L' approche IaC (Infrastructure as Code) se compose non seulement du code stocké dans le référentiel, mais également des personnes et des processus qui entourent ce code. Est-il possible de réutiliser des approches allant du développement logiciel à la gestion et à la description de l'infrastructure? Il ne sera pas superflu de garder cette idée à l'esprit lorsque vous lirez l'article.
Version russe
Ceci est une transcription de ma performance à DevopsConf 2019-05-28 .
L'infrastructure comme histoire bash

Supposons que vous arriviez à un nouveau projet et qu'ils vous disent: "nous avons l' infrastructure comme code ." En réalité, il s'avère, Infrastructure comme histoire bash ou par exemple Documentation comme histoire bash . C'est une situation très réelle, par exemple, un cas similaire a été décrit par Denis Lysenko dans son discours Comment remplacer toute l'infrastructure et commencer à dormir paisiblement , il a expliqué comment, grâce à l'histoire bash, ils ont obtenu une infrastructure mince sur le projet.
Si vous le souhaitez, vous pouvez dire que l' infrastructure en tant qu'historique bash est comme du code:
- reproductibilité : vous pouvez prendre l'historique bash, exécuter des commandes à partir de là, peut-être, en passant, vous obtiendrez une configuration de travail à la sortie.
- versionnage : vous savez qui est entré et ce qui a fait, encore une fois, pas le fait que cela vous conduira à une configuration de travail sur la sortie.
- histoire : histoire de qui a fait quoi. vous ne pouvez l’utiliser que si vous perdez le serveur.
Que faire?
L'infrastructure comme code
Même un cas aussi étrange que Infrastructure en tant qu'historique bash peut être tiré par les oreilles vers Infrastructure en tant que code , mais lorsque nous voulons faire quelque chose de plus compliqué que le bon vieux serveur LAMP, nous arriverons à la conclusion que ce code doit être modifié, modifié, modifié d'une manière ou d'une autre . De plus, nous aimerions considérer les parallèles entre l' infrastructure en tant que code et le développement de logiciels.
SEC
Sur le projet de développement de systèmes de stockage, il y avait une sous-tâche pour configurer périodiquement SDS : nous publions une nouvelle version - elle doit être déployée pour des tests supplémentaires. La tâche est extrêmement simple:
- venez ici par ssh et exécutez la commande.
- copiez-y le fichier.
- voici un tweak à la config.
- démarrer le service là-bas
- ...
- PROFIT!
Bash est plus que suffisant pour la logique décrite, en particulier dans les premiers stades d'un projet lorsqu'il ne fait que commencer. Ce n'est pas mal que vous utilisiez bash , mais au fil du temps, vous êtes invité à déployer quelque chose de similaire, mais légèrement différent. La première chose qui me vient à l'esprit: le copier-coller. Et maintenant, nous avons deux scripts très similaires qui font presque la même chose. Au fil du temps, le nombre de scripts a augmenté, et nous sommes confrontés au fait qu'il existe une certaine logique métier pour le déploiement de l'installation, qui doit être synchronisée entre différents scripts, c'est assez difficile.
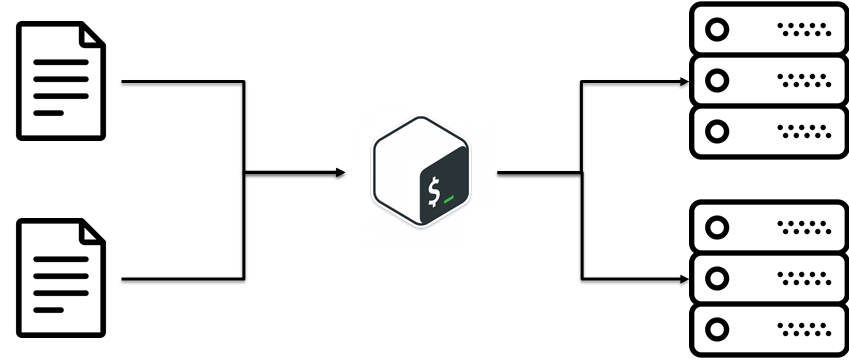
Il s'avère qu'il existe une telle pratique SECHE (ne vous répétez pas). L'idée est de réutiliser le code existant. Cela semble simple, mais ce n'est pas venu tout de suite. Dans notre cas, c'était une idée courante: séparer les configurations des scripts. C'est-à-dire logique métier comment l'installation est déployée séparément, configure séparément.
SOLIDE pour CFM

Au fil du temps, le projet a grandi et une extension naturelle a été l'émergence d'Ansible. La raison principale de son apparition est la présence d'une expertise dans l'équipe et ce bash n'est pas destiné à une logique complexe. Ansible a également commencé à contenir une logique complexe. Pour que la logique complexe ne se transforme pas en chaos, il existe des principes d'organisation du code SOLIDE dans le développement de logiciels. Par exemple, Grigory Petrov dans son rapport «Pourquoi les TI ont-ils besoin d'une marque personnelle» a soulevé la question qu'une personne est tellement conçue qu'il est plus facile de fonctionner avec certains les entités sociales, dans le développement de logiciels ce sont des objets. Si vous combinez ces deux idées et continuez à les développer, vous remarquerez que vous pouvez également utiliser SOLID dans la description de l'infrastructure afin qu'il soit plus facile de maintenir et de modifier cette logique à l'avenir.
Le principe de responsabilité unique

Chaque classe n'effectue qu'une seule tâche.
Pas besoin de mélanger le code et de faire des monstres de pâtes divines monolithiques. L'infrastructure doit être constituée de briques simples. Il s'avère que si vous divisez le livre de jeu Ansible en petits morceaux, lisez les rôles Ansible, alors ils sont plus faciles à maintenir.
Les principes ouverts fermés
Le principe d'ouverture / de proximité.
- Ouvert pour l'expansion: signifie que le comportement d'une entité peut être étendu en créant de nouveaux types d'entités.
- Fermé pour modification: suite à l'extension du comportement d'une entité, aucune modification ne doit être apportée au code qui utilise ces entités.
Au départ, nous avons déployé l'infrastructure de test sur des machines virtuelles, mais en raison du fait que la logique de déploiement métier était distincte de l'implémentation, nous avons facilement ajouté un roulement au bare-metall.
Le principe de substitution de Liskov

Le principe de substitution de Barbara Liskov. les objets du programme doivent être remplaçables par des instances de leurs sous-types sans modifier l'exactitude du programme
Si vous regardez plus largement, ce n'est pas une caractéristique d'un projet particulier que vous pouvez appliquer SOLID , il s'agit généralement de CFM, par exemple, sur un autre projet, vous devez déployer une application Java en boîte au-dessus de divers Java, serveurs d'applications, bases de données, OS, etc. Pour cet exemple, je considérerai d'autres principes SOLID .
Dans notre cas, en tant que membre de l'équipe d'infrastructure, il y a un accord que si nous avons installé le rôle d'imbjava ou d'oraclejava, nous avons alors un exécutable java binaire. Ceci est nécessaire car les rôles supérieurs dépendent de ce comportement; ils s'attendent à ce que java soit présent. En même temps, cela nous permet de remplacer une implémentation / version de java par une autre sans changer la logique de déploiement de l'application.
Le problème ici réside dans le fait que dans Ansible, il est impossible de mettre en œuvre de tels, par conséquent, certains accords apparaissent au sein de l'équipe.
Le principe de ségrégation des interfaces
Le principe de la séparation des interfaces «de nombreuses interfaces spécialement conçues pour les clients sont meilleures qu'une seule interface à usage général.
Initialement, nous avons essayé de mettre toutes les variantes dans le déploiement de l'application dans un playbook Ansible, mais c'était difficile à prendre en charge, et l'approche lorsque nous avons une interface en sortie (le client attend le port 443) est spécifiée, puis pour une implémentation spécifique, vous pouvez construire l'infrastructure à partir de briques distinctes.
Le principe d'inversion de dépendance

Le principe de l'inversion de dépendance. Les modules de niveau supérieur ne doivent pas dépendre de modules de niveau inférieur. Les deux types de modules doivent dépendre d'abstractions. Les abstractions ne devraient pas dépendre des détails. Les détails doivent dépendre des abstractions.
Ici, l'exemple sera basé sur antipattern.
- L'un des clients disposait d'un cloud privé.
- À l'intérieur du cloud, nous avons commandé des machines virtuelles.
- Mais compte tenu des fonctionnalités du cloud, le déploiement de l'application était lié à l'hyperviseur sur lequel se trouvait la machine virtuelle.
C'est-à-dire logique de déploiement d'applications de haut niveau, les dépendances se sont propagées aux niveaux inférieurs de l'hyperviseur, ce qui a entraîné des problèmes lors de la réutilisation de cette logique. Ne fais pas ça.
L'interaction

L'infrastructure en tant que code ne concerne pas seulement le code, mais aussi la relation entre le code et une personne, les interactions entre les développeurs de l'infrastructure.
Facteur de bus
Supposons que Vasya participe au projet. Vasya sait tout sur votre infrastructure, que se passera-t-il si Vasya disparaît soudainement? C'est une situation très réelle, car elle peut être heurtée par un bus. Cela arrive parfois. Si cela se produit et que les connaissances sur le code, sa structure, son fonctionnement, ses apparences et ses mots de passe ne sont pas distribués dans l'équipe, vous pouvez rencontrer un certain nombre de situations désagréables. Différentes approches peuvent être utilisées pour minimiser ces risques et diffuser les connaissances au sein de l'équipe.
Paire devopsing

Ce n'est pas comme une blague selon laquelle les administrateurs ont bu de la bière, changé de mot de passe, mais un analogue de la programmation par paires. C'est-à-dire deux ingénieurs s'assoient devant un ordinateur, un clavier et commencent à configurer ensemble votre infrastructure: configurer le serveur, écrire le rôle Ansible, etc. Cela semble bien, mais cela n'a pas fonctionné pour nous. Mais les cas particuliers de cette pratique ont fonctionné. Un nouvel employé est venu, son mentor prend une vraie tâche avec lui, travaille, transfère des connaissances.
Un autre cas particulier est un appel incident. Pendant le problème, un groupe de personnes de service et des rassemblements impliqués, un leader est nommé, qui partage son écran et exprime le courant de la pensée. Les autres participants suivent la pensée du leader, espionnent les astuces depuis la console, vérifient qu’ils n’ont pas manqué une ligne dans le journal, apprennent de nouvelles choses sur le système. Cette approche a fonctionné plutôt que non.
Examen du code
Subjectivement, plus efficacement, la diffusion des connaissances sur l'infrastructure et la façon dont elle a été organisée a été réalisée à l'aide de la révision du code:
- L'infrastructure est décrite par du code dans le référentiel.
- Les changements se produisent dans une branche distincte.
- Avec une demande de fusion, vous pouvez voir le delta des changements dans l'infrastructure.
Le fait saillant ici est que les examinateurs ont été sélectionnés à tour de rôle, selon le calendrier, c'est-à-dire avec une certaine probabilité, vous monterez dans une nouvelle infrastructure.
Style de code

Au fil du temps, des querelles ont commencé à apparaître au cours de l'examen, les examinateurs avaient leur propre style et leur propre rotation, les examinateurs les ont empilés avec différents styles: 2 espaces ou 4, camelCase ou snake_case. Mettre en œuvre cela n'a pas fonctionné tout de suite.
- La première idée était de recommander l'utilisation de linter, car tous les mêmes ingénieurs, tous intelligents. Mais différents éditeurs, OS, pas pratique
- Cela a évolué en un bot, qui pour chaque commit s'est engagé dans la problématique, écrit en slack, et a appliqué la sortie de linter. Mais dans la plupart des cas, des problèmes plus importants ont été trouvés et le code n'est pas resté fixe.
Maître de la construction écologique
Le temps passe et nous sommes arrivés à la conclusion que vous ne devez pas autoriser les validations qui ne réussissent pas certains tests dans le maître. Voila! nous avons inventé le Green Build Master, qui a longtemps été pratiqué dans le développement de logiciels:
- Le développement est dans une branche distincte.
- Les tests s'exécutent sur ce fil.
- Si les tests échouent, le code n'entrera pas dans l'assistant.
Prendre cette décision a été très douloureux car causé beaucoup de controverse, mais cela en valait la peine, car les demandes de fusion ont commencé à être examinées sans désaccord sur le style et avec le temps, le nombre de problèmes a commencé à diminuer.
Test IaC

En plus de la vérification du style, vous pouvez utiliser d'autres éléments, par exemple, pour vérifier que votre infrastructure peut vraiment être déployée. Ou vérifiez que les changements d'infrastructure n'entraîneront pas de perte d'argent. Pourquoi cela pourrait-il être nécessaire? La question est complexe et philosophique, il vaut mieux répondre avec le récit qu'il y avait en quelque sorte un auto-scaler sur Powershell qui n'a pas vérifié les conditions aux limites => plus de machines virtuelles ont été créées que nécessaire => le client a dépensé plus d'argent que prévu. Ce n'est pas assez agréable, mais il serait tout à fait réaliste de détecter cette erreur à des stades antérieurs.
On peut se demander pourquoi rendre une infrastructure complexe encore plus difficile? Les tests pour l'infrastructure, ainsi que pour le code, ne concernent pas la simplification, mais la connaissance du fonctionnement de votre infrastructure.
Pyramide de test IaC

Tests IaC: analyse statique
Si vous déployez immédiatement l'ensemble de l'infrastructure et vérifiez qu'elle fonctionne, il peut s'avérer que cela prend beaucoup de temps et nécessite beaucoup de temps. Par conséquent, la base devrait être quelque chose qui fonctionne rapidement, c'est beaucoup et elle couvre de nombreux endroits primitifs.
Bash est délicat
Voici un exemple trivial. sélectionnez tous les fichiers du répertoire actuel et copiez-les vers un autre emplacement. La première chose qui me vient à l'esprit:
for i in * ; do cp $i /some/path/$i.bak done
Mais que faire s'il y a un espace dans le nom du fichier? Eh bien, ok, nous sommes intelligents, nous pouvons utiliser des guillemets:
for i in * ; do cp "$i" "/some/path/$i.bak" ; done
Bravo? non! Et s'il n'y a rien dans le répertoire, c'est-à-dire Globbing ne fonctionnera pas.
find . -type f -exec mv -v {} dst/{}.bak \;
Maintenant bien joué? pas ... J'ai oublié que le nom du fichier peut être \n .
touch x mv x "$(printf "foo\nbar")" find . -type f -print0 | xargs -0 mv -t /path/to/target-dir
Le problème de l'étape précédente a pu être détecté lorsque nous avons oublié les citations, car dans la nature, il existe de nombreux outils Shellcheck , il y en a beaucoup, et très probablement, vous pouvez trouver une doublure pour votre pile sous votre IDE.
Tests IaC: tests unitaires
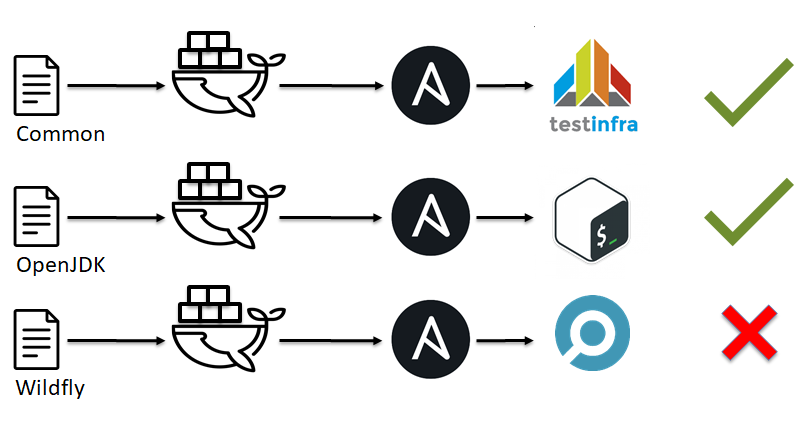
Comme nous l'avons vu dans l'exemple précédent, linter n'est pas omnipotent et ne peut pas pointer vers toutes les zones problématiques. De plus, par analogie avec les tests de développement logiciel, on peut rappeler les tests unitaires. Puis shunit , junit , rspec , pytest viennent immédiatement à l'esprit. Mais que faire de l'ansible, du chef, du saltstack et d'autres comme eux?
Au tout début, nous avons parlé de SOLID et du fait que notre infrastructure doit être constituée de petites briques. Leur heure est venue.
- L'infrastructure est écrasée en petites briques, par exemple, les rôles Ansible.
- Une sorte d'environnement se déroule, que ce soit docker ou VM.
- Nous appliquons notre rôle Ansible à cet environnement de test.
- Nous vérifions que tout a fonctionné comme prévu (exécutez les tests).
- Nous décidons ok ou pas ok.
La question est, quels sont les tests pour CFM? vous pouvez exécuter le script ringard, ou vous pouvez utiliser des solutions prêtes à l'emploi pour cela:
Exemple pour testinfra, nous vérifions que les utilisateurs test1 , test2 existent et sont dans le groupe sshusers :
def test_default_users(host): users = ['test1', 'test2' ] for login in users: assert host.user(login).exists assert 'sshusers' in host.user(login).groups
Que choisir? La question est complexe et ambiguë, voici un exemple de changement de projets sur github pour 2018-2019:

Cadres de test IaC
Il y a comment mettre tout cela ensemble et courir? Vous pouvez prendre et faire tout vous - même si vous avez un nombre suffisant d'ingénieurs. Et vous pouvez prendre des solutions toutes faites, bien qu'il n'y en ait pas beaucoup:
Un exemple de changement de projets sur github pour 2018-2019:

Molécule vs. Testkitchen

Au départ, nous avons essayé d'utiliser testkitchen :
- Créez des VM en parallèle.
- Appliquer des rôles Ansible.
- Éloignez l'inspec.
Pour 25 à 35 rôles, cela a fonctionné pendant 40 à 70 minutes, ce qui était long.
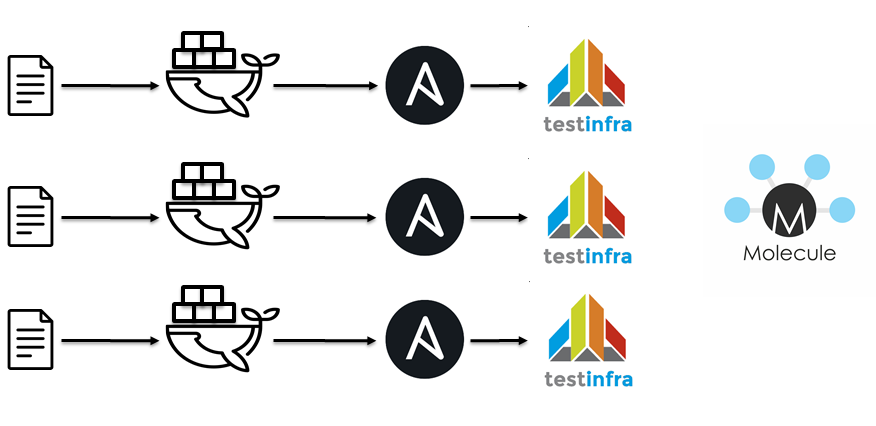
L'étape suivante consistait à passer à jenkins / docker / ansible / molécule. Idiologiquement, tout est pareil
- Playbooks de peluches.
- Pour renverser les rôles.
- Exécuter le conteneur
- Appliquer des rôles Ansible.
- Éloignez-vous de testinfra.
- Vérifiez l'idempotence.
Une règle pour 40 rôles et des tests pour une douzaine ont commencé à prendre environ 15 minutes.

Le choix dépend de nombreux facteurs, tels que la pile utilisée, l'expertise de l'équipe, etc. ici, tout le monde décide comment clore le problème des tests unitaires
Tests IaC: tests d'intégration
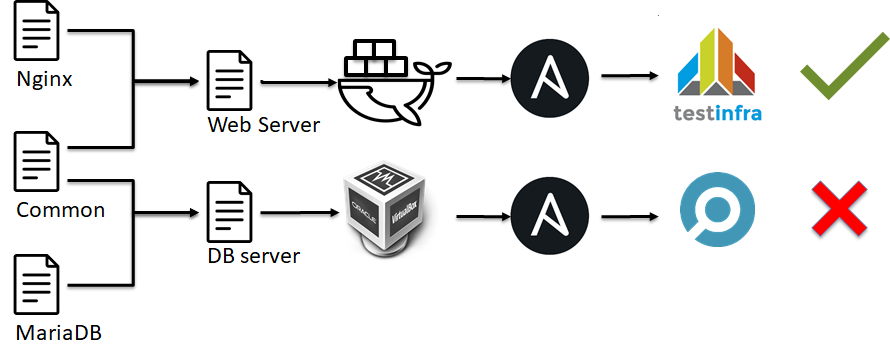
À l'étape suivante de la pyramide des tests d'infrastructure, des tests d'intégration apparaîtront. Ils sont similaires aux tests unitaires:
- L'infrastructure est écrasée en petites briques, comme les rôles Ansible.
- Une sorte d'environnement se déroule, que ce soit docker ou VM.
- Il existe de nombreux rôles Ansible appliqués à cet environnement de test.
- Nous vérifions que tout a fonctionné comme prévu (exécutez les tests).
- Nous décidons ok ou pas ok.
En gros, nous ne vérifions pas l'opérabilité d'un élément individuel du système comme dans les tests unitaires, nous vérifions comment le serveur est configuré dans son ensemble.
Tests IaC: tests de bout en bout
Au sommet de la pyramide, nous rencontrons des tests de bout en bout. C'est-à-dire nous ne vérifions pas le fonctionnement d'un serveur distinct, d'un script distinct, d'une brique distincte de notre infrastructure. Nous vérifions que de nombreux serveurs sont combinés ensemble, notre infrastructure fonctionne comme prévu. Malheureusement, je n'ai vu aucune solution de boîte prête à l'emploi, probablement parce que l'infrastructure est souvent unique et difficile à modéliser et à créer un cadre pour la tester. En conséquence, chacun crée sa propre solution. Il y a une demande, mais il n'y a pas de réponse. Par conséquent, je vais vous dire ce qui est là pour inciter les autres à sonder les pensées ou à me piquer le nez, que tout a été inventé bien avant nous.
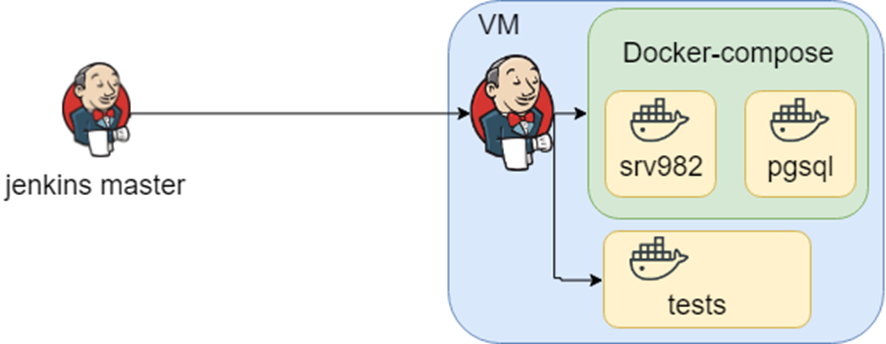
Un projet avec une histoire riche. Utilisé dans de grandes organisations et probablement chacun de vous s'est indirectement recoupé. L'application prend en charge de nombreuses bases de données, intégrations, etc., etc. Savoir à quoi peut ressembler l'infrastructure représente beaucoup de fichiers de composition de docker et savoir quels tests exécuter dans quel environnement est jenkins.
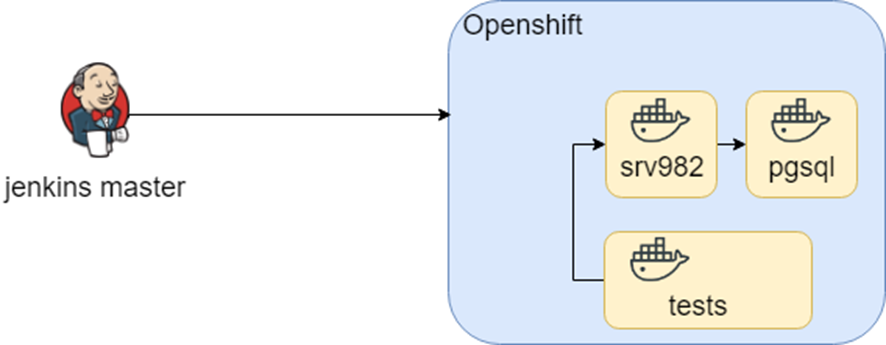
Ce schéma a fonctionné pendant longtemps, jusqu'à ce que dans le cadre de l' étude, nous tentions de le transférer vers Openshift. Les conteneurs sont restés les mêmes, mais l'environnement de lancement a changé (bonjour DRY à nouveau).
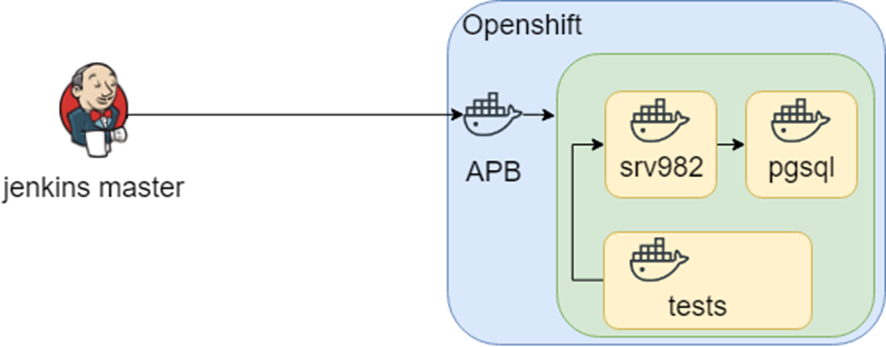
L'idée de la recherche est allée plus loin, et dans openshift, il y avait une telle chose APB (Ansible Playbook Bundle) qui vous permet de regrouper les connaissances dans un conteneur sur la façon de déployer l'infrastructure. C'est-à-dire Il existe un point de connaissance reproductible et testable sur la façon de déployer l'infrastructure.

Tout cela sonnait bien, jusqu'à ce que nous nous enfouissions dans une infrastructure hétérogène: nous avions besoin de Windows pour les tests. Par conséquent, la connaissance de l'emplacement de déploiement et de test se trouve dans Jenkins.
Conclusion
Infrastructure comme le code est
- Le code dans le référentiel.
- L'interaction des personnes.
- Test d'infrastructure.