Récemment, je suis tombé
sur un ensemble de données
Kaggle avec des données sur 45 000 films de l'
ensemble de données Full MovieLens. Les données contenaient non seulement des informations sur les acteurs, l'équipe, l'intrigue, etc., mais aussi les cotes émises par les utilisateurs des films pour les films (26 millions de cotes pour 270 000 utilisateurs).
Une tâche standard pour ces données est un système de recommandation. Mais pour une raison quelconque, il m'est venu à l'esprit de
prédire la cote d'un film sur la base des informations disponibles avant sa sortie . Je ne suis pas un connaisseur du cinéma, et je me concentre donc généralement sur les critiques, en choisissant quoi voir dans les nouvelles. Mais les critiques sont également quelque peu partiaux - ils regardent beaucoup plus de films différents que le spectateur moyen. Il nous a donc semblé intéressant de prédire comment le film serait apprécié par le grand public.
Ainsi, l'ensemble de données contient les informations suivantes:
- Informations sur le film: heure de sortie, budget, langue, société et pays d'origine, etc. Ainsi que la note moyenne (et nous le prédirons)
- Mots clés (tags) sur l'intrigue
- Noms des acteurs et de l'équipe
- Notes (estimations)
Le code utilisé dans l'article (python) est disponible sur
github .
Préfiltrage des données
La gamme complète contient des données sur plus de 45 000 films, mais comme la tâche consiste à prédire la note, vous devez vous assurer que les notes d'un film particulier sont objectives. Par exemple, dans le fait que beaucoup de gens l'ont apprécié.
La plupart des films ont très peu de notes:

Soit dit en passant, le film avec le plus grand nombre de notes (14075) m'a surpris - c'est
«Inception» . Mais les trois suivants - "The Dark Knight", "Avatar" et "Avengers" semblent assez logiques.
Il est prévu que le nombre de classements et le budget du film soient interconnectés (budget inférieur - classements inférieurs). Par conséquent, la suppression des films avec un petit nombre de notes rend le modèle biaisé vers des films plus chers:
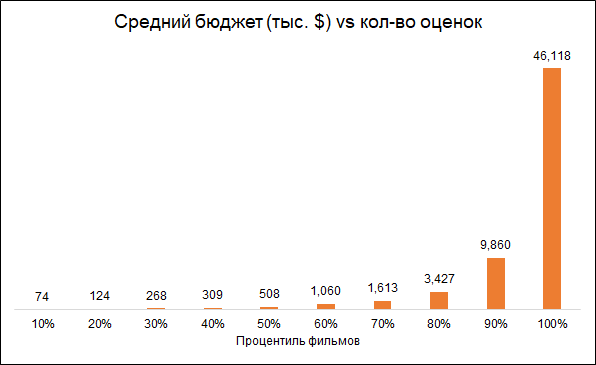
Nous partons pour des films d'analyse avec plus de 50 notes.
De plus, nous supprimerons les films sortis avant le début du service de notation (1996). Ici, le problème est que les films modernes sont en moyenne moins bien notés que les anciens, simplement parce que parmi les vieux films, ils regardent et évaluent les meilleurs, et parmi les films modernes, c'est tout.
En conséquence, la matrice finale contient environ 6 000 films.
Caractéristiques utilisées
Nous utiliserons plusieurs groupes de fonctionnalités:
- Métadonnées du film : si le film appartient à la «collection» (série de films), pays de sortie, société de fabrication, langue du film, budget, genre, année et mois de sortie du film, sa durée
- Mots-clés: pour chaque film, il existe une liste de balises décrivant son intrigue. Puisqu'il y a beaucoup de mots, ils ont été traités comme suit: regroupés en groupes de similitude (par exemple, accident et accident de voiture), sur la base de ces groupes et mots individuels, une analyse PCA a été effectuée et les composants les plus importants ont été sélectionnés à partir de ses résultats. Cela a réduit la dimension de l'espace de fonctionnalité.
- Les «mérites» précédents des acteurs qui ont joué dans le film. Pour chaque acteur, une liste de films a été formée dans laquelle il a joué plus tôt et la note de ces films a été calculée. Ainsi, pour chaque film, un indicateur a été formé qui agrège le succès des films dans lesquels les acteurs ont joué plus tôt.
- Oscars. Si les acteurs, le réalisateur, le producteur, le scénariste ou le caméraman ont déjà participé à un film qui a été nominé ou a reçu un Oscar du meilleur film, réalisation ou scénario, cela a été pris en compte dans le modèle. De plus, si les acteurs étaient des nominés ou des lauréats de l'Academy Award du meilleur acteur de soutien ou du second rôle, cela a également été pris en compte. Informations sur les Oscars reçues de Wikipedia.
Quelques statistiques intéressantes
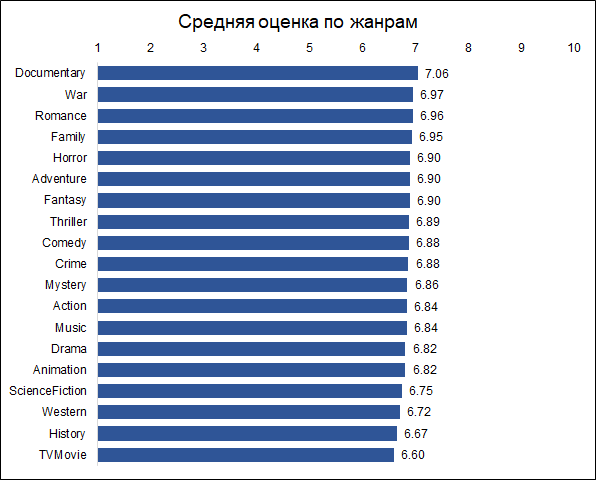
Les films documentaires sont les mieux notés. C'est une bonne raison de noter que différents films sont évalués par différentes personnes, et si les documentaires ont été évalués par des mordus d'action, les résultats peuvent être différents. Autrement dit, les estimations sont biaisées en raison des préférences initiales du public. Mais pour notre tâche, cela n'est pas important, car nous voulons prévoir une évaluation non conditionnellement objective (comme si chaque spectateur avait regardé tous les films), à savoir celle qui sera donnée au film par son public.
Soit dit en passant, il est intéressant de noter que les films historiques sont classés bien moins bien que les documentaires.
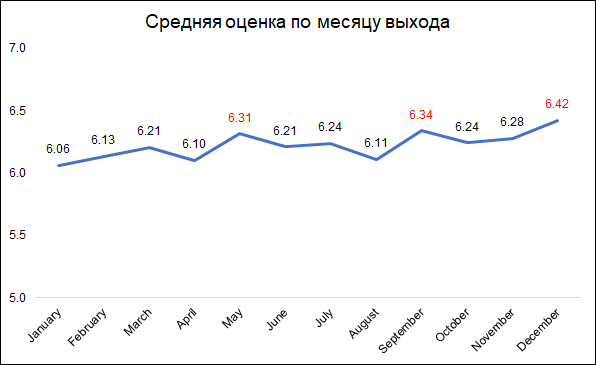
 Les notes les plus élevées sont attribuées aux films sortis en décembre, septembre et mai.
Les notes les plus élevées sont attribuées aux films sortis en décembre, septembre et mai.Cela peut probablement s'expliquer comme suit:
- en décembre, les entreprises sortent les meilleurs films à collectionner au box-office pendant les vacances de Noël
- en septembre, sortira des films qui participeront à la lutte pour l'Oscar
- Mai est la date de sortie des blockbusters d'été.
 La classification des films dépend peu du budget
La classification des films dépend peu du budget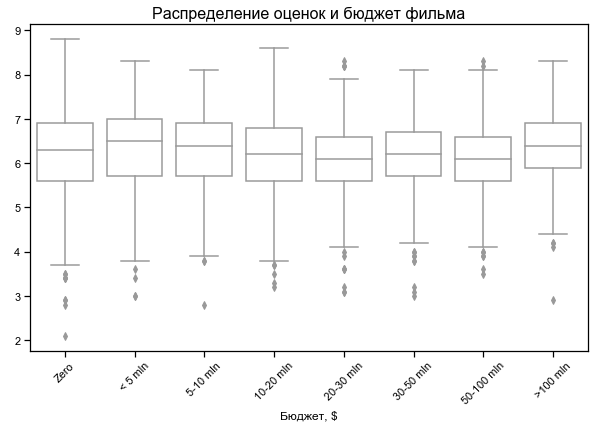
Budget nul pour certains films - probablement pas de données
Films les plus courts et les plus longs les mieux notés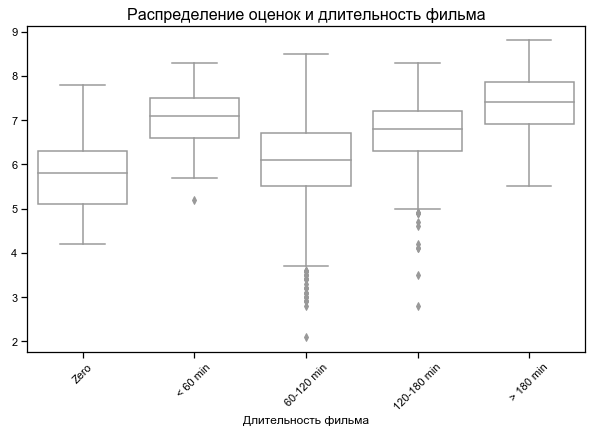
Pour certains films, une durée nulle est indiquée - probablement aucune donnée
Résultats sur différents ensembles de fonctionnalités
Notre tâche - prévoir la cote - la tâche de régression. Nous allons tester trois modèles - régression linéaire (comme la ligne de base), SVM et XGB. En tant que mesure de qualité, nous choisissons RMSE. Le graphique ci-dessous montre les valeurs RMSE sur l'ensemble de validation pour différents modèles et différents ensembles de fonctionnalités (je voulais comprendre s'il valait la peine de jouer avec les mots-clés et les Oscars). Tous les modèles sont construits avec des hyperparamètres de base.
Comme vous pouvez le voir, XGB a le meilleur résultat avec un ensemble complet de fonctionnalités (métadonnées de film + mots-clés + Oscars).
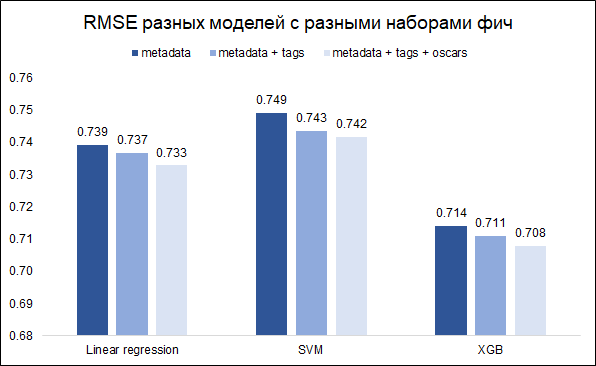
En réglant les hyperparamètres, il a été possible de réduire le RMSE de 0,708 à 0,706
Analyse des erreurs et commentaires finaux
Nous supposons que les erreurs de moins de 5% sont petites (environ un tiers) et que les erreurs de plus de 20% sont importantes (environ 10%). Dans d'autres cas (un peu plus de la moitié), nous considérerons la moyenne d'erreur.
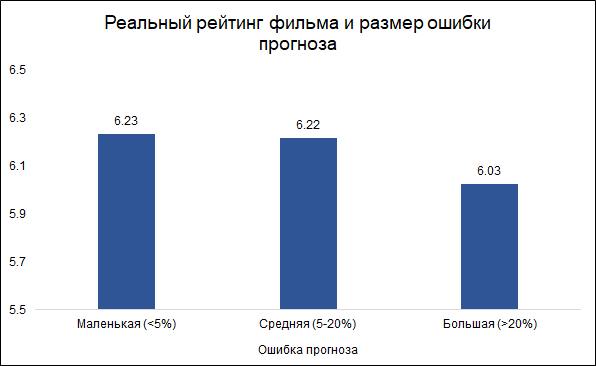
Fait intéressant, la taille de l'erreur et la cote du film sont liées: le
modèle est moins susceptible de faire des erreurs sur les bons films et plus souvent sur les mauvais. Cela semble logique: les bons films, comme tout autre travail, sont plutôt réalisés par des gens plus expérimentés et professionnels. À propos du film Tarantino avec la participation de Brad Pitt, vous pouvez dire à l'avance qu'il se révélera très probablement bon. Dans le même temps, un film à petit budget avec des acteurs peu connus peut être à la fois bon et mauvais, et il est difficile de juger sans le voir.
Voici les caractéristiques les plus importantes du modèle (les variables PCA se réfèrent aux mots clés traités qui décrivent l'intrigue du film):

Deux de ces longs métrages appartiennent aux Oscars, qui avaient été précédemment nommés par des membres de l'équipe (réalisateur, producteur, scénariste, caméraman) ou des films dans lesquels les acteurs ont joué. Comme mentionné ci-dessus, l'erreur de prévision est associée à l'évaluation du film, et en ce sens, les nominations précédentes aux Oscars peuvent être un bon délimiteur pour le modèle. En effet, les films qui ont au moins une nomination aux Oscars (parmi les acteurs ou les équipes) ont une erreur de prévision moyenne de 8,3%, et ceux qui n'ont pas de telles nominations - 9,8%. Parmi les 10 principales fonctionnalités utilisées dans le modèle, ce sont les nominations aux Oscars qui donnent le meilleur rapport avec la taille de l'erreur.
Par conséquent, l'idée est venue de construire deux modèles distincts: l'un pour les films dans lesquels les acteurs ou l'équipe ont été nominés pour un Oscar, et le second pour le reste. L'idée était que cela pourrait réduire l'erreur globale. Cependant, l'expérience a échoué: le modèle général a donné RMSE 0,706 et deux modèles distincts ont donné 0,715.
Par conséquent, nous laisserons le modèle d'origine. Les résultats de sa précision sont les suivants: RMSE dans l'échantillon d'apprentissage - 0,688, dans l'échantillon de validation - 0,706 et dans l'échantillon d'essai - 0,732.
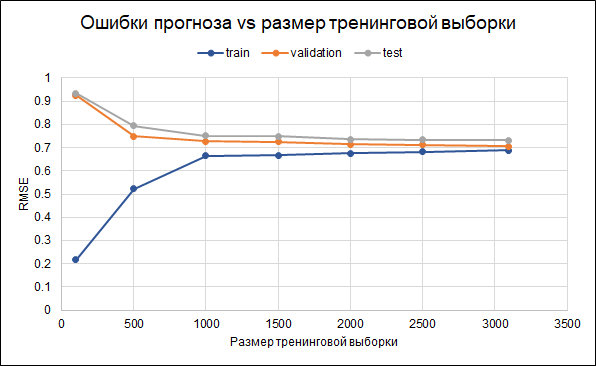
Autrement dit, il y a un sur-ajustement. Des paramètres de régularisation ont déjà été définis dans le modèle lui-même. Une autre façon de réduire le surapprentissage pourrait être de collecter davantage de données. Pour comprendre si cela peut aider, nous allons construire un graphique des erreurs pour différentes tailles de l'échantillon de formation - de 100 au maximum 3 000 disponibles. Le graphique montre qu'à partir d'environ 2,5 mille points dans l'ensemble de formation, des erreurs dans la formation, la validation et le changement de l'ensemble de tests petite, c'est-à-dire qu'une augmentation de l'échantillon n'aura pas d'effet significatif.
 Quoi d'autre pouvez-vous essayer d'affiner le modèle:
Quoi d'autre pouvez-vous essayer d'affiner le modèle:- Initialement, les films sont sélectionnés différemment (limite différente sur le nombre de votes, limites supplémentaires sur d'autres variables)
- Toutes les notes ne sont pas utilisées pour calculer la note - il est possible de sélectionner des utilisateurs plus actifs ou de supprimer ceux qui ne donnent que de mauvaises notes
- Essayez différentes façons de remplacer les données manquantes
Fait intéressant, le film de 1997 «Batman et Robin» a enregistré la plus grande erreur de prévision (7 points de prévision au lieu de 4,2 réels). Le film avec Arnold Schwarzenegger, George Clooney et Uma Thurman a reçu
11 nominations aux Golden Raspberry
Awards (et une victoire) , en tête de la
liste des 50 pires films de l'histoire d'Empire Newsreel, et a conduit à l'
annulation de la suite et au redémarrage de toute la série . Eh bien, ici, le modèle s'est peut-être trompé comme un homme :)