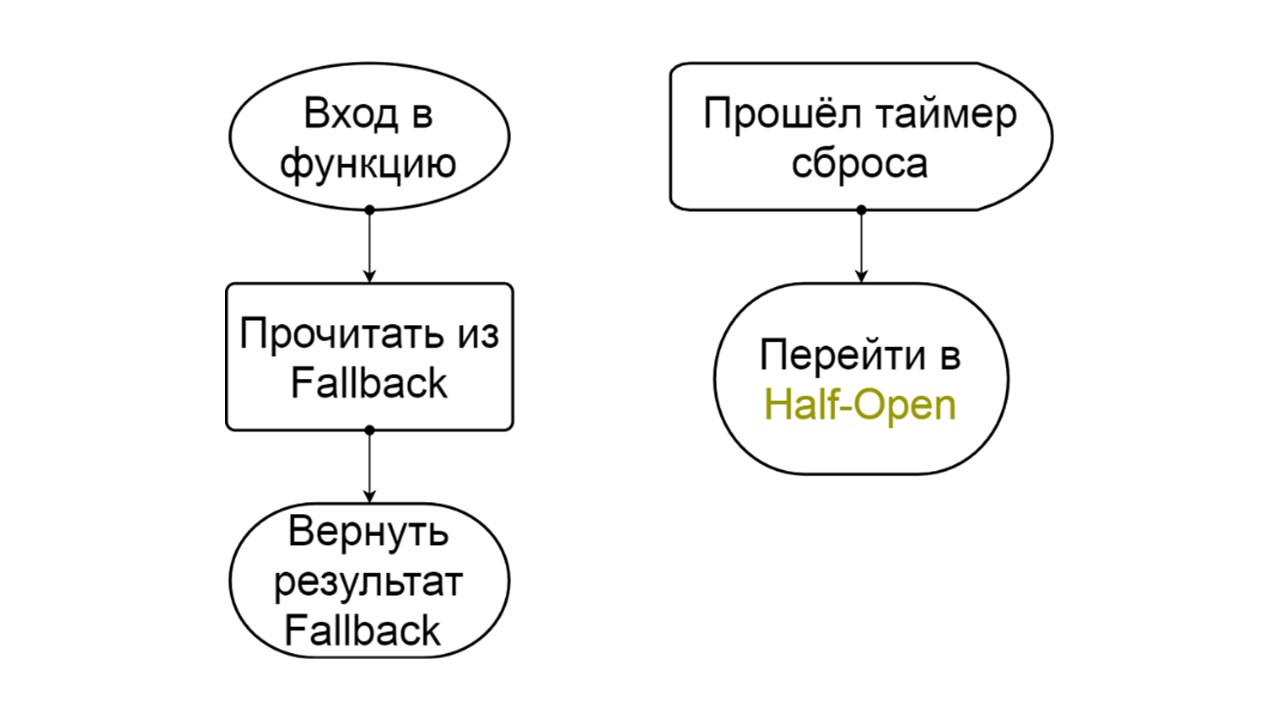
Après un certain temps, nous décidons de savoir si le backend s'est réveillé et essayons de réinitialiser l'état
Half-Open - un état de courte durée . Sa durée de vie est une demande.
Dans l'état de courte durée, nous choisissons de refermer ou d'ouvrir encore plus longtemps. Si dans l'état semi-ouvert, nous atteignons avec succès Fallback et recevons la prochaine demande, nous passons à l'état fermé. Si nous ne pouvions pas passer, nous retournons à Open, mais pour longtemps.
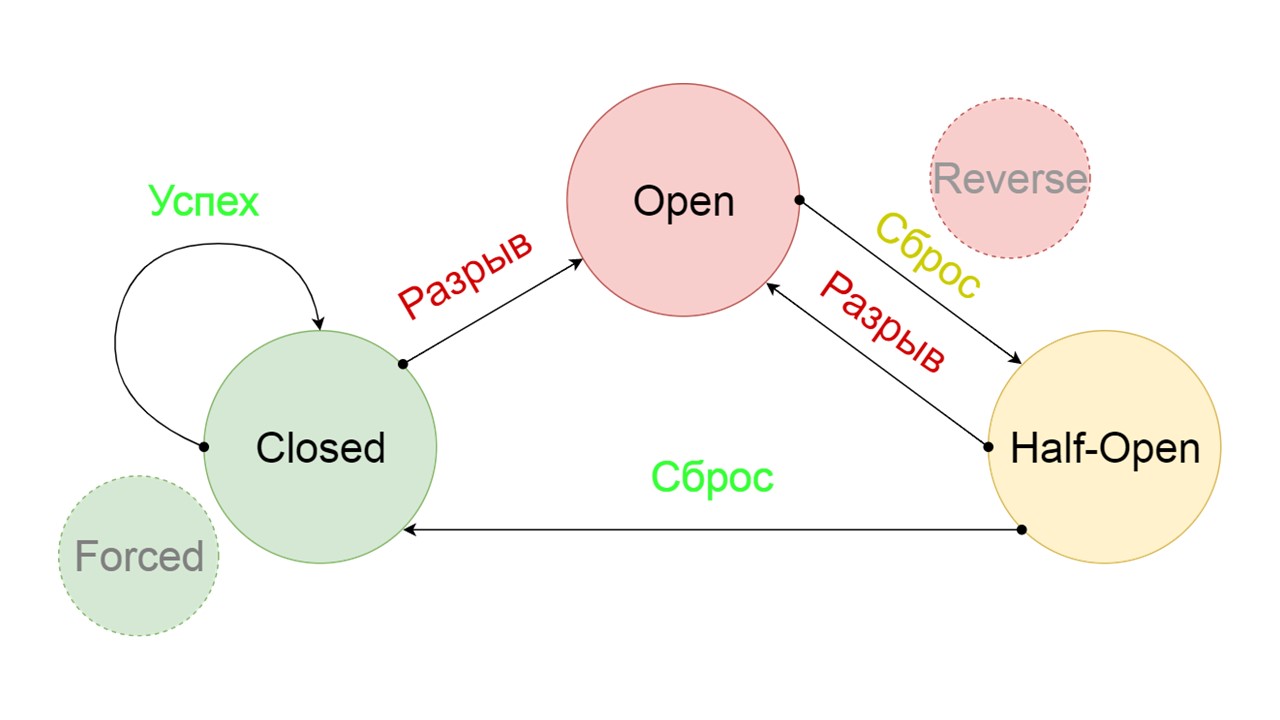
Nous avons ajouté deux états supplémentaires qui ne sont clairement pas liés au circuit du disjoncteur:
- Forcé - état fermé de force;
- Inversé - priorité pour l'état ouvert, fermé inversé.
Voyons voir ce qu'ils font.
Le principe de fonctionnement des États
Fermé Le schéma est vaste, mais il suffit d'en comprendre le principe général. Nous gardons Fallback en parallèle avec la façon dont nous renvoyons le résultat du backend, si tout s'est bien passé et lu à partir de Fallback. Si c'est mauvais partout, nous renvoyons la priorité d'erreur.
Parmi les deux erreurs, sélectionnez l'erreur de backend.
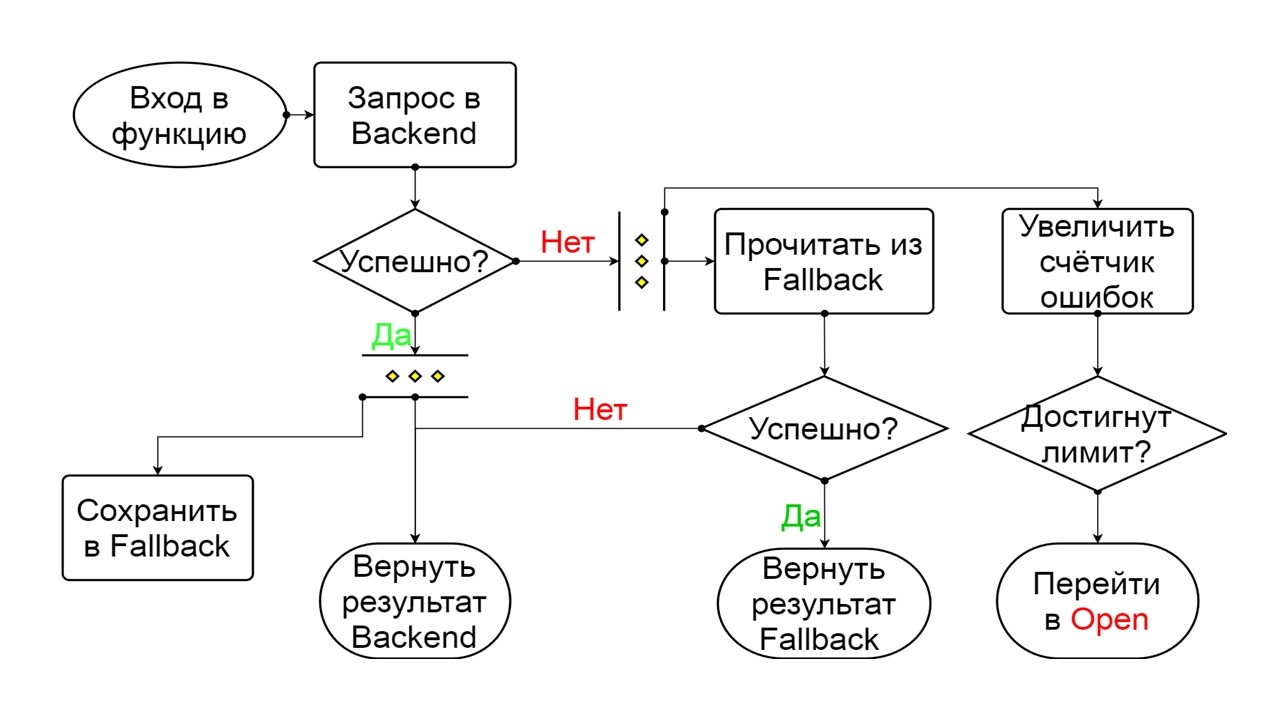
S'il n'y a pas d'erreur, nous incrémentons le compteur en parallèle et passons à l'état ouvert lorsqu'il y a trop de requêtes.
 Ouverte
Ouverte L'état ouvert d'Open est plus simple - nous lisons constamment dans Fallback, quoi qu'il arrive, et après un certain temps, nous essayons de passer à l'état semi-ouvert.
Demi-ouvert . L'état dans la structure ressemble à fermé. La différence est que dans le cas d'une réponse réussie, nous entrons dans un état fermé. En cas d'échec - nous revenons à l'ouverture avec un intervalle prolongé.
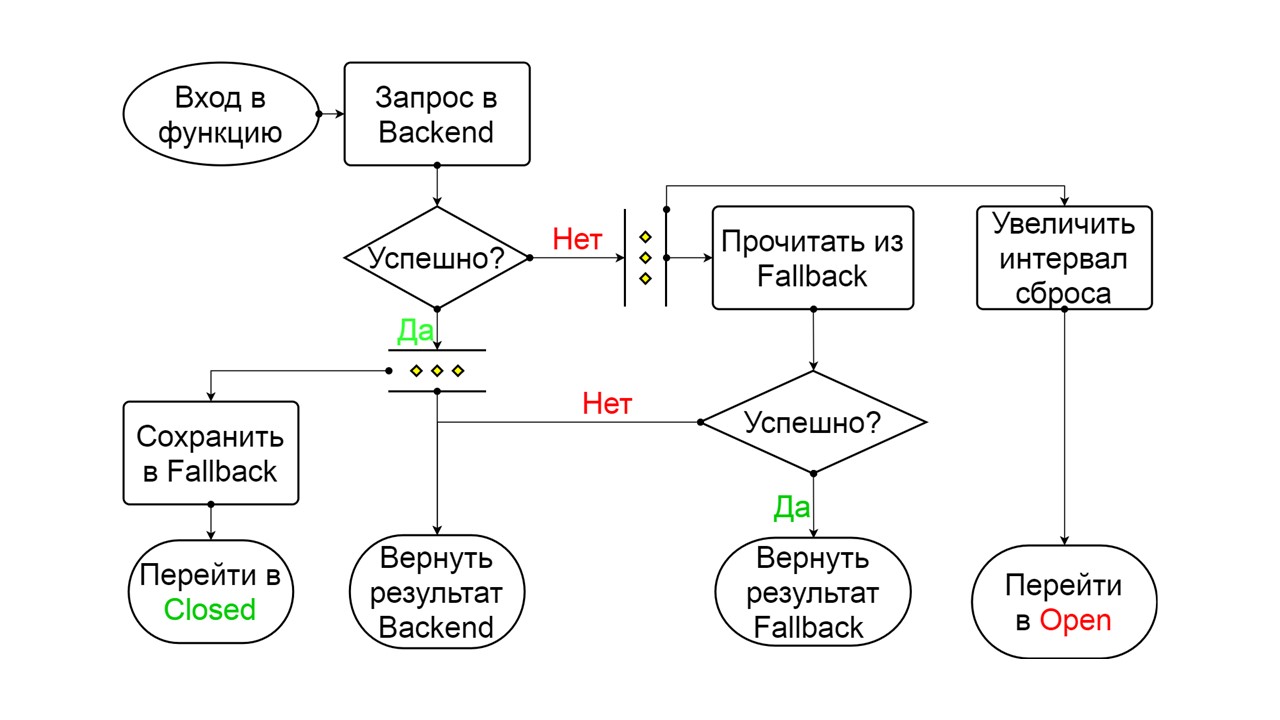 Forcé est un état supplémentaire pour réchauffer le cache
Forcé est un état supplémentaire pour réchauffer le cache . Lorsque nous le remplissons de données, il n'essaie jamais de lire à partir de Fallback, mais ajoute uniquement des enregistrements.
 Inversé est un deuxième état farfelu
Inversé est un deuxième état farfelu . Cela fonctionne comme un cache persistant. Nous activons l'état lorsque nous voulons supprimer définitivement la charge du backend, même si les données peuvent ne pas être pertinentes. Inversé les premières recherches dans Fallback, et si la recherche a échoué, elle va au backend et la traite.
Les problèmes
Avec tout ce schéma, nous avons eu plusieurs problèmes. Le plus grave est de comprendre comment fonctionnent les
déclarations préparées à Cassandra. Ce problème a été corrigé dans la version 4.0, qui n'a pas encore été publiée, donc je vais vous le dire.
Cassandra est conçue pour y connecter des millions de clients en même temps, et tout le monde essaie de préparer ses relevés préparés. Naturellement, Cassandra ne prépare pas chaque instruction préparée, sinon elle manquera de mémoire. Il calcule le paramètre MD5 en fonction du texte, de l'espace clé et des options de requête. Si elle reçoit exactement la même demande avec exactement le même MD5, elle prend la demande déjà préparée. Il contient déjà des informations sur les métadonnées et comment les gérer.
Mais il y a des problèmes de version. Nous publions une nouvelle version, elle a réussi les migrations, ajouté des champs dans les types et exécuté des instructions préparées. Ils reviennent avec la version précédente de notre état et de nos métadonnées - avec des types sans champs. Au moment de la lecture des données, nous essayons d'écrire leurs nouvelles colonnes obligatoires, et sommes confrontés au fait qu'elles n'existent tout simplement pas! Cassandra dit que c'est généralement un type différent qu'elle ne connaît pas.
Nous avons traité ce problème comme suit: nous avons
ajouté un texte unique à chacune de nos demandes préparées .
create table get_offer( key frozen<tuple<frozen<user>, bigint>> PRIMARY KEY, value frozen<friend_data>, query_tag text ) insert into get_offer (key, value, query_tag) values (?key, ?value, 'tag_123'); select value as tag_123 from get_offer where key = ?key;
Nous n'aurons pas des millions de clients connectés, mais une seule session pour chaque nœud qui détient plusieurs connexions. Pour chaque préparation de déclaration une fois. Nous supposons que tout va bien si pour chaque version de l'application ou pour chaque début de nœud, un texte unique est généré, qui sera clairement dans le texte de notre demande.
Nous avons ajouté un champ spécial pour le tromper. Lors de l'insertion, nous écrivons une constante dans ce champ. Il est unique pour chaque lancement ou version d'application - il est configuré dans la bibliothèque. Lors de la lecture, nous utilisons ce nom comme alias pour la valeur que nous obtenons. La demande est exactement la même, nous faisons toujours une sélection de valeur, mais le texte est différent. Cassandra ne se rend pas compte qu'il s'agit de la même demande, calcule un autre MD5 et prépare à nouveau la demande avec de nouvelles métadonnées.
Le deuxième problème est la
course à la
migration . Par exemple, nous voulons effectuer plusieurs migrations parallèles. Commençons quelques notes et en même temps ils commenceront les calculs, ils exécuteront créer des tables, créer des types. Cela peut conduire au fait que sur chaque nœud ou dans chacun des threads parallèles, tout réussira et que deux tables semblent avoir été créées avec succès. Mais à l'intérieur, Cassandra est confuse et nous recevrons des délais pour écrire et lire.
Vous pouvez casser Cassandra si vous essayez de paralléliser des processus à partir de plusieurs threads ou de plusieurs nœuds.
Si nous savons que nous devons avoir la migration de secours, nous
migrons à partir d'un nœud spécial avant la publication . Ce n'est qu'alors que nous démarrerons tous nos nœuds lors de la publication. Nous avons donc résolu ce problème.
Le troisième problème est le
manque de données dans Fallback Cache . Il se peut que nous ayons «soutenu» la méthode, elle devrait stocker les données historiques d'il y a un an, mais en réalité nous l'avons lancée hier.
Le problème a été résolu par l'échauffement . Nous avons utilisé l'état Forced et lancé des nœuds spéciaux qui ne communiqueront pas avec de vrais utilisateurs. Ils prendront toutes les clés possibles que nous supposons et réchaufferont le cache en cercle. L'échauffement va si vite pour ne pas tuer le backend que nous lisons.
Mise à l'échelle des applications, du backend, du big data et du frontend - Scala convient à tout cela. Le 26 novembre, nous organisons une conférence professionnelle pour les développeurs Scala . Styles, approches, des dizaines de solutions pour le même problème, les nuances de l'utilisation d'approches anciennes et éprouvées, la pratique de la programmation fonctionnelle, la théorie de la cosmonautique fonctionnelle radicale - nous parlerons de tout cela lors de la conférence. Demandez un rapport si vous souhaitez partager votre expérience Scala avant le 26 septembre ou réservez vos billets .