Aujourd'hui, nous allons commencer à étudier le routage OSPF. Ce sujet, ainsi que la prise en compte du protocole EIGRP, est le plus important tout au long du cours CCNA. Comme vous pouvez le voir, la section 2.4 est intitulée «Configuration, vérification et problèmes avec une zone unique et multizone OSPFv2 pour IPv4 (sauf pour l'authentification, le filtrage, la sommation manuelle des itinéraires, la redistribution, la zone sans issue, le réseau virtuel et LSA)».

Le sujet OSPF est assez étendu, il faudra donc 2, voire 3 tutoriels vidéo. La leçon d'aujourd'hui sera consacrée au côté théorique de la question, je vais vous dire ce qu'est ce protocole en termes généraux et comment il fonctionne. Dans la vidéo suivante, nous passerons en mode de configuration OSPF à l'aide de Packet Tracer.
Ainsi, dans cette leçon, nous allons examiner trois choses: qu'est-ce que l'OSPF, comment cela fonctionne-t-il et quelles sont les zones OSPF. Dans la leçon précédente, nous avons dit que OSPF est un protocole de routage de type état de liaison qui examine les canaux de communication entre les routeurs et prend des décisions en fonction de la vitesse de ces canaux. Un canal long avec une vitesse plus élevée, c'est-à-dire avec une bande passante plus élevée, sera une priorité par rapport à un canal court avec une bande passante plus faible.
Le protocole RIP, étant un vecteur de distance, choisira un chemin dans un saut, même si ce canal a une faible vitesse, et OSPF choisira un itinéraire long parmi plusieurs espoirs si la vitesse totale sur cet itinéraire est supérieure à la vitesse du trafic sur un itinéraire court.

Plus tard, nous nous pencherons sur l'algorithme de prise de décision, pour l'instant vous devez vous rappeler que OSPF est le protocole d'état de lien Link State. Cette norme ouverte a été créée en 1988, de sorte que tout fabricant d'équipement réseau et tout fournisseur de réseau pouvaient l'utiliser. Par conséquent, OSPF est beaucoup plus populaire que EIGRP.
OSPF version 2 ne prend en charge que IPv4, et un an plus tard, en 1989, les développeurs ont annoncé la sortie de la version 3, qui prend en charge IPv6. Cependant, la troisième version entièrement fonctionnelle d'OSPF pour IPv6 n'est apparue qu'en 2008. Pourquoi avez-vous choisi OSPF? Dans la dernière leçon, nous avons appris que ce protocole de passerelle interne effectue la convergence des routes beaucoup plus rapidement que RIP. Il s'agit d'un protocole sans classe.
Si vous vous souvenez, RIP est un protocole de classe, c'est-à-dire qu'il n'envoie pas d'informations sur le masque de sous-réseau, et s'il rencontre une adresse IP de classe A / 24, il ne l'acceptera pas. Par exemple, si vous lui présentez une adresse IP de la forme 10.1.1.0/24, il la percevra comme un réseau 10.0.0.0, car il ne comprend pas quand un réseau est divisé en sous-réseaux utilisant plus d'un masque de sous-réseau.
OSPF est un protocole sécurisé. Par exemple, si deux routeurs échangent des informations OSPF, vous pouvez configurer l'authentification afin de pouvoir partager des informations avec un routeur voisin uniquement après avoir entré le mot de passe. Comme nous l'avons dit, il s'agit d'une norme ouverte, c'est pourquoi l'OSPF est utilisé par de nombreux fabricants d'équipements réseau.
Dans un sens global, OSPF est le mécanisme d'échange d'annonces d'état de liaison, ou LSA. Les messages LSA sont générés par le routeur et contiennent beaucoup d'informations: un identifiant unique pour le routeur router-id, des données sur les réseaux connus du routeur, des données sur leur coût, etc. Le routeur a besoin de toutes ces informations pour prendre une décision concernant le routage.

Le routeur R3 envoie ses informations LSA au routeur R5 et le routeur R5 partage ses informations LSA avec R3. Ces LSA sont une structure de données qui forme une base de données d'états de liens, ou LSDB, base de données d'états de liens. Le routeur collecte tous les LSA reçus et les place dans son LSDB. Une fois que les deux routeurs ont créé leurs propres bases de données, ils échangent des messages Hello, qui sont utilisés pour découvrir les voisins, et commencent la procédure de comparaison de leurs LSDB.
Le routeur R3 envoie un message DBD, ou «description de la base de données», à R5, et R5 envoie son DBD à R3. Ces messages contiennent les indices LSA qui se trouvent dans les bases de chaque routeur. Après avoir reçu un DBD, R3 envoie une demande d'état du réseau LSR à R5, qui dit: «J'ai déjà les messages 3.4 et 9, alors n'envoyez-moi que 5 et 7».
R5 fait exactement la même chose, en disant au troisième routeur: "J'ai des informations 3,4 et 9, alors envoyez-moi 1 et 2". Lors de la réception des demandes LSR, les routeurs renvoient des paquets de mise à jour de l'état du réseau LSU, c'est-à-dire qu'en réponse à leur LSR, le troisième routeur reçoit le LSU du routeur R5. Une fois que les routeurs ont mis à jour leurs bases de données, tous, même si vous avez 100 routeurs, auront le même LSDB. Dès que les bases de données LSDB sont créées dans les routeurs, chacun d'eux connaîtra l'ensemble du réseau dans son ensemble. Le protocole OSPF utilise l'algorithme Shortest Path First pour créer une table de routage. La condition la plus importante pour son fonctionnement correct est donc la synchronisation du LSDB de tous les périphériques du réseau.

Le diagramme ci-dessus contient 9 routeurs, chacun échangeant des messages LSR, LSU, etc. avec des voisins. Tous sont connectés les uns aux autres comme p2p ou interfaces point à point qui prennent en charge le protocole OSPF et interagissent les uns avec les autres pour créer le même LSDB.

Dès que les bases de données sont synchronisées, chaque routeur, en utilisant l'algorithme de chemin le plus court, forme sa propre table de routage. Différents routeurs auront des tables différentes. Autrement dit, tous les routeurs utilisent le même LSDB, mais créent des tables de routage en fonction de leurs propres considérations sur les itinéraires les plus courts. Pour utiliser cet algorithme, OSPF a besoin de mises à jour régulières de la base de données LSDB.
Donc, pour son propre fonctionnement, OSPF doit d'abord fournir 3 conditions: trouver des voisins, créer et mettre à jour LSDB, et créer une table de routage. Pour remplir la première condition, l'administrateur réseau peut avoir besoin de configurer manuellement l'ID de routeur, les horaires ou le masque générique. Dans la vidéo suivante, nous verrons comment configurer l'appareil pour qu'il fonctionne avec OSPF, jusqu'à présent, vous devez savoir que ce protocole utilise un masque inversé, et s'il ne correspond pas, si vos sous-réseaux ne correspondent pas ou que l'authentification ne correspond pas, le voisinage des routeurs ne sera pas formé. Par conséquent, lors du dépannage des problèmes OSPF, vous devez découvrir pourquoi ce voisinage ne se forme pas, c'est-à-dire vérifier que les paramètres ci-dessus correspondent.
En tant qu'administrateur réseau, vous n'êtes pas impliqué dans le processus de création d'un LSDB. Les bases de données sont mises à jour automatiquement après la création d'un voisinage de routeurs, ainsi que la création de tables de routage. Tout cela est effectué par l'appareil lui-même, qui est configuré pour fonctionner avec le protocole OSPF.
Regardons un exemple. Nous avons 2 routeurs, pour lesquels j'ai attribué des identifiants RID 1.1.1.1 et 2.2.2.2 pour plus de simplicité. Dès que nous les connectons, le canal de liaison passe immédiatement à l'état haut, car j'ai d'abord configuré ces routeurs pour qu'ils fonctionnent avec OSPF. Dès que le canal de communication est formé, le routeur A enverra immédiatement le deuxième paquet Hello. Ce package contiendra des informations que ce routeur n'a "vu" personne sur ce canal, car il envoie pour la première fois Hello, ainsi que son propre identifiant, des données sur le réseau qui lui est connecté et d'autres informations qu'il peut partager avec un voisin.

Ayant reçu ce paquet, le routeur B dira: "Je vois que sur ce canal de communication il y a un candidat potentiel pour le voisinage OSPF" et passera à l'état initial Init. Le paquet Hello n'est pas un message de monodiffusion ou de diffusion, c'est un paquet de multidiffusion envoyé à l'adresse IP de multidiffusion OSPF 224.0.0.5. Certaines personnes demandent ce qu'est un masque de sous-réseau pour une multidiffusion. Le fait est qu'une multidiffusion n'a pas de masque de sous-réseau, elle est distribuée comme un signal radio qui est entendu par tous les appareils réglés sur sa fréquence. Par exemple, si vous souhaitez écouter une émission de radio FM à une fréquence de 91,0, réglez votre radio sur cette fréquence.
De la même manière, le routeur B est configuré pour recevoir des messages pour l'adresse de multidiffusion 224.0.0.5. En écoutant ce canal, il reçoit le paquet Hello envoyé par le routeur A et y répond avec son message.

De plus, le voisinage ne peut être établi que si la réponse B satisfait à un ensemble de critères. Le premier critère - la fréquence d'envoi des messages Hello et l'intervalle d'attente d'une réponse à ce message Dead Interval doivent coïncider pour les deux routeurs. L'intervalle normalement mort est égal à plusieurs valeurs de minuterie Hello. Ainsi, si la temporisation Bonjour du routeur A est de 10 s et que le routeur B lui envoie un message après 30 s avec un intervalle mort égal à 20 s, le voisinage n'aura pas lieu.
Le deuxième critère est que les deux routeurs doivent utiliser le même type d'authentification. Par conséquent, les mots de passe d'authentification doivent également correspondre.
Le troisième critère est la coïncidence des identificateurs de zone Arial ID, le quatrième est la coïncidence de la longueur du préfixe du réseau. Si le routeur A signale le préfixe / 24, le routeur B doit également avoir un préfixe réseau / 24. Dans la vidéo suivante, nous examinerons cela plus en détail, pour l'instant je remarquerai que ce n'est pas un masque de sous-réseau, ici les routeurs utilisent le masque Wildcard inversé. Et bien sûr, les drapeaux de la zone de stub de la zone Stub doivent également correspondre si les routeurs se trouvent dans cette zone.
Après avoir vérifié ces critères, s'ils correspondent, le routeur B envoie son paquet Hello au routeur A. Contrairement au message A, le routeur B signale qu'il a vu le routeur A et se présente.

En réponse à ce message, le routeur A envoie à nouveau Hello au routeur B, dans lequel il confirme qu'il a également vu le routeur B, le canal de communication entre eux se compose des appareils 1.1.1.1 et 2.2.2.2, et il est lui-même l'appareil 1.1.1.1. Il s'agit d'une étape très importante pour établir un quartier. Dans ce cas, une connexion bidirectionnelle bidirectionnelle est utilisée, mais que se passe-t-il si nous avons un commutateur avec un réseau distribué de 4 routeurs? Dans un tel environnement «partagé», l'un des routeurs devrait jouer le rôle d'un routeur dédié Routeur désigné DR, et le second - un routeur dédié de sauvegarde Routeur désigné de sauvegarde, BDR

Chacun de ces appareils formera une connexion complète, ou un état de pleine contiguïté, plus tard, nous considérerons ce que c'est, cependant, une connexion de ce type ne sera établie qu'avec DR et BDR, les deux routeurs inférieurs D et B communiqueront toujours entre eux selon le schéma de connexion bidirectionnelle Point à point.
Autrement dit, avec DR et BDR, tous les routeurs établissent une relation de proximité complète et une connexion point à point les uns avec les autres. Ceci est très important, car lors de la connexion des périphériques adjacents dans les deux sens, tous les paramètres du paquet Hello doivent correspondre. Dans notre cas, tout coïncide, donc les appareils forment un quartier sans problème.
Dès que la communication bidirectionnelle est établie, le routeur A envoie au routeur B le package de description de la base de données, ou la «description de la base de données», et bascule vers l'état ExStart - le début de l'échange ou l'attente du téléchargement. Le descripteur de base de données est une information similaire à la table des matières du livre - il s'agit d'une énumération de tout ce qui est disponible dans la base de données de routage. En réponse, le routeur B envoie sa description de base de données au routeur A et entre dans l'état d'échange de données sur les canaux Exchange. Si dans l'état Exchange, le routeur détecte qu'il y a des informations dans sa base de données, il passe alors à l'état de démarrage LOADING et commence à échanger des messages LSR, LSU et LSA avec le voisin.

Ainsi, le routeur A envoie un LSR à un voisin, il répondra avec un paquet LSU, auquel le routeur A répondra au routeur B avec un message LSA. Cet échange se produira autant de fois que le nombre de fois que le périphérique souhaite échanger des messages LSA. Un état CHARGEMENT signifie qu'une mise à niveau complète de la base de données LSA n'a pas encore eu lieu. Après avoir téléchargé toutes les données, les deux appareils entreront dans l'état de contiguïté COMPLET.
Je note qu'avec une connexion bidirectionnelle, le périphérique est simplement dans l'état de proximité et l'état de pleine contiguïté n'est possible qu'entre les routeurs, DR et BDR. Cela signifie que chaque routeur informe DR des changements dans le réseau, et tous les routeurs apprennent ces changements à partir de DR
Le choix du DR et du BDR est une question importante. Considérez comment la sélection de DR dans un environnement commun. Supposons que dans notre circuit il y ait trois routeurs et un commutateur. Tout d'abord, les périphériques OSPF comparent la priorité dans les messages Hello, puis comparez l'ID du routeur.
L'appareil avec la priorité la plus élevée devient DR. Si les priorités des deux appareils correspondent, alors des deux appareils, l'appareil avec l'ID de routeur le plus élevé est sélectionné, qui devient DR
Un périphérique avec la deuxième priorité ou le deuxième ID de routeur le plus important devient le routeur BDR dédié de sauvegarde. Si DR échoue, il sera immédiatement remplacé par BDR. Il commencera à jouer le rôle de DR et le système choisira un autre BDR.

J'espère que vous avez compris le choix de DR et BDR, sinon, je reviendrai sur ce problème dans l'une des vidéos suivantes et expliquerai ce processus.
Nous avons donc examiné ce qu'est Hello, une description du descripteur de base de données et des messages LSR, LSU et LSA. Avant de passer au sujet suivant, parlons un peu du coût de l'OSPF.

Chez Cisco, le coût d'un itinéraire est calculé à l'aide de la formule du rapport entre la bande passante et la bande passante de référence, qui par défaut est supposée être de 100 Mbps, par rapport au coût du canal. Par exemple, lors de la connexion de périphériques via un port série, la vitesse est de 1,544 Mb / s et le coût est de 64. Lors de l'utilisation d'une connexion Ethernet avec une vitesse de 10 Mb / s, le coût est de 10 et le coût d'une connexion FastEthernet avec une vitesse de 100 Mb / s sera de 1.
Lorsque vous utilisez Gigabit Ethernet, nous avons une vitesse de 1000 Mbps, mais dans ce cas, la vitesse est toujours supposée être 1. Ainsi, si vous avez Gigabit Ethernet sur votre réseau, vous devez changer la valeur par défaut Réf. BW pour 1000. Dans ce cas, le coût sera de 1 et la table entière sera recalculée avec une augmentation de la valeur de 10 fois. Après avoir formé le quartier et construit la base de données LSDB, nous procédons à la construction de la table de routage.

Après avoir reçu le LSDB, chacun des routeurs procède indépendamment pour former une liste de routes en utilisant l'algorithme SPF. Dans notre schéma, le routeur A créera une telle table pour lui-même. Par exemple, il calcule le coût de l'itinéraire A-R1 et le détermine égal à 10. Pour simplifier la compréhension du schéma, supposons que le routeur A détermine l'itinéraire optimal vers le routeur B. Le coût de la connexion A-R1 est 10, la connexion A-R2 est 100 et le coût de l'itinéraire A-R3 est 11, c'est-à-dire la somme des routes A-R1 (10) et R1-R3 (1).
Si le routeur A veut se rendre au routeur R4, il peut le faire le long de la route A-R1-R4 ou le long de la route A-R2-R4, et dans les deux cas, le coût des routes sera le même: 10 + 100 = 100 + 10 = 110. La route A-R6 coûtera 100 + 1 = 101, ce qui est déjà mieux. Ensuite, nous considérons le chemin vers le routeur R5 le long de la route A-R1-R3-R5, dont le coût sera 10 + 1 + 100 = 111.
Le chemin vers le routeur R7 peut être tracé le long de deux itinéraires: A-R1-R4-R7 ou A-R2-R6-R7. Le coût du premier sera de 210, le second - 201, vous devez donc choisir 201. Ainsi, pour atteindre le routeur B, le routeur A peut utiliser 4 routes.

Le coût de la route A-R1-R3-R5-B sera de 121. La route A-R1-R4-R7-B coûtera 220. La route A-R2-R4-R7-B coûte 210 et A-R2-R6-R7- B a un coût de 211. Sur cette base, le routeur A sélectionne l'itinéraire avec le coût le plus bas égal à 121 et le place dans la table de routage. Il s'agit d'un diagramme très simplifié du fonctionnement de l'algorithme SPF. En fait, le tableau contient non seulement les désignations des routeurs par lesquels la route optimale passe, mais également les désignations des ports les reliant et toutes les autres informations nécessaires.
Prenons un autre sujet qui concerne les zones de routage. Habituellement, lors de la configuration des périphériques OSPF d'une entreprise, ils sont tous dans une zone commune.

Que se passe-t-il si un appareil connecté au routeur R3 tombe soudainement en panne? Le routeur R3 commencera immédiatement à envoyer un message aux routeurs R5 et R1 indiquant que le canal avec cet appareil ne fonctionne plus, et tous les routeurs commenceront à échanger des mises à jour sur cet événement.
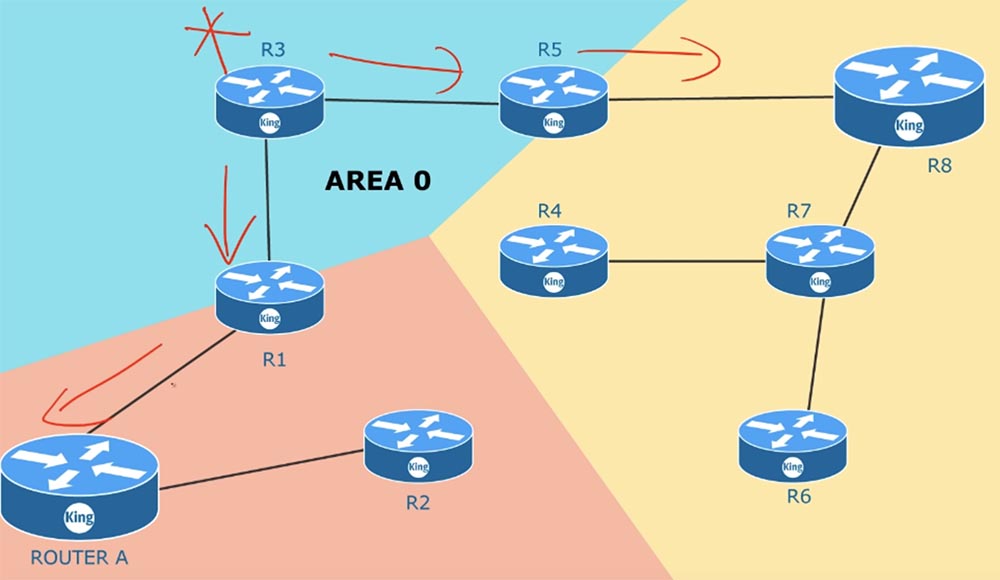
Si vous avez 100 routeurs, tous mettront à jour les informations sur l'état des canaux, car ils se trouvent dans la même zone commune. La même chose se produira si l'un des routeurs voisins tombe en panne - tous les appareils de la zone échangeront des mises à jour LSA. Après avoir échangé de tels messages, la topologie du réseau elle-même changera. Une fois que cela se produit, le SPF recalcule les tables de routage en fonction des conditions modifiées. C'est un processus très long, et si vous avez mille appareils dans une zone, vous devez contrôler la taille de la mémoire des routeurs afin qu'il soit suffisant de stocker tous les LSA et une énorme base de données de l'état des canaux LSDB. Dès que des changements se produisent dans une partie de la zone, l'algorithme SPF recalcule immédiatement les itinéraires. Par défaut, le LSA est mis à jour toutes les 30 minutes. Ce processus ne se produit pas simultanément sur tous les appareils, cependant, dans tous les cas, les mises à jour sont effectuées par chaque routeur avec une fréquence de 30 minutes. Plus d'appareils réseau. Plus il faut de mémoire et de temps pour mettre à jour le LSDB.
Vous pouvez résoudre ce problème en divisant une zone commune en plusieurs zones distinctes, c'est-à-dire en utilisant le multi-zonage. Pour ce faire, vous devez disposer d'un plan ou d'un diagramme de l'ensemble du réseau que vous gérez. ZONE ZONE AREA 0 est votre zone principale. C'est l'endroit où vous vous connectez à un réseau externe, par exemple, l'accès à Internet. Lorsque vous créez de nouvelles zones, vous devez être guidé par la règle: chaque zone doit avoir un ABR, Area Border Router. Le routeur frontière a une interface dans une zone et une seconde interface dans une autre zone. Par exemple, le routeur R5 a des interfaces dans la zone 1 et la zone 0. Comme je l'ai dit, chacune des zones doit être connectée à la zone zéro, c'est-à-dire avoir un routeur périphérique, dont l'une des interfaces est connectée à la ZONE 0.
 Supposons que la connexion R6-R7 soit hors service. Dans ce cas, la mise à jour LSA sera distribuée uniquement dans la zone AREA 1 et ne concernera que cette zone. Les appareils des zones 2 et 0 ne le savent même pas. Le routeur frontière R5 résume les informations sur ce qui se passe dans sa zone et envoie à la zone principale AREA 0 les informations totales sur l'état du réseau. Les périphériques d'une zone n'ont pas besoin d'être au courant de toutes les modifications LSA dans d'autres zones, car le routeur ABR transmet des informations récapitulatives sur les itinéraires d'une zone à une autre.Si vous n'êtes pas complètement clair sur le concept de zones, vous pouvez en savoir plus dans la prochaine leçon lorsque nous allons configurer le routage OSPF et considérer quelques exemples.
Supposons que la connexion R6-R7 soit hors service. Dans ce cas, la mise à jour LSA sera distribuée uniquement dans la zone AREA 1 et ne concernera que cette zone. Les appareils des zones 2 et 0 ne le savent même pas. Le routeur frontière R5 résume les informations sur ce qui se passe dans sa zone et envoie à la zone principale AREA 0 les informations totales sur l'état du réseau. Les périphériques d'une zone n'ont pas besoin d'être au courant de toutes les modifications LSA dans d'autres zones, car le routeur ABR transmet des informations récapitulatives sur les itinéraires d'une zone à une autre.Si vous n'êtes pas complètement clair sur le concept de zones, vous pouvez en savoir plus dans la prochaine leçon lorsque nous allons configurer le routage OSPF et considérer quelques exemples.Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en le recommandant à vos amis, une
réduction de 30% pour les utilisateurs Habr sur un analogue unique de serveurs d'entrée de gamme que nous avons inventés pour vous: Toute la vérité sur VPS (KVM) E5-2650 v4 (6 cœurs) 10 Go DDR4 240 Go SSD 1 Gbps à partir de 20 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
Dell R730xd 2 fois moins cher? Nous avons seulement
2 x Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV à partir de 199 $ aux Pays-Bas! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - à partir de 99 $! Pour en savoir plus sur la
création d'un bâtiment d'infrastructure. classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou?