Salut, Habr.
Cet article est une suite logique du classement des
articles de Best Habr pour 2018 . Et bien que l'année ne soit pas encore terminée, mais comme vous le savez, en été, il y a eu des changements dans les règles, en conséquence, il est devenu intéressant de voir si cela affectait quoi que ce soit.

En plus des statistiques elles-mêmes, une note actualisée des articles sera donnée, ainsi que quelques codes sources pour ceux qui sont intéressés par la façon dont cela fonctionne.
Pour ceux qui sont intéressés par ce qui s'est passé, a continué sous la coupe. Ceux qui sont intéressés par une analyse plus détaillée des sections du site peuvent également voir la
partie suivante .
Données source
Cette note n'est pas officielle et je n'ai aucune donnée privilégiée. Comme il est facile de voir, après avoir regardé dans la barre d'adresse du navigateur, tous les articles sur Habré ont une numérotation de bout en bout. Ensuite, c'est une question technique, nous venons de lire tous les articles d'affilée dans un cycle (dans un fil et avec des pauses afin de ne pas charger le serveur). Les valeurs elles-mêmes ont été obtenues par un simple analyseur en Python (le code source est
ici ) et stockées dans un fichier csv d'environ ce type:
2019-08-11T22:36Z,https://habr.com/ru/post/463197/,"Blazor + MVVM = Silverlight , ",votes:11,votesplus:17,votesmin:6,bookmarks:40,views:5300,comments:73
2019-08-11T05:26Z,https://habr.com/ru/news/t/463199/," NASA ",votes:15,votesplus:15,votesmin:0,bookmarks:2,views:1700,comments:7Traitement
Pour l'analyse, nous utiliserons Python, Pandas et Matplotlib. Ceux qui ne sont pas intéressés par les statistiques peuvent sauter cette partie et accéder immédiatement aux articles.
Vous devez d'abord charger l'ensemble de données en mémoire et sélectionner les données pour l'année souhaitée.
import pandas as pd import datetime import matplotlib.dates as mdates from matplotlib.ticker import FormatStrFormatter from pandas.plotting import register_matplotlib_converters df = pd.read_csv("habr.csv", sep=',', encoding='utf-8', error_bad_lines=True, quotechar='"', comment='#') dates = pd.to_datetime(df['datetime'], format='%Y-%m-%dT%H:%MZ') df['datetime'] = dates year = 2019 df = df[(df['datetime'] >= pd.Timestamp(datetime.date(year, 1, 1))) & (df['datetime'] < pd.Timestamp(datetime.date(year+1, 1, 1)))] print(df.shape)
Il s'avère que pour cette année (bien qu'elle ne soit pas encore terminée) au moment de la rédaction, 12715 articles ont été publiés. À titre de comparaison, pour l'ensemble de 2018 - 15904. En général, beaucoup - c'est environ 43 articles par jour (et ce n'est qu'avec une note positive, combien d'articles téléchargés sont négatifs ou supprimés, vous ne pouvez que deviner ou comprendre approximativement les omissions parmi identifiants).
Sélectionnez les champs nécessaires dans l'ensemble de données. Comme métriques, nous utiliserons le nombre de vues, de commentaires, de valeurs de notation et le nombre de signets ajoutés.
def to_float(s):
Maintenant, les données ont été ajoutées à l'ensemble de données et nous pouvons les utiliser. Regroupez les données par jour et prenez les valeurs moyennes.
g = df.groupby(['date']) days_count = g.size().reset_index(name='counts') year_days = days_count['date'].values grouped = g.median().reset_index() grouped['counts'] = days_count['counts'] counts_per_day = grouped['counts'].values counts_per_day_avg = grouped['counts'].rolling(window=20).mean() view_per_day = grouped['views'].values view_per_day_avg = grouped['views'].rolling(window=20).mean() votes_per_day = grouped['votes'].values votes_per_day_avg = grouped['votes'].rolling(window=20).mean() bookmarks_per_day = grouped['bookmarks'].values bookmarks_per_day_avg = grouped['bookmarks'].rolling(window=20).mean()
Maintenant, pour la partie amusante, nous pouvons regarder les graphiques.
Voyons le nombre de publications sur Habré en 2019.
import matplotlib.pyplot as plt plt.rcParams["figure.figsize"] = (16, 8) fig, ax = plt.subplots() plt.bar(year_days, counts_per_day, label='Articles/day') plt.plot(year_days, counts_per_day_avg, 'g-', label='Articles avg/day') plt.xticks(rotation=45) ax.xaxis.set_major_formatter(mdates.DateFormatter("%d-%m-%Y")) ax.xaxis.set_major_locator(mdates.MonthLocator(interval=1)) plt.legend(loc='best') plt.tight_layout() plt.show()
Le résultat est intéressant. Comme vous pouvez le constater, Habr a légèrement «saucisse» au cours de l'année. Je ne connais pas la raison.

À titre de comparaison, 2018 semble un peu plus "fluide":

En général, je n'ai pas vu de baisse drastique du nombre d'articles publiés en 2019 sur le graphique. De plus, au contraire, il semble même avoir légèrement augmenté depuis l'été.
Mais les deux graphiques suivants me dépriment un peu plus.
Vues moyennes par article:

Note moyenne par article:
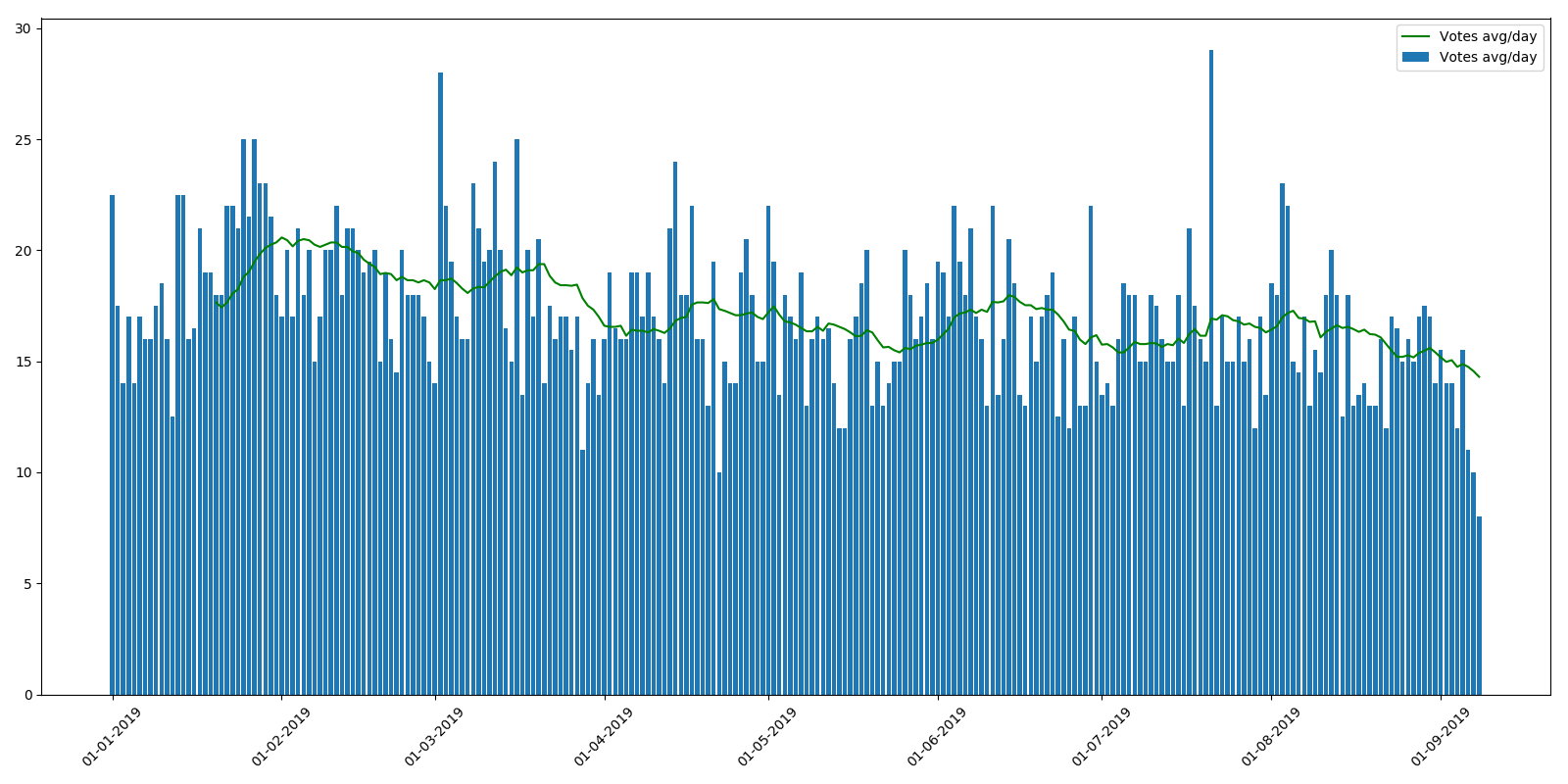
Comme vous pouvez le voir, le nombre moyen de vues au cours de l'année est légèrement réduit. Cela peut s'expliquer par le fait que les nouveaux articles n'ont pas encore été indexés par les moteurs de recherche et qu'ils ne sont pas trouvés si souvent. Mais la baisse de la note moyenne par article est plus incompréhensible. Le sentiment est que les lecteurs n'ont tout simplement pas le temps de parcourir autant d'articles ou ne prêtent pas attention aux notes. Du point de vue du programme de récompense des auteurs, cette tendance est très désagréable.
Soit dit en passant, ce n'était pas le cas en 2018, et le calendrier est plus ou moins uniforme.
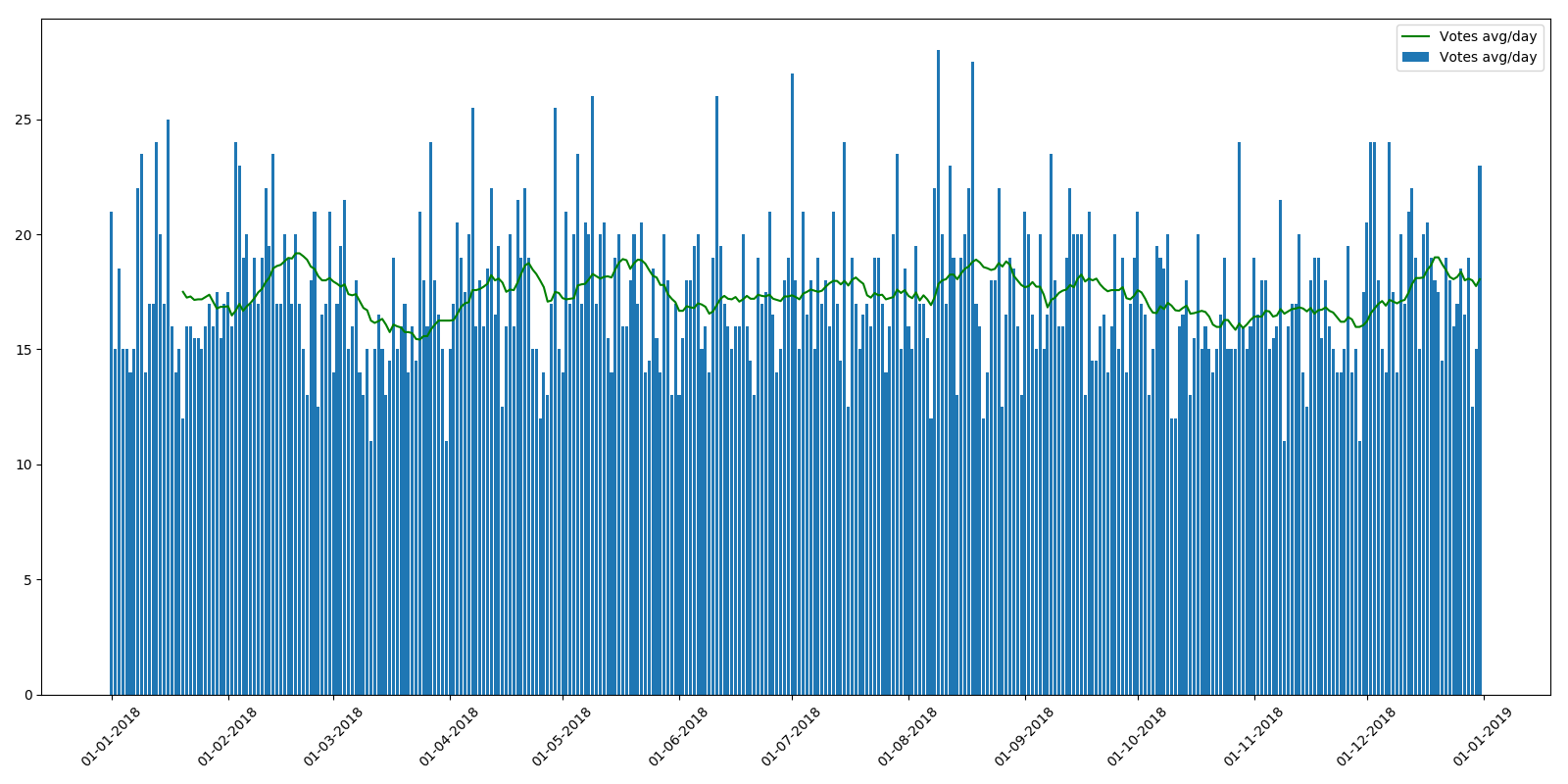
En général, les propriétaires de ressources ont quelque chose à penser.
Mais ne parlons pas de tristes choses. En général, on peut dire que Habr a "survécu" aux changements estivaux avec assez de succès, et le nombre d'articles sur le site n'a pas diminué.
Évaluation
Maintenant, en fait, la cote. Félicitations à ceux qui l'ont frappé. Je vous rappelle encore une fois que la note n'est pas officielle, peut-être que j'ai raté quelque chose, et si un article devrait certainement être ici, mais ce n'est pas le cas, écrivez, je vais l'ajouter manuellement En tant que note, j'utilise des mesures calculées, qui, il me semble, se sont révélées assez intéressantes.
Articles les plus consultés- Des mensonges LED aux proportions sans précédent 241 000 vues, 569 commentaires, note + 364,0 / -1,0
- «Article de fellation»: des scientifiques ont traité 109 heures de sexe oral pour développer une IA qui suce un membre 236 000 vues, 361 commentaires, note + 240,0 / -68,0
- Ce que le créateur a fumé: une arme à feu inhabituelle 235 000 vues, 123 commentaires, note + 119,0 / -9,0
- Comment je n'ai pas travaillé pendant un an chez Sberbank 233 000 vues, 580 commentaires, note + 449,0 / -14,0
- Les scientifiques ont trouvé le plus vieux vertébré vivant sur Terre 221000 vues, 211 commentaires, note + 82,0 / -14,0
- Les ampoules intelligentes jetées à la poubelle sont une précieuse source d'informations personnelles 219 000 vues, 147 commentaires, note + 73,0 / -11,0
- Development King 178 000 vues, 668 commentaires, note + 315,0 / -60,0
- Fraudsters et EDS - tout va très mal 175 000 vues, 778 commentaires, note + 356,0 / -0,0
- La série 'Tchernobyl': regardez et pensez 172 000 vues, 803 commentaires, note + 164,0 / -25,0
- Le pire contrôle du volume sonore de l'interface utilisateur 166 000 vues, 176 commentaires, note + 292,0 / -30,0
- Un CV honnête d'un programmeur 165 000 vues, 283 commentaires, note + 410,0 / -40,0
- Je ruine la vie des développeurs avec mes critiques de code et je suis désolé 164 000 vues, 12 commentaires, note + 33,0 / -3,0
- Comment Megafon a dormi sur les abonnements mobiles 162 000 vues, 676 commentaires, note + 624,0 / -2,0
- Émeute sur le Picaba. Les utilisateurs vont à Reddit en masse 160 000 vues, 484 commentaires, note + 215,0 / -41,0
- Piles AAA bon marché et chères 159 000 vues, 382 commentaires, note + 363,0 / -6,0
- Retired at 22,156,000 views, 922 comments, rating + 259.0 / -100.0
- Homme sans smartphone 152000 vues, 736 commentaires, note + 173,0 / -25,0
- Vous voulez des LED éternelles? Découvrez les fers à souder et les fichiers. Ou éclairage maison fait maison 149 000 vues, 262 commentaires, note + 94,0 / -6,0
- Ce que vous n'avez pas besoin de faire si votre téléphone est volé 144 000 vues, 638 commentaires, note + 259,0 / -27,0
- 1 février 2019 votre site pourrait cesser de fonctionner 143,000 vues, 162 commentaires, rating + 89.0 / -8.0
Principaux articles sur le rapport entre les notes et les vues- Affaiblir les noix, partie 2: la durée du vote pour les publications et autres changements est de 14 000 vues, note + 238,0 / -3,0
- Des débuts assez fantaisistes d'Euclide dans le TeX-e 10,800 vues, note + 136,0 / -0,0
- Récompense utilisateur aux auteurs de Habr 26400 vues, note + 320.0 / -0.0
- Envoi de messages d'erreur d'impression dans les publications 18 900 vues, note + 179,0 / -2,0
- Bonjour tout le monde! Ou Habr en anglais, v1.0 21,000 vues, note + 178.0 / -2.0
- Vie sur les particules 34 000 vues, note + 267,0 / -2,0
- Civilization of Springs, 5/5 25800 vues, note + 201.0 / -1.0
- On joue à Tetris sur l'écran électromécanique 16300 vues, note + 124.0 / -0.0
- Recréation de polices à partir d'un écran CRT 13 400 vues, note + 101,0 / -0,0
- Le modèle mathématique du jeu est Dobble 14600 vues, note + 110,0 / -0,0
- Un message important sur les invitations dans le profil est 18300 vues, note + 137.0 / -8.0
- Affaiblir les noix dans les règles du Habr 48300 vues, note + 338.0 / -13.0
- Comparaison des codecs magiques de rue. Nous dévoilons les secrets de 21700 vues, note + 144,0 / -0,0
- Analyseur intelligent pour les nombres enregistrés en mots 20 500 vues, note + 136,0 / -1,0
- Modèles génériques et de métaprogrammation: Go, Rust, Swift, D et autres 17000 vues, note + 110,0 / -2,0
- Je crée une base de connaissances globale sur les batteries 22 200 vues, note + 139,0 / -0,0
- Comme j'ai écrit et publié un livre sur l'Université d'État de Moscou, ou 12 erreurs critiques, 21 600 vues, note + 134,0 / -0,0
- À propos de Kote, de sa femme, de ses deux fils, de l'idée ... et pas seulement. Une histoire avec une continuation de 43 000 vues, note + 269,0 / -8,0
- Vidéo calculée en 755 mégapixels: plénoptique hier, aujourd'hui et demain 41 500 vues, note + 244,0 / -0,0
- La densité de la parcelle dans la vente au détail 27 500 vues, note + 160,0 / -1,0
Principaux articles sur le rapport des commentaires aux vues- Github a commencé à bloquer les référentiels d'utilisateurs de Crimée, Cuba, Iran, Corée du Nord et Syrie 44 500 vues, 1 309 commentaires, note + 115,0 / -6,0
- Cours d'ukrainien 60400 vues, 1672 commentaires, rating + 285.0 / -41.0
- Affaiblir les noix dans les règles Habr 48300 vues, 1285 commentaires, note + 338.0 / -13.0
- Le rassemblement contre l'isolement de Runet 50 900 vues, 923 commentaires, note + 204,0 / -32,0
- Comment rouler sur deux roues pour travailler 47100 vues, 781 commentaires, note + 113,0 / -10,0
- Crash d'un avion à Sheremetyevo: analogies historiques 82 400 vues, 1211 commentaires, note + 147,0 / -11,0
- Les ingénieurs sauvent les personnes perdues dans la forêt, mais la forêt ne s'est pas encore rendue 28 900 vues, 423 commentaires, note + 132,0 / -1,0
- Rassemblement contre l'isolement du Runet 63 300 vues, 820 commentaires, note + 182,0 / -20,0
- Comment la protection des enfants contre les informations est organisée - et l'histoire enchanteresse sur l'origine (18+) 65 400 vues, 811 commentaires, note + 175,0 / -2,0
- Bonjour tout le monde! Ou Habr en anglais, v1.0 21 000 vues, 249 commentaires, note + 178,0 / -2,0
- Comment acheter des pommes de terre correctement si vous êtes daltonien 51,800 vues, 607 commentaires, note + 135,0 / -3,0
- Comment on se sent d'être un mainteneur de logiciels libres 22 900 vues, 259 commentaires, note + 129,0 / -3,0
- Affaiblir les noix, partie 2: période de vote pour les publications et autres changements 14000 vues, 158 commentaires, note + 238,0 / -3,0
- Production pilote d'électronique pour un prix minimum de 34 200 vues, 382 commentaires, note + 165,0 / -3,0
- Comment équiper le mégaphone 39800 vues, 405 commentaires, note + 140.0 / -6.0
- Des guerres nucléaires d'un passé lointain? 83,400 vues, 843 commentaires, note + 133,0 / -5,0
- Bonjour tout le monde! Ou Habr anglophone, v1.0 60 300 vues, 591 commentaires, note + 268,0 / -7,0
- L'espace comme un vague souvenir 43200 vues, 402 commentaires, note + 190,0 / -7,0
- Récompense utilisateur aux auteurs de Habr 26,400 vues, 245 commentaires, rating + 320.0 / -0.0
- Les principes du marché libre dans la compréhension des États-Unis 56 300 vues, 502 commentaires, note + 160,0 / -44,0
Articles les plus controversés- State and T-killers 752 commentaires, note + 83.0 / -80.0, 15100 vues
- Ces mecs toxiques: ils empoisonnent des projets 120 commentaires, note + 67,0 / -51,0, 50300 vues
- Pourquoi enseignez-vous Go 70 commentaires, note + 76,0 / -57,0, 23100 vues
- J'ai lu 80 CV, j'ai des questions 635 commentaires, note + 135,0 / -94,0, 90700 vues
- Pourquoi il est en fait impossible d'être végétarien 940 commentaires, note + 76,0 / -52,0, 51 600 vues
- Programmation fonctionnelle: un jouet farfelu qui tue la productivité du travail. Partie 1394 commentaires, note + 100,0 / -68,0, 54000 vues
- Nous avons écrit le code le plus utile de notre vie, mais nous l'avons jeté à la poubelle. Avec nous 259 commentaires, note + 101,0 / -63,0, 62900 vues
- Appel dans Apple 96 commentaires, note + 90,0 / -52,0, 39300 vues
- Pourquoi Windows ne pilote-t-il pas en 2019 ou CHYDNT? 881 commentaires, note + 123,0 / -70,0, 75000 vues
- Je ne suis pas réel 246 commentaires, note + 105,0 / -59,0, 63900 vues
- Cinq tendances effrayantes du développement moderne 262 commentaires, note + 95,0 / -52,0, 77400 vues
- Plus vite vous oubliez la POO, mieux c'est pour vous et vos programmes 1271 commentaires, note + 131,0 / -63,0, 128000 vues
- Un an derrière le volant d'un véhicule électrique 1098 commentaires, note + 131.0 / -58.0, 71800 vues
- Je vais arrêter de donner de bons coups pour lancer 179 commentaires, note + 147,0 / -62,0, 34 400 vues
- Catch me if you can 215 commentaires, rating + 141.0 / -58.0, 65,400 views
- Retired at 22,922 comments, rating + 259.0 / -100.0, 156,000 views
- Réponse du psychiatre à l'article «Malade et santé» 272 commentaires, note + 154,0 / -55,0, 43 400 vues
- De nouveaux langages de programmation tuent imperceptiblement notre connexion avec la réalité 764 commentaires, note + 164,0 / -52,0, 106 000 vues
- Alcoolisme de dernière étape 597 commentaires, note + 208,0 / -60,0, 123 000 vues
- 'Article de fellation': des scientifiques ont traité 109 heures de sexe oral pour développer une IA qui suce un membre 361 commentaires, note + 240,0 / -68,0, 236 000 vues
Articles les mieux notés- Comment Megafon a dormi sur les abonnements mobiles , 676 commentaires, note + 624,0 / -2,0, 162 000 vues
- «Contenu mobile» gratuitement, sans SMS et inscriptions. Détails sur la fraude au mégaphone , 474 commentaires, note + 488,0 / -8,0, 112 000 vues
- Innovations en russe , 612 commentaires, note + 480,0 / -33,0, 127 000 vues
- Comment je n'ai pas travaillé pendant un an à Sberbank , 580 commentaires, note + 449,0 / -14,0, 233 000 vues
- Comment Protonmail est bloqué en Russie , 398 commentaires, note + 418,0 / -7,0, 102 000 vues
- 10 ans en informatique avec un diagnostic de schizophrénie, conseils de survie , 281 commentaires, note + 403,0 / -8,0, 122 000 vues
- Un CV honnête d'un programmeur , 283 commentaires, note + 410,0 / -40,0, 165 000 vues
- Lorsque «a» n'est pas égal à «a». Dans le sillage d'un hack , 64 commentaires, note + 374,0 / -5,0, 74 600 vues
- Augmentez-le! Augmentation de la résolution moderne , 214 commentaires, note + 366,0 / -1,0, 104000 vues
- Les mensonges LED aux proportions sans précédent , 569 commentaires, note + 364,0 / -1,0, 241 000 vues
- Piles AAA bon marché et chères , 382 commentaires, note + 363,0 / -6,0, 159 000 vues
- Fraudsters et EDS - tout est très mauvais , 778 commentaires, note + 356,0 / -0,0, 175000 vues
- Japon: un pays d'un tel bon sens que, dans certains endroits, il est irrationnel pour nous , 483 commentaires, note + 365,0 / -12,0, 138 000 vues
- Affaiblir les noix dans les règles Habr , 1285 commentaires, note + 338,0 / -13,0, 48300 vues
- Récompense utilisateur aux auteurs de Habr , 245 commentaires, note + 320,0 / -0,0, 26 400 vues
- Comment j'ai attrapé un pirate , 273 commentaires, note + 305,0 / -6,0, 110 000 vues
- Mythes de la physique populaire moderne , 556 commentaires, note + 304,0 / -6,0, 99 600 vues
- Maintenant, les bons développeurs sont mesurés par les vues et les abonnés - et c'est mauvais , 486 commentaires, note + 324,0 / -26,0, 74800 vues
- Survivre à une collision frontale et pourquoi l'amnésie n'est pas ce que vous pensez , 165 commentaires, note + 297.0 / -4.0, 61800 vues
- Scanner de port dans le compte personnel de Rostelecom , 194 commentaires, note + 300,0 / -8,0, 111 000 vues
Articles favoris- 42 opérateurs de recherche avancée de Google (liste complète) 47 100 vues, 917 signets
- Comment devenir développeur Java en un an et demi 88 500 vues, 894 signets
- Échantillonneur. Utilitaire de console pour visualiser le résultat des commandes shell 58 400 vues, 801 signets
- HBO, merci de me rappeler ... 'Trousse de premiers secours à Tchernobyl' d'un pharmacien biélorusse 88 500 vues, 797 signets
- Conseils pratiques, exemples et tunnels SSH 40 000 vues, 787 signets
- 256 lignes de C ++ nu: écriture d'un ray tracer à partir de zéro en quelques heures 60 000 vues, 745 signets
- Programmation asynchrone (cours complet) 36 700 vues, 690 signets
- Employés «brûlés»: y a-t-il une issue? 116 000 vues, 688 signets
- Un aperçu complet des interviews Python. Trucs et astuces 28 400 vues, 687 signets
- 15 livres d'apprentissage automatique pour débutants 18 700 vues, 670 signets
- Cours magistral sur JavaScript et Node.js en KPI 52500 vues, 656 signets
- Comment j'écris des notes mathématiques sur LaTeX dans Vim 58100 vues, 652 signets
- Ce que j'ai appris de mon amère expérience (plus de 30 ans dans le développement de logiciels) 100 000 vues, 651 signets
- Une sélection de diapositives utiles de Julia Evans 41 000 vues, 587 signets
- En-têtes HTTP pour développeur responsable 33 600 vues, 566 signets
- N + 7 livres utiles 42 700 vues, 563 signets
- Piratage automatique du bus CAN. Tableau de bord virtuel 60 700 vues, 562 signets
- Déménagement prudent aux Pays-Bas avec sa femme et son hypothèque. Partie 1: recherche d'emploi 76200 vues, 555 signets
- TCP vs UDP ou l'avenir des protocoles réseau 50 300 vues, 538 signets
- Meilleures distributions Linux pour les ordinateurs plus anciens 66 000 vues, 523 signets
Top by View Bookmark Ratio- 15 livres d'apprentissage automatique pour les débutants 670 signets, 18 700 vues
- Musique pour vos projets: 12 ressources thématiques avec des pistes sous licence Creative Commons 477 signets, 18 100 vues
- Un aperçu complet des interviews Python. Trucs et astuces 687 signets, 28 400 vues
- Une sélection d'ensembles de données pour l'apprentissage automatique 455 signets, 19 000 vues
- Générateur de donjon basé sur les nœuds des signets du graphique 304, 12 700 vues
- Une explication simple des algorithmes de recherche de chemin et des signets A * 316, 13 500 vues
- Outils Web, ou par où commencer un pentester? 421 signets, 18800 vues
- Learning Docker, Partie 2: Termes et concepts 341 signets, 15,600 vues
- Exploration de Docker, partie 3: fichiers Dockerfile 297 signets, 13 800 vues
- Outils d'analyse et de débogage des applications .NET 244 signets, 11 600 vues
- Comment déboguer les variables d'environnement dans les signets Linux 322, 15 900 vues
- Comment faire les premiers pas en robotique? 224 signets, 11,200 vues
- Labyrinthes: classification, génération, recherche de solutions 318 signets, 16 000 vues
- Conseils pratiques, exemples et tunnels Signets SSH 787, 40 000 vues
- Cours magistral «Notions fondamentales du traitement numérique du signal» 418 signets, 21 400 vues
- 42 opérateurs de recherche avancée de Google (liste complète) 917 signets, 47 100 vues
- Game Shaders 3D pour débutants 239 signets, 12 400 vues
- Contournement de points PKH verrouille sur un routeur avec OpenWrt à l'aide des signets WireGuard et DNSCrypt 302, 15 700 vues
- Développer les compétences d'utilisation du regroupement et de la visualisation des données dans les signets Python 192, 10 000 vues
- Un autre Github 2: apprentissage automatique, jeux de données et cahiers Jupyter 265 signets, 13 900 vues
Articles les plus commentés- Cours d'ukrainien 1672 commentaires, 60,400 vues
- Rocket 9M729. Quelques mots sur le «violateur» du traité INF 1371 commentaires, 83 000 vues
- Github a commencé à bloquer les référentiels d'utilisateurs de Crimée, Cuba, Iran, Corée du Nord et Syrie 1 309 commentaires, 44 500 vues
- Affaiblir les noix dans les règles Habr 1285 commentaires, 48300 vues
- Plus vite vous oubliez la POO, mieux c'est pour vous et vos programmes 1271 commentaires, 128000 vues
- Crash d'un avion à Sheremetyevo: analogies historiques 1211 commentaires, 82,400 vues
- Comment la génération Y est-elle devenue une génération épuisée? 1122 commentaires, 81,500 vues
- La voiture électrique n'est pas pour moi 1116 commentaires, 50,700 vues
- 1098 , 71800
- 1021 , 27500
- 999 , 62100
- 997 , 7700
- 940 , 51600
- , 933 , 120000
- 923 , 50900
- 22 922 , 156000
- Choisir une voiture pour un spécialiste informatique, ou des conseils pour des théières à partir d'une théière 914 commentaires, 43,400 vues
- Pourquoi les développeurs seniors ne peuvent pas obtenir un emploi 901 commentaires, 119 000 vues
- Le plan est revenu à l'économie 892 commentaires, 27 800 vues
- Personal City Teleportator 889 commentaires, 40,800 vues
Et enfin, le dernier anti-stop par le nombre de dégoûts- Retiré à 22922 commentaires, note + 259,0 / -100,0
- J'ai lu 80 CV, j'ai des questions , 635 commentaires, note + 135,0 / -94,0
- Chérie, nous tuons Internet , 933 commentaires, note + 392.0 / -83.0
- State and T-killers , 752 commentaires, rating + 83.0 / -80.0
- Windows 2019 , ? , 881 , +123.0/-70.0
- : , . 1 , 394 , +100.0/-68.0
- ' ': 109 , , , 361 , +240.0/-68.0
- , . , 259 , +101.0/-63.0
- , , 1271 , +131.0/-63.0
- - , 179 , +147.0/-62.0
- , 668 , +315.0/-60.0
- , 597 , +208.0/-60.0
- , 246 , +105.0/-59.0
- , , 215 , +141.0/-58.0
- , 1098 , +131.0/-58.0
- Go , 70 , +76.0/-57.0
- '-' , 272 , +154.0/-55.0
- Apple , 96 , +90.0/-52.0
- , 764 , +164.0/-52.0
- Cinq tendances effrayantes du développement moderne , 262 commentaires, note + 95,0 / -52,0
Uff. J'ai quelques échantillons plus intéressants, mais je n'ennuierai pas les lecteurs.Conclusion
Lors de la construction de la note, j'ai attiré l'attention sur deux points qui me semblaient intéressants.Tout d'abord, après tout, 60% du top sont des articles du genre geektimes. S'il y en aura moins l'année prochaine, et à quoi ressemblera Habr sans articles sur la bière, l'espace, les médicaments, etc. - je ne sais pas. Les lecteurs vont certainement perdre quelque chose. Voyons voir.
Deuxièmement, le haut du signet s'est révélé d'une qualité inattendue. Ceci est psychologiquement compréhensible, les lecteurs peuvent ne pas prêter attention à la note et si un article est nécessaire , ils l'ajouteront aux signets. Et voici juste la plus grande concentration d'articles utiles et sérieux. Je pense que les propriétaires du site devraient en quelque sorte considérer la relation entre le nombre de bookmarking et le programme d'incitation s'ils veulent augmenter cette catégorie particulière d'articles ici sur Habré.Quelque chose comme ça.
J'espère que c'était instructif.La liste des articles est longue, mais c'est probablement pour le mieux. Bonne lecture à tout le monde.