De nombreux programmeurs ont entendu que parfois le code devrait être alloué à des bibliothèques distinctes pour une réutilisation ultérieure. Cependant, la question de savoir comment le même code doit être distingué en tant qu'entité distincte prête à confusion pour de nombreux développeurs. Lors de la lecture d'articles / conversations sur ce sujet, le problème de la généralisation prématurée est généralement rappelé.
Les programmeurs expérimentés ont généralement leurs propres règles, après quoi ils comprennent si le code doit être distingué comme réutilisable. Par exemple, si un code (ou très similaire) est utilisé à trois endroits ou plus. Néanmoins, tous ceux avec qui j'ai eu l'occasion de m'entretenir sur ce sujet conviennent qu'un tel code réutilisable doit exister, sa création est une bénédiction, et cela vaut la peine de passer son temps.
Je veux aborder le sujet de la réutilisation du code dans le contexte de la création d'une architecture orientée services et microservices.
Qu'est-ce que le code réutilisable?
Le code réutilisable est un code isolé dans une entité distincte, appelé différemment dans différentes langues - bibliothèque, package, dépendance, etc. En règle générale, ce code est stocké dans un référentiel distinct et il existe une documentation pour la connexion et l'utilisation de ce code (README.md). En outre, le code peut être couvert par des tests, il peut y avoir des instructions pour apporter des modifications (CONTRIBUTING.md) et CI peut être configuré. Divers badges attachés à la description n'améliorent que la représentation visuelle de la maturité d'une entité donnée, et le nombre d'étoiles attribuées indiquera la popularité de cette solution. Vous n'avez pas besoin d'aller loin pour des exemples - ouvrez simplement la page github de n'importe quel framework populaire dans votre langue préférée, par exemple
vue.js. En général, les méthodes de conception de haute qualité des bibliothèques sont un wagon et un petit chariot.
Services et microservices
Dans cet article, un service est une entité complète qui effectue un ensemble spécifique de tâches spécifiques dans son domaine de responsabilité et fournit une interface pour l'interaction. Le service ou microservice de cet article d'un point de vue architectural peut être des concepts identiques, la question n'est qu'à l'échelle. Un service peut consister en un ensemble de microservices qui mettent en œuvre leur secteur de logique métier, ou être un microservice fier.
L'architecture orientée services suppose que chaque service est connecté de manière minimale aux autres. Néanmoins, l'interaction interservices n'est pas exclue, mais on suppose seulement qu'elle devrait être minimisée. Pour recevoir des demandes, un service implémente généralement une API standardisée. Cela peut être n'importe quoi - REST, SOAP, JSONRPC ou le nouveau graphQL GraphQL.
Classiquement, les services peuvent être divisés en infrastructure et épicerie. Les services produits sont ceux qui implémentent la logique d'un produit client. Par exemple, ils travaillent avec des applications pour sa connexion ou organisent la prise en charge de ce produit tout au long du cycle de vie d'un client. Les services d'infrastructure concernent davantage les fonctionnalités de base d'une entreprise (ou d'un projet), par exemple, un service contenant des informations client ou un service qui stocke des informations sur certaines commandes. En outre, les services d'infrastructure incluent des services qui implémentent des fonctionnalités auxiliaires, par exemple, un service d'information client (envoi de messages push ou SMS) ou un service d'interaction avec les données.
Un peu de fantaisie
Supposons qu'il existe une boutique en ligne hypothétique construite sur une architecture orientée services. Les développeurs de ce miracle d'ingénierie ont pu s'entendre entre eux et sont arrivés à la conclusion que tous leurs services fonctionneront comme des API, par exemple en utilisant le protocole jsonrpc. Cependant, comme la boutique en ligne est grande, elle ne reste pas immobile et se développe activement, il existe plusieurs groupes de développement, que ce soit plus de deux - deux groupes de conception, l'un accompagné de ce qui a déjà été écrit. De plus, pour améliorer l'effet, toutes les équipes écrivent sur la même pile.
L'architecture d'une boutique en ligne hypothétique: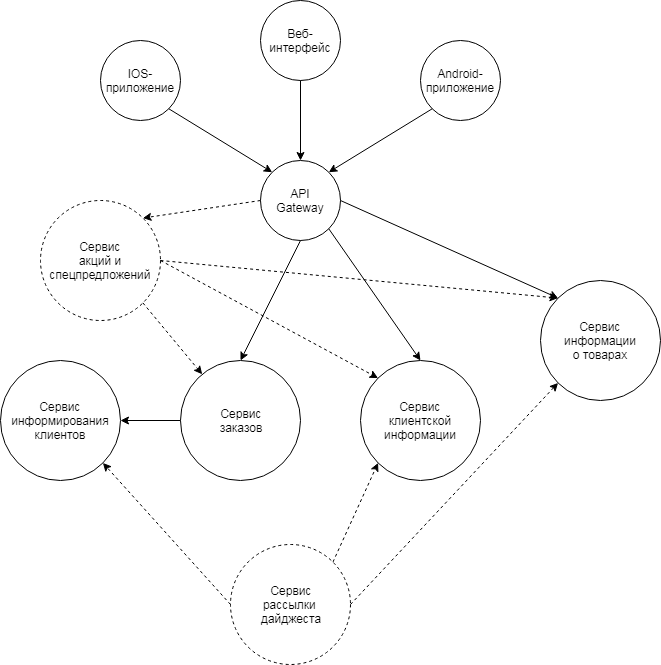
Seul le service API qui se déploie sur Internet donne accès à tous les systèmes frontaux - l'interface Web de la boutique en ligne, ainsi qu'aux applications mobiles.
Le service d'information client stocke les informations sur les clients, sait comment les démarrer, autoriser, délivrer les informations nécessaires à leur sujet.
Le service d'information sur les produits stocke des informations sur les produits, leurs soldes et la disponibilité pour la commande, fournit également des méthodes pour obtenir facilement les informations nécessaires.
Le service de commande fonctionne avec les commandes. Voici la logique de la formation de la commande, sa confirmation, le choix du type de paiement et de l'adresse de livraison, etc.
Le service d'information client peut envoyer des messages PUSH / SMS / email. Le type de communication, par exemple, dépend des paramètres d'un client particulier, et le client peut également définir l'heure souhaitée pour la réception des notifications.
Ces services sont conditionnellement infrastructurels, car sans eux, une boutique en ligne ne peut pas fonctionner en tant que telle.
Les services de promotions et d'offres et la distribution du condensé sont censés être développés dans un futur proche par les équipes projets. Ces services sont conditionnellement épicerie.
De toute évidence, dans tous les cas, aucun nouveau service produit ne pourra exister sans interaction avec les services d'infrastructure - il devra très probablement recevoir des informations sur les clients ou envoyer des notifications.
Dans l'exemple décrit ci-dessus, les détails de la mise en œuvre de chaque service sont intentionnellement masqués. Ainsi, par exemple, un service d'information client a probablement un mécanisme d'exécution de code retardé, comme une file d'attente d'exécution, et un service d'information produit peut avoir son propre panneau d'administration pour une gestion pratique des marchandises, et l'api pour les systèmes frontaux a probablement plusieurs répliques. De plus, l'architecture décrite peut ne pas être optimale, elle est simplement prise de la tête.
Dans le contexte de l'architecture proposée, il devient immédiatement clair que les bibliothèques prêtes à l'emploi sont essentielles pour le développement rapide de produits. Il est donc important d'avoir une implémentation prête à l'emploi du serveur jsonrpc, ainsi que du client pour celui-ci, car il s'agit du protocole principal pour organiser l'interaction interservices. Dans cet exemple également, la question de la documentation de l'API prend tout son potentiel. De toute évidence, pour la formation de la documentation, les équipes doivent également disposer d'un outil prêt à l'emploi. Si nous supposons qu'il existe toujours un outil prêt à l'emploi pour générer des schémas smd pour les serveurs jsonrpc, alors la vitesse de développement de nouveaux services peut encore augmenter. Par conséquent, dans l'entreprise, idéalement, il devrait y avoir un ensemble de bibliothèques prêtes à l'emploi que toutes les équipes utilisent pour effectuer des tâches typiques. Ces bibliothèques peuvent être propriétaires ou open-source, l'essentiel est qu'elles accomplissent bien leurs tâches. De toute évidence, une équipe qui est sur la pile générale et qui écrit des services à l'aide de bibliothèques prêtes à l'emploi sera plus efficace qu'une équipe qui fait constamment du vélo. La présence d'un cadre unique et d'une base de données unique de bibliothèques utilisées dans toutes les équipes de projet, j'appelle un écosystème unique.
Et les grandes entreprises?
Dans les grandes entreprises, il existe beaucoup plus de services d'infrastructure, ainsi que les protocoles d'interaction utilisés. Le nombre de bibliothèques terminées peut atteindre des dizaines voire des centaines. Mettre en évidence le code réutilisable ici est encore plus pertinent.
Il se trouve que j'ai de l'expérience dans une entreprise qui emploie environ 200 développeurs qui écrivent dans différentes langues - java, c #, php, python, go, js, etc. Étonnamment, l'écosystème commun, dans le contexte d'une seule pile, loin de toutes les équipes de développement ont et utilisent. Il semblerait que la chose évidente - préparer du code réutilisable, le formater correctement et l'utiliser - soit loin d'être évidente. Bien sûr, les équipes de développement résolvent leurs problèmes. Quelqu'un utilise un modèle de service - un ensemble de code qui constitue le cœur de chaque nouveau service, à partir duquel tout ce qui est inutile est jeté et le nécessaire est ajouté.
D'autres équipes de développement utilisent leurs propres vélos, les copient et les collent d'un projet à l'autre, et ne se soucient pas de les documenter et de les tester. En général, il y a beaucoup de désunion dans les outils et les approches utilisés au sein de la même pile dans une entreprise. De plus, géographiquement situé dans une ville.
Les avantages d'un écosystème unique
La formation d'un écosystème unique peut résoudre de nombreuses difficultés et présente un énorme potentiel d'augmentation de la productivité pour une grande entreprise. En fait, cette pratique est tirée de la communauté Open Source - les meilleures solutions dans leur domaine survivent et sont les plus populaires. Maintenant, il suffit d'ouvrir un gestionnaire de dépendances et d'être simplement surpris de l'abondance des solutions proposées. Mais une telle approche peut être mise en œuvre au sein de l'entreprise. Les avantages de cette approche lors de la mise en œuvre d'un nouveau service sont les suivants:
- Haute stabilité - l'utilisation de bibliothèques couvertes par des tests et bien documentées augmente la stabilité du service dans son ensemble;
- Rotation facile des collègues entre les équipes - si toutes les équipes se trouvent dans un même écosystème, alors lors du passage d'une équipe à l'autre, le développeur n'aura pas à passer beaucoup de temps à connaître les outils utilisés, car il les connaît déjà;
- Concentration sur la logique métier - en effet, le développement d'un nouveau service se résume à la nécessité de resserrer les dépendances nécessaires pour résoudre toutes les tâches d'infrastructure et écrire uniquement la logique métier;
- Accélération du développement - pas besoin de cycle, tout est prêt, sauf pour la logique métier;
- Simplification des tests - seule la logique métier doit être testée, car les bibliothèques ont déjà été testées;
Voler dans la pommade
Il est clair que pour parvenir à cette approche, certaines pratiques doivent être suivies, à savoir développer des bibliothèques en utilisant le versionnage sémantique, prendre en charge la documentation et les tests et avoir ci configuré. Il s'agit d'une sorte d'indicateur de maturité non seulement de l'équipe de développement, mais aussi des développeurs de l'entreprise dans son ensemble.
PS
Et l'approche orientée package est juste parce que le code réutilisable sur ma pile s'appelle un package. Eh bien, ça a l'air drôle. Récemment, j'ai eu un dialogue avec un de mes collègues qui m'a incité à écrire cet article:
- Collègue: vous devenez caissier sur cinq
- moi: ça veut dire?)
- Collègue: bientôt vous demanderez "avez-vous besoin d'un colis?"
- I: veuillez ouvrir une pensée. je ne comprends pas
- Collègue: eh bien, pour la énième fois, vous avez un paquet prêt à l'emploi pour résoudre mon problème
Le fait est que dans notre communauté de développeurs au sein de l'entreprise, il y a environ 20 ensembles de packages prêts à l'emploi, et la création d'un nouveau service se traduit par la mise en place des dépendances nécessaires, ainsi que l'écriture de la logique métier. Le coût de la liaison en termes d'écriture de code est presque annulé.