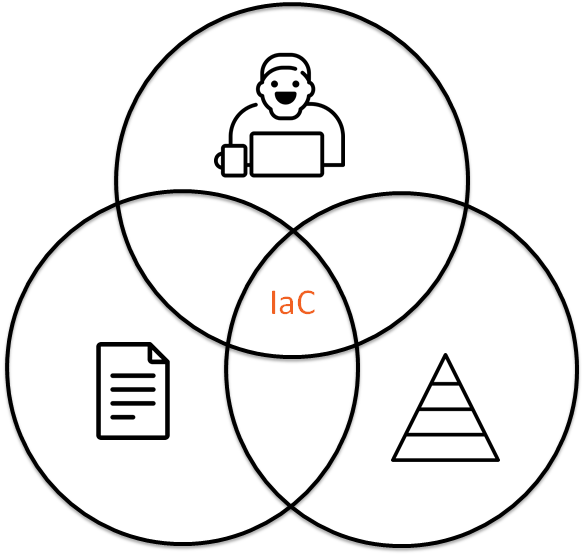
L'IaC (Infrastructure as Code) est une approche moderne et je crois que l'infrastructure est du code. Cela signifie que nous devrions utiliser la même philosophie pour l'infrastructure que pour le développement de logiciels. Si nous parlons que l'infrastructure est du code, nous devons réutiliser les pratiques de développement pour l'infrastructure, c'est-à-dire les tests unitaires, la programmation de paires, la révision de code. Veuillez garder à l'esprit cette idée lors de la lecture de l'article.
Version russe
Il s'agit de la traduction de mon discours ( vidéo RU ) à DevopsConf 2019-05-28 .
L'infrastructure comme histoire bash

Imaginons que vous embarquiez sur un projet et que vous entendiez quelque chose comme: "Nous utilisons l' infrastructure comme approche de code ". Malheureusement, ce qu'ils signifient vraiment, c'est Infrastructure en tant qu'historique bash ou Documentation en tant qu'historique bash . C'est presque une situation réelle. Par exemple, Denis Lysenko a décrit cette situation dans son discours Comment remplacer les infrastructures et arrêter de s'inquiéter (RU) . Denis a partagé l'histoire sur la façon de convertir l'histoire de bash en une infrastructure haut de gamme.
Vérifions la définition du code source: a text listing of commands to be compiled or assembled into an executable computer program . Si nous voulons, nous pouvons présenter Infrastructure comme un historique bash comme du code. Ceci est un texte et une liste de commandes. Il décrit comment un serveur a été configuré. De plus, c'est:
- Reproductible : vous pouvez obtenir l'historique de bash, exécuter des commandes et probablement obtenir une infrastructure fonctionnelle.
- Versioning : vous savez qui s'est connecté, quand et ce qui a été fait.
Malheureusement, si vous perdez le serveur, vous ne pourrez rien faire car il n'y a pas d'historique bash, vous l'avez perdu avec le serveur.
Que faut-il faire?
L'infrastructure comme code
D'une part, ce cas anormal, Infrastructure en tant qu'historique bash , peut être présenté comme Infrastructure en tant que code , mais d'autre part, si vous voulez faire quelque chose de plus complexe que le serveur LAMP, vous devez gérer, maintenir et modifier le code . Parlons des parallèles entre Infrastructure en tant que développement de code et développement de logiciels.
SEC
Nous développions SDS (stockage défini par logiciel). La SDS se composait de serveurs OS distributifs personnalisés et haut de gamme, beaucoup de logique métier, par conséquent, elle devait utiliser du matériel réel. Périodiquement, il y avait une sous-tâche d' installation SDS . Avant de publier une nouvelle version, nous devions l'installer et vérifier. Au début, cela semblait être une tâche très simple:
- SSH pour héberger et exécuter la commande.
- SCP un fichier.
- Modifiez une configuration.
- Exécutez un service.
- ...
- PROFIT!
Je crois que Make CM, not bash est une bonne approche. Cependant, bash n'est utilisé que dans des cas extrêmes et limités, comme au tout début d'un projet. Donc, bash était un choix assez bon et raisonnable au tout début du projet. Le temps tournait. Nous étions confrontés à différentes demandes de création de nouvelles installations dans une configuration légèrement différente. Nous étions SSHing dans les installations, et exécutions les commandes pour installer tous les logiciels nécessaires, éditant les fichiers de configuration par des scripts et, enfin, configurant SDS via Web HTTP rest API. Après tout, l'installation a été configurée et fonctionne. C'était une pratique assez courante, mais il y avait beaucoup de scripts bash et la logique d'installation devenait chaque jour plus complexe.
Malheureusement, chaque script était comme un petit flocon de neige selon qui le copiait. C'était aussi une vraie douleur lorsque nous créions ou recréions l'installation.
J'espère que vous avez eu l'idée principale, qu'à ce stade, nous devions constamment modifier la logique des scripts jusqu'à ce que le service soit OK. Mais il y avait une solution à cela. C'était SEC
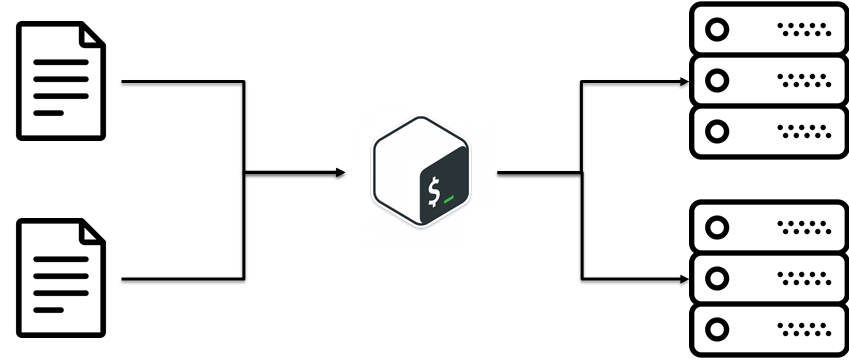
Il existe une approche SÈCHE (ne vous répétez pas). L'idée principale est de réutiliser du code déjà existant. Cela semble extrêmement simple. Dans notre cas, DRY signifiait: configurations et scripts séparés.
SOLIDE pour CFM

Le projet grandissait, nous avons donc décidé d'utiliser Ansible. Il y avait des raisons à cela:
- Bash ne doit pas contenir de logique complexe .
- Nous avions une certaine expertise dans Ansible.
Il y avait une quantité de logique métier dans le code Ansible. Il existe une approche pour mettre les choses dans le code source pendant le processus de développement logiciel. Il s'appelle SOLID . De mon point de vue, nous pouvons réutiliser SOLID for Infrastructure comme code . Laissez-moi vous expliquer étape par étape.
Le principe de responsabilité unique

Une classe ne devrait avoir qu'une seule responsabilité, c'est-à-dire que seules les modifications apportées à une partie de la spécification du logiciel devraient pouvoir affecter la spécification de la classe.
Vous ne devez pas créer de code spaghetti dans votre code d'infrastructure. Votre infrastructure doit être constituée de simples briques prévisibles. En d'autres termes, ce pourrait être une bonne idée de diviser l'immense livre de jeu Ansible en rôles Ansible indépendants. Il sera plus facile à entretenir.
Les principes ouvert-fermé
Les entités logicielles ... devraient être ouvertes pour extension, mais fermées pour modification.
Au début, nous déployions le SDS sur des machines virtuelles, un peu plus tard, nous avons ajouté le déploiement sur des serveurs bare metal . Nous l'avions fait. Cela a été aussi simple que facile pour nous car nous venons d'ajouter une implémentation pour des pièces spécifiques au métal nu sans modifier la logique d'installation de SDS.
Le principe de substitution de Liskov

Les objets d'un programme doivent être remplaçables par des instances de leurs sous-types sans altérer l'exactitude de ce programme.
Soyons ouverts d'esprit. SOLID est possible d'utiliser dans CFM en général, ce n'était pas un projet chanceux. Je voudrais décrire un autre projet. Il s'agit d'une solution d'entreprise prête à l'emploi. Il prend en charge différentes bases de données, serveurs d'applications et interfaces d'intégration avec des systèmes tiers. Je vais utiliser cet exemple pour décrire le reste de SOLID
Par exemple dans notre cas, il y a un accord au sein de l'équipe d'infrastructure: si vous déployez le rôle java ibm ou l'oracle java ou openjdk, vous aurez un exécutable java binaire. Nous en avons besoin car les rôles Ansible de niveau supérieur * en dépendent. En outre, cela nous permet d'échanger l'implémentation java sans modifier la logique d'installation des applications.
Malheureusement, il n'y a pas de sucre de syntaxe pour cela dans les playbooks Ansible. Cela signifie que vous devez en tenir compte lors du développement des rôles Ansible.
Le principe de ségrégation des interfaces
De nombreuses interfaces spécifiques au client valent mieux qu'une interface à usage général.
Au début, nous mettions la logique d'installation des applications dans le playbook unique, nous essayions de couvrir tous les cas et les tranchants. Nous avions fait face au problème qu'il est difficile de maintenir, alors nous avons changé notre approche. Nous avons compris qu'un client avait besoin d'une interface de notre part (c'est-à-dire https au port 443) et nous avons pu combiner nos rôles Ansible pour chaque environnement spécifique.
Le principe d'inversion de dépendance

Il faut "dépendre d'abstractions, pas de concrétions".
- Les modules de haut niveau ne doivent pas dépendre de modules de bas niveau. Les deux devraient dépendre d'abstractions (par exemple des interfaces).
- Les abstractions ne devraient pas dépendre des détails. Les détails (implémentations concrètes) doivent dépendre des abstractions.
Je voudrais décrire ce principe via anti-pattern.
- Il y avait un client avec un cloud privé.
- Nous demandions des machines virtuelles dans le cloud.
- Notre logique de déploiement dépendait de l'hyperviseur sur lequel une machine virtuelle était située.
En d'autres termes, nous n'avons pas pu réutiliser notre IaC dans un autre cloud car la logique de déploiement de niveau supérieur dépendait de l'implémentation de niveau inférieur. S'il te plait ne le fais pas
L'interaction

L'infrastructure n'est pas seulement du code, il s'agit aussi du code d'interaction <-> DevOps, DevOps <-> DevOps, IaC <-> personnes.
Facteur de bus
Imaginons, il y a l'ingénieur DevOps John. John sait tout sur votre infrastructure. Si John se fait heurter par un bus, qu'arrivera-t-il à votre infrastructure? Malheureusement, c'est presque un cas réel. Parfois, des choses se produisent. Si cela s'est produit et que vous ne partagez pas les connaissances sur l'IaC, l'infrastructure entre les membres de votre équipe, vous serez confronté à de nombreuses conséquences imprévisibles et délicates. Il existe certaines approches pour y faire face. Laissez-nous en parler.
Pair DevOpsing

C'est comme la programmation par paires. En d'autres termes, il y a deux ingénieurs DevOps et ils utilisent un seul ordinateur portable \ clavier pour configurer l'infrastructure: configurer un serveur, créer un rôle Ansible, etc. Cela semble génial, cependant, cela n'a pas fonctionné pour nous. Il y avait des cas personnalisés quand cela fonctionnait partiellement.
- Intégration : le mentor et la nouvelle personne obtiennent une tâche réelle à partir d'un carnet de commandes et travaillent ensemble - transfèrent les connaissances du mentor à la personne.
- Appel incident : Lors du dépannage, il y a un groupe d'ingénieurs, ils recherchent une solution. Le point clé est qu'il y a une personne qui dirige cet incident. La personne partage l'écran et les idées. D'autres personnes le suivent attentivement et remarquent les astuces bash, les erreurs, l'analyse des journaux, etc.
Examen du code
De mon point de vue, la révision de code est l'un des moyens les plus efficaces de partager des connaissances au sein d'une équipe sur votre infrastructure. Comment ça marche?
- Il existe un référentiel qui contient la description de votre infrastructure.
- Tout le monde fait ses changements dans une branche dédiée.
- Au cours de la demande de fusion, vous êtes en mesure d'examiner les changements de delta dans votre infrastructure.
La chose la plus intéressante est que nous faisions tourner un relecteur. Cela signifie que tous les deux jours, nous avons élu un nouvel examinateur et l'examinateur examinait toutes les demandes de fusion. Par conséquent, théoriquement, chaque personne devait toucher une nouvelle partie de l'infrastructure et avait une connaissance moyenne de notre infrastructure en général.
Style de code

Le temps avançait, nous nous disputions parfois lors de la révision car le réviseur et le committer pouvaient utiliser un style de code différent: 2 espaces ou 4, camelCase ou snake_case . Nous l'avons mis en œuvre, cependant, ce n'était pas un pique-nique.
- La première idée a été de recommander l'utilisation de linters. Chacun avait son propre environnement de développement: IDE, OS ... c'était difficile de tout synchroniser & unifier.
- L'idée a évolué en un robot lâche. Après chaque commit, le bot vérifiait le code source et poussait dans les messages lâches avec une liste de problèmes. Malheureusement, dans la grande majorité des cas, il n'y a eu aucun changement de code source après les messages.
Maître de la construction écologique
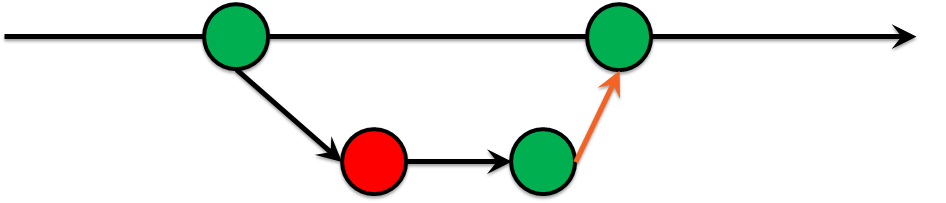
Ensuite, l'étape la plus douloureuse a été de restreindre la poussée à la branche principale pour tout le monde. Seulement via les demandes de fusion et les tests verts doivent être corrects. Cela s'appelle Green Build Master . En d'autres termes, vous êtes sûr à 100% que vous pouvez déployer votre infrastructure à partir de la branche principale. C'est une pratique assez courante dans le développement de logiciels:
- Il existe un référentiel qui contient la description de votre infrastructure.
- Tout le monde fait ses changements dans une branche dédiée.
- Pour chaque branche, nous effectuons des tests.
- Vous ne pouvez pas fusionner dans la branche principale si les tests échouent.
Ce fut une décision difficile. Espérons que, lors du processus de révision, il n'y ait eu aucune discussion sur le style de code et la quantité d'odeur de code diminuait.
Test IaC

Outre la vérification du style de code, vous pouvez vérifier que vous pouvez déployer ou recréer votre infrastructure dans un sandbox. À quoi ça sert? C'est une question sophistiquée et je voudrais partager une histoire au lieu d'une réponse. Était un scaler automatique personnalisé pour AWS écrit en Powershell. Le détartreur automatique n'a pas vérifié les paramètres de coupe pour les paramètres d'entrée, par conséquent, il a créé des tonnes de machines virtuelles et le client n'était pas satisfait. C'est une situation délicate, espérons-le, il est possible de l'attraper dès les premières étapes.
D'une part, il est possible de tester le script et l'infrastructure, mais d'autre part, vous augmentez la quantité de code et complexifiez l'infrastructure. Cependant, la vraie raison sous le capot est que vous mettez vos connaissances sur l'infrastructure à l'épreuve. Vous décrivez comment les choses devraient fonctionner ensemble.
Pyramide de test IaC

Tests IaC: analyse statique
Vous pouvez créer l'intégralité de l'infrastructure à partir de zéro pour chaque validation, mais, généralement, il existe certains obstacles:
- Le prix est stratosphérique.
- Cela demande beaucoup de temps.
Espérons qu'il y ait quelques astuces. Vous devriez avoir beaucoup de tests simples, rapides et primitifs dans votre fondation.
Bash est délicat
Prenons un exemple extrêmement simple. Je voudrais créer un script de sauvegarde:
- Récupère tous les fichiers du répertoire courant.
- Copiez les fichiers dans un autre répertoire avec un nom modifié.
La première idée est:
for i in * ; do cp $i /some/path/$i.bak done
Assez bien. Cependant, que se passe-t-il si le nom de fichier contient de l' espace ? Nous sommes des gars intelligents, nous utilisons des citations:
for i in * ; do cp "$i" "/some/path/$i.bak" done
Avons-nous fini? Non! Et si le répertoire est vide? Globing échoue dans ce cas.
find . -type f -exec mv -v {} dst/{}.bak \;
Avons-nous fini? Pas encore ... Nous avons oublié que le nom de fichier peut contenir \n caractère.
touch x mv x "$(printf "foo\nbar")" find . -type f -print0 | xargs -0 mv -t /path/to/target-dir
Vous pouvez intercepter certains problèmes de l'exemple précédent via Shellcheck . Il existe de nombreux outils de ce type, appelés linters, et vous pouvez trouver celui qui convient le mieux à votre IDE, à votre pile et à votre environnement.
Tests IaC: tests unitaires
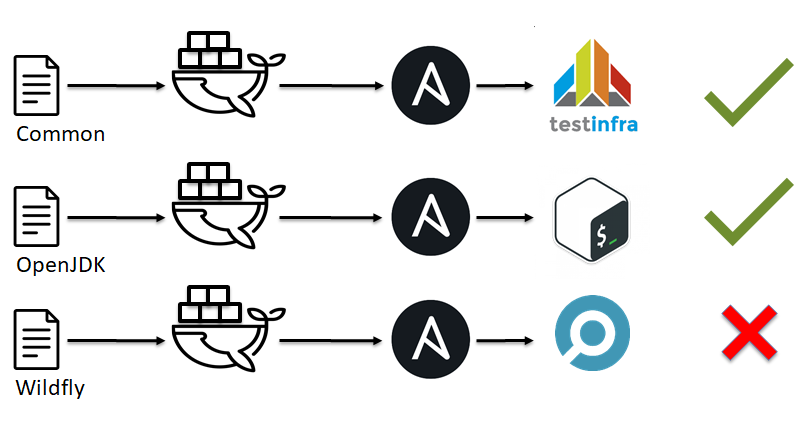
Comme vous pouvez le voir, les linters ne peuvent pas tout attraper, ils ne peuvent que prédire. Si nous continuons de penser aux parallèles entre le développement de logiciels et l'infrastructure en tant que code, nous devrions mentionner les tests unitaires. Il existe de nombreux systèmes de tests unitaires comme shunit , JUnit , RSpec , pytest . Mais avez-vous déjà entendu parler des tests unitaires pour Ansible, Chef, Saltstack, CFengine?
Lorsque nous parlions de SOLID for CFM, j'ai mentionné que notre infrastructure devait être faite de briques / modules simples. Le moment est maintenant venu:
- Divisez l'infrastructure en modules / coupures simples, c'est-à-dire des rôles Ansible.
- Créez un environnement, c'est-à-dire Docker ou VM.
- Appliquez votre unique rupture / module à l'environnement.
- Vérifiez que tout va bien ou non.
... - PROFIT!
Quel est le test pour CFM et votre infrastructure? c'est-à-dire que vous pouvez simplement exécuter un script ou utiliser une solution prête pour la production comme:
Jetons un œil à testinfra, je voudrais vérifier que les utilisateurs test1 , test2 existent et font partie du groupe sshusers :
def test_default_users(host): users = ['test1', 'test2' ] for login in users: assert host.user(login).exists assert 'sshusers' in host.user(login).groups
Quelle est la meilleure solution? Il n'y a pas de réponse unique à cette question, cependant, j'ai créé la carte de chaleur et comparé les changements dans ces projets au cours de 2018-2019:

Cadres de test IaC
Après cela, vous pouvez vous poser une question sur la façon de gérer tout cela ensemble? D'une part, vous pouvez tout faire par vous-même si vous avez suffisamment de grands ingénieurs, mais d'autre part, vous pouvez utiliser des solutions open source prêtes pour la production:
J'ai créé la carte de chaleur et comparé les changements de ces projets au cours de 2018-2019:

Molécule vs. Testkitchen

Au début, nous avons essayé de tester les rôles ansibles via testkitchen dans hyper-v :
- Créez des VM.
- Appliquer des rôles Ansible.
- Exécutez Inspec.
Il a fallu 40 à 70 minutes pour 25 à 35 rôles Ansible. C'était trop long pour nous.
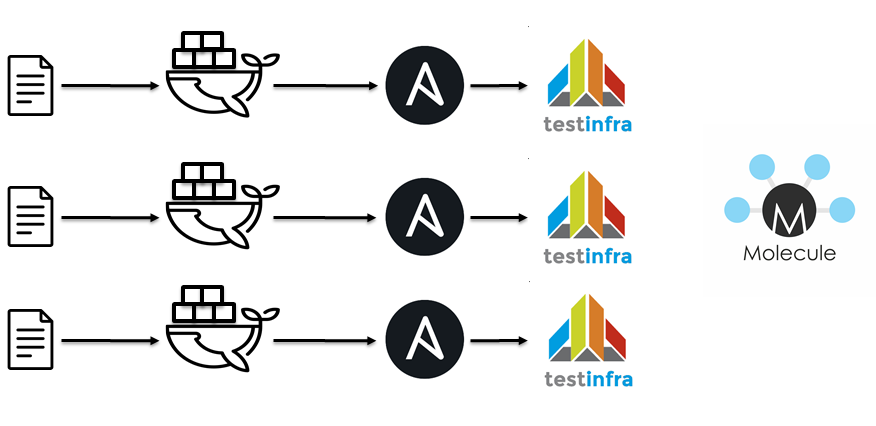
L'étape suivante consistait à utiliser Jenkins / docker / Ansible / molécule. C'est à peu près la même idée:
- Playbooks Lint Ansible.
- Rôles de Lint Ansible.
- Exécutez un conteneur Docker.
- Appliquer des rôles Ansible.
- Exécutez testinfra.
- Vérifiez l'idempotence.
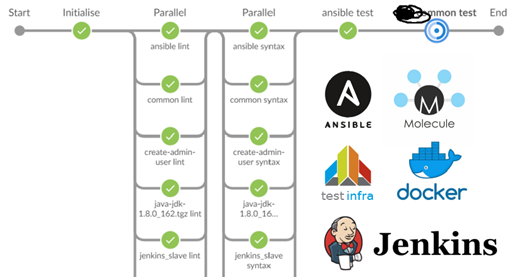
Linting pour 40 rôles et les tests pour dix d'entre eux ont pris environ 15 minutes.

Quelle est la meilleure solution? D'une part, je ne veux pas être l'autorité finale, mais d'autre part, je voudrais partager mon point de vue. Il n'y a pas de solution miracle, cependant, dans le cas où la molécule Ansible est une solution plus appropriée que la cuisine de test.
Tests IaC: tests d'intégration
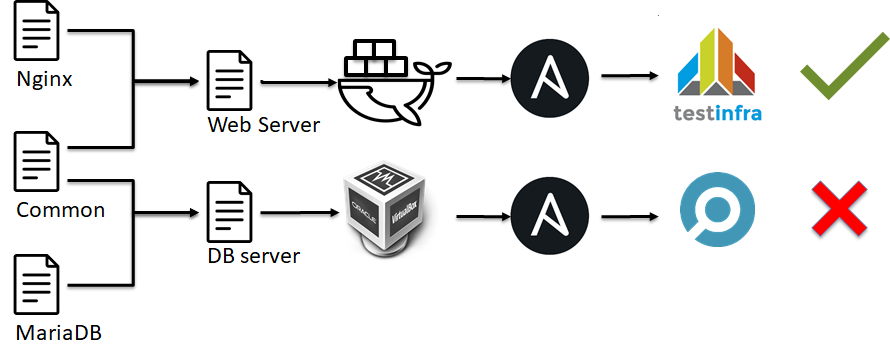
Au niveau suivant de la pyramide de tests IaC , il y a les tests d'intégration . Les tests d'intégration pour l'infrastructure ressemblent à des tests unitaires:
- Divisez l'infrastructure en modules / coupures simples, c'est-à-dire des rôles Ansible.
- Créez un environnement, c'est-à-dire Docker ou VM.
- Appliquer une combinaison de rupture / module simple à l'environnement.
- Vérifiez que tout va bien ou non.
... - PROFIT!
En d'autres termes, lors des tests unitaires, nous vérifions un module simple (ie rôle Ansible, script python, module Ansible, etc.) d'une infrastructure, mais dans le cas des tests d'intégration, nous vérifions la configuration complète du serveur.
Tests IaC: tests de bout en bout
En plus de la pyramide des tests IaC , il existe des tests de bout en bout . Dans ce cas, nous ne vérifions pas le serveur dédié, le script, le module de notre infrastructure; Nous vérifions que l'ensemble de l'infrastructure fonctionne correctement. Malheureusement, il n'y a pas de solution prête à l'emploi pour cela ou je n'en ai pas entendu parler (veuillez me signaler si vous les connaissez). Habituellement, les gens réinventent la roue, car il y a une demande de tests de bout en bout pour les infrastructures. Donc, je voudrais partager mon expérience, j'espère qu'elle sera utile à quelqu'un.
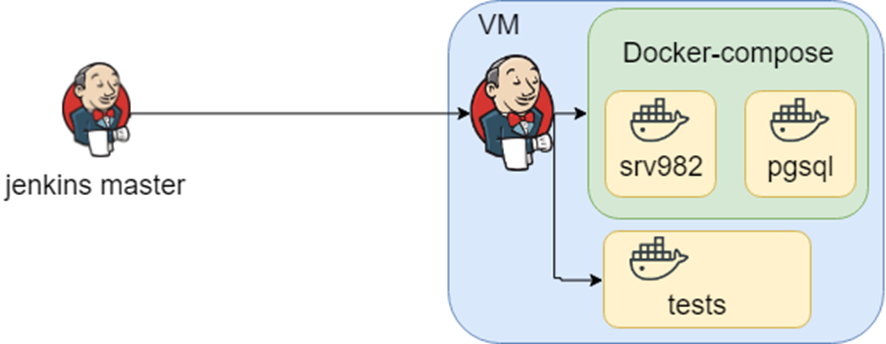
Tout d'abord, je voudrais décrire le contexte. Il s'agit d'une solution d'entreprise prête à l'emploi, elle prend en charge différentes bases de données, serveurs d'applications et interfaces d'intégration avec des systèmes tiers. Habituellement, nos clients sont une immense entreprise avec un environnement complètement différent. Nous avons des connaissances sur les différentes combinaisons d'environnements et nous les stockons dans différents fichiers de composition de docker. En outre, il existe une correspondance entre les fichiers de composition docker et les tests, nous les stockons en tant que travaux Jenkins.
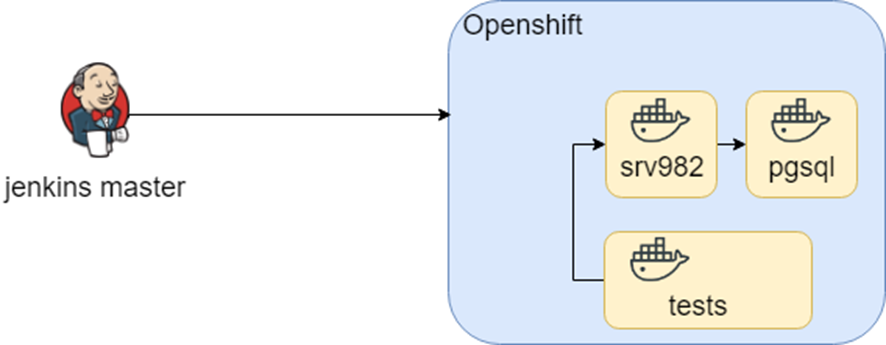
Ce schéma fonctionnait pendant une période de temps calme et logicielle lorsque, au cours de la recherche OpenShift, nous avons essayé de le migrer vers OpenShift. Nous avons utilisé à peu près les mêmes conteneurs (encore une fois DRY) et nous avons uniquement changé l'environnement.
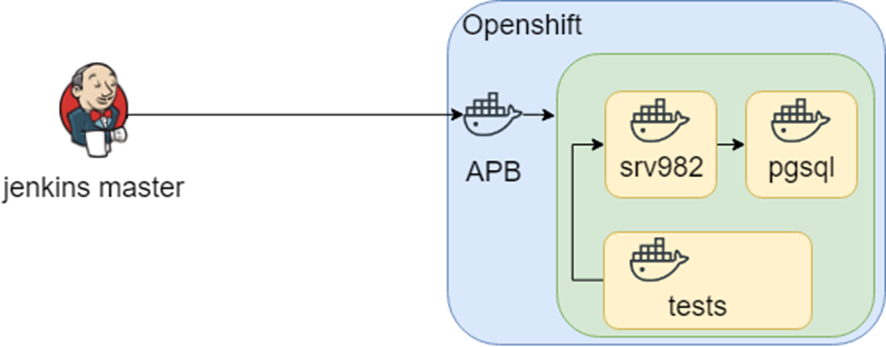
Nous continuons à rechercher et à trouver APB (Ansible Playbook Bundle). L'idée principale est que vous emballiez toutes les choses nécessaires dans un conteneur et que vous exécutiez le conteneur dans Openshift. Cela signifie que vous disposez d'une solution reproductible et testable.

Tout allait bien jusqu'à ce que nous rencontrions un autre problème: nous devions maintenir une infrastructure hétérogène pour les environnements de test. En conséquence, nous stockons nos connaissances sur la façon de créer une infrastructure et d'exécuter des tests dans les travaux Jenkins.
Conclusion
L'infrastructure en tant que code est une combinaison de:
- Code
- Interaction avec les gens.
- Test d'infrastructure.