Pourquoi voulons-nous même écrire du code concurrentiel? Parce que les processeurs ont cessé de croître le long des creux et ont commencé à croître le long des noyaux. Le nombre de cœurs de processeur augmente chaque année et nous voulons les utiliser efficacement. Go est la langue créée pour cela. La documentation le dit.
Nous prenons Go, commençons à écrire du code compétitif. Bien sûr, nous nous attendons à pouvoir facilement limiter la puissance de chaque cœur de notre processeur. En est-il ainsi?
Je m'appelle Artemy. Ce message est une transcription gratuite de mon entretien avec GopherCon Russie. Il est apparu comme une tentative de donner un élan aux personnes qui veulent comprendre comment écrire un bon code compétitif.
Vidéo de la conférence GopherCon Russie
Modèles d'interaction
Pour comprendre si Go nous facilite vraiment la tâche, examinons deux modèles d'interaction: mémoire partagée et transmission de messages .

La mémoire partagée concerne la mémoire partagée que plusieurs threads utilisent pour échanger des données. L'accès à la mémoire doit être synchronisé. Cette synchronisation est généralement implémentée par une sorte de verrous. Cette approche est considérée comme une communication implicite.
La transmission de messages indique que nous interagirons explicitement, et pour cela, nous utiliserons les canaux dans lesquels nous enverrons des messages. Le CSP ( Communicating Sequential Processes ) et le modèle d'acteur sont basés sur cette approche.

Rob Pike , qui est le père fondateur de Go, dit que vous devez abandonner la programmation de bas niveau en utilisant la mémoire partagée et utiliser l'approche de transmission de messages . Cette approche vous aidera à écrire du code plus facilement, plus efficacement et, surtout, avec moins de bogues. Go choisit l'approche CSP . La même approche a grandement influencé le développement d'une langue comme Erlang.
Question: Est-il vrai que si nous prenons Go, tout ira bien?

Je suis tombé sur une étude dans laquelle cette tablette a été trouvée. La tablette indique les raisons et le nombre de bugs liés aux verrous. La première colonne montre les produits qui ont été inclus dans l'étude. Ce sont les produits les plus populaires écrits en Go. La colonne Mémoire partagée indique le nombre de bogues qui surviennent en raison d'une mauvaise utilisation de la mémoire partagée et la colonne Message Passing, respectivement, indique le nombre de bogues dus à Message Passing.
La chose la plus importante sur cette plaque est la ligne Total . Si vous le regardez, vous remarquerez qu'il y a plus de bogues lors de l'utilisation de la transmission de messages que lors de l'utilisation de la mémoire partagée . Je suis sûr que les personnes qui écrivent Kubernetes, Docker ou etcd sont des développeurs assez expérimentés, mais même le passage de messages ne les sauve pas des erreurs, et ces erreurs ne sont pas moins qu'avec la mémoire partagée.
Donc, prendre Go et commencer à écrire du code sans erreur échouera.
Concurrence et parallélisme
Lorsque nous commençons à parler de développement multi-thread, nous devons introduire des concepts tels que la concurrence et le parallélisme . Dans le monde de Go, il y a l'expression «la concurrence n'est pas le parallélisme» . L'essentiel est que la concurrence concerne la conception, c'est-à-dire la façon dont nous concevons notre programme. Le parallélisme n'est qu'un moyen d'exécuter notre code.

Si nous avons plusieurs fils d'instructions qui sont exécutés simultanément, alors nous exécutons le code en parallèle. Le parallélisme requiert de la concurrence. Il ne sera pas possible de paralléliser un programme sans une conception compétitive, tandis que la compétitivité ne nécessite pas le parallélisme, car un programme qui peut fonctionner sur de nombreux cœurs, en fait, peut fonctionner sur un seul cœur.
Go est un langage qui nous aide à écrire des programmes compétitifs, nous aide à construire le design. Cela vous permet de penser un peu moins aux choses de bas niveau.
La loi d'Amdahl
Nous voulons utiliser les cœurs de processeur, nous écrivons du code pour cela. Mais la question se pose: quel type d'augmentation de la productivité nous obtenons avec une augmentation du nombre de cœurs. Ainsi, l'accélération que nous pouvons obtenir, elle est, en fait, limitée par la loi d'Amdal .
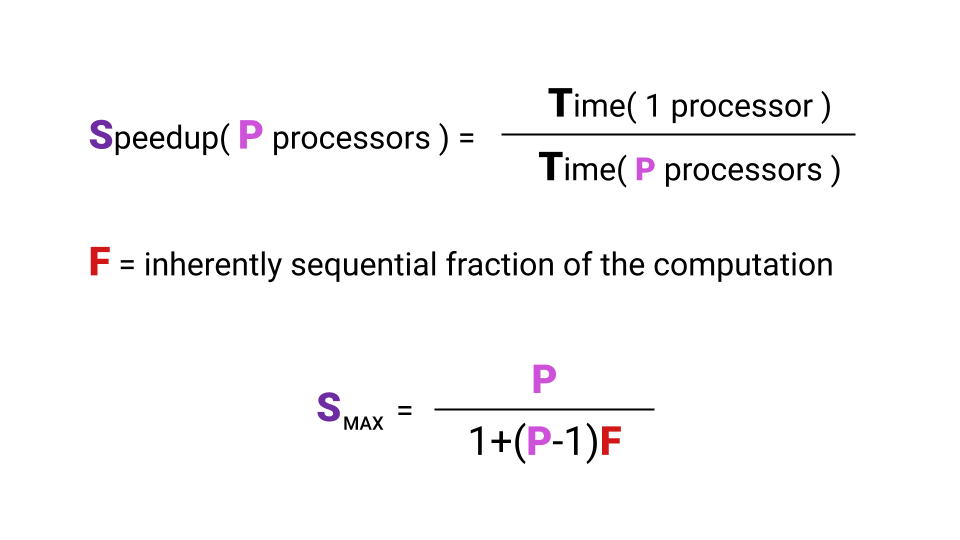
Qu'est-ce que l'accélération? L'accélération est la durée d'exécution d'un programme sur un seul processeur divisée par la durée d'exécution d'un programme sur P processeurs. La lettre F ( fraction ) désigne la partie du programme qui doit être exécutée séquentiellement. Et ici, il n'est même pas nécessaire de se plonger dans la formule, l'essentiel est de noter que l'accélération maximale que l'on obtient avec une augmentation du nombre de noyaux dépend fortement de F. Jetez un œil au graphique pour visualiser cette relation.
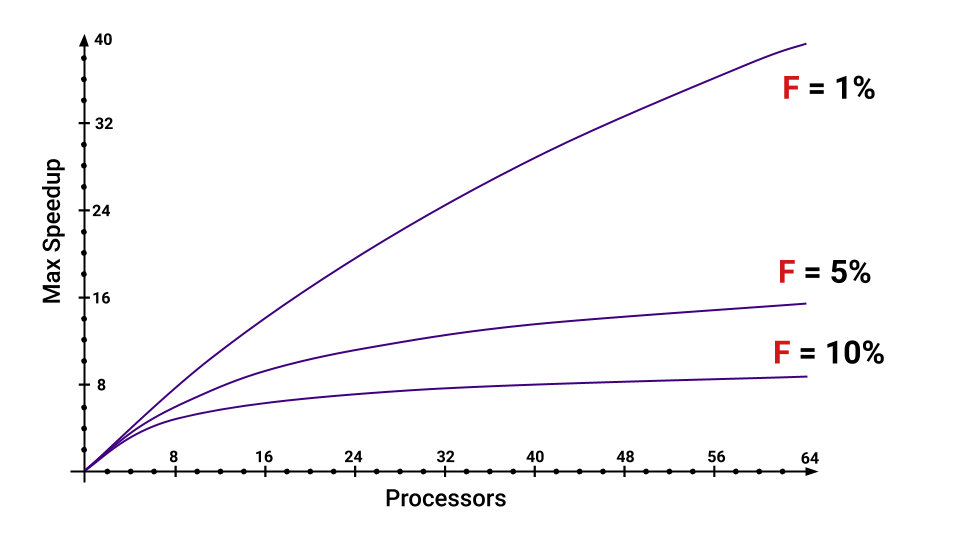
Même si nous n'avons que 5% du programme à exécuter séquentiellement, l'accélération maximale que nous obtenons diminuera considérablement avec une augmentation du nombre de cœurs. Vous pouvez estimer quelles sont les parties qui augmentent F.
CPU Bound vs I / O Bound
Il n'est pas toujours judicieux d'utiliser le multithreading. Vous devez d'abord regarder le type de charge. Il existe deux types de charge: CPU Bound et I / O Bound . La différence est qu'avec CPU Bound, nous sommes limités par les performances du processeur, et avec I / O Bound, nous sommes limités par la vitesse de notre sous-système d'E / S. Pas même la vitesse, mais le temps d'attente pour une réponse. Aller en ligne - attendre une réponse, aller sur le disque - encore une fois attendre une réponse. Quelle est la différence, combien de cœurs y a-t-il, si la plupart du temps on attend une réponse?
Par conséquent, un cœur ou mille, nous n'obtiendrons pas d'augmentation des performances sous la charge liée aux E / S. Mais si nous avons une charge CPU Bound, alors il y a une chance d'obtenir une accélération lors de la parallélisation de notre programme.
Bien qu'il existe des situations où la charge apparente du CPU Bound, elle dégénère en fait en un I / O Bound. Si, par exemple, nous voulons prendre et additionner tous les éléments d'un grand tableau, que ferons-nous? Nous écrirons un cycle, tout fonctionnera. Puis nous pensons: «Nous avons donc un tas de cœurs. Prenons-le, divisons le tableau en morceaux et parallélisons le tout. » Quel sera le résultat?
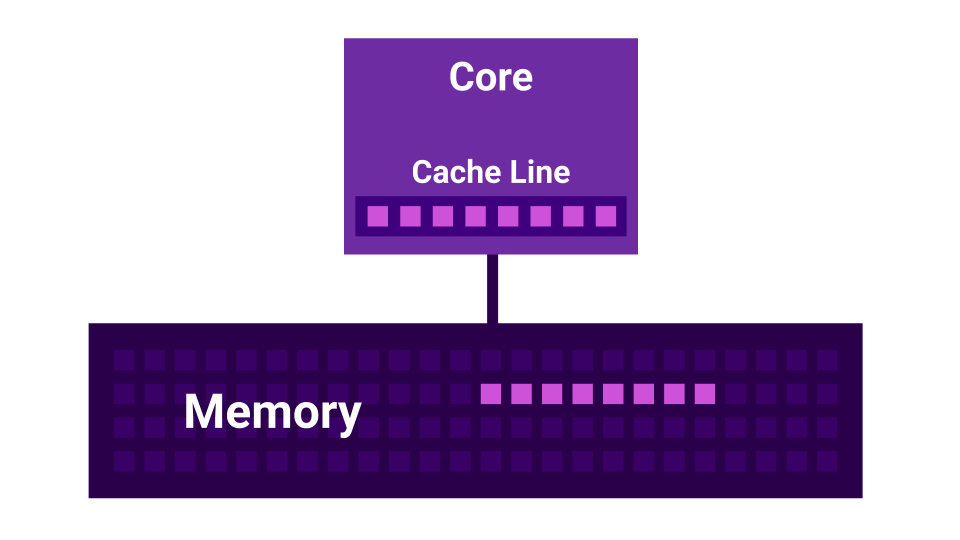
Le résultat est une situation où notre processeur traite les données plus rapidement qu'il ne parvient à provenir de la mémoire. Dans ce cas, la plupart du temps, nous attendrons les données de la mémoire, et la charge, qui semblait être liée au processeur, se révèle en fait être liée aux E / S.
Faux partage
De plus, il y a une histoire comme False Sharing . Le faux partage est une situation où les noyaux commencent à interférer les uns avec les autres. Il y a un premier noyau, il y a un deuxième noyau, et chacun d'eux a son propre cache L1 . Le cache L1 est divisé en lignes ( ligne de cache ) de 64 octets. Lorsque nous obtenons des données de la mémoire, nous obtenons toujours pas moins de 64 octets. En modifiant ces données, nous désactivons les caches de tous les cœurs.

Il s'avère que si deux cœurs modifient des données très proches l'une de l'autre ( à une distance inférieure à 64 octets ), ils commencent à interférer l'un avec l'autre, invalidant les caches. Dans ce cas, si le programme était écrit séquentiellement, il fonctionnerait plus rapidement que lors de l'utilisation de plusieurs cœurs qui interfèrent les uns avec les autres. Plus il y a de cœurs, plus les performances sont faibles.
Planificateurs
Nous passerons au prochain niveau d'abstraction - aux planificateurs.
Lorsque le travail commence avec un code concurrentiel, des planificateurs apparaissent. Go a un soi-disant planificateur d'espace utilisateur qui fonctionne sur des goroutines . Le système d'exploitation a également son propre ordonnanceur , qui fonctionne avec les threads du système d'exploitation . Et même le processeur n'est pas si simple. Par exemple, les processeurs modernes ont une prédiction de branche et d'autres façons de gâcher notre belle image de la linéarisation du monde.
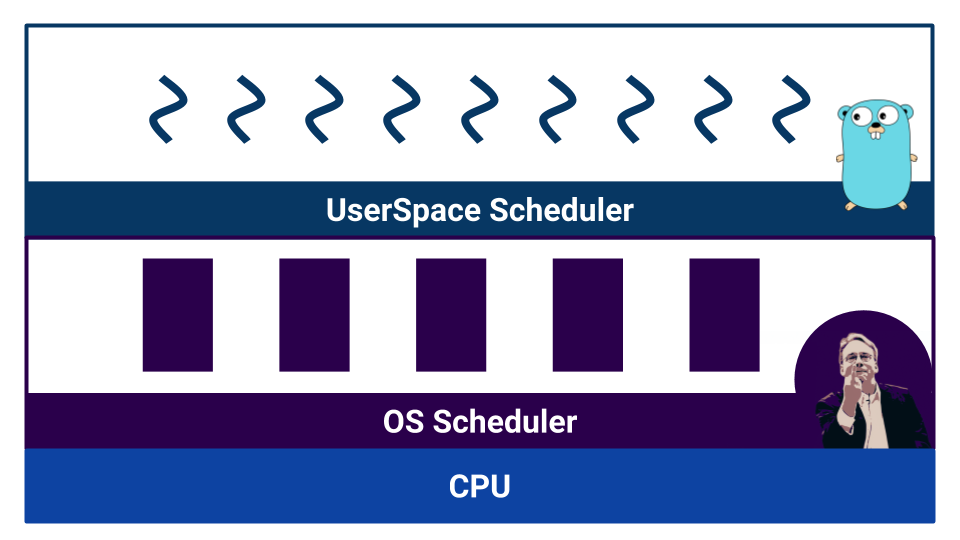
Les planificateurs sont divisés par type de multitâche. Il existe un multitâche coopératif et un multitâche préemptif . Dans le cas du multitâche coopératif , le processus d' exécution lui-même décide quand il doit transférer le contrôle à un autre processus, et dans le cas du multitâche surchargé, il existe un composant externe - planificateur, qui contrôle la quantité de ressources allouées au processus.

Le multitâche coopératif permet à un processus de «monopoliser» la totalité de la ressource CPU. Dans le multitâche préemptif, cela ne se produira pas, car il existe un organisme de contrôle. Mais avec le multitâche coopératif, le changement de contexte est plus efficace, car le processus sait avec certitude à quel moment il vaut mieux donner le contrôle à un autre processus. Dans le multitâche préemptif, le planificateur peut arrêter le processus à tout moment - ce n'est pas très efficace. En même temps, en multitâche préemptif, nous pouvons fournir la même ressource pour chaque processus grâce à un planificateur externe.
Le système d'exploitation utilise un planificateur basé sur le multitâche préemptif, car le système d'exploitation est nécessaire pour garantir des conditions égales pour chaque utilisateur. Et Go?
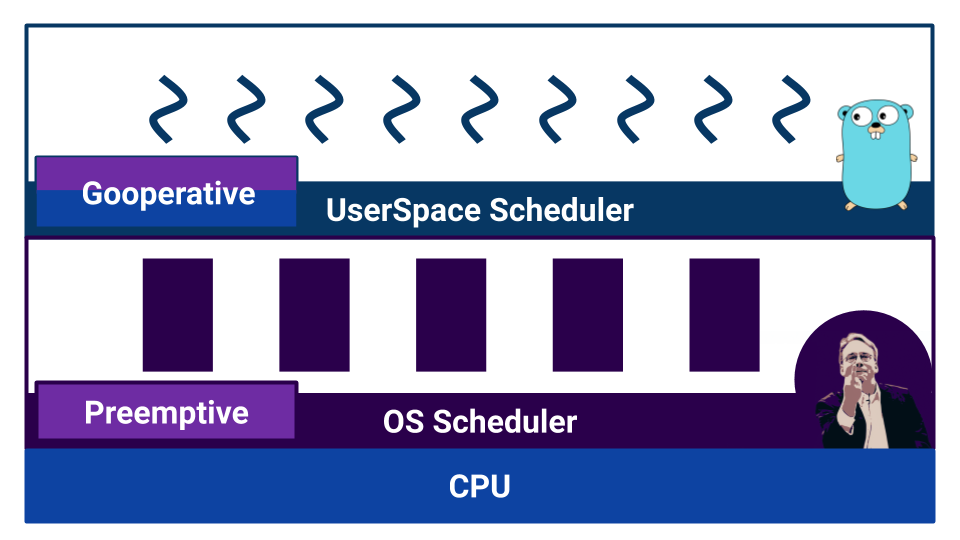
Si nous lisons la documentation, nous apprenons que le planificateur de Go est préemptif. Mais, lorsque nous commençons à comprendre, il s'avère que Go n'a pas de planificateur comme composant externe. Dans Go, le compilateur définit les points de changement de contexte. Et bien que nous, en tant que développeurs, n'ayons pas besoin de changer manuellement le contexte, le contrôle de commutation n'est pas retiré au composant externe. Grâce à cela, Go est très efficace pour passer d'un goroutine à un autre. Mais une mauvaise compréhension des caractéristiques du travail d'un tel «planificateur» peut conduire à un comportement inattendu. Par exemple, que produira ce code?

Un tel code se fige.
Pourquoi? Parce qu'au début, en utilisant GOMAXPROCS , nous avons forcé le programme à utiliser un seul cœur. Après cela, le goroutine a été mis dans la file d'attente, à l'intérieur duquel un cycle sans fin devrait fonctionner. Ensuite, nous attendons 500 ms et imprimons x . Après time.Sleep goroutine démarrera réellement, mais il n'y aura aucun moyen de sortir de la boucle infinie, car le compilateur ne mettra pas le point de changement de contexte. Le programme se bloque.
Et si nous ajoutons runtime.Gosched() à l'intérieur de la boucle, tout ira bien, car nous indiquerons explicitement que nous voulons changer de contexte.
Ces fonctionnalités doivent également être connues et mémorisées.
Nous avons parlé de changement de contexte, mais où Go insère-t-il généralement des points de commutation?

runtime.morestack() et runtime.newstack() sont généralement insérés au moment où la fonction est appelée. runtime.Goshed() nous pouvons nous fournir. Et bien sûr, le changement de contexte se produit pendant les verrous, les hausses de réseau et les appels système. Vous pouvez regarder à ce sujet un rapport de Kirill Lashkevich . Très bien, je conseille.
Allons plus loin dans le code. Nous allons examiner les erreurs.
Condition de course
L'une des erreurs les plus populaires que nous commettons est la Race Condition . L'essentiel, c'est que lorsque nous faisons, par exemple, un incrément, en fait, nous ne faisons pas une opération, mais plusieurs: le processeur lit les données de la mémoire pour les enregistrer, met à jour le registre et écrit les données dans la mémoire.

Ces trois opérations ne sont pas effectuées de manière atomique. Par conséquent, le planificateur à tout moment, sur n'importe laquelle de ces opérations, peut prendre et évincer notre flux. Il s'avère que l'action n'est pas terminée, et à cause de cela, nous attrapons des bugs.
Voici un exemple d'un tel code (l' incrément est immédiatement décomposé en plusieurs opérations ).

Le planificateur peut préempter le premier thread après l'exécution de la première ligne et le deuxième thread après avoir vérifié la condition. Dans ce cas, les deux flux tomberont dans la section critique, et donc ils sont «critiques» - les deux flux ne peuvent pas y être entrés simultanément.
Nous pouvons verrouiller en utilisant sync.Mutex partir du package de sync standard. Le blocage d'accès nous permet d'indiquer explicitement que le code doit être exécuté par un thread à la fois. Avec ce code, nous obtenons ce dont nous avons besoin.

Les verrous sont une opération assez coûteuse. Par conséquent, il existe des opérations atomiques au niveau du processeur. Dans ce cas, l'incrément peut être rendu atomique en le remplaçant par l'opération atomic.AddInt64 du package atomic .
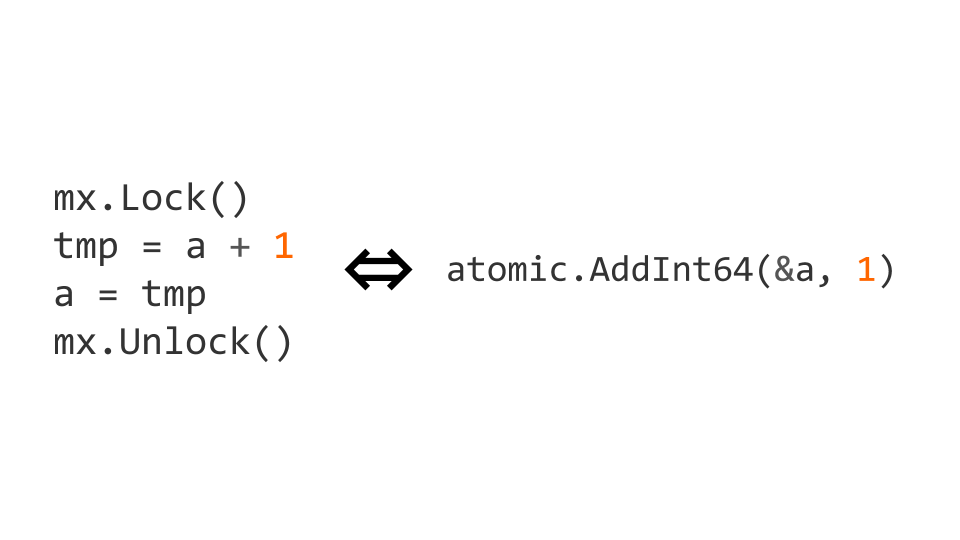
Si nous commençons à travailler avec des instructions atomiques, nous devons non seulement écrire atomiquement, mais aussi lire atomiquement. Si nous ne le faisons pas, des problèmes peuvent survenir.
Optimisation - Qu'est-ce qui pourrait mal tourner?
Les verrous sont bons, mais peuvent être chers. Les atomiques sont assez bon marché pour ne pas se soucier des performances.
Nous avons donc appris que les primitives de synchronisation introduisaient une surcharge et avons décidé d'ajouter une optimisation - nous vérifierons l'indicateur sans tenir compte du multithreading, puis revérifierons en utilisant des primitives de synchronisation. Tout semble bien et devrait fonctionner.

Tout va bien, sauf que le compilateur essaie d'optimiser notre code. Que fait-il? Il échange les instructions d'affectation, et nous obtenons un comportement non valide, car notre done devient true avant que la valeur de la variable «
N'essayez pas de faire de telles optimisations - à cause d'eux, vous aurez beaucoup de problèmes. Je vous conseille de lire la spécification du modèle de mémoire Go et un article de Dmitry Vyukova ( @dvyukov ) Courses de données bénignes: qu'est-ce qui pourrait mal tourner ? pour mieux comprendre les enjeux.
Si vous comptez vraiment sur les performances des verrous, écrivez du code sans verrouillage, mais vous n'avez pas besoin de faire un accès non synchronisé à la mémoire.
Impasse
Le prochain problème auquel nous serons confrontés est Deadlock. Il peut sembler que tout est assez trivial ici. Il existe deux ressources, par exemple, deux Mutex . Dans le premier thread, nous capturons d'abord le premier Mutex , et dans le deuxième thread, nous capturons d'abord le deuxième Mutex . De plus, nous voudrons prendre le deuxième Mutex dans le premier thread, mais nous ne pourrons pas le faire, car il est déjà bloqué. Dans le deuxième thread, nous allons essayer de prendre, respectivement, le premier Mutex et aussi le bloc. Il est là, Deadlock.
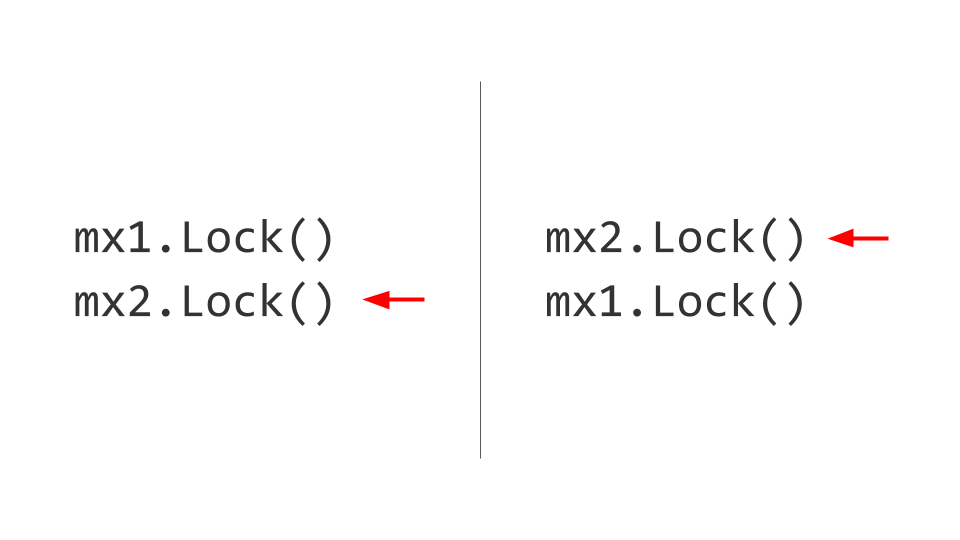
Aucun de ces deux threads ne pourra progresser davantage, car les deux attendront la ressource. Comment est-ce résolu? Nous échangeons les verrous, puis aucun problème ne se pose. Bien sûr, c'est facile à dire, mais le maintien de cette règle tout au long de la vie du produit n'est pas facile. Si possible, faites-le - prenez et remettez les serrures dans le même ordre .
Il peut sembler que les développeurs expérimentés ne rencontrent pas de telles erreurs, mais voici un exemple de blocage du code de projet etcd.

Ici, le principal problème est que l'écriture sur un canal sans tampon est bloquante; pour écrire, vous avez besoin d'un lecteur d'autre part. Prenant le mutex, le premier fil attend que le lecteur apparaisse. Le deuxième thread ne peut plus capturer le mutex. Impasse
Je vous conseille d'essayer le jeu passionnant The Deadlock Empire . Dans ce jeu, vous agissez comme un planificateur qui doit changer de contexte afin d'empêcher le code de s'exécuter correctement.
Sorte de problèmes
Quels problèmes existent encore? Nous avons commencé avec les conditions de course . Ensuite, nous avons examiné Deadlock (il existe encore une variante de Livelock , c'est à ce moment que nous ne pouvons pas capturer la ressource, mais il n'y a pas de verrous explicites). Il y a la famine , c'est quand nous allons à l'imprimante pour imprimer un morceau de papier, et il y a une file d'attente, et nous ne pouvons pas accéder à la ressource. Nous avons examiné le comportement du programme avec False Sharing . Il y a toujours un problème - Lock Contention , lorsque les performances se dégradent en raison de la forte concurrence pour une ressource (par exemple, un mutex dont un grand nombre de threads ont besoin).

Détection de course
Go est puissant avec la boîte à outils fournie. Race Detector est un de ces outils. Son utilisation est simple: nous écrivons des tests ou l'exécutons sur une charge de combat et prenons des erreurs.
Vous pouvez en savoir plus sur l'utilisation du Race Detector dans la documentation , mais n'oubliez pas qu'il a des limites. Arrêtons-nous plus en détail sur eux.

Premièrement, le code non exécuté n'est pas vérifié par le Race Detector. Par conséquent, la couverture du test doit être élevée. De plus, le Race Detector se souvient de l'historique des appels à chaque mot en mémoire, mais cet historique des appels a de la profondeur. Dans Go, par exemple, cette profondeur est de quatre à quatre éléments, quatre accès. Si le détecteur de course n'a pas pris de course dans cette profondeur, il pense qu'il n'y a pas de course. Par conséquent, bien que le détecteur de course ne se soit jamais trompé, il ne détectera pas toutes les erreurs. Vous pouvez espérer pour le détecteur de course, mais vous devez vous rappeler ses limites. Séparément, vous pouvez lire sur l' algorithme de travail .
Profil de bloc
Le profil de blocage est un autre outil qui nous permet de trouver et de résoudre les problèmes de blocage.

Il peut être utilisé à la fois au niveau du test de référence et peut être observé pendant la charge de combat. Par conséquent, si vous recherchez des problèmes associés à la synchronisation de l'accès aux données, essayez de démarrer avec le détecteur de course et continuez à utiliser le profil de blocage.
Exemple de programme
Regardons le vrai code sur lequel nous pouvons tomber. Nous allons écrire une fonction qui prend simplement un tableau de requêtes et essaie de les exécuter: chaque requête en séquence. Si l'une des demandes renvoie une erreur, la fonction met fin à l'exécution.

Si nous écrivons en Go, nous devons utiliser toute la puissance de la langue. Nous essayons. Nous obtenons trois fois plus de code.

Question: y a-t-il des erreurs dans le code?
Bien sûr! Regardons lesquels.
Dans la boucle, nous courons des goroutines. Pour l'orchestration de goroutine, nous utilisons sync.WaitGroup . Mais qu'est-ce qu'on fait mal? Déjà à l'intérieur du goroutine en cours d'exécution, nous appelons wg.Add(1) , c'est-à-dire que nous ajoutons un goroutine de plus à attendre. Et en utilisant wg.Wait() , nous attendons que tous les goroutines se terminent. Mais il peut arriver qu'au moment où wg.Wait() est appelé, pas un seul goroutine ne démarre. Dans ce cas, wg.Wait() considérera que tout est fait, nous fermerons le canal et quitterons la fonction sans erreur, croyant que tout va bien.

Que se passera-t-il ensuite? Ensuite, les goroutines démarreront, le code s'exécutera et peut-être qu'une des requêtes retournera une erreur. Une erreur est écrite sur un canal fermé et l'écriture sur un canal fermé est une panique. Notre application va planter. Il est peu probable que ce soit ce que je voulais obtenir, nous le corrigeons donc en indiquant à l'avance combien de goroutines nous lancerons.

Peut-être qu'il y a encore des problèmes?
Il y a une erreur liée à la façon dont l'objet req apparaît à l'intérieur de la fonction. La variable req agit comme un itérateur du cycle, et nous ne savons pas quelle valeur elle aura au moment du lancement de la goroutine.

En pratique, dans ce code, la valeur req sera très probablement égale au dernier élément du tableau. Par conséquent, vous envoyez simplement la même demande N fois. Correction: passez explicitement notre requête en argument à la fonction.

Examinons de plus près comment nous traitons les erreurs. Nous déclarons un canal tamponné sur un emplacement. Lorsqu'une erreur se produit, nous l'envoyons sur ce canal. Tout semble aller bien: une erreur s'est produite - nous avons renvoyé cette erreur à partir d'une fonction.

Mais que faire si toutes les demandes reviennent avec une erreur?
Ensuite, l'écriture sur le canal n'obtiendra que la première erreur, le reste bloquera l'exécution des goroutines. Puisqu'il n'y aura plus de lectures du canal au moment de quitter la fonction de lecture, nous obtenons une fuite de goroutine. Autrement dit, tous ces gorutins qui n'ont pas pu écrire l'erreur sur le canal se bloquent simplement en mémoire.
Nous le fixons très simplement: nous sélectionnons dans le canal de slot le nombre de requêtes. Cela résout notre problème peu efficace en mémoire, car si nous avons un milliard de requêtes, nous devons allouer un milliard de slots.

Nous avons résolu les problèmes. Le code est désormais compétitif. Mais le problème vient de la lisibilité - par rapport à la version synchrone du code, il y en a beaucoup. Et ce n'est pas cool, car le développement de programmes compétitifs est déjà difficile, pourquoi le complique-t-on avec beaucoup de code?

Errgroup
Je suggère d'augmenter la lisibilité du code.
J'aime utiliser le package errgroup au lieu de sync.WaitGroup . Ce package ne nécessite pas de spécifier le nombre de goroutines à attendre et vous permet d'ignorer la collection d'erreurs. Voici à quoi ressemblera notre fonction lorsque vous utiliserez errgroup :

De plus, errgroup permet d'orchestrer facilement les composants de notre programme en utilisant context.Context . Qu'est-ce que je veux dire?
Supposons que nous ayons plusieurs composants de notre programme, si au moins l'un d'entre eux échoue, nous voulons terminer soigneusement tous les autres. Ainsi, errgroup lorsqu'une erreur errgroup , termine le context et, par conséquent, tous les composants reçoivent une notification sur la nécessité de terminer le travail.

Cela peut être utilisé pour créer des programmes multicomposants complexes qui se comportent de manière prévisible.
Conclusions
Rendez-le aussi simple que possible. Mieux synchroniquement. Le développement de programmes multithread est généralement un processus complexe, conduisant à l'apparition de bugs désagréables.

N'utilisez pas de synchronisation implicite. Si vous vous y êtes vraiment reposé, pensez à comment vous débarrasser des verrous, comment créer un algorithme sans verrouillage.
Go est un bon langage pour écrire des programmes qui fonctionnent efficacement avec un grand nombre de cœurs, mais ce n'est pas mieux que toutes les autres langues, et des erreurs apparaîtront toujours. Par conséquent, même armé de Go, essayez de comprendre plusieurs niveaux d'abstractions inférieurs à ce que vous travaillez.
