En train de travailler sur le prochain projet, l'équipe s'est disputée sur l'utilisation du format XML ou SQL dans Liquibase. Naturellement, de nombreux articles ont déjà été écrits sur Liquibase, mais comme toujours, je veux ajouter mes observations. L'article présentera un petit tutoriel sur la création d'une application simple avec une base de données et considérera la différence de méta-informations pour ces types.
Liquibase est une bibliothèque indépendante de la base de données pour le suivi, la gestion et l'application des modifications de schéma de base de données. Afin d'apporter des modifications à la base de données, un fichier de migration (* changeset *) est créé, qui est connecté au fichier principal (* changeLog *), qui contrôle les versions et gère toutes les modifications.
Les formats XML ,
YAML ,
JSON et
SQL sont utilisés pour décrire la structure et les modifications de la base de données.
Le concept de base de la migration de base de données est le suivant:
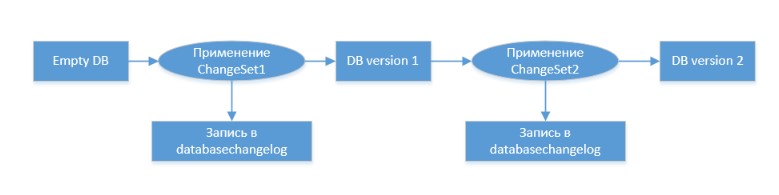
Vous trouverez plus d'informations sur Liquibase
ici ou
ici . J'espère que l'image globale est claire, alors passons à la création du projet.
Le projet de test utilise
- Java 8
- Botte de printemps
- Maven
- H2
- bien se liquibase
Création de projet et dépendances
L'utilisation de Spring-boot n'est pas conditionnelle ici, vous pouvez faire juste un plugin maven pour rouler des scripts. Commençons donc.
1. Créez un projet maven dans l'EDI et ajoutez les dépendances suivantes au fichier pom:
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.liquibase</groupId> <artifactId>liquibase-core</artifactId> <version>3.6.3</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>com.h2database</groupId> <artifactId>h2</artifactId> <scope>runtime</scope> </dependency> </dependencies>
2. Dans le dossier des ressources, créez le fichier application.yml et ajoutez les lignes suivantes:
spring: liquibase: change-log: classpath:/db/changelog/db.changelog-master.yaml datasource: url: jdbc:h2:mem:test; platform: h2 username: sa password: driverClassName: org.h2.Driver h2: console: enabled: true
Ligne Liquibase: change-log: classpath: /db/changelog/db.changelog-master.yaml - nous indique où se trouve le fichier de script liquibase.
3. Dans le dossier des ressources le long du chemin db.changelog-master, créez les fichiers suivants:
- xmlSchema.xml - changer le script au format xml
- sqlSchema.sql - script de modifications au format sql
- data.xml - ajouter des données à la table
- db.changelog-master.yml - liste des changements
4. Ajout de données aux fichiers:
Pour le test, vous devez créer deux t sans rapport
tableaux et l'ensemble minimal de données.
Dans le fichier sqlSchema.sql, nous ajoutons la syntaxe sql bien connue à tout le monde:
L'utilisation de sql comme changeet est guidée par un script facile. Dans les fichiers, tout le monde comprend le sql habituel.
Un commentaire est utilisé pour séparer l'ensemble de modifications:
--changeset TestUsers_sql: 1 avec le numéro de changement et le nom de famille
(les paramètres peuvent être trouvés
ici .)
Dans le fichier xmlSchema.sql, ajoutez la DSL fournie par liquibase: <?xml version="1.0" encoding="UTF-8"?> <databaseChangeLog xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.liquibase.org/xml/ns/dbchangelog" xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.6.xsd"> <changeSet id="Create table test_xml_table" author="TestUsers_xml"> <createTable tableName="test_xml_table"> <column name="name" type="character varying"> <constraints primaryKey="true" nullable="false"/> </column> <column name="description" type="character varying"/> </createTable> </changeSet> <changeSet id="Create table test_xml_table_2" author="TestUsers_xml"> <createTable tableName="test_xml_table_2"> <column name="name" type="character varying"> <constraints primaryKey="true" nullable="false"/> </column> <column name="description" type="character varying"/> </createTable> </changeSet> </databaseChangeLog>
Ce format pour décrire la création de tables est universel pour différentes bases de données. Tout comme le slogan de Java:
"Il est écrit une fois, il fonctionne partout .
" Liquibase utilise la description xml et la compile en code sql spécifique, en fonction de la base de données sélectionnée. Ce qui est très pratique pour les paramètres généraux.
Chaque opération est effectuée dans un changeSet distinct, indiquant l'id et le nom de l'auteur. Je pense que le langage utilisé en xml est très facile à comprendre et n'a même pas besoin d'être expliqué.
5. Téléchargez les données dans nos assiettes, ce n'est pas nécessaire, mais puisque les assiettes ont été faites, vous devez y mettre quelque chose. Nous remplissons le fichier data.xml avec les données suivantes:
<?xml version="1.0" encoding="UTF-8"?> <databaseChangeLog xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.liquibase.org/xml/ns/dbchangelog" xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.6.xsd"> <changeSet id="insert data to test_xml_table" author="TestUsers"> <insert tableName="test_xml_table"> <column name="name" value="model"/> <column name="description" value="- "/> </insert> </changeSet> <changeSet id="insert data to test_xml_table_2" author="TestUsers"> <insert tableName="test_xml_table_2"> <column name="name" value="model"/> <column name="description" value="- "/> </insert> </changeSet> <changeSet id="insert data to test_sql_table" author="TestUsers"> <insert tableName="test_sql_table"> <column name="name" value="model"/> <column name="description" value="- "/> </insert> </changeSet> <changeSet id="insert data to test_sql_table_2" author="TestUsers"> <insert tableName="test_sql_table_2"> <column name="name" value="model"/> <column name="description" value="- "/> </insert> </changeSet> </databaseChangeLog>
Les fichiers des tables roulantes sont créés, les données des tables sont créées. Il est temps de combiner tout cela en un ordre de roulement commun et de lancer notre application.
Ajoutez nos fichiers sql et xml au fichier db.changelog-master.yml:
databaseChangeLog: - include: # schema file: db/changelog/xmlSchema.xml - include: file: db/changelog/sqlSchema.sql # data - include: file: db/changelog/data.xml
Et maintenant que nous avons tout créé. Exécutez simplement notre application. Vous pouvez utiliser la ligne de commande ou le plugin pour démarrer, mais nous allons créer uniquement la méthode principale et exécuter notre SpringApplication.
Afficher les métadonnées
Maintenant que nous avons exécuté nos deux scripts pour créer et remplir les tables, nous pouvons regarder la table databaseChangeLog et voir ce qui est arrivé.

Le résultat du roulement de xml:
- Dans le champ id des fichiers xml, un en-tête apparaît que le développeur pointe vers changeSet, chaque changeSet individuel est une ligne distincte dans la base de données avec un titre et une description.
- L'auteur de chaque modification est indiqué.
Résultat du rouleau SQL:
- Il n'y a pas d'informations détaillées sur changeSet dans le champ id des fichiers sql.
- L'auteur de chaque modification n'est pas indiqué.
Une autre conclusion importante à l'utilisation de xml est la restauration. Les commandes telles que créer une table, modifier une table, ajouter une colonne ont une restauration automatique lors de l'utilisation de xml. Pour les fichiers SQL, chaque restauration doit être écrite manuellement.
Conclusion
Chacun choisit lui-même quoi utiliser. Mais notre choix s'est porté sur le côté xml. Des méta-informations détaillées et une transition facile vers d'autres bases de données l'emportent sur les échelles du format sql préféré de tous.