Sur Internet, les captchas restent d'actualité, qui proposent en option d'écouter le texte de l'image en cliquant sur le bouton correspondant. Si quelqu'un connaît l'image ci-dessous et / ou souhaite savoir comment la contourner à l'aide d'un système de reconnaissance sonore hors ligne, il est suggéré de la lire.
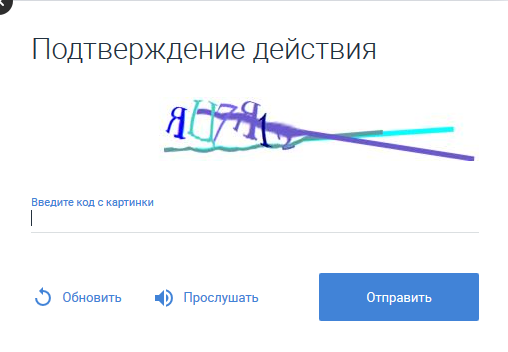
Nous ne tourmenterons pas les intrigues d'experts dans le domaine de la reconnaissance vocale, déclarant immédiatement qu'aucun système de reconnaissance vocale propriétaire n'a été développé pour les objectifs énoncés. L'article utilise le bon vieux Pocketsphinx, mais avec un certain degré de personnalisation.
La préparation
"Vous tombez sur le bureau de concurrents qui ont un contrôle vocal sur les ordinateurs, criez" Sudo Era moins Eref Home "et vous enfuyez." D'après les commentaires.
Ainsi, le captcha propose de s'écouter en cliquant sur le bouton approprié. Si vous enregistrez le fichier audio résultant, vous pouvez découvrir à quoi ressemble un court morceau audio en .mp3. En même temps, il s'est avéré que les captchas sont proposés avec une voix agissant d'une voix féminine ou masculine. Le "dessin" des mêmes sons émis par un homme et une femme est différent:
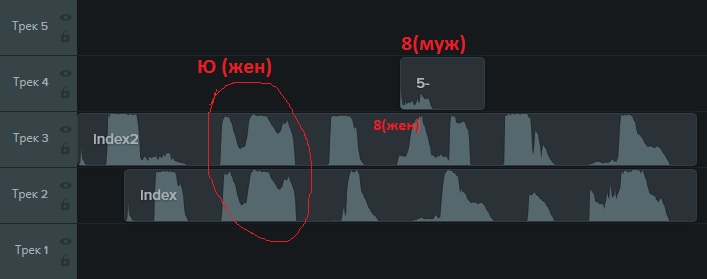
Ils sonnent à la fois des lettres (et du russe) et des chiffres.
À première vue, tout est triste. Mais il y a un point positif en ce que les sons des mêmes lettres coïncident.
Jusqu'à présent, cette connaissance n'aide pas beaucoup. Comment pousser tout cela dans le package du Sphinx?
Installez Pocketsphinx, un modèle de son russe
* Il existe
un article sur Habré où le son est transmis au traducteur Google en ligne via la redirection de la sortie audio. Et cela pourrait terminer ce post, si tout cela fonctionnait pour ce cas.
L'installation de Pocketsphinx lui-même sur Windows (et sur Linux également) n'est pas très compliquée -
téléchargez , installez.
Étant donné que, par défaut, pocketphinx est livré avec une langue anglaise, des modèles acoustiques et un dictionnaire, vous aurez tout de même besoin de la langue russe.
Téléchargez la version russe -
lien .
Après avoir déballé le modèle russe dans la structure du fichier, vous pouvez essayer le fichier test .wav decoder-text.wav avec le code python suivant:
import os from pocketsphinx import AudioFile, get_model_path, get_data_path
Le contenu du fichier audio doit être affiché sur la ligne: "Ilya Ilf Evgeny Petrov Golden Calf".
S'il ne sort pas (comme dans ma situation), vous devez convertir decoder-test.wav en un autre format audio.
Vous aurez besoin de ffmpeg pour cela.
Ffmpeg
Après avoir téléchargé l'utilitaire ffmpeg, placez decoder-test.wav dans C: \ python3 \ ffmpeg \ bin.
Ensuite, convertissez la ligne de commande:
ffmpeg -i decoder-test.wav -ar 16000 decoder-test-.wav
Ensuite, corrigez le lien vers le fichier audio source en code python:
'audio_file': os.path.join(data_path, 'C://python3//decoder-test-.wav'),
Maintenant, après avoir élaboré le code:

Certes, vous devez attendre la seconde venue, le code fonctionne très lentement - environ 20 secondes.
Nous convertissons le captcha audio par le même principe de mp3 en wav et alimentons l'audio du captcha. Jetez un œil au code:

Une sorte d'ignorance, mais il y a un résultat. Cela aurait été bien pire si rien n'avait été mis en évidence. Comme avec une voix féminine:

Voyons comment améliorer le résultat et en même temps l'accélérer.
Vocabulaire
Vous aurez besoin de votre propre dictionnaire. Dans ce cas, il sera composé de toutes les lettres de l'alphabet russe (sauf b, s, b) et des chiffres.
Tous les caractères doivent être placés dans un fichier texte brut, un sur chaque ligne dans le codage UTF-8.
Vous devez maintenant convertir le dictionnaire.
Vous devrez installer perl (il est nécessaire pour que le convertisseur fonctionne).
Ensuite, téléchargez le projet de conversion de
ru4sphinx .
Et convertissez le dictionnaire créé précédemment:
C:\ru4sphinx-master\ru4sphinx-master\text2dict> perl dict2transcript.pl my_dictionary.txt my_dictionary_out.txt.
La sortie est un dictionnaire pour le travail:

L'extension du dictionnaire doit être renommée du format .txt au format .dic et le fichier lui-même doit être placé dans un endroit accessible.
Dans le code python, nous indiquerons l'emplacement du dictionnaire en commentant l'ancien dictionnaire:
Parcourez le programme et voyez le résultat:

Mieux, mais tout aussi lentement, et toutes les lettres ne sont pas correctement identifiées.
Créez votre propre modèle
Cela augmentera considérablement la vitesse de travail et un peu de précision du résultat.
Allons un peu loin des
instructions .
Suivez le
lien et téléchargez notre dictionnaire, précédemment créé au format .txt (pas .dic!) Sur le site:
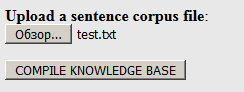
Cliquez sur "Compiler ...". En sortie, vous pouvez télécharger le package résultant dans l'archive .tgz (il contient tous les fichiers nécessaires):
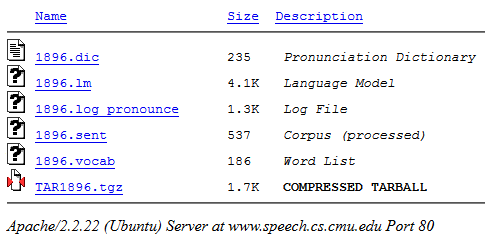
Ensuite, nous prenons un fichier avec l'extension .lm (notre modèle) de l'archive.
Corrigeons le script de reconnaissance python en remplaçant le modèle par un nouveau:
Nous essayons:

Cela fonctionne beaucoup plus rapidement - moins d'une seconde, de plus, toutes les lettres sont définies.
Mais ici, une petite remarque s'impose.
Tous les caractères ne sont pas reconnus correctement et si, au lieu de la bonne lettre, un caractère différent s'affiche, vous pouvez corriger manuellement le dictionnaire .dic créé précédemment en faisant correspondre la correspondance de la lettre.
Par exemple, au lieu de la lettre a, affiche e. Il faut prendre une ligne du dictionnaire e:
ryet le
transférer (en supprimant l'ancien), en changeant la lettre:
ryMais comme la lettre "a" est déjà dans le dictionnaire, vous devez ajouter "(2)" (ou 3,4) à la lettre, en général, un numéro de série, selon le nombre de sons déjà dans le dictionnaire:
a(2) ryLa reconversion du dictionnaire n'est pas nécessaire. D'une manière si simple, vous pouvez presque "ramasser" les phonèmes de toutes les lettres.
Cherchez la femme
Travail de modèle et de vocabulaire, mais pas avec une voix féminine. Si la voix du captcha est féminine, nous n'obtenons rien à la sortie. C'est à la fois bon et mauvais en même temps. Tout d'abord sur le bien.
Si vous n'avez rien reconnu au démarrage du programme, cela signifie que nous avons affaire à une voix féminine, vous pouvez donc filtrer les captchas «féminins».
Mais qu'en faire?
Ici, vous devez travailler avec la conversion.
Par exemple, avec un captcha "masculin", la fréquence était de 16000 et pour un "captcha" féminin 24000:
ffmpeg -i acap(3).mp3 -ar 24000 acap(3)2.wav

Tous les sons sont définis (dans chaque ligne par le son), mais leur correspondance est boiteuse.
Il est préférable de créer un dictionnaire séparé pour le modèle féminin, puis de le modifier.
Cependant, c'est pour l'auto-apprentissage.
Liens utiles:
1.home-smart-home.ru/raspberry-pi-pocketsphinx-offlajn-raspoznavanie-rechi-i-upravlenie-golosom2. https: //itnan.ru/post.php? C = 1 & p = 351376
3.
ru.wikipedia.org/wiki/Cherchez_la_femmeFichiers:
1.
Le programme .
2.
Le modèle .
3. Le
modèle russe .
4.
Dictionnaire .
5.
Testez le captcha .
6.
ffmpeg .
7.
Un pack de captcha .