Dans les applications mobiles, la fonction de recherche est très populaire. Et si cela peut être négligé dans les petits produits, alors dans les applications qui donnent accès à une grande quantité d'informations, vous ne pouvez pas vous passer d'une recherche. Aujourd'hui, je vais vous dire comment implémenter correctement cette fonction dans les programmes pour Android.

Approches de l'implémentation de la recherche dans une application mobile
- Rechercher comme filtre de données
Habituellement, cela ressemble à une barre de recherche au-dessus d'une liste. Autrement dit, nous filtrons simplement les données finies. - Recherche de serveur
Dans ce cas, nous remettons l'intégralité de l'implémentation au serveur, et l'application agit comme un client léger, à partir duquel il suffit de montrer les données sous la bonne forme. - Recherche intégrée
- l'application contient une grande quantité de données de différents types;
- l'application fonctionne hors ligne;
- La recherche est nécessaire en tant que point d'accès unique aux sections / au contenu de l'application.
Dans ce dernier cas, la recherche en texte intégral intégrée à SQLite vient à la rescousse. Avec lui, vous pouvez trouver très rapidement des correspondances dans une grande quantité d'informations, ce qui nous permet de faire plusieurs requêtes sur différentes tables sans sacrifier les performances.
Envisagez la mise en œuvre d'une telle recherche à l'aide d'un exemple spécifique.
Préparation des données
Disons que nous devons implémenter une application qui affiche une liste de films de
themoviedb.org . Pour simplifier (afin de ne pas aller en ligne), prenez une liste de films et formez-en un fichier JSON, mettez-le dans les actifs et remplissez localement notre base de données.
Exemple de structure de fichier JSON:
[ { "id": 278, "title": " ", "overview": " ..." }, { "id": 238, "title": " ", "overview": " , ..." }, { "id": 424, "title": " ", "overview": " ..." } ]
Remplissage de la base de données
SQLite utilise des tables virtuelles pour implémenter la recherche en texte intégral. Extérieurement, ils ressemblent à des tables SQLite normales, mais tout accès à celles-ci fait un peu de travail dans les coulisses.
Les tables virtuelles nous permettent d'accélérer la recherche. Mais, en plus des avantages, ils présentent également des inconvénients:
- Vous ne pouvez pas créer de déclencheur sur une table virtuelle;
- Vous ne pouvez pas exécuter les commandes ALTER TABLE et ADD COLUMN pour une table virtuelle;
- chaque colonne de la table virtuelle est indexée, ce qui signifie que des ressources peuvent être gaspillées sur des colonnes d'indexation qui ne devraient pas être impliquées dans la recherche.
Pour résoudre ce dernier problème, vous pouvez utiliser des tables supplémentaires qui contiendront une partie des informations et stocker des liens vers des éléments d'une table standard dans une table virtuelle.
La création d'une table est légèrement différente de la norme, nous avons les mots-clés
VIRTUAL et
fts4 :
CREATE VIRTUAL TABLE movies USING fts4(id, title, overview);
Commenter la version fts5Il a déjà été ajouté à SQLite. Cette version est plus productive, plus précise et contient de nombreuses nouvelles fonctionnalités. Mais en raison de la grande fragmentation d'Android, nous ne pouvons pas utiliser fts5 (disponible avec API24) sur tous les appareils. Vous pouvez écrire une logique différente pour différentes versions du système d'exploitation, mais cela compliquera sérieusement le développement et la prise en charge. Nous avons décidé d'aller plus facilement et d'utiliser fts4, qui est pris en charge sur la plupart des appareils.
Le remplissage n'est pas différent de l'habituel:
fun populate(context: Context) { val movies: MutableList<Movie> = mutableListOf() context.assets.open("movies.json").use { val typeToken = object : TypeToken<List<Movie>>() {}.type movies.addAll(Gson().fromJson(InputStreamReader(it), typeToken)) } try { writableDatabase.beginTransaction() movies.forEach { movie -> val values = ContentValues().apply { put("id", movie.id) put("title", movie.title) put("overview", movie.overview) } writableDatabase.insert("movies", null, values) } writableDatabase.setTransactionSuccessful() } finally { writableDatabase.endTransaction() } }
Version de base
Lors de l'exécution de la requête, le mot clé
MATCH est utilisé à la place de
LIKE :
fun firstSearch(searchString: String): List<Movie> { val query = "SELECT * FROM movies WHERE movies MATCH '$searchString'" val cursor = readableDatabase.rawQuery(query, null) val result = mutableListOf<Movie>() cursor?.use { if (!cursor.moveToFirst()) return result while (!cursor.isAfterLast) { val id = cursor.getInt("id") val title = cursor.getString("title") val overview = cursor.getString("overview") result.add(Movie(id, title, overview)) cursor.moveToNext() } } return result }
Pour implémenter le traitement de saisie de texte dans l'interface, nous utiliserons
RxJava :
RxTextView.afterTextChangeEvents(findViewById(R.id.editText)) .debounce(500, TimeUnit.MILLISECONDS) .map { it.editable().toString() } .filter { it.isNotEmpty() && it.length > 2 } .map(dbHelper::firstSearch) .subscribeOn(Schedulers.computation()) .observeOn(AndroidSchedulers.mainThread()) .subscribe(movieAdapter::updateMovies)
Le résultat est une option de recherche de base. Dans le premier élément, le mot souhaité a été trouvé dans la description, et dans le deuxième élément à la fois dans le titre et dans la description. De toute évidence, sous cette forme, ce que nous avons trouvé n'est pas tout à fait clair. Corrigeons-le.
Ajouter des accents
Pour améliorer l'évidence de la recherche, nous utiliserons la fonction auxiliaire
SNIPPET . Il est utilisé pour afficher un fragment de texte formaté dans lequel une correspondance est trouvée.
snippet(movies, '<b>', '</b>', '...', 1, 15)
- films - nom de la table;
- <b & gt et </b> - ces arguments sont utilisés pour mettre en évidence une section de texte qui a été recherchée;
- ... - pour la conception du texte, si le résultat était une valeur incomplète;
- 1 - numéro de colonne du tableau à partir duquel les morceaux de texte seront attribués;
- 15 est un nombre approximatif de mots inclus dans la valeur de texte renvoyée.
Le code est identique au premier, sans compter la demande:
SELECT id, snippet(movies, '<b>', '</b>', '...', 1, 15) title, snippet(movies, '<b>', '</b>', '...', 2, 15) overview FROM movies WHERE movies MATCH ''
Nous réessayons:
Cela s'est avéré plus clairement que dans la version précédente. Mais ce n'est pas la fin. Rendons notre recherche plus "complète". Nous utiliserons l'analyse lexicale et mettrons en évidence les parties importantes de notre requête de recherche.
Amélioration de la finition
SQLite a des jetons intégrés qui vous permettent d'effectuer une analyse lexicale et de transformer la requête de recherche d'origine. Si lors de la création de la table nous n'avons pas spécifié de tokenizer spécifique, alors "simple" sera sélectionné. En fait, il convertit simplement nos données en minuscules et supprime les caractères illisibles. Cela ne nous convient pas.
Pour une amélioration qualitative de la recherche, nous devons utiliser
stemming - le processus de recherche de la base d'un mot pour un mot source donné.
SQLite a un tokenizer intégré supplémentaire qui utilise l'algorithme Porter Stemmer. Cet algorithme applique séquentiellement un certain nombre de certaines règles, mettant en évidence des parties importantes d'un mot en supprimant les terminaisons et les suffixes. Par exemple, lors de la recherche de «clés», nous pouvons obtenir une recherche contenant les mots «clé», «clés» et «clé». Je vais laisser un lien vers une description détaillée de l'algorithme à la fin.
Malheureusement, le tokenizer intégré à SQLite ne fonctionne qu'avec l'anglais, donc pour la langue russe, vous devez écrire votre propre implémentation ou utiliser des développements prêts à l'emploi. Nous prendrons l'implémentation terminée sur le site
algorithmist.ru .
Nous transformons notre requête de recherche sous la forme nécessaire:
- Supprimez les caractères supplémentaires.
- Divisez la phrase en mots.
- Passer à travers le stemmer.
- Collectez dans une requête de recherche.
Algorithme de Porter object Porter { private val PERFECTIVEGROUND = Pattern.compile("((|||||)|((<=[])(||)))$") private val REFLEXIVE = Pattern.compile("([])$") private val ADJECTIVE = Pattern.compile("(|||||||||||||||||||||||||)$") private val PARTICIPLE = Pattern.compile("((||)|((?<=[])(||||)))$") private val VERB = Pattern.compile("((||||||||||||||||||||||||||||)|((?<=[])(||||||||||||||||)))$") private val NOUN = Pattern.compile("(|||||||||||||||||||||||||||||||||||)$") private val RVRE = Pattern.compile("^(.*?[])(.*)$") private val DERIVATIONAL = Pattern.compile(".*[^]+[].*?$") private val DER = Pattern.compile("?$") private val SUPERLATIVE = Pattern.compile("(|)$") private val I = Pattern.compile("$") private val P = Pattern.compile("$") private val NN = Pattern.compile("$") fun stem(words: String): String { var word = words word = word.toLowerCase() word = word.replace('', '') val m = RVRE.matcher(word) if (m.matches()) { val pre = m.group(1) var rv = m.group(2) var temp = PERFECTIVEGROUND.matcher(rv).replaceFirst("") if (temp == rv) { rv = REFLEXIVE.matcher(rv).replaceFirst("") temp = ADJECTIVE.matcher(rv).replaceFirst("") if (temp != rv) { rv = temp rv = PARTICIPLE.matcher(rv).replaceFirst("") } else { temp = VERB.matcher(rv).replaceFirst("") if (temp == rv) { rv = NOUN.matcher(rv).replaceFirst("") } else { rv = temp } } } else { rv = temp } rv = I.matcher(rv).replaceFirst("") if (DERIVATIONAL.matcher(rv).matches()) { rv = DER.matcher(rv).replaceFirst("") } temp = P.matcher(rv).replaceFirst("") if (temp == rv) { rv = SUPERLATIVE.matcher(rv).replaceFirst("") rv = NN.matcher(rv).replaceFirst("") } else { rv = temp } word = pre + rv } return word } }
Algorithme où nous décomposons la phrase en mots val words = searchString .replace("\"(\\[\"]|.*)?\"".toRegex(), " ") .split("[^\\p{Alpha}]+".toRegex()) .filter { it.isNotBlank() } .map(Porter::stem) .filter { it.length > 2 } .joinToString(separator = " OR ", transform = { "$it*" })
Après cette conversion, l'expression «cours et fantômes» ressemble à «yard
* OU fantôme
* ».
Le symbole "
* " signifie que la recherche sera effectuée par l'occurrence d'un mot donné en d'autres termes. L'opérateur "
OU " signifie que les résultats seront affichés qui contiennent au moins un mot de la phrase de recherche. Nous regardons:
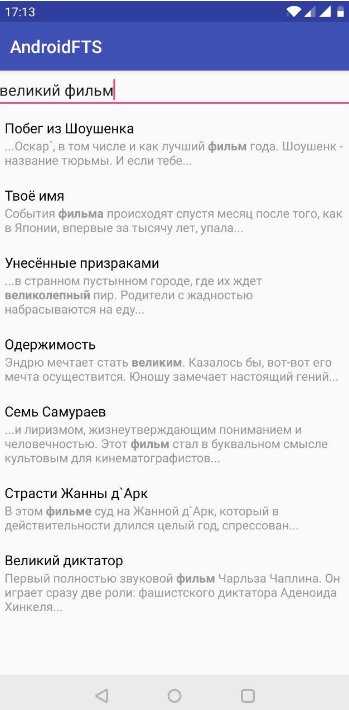
Résumé
La recherche en texte intégral n'est pas aussi compliquée que cela puisse paraître à première vue. Nous avons analysé un exemple spécifique que vous pouvez mettre en œuvre rapidement et facilement dans votre projet. Si vous avez besoin de quelque chose de plus compliqué, alors vous devriez vous tourner vers la documentation, car il y en a une et elle est assez bien écrite.
Références: