Habituellement, lorsque quelqu'un parle d'OSM, l'un des services Web apparaît dans votre tête ou une application comme Maps.me, basée sur des
données OSM. En fait, le projet OSM est principalement des données, tout le reste est essentiellement un cas particulier de leur utilisation. Les services ne fournissent généralement qu'une partie des informations tirées conformément à leurs règles.
Au départ, OSM est une collection de points, de liens entre les points et de balises pour eux. Les sources communautaires ont deux formats. Initialement,
XML a été utilisé comme moyen prioritaire de distribution des données, mais le fichier Planet.osm a déjà dépassé les téraoctets sous une forme non compressée, et je ne vois aucune raison de l'utiliser pour des informations relativement volumineuses.
PBF a un gros avantage - il est binaire et le fichier Earth entier a une taille d'environ 50 Go (XML compressé environ 80 Go).
Il s'agira d'importer des données OSM du format «natif» à l'aide de l'outil Osmose.
Nous avons également besoin de PostgreSql avec l'extension Postgis, dans laquelle nous importerons des données OSM.
Par conséquent, il est possible d'obtenir des informations sur les objets
avec les balises répertoriées ici dans leur base de données
.
Préparation DB.
Tout d'abord, créez une base de données dans Postgresql, le nom n'a pas vraiment d'importance.
psql -c "CREATE DATABASE map;"
Ensuite, ajoutez les extensions nécessaires pour poursuivre les travaux.
psql -d map -c "CREATE EXTENSION postgis; CREATE EXTENSION hstore; "
L'extension Postgis "connecte" à la base de données le module réel pour travailler avec les géodonnées (je vous rappelle que vous devez installer Postgis lui-même). L'extension hstore est conçue pour fonctionner avec des ensembles clé / valeur, comme beaucoup d'informations seront contenues dans les balises OSM.
Téléchargez
Osmosis . En bref, c'est un logiciel pour une grande variété d'opérations avec des données OSM. Il existe une bonne documentation sur l'utilisation de la ligne de commande. Sources en Java. Ci-dessous, nous utiliserons la ligne de commande. J'ai également utilisé Osmosis comme bibliothèque Java, le code source (disponible sur GitHub) me semblait assez clair et l'API était facile à utiliser.
Nous préparons maintenant la base de données pour l'importation. Les tables et fonctions nécessaires peuvent être créées à l'aide de scripts qui se trouvent dans le dossier osmosis / script. En plus du script principal, nous exécuterons du code SQL qui créera un champ pour stocker la géométrie des lignes. Cela est dû au fait que les données OSM sont plus probablement représentées comme des connexions ponctuelles que comme un ensemble de formes géométriques.
psql -d map -fc:\osmosis\script\pgsnapshot_schema_0.6.sql psql -d map -fc:\osmosis\script\pgsnapshot_schema_0.6_linestring.sql
Importez des données OSM dans une base de données
Eh bien, maintenant presque tout est prêt. Vous pouvez même exécuter l'importation. Il est nécessaire de décider ce que nous prendrons comme source. À savoir, vous devez choisir le format et la source. Initialement, la communauté OSM a utilisé (et utilise) le format XML. Mais, la quantité de données augmente de plus en plus, de sorte que le format texte est progressivement évincé. L'utilisation du PBF est un peu plus pratique. La source centrale
planet.openstreetmap.org contient des données pour le globe entier. Avec un seul fichier, vous pouvez télécharger l'intégralité de la base de connaissances du projet, qui a déjà dépassé 40 gigaoctets sous forme binaire. Dans ces cas, lorsque je voulais supprimer une donnée à partir de là, je laissais généralement l'ordinateur portable travailler toute la nuit, en lui fournissant plus de 100 Go d'espace libre sur le SSD pour les fichiers temporaires.
Dans notre cas, nous pouvons commencer par utiliser les téléchargements des membres de la communauté. Il existe des ressources qui permettent de télécharger des données uniquement pour une région spécifique. Par exemple,
download.geofabrik.de . Prenez la région de Voronej. Là, il est inclus dans un fichier contenant des données pour l'ensemble du district fédéral central. Vous pouvez télécharger central-fed-district-latest.osm.pbf, puis couper la «pièce» souhaitée dans un fichier séparé ou filtrer par coordonnées lors de l'importation dans la base de données. Je suggérerais la première option:
c:\osmosis\bin\osmosis.bat --read-pbf file="c:\downloads\central-fed-district-latest.osm.pbf" --bounding-box top=52.059564 left=37.92290 bottom=49.612297 right=43.225858 --write-pbf file="c:\map\voronezh.osm.pbf"
Ici, tout est simple. Nous lisons le fichier PBF, filtrons les résultats de lecture par le rectangle de coordonnées et écrivons les résultats après filtrage dans le fichier de sortie. Vous pouvez filtrer les coordonnées plus précisément en utilisant non pas un rectangle, mais un polygone dont les coordonnées sont dans un fichier séparé.
Le fichier résultant voronezh.osm.pbf est ensuite importé dans la base de données. Pour vous connecter, créez un fichier de propriétés avec les paramètres d'accès à la base de données:
host=localhost database=map user=pguser password=pgpassword dbType=postgresql
Eh bien, l'importation elle-même:
c:\osmosis\bin\osmosis.bat --read-pbf c:\map\voronezh.osm.pbf --write-pgsql authFile=c:\map\databaseinfo.properties
Données importées
Maintenant, vous pouvez déjà commencer à étudier ce que nous avons dans la base de données. La première pensée est qu'il existe un ensemble de chiffres, mais ce n'est pas entièrement vrai. Comme je l'ai dit, l'élément principal est le point. Tout le reste est créé en créant des liens (relations) entre les points. Nous n'irons pas encore en profondeur, d'autant plus que les mains ont déjà envie de créer leur propre table «plate» avec quelques données. Eh bien, pour les lignes et les points, tout est prêt, il vous suffit de créer un tableau avec les champs nécessaires et d'y insérer les entrées nécessaires. Et quels domaines avons-nous? Ici pour aider le wiki. Par exemple,
prenez la paire clé / valeur puissance = ligne . Choisissez une liste de champs que nous utiliserons, par exemple: nom, tension, opérateur, câbles. Il s'avère que nous voulons sélectionner les lignes qui ont nécessairement la propriété power = line, ainsi que le nom des champs, la tension, l'opérateur, les câbles. Créez une table:
CREATE TABLE power_lines ( name varchar, voltage varchar, operator varchar, cables varchar, geom geometry )
Et la demande elle-même de remplir notre nouveau tableau:
INSERT INTO power_lines SELECT ways.tags -> 'name' as name, ways.tags -> 'voltage' as voltage, ways.tags -> 'operator' as operator, ways.tags -> 'cables' as cables, ways.linestring as geom FROM ways WHERE ways.tags -> 'power' IN ( 'line' )
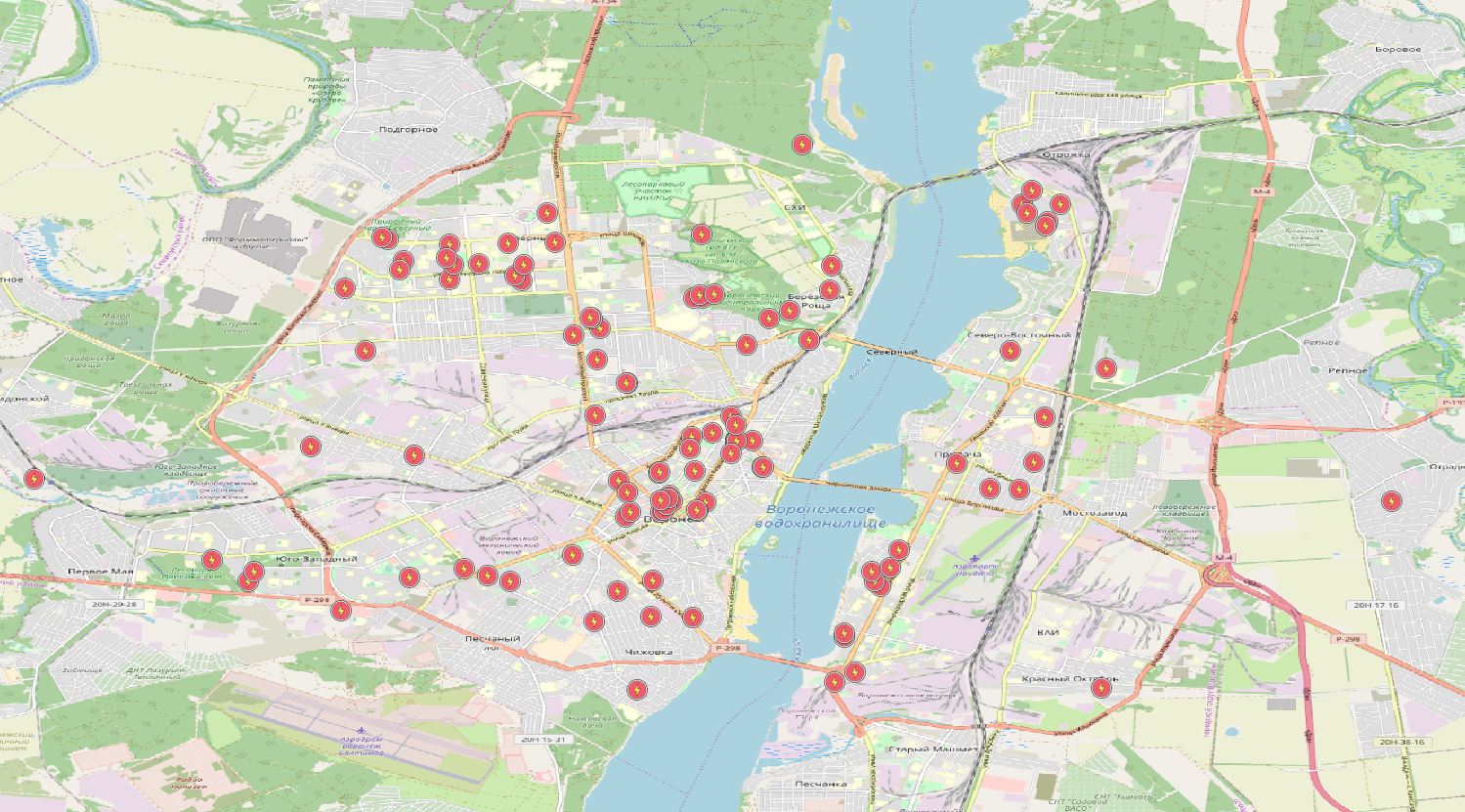
Terminé, nous avons une table avec des lignes électriques, où certaines lignes ont même certains champs remplis! Eh bien, le tableau est certainement intéressant, mais visualiser les données pour visualiser la géométrie serait également bien. Le moyen le plus rapide de le faire est avec QGIS, sauf que ce puissant SIG doit d'abord être installé. Là, nous ajoutons déjà une couche Postgis, utilisez n'importe quelle carte comme substrat (vous pouvez utiliser le plugin OpenLayers). Configuré, regardez:

Hourra! Même très semblable à la vérité, pensai-je en regardant par la fenêtre les lignes électriques.
Et les polygones?
La situation avec les points est presque la même, sauf que vous devez utiliser la table des nœuds. KDPV ne contient que des
données sur les sous-stations . Et qu'en est-il des polygones? Les polygones sont également constitués de lignes (fermées). Il semble que vous puissiez simplement fermer les lignes et profiter du résultat, mais cela ne fonctionne pas de cette façon. Les écueils sont nombreux. Les polygones peuvent être constitués de plusieurs lignes fermées.
Par exemple, une île peut être sur un lac. Par conséquent, nous obtenons un «trou» dans la décharge. J'ai également dû apprendre la signification du mot «exclave» (à ma honte, je ne connaissais que «l'enclave»). Les polygones sont également regroupés. Par exemple, une forêt peut être constituée de plusieurs «morceaux». Que nous devrions représenter comme un seul objet. Pour couronner le tout, nous devons couper les polygones ouverts si certaines des données sont en dehors de la carte. J'ai résolu ces problèmes, ainsi que d'autres problèmes dans le script SQL, que j'ai mis en toute sécurité sur l'étagère après que cela a fonctionné. Le projet
osmose-multypolygone a été trouvé sur GitHub. À contrecœur, j'ai décidé que l'utilisation de cette solution est une meilleure option que mon ensemble de scripts écrits sur mes genoux en quelques jours. Nous faisons comme il est dit dans README, à savoir, nous exécutons la liste des scripts, et nous avons la table multipolygons, qui est remplie avec l'instruction d'assemble.sql. Après avoir rempli le tableau de polygones, vous pouvez trouver ce que nous voulons obtenir. Choisissons le
territoire des parcs ?
Nous regardons le wiki et écrivons un script:
CREATE TABLE parks ( name varchar, geom geometry ); INSERT INTO parks SELECT m.tags -> 'name' as name, m.geom FROM multipolygons m WHERE m.tags -> 'leisure' IN ( 'park' )
Maintenant, nous visualisons:
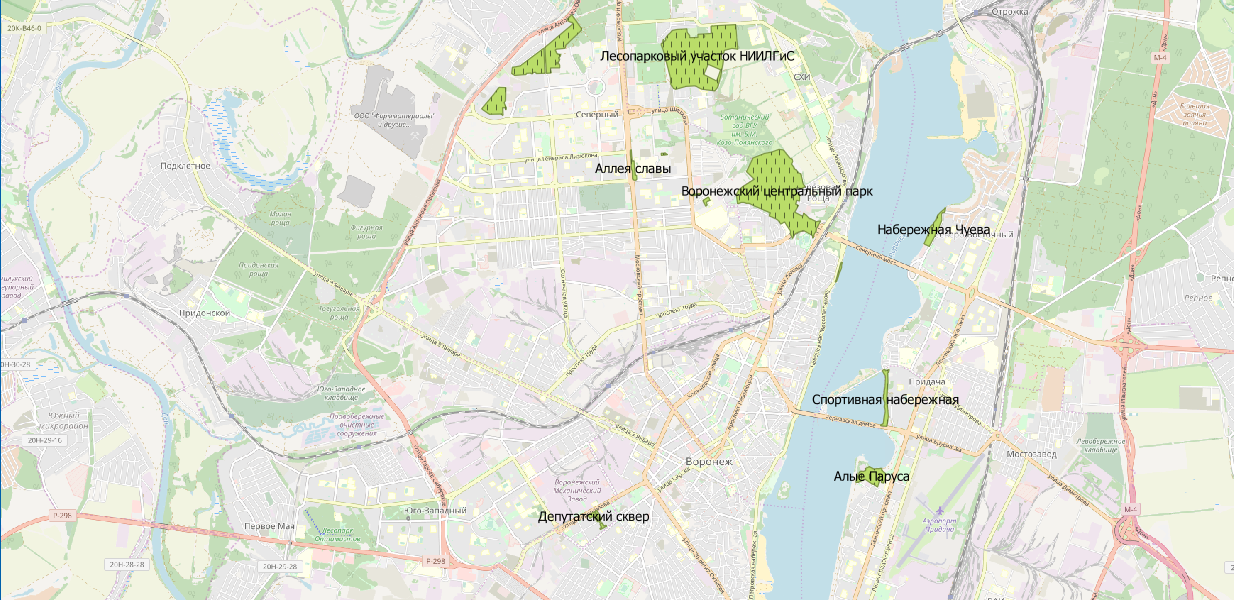
Eh bien, pour être honnête, vous pouvez ici discuter de la pertinence des données. Mais c'est un sujet pour une autre discussion.