Salut Du titre, vous avez déjà compris de quoi je vais parler. Il y aura beaucoup de hardcore:
nous discuterons de Java, C, C ++, assembleur, un peu de Linux, un peu du noyau du système d'exploitation. Nous analyserons également un cas pratique, donc l'article sera en trois grandes parties (assez volumineuses).
Dans le premier, nous essaierons de tout extraire des profileurs existants.
Dans la deuxième partie, nous allons créer notre propre petit profileur, et dans la troisième, nous verrons comment profiler ce qui n'est pas habituel à profiler, car les outils existants ne sont pas très adaptés à cela. Si vous êtes prêt à suivre cette voie - je vous attends sous la coupe :)
Table des matières
Temps et moyens de compréhension - profileur
Du point de vue quotidien, 1 seconde est très petite. Mais nous savons qu'une seconde équivaut à un milliard de nanosecondes. Et laissez-le prendre environ 4 cycles de processeur en seulement 1 nanoseconde, en 1 seconde, beaucoup de choses sont faites dans l'ordinateur qui peuvent améliorer ou aggraver nos vies.
Supposons que nous développons une application qui en elle-même est suffisamment critique pour accélérer, et pour certains fragments de code, cela est généralement critique. Ces pièces sont exécutées, disons, des centaines de microsecondes - assez rapidement, mais elles [
sections de code ] affectent directement le succès de notre application et le montant d'argent gagné ou perdu. Par exemple
lors de l'envoi d'ordres pour conclure des transactions d'échange, un retard de 100 microsecondes peut coûter à l'échange 1 million de roubles ou plus sur chaque transaction, qui est complétée par un, pas deux, voire même pas cent.
Et la
tâche était fixée pour moi: d'une part, vous devez envoyer toutes les commandes en même temps, et d'autre part, envoyez-les de sorte que l'écart entre la première et la dernière soit minime. Autrement dit, il était nécessaire de profiler une fonction qui envoie des ordres à la bourse. Une tâche typique, à l'exception d'une petite nuance: le temps d'exécution caractéristique de cette fonction est
nettement inférieur à 100 μs .
Réfléchissons à la façon dont nous profilons ces 100 μs afin de comprendre ce qui se passe à l'intérieur.
Que considérer lors du choix de cet outil?
- La section de code qui nous intéresse est rarement exécutée, c'est-à-dire que 100 microsecondes sont exécutées quelque part une fois par seconde. Et c'est dans le banc d'essai, et en production encore moins.
- Ce morceau de code sera difficile à isoler dans la microbenchmark, car il affecte une partie importante du projet, et même des entrées / sorties via le réseau.
- Et enfin, plus important encore, je veux que le profil résultant corresponde au comportement qui sera sur nos serveurs de production.
Comment prendre en compte toutes ces nuances et profiler correctement la méthode d'intérêt?
Conceptuellement, tous les profileurs peuvent être divisés en deux groupes de profileurs
instrumentant ou
échantillonnant . Examinons chaque groupe séparément.
Les profileurs d'outillage apportent beaucoup de frais généraux car ils modifient notre bytecode et y insèrent un enregistrement de temps. D'où l'inconvénient majeur de tels profileurs: ils peuvent affecter de manière significative le code exécutable. Par conséquent, il sera difficile de dire dans quelle mesure le profil résultant correspond au comportement sur les serveurs de production: certaines optimisations peuvent fonctionner différemment, certaines se produisent et d'autres non. Peut-être qu'à d'autres échelles de temps - secondes, minutes, heures - nous obtiendrons des données représentatives. Mais sur une échelle de 100 μs, une optimisation déclenchée ou échouée peut conduire à un profil totalement non représentatif. Examinons donc de plus près un autre groupe de profileurs.
Les profileurs d'échantillonnage contribuent aux frais généraux minimes ou modérés. Ces outils n'affectent pas directement le code exécutable et leur utilisation nécessite un peu plus d'attention de votre part. Par conséquent, nous nous attarderons sur les profileurs de samping. Voyons quelles données et sous quelle forme nous recevrons d'eux.
Comment fonctionnent les profileurs d'échantillonnage?
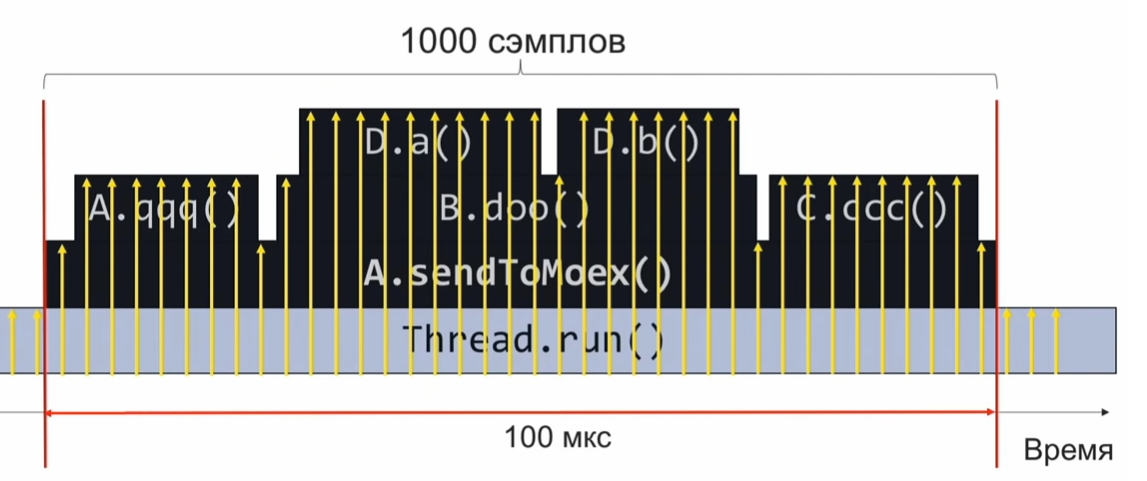
Pour comprendre le fonctionnement du profileur d'échantillonnage, considérons l'exemple suivant: la méthode
sendToMoex appelle plusieurs autres méthodes. Nous regardons:
void sendToMoex() { a.qqq(); b.doo(); c.ccc() } void doo() { da(); db(); }
Si nous surveillons l'état de la pile d'appels au moment de l'exécution de cette section du programme et l'enregistrons périodiquement, nous obtiendrons des informations sur ce formulaire:

Il s'agit d'un ensemble de piles d'appels. En supposant que les échantillons sont répartis uniformément, le nombre de piles identiques indique le temps d'exécution relatif de la méthode qui se trouve au sommet de la pile.
Dans cet exemple, la méthode Da a été exécutée autant que la méthode C.ccc, ce qui est 2 fois plus que la méthode Db. Cependant, l'hypothèse selon laquelle les échantillons sont uniformément répartis peut ne pas être complètement correcte, puis l'estimation du temps d'exécution sera incorrecte.
À quelle fréquence devons-nous échantillonner?
Supposons que nous voulons prélever 1000 échantillons en 100 microsecondes pour comprendre ce qui a été joué à l'intérieur. Ensuite, nous calculons avec une proportion simple que si nous devons faire 1000 échantillons en 100 μs, alors c'est 10 millions d'échantillons en 1 seconde ou 10000000 échantillons / s.
Si nous échantillonnons à cette vitesse, alors dans une exécution du code, nous collecterons 1000 échantillons, agrégerons et comprendrons ce qui a fonctionné rapidement ou lentement. Après cela, nous analyserons les performances et ajusterons le code.
Cependant, une fréquence de 10 millions d'échantillons par seconde est beaucoup. Et si nous n'arrivons pas à atteindre une telle vitesse de profilage dès le début? Supposons que nous ayons collecté pour 10 μs seulement 10 échantillons, pas 1000. Dans ce cas, nous devons attendre la prochaine exécution du code profilé, qui se produira après 1 seconde (après tout, le code profilé est exécuté une fois par seconde). Nous allons donc collecter 10 échantillons supplémentaires. Puisqu'ils sont distribués uniformément avec nous, ils peuvent être combinés en un ensemble commun. Il suffit d'attendre que le code profilé soit exécuté 1000/10 = 100 fois, et nous collecterons les 1000 échantillons requis (10 échantillons chacun de 100 fois).
Choisissez un profileur
Armés de ces connaissances théoriques, passons à la pratique.
Prenez
Async-profiler. Un excellent outil (utilise l'appel de machine virtuelle AsyncGetCallTrace) qui collecte la pile d'appels jusqu'à l'instruction du code d'octet de la machine virtuelle Java. Le taux d'échantillonnage natif async-profiler est de
1000 échantillons par seconde .
Nous allons résoudre une proportion simple: 10 000 000 d'échantillons / sec - 1 seconde, 1000 échantillons / sec - X secondes.
Nous obtenons qu'à la fréquence d'échantillonnage standard de async-profiler, le profilage prendra environ 3 heures. Ça fait longtemps. Idéalement, je veux assembler le profil le plus rapidement possible, juste à la vitesse supraluminale.
Essayons d'overclocker le
profileur Async . Pour ce faire, dans le fichier Lisezmoi, nous trouvons l'indicateur
-i , qui définit l'intervalle d'échantillonnage. Essayons de définir l'indicateur
-i1 (1 nanoseconde), ou
-i0 en général, afin que le profileur échantillonne sans s'arrêter. J'ai obtenu une fréquence d'environ 2,5 mille échantillons par seconde. Dans ce cas, la durée totale du profilage sera d'environ 1 heure. Bien sûr, pas 3 heures, mais aussi pas très vite. Il semble que pour atteindre les vitesses de profilage requises, vous devez faire quelque chose de qualitativement différent, pour atteindre un nouveau niveau.
Pour atteindre des fréquences nettement plus élevées, vous devrez abandonner l'appel AsyncGetCallTrace et utiliser
perf , le profileur Linux à temps plein que l'on trouve dans chaque distribution Linux. Cependant, perf ne sait rien de Java et nous n'avons pas encore formé perf pour travailler avec Java. En attendant, essayons d'exécuter perf de cette façon effrayante:
$ perf record –F 10000 -p PID -g -- sleep 1 [ perf record: Woken up 1 times to write data ] [ perf record: .. 0.215 MB perf.data (4032 samples) ]
En savoir plus sur la notation- record de performance signifie que nous voulons enregistrer un profil.
- L'indicateur
-F et l'argument 10 000 sont le taux d'échantillonnage. - L'indicateur
-p indique que nous voulons profiler uniquement le PID spécifique de notre processus Java. - L'indicateur
-g est responsable de la collecte des piles d'appels. - Enfin, avec sleep 1, nous limitons l'entrée de profil à 1 seconde.
Pourquoi devons-nous collecter des piles d'appels? Nous profilons tout de suite, puis à partir des données collectées, nous extrayons la partie qui nous intéresse (la méthode responsable de la formation et de l'envoi des commandes). Le marqueur d'appartenance de l'échantillon collecté aux données qui nous intéressent est la présence de la trame de pile de l'
appel de méthode
sendToMoex .
Apprenez à créer un profil d'application Java.
Nous exécutons la commande perf record ..., attendons 1 seconde et exécutons le script perf pour voir ce qui a été profilé? Et nous verrons quelque chose de pas très clair:
$ perf script java 8079 2008793.746571: 3745505 cycles:uppp: 7fa1e88b53f8 [unknown] (/tmp/perf-11038.map) java 8079 2008793.747565: 3728336 cycles:uppp: 7fa1e88b5372 [unknown] (/tmp/perf-11038.map) java 8079 2008793.748613: 3731147 cycles:uppp: 7fa1e88b53ef [unknown] (/tmp/perf-11038.map)
Il semble s'agir d'adresses, mais il n'y a pas de noms de méthodes Java. Vous devez donc apprendre à perf à faire correspondre ces adresses avec les noms des méthodes.
Dans le monde du C et du C ++, les informations dites de débogage sont utilisées pour faire correspondre les adresses et les noms de fonction. Une correspondance est stockée dans une section spéciale du fichier exécutable: une méthode se trouve à ces adresses, une autre méthode se trouve à d'autres adresses. Perf récupère ces informations et effectue un mappage.
De toute évidence, le compilateur JIT de la machine virtuelle ne génère pas d'informations de débogage dans ce format. Nous avons encore un autre moyen: écrire des données sur la correspondance des adresses et des noms de méthodes dans un fichier perf-map spécial, que perf traitera comme un ajout aux informations de débogage lues. Ce fichier perf-map doit être dans le dossier tmp et avoir la structure de données suivante:
La première colonne est l'adresse du début du code de méthode, la seconde est sa longueur, la troisième colonne est le nom de la méthode.
Nous devons donc générer un fichier similaire. De toute évidence, nous ne pourrons pas le faire manuellement (comment savoir à quelles adresses le compilateur JIT placera le code), nous utiliserons donc le script create-java-perf-map.sh du projet perf-map-agent, en lui transmettant le PID de notre processus Java . Le fichier est prêt, vérifiez son contenu, réexécutez perf-script.
$ perf script java 8080 1895245.867498: cycles:uppp: 7fb2dd10f527 Loop3.doRecursiveCall (/tmp/perf-8079.map) java 8080 1895245.868176: 2127960 cycles:uppp: 7fb2dd10f57f Loop3.doRecursiveCall (/tmp/perf-8079.map) java 8080 1895245.868737: 1959990 cycles:uppp: 7fb2dd10f627 Loop3.doRecursiveCall (/tmp/perf-8079.map)
Voila! Nous voyons les noms des méthodes java! Ce qui vient de se passer: nous avons appris au profileur de perf, qui ne sait rien de Java, à profiler une application Java régulière et à voir les méthodes java à chaud de cette application!
Cependant, pour analyser les performances de la partie du programme que nous interrogons, nous n'avons pas assez de pile d'appels pour filtrer les données d'intérêt de tous les échantillons collectés.
Comment obtenir une pile d'appels?Vous devez maintenant faire autre chose avec perf ou une machine virtuelle pour obtenir des piles d'appels. Pour comprendre ce qui doit être fait, prenons un peu de recul et voyons comment fonctionne généralement la pile. Imaginez que nous ayons trois fonctions f1, f2, f3. De plus, f1 appelle f2 et f2 appelle f3.
void f1() { f2(); } void f2() { f3(); } void f3() { ... }
Au moment où la fonction
f3 exécutée, voyons dans quel état se trouve la pile. Nous voyons le registre
rsp , qui pointe vers le haut de la pile. Nous savons également que la pile a l'adresse de la trame de pile précédente. Et comment puis-je obtenir une pile d'appels?
Si nous pouvions en quelque sorte obtenir l'adresse de cette zone, alors nous pourrions imaginer la pile comme une liste simplement connectée et comprendre la séquence d'appels qui nous a amenés au point d'exécution actuel.
De quoi avons-nous besoin pour cela? Nous avons besoin d'un registre rbp supplémentaire qui pointera vers la zone jaune. Il s'avère que le registre rbp permet à perf d'obtenir la pile d'appels, de comprendre la séquence qui nous a amenés au point courant. Je recommande de lire ces détails dans l'
interface binaire d'application System V. Il décrit comment les méthodes sont appelées sous Linux.

Nous avons compris quel est notre problème. Nous devons forcer la machine virtuelle à utiliser le registre rbp pour son objectif d'origine - comme pointeur vers le début du cadre de pile. C'est ainsi que le compilateur JIT doit utiliser le registre rbp. Il y a un indicateur PreserveFramePointer dans la machine virtuelle pour cela. Lorsque nous transmettons cet indicateur à la machine virtuelle, la machine virtuelle commencera à utiliser le registre rbp pour son usage traditionnel. Et puis Perf peut faire tourner la pile. Et nous obtenons une vraie pile d'appels dans le profil. Le drapeau a été apporté par le célèbre Brendan Gregg en seulement JDK8u60.
Nous démarrons la machine virtuelle avec un nouveau drapeau. Exécutez
create-java-perf-map , puis
perf record et
perf script . Nous pouvons maintenant créer un profil précis avec des piles d'appels:
$ perf script java 18657 1901247.601878: 979583 cycles:uppp: 7fbfd1101edc Loop3.doRecursiveCall (...) 7fbfd1101edc Loop3.doRecursiveCall (...) 7fbfd1101edc Loop3.doRecursiveCall (...) 7fbfd1101edc Loop3.doRecursiveCall (...) 7f285d007b10 Interpreter (...) 7f285d0004e7 call_stub (...) 67d0db [unknown] (... libjvm.so) ... 708c start_thread (... libpthread-2.26.so)
Nous avons appris à perf profiler, inclus dans la plupart des distributions Linux, à travailler avec les applications Java. Par conséquent, nous pouvons maintenant voir non seulement les sections chaudes du code, mais aussi la séquence d'appels qui a conduit au point chaud actuel. Une grande réussite, étant donné que le profileur de perf ne sait rien de java. Nous venons d'apprendre la perf tout ça!
Augmenter le taux d'échantillonnage de perf
Essayons d'overclocker la perf à 10 millions d'échantillons par seconde. Maintenant, nous avons une fréquence nettement inférieure.
Pour automatiser toutes les tâches que nous venons de faire, vous pouvez utiliser le script
perf-java-record-stack du projet perf-map-agent. Il a un merveilleux stylo - la variable d'environnement
perf_record-freq , avec laquelle vous pouvez régler la fréquence d'échantillonnage. Commençons par définir 100 000 échantillons par seconde et essayons d'exécuter. Un terrible message apparaît dans la console que nous avons dépassé la fréquence d'échantillonnage maximale autorisée:
$ PERF_RECORD_FREQ=100000 ./bin/perf-java-record-stack PID ... Maximum frequency rate (30000) reached. Please use -F freq option with lower value or consider tweaking /proc/sys/kernel/perf_event_max_sample_rate. ...
Dans mon cas, la limite était de 30 000 échantillons par seconde. Perf indique immédiatement quel argument du noyau doit être corrigé, ce que nous ferons soit en utilisant echo sudo tee dans le fichier souhaité, soit directement via
sysctl . Donc:
$ echo '1000000' | sudo tee /proc/sys/kernel/perf_event_max_sample_rate
ou alors:
$ sudo sysctl kernel.perf_event_max_sample_rate=1000000
Maintenant, nous disons au noyau que la limite supérieure de la fréquence est maintenant de 1 million d'échantillons par seconde. Nous redémarrons le profileur et indiquons la fréquence de 200 000 échantillons par seconde. Le profileur fonctionnera pendant 15 secondes et nous donnera 1 million d'échantillons. Tout semble aller bien. Du moins pas de formidables messages d'erreur. Mais quelle fréquence avons-nous réellement obtenue? Il s'avère que seulement 70 000 échantillons par seconde. Qu'est-ce qui a mal tourné?
Voyons la sortie de la
dmesg :
[84430.412898] perf: interrupt took too long (1783 > 200), lowering kernel.perf_event_max_sample_rate to 89700 ... [84431.618452] perf: interrupt took too long (2229 > 2228), lowering kernel.perf_event_max_sample_rate to 71700
Ceci est la sortie du noyau Linux. Il s'est rendu compte que nous échantillonnions trop souvent et que cela prenait trop de temps, donc le noyau abaissait la fréquence. Il s'avère que nous devons dévisser une autre poignée dans le noyau - elle s'appelle
kernel.perf_cpu_time_max_percent et contrôle la quantité de temps que le noyau peut passer sur les interruptions de perf.
Nous commanderons une fréquence d'échantillonnage de 200 000 échantillons par seconde. Et après 15 secondes, nous obtenons 3 millions d'échantillons - 200 000 échantillons par seconde.
$ PERF_RECORD_FREQ=200000 ./bin/perf-java-record-stack PID Recording events for 15 seconds ... ... [ perf record: Captured ... (2.961.252 samples) ]
Voyons maintenant le profil. Exécutez le
perf script :
$ perf script ... java ... native_write_msr (/.../vmlinux) java ... Loop2.main (/tmp/perf-29621.map) java ... native_write_msr (/.../vmlinux) ...
Nous voyons des fonctions étranges et le module exécutable vmlinux - le noyau Linux. Ce n'est certainement pas notre code. Que s'est-il passé? La fréquence s'est avérée si élevée que le code du noyau a commencé à tomber dans les échantillons. Autrement dit, plus nous augmentons la fréquence, plus il y aura d'échantillons qui ne sont pas liés à notre code, mais au noyau Linux.
Impasse.
Nous utilisons (explicitement) des événements matériels PMU / PEBS
J'ai alors décidé d'essayer d'utiliser la technologie matérielle PMU / PEBS - Performance Monitoring Unit, Precise Event Based Sampling. Il vous permet de recevoir des notifications qu'un événement s'est produit un certain nombre de fois. C'est ce qu'on appelle une «période». Par exemple, nous pouvons recevoir des notifications sur l'exécution par le processeur de chaque 20e instruction. Regardons un exemple. Laissez l'instruction xor être exécutée maintenant et le compteur PMU obtiendra la valeur 18; vient ensuite l'instruction mov - le compteur est 19; et l'instruction suivante,
ajouter% r14,% r13 , PMU s'affichera comme «chaud».
Puis un nouveau cycle commence:
inc est exécuté - le PMU est réinitialisé à 1. Quelques itérations supplémentaires du cycle passent. À la fin, nous nous arrêtons à l'instruction
mov , le PMU s'enclenche 19. La prochaine instruction add, et encore une fois, nous la marquons à chaud. Voir la liste:
mov aaa, bbbb xor %rdx, %rdx L_START: mov $0x0(%rbx, %rdx),%r14 add %r14, %r13 ; (PMU "") cmp %rdx,100000000 jne L_START
Ne remarquez pas les bizarreries? Un cycle de cinq instructions, mais à chaque fois nous marquons la même instruction comme chaude. Évidemment, ce n'est pas vrai: toutes les instructions sont «chaudes». Ils passent également du temps, et nous n'en marquons qu'un. Le fait est qu'entre la période et le compteur du nombre d'instructions dans l'itération, nous avons un facteur commun 4. Il s'avère que toutes les quatre itérations, nous marquerons la même instruction comme «chaude». Pour éviter ce comportement, vous devez choisir un nombre comme période pendant laquelle la probabilité d'un diviseur commun entre le nombre d'itérations dans la boucle et le compteur lui-même est minimisée. Idéalement, la période devrait être un premier, c'est-à-dire partager uniquement sur vous-même et sur l'appareil. Pour l'exemple ci-dessus: vous devez choisir une période égale à 23. Ensuite, nous marquerions uniformément toutes les instructions de ce cycle comme «chaudes».
La technologie PMU / PEBS est prise en charge sous sa forme moderne depuis au moins 2009, c'est-à-dire qu'elle est disponible sur presque tous les ordinateurs. Pour l'appliquer explicitement, modifions le script
perf-java-record-stack . Remplacez l'indicateur
-F par
-e , qui spécifie explicitement l'utilisation de PMU / PEBS.
... sudo perf record -F $PERF_RECORD_FREQ ... ...
Transformer le script:
... sudo perf record -e cycles –c 10007 ... ...
Vous savez déjà quelles propriétés une période devrait avoir - nous avons besoin d'un nombre premier. Pour notre cas, ce sera la période 10007.
Nous avons lancé le script perf-java-record-stack modifié et en 15 secondes, nous avons reçu 4,5 millions d'échantillons, soit près de 300 000 par seconde, un échantillon toutes les 3 μs. Autrement dit, pour une exécution de notre code profilé, pour 100 μs, nous collecterons 33 échantillons. À cette fréquence, le temps total de collecte de profil n'est que de 30 secondes. Ne buvez même pas une tasse de café! En réalité, tout est un peu plus compliqué. Que se passe-t-il si notre code commence à s'exécuter non pas une fois par seconde, mais une fois toutes les 5 secondes? Ensuite, la durée du profilage augmentera jusqu'à 2,5 minutes, ce qui est également un résultat assez décent.
Ainsi, en 30 secondes, vous pouvez obtenir un profil qui couvre complètement tous nos besoins de recherche. Victoire
Mais le sentiment d'un sale tour ne m'a pas quitté. Revenons à la situation dans laquelle notre code est exécuté toutes les 5 secondes. Le profilage prendra ensuite 150 secondes, pendant lesquelles nous collecterons environ 45 millions d'échantillons. De ce nombre, nous n'avons besoin que de 1 000, soit 0,002% des données collectées. Tout le reste est des ordures, ce qui ralentit le travail des autres outils et ajoute des frais généraux. Oui, le problème est résolu, mais il est résolu dans le front, la force sale et contondante.
Et ce soir-là, quand j'ai obtenu un profil aussi détaillé avec l'aide de la perf, j'ai fait un rêve. Je rentrais du travail et de la réflexion, mais ce serait bien si le fer pouvait assembler le profil lui-même et même avec la précision des microstructures et des microsecondes, et nous analyserions uniquement les résultats. Mon rêve se réalisera-t-il? Qu'en penses-tu?
Bref résumé:
- Pour créer un profil d'une application Java à l'aide de perf, vous devez générer un fichier contenant des informations sur les symboles à l'aide de scripts du projet perf-map-agent
- Pour collecter des informations non seulement sur les sections chaudes de code, mais également sur les piles, vous devez exécuter une machine virtuelle avec l'indicateur -XX: + PreserveFramePointer
- Si vous souhaitez augmenter la fréquence d'échantillonnage, vous devez faire attention à sysctl'i et kernel.perf_cpu_time_max_percent et kernel.perf_event_max_sample_rate.
- Si des échantillons du noyau qui ne sont pas liés à l'application ont commencé à entrer dans le profil, vous devriez penser à spécifier explicitement la période PMU / PEBS.
Cet article (et ses parties suivantes) est une transcription du rapport, adaptée sous forme de texte. Si vous voulez non seulement lire, mais aussi écouter le profilage, une
référence à la présentation.