
Il y a beaucoup d'articles avec un titre similaire, donc j'essaierai d'éviter les sujets courants. J'espère que même un développeur très expérimenté trouvera quelque chose d'utile ici. Cet article ne considérera que des mécanismes et des approches d'optimisation simples qui leur permettront d'être appliqués avec un minimum d'effort. Et ces changements n'augmenteront pas l'entropie de votre code. L'article ne fera pas attention à quoi et quand optimiser, cet article concerne plus l'approche de l'écriture de code en général.
1. ToArray vs ToList
public IEnumerable<string> GetItems() { return _storage.Items.Where(...).ToList(); }
D'accord, un code très typique pour les projets industriels. Mais qu'est-ce qui ne va pas avec lui? L'interface IEnumerable renvoie une collection que vous pouvez «parcourir», cette interface n'implique pas que nous puissions ajouter / supprimer des éléments. Par conséquent, il n'est pas nécessaire de mettre fin à l'expression LINQ en effectuant un transtypage en liste (ToList). Dans ce cas, la conversion en tableau (ToArray) est préférable. Puisque List est un wrapper sur Array, et toutes les fonctionnalités supplémentaires fournies par ce wrapper, nous avons coupé l'interface. Un tableau consomme moins de mémoire et l'accès à ses valeurs est plus rapide. Par conséquent, pourquoi payer plus. D'une part, cette optimisation n'est pas significative, comme on dit «optimisation sur les matchs», mais ce n'est pas tout à fait vrai. Le fait est que dans une application typique dans laquelle les services renvoient des modèles pour la couche de présentation, il peut y avoir une myriade d'appels ToList. Dans l'exemple décrit ci-dessus, l'interface IEnumerable est introduite à des fins d'illustration uniquement. Cette approche est pertinente pour tous les cas où vous devez renvoyer une collection que vous n'allez pas modifier plus tard.
Je prévois un commentaire selon lequel Array et List ne fonctionneront pas de manière équivalente dans le cas d'un accès multi-thread à la collection. Ça l'est vraiment. Mais si vous, en tant que développeur, envisagez la possibilité d'un accès multithread à une telle collection avec la possibilité de la modifier, alors avec un haut degré de probabilité, ni Array ni List ne vous conviendront.
2. Le paramètre «chemin d'accès au fichier» n'est pas toujours le meilleur choix pour votre méthode
Lors du développement d'une API, évitez les signatures de méthode qui reçoivent un chemin de fichier en entrée (pour un traitement ultérieur par votre méthode). Au lieu de cela, donnez la possibilité de passer un tableau d'octets à l'entrée, ou
en dernier recours Stream. Le fait est qu'au fil du temps, votre méthode peut être appliquée non seulement à un fichier du disque, mais aussi à un fichier transféré sur le réseau, à un fichier d'une archive, à un fichier d'une base de données, à un fichier dont le contenu est généré dynamiquement en mémoire, etc. e. En fournissant une méthode avec le paramètre d'entrée "chemin de fichier", vous obligez l'utilisateur de votre API à sauvegarder les données sur le disque avant de les relire. Cette opération sans signification affecte de manière critique les performances. Un lecteur est une chose extrêmement lente. Pour plus de commodité, vous pouvez fournir une méthode avec un paramètre d'entrée "chemin vers un fichier", mais à l'intérieur, utilisez toujours une méthode publique surchargée avec un tableau d'octets ou un flux à l'entrée. Il existe un «marqueur» qui peut aider à trouver des opérations d'écriture / lecture de disque supplémentaires, essayez de trouver dans votre projet en utilisant des méthodes standard:
Path.GetTempPath() et
Path.GetRandomFileName() (de System.IO). Avec un degré de probabilité élevé, vous rencontrerez une solution de contournement du problème ci-dessus ou similaire.
Un lecteur attentif et expérimenté remarquera que dans certains cas, l'écriture sur disque peut, au contraire, améliorer les performances, par exemple si nous avons affaire à des fichiers très volumineux. C'est vrai, il faut en tenir compte, mais je suppose que c'est une situation très rare avec une implémentation spécifique.
3. Évitez d'utiliser des threads comme paramètres et le résultat de retour de vos méthodes
Quel est le problème ici ... lorsque nous obtenons un flux d'une certaine "boîte noire", nous devons garder à l'esprit son état. C'est-à-dire Le flux est-il ouvert? Où est le marqueur de lecture / écriture? Son état peut-il changer quel que soit notre code? Si un flux est déclaré en tant que classe de base de Stream, nous ne disposons même pas d'informations sur les opérations disponibles. Tout cela est résolu par des vérifications supplémentaires, et c'est du code et des coûts supplémentaires. De plus, je suis tombé à plusieurs reprises sur une situation où, lors de la réception de Stream d'une méthode «obscure», le développeur préférait jouer en toute sécurité et «transférer» les données de celui-ci vers un nouveau MemoryStream local complètement contrôlé. Bien que le flux source puisse être assez sûr. Peut-être même que c'était déjà gentiment préparé pour lire MemoryStream. Parfois, il peut atteindre le point d'absurdité - à l'intérieur d'une méthode, un tableau d'octets est placé dans un MemoryStream, puis ce MemoryStream est renvoyé comme résultat d'une méthode déclarée comme un flux de base. À l'extérieur, ce flux se transforme en un nouveau MemoryStream, puis ToArray () renvoie un tableau d'octets, que nous avions à l'origine. Plus précisément, ce sera sa prochaine copie. L'ironie est qu'à l'intérieur et à l'extérieur de notre méthode, le code est complètement correct. À mon avis, cet exemple n'est pas sorti de ma tête, mais a été trouvé quelque part dans le code commercial.
Par conséquent, si vous avez la possibilité d'envoyer / recevoir des données "propres", n'utilisez pas de flux pour cela - ne créez pas de pièges pour ceux qui les utiliseront. Si votre application dispose déjà d'un flux de transfert / retour, analysez leur utilisation en fonction de ce qui précède.
4. Héritage des énumérations
Cette optimisation est courante, tout le monde le sait, même les étudiants. Mais d'après mon expérience, il est extrêmement rarement utilisé. Donc, par défaut, enum hérite de int. Cependant, il peut être hérité de l'octet, qui contient 256 valeurs (ou 8 valeurs «flaggables»). Ce qui couvre presque toujours la fonctionnalité de l'énumération «intermédiaire». Un changement minimal dans le code et toutes les valeurs de votre énumération prennent moins de mémoire pour toujours. Vous trouverez ci-dessous une illustration d'une référence pour remplir une collection avec des valeurs d'énumération héritées de int et byte.
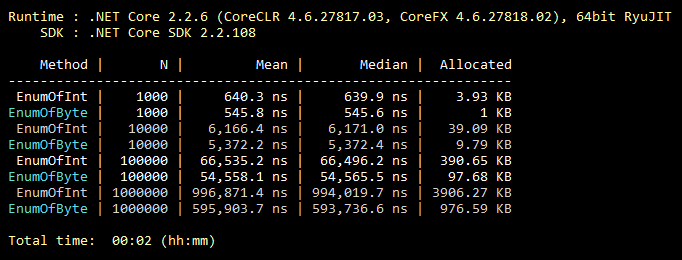
Code de référence public class CollectEnums { [Params(1000, 10000, 100000, 1000000)] public int N; [Benchmark] public EnumFromInt[] EnumOfInt() { EnumFromInt[] results = new EnumFromInt[N]; for (int i = 0; i < N; i++) { results[i] = EnumFromInt.Value1; } return results; } [Benchmark] public EnumFromByte[] EnumOfByte() { EnumFromByte[] results = new EnumFromByte[N]; for (int i = 0; i < N; i++) { results[i] = EnumFromByte.Value1; } return results; } } public enum EnumFromInt { Value1, Value2 } public enum EnumFromByte: byte { Value1, Value2 }
5. Encore quelques mots sur les classes Array et List
Suivant la logique, l'itération sur un tableau est toujours plus efficace que l'itération sur une «feuille», car une «feuille» est un wrapper sur un tableau. En outre, selon la logique, «for» est toujours plus rapide que «foreach», car «foreach» effectue un grand nombre des actions requises par la mise en œuvre de l'interface IEnumerable. Tout est logique ici, mais faux! Jetons un coup d'œil aux résultats de référence:

Code de référence public class IterationBenchmark { private List<int> _list; private int[] _array; [Params(100000, 10000000)] public int N; [GlobalSetup] public void Setup() { const int MIN = 1; const int MAX = 10; Random rnd = new Random(); _list = Enumerable.Repeat(0, N).Select(i => rnd.Next(MIN, MAX)).ToList(); _array = _list.ToArray(); } [Benchmark] public int ForList() { int total = 0; for (int i = 0; i < _list.Count; i++) { total += _list[i]; } return total; } [Benchmark] public int ForeachList() { int total = 0; foreach (int i in _list) { total += i; } return total; } [Benchmark] public int ForeachArray() { int total = 0; foreach (int i in _array) { total += i; } return total; } [Benchmark] public int ForArray() { int total = 0; for (int i = 0; i < _array.Length; i++) { total += _array[i]; } return total; } }
Le fait est que pour itérer sur un tableau, «foreach» n'utilise pas une implémentation IEnumerable. Dans ce cas particulier, l'itération la plus optimisée par index est effectuée, sans vérifier les limites du tableau, car la construction «foreach» ne fonctionne pas avec les index, donc le développeur n'a pas la possibilité de «foirer» le code. Telle est l'exception à la règle. Par conséquent, si dans une section critique du code vous avez remplacé l'utilisation de «foreach» par «for» dans un souci d'optimisation, vous vous êtes tiré une balle dans le pied. Veuillez noter que cela n'est pertinent
que pour les tableaux . Il y a plusieurs branches sur StackOverflow où cette fonctionnalité est discutée.
6. La recherche dans une table de hachage est-elle toujours justifiée?
Tout le monde sait que les tables de hachage sont très efficaces pour la recherche. Mais ils oublient souvent que le prix d'une recherche rapide est un ajout lent à la table de hachage. Qu'est-ce qui en découle? Pour que l'utilisation de la table de hachage soit justifiée, il est nécessaire que le nombre d'éléments de table de hachage soit d'au moins 8 (environ). Et pour que le nombre d'opérations de recherche soit au moins d'un ordre de grandeur supérieur au nombre d'opérations d'ajout. Sinon, utilisez une collection plus simple. La qualité de la fonction de hachage fera ses propres ajustements à l'efficacité, mais la signification de cela ne changera pas. Dans ma pratique, il y avait un cas où le plus de goulot d'étranglement dans le code chargé appelait la méthode Dictionary.Add (). La clé était une chaîne régulière, de courte longueur. Se souvenir de cela et est devenu un déclencheur pour écrire ce paragraphe. Pour illustrer, un exemple de très mauvais code:
private static int GetNumber(string numberStr) { Dictionary<string, int> dictionary = new Dictionary<string, int> { {"One", 1}, {"Two", 2}, {"Three", 3} }; dictionary.TryGetValue(numberStr, out int result); return result; }
Peut-être que quelque chose de similaire se produit dans votre projet?
7. Méthodes d'intégration
Le code est divisé en méthodes le plus souvent pour 2 raisons. Assurez la réutilisation et la décomposition du code lorsqu'une tâche est divisée en plusieurs sous-tâches. C’est plus facile pour une personne. L'intégration est le processus inverse de décomposition, c'est-à-dire le code de la méthode est incorporé à l'endroit où la méthode doit être appelée; en conséquence, nous économisons sur la pile d'appels et en passant les paramètres. Je ne recommande en aucun cas de tout mettre dans une seule méthode. Mais ces méthodes que nous pourrions théoriquement «inline» peuvent être marquées avec l'attribut correspondant:
[MethodImpl(MethodImplOptions.AggressiveInlining)]
Cet attribut indiquera au système que cette méthode peut être intégrée. Cela ne signifie pas que la méthode marquée avec cet attribut sera nécessairement intégrée. Par exemple, il n'est pas possible d'incorporer des méthodes récursives ou virtuelles. Il convient également de noter que le mécanisme d'ancrage est extrêmement «délicat». Il existe de nombreuses autres raisons pour lesquelles le système refusera d'intégrer votre méthode. Cependant, l'équipe Microsoft travaillant sur .NET Core utilise activement cet attribut. Le code source de .NET Core contient de nombreux exemples de son utilisation.
8. Capacité estimée
J'ai (et j'espère que la plupart des développeurs aussi) ai développé un réflexe: j'ai initialisé la collection - je me suis demandé s'il était possible de définir Capacity pour cela. Cependant, le nombre exact d'éléments de collection n'est pas toujours connu à l'avance. Mais ce n'est pas une raison pour ignorer ce paramètre. Par exemple, si, en parlant du nombre d'articles qui seront dans votre collection, vous supposez un «couple de milliers» flou, c'est l'occasion de définir la capacité à 1000. Une petite théorie, par exemple, pour Liste par défaut, Capacité = 16, de sorte que seulement atteindre 1000, le système fera 1008 (16 + 32 + 64 + 128 + 256 + 512) copies supplémentaires des éléments et créera 7 tableaux temporaires à la merci du prochain appel GC. C'est-à-dire tout ce travail sera gaspillé. De plus, en tant que Capacité, personne n'interdit d'utiliser la formule. Si la taille de votre collection est estimée à un tiers de l'autre collection, vous pouvez définir une capacité égale à otherCollection.Count / 3. Lorsque vous définissez la capacité, il est bon de comprendre la plage de la taille possible de la collection et le degré de distribution de sa valeur. Il y a toujours un risque de dommage, mais s'il est utilisé correctement, une capacité estimée vous donnera une bonne victoire.
9. Spécifiez toujours votre code.
Utilisez activement (à première vue, facultatif) des mots clés C #, tels que: statique, const, en lecture seule, scellé, abstrait, etc. Naturellement, là où ils ont du sens. Et voici la performance? Le fait est que plus vous décrivez votre système au compilateur, plus le code qu'il peut générer est optimal. Un lecteur attentif et expérimenté peut remarquer que, par exemple, le mot clé scellé n'a aucun effet sur les performances. Maintenant, c'est vrai, mais dans les versions futures, tout peut changer. Donnez une chance au compilateur et à la machine virtuelle! Obtenez un bonus, identifiant de nombreuses erreurs d'utilisation incorrecte de votre code au stade de la compilation. Règle générale: plus le système est décrit clairement, plus le résultat est optimal. Apparemment, avec des gens aussi.
La vraie histoire confirme cette règle, mais si vous lisez la paresse, vous pouvez sauterUne nuit, alors qu'il était engagé dans son
projet de passe-temps , il s'est donné pour tâche d'augmenter les performances d'une section de code au-dessus d'un certain niveau. Mais ce site était court et il y avait peu d'options pour en faire quoi. J'ai trouvé dans la documentation qu'à partir de la version C # 7.2, le mot-clé "readonly" peut être utilisé pour les structures. Et dans mon cas, des structures immuables ont été utilisées, en ajoutant un seul mot «en lecture seule», j'ai obtenu ce que je voulais, même avec une marge! Le système, sachant que mes structures ne sont pas destinées à être modifiées, a pu générer un meilleur code pour mon cas.
10. Si possible, utilisez une version de .NET pour tous les projets de solution
Vous devez vous assurer que tous les assemblys de votre application appartiennent à la même version de .NET. Cela s'applique aux packages NuGet (modifiés dans packages.config / json) et à vos propres assemblys (modifiés dans les propriétés du projet). Cela permettra d'économiser de la RAM et d'accélérer le démarrage "à froid", car dans la mémoire de votre application, il n'y aura pas de copies des mêmes bibliothèques pour différentes versions de .NET. Il convient de noter que dans tous les cas, différentes versions de .NET génèrent des copies en mémoire. Mais supposons qu'une application construite sur la même version de .NET soit toujours meilleure. En outre, cela élimine un certain nombre de problèmes potentiels qui n'entrent pas dans le cadre de cet article. La consolidation des versions de tous les packages NuGet que vous utilisez contribuera également à améliorer les performances de votre application.
Quelques outils utiles
ILSpy est un outil gratuit qui vous permet de visualiser le code source de l'assembly restauré. Si j'ai une question sur le mécanisme .NET le plus efficace, j'ouvre d'abord ILSpy (et non Google ou StackOverflow), et déjà là, je vois comment il est mis en œuvre. Par exemple, pour savoir ce qui est le mieux utilisé en termes de performances pour recevoir des données sur HTTP, la classe HttpWebRequest ou WebClient, il suffit de regarder leur implémentation via ILSpy. Dans ce cas particulier, WebClient est un wrapper sur HttpWebRequest, respectivement, la réponse est évidente. Les codes source .NET ne valent pas la peine, ils sont écrits par les mêmes programmeurs ordinaires.
BenchmarkDotNet est une bibliothèque gratuite de benchmarks. Il existe un chronomètre simple et intuitif (de System.Diagnostics). Mais parfois, cela ne suffit pas. Comme dans le bon sens il faut prendre en compte non pas un seul résultat, mais la moyenne de plusieurs comparaisons, il vaut mieux comparer leur médiane afin de minimiser l'influence de l'OS. En outre, vous devez prendre en compte le "démarrage à froid" et la quantité de mémoire allouée. Pour ces tests complexes, BenchmarkDotNet a été créé. C'est cette bibliothèque que les développeurs .NET Core utilisent dans les tests officiels. La bibliothèque est facile à utiliser, mais si ses auteurs lisent soudainement cet article, donnez-leur une opportunité plus pratique d'influencer la structure du tableau des résultats.
U2U Consult Performance Analyzers est un plug-in gratuit pour Visual Studio qui fournit des conseils sur l'amélioration du code en termes de performances. 100% se fier aux conseils de cet analyseur n'en vaut pas la peine. Depuis que je suis tombé sur une situation où un conseil m'a un peu surpris et après une analyse détaillée, il s'est avéré vraiment erroné. Malheureusement, cet exemple est perdu, alors prenez un mot. Cependant, si vous l'utilisez judicieusement, c'est un outil très utile. Par exemple, il suggérera qu'au lieu de
myStr.Replace("*", "-") plus efficace d'utiliser
myStr.Replace('*', '-') . Et les deux expressions Where dans LINQ sont mieux combinées en une seule. Ce sont tous des «optimisations sur les correspondances», mais elles sont faciles à appliquer et n'entraînent pas une augmentation du code / de la complexité.
En conclusion
Si chaque 10e personne qui lit l'article applique les approches ci-dessus à son projet actuel (ou une partie critique de celui-ci), et adhère également à ces approches à l'avenir, alors ensemble, nous pouvons sauver toute la forêt! Forêt ??? C'est-à-dire les ressources économisées des systèmes informatiques, sous forme d'électricité obtenue à partir de la combustion du bois, resteront inutilisées. Dans ce cas, la «forêt» n'est qu'une sorte d'équivalent. Une conclusion étrange est probablement sortie, mais j'espère que cette pensée vous a inspiré.
Mise à jour PS basée sur les commentaires de publication
L'avantage de ToArray sur ToList est pertinent pour .NET Core. Mais si vous utilisez l'ancien .NET Framework, ToList sera probablement préférable pour vous. Le problème est que dans le .NET Framework, l'appel ToArray lui-même est beaucoup plus lent que l'appel ToList. Et ces pertes peuvent ne pas être compensées par des accès plus rapides aux éléments et moins de stockage en baie. En général, ce problème s'est avéré plus compliqué, car différentes classes implémentant IEnumerable peuvent avoir différentes implémentations de ToArray et ToList, avec différents niveaux d'efficacité.
Si l'énumération héritée de l'octet est utilisée en tant que membre d'une classe (structure), et non séparément, il peut ne pas y avoir d'économie de mémoire. En raison de l'alignement de la mémoire occupée de tous les membres de la classe (structure). Ce point manque dans l'article. Néanmoins, le gain potentiel est meilleur que son absence, car en plus de la mémoire occupée, des énumérations sont également utilisées. Par conséquent, le paragraphe 4 est toujours pertinent, mais avec cette importante réserve.
Merci à
KvanTTT et
epetrukhin pour leurs commentaires constructifs sur ces questions.
En outre, comme
Taritsyn l'a noté, l'optimisation au stade de la compilation JIT pour le mot clé "scellé" existe toujours. Mais cela ne fait que confirmer toutes les thèses du 9ème paragraphe.
Il semble que tous les commentaires constructifs aient été pris en compte. Je suis très satisfait de ces commentaires. Depuis que moi-même, en tant qu'auteur, j'ai reçu un retour et j'ai aussi appris quelque chose de nouveau pour moi.