J'ai toujours été intéressé par une meilleure distribution des livres dans ma bibliothèque électronique. En conséquence, je suis arrivé à cette option avec un calcul automatique du nombre de pages et d'autres goodies. Je demande à tous les intéressés sous cat.
Partie 1. Dropbox
Tous les livres que j'ai sont sur la liste déroulante. Il y a 4 catégories dans lesquelles j'ai tout divisé: manuel, référence, artistique, non artistique. Mais je n'ajoute pas de livres de référence à la tablette.
La plupart des livres sont .epub, les autres sont .pdf. Autrement dit, la solution finale devrait en quelque sorte couvrir les deux options.
Les chemins vers les livres ressemblent à ceci:
///// / .epub
Si le livre est une fiction, la catégorie (c'est-à-dire "Design" dans le cas ci-dessus) est supprimée.
J'ai décidé de ne pas m'embêter avec l'API dropbox, heureusement j'ai leur application qui synchronise le dossier. Autrement dit, le plan est le suivant: prendre des livres à partir d'un dossier, exécuter chaque livre via un compteur de mots, l'ajouter à Notion.
Partie 2. Ajouter une ligne
La table elle-même devrait ressembler à ceci. ATTENTION: les noms de colonne sont mieux faits en lettres latines.
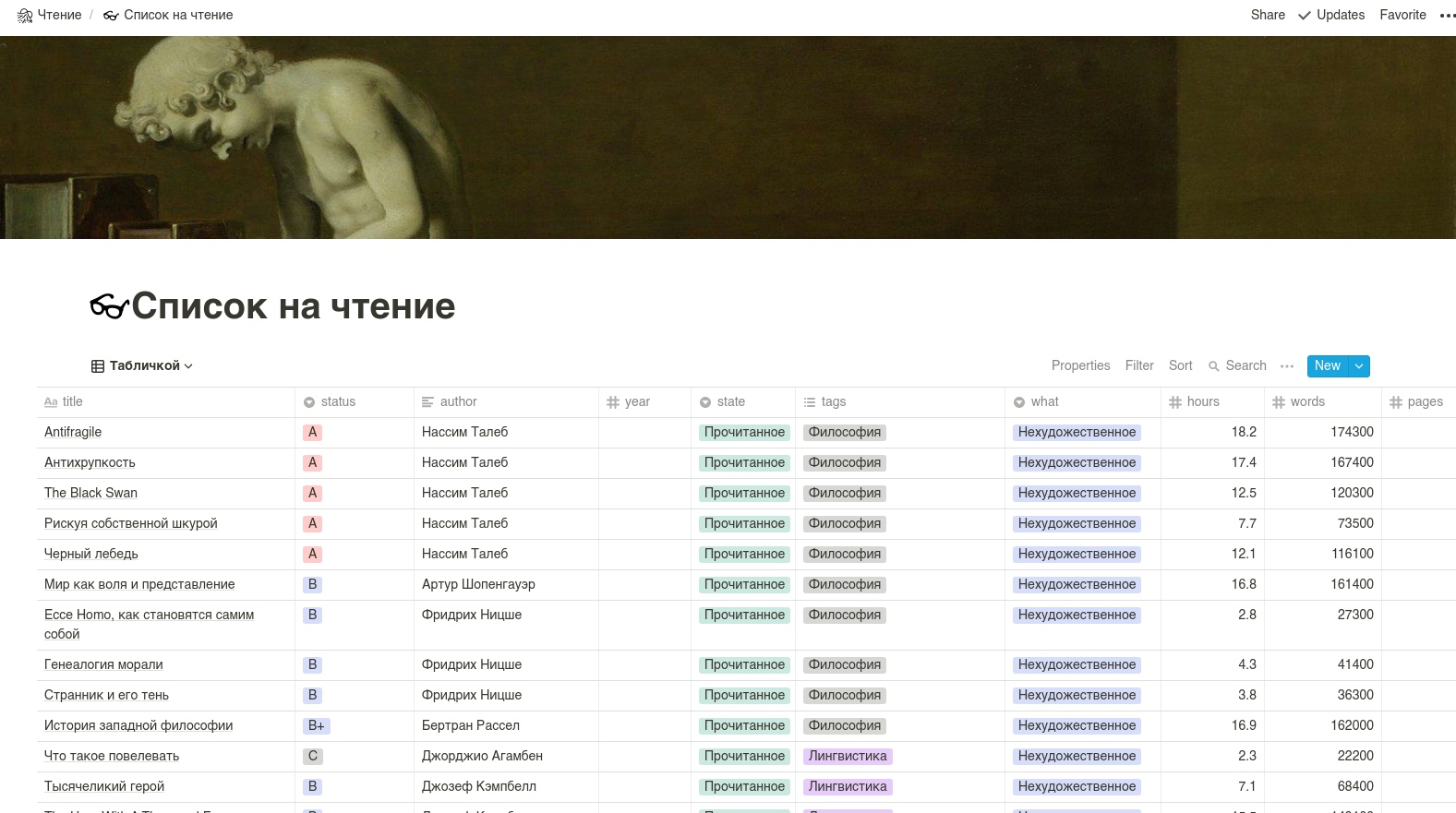
Nous utiliserons l'API Notion non officielle, car celle officielle n'a pas encore été livrée.

Allez dans Notion, appuyez sur Ctrl + Maj + J, allez dans Application -> Cookies, copiez token_v2 et appelez-le TOKEN. Ensuite, nous allons à la page dont nous avons besoin avec la plaque de bibliothèque et copions le lien. Appelez NOTION.
Ensuite, nous écrivons le code pour se connecter à Notion.
database = client.get_collection_view(NOTION) current_rows = database.default_query().execute()
Écrivons ensuite une fonction pour ajouter une ligne à l'étiquette.
def add_row(path, file, words_count, pages_count, hours): row = database.collection.add_row() row.title = file tags = path.split("/") if len(tags) >= 1: row.what = tags[0] if len(tags) >= 2: row.state = tags[1] if len(tags) >= 3: if tags[0] == "": row.author = tags[2] elif tags[0] == "": row.tags = tags[2] elif tags[0] == "": row.tags = tags[2] if len(tags) >= 4: row.author = tags[3] row.hours = hours row.pages = pages_count row.words = words_count
Que se passe-t-il ici. Nous prenons et ajoutons une nouvelle ligne au tableau de la première ligne. Ensuite, nous séparons notre chemin par "/" et obtenons les balises. Tags - en termes de "Artistique", "Design", qui est l'auteur et ainsi de suite. Ensuite, nous définissons tous les champs nécessaires de la plaque.
Partie 3. Compter les mots, les montres et autres délices
C'est une tâche plus compliquée. Comme nous nous en souvenons, nous avons deux formats: epab et pdf. Si tout est clair avec l'epab - il y a probablement des mots, alors qu'en est-il du pdf n'est pas si simple: il peut simplement consister en des images collées.
Ainsi la fonction de comptage des mots en pdf ressemblera à ceci: on prend le nombre de pages et on multiplie par une certaine constante (nombre moyen de mots par page).
Le voici:
def get_words_count(pages_number): return pages_number * WORDS_PER_PAGE
Il s'agit de WORDS_PER_PAGE pour une page A4 d'environ 300.
Écrivons maintenant une fonction pour compter les pages. Nous utiliserons PyPDF2 .
def get_pdf_pages_number(path, filename): pdf = PdfFileReader(open(os.path.join(path, filename), 'rb')) return pdf.getNumPages()
Ensuite, nous allons écrire une petite chose pour compter les pages dans epaba. Nous utilisons epub_converter . Ici, nous prenons un livre, le convertissons en lignes, et pour chaque ligne, nous comptons les mots.
def get_epub_pages_number(path, filename): book = open_book(os.path.join(path, filename)) lines = convert_epub_to_lines(book) words_count = 0 for line in lines: words_count += len(line.split(" ")) return round(words_count / WORDS_PER_PAGE)
Faisons maintenant le décompte du temps. Nous prenons notre nombre de mots préférés et divisons par votre vitesse de lecture.
def get_reading_time(words_count): return round(((words_count / WORDS_PER_MINUTE) / 60) * 10) / 10
Partie 4. Connexion de toutes les pièces
Nous devons parcourir tous les chemins possibles dans notre dossier de livres. Vérifiez s'il existe déjà un livre dans Notion: s'il y en a un, nous n'avons plus besoin de créer de ligne.
Ensuite, nous devons déterminer le type de fichier, en fonction de cela, compter le nombre de mots. Ajoutez un livre à la fin.
Voici le code que nous obtenons:
for root, subdirs, files in os.walk(BOOKS_DIR): if len(files) > 0 and check_for_excusion(root): for file in files: array = file.split(".") filetype = file.split(".")[len(array) - 1] filename = file.replace("." + filetype, "") local_root = root.replace(BOOKS_DIR, "") print("Dir: {}, file: {}".format(local_root, file)) if not check_for_existence(filename): print("Dir: {}, file: {}".format(local_root, file)) if filetype == "pdf": count = get_pdf_pages_number(root, file) else: count = get_epub_pages_number(root, file) words_count = get_words_count(count) hours = get_reading_time(words_count) print("Pages: {}, Words: {}, Hours: {}".format(count, words_count, hours)) add_row(local_root, filename, words_count, count, hours)
Et la fonction pour vérifier si le livre est ajouté ressemble à ceci:
def check_for_existence(filename): for row in current_rows: if row.title in filename: return True elif filename in row.title: return True return False
Conclusion
Merci à tous ceux qui ont lu cet article. J'espère qu'elle vous aidera à lire plus :)