Salut Connected Big Data Ad-hoc analytics team from X5 Retail Group.
Dans cet article, nous parlerons de notre méthodologie de test A / B et des défis auxquels nous sommes confrontés quotidiennement.
Le Big Data X5 emploie environ 200 personnes, dont 70 la date des scientifiques et la date des analystes. Notre partie principale est engagée dans des produits spécifiques - demande, assortiment, campagnes de promotion, etc. En plus d'eux, il y a notre équipe d'analyse Ad-hoc séparée.
Nous sommes:
- nous aidons les unités commerciales avec des demandes d'analyse de données qui ne correspondent pas aux produits existants;
- nous aidons les équipes produits si elles ont besoin de mains supplémentaires;
- Nous sommes engagés dans des tests A / B - et c'est la fonction principale de l'équipe.
La situation dans laquelle nous travaillons est très différente des tests A / B typiques. En règle générale, la technique est associée à des mesures en ligne et en ligne: comment les modifications ont affecté la conversion, la rétention, le CTR, etc. La plupart des expériences sont liées à des changements d'interface: réarrangement de la bannière, repeint le bouton, remplacement du texte, etc.
Le commerce X5 est différent - il s'agit de 15 000 magasins hors ligne en direct de différents formats, répartis dans tout le pays. Cette fonctionnalité impose certaines limitations. Premièrement, l'ensemble des métriques qui peuvent être testées varie considérablement, et deuxièmement, la restriction sur les expériences est imposée. La tâche de changer la conception d'une devanture de magasin en ligne n'est pas comparable en termes de travail à la tâche de changer l'ordre des rayons dans les magasins hors ligne.
L'entreprise a une équipe engagée dans un programme de fidélité et leurs pilotes sont les plus proches de l'idée classique des tests A / B. Les questions qui nous viennent sont très atypiques pour les tests A / B «ordinaires». Par exemple:
- Comment la performance financière du magasin changera-t-elle si je change l'ordre des rayons Saucisse et Gâteaux?
- Comment le modèle de désabonnement des clients affectera-t-il le résultat financier?
- Comment la définition de postamates affectera-t-elle les performances du magasin?
Les clients pensent qu'un certain changement affectera positivement l'un des indicateurs (nous en parlerons plus tard). Notre travail consiste à les aider à valider leurs hypothèses sur la base de données.
Mesures
Quels indicateurs testons-nous?
RTO ,
contrôle moyen et
trafic sont les mots les plus fréquemment utilisés dans notre aile d'espace ouvert.
- RTO (chiffre d'affaires de détail) - le montant d'argent gagné par le magasin.
L'une des principales mesures pour les entreprises et la plus difficile à tester.
Le chiffre d'affaires quotidien du magasin est mesuré en millions de roubles. En conséquence, la propagation de l'indicateur est mesurée en au moins des milliers de roubles. La formule longue et complexe pour déterminer la taille de l'échantillon indique que plus la variance est grande, plus il faut de données pour tirer des conclusions significatives. Pour capter l'effet même dans le dixième pour cent avec une si grande dispersion de prise de force, les pilotes dans les magasins doivent passer six mois.
Imaginez la réaction du conseil d'administration, si lors d'une réunion avec eux dire que le pilote doit passer six mois, voire un an dans tous les magasins? =)
Nous avons deux approches standard.
La première approche: nous ne considérons pas le RTO de l'ensemble du magasin, mais une sorte de catégorie de produits. Par exemple, à la suite du réaménagement de deux sections dans le magasin («Gâteaux» et «Saucisses»), une augmentation de la prise de force dans les deux catégories est attendue. Le RTO d'une catégorie est beaucoup plus petit que le RTO de l'ensemble du magasin, par conséquent, la dispersion est plus faible. Dans ce cas, nous espérons que le pilote de ces catégories sera isolé des autres catégories.
Deuxième approche: nous échantillonnons le temps. L'unité d'observation n'est pas la prise de force du magasin pour l'ensemble du pilote, mais la prise de force par semaine ou par jour. Ainsi, nous augmentons le nombre d'observations, tout en conservant la variance des données brutes.
- Chèque moyen , ou RTO / nombre de chèques - montant moyen d'un chèque.
Une partie des changements vise à inciter les gens à acheter plus, nous testons donc le RTO / nombre de chèques, ou le chèque moyen, si nous faisons des analogies avec les mesures habituelles.
La difficulté de tester cette métrique est liée aux spécificités de la vente au détail. Par exemple, avec le lancement pilote de la promotion «3 pour le prix de 2», une personne qui prévoyait d'acheter un produit en achèterait trois, et le montant du chèque augmentera. Mais que se passe-t-il s'il devient plus tard moins susceptible d'aller au magasin et que le pilote ne réussit pas vraiment?
- Trafic - le nombre de chèques dans le magasin pendant une certaine période de temps.
Pour éviter des conclusions erronées lors du test d'hypothèses qui affectent la vérification moyenne, nous examinons simultanément les changements de trafic. Nous ne pouvons pas suivre directement le nombre de personnes qui sont venues au magasin, car tous les visiteurs ne sont pas des clients du programme de fidélité, donc pour les tests A / B, chaque chèque est une «visite unique» pour le client. Par analogie avec la prise de force, nous considérons le trafic à différents intervalles de temps: trafic par jour, trafic par heure.
L'interrelation entre le contrôle moyen et le trafic est très importante: le pilote pourrait-il augmenter le contrôle moyen, mais réduire le trafic et finalement conduire non pas à une augmentation de la prise de force, mais à sa diminution? Le pilote pourrait-il aider à augmenter le trafic sans modifier la facture moyenne?
- Marge - la différence entre le prix d'un produit et son coût
Il existe des pilotes dans le cadre desquels nous modifions les prix des marchandises - pour certains, le prix a augmenté, pour certains au contraire. Puisque nous n'affectons pas les coûts de production, en modifiant les prix, nous modifions la marge des marchandises. Un tel pilote peut entraîner une augmentation du trafic et augmenter le contrôle moyen. Mais cela signifie-t-il que le pilote réussit et mérite de changer les prix dans tous les magasins du réseau? Non, il pourrait très bien arriver que les gens commencent à acheter des produits à marge négative ou faible plus souvent et abandonnent des produits à marge élevée. Par conséquent, une augmentation de l'OTR n'est pas toujours suivie d'une augmentation de la marge totale; il convient donc de tester ces indicateurs séparément.
Eh bien, disons que nous avons décidé des mesures cibles. Les questions suivantes:
- Quel effet de taille le client prévoit-il de recevoir?
- Quel effet peut-on réellement détecter dans l'expérience?
- Combien de temps dure l'expérience?
- Quels groupes?
Résumé de l'expérience
Les tests A / B menés sur les utilisateurs en ligne ont un avantage significatif - ils ont une grande capacité de généralisation. En d'autres termes, les conclusions obtenues au cours de l'expérience peuvent être adaptées à tous les utilisateurs. La capacité de généralisation est garantie par le paramétrage de l'expérience: les groupes de contrôle et de test sont formés de manière aléatoire, presque exactement les deux groupes de la même distribution, vous pouvez attraper beaucoup de trafic dans les deux groupes - il y aurait un budget.
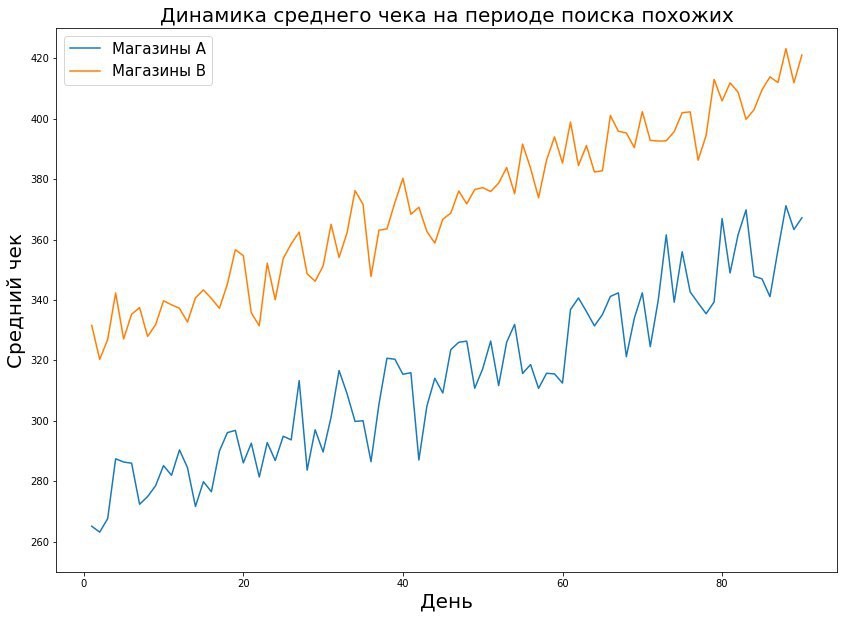
Dans le cas de la vente au détail hors ligne, aucun de ces paramètres ne fonctionne. Premièrement, le nombre de magasins est limité. Deuxièmement, les magasins sont très différents les uns des autres. Le magasin Perekrestok dans le quartier résidentiel et le Perekrestok près du centre d'affaires sont, en fait, des objets très différents de différentes distributions.

Sur le graphique, nous voyons que les magasins du groupe de test sont différents des magasins de l'ensemble du réseau. C'est une situation assez typique: dans la chaîne de Pyaterochka, les magasins sont situés non seulement dans les villes, mais aussi dans de petites colonies. Les grands pilotes se déroulent le plus souvent dans les villes. Quel que soit l'effet que nous capturons, sa mise à l'échelle sur l'ensemble du réseau est incorrecte.
L'effet total
Є du pilote que nous évaluons par la formule:

a est la zone d'intersection des distributions du groupe pilote et de tous les magasins du réseau.
Notez que ce n'est pas une conséquence des lois statistiques, mais notre hypothèse sur la façon dont il est logique de considérer l'effet cumulatif.
L'option idéale consiste à recruter un échantillon représentatif dans le groupe de test, c'est-à-dire les magasins qui reflètent vraiment l'état complet du réseau. Mais la représentativité conduit à l'hétérogénéité de l'échantillon, car les magasins avec une PDF faible ou élevée seront échantillonnés.
Taille des groupes, durée du pilote et effet détectable minimal
Et maintenant, pour la chose la plus importante - la taille de l'effet et la durée du pilote. En règle générale, nous sommes confrontés à l'une des trois situations suivantes:
- le client a une limite de temps pour le pilote et le nombre de magasins avec lesquels vous pouvez travailler;
- le client sait quelle taille d'effet il s'attend à recevoir et demande d'indiquer le nombre de magasins dont le pilote a besoin (puis les magasins eux-mêmes);
- le client est ouvert à nos offres.
On ne peut pas dire que l'un des scénarios est plus simple, car en tout cas nous préparons un tableau de l'effet-erreur.
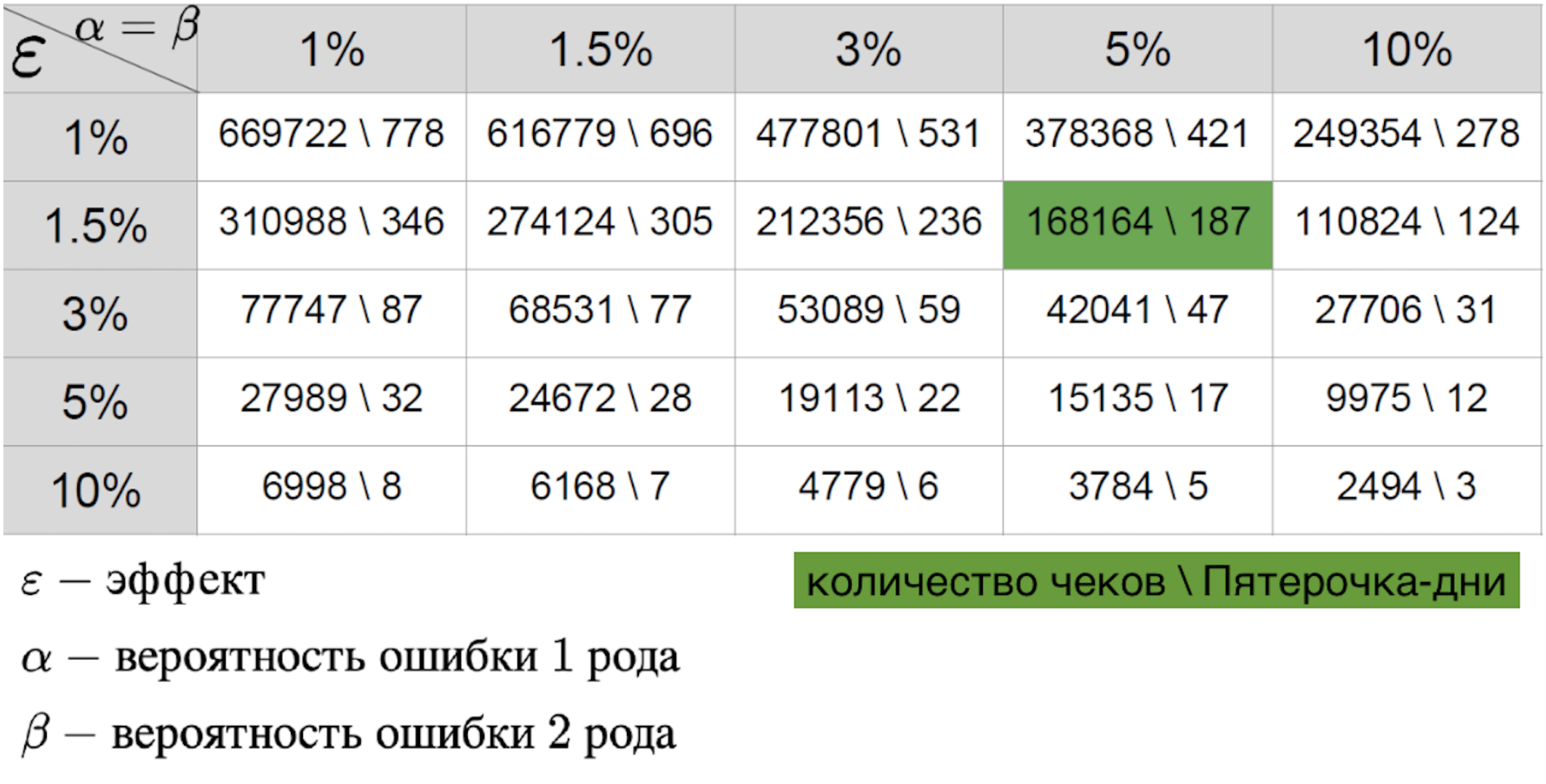
Important pour elle:
- une erreur du premier type - la probabilité de voir l'effet quand il n'est pas là;
- une erreur du deuxième type - la probabilité de sauter l'effet quand il l'est;
- l'ampleur de l'effet que l'on s'attend à voir avec un pilote réussi.
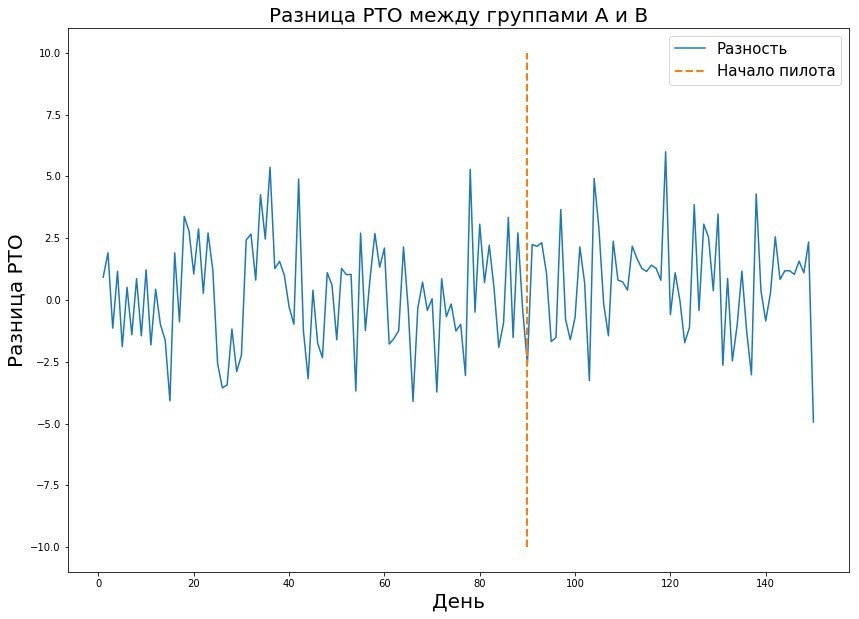
La combinaison de ces trois paramètres vous permet de calculer la durée requise du pilote. La valeur dans le tableau est la taille de l'échantillon - dans ce cas, le nombre de reçus ou la métrique moyenne dans le magasin par jour, qui sont nécessaires pour mener le pilote. Si nous parlons du monde réel, la probabilité d'erreurs du premier et du deuxième type est généralement de 5 à 10%. Comme le montre le tableau, avec de telles erreurs fixes, nous avons besoin de 421 jours de pyaterochka pour capter l'effet d'un pour cent. Il semble que le chiffre soit assez bon - après tout, 421 jours Pyaterochka est un pilote dans 40 magasins pendant 10 jours. Cependant, il y a un «mais» - il y a très peu de pilotes qui s'attendent vraiment à un effet d'un pour cent. Habituellement, nous parlons de dixièmes de pour cent. Étant donné que le RTO est mesuré en milliards, un dixième de pour cent de l'effet d'un pilote réussi peut entraîner une forte augmentation des revenus. Pour cette raison, je veux mesurer même le plus petit effet. Mais plus la taille de l'effet est petite, plus l'erreur du second type est élevée. Cela est compréhensible: le petit effet est similaire au bruit aléatoire et sera rarement considéré comme un véritable écart par rapport à la norme. Ceci est clairement visible dans le graphique ci-dessous, où nous voulons attraper un petit effet dans les données avec une grande variance.

Test A / A
Avant le démarrage du pilote, vous devez décider du groupe de test et de contrôle. Le client peut avoir ou non un groupe pilote. Nous sommes prêts à l'aider dans les deux cas en demandant des restrictions - par exemple, les magasins doivent être strictement de trois régions spécifiques.
Supposons que nous ayons choisi en quelque sorte un groupe de test et de contrôle. Comment être sûr que les groupes sélectionnés sont bons et que vous pouvez vraiment effectuer des tests A / B sur eux? Il semble que tout semble harmonieux: nous avons marqué le nombre requis d'observations, selon la formule nous pouvons attraper l'effet de 0,7%, nous avons trouvé des magasins similaires. Qu'est-ce qui ne nous convient pas maintenant?
Malheureusement, beaucoup de faits sérieux:
- les éléments de l'échantillon ne sont pas de la même distribution - notre échantillon est un mélange d'observations provenant de différents magasins, et chaque magasin a sa propre distribution.
- les éléments de l'échantillon ne sont pas indépendants - dans l'échantillon, il y a de nombreuses observations d'un magasin, respectivement, il y a un lien entre eux;
- l'égalité des moyens n'est pas garantie en l'absence de pilote - c'est-à-dire nous ne sommes pas du tout sûrs que s'il n'y avait pas de pilote, les statistiques du magasin ne seraient pas différentes.
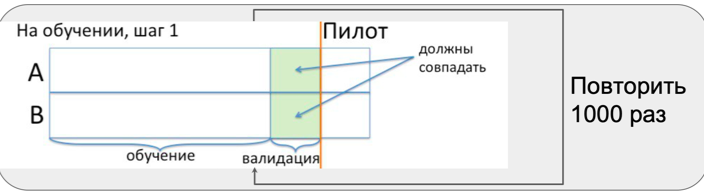
Tous ces problèmes ne sont pas pris en compte dans le calcul de la formule de sélection du nombre d'observations en fonction des erreurs et des effets. Pour comprendre l'étendue de l'impact des problèmes ci-dessus, nous effectuons des tests A / A. En fait, il s'agit d'une simulation de l'ensemble du pilote en magasin à un moment où il n'y a pas de pilote en magasin. Cette période est appelée pré-pilote.

Pendant la période pré-pilote, nous répétons trois fois plusieurs étapes:
- sélection de groupes similaires;
- tests d'égalité dans deux groupes;
- ajouter de l'effet au groupe de test et tester les moyens d'égalité.

Faire correspondre des groupes similaires
Nous n'inventons pas de vélo, nous recherchons donc des groupes similaires avec la bonne vieille méthode des voisins les plus proches. La stratégie de génération de fonctionnalités pour le magasin est un art distinct. Nous avons trouvé trois méthodes de travail:
- Chaque magasin est décrit par un vecteur d'entités selon la métrique que nous testons. Par exemple, lorsque nous examinons le chèque moyen, nous décrivons les chèques moyens quotidiens pendant 8 semaines - nous obtenons 56 signes pour le magasin. Ensuite, nous prenons la distance euclidienne entre les signes d'une paire de magasins.
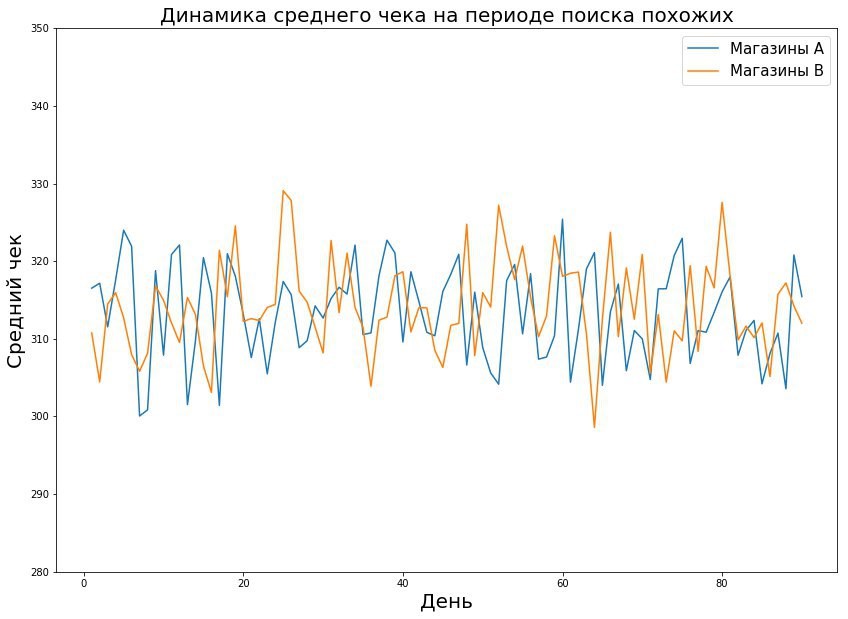
- Trouvez des magasins dont la dynamique est similaire. Les magasins peuvent différer en valeurs absolues de métriques, mais coïncident dans les tendances - et avec certaines manipulations mathématiques, ces magasins peuvent être considérés comme les mêmes.
- Prédisez les performances du magasin au cours de la période du pilote (dans le futur) et sélectionnez des performances similaires en fonction de celles-ci - mais ici, nous avons besoin d'un oracle qui peut prédire les performances du pilote de manière assez précise.
Nous adhérons à une hypothèse très simple: si les magasins étaient similaires avant le pilote, alors s'il n'y avait pas eu de changement de pilote, ils seraient restés similaires.
Vous pouvez remarquer que même dans ces trois méthodes de travail, il existe de nombreux aspects qui peuvent être variés: le nombre de jours / semaines par lesquels une caractéristique est considérée, une méthode pour évaluer la dynamique d'un indicateur, etc.
Il n'y a pas de pilule universelle, dans chaque expérience, nous passons par différentes options en fonction de notre objectif. Mais c'est très simple: trouvez une méthode pour sélectionner les voisins les plus proches qui donne des erreurs raisonnables du premier et du deuxième type. D'où ils viennent, nous disons plus loin.
Test d'égalité des moyens, ou erreur du premier type de méthode
Rappelons qu'à ce stade, nous:
- déterminé avec le client l'ampleur de l'effet et la durée du pilote
- a expliqué l'essence des erreurs du premier et du deuxième type
- construit une méthode pour sélectionner des groupes similaires
L'objectif de cette étape est de s'assurer que la méthode que nous avons sélectionnée dans la section 3 trouve des groupes tels qu'avant le démarrage du pilote, l'indicateur (RTO, contrôle moyen, trafic) dans ces magasins n'est pas statistiquement différent.
Dans le cycle, nous sélectionnons les groupes sélectionnés à plusieurs reprises pour l'égalité par une sorte de test statistique et de bootstrap. Si la proportion d'erreurs (c'est-à-dire que les groupes ne sont pas égaux les uns aux autres) est supérieure au seuil, la méthode est rejetée et une nouvelle est sélectionnée. Donc, jusqu'à ce que nous atteignions le seuil d'erreur souhaité.
Il est important de savoir à quelle fréquence nous captons l'effet lorsqu'il n'est pas là, c'est-à-dire si notre méthode de sélection répond ou non aux différences aléatoires entre les magasins.
Ajout d'un effet ou d'une erreur du deuxième type de méthode
Une question raisonnable, mais ne nous recyclons-nous pas de manière à percevoir également les effets réels comme du bruit et à les ignorer? En d'autres termes, pouvons-nous détecter un effet quand il l'est?
Après avoir vérifié à la dernière étape que les groupes coïncident, nous ajoutons un effet artificiel à l'un des groupes, c'est-à-dire Nous garantissons que le pilote réussit et que l'effet devrait l'être.
Cette fois, l'objectif est de savoir à quelle fréquence l'hypothèse d'égalité est rejetée, c'est-à-dire le test a permis de distinguer deux groupes. L'erreur dans ce cas est de supposer que les groupes sont égaux. Nous appelons cette erreur une erreur du deuxième type.
De nouveau dans le cycle, nous testons l'égalité du groupe témoin et du groupe de test «bruyant». Si nous commettons des erreurs assez rarement, nous pensons que la méthode de sélection des groupes a passé la validation. Il peut être utilisé pour sélectionner des groupes dans la période pilote et être sûr que si le pilote donne un effet, nous serons en mesure de le détecter.

À propos de l'hétérogénéité
Nous avons déjà mentionné que l'hétérogénéité des données est l'un des pires ennemis que nous combattons. Les inhomogénéités proviennent de diverses causes profondes:
- hétérogénéité des achats - chaque magasin a sa propre valeur métrique moyenne (dans les magasins RTO de Moscou et le trafic est beaucoup plus que dans les magasins du village)
- hétérogénéité par jour de la semaine - répartition différente du trafic et contrôle moyen différent selon les jours de la semaine: le trafic du mardi ne ressemble pas au trafic du vendredi
- hétérogénéité météorologique - les gens font leurs courses différemment selon les conditions météorologiques
- l'hétérogénéité de la période de l'année - le trafic pendant les mois d'hiver diffère du trafic en été - cela doit être pris en compte si le pilote dure plusieurs semaines.
L'inhomogénéité augmente la variance qui, comme mentionné ci-dessus, dans l'évaluation des magasins de PTO prend déjà une énorme importance. La taille de l'effet capté dépend directement de la variance. Par exemple, réduire la dispersion d'un facteur quatre vous permet de détecter un demi-effet.
Dans le cas le plus simple, nous sommes aux prises avec l'hétérogénéité de la linéarisation.
Supposons que nous ayons eu un pilote dans deux magasins pendant trois jours (oui, cela contredit toutes les formules prescrites concernant la taille de l'effet, mais ceci est un exemple). Les
RTO moyens dans les magasins sont respectivement de 200 000 et 500 000, tandis que la variance dans les deux groupes est de 10 000, et selon toutes les observations - 35 000
Après le pilote, les moyennes se situent dans les 300 et 600 groupes et les écarts sont respectivement de 10 000 et 22 500 et le groupe entier est de 40 000.

Une démarche simple et élégante consiste à linéariser les données, c'est-à-dire soustraire de chaque période la valeur moyenne de la précédente.

En sortie, l'échantillon: 100, 0, 200, -50, 100, 250. La dispersion dans la période pilote a été réduite de 3 fois à 13000.
Cela signifie que nous pouvons voir un effet beaucoup plus subtil qu'avec les valeurs absolues d'origine.
Ce n'est pas la seule façon de gérer l'hétérogénéité. Nous en parlerons dans le prochain article.
Approche générale des tests A / B
La préparation des grands pilotes et leur évaluation passent par notre équipe et sont minutieusement testées.
Notre protocole:
- recevoir des informations du client sur la métrique et l'effet attendu;
- déterminer la taille des groupes et la durée du pilote;
- développer un algorithme de répartition des magasins par groupes;
- effectuer un test A / A entre les groupes et valider cet algorithme;
- attendez la fin du pilote et calculez l'effet.
Aucune de ces étapes ne passe sans difficultés, chacune a ses particularités. Comment nous traitons certains d'entre eux, nous l'avons décrit dans cet article. Dans le prochain, nous parlerons de ....
L'équipe
Au final, je voudrais mentionner tous les acteurs:
- Valery Babushkin
- Alexander Sakhnov
- Denis Ivanov
- Sergey Demchenko
- Nikolay Nazarov
- Sergey Kabanov
- Yuri Galimullin
- Helen Tevanyan
- Vladislav Ladenkov
- Sergey Zakharov
- Histoires de Vasily
- Alexander Belyaev
- Kismat Magomedov
- Egor Krashennikov
- Egor Karnaukh
- Svyatoslav Oreshin
- Yuri Trubitsyn