Poursuite de la traduction d'un petit livre:
"Comprendre les courtiers de messages",
auteur: Jakub Korab, éditeur: O'Reilly Media, Inc., date de publication: juin 2017, ISBN: 9781492049296.
Traduction terminée: tele.gg/middle_javaPartie précédente:
Comprendre les courtiers de messages. Apprentissage de la mécanique de la messagerie via ActiveMQ et Kafka. Chapitre 2. ActiveMQCHAPITRE 3
Kafka
Kafka a été développé sur LinkedIn pour contourner certaines des limitations des courtiers de messages traditionnels et pour éviter d'avoir à configurer plusieurs courtiers de messages pour différentes interactions point à point, ce qui est décrit dans la section «Mise à l'échelle verticale et horizontale» à la page 28 de ce livre. LinkedIn s'est fortement appuyé sur l'absorption unidirectionnelle de très grandes quantités de données, telles que les clics sur les pages et les journaux d'accès, tout en permettant à plusieurs systèmes d'utiliser ces données. h, sans affecter les performances des autres producteurs ou konsyumerov. En fait, la raison pour laquelle Kafka existe est d'obtenir l'architecture de messagerie décrite par Universal Data Pipeline.
Compte tenu de cet objectif ultime, d'autres exigences ont naturellement surgi. Kafka doit:
- Soyez extrêmement rapide
- Fournir un débit de messagerie supérieur
- Prise en charge des modèles Publisher-Subscriber et Point-to-Point
- Ne ralentissez pas avec l'ajout de consommateurs. Par exemple, les performances des files d'attente et des rubriques dans ActiveMQ se détériorent à mesure que le nombre de consommateurs à destination augmente.
- Être évolutif horizontalement; si un seul message persiste ne peut le faire qu'à la vitesse maximale du disque, alors pour augmenter les performances, il est logique d'aller au-delà des limites d'une instance de courtier
- Délimiter l'accès au stockage et à la récupération des messages
Pour y parvenir, Kafka a adopté une architecture qui a redéfini les rôles et responsabilités des clients et des courtiers de messagerie. Le modèle JMS est très axé sur le courtier, où il est responsable de la distribution des messages, et les clients n'ont qu'à se soucier d'envoyer et de recevoir des messages. Kafka, d'autre part, est orienté vers le client, le client assumant de nombreuses fonctions d'un courtier traditionnel, telles que la distribution équitable des messages pertinents parmi les consommateurs, en échange de recevoir un courtier extrêmement rapide et évolutif. Pour les personnes travaillant avec des systèmes de messagerie traditionnels, travailler avec Kafka nécessite un changement d'attitude fondamental.
Cette direction technique a conduit à la création d'une infrastructure de messagerie qui peut augmenter le débit de plusieurs ordres de grandeur par rapport à un courtier conventionnel. Comme nous le verrons, cette approche est lourde de compromis, ce qui signifie que Kafka n'est pas adapté à certains types de charges et de logiciels installés.
Modèle de destination unifiée
Pour répondre aux exigences décrites ci-dessus, Kafka a combiné la publication-abonnement et la messagerie point à point dans un seul type de destinataire - le
sujet . C'est déroutant pour les personnes travaillant avec des systèmes de messagerie, où le mot «sujet» fait référence à un mécanisme de diffusion à partir duquel (à partir du sujet) la lecture n'est pas fiable (n'est pas durable). Les sujets Kafka doivent être considérés comme un type de destination hybride, tel que défini dans l'introduction de ce livre.
Dans la suite de ce chapitre, sauf indication contraire explicite, le terme sujet fera référence au sujet Kafka.
Pour bien comprendre comment les sujets se comportent et quelles garanties ils offrent, nous devons d'abord examiner comment ils sont mis en œuvre dans Kafka.
Chaque sujet dans Kafka a son propre journal.Les producteurs qui envoient des messages à Kafka s'ajoutent à ce magazine, et les consommateurs lisent le magazine à l'aide de pointeurs qui avancent constamment. Kafka supprime périodiquement les parties les plus anciennes du journal, que les messages de ces parties aient été lus ou non. Un élément central de la conception de Kafka est que le courtier ne se soucie pas de savoir si les messages sont lus ou non - c'est la responsabilité du client.
Les termes «journal» et «index» ne se trouvent pas dans la documentation de Kafka . Ces termes bien connus sont utilisés ici pour aider à la compréhension.
Ce modèle est complètement différent d'ActiveMQ, où les messages de toutes les files d'attente sont stockés dans un journal, et le courtier marque les messages comme supprimés après leur lecture.
Allons maintenant un peu plus loin et regardons le magazine thématique plus en détail.
Kafka Magazine se compose de plusieurs partitions (
figure 3-1 ). Kafka garantit un ordre strict dans chaque partition. Cela signifie que les messages écrits sur la partition dans un certain ordre seront lus dans le même ordre. Chaque partition est implémentée en tant que fichier journal tournant (journal) qui contient un
sous -
ensemble de tous les messages envoyés au sujet par ses producteurs. La rubrique créée contient une partition par défaut. Le partitionnement est l'idée centrale de Kafka pour la mise à l'échelle horizontale.
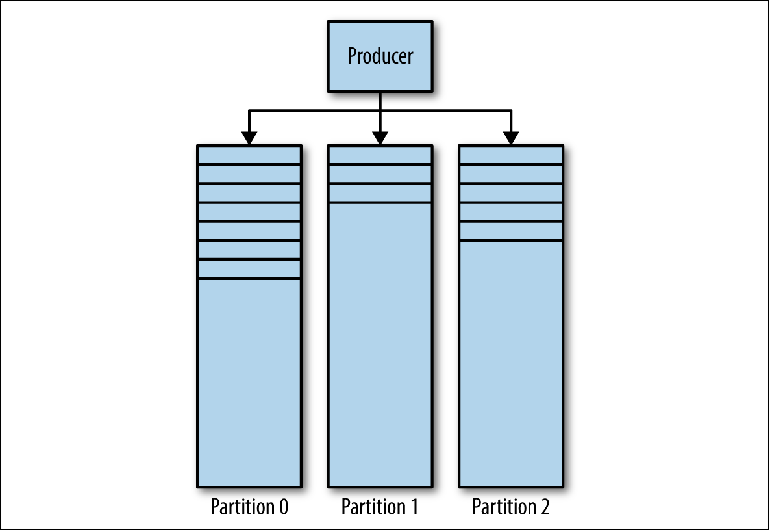 Figure 3-1. Cloisons Kafka
Figure 3-1. Cloisons KafkaLorsque le producteur envoie un message au sujet Kafka, il décide à quelle partition envoyer le message. Nous examinerons cela plus en détail plus tard.
Lire des messages
Un client qui souhaite lire des messages contrôle un pointeur nommé appelé
groupe de consommateurs , qui indique le
décalage d'un message dans une partition. Un décalage est une position avec un nombre croissant qui commence à 0 au début de la partition. Ce groupe de consommateurs, référencé dans l'API via un identifiant défini par l'utilisateur group_id, correspond à un
seul consommateur ou système logique .
La plupart des systèmes de messagerie lisent les données du destinataire via plusieurs instances et threads pour traiter les messages en parallèle. Ainsi, il y aura généralement de nombreux cas de consommateurs qui partagent le même groupe de consommateurs.
Le problème de lecture peut être représenté comme suit:
- Le sujet a plusieurs partitions
- Plusieurs groupes de consommateurs peuvent utiliser le sujet en même temps.
- Un groupe de consommateurs peut avoir plusieurs instances distinctes.
Il s'agit d'un problème de plusieurs à plusieurs non trivial. Pour comprendre comment Kafka gère les relations entre les groupes de consommateurs, les instances de consommateurs et les partitions, examinons une série de scripts de lecture de plus en plus complexes.
Consommateurs et groupes de consommateurs
Prenons un sujet à partition unique comme point de départ (
figure 3-2 ).
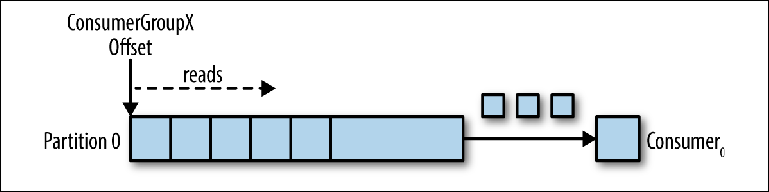 Figure 3-2. Le consommateur lit à partir de la partition
Figure 3-2. Le consommateur lit à partir de la partitionLorsqu'une instance de consommateur est connectée avec son propre group_id à cette rubrique, une partition à lire et un décalage dans cette partition lui sont attribués. La position de ce décalage est configurée dans le client comme un pointeur vers la position la plus récente (le message le plus récent) ou la position la plus ancienne (le message le plus ancien). Le consommateur demande (interroge) des messages du sujet, ce qui conduit à leur lecture séquentielle dans le journal.
La position de décalage est régulièrement
validée dans Kafka et enregistrée sous forme de messages dans la
rubrique interne
_consumer_offsets . Contrairement aux courtiers habituels, les messages lus ne sont toujours pas supprimés et le client peut rembobiner le décalage afin de retraiter les messages déjà consultés.
Lorsqu'un deuxième consommateur logique est connecté à l'aide d'un autre group_id, il contrôle un deuxième pointeur indépendant du premier (
figure 3-3 ). Ainsi, le sujet Kafka agit comme une file d'attente dans laquelle il y a un consommateur et, comme sujet régulier, un éditeur-abonné (pub-sub), auquel plusieurs consommateurs sont abonnés, avec l'avantage supplémentaire que tous les messages sont enregistrés et peuvent être traités plusieurs fois.
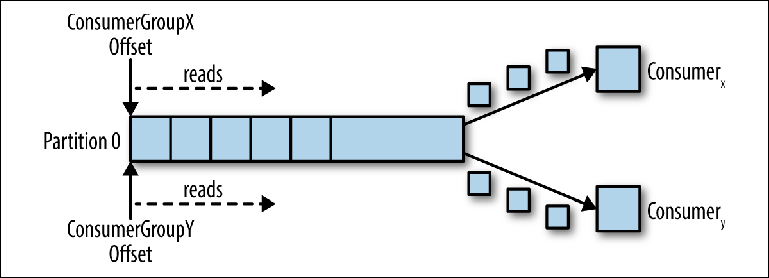 Figure 3-3. Deux consommateurs dans différents groupes de consommateurs lisent à partir de la même partition
Figure 3-3. Deux consommateurs dans différents groupes de consommateurs lisent à partir de la même partitionConsommateurs du groupe des consommateurs
Lorsqu'une instance du consommateur lit les données de la partition, il contrôle complètement le pointeur et traite les messages, comme décrit dans la section précédente.
Si plusieurs instances des consommateurs étaient connectées avec le même group_id au sujet avec la même partition, la dernière instance connectée recevra alors le contrôle du pointeur et à partir de là, elle recevra tous les messages (
Figure 3-4 ).
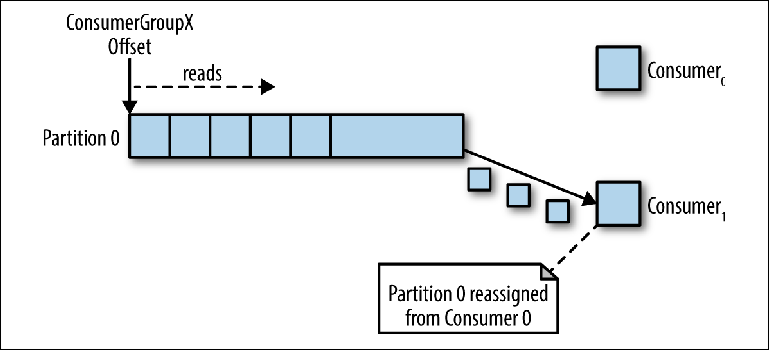 Figure 3-4. Deux consommateurs dans le même groupe de consommateurs lisent à partir de la même partition
Figure 3-4. Deux consommateurs dans le même groupe de consommateurs lisent à partir de la même partitionCe mode de traitement, dans lequel le nombre d'instances de consommateurs dépasse le nombre de partitions, peut être considéré comme une sorte de consommateur monopolistique. Cela peut être utile si vous avez besoin d'un clustering "actif-passif" (ou "chaud-chaud") de vos instances de consommateurs, bien que le fonctionnement parallèle de plusieurs consommateurs ("actif-actif" ou "chaud-chaud") soit beaucoup plus typique que les consommateurs. en mode veille.
Ce comportement de distribution des messages, décrit ci-dessus, peut être surprenant par rapport au comportement d'une file d'attente JMS standard. Dans ce modèle, les messages envoyés à la file d'attente seront répartis également entre les deux consommateurs.
Le plus souvent, lorsque nous créons plusieurs instances de compilateurs, nous le faisons soit pour le traitement parallèle des messages, soit pour augmenter la vitesse de lecture, soit pour augmenter la stabilité du processus de lecture. Étant donné qu'une seule instance d'un consommateur peut lire les données d'une partition, comment cela est-il possible dans Kafka?
Une façon de procéder consiste à utiliser une instance du consommateur pour lire tous les messages et les envoyer au pool de threads. Bien que cette approche augmente le débit de traitement, elle augmente la complexité de la logique des consommateurs et ne fait rien pour augmenter la stabilité du système de lecture. Si une instance du consommateur s'éteint en raison d'une panne de courant ou d'un événement similaire, la relecture s'arrête.
La manière canonique de résoudre ce problème dans Kafka est d'utiliser plus de partitions.
Partitionnement
Les partitions sont le principal mécanisme de parallélisation de la lecture et de la mise à l'échelle du sujet au-delà de la bande passante d'une instance du courtier. Pour mieux comprendre cela, examinons une situation où il existe un sujet avec deux partitions et un consommateur souscrit à ce sujet (
figure 3-5 ).
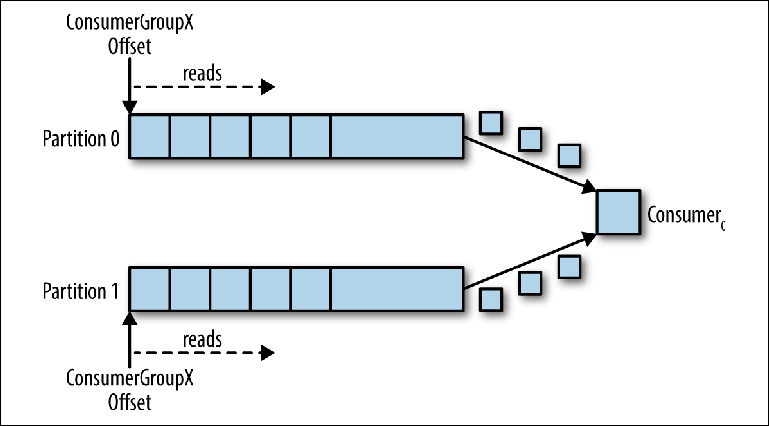 Figure 3-5. Un consommateur lit à partir de plusieurs partitions
Figure 3-5. Un consommateur lit à partir de plusieurs partitionsDans ce scénario, le consultant obtient le contrôle sur les pointeurs correspondant à son group_id dans les deux partitions et la lecture des messages des deux partitions commence.
Lorsqu'un calculateur supplémentaire est ajouté à cette rubrique pour le même group_id, Kafka réaffecte (réaffecte) l'une des partitions de la première à la seconde. Après cela, chaque instance du consommateur sera soustraite d'une partition du sujet (
figure 3-6 ).
Pour vous assurer que les messages sont traités en parallèle dans 20 threads, vous aurez besoin d'au moins 20 partitions. S'il y aura moins de partitions, vous aurez toujours des consommateurs qui n'ont rien à travailler, comme décrit précédemment dans la discussion sur les moniteurs exclusifs.
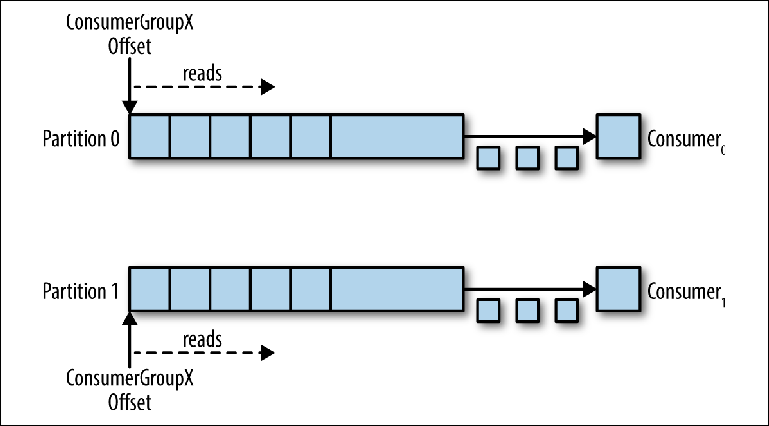 Figure 3-6. Deux consommateurs dans le même groupe de consommateurs lisent à partir de partitions différentes
Figure 3-6. Deux consommateurs dans le même groupe de consommateurs lisent à partir de partitions différentesCe schéma réduit considérablement la complexité du courtier Kafka par rapport à la distribution des messages nécessaire pour prendre en charge la file d'attente JMS. Il n'est pas nécessaire de prendre soin des points suivants:
- Quel consommateur devrait recevoir le message suivant en fonction de la distribution à tour de rôle, de la capacité actuelle du tampon de prélecture ou des messages précédents (comme pour les groupes de messages JMS).
- Quels messages ont été envoyés à quels consommateurs et devraient-ils être renvoyés en cas de défaillance.
Tout ce que le courtier Kafka doit faire est d'envoyer systématiquement des messages au conseiller lorsque celui-ci le demande.
Cependant, les exigences de parallélisation de la relecture et de la réexpédition des messages infructueux ne disparaissent pas - leur responsabilité passe simplement du courtier au client. Cela signifie qu'ils doivent être pris en compte dans votre code.
Envoi de messages
La responsabilité de décider à quelle partition envoyer le message est le producteur du message. Pour comprendre le mécanisme par lequel cela se fait, vous devez d'abord considérer ce que nous envoyons réellement.
Alors que dans JMS, nous utilisons une structure de message avec des métadonnées (en-têtes et propriétés) et un corps contenant une charge utile, dans Kafka, le message est
une paire clé-valeur . La charge utile du message est envoyée en tant que valeur. Une clé, d'autre part, est principalement utilisée pour le partitionnement et doit contenir une
clé spécifique à la
logique métier pour placer les messages associés dans la même partition.
Dans le chapitre 2, nous avons discuté du scénario de paris en ligne, lorsque les événements connexes doivent être traités dans l'ordre par un seul consommateur:
- Le compte utilisateur est configuré.
- L'argent est crédité sur le compte.
- Un pari est effectué qui retire de l'argent du compte.
Si chaque événement est un message envoyé au sujet, alors dans ce cas l'identifiant du compte sera la clé naturelle.
Lorsqu'un message est envoyé à l'aide de l'API Kafka Producer, il est transmis à la fonction de partition qui, compte tenu du message et de l'état actuel du cluster Kafka, renvoie l'identifiant de la partition à laquelle le message doit être envoyé. Cette fonctionnalité est implémentée en Java via l'interface de partitionnement.
Cette interface est la suivante:
interface Partitioner { int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster); }
L'implémentation du partitionneur utilise l'algorithme de hachage à usage général par défaut sur la clé ou le tourniquet si la clé n'est pas spécifiée pour déterminer la partition. Cette valeur par défaut fonctionne bien dans la plupart des cas. Cependant, à l'avenir, vous voudrez peut-être écrire le vôtre.
Écrire votre propre stratégie de partitionnement
Regardons un exemple lorsque vous souhaitez envoyer des métadonnées avec la charge utile du message. La charge utile dans notre exemple est une instruction pour effectuer un dépôt sur un compte de jeu. Une instruction est quelque chose que nous voudrions garantir de ne pas modifier pendant la transmission, et nous voulons être sûrs que seul un système supérieur de confiance peut initier cette instruction. Dans ce cas, les systèmes d'envoi et de réception conviennent de l'utilisation de la signature pour authentifier le message.
Dans un JMS standard, nous définissons simplement la propriété de signature de message et l'ajoutons au message. Cependant, Kafka ne nous fournit pas de mécanisme de transmission des métadonnées - uniquement la clé et la valeur.
Étant donné que la valeur est la charge utile d'un virement bancaire (charge utile de virement bancaire), dont nous voulons maintenir l'intégrité, nous n'avons pas d'autre choix que de déterminer la structure de données à utiliser dans la clé. En supposant que nous ayons besoin d'un identifiant de compte pour le partitionnement, puisque tous les messages liés au compte doivent être traités dans l'ordre, nous proposerons la structure JSON suivante:
{ "signature": "541661622185851c248b41bf0cea7ad0", "accountId": "10007865234" }
Étant donné que la valeur de la signature variera en fonction de la charge utile, la stratégie de hachage de l'interface de partitionnement par défaut ne regroupera pas de manière fiable les messages associés. Par conséquent, nous devrons rédiger notre propre stratégie, qui analysera cette clé et partagera la valeur de accountId.
Kafka inclut des sommes de contrôle pour détecter la corruption des messages dans le référentiel et dispose d'un ensemble complet de fonctionnalités de sécurité. Même alors, des exigences spécifiques à l'industrie apparaissent parfois, comme celle ci-dessus.
La stratégie de partitionnement des utilisateurs doit garantir que tous les messages associés se retrouvent dans la même partition. Bien que cela semble simple, l'exigence peut être compliquée en raison de l'importance de la commande des messages associés et de la façon dont le nombre de partitions est fixé dans le sujet.
Le nombre de partitions dans le sujet peut changer au fil du temps, car elles peuvent être ajoutées si le trafic dépasse les attentes initiales. Ainsi, les clés de message peuvent être associées à la partition à laquelle elles ont été envoyées à l'origine, ce qui implique une partie de l'état qui doit être répartie entre les instances de producteur.
Un autre facteur à considérer est la distribution uniforme des messages entre les partitions. En règle générale, les clés ne sont pas réparties également entre les messages et les fonctions de hachage ne garantissent pas une distribution équitable des messages pour un petit ensemble de clés.
Il est important de noter que, quelle que soit la façon dont vous décidez de diviser les messages, le séparateur lui-même peut devoir être réutilisé.
Tenez compte de l'exigence de réplication des données entre les clusters Kafka dans différents emplacements géographiques. À cet effet, Kafka est livré avec un outil en ligne de commande appelé MirrorMaker, qui est utilisé pour lire les messages d'un cluster et les transférer vers un autre.
MirrorMaker doit comprendre les clés de la rubrique répliquée afin de maintenir l'ordre relatif entre les messages lors de la réplication entre les clusters, car le nombre de partitions pour cette rubrique peut ne pas coïncider dans deux clusters.
Les stratégies de partitionnement personnalisées sont relativement rares, car les hachages par défaut ou le tourniquet fonctionnent avec succès dans la plupart des scénarios. Cependant, si vous avez besoin de garanties strictes de commande ou si vous devez extraire des métadonnées des charges utiles, le partitionnement est quelque chose que vous devriez examiner de plus près.
L'évolutivité et les avantages de performance de Kafka proviennent du transfert de certaines responsabilités d'un courtier traditionnel à un client. Dans ce cas, une décision est prise sur la répartition des messages potentiellement liés entre plusieurs consommateurs travaillant en parallèle.
Les courtiers JMS doivent également répondre à ces exigences. Fait intéressant, le mécanisme d'envoi de messages liés au même compte implémenté via les groupes de messages JMS (une sorte de stratégie d'équilibrage de charge rémanente (SLB)) requiert également que l'expéditeur marque les messages comme liés. Dans le cas de JMS, le courtier est responsable de l'envoi de ce groupe de messages associés à l'un des nombreux clients et du transfert de propriété du groupe si le client est tombé.
Accord avec le producteur
Le partitionnement n'est pas la seule chose à considérer lors de l'envoi de messages. Examinons les méthodes send () de la classe Producer dans l'API Java:
Future < RecordMetadata > send(ProducerRecord < K, V > record); Future < RecordMetadata > send(ProducerRecord < K, V > record, Callback callback);
Il convient de noter tout de suite que les deux méthodes renvoient Future, ce qui indique que l'opération d'envoi n'est pas effectuée immédiatement. Par conséquent, il s'avère que le message (ProducerRecord) est écrit dans le tampon d'envoi pour chaque partition active et transmis au courtier dans le flux d'arrière-plan de la bibliothèque cliente Kafka. Bien que cela rend le travail incroyablement rapide, cela signifie qu'une application inexpérimentée peut perdre des messages si son processus est arrêté.
Comme toujours, il existe un moyen de rendre l'opération d'envoi plus fiable en raison des performances. La taille de ce tampon peut être définie sur 0 et le thread de l'application d'envoi sera obligé d'attendre que le message soit envoyé au courtier, comme suit:
RecordMetadata metadata = producer.send(record).get();
Encore une fois sur la lecture des messages
La lecture des messages présente des difficultés supplémentaires qui doivent être prises en compte. Contrairement à l'API JMS, qui peut démarrer un écouteur de message en réponse à un message, l'interface
Consumer Kafka interroge uniquement. Examinons de plus près la méthode
poll () utilisée à cet effet:
ConsumerRecords < K, V > poll(long timeout);
La valeur de retour de la méthode est une structure de conteneur contenant plusieurs objets
ConsumerRecord provenant potentiellement de plusieurs partitions.
Un ConsumerRecord lui-même est un objet détenteur pour une paire clé-valeur avec des métadonnées associées, telles que la partition dont il est dérivé.
Comme indiqué au chapitre 2, nous devons constamment nous souvenir de ce qui arrive aux messages après leur traitement réussi ou échoué, par exemple, si le client ne peut pas traiter le message ou s'il interrompt le travail. Dans JMS, cela a été géré via le mode d'accusé de réception. Le courtier supprimera le message traité avec succès ou remettra le message brut ou retourné (à condition que des transactions aient été utilisées).
Kafka fonctionne d'une manière complètement différente. Les messages ne sont pas supprimés dans le courtier après la relecture et la responsabilité de ce qui se produit en cas d'échec incombe au code lui-même.
Comme nous l'avons déjà dit, un groupe de consommateurs est associé à une compensation dans le magazine. La position du journal associée à ce biais correspond au message suivant qui sera émis en réponse à
poll () . Crucial en lecture est le moment où ce décalage augmente.
Revenant au modèle de lecture discuté précédemment, le traitement des messages comprend trois étapes:
- Récupérez un message à lire.
- Traitez le message.
- Confirmer le message.
Kafka Consumer Advisor est livré avec l'
option de configuration
enable.auto.commit . Il s'agit d'un paramètre par défaut couramment utilisé, comme c'est généralement le cas avec les paramètres contenant le mot «auto».
Avant Kafka 0.10, le client utilisant ce paramètre envoyait le décalage du dernier message lu lors du prochain appel
poll () après le traitement. Cela signifiait que tous les messages qui étaient déjà récupérés pouvaient être retraités si le client les avait déjà traités, mais qu'ils étaient détruits de manière inattendue avant d'appeler
poll () . Étant donné que le courtier ne conserve aucun état concernant le nombre de fois que le message a été lu, le prochain consommateur qui récupère ce message ne saura pas que quelque chose de mauvais s'est produit. Ce comportement était pseudo transactionnel. Le décalage n'a été validé qu'en cas de traitement réussi du message, mais si le client a interrompu, le courtier a de nouveau envoyé le même message à un autre client. Ce comportement était conforme à la garantie de remise de message "
au moins une fois ".
Dans Kafka 0.10, le code client a été modifié de telle manière que la validation a commencé à être périodiquement lancée par la bibliothèque cliente, conformément au paramètre
auto.commit.interval.ms . Ce comportement se situe quelque part entre les modes JMS AUTO_ACKNOWLEDGE et DUPS_OK_ACKNOWLEDGE. Lors de l'utilisation de la validation automatique, les messages pouvaient être confirmés, qu'ils aient été réellement traités ou non - cela pouvait arriver dans le cas d'un consommateur lent. Si le calculateur était interrompu, les messages étaient récupérés par le prochain calculateur, à partir d'une position sécurisée, ce qui pouvait entraîner un saut de message. Dans ce cas, Kafka n'a pas perdu de messages, le code de lecture ne les a tout simplement pas traités.
Ce mode a les mêmes perspectives que dans la version 0.9: les messages peuvent être traités, mais en cas d'échec, le décalage peut ne pas être fermé, ce qui pourrait potentiellement conduire à une duplication de livraison. Plus vous récupérez de messages lorsque vous effectuez
poll () , plus ce problème est important.
Comme indiqué dans la section «Soustraction de messages de la file d'attente» du
chapitre 2 , il n'y a rien de tel qu'une remise de message unique dans le système de messagerie, compte tenu des modes de défaillance.
Dans Kafka, il existe deux façons de corriger (valider) un décalage (décalage): automatiquement et manuellement. Dans les deux cas, les messages peuvent être traités plusieurs fois, dans le cas où le message a été traité mais a échoué avant la validation. Vous ne pouvez pas non plus traiter le message du tout si la validation s'est produite en arrière-plan et que votre code a été terminé avant le début du traitement (éventuellement dans Kafka 0.9 et les versions antérieures).
Vous pouvez contrôler le processus de validation manuelle des décalages dans l'API Kafka
Consumer en définissant
enable.auto.commit sur false et en appelant explicitement l'une des méthodes suivantes:
void commitSync(); void commitAsync();
Si vous souhaitez traiter le message «au moins une fois», vous devez valider le décalage manuellement à l'aide de
commitSync () en exécutant cette commande immédiatement après le traitement des messages.
Ces méthodes ne permettent pas de traiter les messages accusés de réception avant qu'ils ne soient traités, mais ils ne font rien pour éliminer la duplication potentielle du traitement, tout en créant l'apparence d'une transactionnalité. Kafka n'a effectué aucune transaction. Le client n'a pas la possibilité de faire ce qui suit:
- Annulez automatiquement un message d'annulation. Les consommateurs eux-mêmes doivent gérer les exceptions résultant de charges utiles et de déconnexions dorsales, car ils ne peuvent pas compter sur le courtier pour renvoyer des messages.
- Envoyez des messages à plusieurs sujets au sein d'une même opération atomique. Comme nous le verrons bientôt, le contrôle de divers sujets et partitions peut être localisé sur différentes machines du cluster Kafka, qui ne coordonnent pas les transactions lors de l'envoi. Au moment d'écrire ces lignes, certains travaux ont été réalisés pour rendre cela possible avec le KIP-98.
- Associez la lecture d'un message d'un sujet à l'envoi d'un autre message à un autre sujet. Encore une fois, l'architecture de Kafka dépend de nombreuses machines indépendantes fonctionnant comme un seul bus et aucune tentative n'est faite pour le cacher. Par exemple, aucun composant API ne permettrait de lier le consommateur et le producteur dans une transaction. Dans JMS, cela est fourni par l'objet Session à partir duquel MessageProducers et MessageConsumers sont créés.
Si nous ne pouvons pas compter sur les transactions, comment pouvons-nous fournir une sémantique plus proche de celles fournies par les systèmes de messagerie traditionnels?
S'il existe une possibilité que le décalage du consommateur augmente avant que le message n'ait été traité, par exemple lors de la défaillance du client, le client n'aura aucun moyen de savoir si le groupe de clients a manqué le message lorsque la partition est affectée. Ainsi, une stratégie consiste à rembobiner le décalage à la position précédente. L'API Kafka Consumer Advisor fournit les méthodes suivantes pour cela:
void seek(TopicPartition partition, long offset); void seekToBeginning(Collection < TopicPartition > partitions);
La méthode
seek () peut être utilisée avec la méthode
offsetsForTimes (Map <TopicPartition, Long> timestampsToSearch) pour revenir à un état à un moment donné dans le passé.
Implicitement, l'utilisation de cette approche signifie qu'il est très probable que certains messages qui ont été traités précédemment seront lus et traités à nouveau. Pour éviter cela, nous pouvons utiliser la lecture idempotente, comme décrit dans le chapitre 4, pour suivre les messages précédemment consultés et éliminer les doublons.
Comme alternative, le code de votre consommateur peut être simple si la perte ou la duplication de messages est autorisée. Lorsque nous examinons les scénarios d'utilisation pour lesquels Kafka est généralement utilisé, par exemple, le traitement des événements du journal, des mesures, du suivi des clics, etc., nous comprenons que la perte de messages individuels est peu susceptible d'avoir un impact significatif sur les applications environnantes. Dans de tels cas, les valeurs par défaut sont acceptables. En revanche, si votre application doit transférer des paiements, vous devez prendre soin de chaque message individuel. Tout se résume au contexte.
Les observations personnelles montrent qu'avec l'augmentation de l'intensité du message, la valeur de chaque message individuel diminue. Les messages à volume élevé ont tendance à devenir précieux lorsqu'ils sont affichés sous forme agrégée.
Haute disponibilité
L'approche de haute disponibilité de Kafka est très différente d'ActiveMQ. Kafka est développé sur la base de clusters évolutifs horizontalement dans lesquels toutes les instances du courtier reçoivent et distribuent des messages simultanément.
Le cluster Kafka se compose de plusieurs instances de courtier s'exécutant sur différents serveurs. Kafka a été conçu pour fonctionner sur un matériel autonome conventionnel, où chaque nœud a son propre stockage dédié. L'utilisation du stockage en réseau (SAN) n'est pas recommandée car plusieurs nœuds de calcul peuvent entrer en concurrence pour les intervalles de temps de stockage et créer des conflits.
Kafka est un système
constamment activé. De nombreux grands utilisateurs de Kafka n'éteignent jamais leurs clusters et le logiciel fournit toujours des mises à jour via un redémarrage cohérent. Ceci est réalisé en garantissant la compatibilité avec la version précédente pour les messages et les interactions entre les courtiers.
Les courtiers sont connectés à un
cluster de serveurs
ZooKeeper , qui agit comme un registre de configuration donné et est utilisé pour coordonner les rôles de chaque courtier. ZooKeeper lui-même est un système distribué qui fournit une haute disponibilité grâce à la réplication des informations en établissant un
quorum .
Dans le cas de base, la rubrique est créée dans le cluster Kafka avec les propriétés suivantes:
- Le nombre de partitions. Comme indiqué précédemment, la valeur exacte utilisée ici dépend du niveau souhaité de lecture simultanée.
- Le coefficient de réplication (facteur) détermine combien d'instances de courtier dans le cluster doivent contenir les journaux de cette partition.
En utilisant ZooKeepers pour la coordination, Kafka essaie de répartir équitablement les nouvelles partitions entre les courtiers du cluster. Cette opération est effectuée par une instance, qui agit en tant que contrôleur.
Lors de l'exécution
de chaque partition du sujet, le contrôleur attribue au courtier les rôles de
leader (leader, maître, leader) et
followers (followers, esclaves, subordonnés). Le courtier, agissant en tant que leader de cette partition, est responsable de la réception de tous les messages qui lui sont envoyés par les producteurs et de la distribution des messages aux consommateurs. Lors de l'envoi de messages à une partition de rubrique, ils sont répliqués sur tous les nœuds du courtier agissant en tant que suiveurs pour cette partition. Chaque nœud contenant les journaux de la partition est appelé
réplique . Un courtier peut agir en tant que leader pour certaines partitions et en tant que suiveur pour d'autres.
Un suiveur contenant tous les messages stockés par le leader est appelé une
réplique synchronisée (une réplique dans un état synchronisé, une réplique synchronisée). Si le courtier agissant en tant que leader de la partition est déconnecté, tout courtier qui est dans l'état mis à jour ou synchronisé pour cette partition peut assumer le rôle de leader. Il s'agit d'un design incroyablement durable.
Une partie de la configuration du producteur est le paramètre
acks , qui détermine le nombre de répliques qui doivent accuser réception d'un message avant que le flux d'application continue à envoyer: 0, 1 ou tous. Si la valeur est définie sur
all , le leader enverra une confirmation au producteur dès réception du message dès qu'il recevra la confirmation de l'enregistrement de plusieurs répliques (y compris lui-même) définies par le
paramètre de rubrique
min.insync.replicas (par défaut 1). Si le message ne peut pas être répliqué avec succès, le producteur
lèvera une exception pour l'application (
NotEnoughReplicas ou
NotEnoughReplicasAfterAppend ).
Dans une configuration typique, une rubrique est créée avec un coefficient de réplication de 3 (1 leader, 2 suiveurs pour chaque partition) et le paramètre min.insync.replicas est défini sur 2. Dans ce cas, le cluster permettra à l'un des courtiers gérant la partition d'être déconnecté sans affecter les applications clientes.Cela nous ramène au compromis déjà familier entre performances et fiabilité. La réplication se produit en raison du temps d'attente supplémentaire pour les accusés de réception (accusés de réception) des abonnés. Bien qu'elle s'exécute en parallèle, la réplication d'au moins trois nœuds a les mêmes performances que deux (en ignorant l'augmentation de l'utilisation de la bande passante réseau).En utilisant ce schéma de réplication, Kafka évite intelligemment la nécessité d'écrire physiquement chaque message sur le disque en utilisant l'opération sync () . Chaque message envoyé par le producteur sera écrit dans le journal de partition, mais, comme expliqué au chapitre 2, l'écriture dans le fichier est initialement effectuée dans le tampon du système d'exploitation. Si ce message est répliqué sur une autre instance de Kafka et est dans sa mémoire, la perte d'un leader ne signifie pas que le message lui-même a été perdu - une réplique synchronisée peut le prendre sur lui.Désactiver le fonctionnement sync ()signifie que Kafka peut recevoir des messages à la vitesse avec laquelle il peut les écrire en mémoire. Inversement, plus vous évitez de vider la mémoire sur le disque, mieux c'est. Pour cette raison, il n'est pas rare que les courtiers Kafka allouent 64 Go ou plus de mémoire. Cette utilisation de la mémoire signifie qu'une instance de Kafka peut facilement fonctionner à des vitesses plusieurs milliers de fois plus rapides qu'un courtier de messages traditionnel.Kafka peut également être configuré pour utiliser sync ()aux packages de messages. Étant donné que tout chez Kafka est orienté package, il fonctionne plutôt bien pour de nombreux cas d'utilisation et est un outil utile pour les utilisateurs qui ont besoin de garanties très solides. La plupart des performances pures de Kafka sont liées aux messages envoyés au courtier sous forme de paquets et au fait que ces messages sont lus à partir du courtier par blocs successifs à l'aide d' opérations de copie nulle (opérations qui n'effectuent pas la tâche de copier des données d'une zone mémoire vers un autre). Ce dernier est un gros gain en termes de performances et de ressources et n'est possible que grâce à l'utilisation de la structure de données de journal sous-jacente qui définit le schéma de partition.Dans un cluster Kafka, des performances beaucoup plus élevées sont possibles que lors de l'utilisation d'un seul courtier Kafka, car les partitions de rubrique peuvent être mises à l'échelle horizontalement sur de nombreuses machines distinctes.Résumé
Dans ce chapitre, nous avons examiné comment l'architecture Kafka réinterprète la relation entre les clients et les courtiers pour fournir un pipeline de messagerie incroyablement robuste, avec une bande passante plusieurs fois supérieure à celle d'un courtier de messages classique. Nous avons discuté de la fonctionnalité qu'il utilise pour atteindre cet objectif et brièvement examiné l'architecture des applications qui fournissent cette fonctionnalité. Dans le chapitre suivant, nous discuterons des problèmes courants que les applications de messagerie doivent résoudre et discuterons des stratégies pour les résoudre. Nous concluons le chapitre en décrivant comment parler des technologies de messagerie en général afin que vous puissiez évaluer leur adéquation à vos cas d'utilisation.Traduction terminée: tele.gg/middle_javaÀ suivre ...