Je m'appelle Igor Volkov. Je travaille dans une société de conseil en tant que développeur Java, architecte, chef d'équipe, responsable technique. Différents rôles en fonction des besoins actuels du projet. Il a attiré l'attention sur les concours de mail.ru pendant longtemps, mais il s'est avéré ne participer activement qu'à Paper IO.
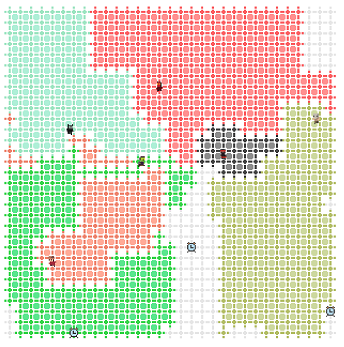
Cette fois, les organisateurs ont proposé de mettre en œuvre une stratégie de gestion des bots basée sur le jeu populaire. En savoir plus sur les règles ici . Le code de ma stratégie se trouve ici , et des exemples de jeux sur le site du championnat .
Au tout début du concours, comme il me semblait, l'idée d'implémentation de pop-up la plus courante était l'utilisation des SCTM . Par conséquent, j'ai passé un peu de temps à expérimenter cet algorithme. Et sans avoir compris comment l'utiliser efficacement pour résoudre le problème, j'ai décidé de commencer par générer de nombreux itinéraires rectangulaires (avec deux, puis avec trois tours) et leur évaluation ultérieure.
Algorithme de stratégie
L'algorithme de haut niveau de la stratégie peut être représenté par les 6 points suivants:
- Lisez l'état du monde
- Convertir des objets de message en objets de travail
- Former un ensemble de routes rectangulaires
- Évaluez chacun des itinéraires générés
- Choisissez le meilleur itinéraire
- Envoyer l'équipe
Cet algorithme n'a pas changé pendant la compétition. Seule la méthode de formation des routes des bots et leur évaluation ont été modifiées.
La classe SimpleStrategy contient la version initiale de la stratégie, et la classe BestStrategy est une version améliorée, qui a pris la 2e place dans la compétition.
Lire l'état du monde
L'état du monde est transmis en tant qu'objet JSON via STDIN . J'ai vu dans pom.xml que vous pouvez utiliser la bibliothèque Gson et la tâche de lire l'état du monde a été grandement simplifiée. À l'aide de la bibliothèque Gson, désérialisé la chaîne JSON lue à partir du flux d'entrée standard dans une instance de la classe Message . Le code est dans Main.java (lignes 44-49) .
Créer des objets de travail
L'utilisation d'objets de transport dans le code du programme principal n'est généralement pas très pratique et incorrecte sur le plan architectural. Par exemple, les organisateurs, pour une raison ou une autre, peuvent changer le format des messages. Par conséquent, il est nécessaire de transformer les objets de transport en travailleurs, qui seront utilisés dans le code de programme principal. Les classes Player et PlayerState préservent l'état du bot, et la classe utilitaire MessagePlayer2PlayerConverter aide à créer ces classes en fonction des données du message de transport. La classe Bonus contient des informations sur le bonus d'une cellule sur le terrain. Le code pour créer des objets de travail se trouve dans Main.java (lignes 61-74) .
Dans les premières versions de la stratégie ( SimpleStrategy ), le chemin était défini à l'aide des classes MovePlanWithScore et Move . Move définit la direction du mouvement et le nombre de cellules que le bot doit déplacer dans cette direction, et MovePlanWithScore contient l'itinéraire spécifié par le tableau Move et une estimation de cet itinéraire. Un tableau peut contenir de un à quatre objets Move . Malgré le fait que seuls les itinéraires rectangulaires avec pas plus de trois tours sont pris en compte, en fait l'itinéraire du bot est obtenu sous la forme d'une ligne brisée. Ceci est réalisé en choisissant un nouveau meilleur itinéraire rectangulaire à chaque tour. La fonction de génération de route , implémentée sous forme de boucles imbriquées, forme une liste à partir de MovePlanWithScore pour son évaluation ultérieure.
Une telle formation des trajectoires du bot n'était pas très efficace en termes de performance de l'évaluation suivante, car il fallait calculer plusieurs fois les mêmes trajectoires, mais elle était très utile pour comprendre la mécanique du jeu.
Dans les versions ultérieures de la stratégie, BestStrategy a commencé à utiliser l'arborescence des itinéraires. La classe MoveNode reflète le nœud de cet arbre. L'arbre est entièrement formé au début de la stratégie. Faites attention à la méthode init de la classe MoveNode . C'est très similaire à la génération de routes à partir de la classe SimpleStrategy . Fondamentalement, l'itinéraire en question n'est pas très différent de la première version.
Je pense que la formation des routes aurait pu être améliorée un peu plus en ajoutant une autre tournure. Mais il n'y avait pas assez de temps pour l'optimisation.
Évaluation de l'itinéraire
Où que se trouve le bot, le meilleur itinéraire se terminant sur son territoire a toujours été choisi pour lui. Pour évaluer l'itinéraire, j'ai introduit deux indicateurs: le score et le risque. Score - reflète approximativement le nombre de points marqués par tick du chemin, et risque - le nombre de ticks qui ne suffisent pas pour terminer le chemin (par exemple, du fait que l'adversaire peut attraper par la queue). Le risque n'est pas apparu immédiatement. Dans la première version, si le bot découvrait soudainement au milieu du chemin qu'il n'avait pas le temps de terminer le parcours, il «devenait fou», car tous les chemins dangereux étaient également mauvais pour lui. De tous les itinéraires considérés, le plus «sûr» est sélectionné avec le nombre maximum de points par tick du chemin.
Pour évaluer la sécurité de l'itinéraire, je calcule la matrice d'accessibilité: pour chaque cellule du terrain de jeu, je trouve une coche sur laquelle le bot de l'adversaire peut y apparaître. Tout d'abord, seulement une coche, puis ajouté un calcul de longueur de queue. Les bonus récupérables en cours de route n'étaient pas non plus pris en compte dans les premières versions de la stratégie. La classe TimeMatrixBuilder calcule les matrices de tiques et les longueurs de queue des bots rivaux. Ces matrices sont ensuite utilisées pour évaluer le risque. Si mon bot est sur son territoire au moment du calcul du prochain mouvement - le niveau de risque maximum est attribué aux routes dangereuses, si le bot était déjà en route sur un territoire étranger ou neutre, le risque est évalué comme la différence entre les tiques de l'achèvement du chemin (le bot est arrivé sur son territoire) et la tique quand il le peut menacer le danger (par exemple, le robot de quelqu'un d'autre peut marcher sur la queue).
Dans les premières versions de la stratégie, le score n'était considéré que sur la base du territoire capturé et les bonus étaient légèrement pris en compte. Pour trouver les cellules capturées, j'utilise un algorithme récursif . De nombreux concurrents se sont plaints de l'étrangeté et de la complexité de calcul excessive de l'algorithme utilisé par les organisateurs de Local Runner . Je suppose que cela a été fait intentionnellement afin de ne pas donner aux participants du concours des solutions toutes faites.
Étrange, mais malgré la primitivité des premières versions de la stratégie, elle se montre plutôt bien: 10e place dans le bac à sable. Certes, lors de la ronde préfinale, il a commencé à baisser rapidement: les autres participants ont amélioré leurs stratégies.
Mon robot est souvent mort. Tout d'abord, en raison du fait qu'une route était en cours de construction vers le territoire qui a été capturé par des robots rivaux. Le chemin s'est allongé de façon inattendue et mon robot a été attrapé par la queue. Souvent décédé en raison d'une prévision incorrecte de la longueur de la queue et de la vitesse du bot de l'adversaire. Par exemple, le robot d'un adversaire prenant un ralentissement était dangereux, car dans le calcul approximatif, la stratégie supposait qu'il aurait déjà dû quitter la cellule et qu'il était toujours là. Pour lutter contre ces problèmes, j'ai commencé à calculer un plus grand nombre d'indicateurs pour chaque cellule du terrain de jeu (classes AnalyticsBuilder et CellDetails ).
Compter les cellules du terrain de jeu
- Coche à laquelle le robot adverse peut occuper la cage (coche à la queue)
- Cochez à partir de laquelle le bot adverse peut entrer dans la cellule
- La longueur de la queue lors de l'entrée dans la cage
- Coche à laquelle le bot adverse peut sortir de la cage
- Longueur de queue en quittant la cage
- Coche à laquelle une cellule peut être capturée par le bot d'un adversaire
- Cochez la case où la cellule peut être la cible pour capturer un territoire
- Cochez sur laquelle la cellule peut être frappée avec une scie
La profondeur de l'analyse est limitée à 10 mouvements. Je pense qu'il était possible d'atteindre une plus grande profondeur en abandonnant le calcul des rivaux individuels ou en introduisant une profondeur flottante, mais il n'y avait pas assez de temps pour l'optimisation. En plus d' AnalyticsBuilder, il a commencé à utiliser SimpleTickMatrixBuilder s'il y avait un manque de profondeur de rendu pour AnalyticsBuilder . Les résultats d'analyse sont utilisés par BestStrategy .
La fonction de notation s'est également légèrement améliorée:
- J'ai commencé à prendre en compte les bonus: une pénalité pour avoir pris un bonus de décélération et un bonus pour avoir pris des accélérations et vu des bonus. En conséquence, le bot a commencé à éviter les mauvais bonus et en a ramassé de bons en cours de route.
- Il a commencé à prendre en compte le choc des têtes. Ajout de quelques points pour le choc de la victoire. Plus une collision est possible, moins il y a de points.
- Pour réduire la probabilité de l'environnement, il a ajouté quelques points pour prendre les cellules limites de l'adversaire.
- Réduction de la valeur des cellules vides à la frontière: plus le centre est éloigné, plus la valeur est basse. En regardant les combats de la finale, je suis arrivé à la conclusion que pour le fait même de capturer une cellule vide, il n'était pas nécessaire d'accumuler des points. La valeur d'une cellule vide doit dépendre de la proximité de grands groupes de cellules ennemies. Malheureusement, en finale, il n'était plus possible de modifier la stratégie.
- Ajout de points pour entourer la tête du bot de l'adversaire. Je ne sais pas si cela a aidé en quelque sorte. Peut-être avec les stratégies les plus simples.
- Il a ajouté des points même pour une saisie futile de la queue (le bot de l'adversaire a réussi à capturer le territoire au même tick dans lequel mon bot a marché sur sa queue). Je ne suis certainement pas sûr, mais je pense que cela a empêché les robots de l'adversaire de capturer le territoire de quelqu'un d'autre et ils ont souvent dû retourner dans le leur.
- En cas de détection de mort possible par capture, le coût des cellules limites du territoire de l’opposant augmente considérablement.
Débogage de stratégie
Les premières versions de la stratégie contenaient un grand nombre de fautes de frappe et d'erreurs: apparemment, le résultat d'une programmation nocturne. Par exemple, dans la classe Cell , l'index a été considéré de manière incorrecte: au lieu de this.index = x * Game.sizeY + y , this.index = x * Game.width + y . Au début, j'ai essayé de ne compter que sur des tests, mais mon intuition suggérait que sans visualisation et sans jouer des matchs joués précédemment, il serait difficile de trouver des erreurs dans le code et d'analyser les raisons des décisions erronées. En conséquence, le visualiseur DebugWindow est apparu , dans lequel vous pouvez afficher les jeux joués précédemment étape par étape, ainsi que commencer le débogage sur la coche souhaitée. Le code n'est pas très beau, écrit à la hâte, mais il m'a beaucoup aidé lors du débogage. Par exemple, une erreur a été immédiatement détectée avec un calcul incorrect de l'indice de cellule. De nombreux concurrents ont affiché des informations de débogage dans la console, mais cela ne m'a pas semblé suffisant.

Optimisation
Afin de ne pas perdre de temps à créer des objets et à exécuter le GC, j'ai essayé de créer certains objets à l'avance. Ce sont les cellules du terrain de jeu (classe Cell ). De plus, pour chaque cellule, des voisins identifiés. Créé un arbre de chemins possibles à l'avance (classe MoveNode ).
J'ai supposé que de nombreux scénarios devraient être simulés, et dans le processus, l'état actuel se détériorerait et devrait être restauré à chaque fois. Par conséquent, pour préserver l'état du monde, j'ai essayé d'utiliser autant que possible des structures compactées. Pour stocker le territoire occupé - BitSet (classe PlayerTerritory ). Chaque cellule du terrain de jeu est numérotée et le numéro de cellule correspond au numéro de bit dans BitSet. Pour stocker la queue, j'ai utilisé BitSet avec ArrayDeque (classe PlayerTail ).
Certes, je n'ai pas pu jouer à différents scénarios par manque de temps. Et comme la fonction principale de calcul du chemin est devenue récursive et que tout l'état peut être stocké sur la pile, les dernières optimisations ne m'ont pas été très utiles.
Idées non réalisées
Lors de l'évaluation du risque de l'itinéraire de mon bot, j'ai pris en compte chaque adversaire indépendamment. En fait, chacun des rivaux a également peur de mourir. Par conséquent, il serait utile d'en tenir compte dans une évaluation des risques. Au moins, cela devait absolument être pris en compte lors des derniers matchs.
Prise en compte de la mort future d'un adversaire. Parfois, il arrivait que le bot capture le territoire de l'adversaire, et l'adversaire meurt de façon inattendue. C'est dommage, car en conséquence, vous ne capturez que des cellules vides.
Comptabilisation des cellules vides qui seront capturées dans un proche avenir en tant que fonction d'évaluation.
Recommandations et remerciements
Je recommande à tous les développeurs de participer activement aux concours AI Cups. Cela développe la réflexion et aide à travers le jeu à apprendre de nouveaux algorithmes. Et comme mon expérience l'a montré, un peu de zèle suffit pour occuper une place de choix et même un code simple et peu optimal peut apporter des résultats.
Un grand merci aux organisateurs. Malgré quelques problèmes techniques, la compétition s'est avérée intéressante. J'attends avec impatience la prochaine!