
TL; DR
- Pour atteindre une observabilité élevée des conteneurs et des microservices, les magazines et les mesures primaires ne suffisent pas.
- Pour une récupération plus rapide et une meilleure tolérance aux pannes, les applications doivent appliquer le principe de haute observabilité (HOP).
- Au niveau de l'application, la NRA requiert: une journalisation appropriée, une surveillance attentive, des contrôles d'intégrité et un suivi des performances / transition.
- Utilisez les contrôles readinessProbe et livenessProbe Kubernetes comme élément HOP .
Qu'est-ce qu'un modèle de bilan de santé?
Lors de la conception d'une application critique et hautement disponible, il est très important de penser à une chose telle que la tolérance aux pannes. Une application est considérée comme tolérante aux pannes si elle est rapidement restaurée après une défaillance. Une application cloud typique utilise une architecture de microservices - lorsque chaque composant est placé dans un conteneur séparé. Et pour vous assurer que l'application sur k8s est hautement accessible, lorsque vous concevez un cluster, vous devez suivre certains modèles. Parmi eux se trouve le modèle de bilan de santé. Il détermine la manière dont l'application signale les performances des k8. Il ne s'agit pas seulement d'informations sur le fonctionnement du pod, mais également sur la façon dont il accepte les demandes et y répond. Plus Kubernetes en sait sur les performances d'un pod, plus il prend de décisions intelligentes concernant le routage du trafic et l'équilibrage de charge. Ainsi, le principe de haute observabilité de l'application en temps opportun pour répondre aux demandes de renseignements.
Le principe de la haute observabilité (NRA)
Le principe de haute observabilité est l'un des principes de conception des applications conteneurisées . Dans l'architecture de microservices, les services ne se soucient pas de la façon dont leur demande est traitée (et à juste titre), mais il est important de savoir comment obtenir des réponses des services reçus. Par exemple, pour authentifier un utilisateur, un conteneur envoie une autre requête HTTP, en attendant une réponse dans un format spécifique - c'est tout. PythonJS peut également gérer la demande et Python Flask peut répondre. Les conteneurs les uns pour les autres sont comme des boîtes noires avec du contenu caché. Cependant, le principe de la NRA exige que chaque service divulgue plusieurs points de terminaison API montrant son efficacité, ainsi que son état de préparation et sa tolérance aux pannes. Kubernetes demande à ces mesures de réfléchir aux prochaines étapes de routage et d'équilibrage de charge.
Une application cloud bien conçue enregistre ses événements clés à l'aide des flux d'E / S standard STDERR et STDOUT. Ensuite, un service auxiliaire, par exemple filebeat, logstash ou fluentd, s'exécute, fournissant les journaux à un système de surveillance central (par exemple Prometheus) et au système de collecte de journaux (suite logicielle ELK). Le diagramme ci-dessous montre comment l'application cloud fonctionne conformément au modèle de bilan de santé et au principe de haute observabilité.
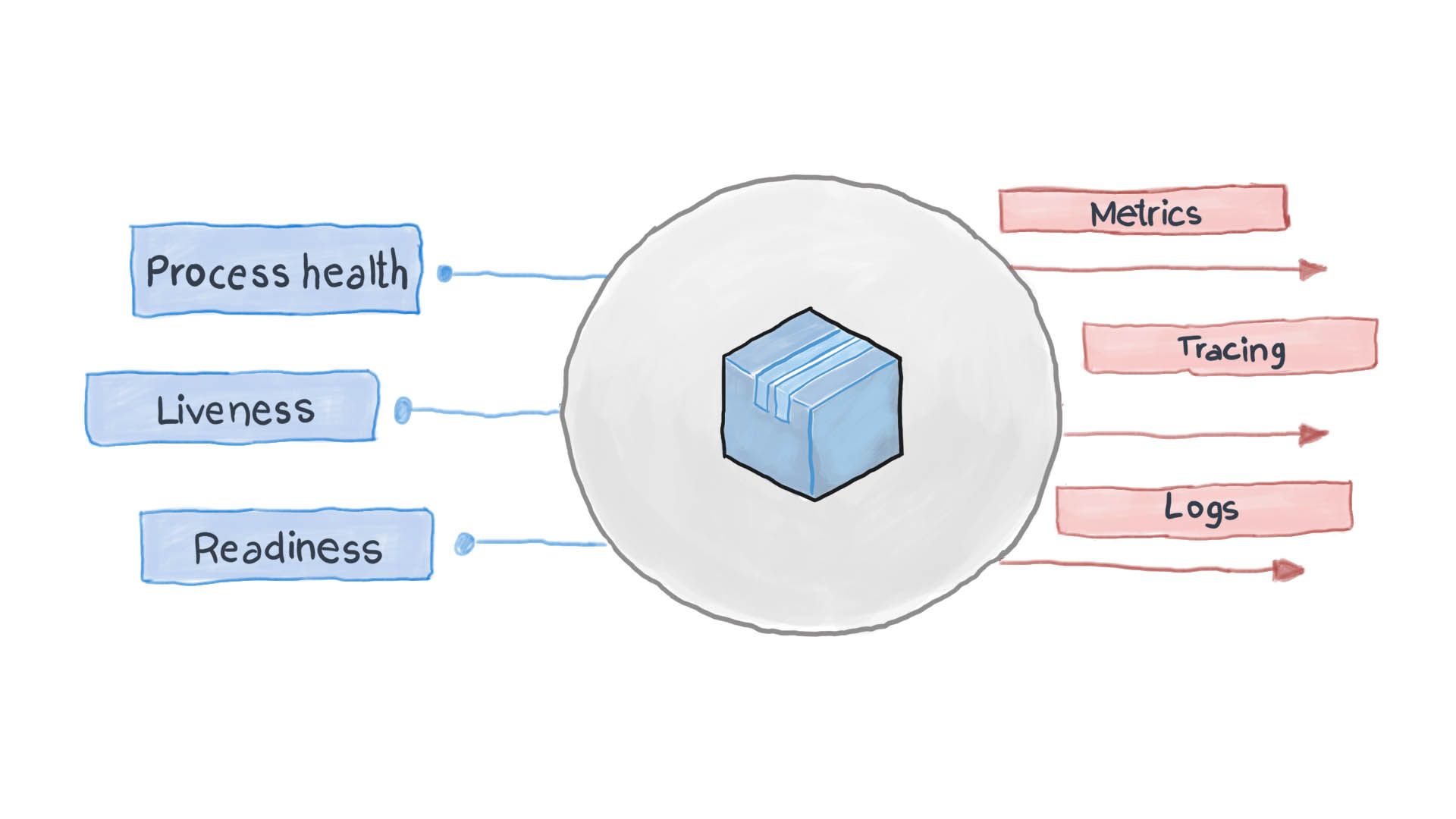
Comment appliquer le modèle de bilan de santé dans Kubernetes?
Prêt à l'emploi, k8s surveille l'état des pods à l'aide de l'un des contrôleurs ( déploiements , ReplicaSets , DaemonSets , StatefulSets , etc., etc.). Après avoir découvert que le pod est tombé pour une raison quelconque, le contrôleur essaie de le redémarrer ou de le déplacer vers un autre nœud. Cependant, pod peut signaler qu'il est opérationnel et qu'il ne fonctionne pas lui-même. Voici un exemple: votre application utilise Apache comme serveur web, vous avez installé le composant sur plusieurs pods du cluster. Étant donné que la bibliothèque n'a pas été configurée correctement, toutes les demandes à l'application répondent avec le code 500 (erreur de serveur interne). Lors de la vérification de la livraison, la vérification du statut des pods donne un résultat positif, cependant, les clients pensent différemment. Nous décrivons cette situation indésirable comme suit:
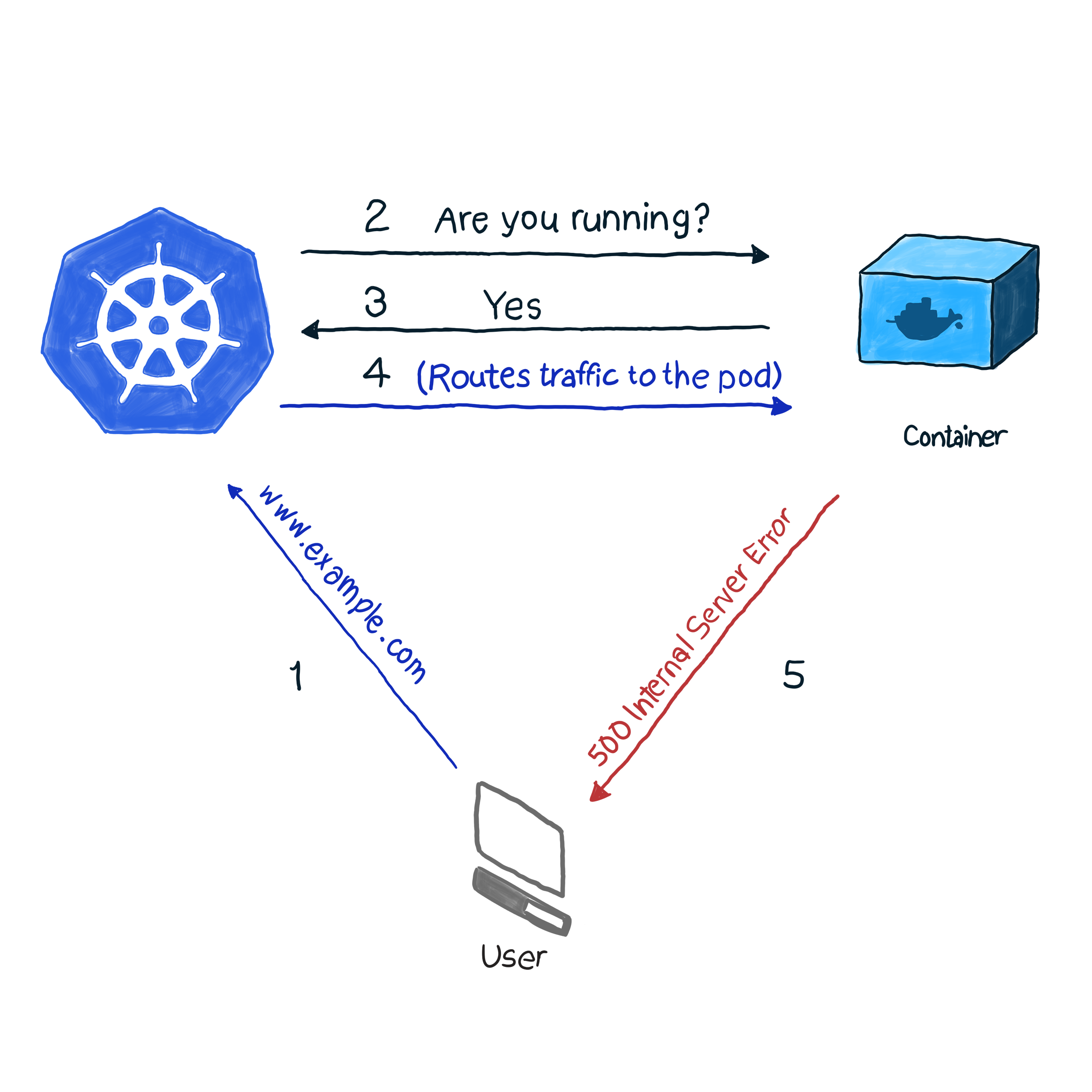
Dans notre exemple, k8s effectue un bilan de santé . Dans ce type de vérification, kubelet vérifie en permanence l'état du processus dans le conteneur. Une fois qu'il comprend que le processus a augmenté, il le redémarre. Si l'erreur est éliminée en redémarrant simplement l'application et que le programme est conçu pour s'éteindre en cas d'erreur, vous devez vérifier l'opérabilité du processus pour suivre la NRA et le modèle de vérification de l'état. Il est dommage que toutes les erreurs ne soient pas éliminées en redémarrant. Dans ce cas, k8s propose 2 méthodes plus approfondies de dépannage d'un module : livenessProbe et readinessProbe .
LivenessProbe
Pendant livenessProbe, kubelet effectue 3 types de vérifications: non seulement il vérifie si le pod fonctionne, mais s'il est prêt à recevoir et à répondre adéquatement aux demandes:
- Définissez une demande HTTP sur pod. La réponse doit contenir un code de réponse HTTP compris entre 200 et 399. Ainsi, les codes 5xx et 4xx indiquent que le pod a des problèmes, même si le processus est en cours d'exécution.
- Pour vérifier les pods avec des services non HTTP (par exemple, serveur de messagerie Postfix), vous devez établir une connexion TCP.
- Exécution d'une commande arbitraire pour le pod (en interne). La vérification est considérée comme réussie si le code d'exit de commande est 0.
Un exemple de comment cela fonctionne. La définition du pod suivant contient une application NodeJS qui donne une erreur de 500 pour les requêtes HTTP. Pour nous assurer que le conteneur redémarre après avoir reçu une telle erreur, nous utilisons le paramètre livenessProbe:
apiVersion: v1 kind: Pod metadata: name: node500 spec: containers: - image: magalix/node500 name: node500 ports: - containerPort: 3000 protocol: TCP livenessProbe: httpGet: path: / port: 3000 initialDelaySeconds: 5
Ce n'est pas différent de toute autre définition de .spec.containers.livenessProbe , mais nous ajoutons un objet .spec.containers.livenessProbe . Le paramètre httpGet accepte le chemin où la requête HTTP GET est envoyée (dans notre exemple, c'est / , mais dans les scénarios de bataille, il peut également y avoir quelque chose comme /api/v1/status ). LivenessProbe accepte toujours le paramètre initialDelaySeconds , qui demande à l'opération de validation d'attendre un nombre spécifié de secondes. Le délai est nécessaire car le conteneur a besoin de temps pour démarrer et lorsqu'il redémarrera, il sera indisponible pendant un certain temps.
Pour appliquer ce paramètre à un cluster, utilisez:
kubectl apply -f pod.yaml
Après quelques secondes, vous pouvez vérifier le contenu du pod avec la commande suivante:
kubectl describe pods node500
Recherchez les éléments suivants à la fin de la sortie.
Comme vous pouvez le voir, livenessProbe a lancé une requête HTTP GET, le conteneur a généré une erreur 500 (qui a été programmée pour), kubelet l'a redémarré.
Si vous êtes intéressé par la façon dont l'application NideJS a été programmée, voici les app.js et Dockerfile qui ont été utilisés:
app.js
var http = require('http'); var server = http.createServer(function(req, res) { res.writeHead(500, { "Content-type": "text/plain" }); res.end("We have run into an error\n"); }); server.listen(3000, function() { console.log('Server is running at 3000') })
Dockerfile
FROM node COPY app.js / EXPOSE 3000 ENTRYPOINT [ "node","/app.js" ]
Il est important de faire attention à ceci: livenessProbe ne redémarrera le conteneur qu'en cas de panne. Si le redémarrage ne corrige pas l'erreur qui interfère avec le fonctionnement du conteneur, kubelet ne pourra pas prendre de mesures pour éliminer le dysfonctionnement.
readinessProbe
readinessProbe fonctionne de manière similaire aux livenessProbes (requêtes GET, communications TCP et exécution de commandes), à l'exception des actions de dépannage. Le conteneur dans lequel l'échec est enregistré ne redémarre pas, mais est isolé du trafic entrant. Imaginez que l'un des conteneurs effectue beaucoup de calculs ou soit soumis à une charge importante, ce qui augmente le temps de réponse aux demandes. Dans le cas de livenessProbe, un contrôle de disponibilité de réponse est déclenché (via le paramètre de contrôle timeoutSeconds), après quoi kubelet redémarre le conteneur. Une fois lancé, le conteneur commence à effectuer des tâches gourmandes en ressources et est redémarré à nouveau. Cela peut être critique pour les applications soucieuses de la vitesse de réponse. Par exemple, une voiture en route attend une réponse du serveur, la réponse est retardée - et la voiture tombe en panne.
Écrivons une définition de readinessProbe qui définit le temps de réponse pour une demande GET à pas plus de deux secondes, et l'application répondra à une demande GET dans 5 secondes. Le fichier pod.yaml devrait ressembler à ceci:
apiVersion: v1 kind: Pod metadata: name: nodedelayed spec: containers: - image: afakharany/node_delayed name: nodedelayed ports: - containerPort: 3000 protocol: TCP readinessProbe: httpGet: path: / port: 3000 timeoutSeconds: 2
Développez le pod avec kubectl:
kubectl apply -f pod.yaml
Attendez quelques secondes, puis regardez comment fonctionne readinessProbe:
kubectl describe pods nodedelayed
À la fin de la conclusion, vous pouvez voir que certains événements sont similaires à cela .
Comme vous pouvez le voir, kubectl n'a pas redémarré le pod lorsque le temps d'analyse a dépassé 2 secondes. Au lieu de cela, il a annulé la demande. Les connexions entrantes sont redirigées vers d'autres modules fonctionnels.
Remarque: maintenant que la charge supplémentaire a été supprimée du pod, kubectl lui envoie à nouveau des requêtes: les réponses à la requête GET ne sont plus retardées.
A titre de comparaison: voici le fichier app.js modifié:
var http = require('http'); var server = http.createServer(function(req, res) { const sleep = (milliseconds) => { return new Promise(resolve => setTimeout(resolve, milliseconds)) } sleep(5000).then(() => { res.writeHead(200, { "Content-type": "text/plain" }); res.end("Hello\n"); }) }); server.listen(3000, function() { console.log('Server is running at 3000') })
TL; DR
Avant l'avènement des applications basées sur le cloud, les journaux étaient le principal moyen de surveiller et de vérifier l'état des applications. Cependant, il n'y avait aucun moyen de prendre des mesures de dépannage. Les journaux sont utiles aujourd'hui, ils doivent être collectés et envoyés au système d'assemblage des journaux pour l'analyse des situations d'urgence et la prise de décision. [ tout cela pourrait être fait sans applications cloud utilisant monit, par exemple, mais avec k8s c'est devenu beaucoup plus facile :) - Ed. ]
Aujourd'hui, les corrections doivent être effectuées presque en temps réel, les applications ne devraient donc plus être des boîtes noires. Non, ils doivent indiquer les points d'extrémité qui permettent aux systèmes de surveillance de demander et de collecter des données précieuses sur l'état des processus afin qu'ils puissent répondre instantanément si nécessaire. C'est ce qu'on appelle le modèle de conception du bilan de santé, qui suit le principe de haute observabilité (NRA).
Par défaut, Kubernetes propose 2 types de contrôles d'intégrité: readinessProbe et livenessProbe. Les deux utilisent les mêmes types de vérifications (requêtes HTTP GET, communications TCP et exécution de commandes). Ils diffèrent dans les décisions qui sont prises en réponse aux problèmes dans les gousses. livenessProbe redémarre le conteneur dans l'espoir que l'erreur ne se reproduira plus, et readinessProbe isole le pod du trafic entrant jusqu'à ce que la cause du problème soit résolue.
Une conception d'application appropriée doit inclure les deux types de validation et collecter suffisamment de données, en particulier lorsqu'une exception est créée. Il doit également indiquer les points de terminaison API nécessaires qui transmettent des mesures importantes de l'état de santé au système de surveillance (également appelé Prometheus).