Le matériel, dont nous publions aujourd'hui la première partie de la traduction, est consacré à un problème à grande échelle qui s'est posé sur gitlab.com. Ici, nous parlerons de la façon dont ils l'ont trouvée, comment ils se sont battus avec elle et comment, finalement, ils l'ont résolue. De plus, face à ce problème, l'équipe de gitlab.com a découvert ce qu'est la tyrannie des montres.

→
La deuxième partie .
Le problème
Nous avons commencé à recevoir des messages de clients qui, lorsqu'ils travaillent avec gitlab.com, rencontrent régulièrement des erreurs lors de l'exécution des demandes de tirage. Des erreurs se sont généralement produites lors de l'exécution des tâches CI ou lors du fonctionnement d'autres systèmes automatisés similaires. Les messages d'erreur ressemblaient à ceci:
ssh_exchange_identification: connection closed by remote host fatal: Could not read from remote repository
La situation est encore compliquée par le fait que les messages d'erreur apparaissent de manière irrégulière et, semble-t-il, imprévisibles. Nous ne pouvions pas les reproduire à volonté, nous n'avons pu identifier aucun signe évident de ce qui se passait sur les cartes ou dans les journaux. Les messages d'erreur eux-mêmes n'ont pas non plus apporté beaucoup d'avantages. Le client SSH a été informé que la connexion a été interrompue, mais la raison pourrait être n'importe quoi: un client défaillant ou une machine virtuelle instable, un pare-feu que nous ne contrôlons pas, des actions de fournisseur étranges ou un problème avec notre application.
Nous, travaillant sur le schéma GIT-over-SSH, traitons un très grand nombre de connexions - environ 26 millions par jour. C'est une moyenne de 300 connexions par seconde. Par conséquent, une tentative de sélection d'un petit nombre de connexions ayant échoué dans le flux de données existant promettait d'être une tâche difficile. La bonne chose à propos de cette situation est que nous aimons résoudre des problèmes complexes.
Premier indice
Nous avons contacté l'un de nos clients (merci à Hubert Holtz d'Atalanda), qui a rencontré un problème plusieurs fois par jour. Cela nous a permis de prendre pied. Hubert a pu nous fournir une adresse IP publique appropriée. Cela signifiait que nous pouvions capturer des paquets sur nos nœuds frontaux HAProxy afin d'essayer d'isoler le problème en s'appuyant sur un ensemble de données plus petit que ce que l'on pourrait appeler «tout le trafic SSH». Encore mieux, la société a utilisé un
port alternatif-ssh . Cela signifiait que nous devions analyser la situation sur seulement deux serveurs HAProxy, et non sur seize.
Cependant, l'analyse des packages n'était pas particulièrement amusante. Malgré des restrictions dans environ 6,5 heures, environ 500 Mo de paquets ont été collectés. Nous avons trouvé des composés de courte durée. La connexion TCP a été établie, le client a envoyé l'identifiant, après quoi notre serveur HAProxy s'est immédiatement déconnecté en utilisant la séquence TCP FIN correcte. En conséquence, nous avions à notre disposition le premier excellent indice. Elle nous a permis de conclure que la connexion était définitivement fermée à l'initiative de gitlab.com, et non à cause de quelque chose entre nous et le client. Cela signifiait que nous étions confrontés à un problème que nous pouvons étudier et corriger.
Leçon numéro 1. Le menu Statistiques de l'outil Wireshark contient une tonne d'outils utiles auxquels, avant ce cas, je n'ai pas prêté beaucoup d'attention.
En particulier, nous parlons de l'élément de menu
Conversations , qui peut montrer des informations de base sur les données capturées sur les connexions TCP. Il y a des informations sur l'heure, les paquets, les octets. Les données affichées dans la fenêtre correspondante peuvent être triées. Je devrais utiliser cet outil dès le début au lieu de jouer manuellement avec les données capturées. Ensuite, j'ai réalisé que je devais rechercher des connexions avec un petit nombre de paquets. La fenêtre
Conversations vous a permis de faire immédiatement attention à eux. Après cela, j'ai pu trouver d'autres composés similaires et m'assurer que la première connexion de ce type n'était pas un phénomène anormal.
Immersion dans le journal
Qu'est-ce qui a poussé HAProxy à se déconnecter du client? Le serveur, bien sûr, ne l'a pas fait de manière arbitraire, ce qui se passait aurait dû avoir une raison plus profonde; si vous aimez - "un autre niveau de
tortues ." Il y avait un sentiment que le prochain objet d'étude devrait être les journaux HAProxy. Nos journaux ont été stockés dans GCP BigQuery. C'est pratique, car nous avons beaucoup de journaux et nous devions les analyser de manière approfondie. Mais d'abord, nous avons pu identifier l'entrée de journal pour l'un des incidents, qui a été trouvé dans les paquets capturés. Nous nous sommes appuyés sur le temps et sur le port TCP, ce qui était une réalisation majeure dans notre étude. Le détail le plus intéressant de l'enregistrement trouvé était l'
t_state (Termination State), qui avait la valeur
SD . Voici un extrait de la documentation HAProxy:
S: , . D: DATA.
La signification de la signification de
D est expliquée très simplement. La connexion TCP a été établie correctement, des données ont été envoyées. Cela coïncidait avec les preuves obtenues à partir des paquets capturés. Une valeur de
S signifie que le HAProxy a reçu un message d'échec RST ou ICMP du backend. Mais nous n'avons pas pu trouver immédiatement un indice pour expliquer pourquoi cela se produisait. La raison pourrait être autre chose - d'un réseau instable (par exemple, une panne ou une congestion) à un problème au niveau de l'application. En utilisant BigQuery pour agréger des données sur les backends Git, nous avons découvert que le problème n'est lié à aucune machine virtuelle particulière. Nous avions besoin de plus d'informations.
Je tiens à noter que les entrées de journal avec la valeur
SD n'étaient pas quelque chose de spécial, caractéristique uniquement pour notre problème. Sur le port alternatif-ssh, nous avons reçu de nombreuses demandes concernant la recherche de HTTPS. Cela a conduit au fait que la valeur
SD est tombée dans les journaux lorsque le serveur SSH a vu le message
TLS ClientHello alors qu'il s'attendait à recevoir un message d'accueil SSH. Cela a brièvement mené notre enquête de manière détournée.
Après avoir capturé du trafic entre HAProxy et le serveur Git et à nouveau à l'aide des outils Wireshark, nous avons rapidement découvert que le SSHD sur le serveur Git se déconnecte de TCP FIN-ACK immédiatement après la prise de contact à trois voies de TCP. HAProxy n'a toujours pas envoyé le premier paquet de données, mais était sur le point de le faire. Lorsqu'il a envoyé le paquet, le serveur Git lui a répondu avec TCP RST. En conséquence - nous avons maintenant découvert la raison pour laquelle HAProxy a écrit aux journaux sur l'échec de la connexion avec la valeur
SD . SSH a fermé la connexion, en le faisant intentionnellement et correctement, et RST n'était qu'un artefact du fait que le serveur SSH a reçu le paquet après FIN-ACK. Cela ne voulait rien dire de plus.
Calendrier éloquent
En regardant et en analysant les journaux avec des valeurs
SD dans BigQuery, nous avons réalisé que les erreurs ont une relation prononcée avec le temps. À savoir, nous avons trouvé des pics dans le nombre de connexions ayant échoué dans les 10 premières secondes de chaque minute. Ils ont été observés pendant 5-6 secondes.
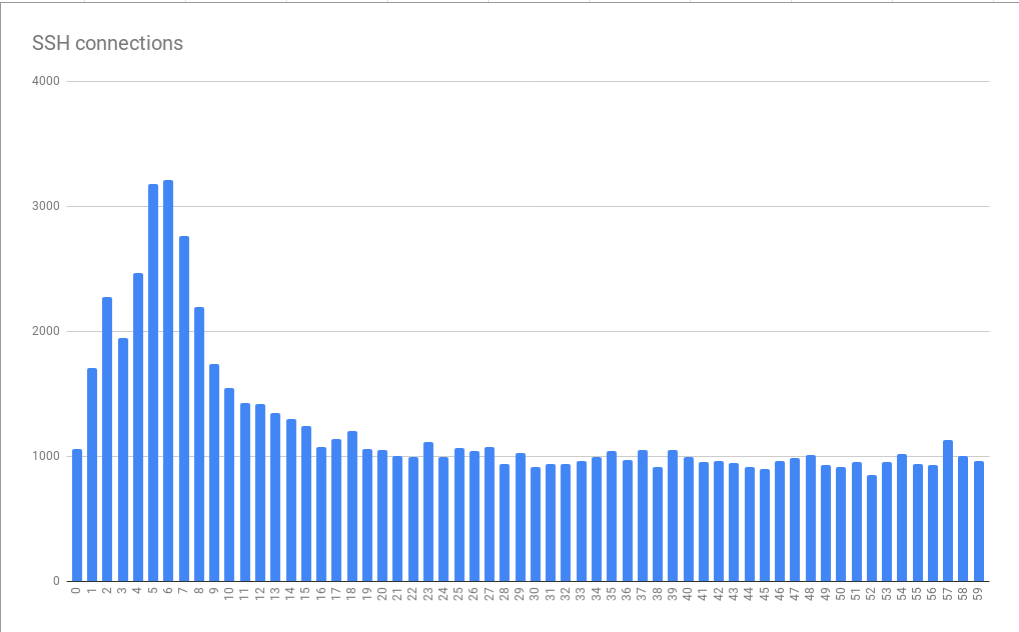 Erreurs de connexion regroupées en quelques minutes ou secondes
Erreurs de connexion regroupées en quelques minutes ou secondesCe graphique est basé sur des données collectées sur plusieurs heures. Le fait que le modèle de distribution d'erreurs détecté se soit avéré stable indique que la cause des erreurs se manifeste de manière stable en quelques minutes et heures individuelles, et, pire encore, elle se manifeste de manière stable à différents moments de la journée. Il est très intéressant de noter que la taille moyenne du pic est environ 3 fois plus grande que la charge de base. Cela signifiait que nous étions confrontés à un problème non négligeable de mise à l'échelle. Par conséquent, le simple fait de connecter «plus de ressources» sous la forme de machines virtuelles supplémentaires, conçues pour nous aider à faire face aux pics de charge, pourrait théoriquement coûter trop cher. Cela indique également que nous atteignons une sorte de restriction sévère. En conséquence, nous avons reçu le premier indice sur le problème systémique fondamental qui provoque des erreurs. Je l'ai appelé la tyrannie des heures.
Les systèmes de planification Cron ou similaires ne diffèrent souvent pas dans la possibilité de personnaliser l'exécution des tâches à la seconde près. Si de tels systèmes ont de telles capacités, ils ne sont pas utilisés très souvent car les gens préfèrent considérer le temps, divisé en intervalles, exprimé par de beaux nombres ronds. Par conséquent, les tâches commencent au début d'une minute ou d'une heure ou à d'autres moments similaires. Si les tâches avaient besoin de quelques secondes pour préparer la commande
git fetch pour télécharger des documents à partir de gitlab.com, cela pourrait expliquer le modèle que nous avons trouvé lorsque la charge sur le système augmente fortement pendant plusieurs secondes chaque minute. À de tels moments, le nombre d'erreurs augmente.
Leçon numéro 2. Beaucoup de gens, apparemment, utilisent une synchronisation horaire correctement configurée (via NTP ou en utilisant d'autres mécanismes).
Si personne ne synchronisait l'heure, notre problème ne se serait pas manifesté aussi clairement. Bonjour, NTP!
Mais qu'est-ce qui fait que SSH se déconnecte?
Plus près du cœur du problème
En étudiant la documentation SSHD, nous avons découvert le paramètre
MaxStartups . Il contrôle le nombre maximal de connexions non authentifiées. Il semble plausible que la limite de connexion soit épuisée quand au début de la minute le système est soumis à la charge créée par une rafale d'appels de tâches planifiées de partout sur Internet. Le paramètre
MaxStartups compose de trois nombres. Le premier est la borne inférieure (le nombre de connexions à l'atteinte duquel les ruptures de connexions commencent). Le second est le pourcentage de composés qui dépassent la limite inférieure des composés qui doivent être cassés au hasard. La troisième valeur est le nombre maximum absolu de connexions, après quoi toutes les nouvelles connexions sont rejetées. La valeur par défaut de MaxStartups ressemble à 10: 30: 100, nos paramètres ressemblaient alors à 100: 30: 200. Cela indique que dans le passé, nous avons augmenté les limites de connexion standard. Peut-être - il est temps de les augmenter à nouveau.
Il s'est avéré un peu désagréable qu'OpenSSH 7.2 étant installé sur nos serveurs, la seule façon de voir les limites définies dans
MaxStartups était
MaxStartups était de passer au niveau de
Debug débogage. Avec cette approche, une avalanche de données tombe dans les journaux. Par conséquent, nous avons brièvement activé ce mode sur l'un des serveurs. Heureusement, en quelques minutes, il est devenu clair que le nombre de connexions dépassait les limites définies dans
MaxStartups , ce qui a entraîné une déconnexion précoce.
Il s'est avéré que dans OpenSSH 7.6 (cette version est fournie avec Ubuntu 18.04), une approche plus pratique pour enregistrer ce qui est lié à
MaxStartups . Ici, il vous suffit de passer en mode de journalisation
Verbose . Bien que ce ne soit pas idéal, c'est toujours mieux que de passer au niveau
Debug .
Leçon numéro 3. Il est considéré comme une bonne forme d'écrire des informations intéressantes dans les journaux aux niveaux de journalisation standard, et les informations sur une déconnexion intentionnelle pour une raison quelconque sont certainement intéressantes pour les administrateurs système.
Maintenant que nous avons découvert la cause du problème, la question s'est posée de savoir comment le résoudre. Nous pourrions augmenter les valeurs du paramètre
MaxStartups , mais combien cela nous coûterait-il? Certes, cela nécessiterait un peu de mémoire supplémentaire, mais cela entraînerait-il des conséquences néfastes dans les parties du système où les demandes sont traitées? Nous ne pouvions que penser à cela, alors nous avons décidé de prendre et d'essayer simplement les nouveaux paramètres
MaxStartups . A savoir, nous les avons échangés contre les suivants: 150: 30: 300. Auparavant, ils ressemblaient à 100: 30: 200, c'est-à-dire - nous avons augmenté le nombre de connexions de 50%. Cela a eu un fort effet positif sur le système. Dans le même temps, certains effets négatifs, tels que l'augmentation de la charge sur les processeurs, n'ont pas été observés.
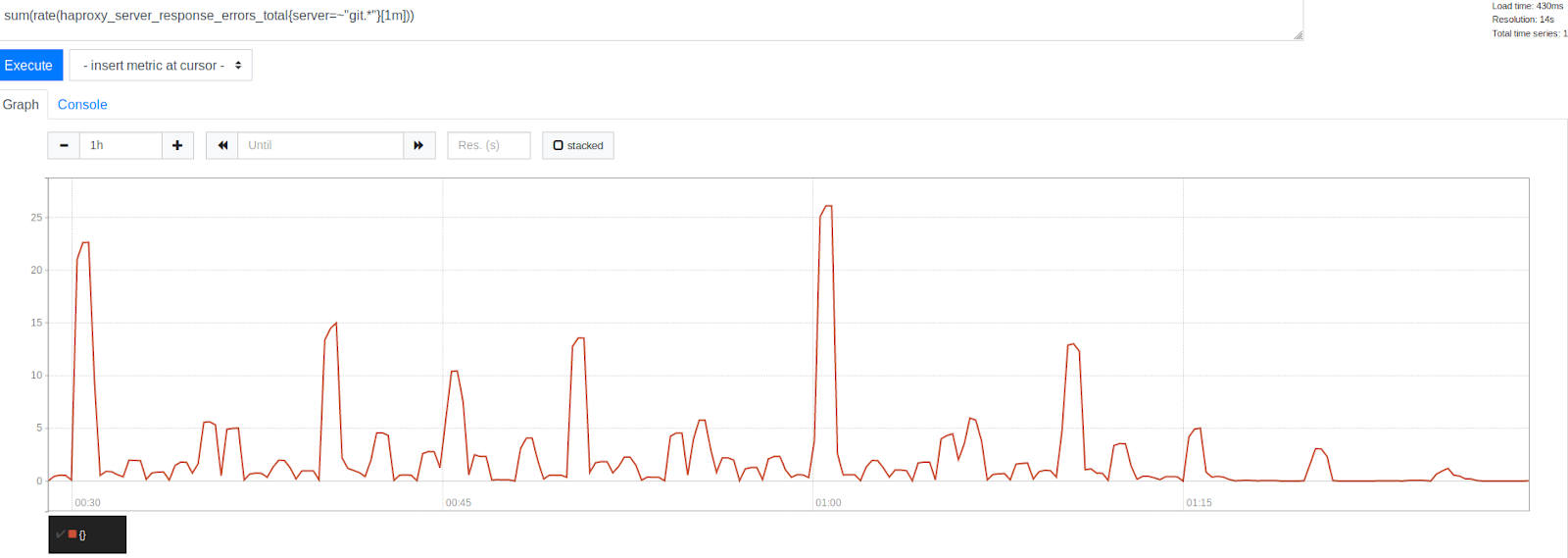 Le nombre d'erreurs avant et après l'augmentation de MaxStartups de 50%
Le nombre d'erreurs avant et après l'augmentation de MaxStartups de 50%Notez la réduction significative des erreurs après l'horodatage 1:15. Cela indique clairement que nous avons pu nous débarrasser d'une partie importante des erreurs, même si certaines d'entre elles étaient toujours présentes. Il est intéressant de noter que les erreurs sont regroupées autour d'horodatages représentés par de beaux nombres ronds. C'est le début de l'heure, toutes les 30, 15 et 10 minutes. Sans aucun doute, la tyrannie de la montre a continué. Au début de chaque heure, le pic d'erreurs le plus élevé est observé. Compte tenu de ce que nous avons déjà compris, cela semble tout à fait compréhensible. De nombreuses personnes prévoient simplement d'exécuter des tâches toutes les heures qui s'exécutent 0 minute après le début de l'heure. Ce fait a confirmé notre théorie selon laquelle les pics d'erreur sont causés par le lancement de tâches planifiées. Cela indiquait que nous étions sur la bonne voie pour résoudre le problème en ajustant les limites du système.
À notre grand plaisir, la modification de la limite
MaxStartups pas entraîné d'effets négatifs notables. L'utilisation du processeur sur les serveurs SSH est restée à peu près au même niveau qu'auparavant, la charge sur nos systèmes n'a pas augmenté non plus. C'était très agréable, étant donné que nous avons maintenant accepté plus de connexions, de celles qui auraient simplement été rompues auparavant. De plus, la situation n'a pas été aggravée par le fait que nous l'avons fait à une époque où nos systèmes étaient très chargés. Tout semblait prometteur.
À suivre ...
Chers lecteurs! Quels outils utilisez-vous pour analyser le trafic et les journaux?
