
Les applications Deep Learning ont changé beaucoup de choses. Certains qui donnent l'espoir d'un avenir meilleur et d'autres qui suscitent des soupçons. Cependant, pour les développeurs, la croissance des applications d'apprentissage en profondeur les a rendus plus perplexes quant au choix des meilleurs parmi tant de cadres d'apprentissage en profondeur.
TensorFlow est l'un des cadres d'apprentissage profond qui vient à l'esprit. C'est sans doute le cadre d'apprentissage en profondeur le plus populaire sur le marché. Rien ne justifie mieux la déclaration que le fait que Tensorflow est utilisé par des personnes comme Uber, Nvidia, Gmail parmi d'autres grandes sociétés pour développer des applications d'apprentissage en profondeur à la pointe de la technologie.
Mais en ce moment, je suis en quête de savoir s'il s'agit bien du meilleur cadre d'apprentissage en profondeur. Ou peut-être trouver ce qui en fait le meilleur de tous les autres cadres avec lesquels il est en concurrence.
Voici tout sur TensorFlow 2.0
La plupart des développeurs et des scientifiques des données préfèrent utiliser Python avec TensorFlow. TensorFlow fonctionne non seulement sur Windows, Linux et Mac, mais également sur les systèmes d'exploitation iOS et Android.
TF utilise un graphe de calcul statique pour les opérations. Cela signifie que les développeurs définissent d'abord le graphique, exécutent tous les calculs, modifient l'architecture si nécessaire, puis réentraînent le modèle. En général, de nombreux concepts d'apprentissage automatique et d'apprentissage profond peuvent être résolus à l'aide de matrices multidimensionnelles. C'est ce que fait Tensorflow 2.0 qui aide à décrire les relations linéaires entre les objets géométriques. Tenseur est une unité primitive où nous pouvons appliquer des opérations matricielles facilement et efficacement.
import tensorflow as TF const1 = TF.constant([[05,04,03], [05,04,03]]); const2 = TF.constant([[01,02,00], [01,02,00]]); result = TF.subtract(const1, const2); print(result)
La sortie du code ci-dessus ressemblera à ceci: TF.Tensor([[04 02 03] [04 02 03]])
Comme vous pouvez le voir, j'ai donné ici deux constantes et j'ai soustrait une valeur de l'autre et obtenu un objet Tensor en soustrayant deux valeurs. De plus, avec Tensorflow 2.0, il n'est pas nécessaire de créer des sessions avant d'exécuter le code.
Une chose à savoir avant de travailler avec TensorFlow 2.0 est que vous devrez beaucoup coder et que vous n'avez pas seulement besoin d'effectuer des opérations arithmétiques avec TensorFlow. Il s'agit davantage de faire de la recherche en profondeur, de créer des prédicteurs de l'IA, des classificateurs, des modèles génératifs, des réseaux de neurones, etc. Bien sûr, TF aide à ce dernier, mais des tâches importantes telles que la définition de l'architecture du réseau neuronal, la définition d'un volume pour les données de sortie et d'entrée, doivent toutes être effectuées avec une pensée humaine prudente.
Le moyen le plus rapide de former ces modèles d'IA est l'unité de traitement du tenseur (TPU) introduite par Google en 2016. TPU gère le problème de la formation des réseaux de neurones de plusieurs manières.
Quantification - C'est un outil puissant qui utilise un entier de 8 bits pour calculer une prédiction de réseau neuronal. Par exemple, lorsque vous appliquez la quantification à un modèle de reconnaissance d'image comme Inception v3, vous le compresserez d'environ un quart de la taille d'origine de 91 Mo à 23 Mo.
Traitement parallèle - Le traitement parallèle sur le multiplicateur matriciel est un moyen bien connu d'améliorer les performances des opérations matricielles de grande taille grâce au traitement vectoriel. Les machines prenant en charge le traitement vectoriel peuvent traiter jusqu'à des centaines et des milliers d'éléments d'opérations en un seul cycle d'horloge.
CISC - TPU fonctionne sur une conception CISC qui se concentre sur la mise en œuvre d'instructions de haut niveau qui exécutent des tâches de haut niveau telles que la multiplication et l'ajout de nombreuses fois, etc. TPU utilise les ressources suivantes pour effectuer des tâches complexes:
- Matrix Multiplier Unit (MXU): 65 536 unités de multiplication et d'ajout 8 bits pour les opérations matricielles.
- Unified Buffer (UB): 24 Mo de SRAM qui fonctionnent comme des registres.
- Unité d'activation (AU): fonctions d'activation câblées.
Matrice systolique - La matrice systolique est basée sur la nouvelle architecture du MXU qui est également appelée le cœur du TPU. Le MXU a lu la valeur une fois mais l'utilise pour de nombreuses opérations différentes sans la stocker dans un registre. Il réutilise plusieurs fois l'entrée pour produire la sortie. Ce réseau est appelé systolique parce que les données circulent dans la puce par vagues de la même manière que notre cœur pompe le sang. Il améliore la flexibilité opérationnelle dans le codage et offre un taux de densité de fonctionnement beaucoup plus élevé.
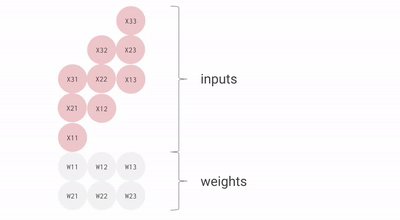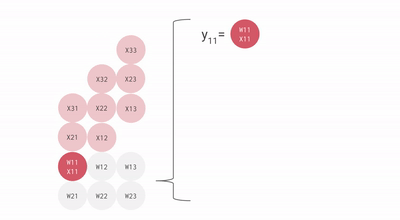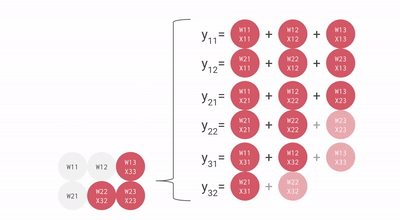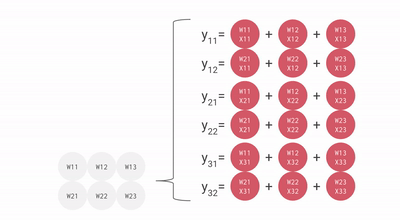
Comme vous pouvez le voir, tous ces points importants du TPU aident à analyser et à gérer efficacement les données. En dehors de cela, il fournit des ensembles de données TensorFlow que les développeurs peuvent utiliser pour la formation de certaines solutions d'IA conçues sur mesure et pour d'autres travaux de recherche.
Toujours selon la dernière mise à jour, Cerebras Systems (une nouvelle société d'intelligence artificielle) dévoile la plus grande puce semi-conductrice basée sur le modèle TPU. Dans cette puce, vous pouvez trouver le plus grand processeur jamais construit conçu pour traiter, former et gérer les applications d'IA. La puce géante est égale à la taille d'un iPad et contient 1,2 trillion de transistors.L'un des plus grands avantages de TensorFlow par rapport aux autres frameworks d'apprentissage en profondeur est en termes d'évolutivité. Contrairement à d'autres frameworks tels que PyTorch, TensorFlow est conçu pour l'inférence à grande échelle et la formation distribuée. Cependant, il peut également être utilisé pour expérimenter de nouveaux modèles d'apprentissage automatique et d'optimisation. Cette flexibilité permet également aux développeurs de déployer des modèles d'apprentissage en profondeur sur plusieurs CPU / GPU avec TensorFlow.
Compatibilité multiplateforme
TensorFlow 2.0 est compatible avec toutes les principales plates-formes de système d'exploitation telles que Windows, Linux, macOS, iOS et Android. De plus, Keras peut également être utilisé avec TensorFlow comme interface.
Évolutivité matérielle
TensorFlow 2.0 est déployable sur une large gamme de machines matérielles, des appareils cellulaires aux ordinateurs à grande échelle avec des configurations complexes. Il peut être déployé sur une gamme de machines matérielles telles que des appareils cellulaires et des ordinateurs avec des configurations complexes. Il peut intégrer différentes API pour construire des architectures d'apprentissage en profondeur à grande échelle telles que CNN ou RNN.
Visualisation
Le framework TensorFlow est basé sur le calcul de graphes et fournit un outil de visualisation pratique à des fins de formation. Cet outil de visualisation, appelé TensorBoard, permet aux développeurs de visualiser la construction d'un réseau de neurones, ce qui facilite à son tour la visualisation et la résolution de problèmes.
Débogage
Tensorflow permet aux utilisateurs d'exécuter les sous-parties d'un graphique pour l'introduction et la récupération de données discrètes en périphérie, fournissant ainsi une méthode de débogage soignée.
Capacité de graphique dynamique pour un déploiement facile
TensorFlow utilise une fonctionnalité appelée «Exécution désireuse» qui facilite la capacité graphique dynamique pour un déploiement facile. Il permet d'enregistrer le graphique en tant que tampon de protocole qui pourrait ensuite être déployé sur quelque chose de différent des infrastructures de relation python, par exemple Java.
Pourquoi TensorFlow continuera de croître?
TensorFlow a le taux de croissance le plus rapide parmi tous les autres cadres d'apprentissage profond qui existent aujourd'hui. Il a l'activité GitHub la plus élevée parmi tous les autres référentiels de la section d'apprentissage en profondeur, ainsi que le plus grand nombre de démarrages.
Dans l'enquête annuelle des développeurs Stack Overflow 2019, TensorFlow a été voté comme le cadre d'apprentissage en profondeur le plus populaire, le deuxième cadre le plus populaire, Torch / PyTorch était très loin.
Ces statistiques suffisent à prouver la domination de TensorFlow. Mais pendant combien de temps va-t-elle soutenir cette croissance? finirait-il par dépasser sa popularité actuelle? Avec l'introduction et la bonne réception de TensorFlow 2.0, ce dernier semble possible.