Nous présentons à votre attention la deuxième partie de la traduction du matériel sur la lutte de l'équipe gitlab.com contre la tyrannie du temps.

→ Voici d'ailleurs la
première partie .
Limite de vitesse de traitement des demandes
À ce stade, nous n'étions pas intéressés à simplement augmenter les valeurs du paramètre
MaxStartups . Bien qu'une augmentation de 50% de ce paramètre se soit avérée bonne, sa nouvelle augmentation sans raison suffisante semblait être une solution plutôt grossière au problème. Il y avait sûrement autre chose que nous pouvions faire.
Les recherches m'ont amené au niveau HAProxy, qui était situé devant les serveurs SSH. HAProxy a une belle option de
rate-limit sessions qui affecte la partie du système qui accepte les demandes entrantes. Si cette option est configurée, elle est utilisée pour limiter le nombre de nouvelles requêtes TCP par seconde que le frontend envoie aux backends, tout en laissant des connexions entrantes supplémentaires au socket TCP. Si la vitesse des demandes entrantes dépasse la limite (modifiable toutes les millisecondes), les nouvelles connexions sont simplement retardées. Le client TCP (dans ce cas, SSH) voit simplement le délai avant d'établir une connexion TCP. À mon avis, c'est une très belle décision. Jusqu'à ce que la vitesse à laquelle les demandes sont reçues, pendant trop longtemps, dépasse trop la limite, le système fonctionnera bien.
La question suivante était la sélection de la valeur de l'option de
rate-limit sessions , que nous devrions utiliser. Trouver une réponse à cette question a été compliqué par le fait que nous avons 27 backends SSH et 18 frontaux HAProxy (16 principaux et 2 alt-ssh), ainsi que par le fait que les frontaux ne se coordonnent pas entre eux en ce qui concerne la vitesse de traitement des demandes. . De plus, nous avons dû prendre en compte la durée de l'étape d'authentification de la nouvelle session SSH. Supposons que la première valeur de
MaxStartups soit 150. Cela signifie que si la phase d'authentification prend deux secondes, nous ne pouvons transférer à chacun des backends que 75 nouvelles sessions par seconde.
Ici vous pouvez trouver des détails sur le calcul de la valeur des
rate-limit sessions , je ne vais pas entrer dans les détails ici. Je note seulement que pour calculer cette valeur, quatre paramètres doivent être pris en compte. Le premier et le second sont le nombre de serveurs des deux types. Le troisième est la valeur de
MaxStartups . Le quatrième est
T - combien de temps faut-il pour authentifier une session SSH. La valeur de
T extrêmement importante, mais elle ne peut être déduite qu'approximativement. C'est ce que nous avons fait, laissant le résultat à 2 secondes. En conséquence, nous avons obtenu la valeur
rate-limit pour les frontaux, qui s'élevait à 112,5. Nous l'avons arrondi à 110.
Et maintenant, les nouveaux paramètres sont entrés en vigueur. Peut-être pensez-vous qu'après cela, tout s'est bien terminé? Ce devait être que le nombre d'erreurs s'est précipité à zéro et que tout le monde était immensément heureux? Eh bien, en fait, c'était loin d'être aussi bon. Cette modification n'a entraîné aucune modification visible du taux d'erreur. Franchement, j'étais assez contrarié. Nous avons raté quelque chose d'important ou avons mal compris l'essence du problème.
En conséquence, nous sommes retournés aux journaux (et, enfin, aux informations HAProxy) et avons pu nous assurer que la limite de vitesse de traitement des requêtes fonctionne au moins en agissant sur les requêtes comme prévu. Auparavant, les indicateurs correspondants étaient plus élevés, ce qui nous a permis de conclure que nous avons réussi à limiter la vitesse à laquelle les demandes entrantes sont envoyées pour traitement. Mais il était clair que le rythme auquel les demandes arrivaient était encore trop élevé. Bien qu'il soit également clair qu'il ne s'est même pas approché de ces niveaux alors qu'il pouvait avoir un effet notable sur le système. Lorsque nous avons analysé le processus de sélection des backends (selon les journaux HAProxy), nous avons remarqué une étrangeté. Au début de l'heure, les connexions backend étaient réparties de manière inégale sur les serveurs SSH. Dans l'intervalle de temps choisi pour l'analyse, le nombre de connexions par seconde sur différents serveurs variait de 30 à 121. Et cela signifiait que notre équilibrage de charge ne faisait pas bien son travail. L'analyse de la configuration a montré que nous avons utilisé l'option de
balance source , de sorte qu'un client avec une adresse IP spécifique est toujours connecté au même backend. Cela peut être considéré comme un phénomène positif dans les cas où une liaison de session est nécessaire. Mais nous avons affaire à SSH, nous n'en avons donc pas besoin. Cette option a été configurée une fois par nous, mais nous n'avons trouvé aucune indication sur la raison pour laquelle cela a été fait. Nous n'avons pas pu trouver de raison valable de continuer à l'utiliser. En conséquence, nous avons décidé de passer à
leastconn . Grâce à cette option, les nouvelles connexions entrantes donnent des backends avec le nombre minimum de connexions actuelles. Cela a affecté l'utilisation des ressources processeur par nos serveurs SSH (Git). Voici l'horaire correspondant.
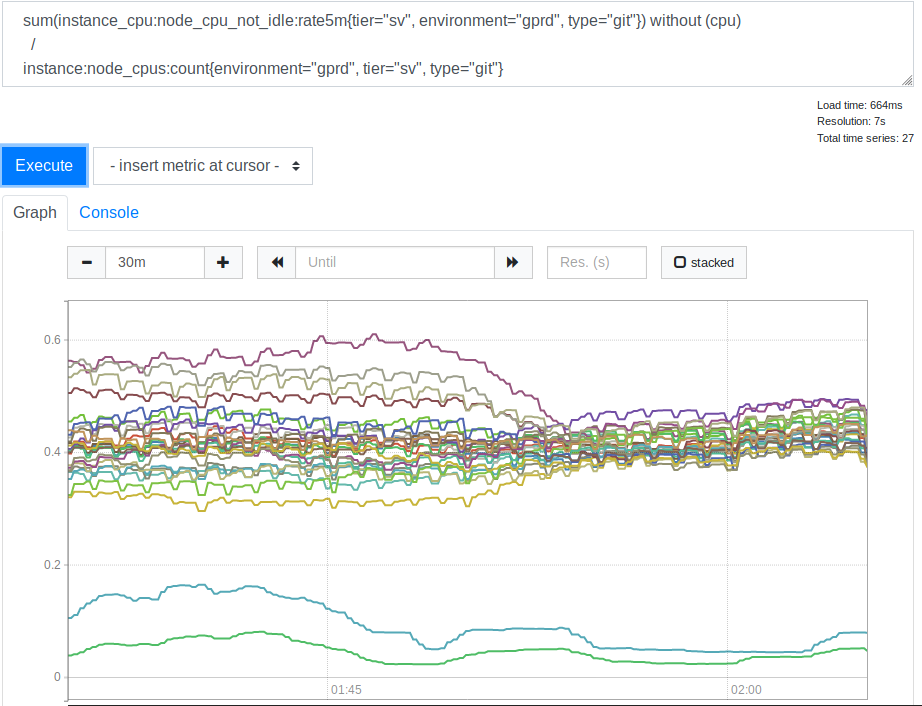 Consommation du processeur par les serveurs avant et après l'application de l'option lessconn
Consommation du processeur par les serveurs avant et après l'application de l'option lessconnAprès avoir vu cela, nous avons réalisé que l'utilisation de
leastconn est une bonne idée. Les deux lignes qui sont en bas du graphique sont nos serveurs Canaries, vous pouvez les ignorer. Mais auparavant, la répartition des valeurs de charge CPU pour les différents serveurs était corrélée à 2: 1 (de 30% à 60%). Cela indiquait clairement qu'auparavant certains de nos backends étaient chargés plus que d'autres en raison de la connexion des clients avec eux. Cela m'a surpris. Il semblait raisonnable de s'attendre à ce qu'un large éventail d'adresses IP de clients soit suffisant pour charger nos serveurs de manière beaucoup plus uniforme. Mais, apparemment, afin de fausser les indicateurs de charge du serveur, plusieurs gros clients suffisaient, dont le comportement diffère d'une option moyenne.
Leçon numéro 4. Lorsque vous sélectionnez des paramètres spécifiques qui diffèrent des paramètres par défaut, commentez-les ou laissez un lien vers les documents expliquant les modifications. Quiconque devra faire face à ces paramètres à l'avenir vous en sera reconnaissant.
Cette transparence est l'
une des valeurs fondamentales de GitLab .
L'activation de l'option
leastconn également contribué à réduire les niveaux d'erreur. Et c'est exactement ce que nous recherchions. Par conséquent, nous avons décidé de laisser cette option. Mais, en continuant d'expérimenter, ils ont réduit le niveau des limites de vitesse de traitement des demandes à 100, ce qui a contribué à réduire davantage le niveau d'erreurs. Cela indique que la sélection initiale de la valeur de
T a probablement été mal effectuée. Mais si c'est le cas, alors cet indicateur était trop petit, ce qui a conduit à une limite de vitesse trop forte, et même 100 requêtes par seconde ont été perçues comme une valeur très faible, et nous n'étions pas prêts à le réduire davantage. Malheureusement, pour une raison interne, ces deux changements n'étaient qu'une expérience. Nous avons dû revenir à l'utilisation de l'option de
balance source et limiter la vitesse de traitement des demandes à 100 demandes par seconde.
Étant donné que la vitesse de traitement des requêtes a été définie à un niveau bas qui nous convient et que nous ne pouvions pas utiliser le moins de
leastconn , nous avons essayé d'augmenter le paramètre
MaxStartups . Au début, nous l'avons augmenté à 200, cela a donné un certain effet. Puis - jusqu'à 250. Les erreurs ont presque complètement disparu et rien de mal ne s'est produit.
Leçon numéro 5. Bien que les MaxStartups élevés puissent sembler intimidants, ils ont très peu d'impact sur les performances même lorsqu'ils sont bien supérieurs aux valeurs par défaut.
C'est peut-être quelque chose comme un grand et puissant levier, que nous pouvons, si nécessaire, utiliser à l'avenir. Nous rencontrerons peut-être des problèmes si nous parlons de chiffres de l'ordre de plusieurs milliers ou plusieurs dizaines de milliers, mais nous en sommes encore loin.
Qu'est-ce que cela dit sur mes estimations du paramètre
T , le temps qu'il faut pour installer et authentifier une session SSH? Si vous travaillez avec la formule de calcul de l'indicateur de limite de vitesse de traitement de connexion, sachant que 200 n'est pas tout à fait suffisant pour l'indicateur
MaxStartups et 250 est suffisant, vous pouvez découvrir que
T probablement une valeur de 2,7 à 3,4 secondes. En conséquence, une valeur estimée de 2 secondes n'était pas loin de la vérité, mais la valeur réelle, bien sûr, était plus élevée que prévu. Nous y reviendrons un peu plus tard.
Étapes finales
Nous avons de nouveau regardé les journaux, en tenant compte de ce que nous savions déjà, et, après réflexion, nous avons découvert que le problème avec lequel tout avait commencé pouvait être identifié par les signes suivants. Tout d'abord, il s'agit d'une valeur
t_state égale à
SD . Deuxièmement, il s'agit de la valeur de
b_read (octets lus par le client), égale à 0. Comme déjà mentionné, nous traitons environ 26 à 28 millions de connexions SSH par jour. Il était désagréable d'apprendre qu'au milieu de la catastrophe, environ 1,5% de ces connexions étaient gravement rompues. De toute évidence, l'ampleur du problème était beaucoup plus grande que nous ne le pensions au tout début. De plus, il n'y avait rien que nous ne pouvions pas détecter plus tôt (même lorsque nous avons réalisé que
t_state="SD" indiquait le problème dans les journaux), mais nous n'avons pas réfléchi à la façon de procéder, bien que nous et vous devriez y penser. Probablement à cause de cela, nous avons consacré beaucoup plus de temps et d'efforts à résoudre le problème que nous n'aurions pu le faire.
Leçon numéro 6. Mesurez les niveaux d'erreur réels le plus tôt possible.
Si nous étions au départ conscients de l’ampleur du problème, nous pourrions y accorder plus d’attention. Bien que, comment le percevoir, dépend toujours de la connaissance des caractéristiques qui nous permettent de décrire les problèmes.
Si nous parlons des avantages qui sont apparus après avoir augmenté les valeurs de
MaxStartups et réglé la vitesse de traitement des demandes, nous pouvons dire que le niveau d'erreur est tombé à 0,001%. C'est - jusqu'à plusieurs milliers par jour. Cette situation paraissait bien meilleure, mais un niveau d'erreurs similaire était encore plus élevé que celui que nous souhaiterions atteindre. Après avoir découvert certaines choses, nous avons de nouveau pu utiliser l'option
leastconn et les erreurs ont complètement disparu. Après cela, nous avons pu pousser un soupir de soulagement.
Travaux futurs
De toute évidence, la phase d'authentification SSH prend encore beaucoup de temps. Peut-être jusqu'à 3,4 secondes. GitLab peut utiliser
AuthorizedKeysCommand pour rechercher directement une clé SSH dans une base de données. Ceci est très important pour des opérations rapides lorsqu'il y a un grand nombre d'utilisateurs. Sinon, SSHD doit lire séquentiellement un très gros fichier
authorized_keys pour trouver la clé publique de l'utilisateur. Cette tâche n'est pas très évolutive. Nous avons implémenté une recherche en utilisant une certaine quantité de code Ruby qui effectue des appels vers une API HTTP externe.
Stan Hugh , le chef de notre département d'ingénierie et une source inépuisable de connaissances sur GitLab, a découvert que les instances Unicorn des serveurs Git / SSH sont sous la charge constante des demandes qui leur sont adressées. Cela pourrait apporter une contribution significative aux trois secondes nécessaires pour authentifier les demandes. En conséquence, nous avons réalisé qu'à l'avenir, nous devrions enquêter sur cette question. Peut-être que nous augmenterons le nombre d'instances Unicorn (ou Puma) sur ces nœuds afin que les serveurs SSH n'aient pas à attendre pour y accéder. Cependant, il y a un certain risque ici, nous devons donc être prudents et prêter attention à la collecte et à l'analyse des indicateurs du système. Le travail sur la productivité se poursuit, mais maintenant, une fois le principal problème résolu, les choses vont plus lentement. Nous pouvons peut-être réduire la valeur de
MaxStartups , mais comme son niveau élevé ne crée pas l'impact négatif sur le système qu'il semble créer, ce n'est pas particulièrement nécessaire. Il sera beaucoup plus facile pour tout le monde de vivre si OpenSSH peut à tout moment nous dire à quel point nous sommes proches des limites de
MaxStartups . Ce sera mieux si nous pouvons toujours être au courant. C'est bien plus agréable que d'apprendre que les limites sont dépassées face à des connexions rompues.
De plus, nous avons besoin d'une sorte de système de notification lorsque des entrées de journal HAProxy apparaissent, indiquant un problème avec les connexions déconnectées. Le fait est que cela ne devrait pas du tout se produire dans la pratique. Si cela se produit à nouveau, nous devrons augmenter davantage les valeurs de
MaxStartups , ou si nous manquons de ressources, nous devrons ajouter plus de nœuds Git / SSH au système.
Résumé
Des parties de systèmes complexes interagissent selon des schémas complexes. Et en eux, pour résoudre divers problèmes, on peut souvent trouver loin d'un "levier". Lorsqu'il s'agit de tels systèmes, il est utile de connaître les outils qui y sont présents. Le fait est qu'ils ont tous leurs avantages et leurs inconvénients. En outre, il convient de noter qu'il peut être risqué d'effectuer certains réglages sur la base d'hypothèses et de valeurs estimées. Maintenant, en regardant le chemin que nous avons parcouru, j'essaierais de mesurer aussi précisément que possible le temps nécessaire pour terminer l'authentification de la demande, ce qui conduirait à la valeur approximative de
T que j'ai déduite serait plus proche de la vérité.
Mais la principale leçon que nous avons apprise de tout cela est que lorsque beaucoup de gens planifient des tâches sur la base de très bons indicateurs de temps, cela, avec des fournisseurs de services centralisés comme GitLab, conduit à des problèmes de mise à l'échelle vraiment inhabituels.
Si vous faites partie de ceux qui utilisent les outils de lancement de tâches planifiées, vous devrez peut-être envisager de définir l'heure de lancement de vos tâches d'une nouvelle manière. Par exemple, vous pouvez rendre les tâches «endormies» pendant un certain temps, en commençant à fonctionner réellement seulement 30 secondes après le lancement. Vous pouvez, par exemple, indiquer des heures aléatoires dans l'heure dans le calendrier de lancement de la tâche (ici, vous pouvez ajouter un temps d'attente aléatoire avant l'exécution réelle de la tâche). Cela nous aidera tous dans la lutte contre la tyrannie des montres.
Chers lecteurs! Avez-vous rencontré des problèmes similaires à celui dont l'histoire est consacrée à ce matériel?
