Dans le
premier article de la série, j'ai activement promu l'idée que le développement de code pour Redd est secondaire et que le projet principal est principal. Redd est un outil auxiliaire, donc y consacrer beaucoup de temps est faux. Autrement dit, le développement pour cela devrait aller rapidement. Mais cela ne signifie pas du tout que les programmes qui en résultent ne devraient pas être optimaux. En fait, s'ils ne sont pas optimisés du tout, alors la puissance de l'équipement ne sera pas suffisante pour mettre en œuvre le système de test souhaité. Par conséquent, le processus, comme je l'ai dit, doit être rapide et facile, mais le développeur doit toujours garder à l'esprit certains principes d'optimisation.
Des livres épais ont été publiés sur l'optimisation. Certains de ces livres sont utiles, d'autres sont déjà dépassés, car les principes qui y sont décrits ont longtemps migré vers l'étape d'optimisation automatique lors de la construction du code ... Mais il y a des choses qui n'ont aucune valeur lors du développement de programmes ordinaires pour des processeurs ordinaires, donc les livres typiques ne décrivent généralement pas . Nous allons maintenant commencer à les considérer.
Présentation
Jusqu'à présent, j'écrivais sur le principe «un problème - un article». Et les articles ont été obtenus sous forme de conférences, touchant plusieurs sujets à la fois, unis par un problème commun. Mais certains lecteurs ont déclaré que de tels articles ne pouvaient pas être lus en une seule fois. Par conséquent, nous allons maintenant essayer de parler d'un seul sujet dans un article. C’est aussi plus facile pour moi d’écrire comme ça. Voyons, ce sera soudainement plus pratique pour tout le monde.
De plus, ravissez les mystérieux mineurs. Si un article est publié le matin, le premier inconvénient arrive après une période de temps pendant laquelle il est impossible de lire l'intégralité du texte. Quelqu'un le fait uniquement par principe, en n'épargnant que des sujets sur l'UDB et la balalaïka. Si la publication n'était pas le matin, mais l'après-midi, alors il jette un moins avec un retard. Le deuxième inconvénient arrive pendant la journée (et cet ami, en passant, a également épargné des sujets sur l'UDB et sur la balalaïka). Dans le nouveau format, il y aura plus d'articles, ce qui signifie des moments plus agréables pour ce couple (bien que, personnellement pour moi, en tant qu'auteur, cela devienne triste et insultant de leurs actions).
Articles précédents de la série:
- Développement du «firmware» le plus simple pour les FPGA installés dans Redd, et débogage en utilisant le test de mémoire comme exemple.
- Développement du «firmware» le plus simple pour les FPGA installés dans Redd. Partie 2. Code de programme.
- Développement de son propre noyau pour l'intégration dans un système de processeur FPGA.
- Développement de programmes pour le processeur central Redd sur l'exemple d'accès au FPGA.
- Les premières expériences utilisant le protocole de streaming sur l'exemple de la connexion du CPU et du processeur dans le FPGA du complexe Redd.
- Joyeux Quartusel, ou comment le processeur est arrivé à une telle vie.
Comportement mystérieux d'un système typique
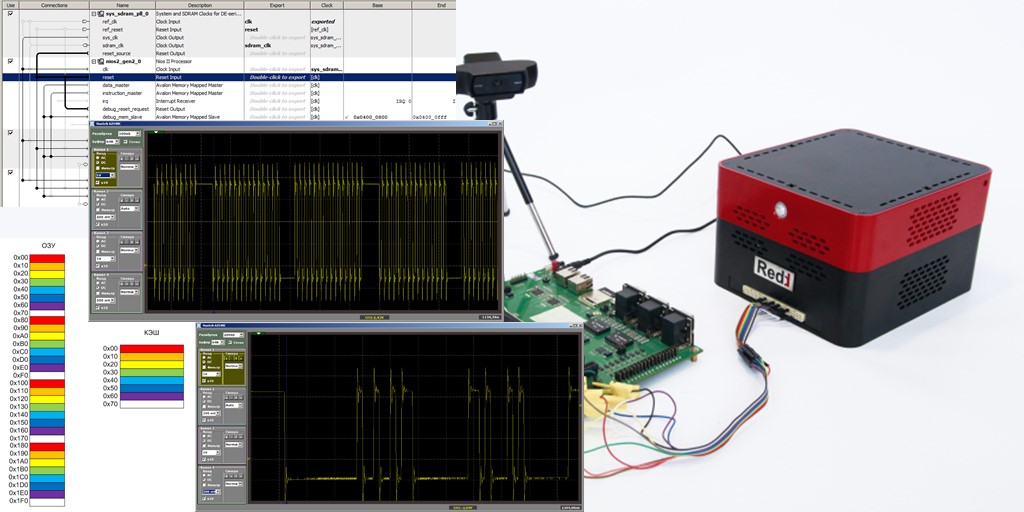
Faisons le système de processeur le plus simple en incluant une horloge, un processeur Nios II / f, un contrôleur SDRAM et un port de sortie. Voilà à quoi ressemble ce système Spartan dans Platform Designer
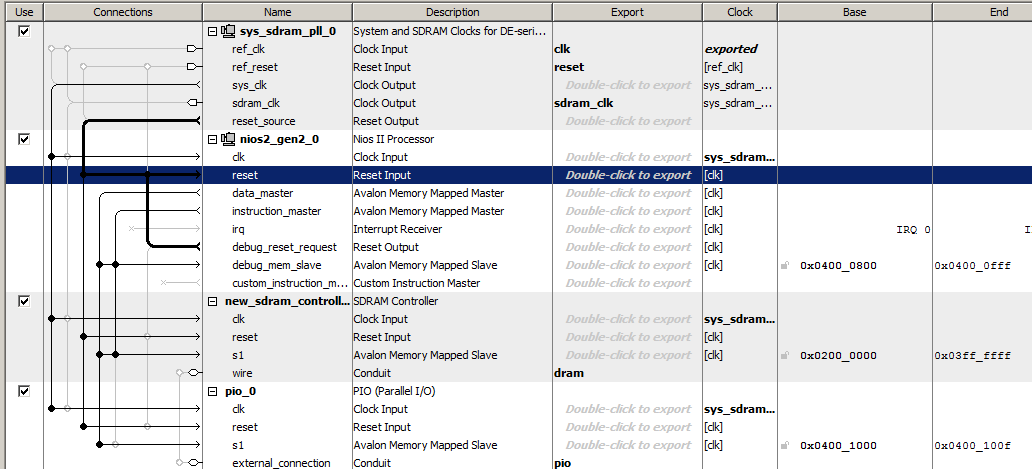
Le code du programme ne contiendra qu'une seule fonction, dont le corps semble quelque peu étrange, car il contient de nombreuses lignes répétitives, mais cela nous sera utile.
Le code est caché car il est trop serré.extern "C" { #include "sys/alt_stdio.h" #include <system.h> #include <io.h> } void MagicFunction() { while (1) { IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); } } int main() { MagicFunction(); /* Event loop never exits. */ while (1); return 0; }
Mettez un point d'arrêt sur la dernière des lignes:
IOWR (PIO_0_BASE,0,0);
dans la fonction
MagicFunction et exécutez le programme. Qu'avons-nous obtenu à la sortie du port? Impulsions très irrégulières:
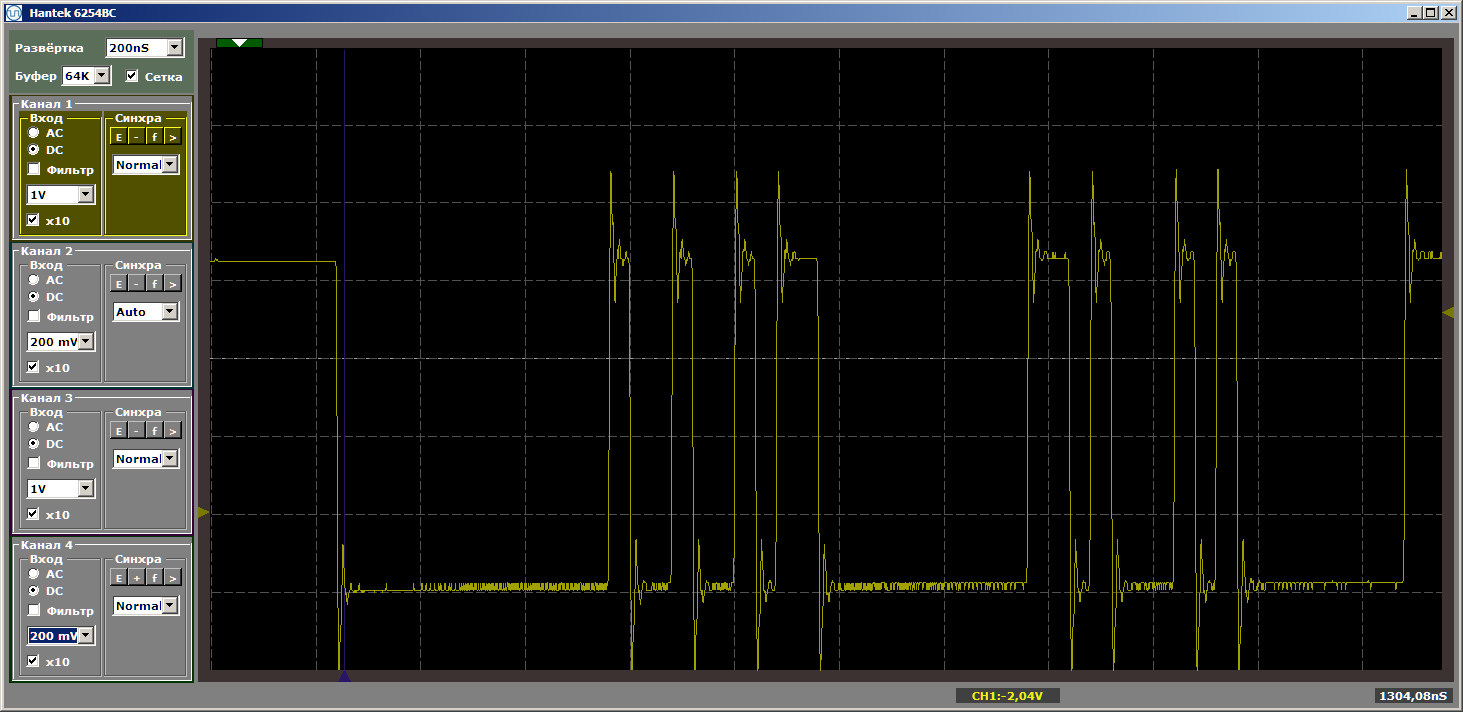
L'horreur Et bien oui. Cependant, cliquez à nouveau sur le «lancement» pour terminer une autre itération de la boucle. Et maintenant, à la sortie, nous voyons un beau méandre lisse:
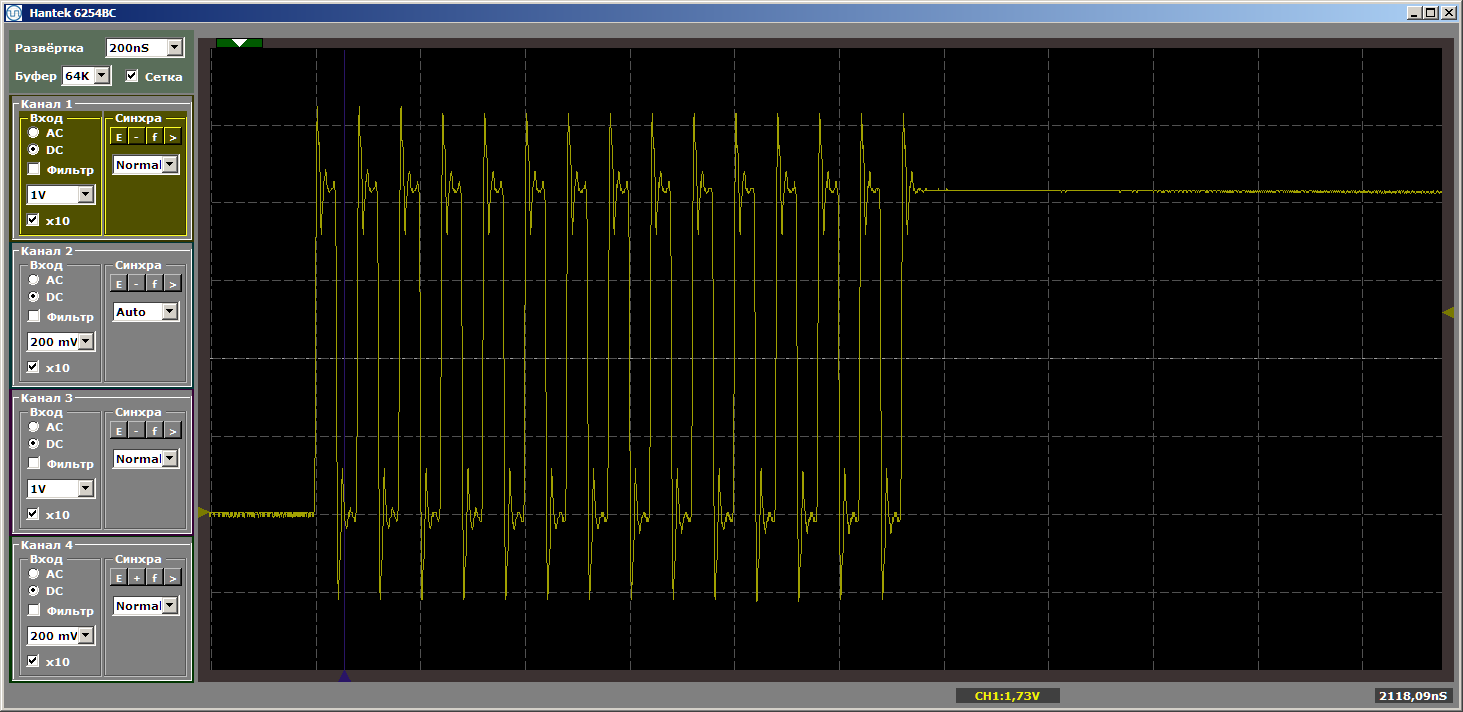
Une autre itération. Et un de plus ... Méandre stable. Nous supprimons le point d'arrêt et observons le travail en dynamique - il n'y a plus de telles ruptures. Il y a une infinité d'impulsions.
Pourquoi avons-nous eu des impulsions déchirées lors de la première passe? Un accident? Non. Nous arrêtons le débogage et le redémarrons. Et encore une fois, nous obtenons des impulsions déchirées. Des lacunes apparaissent toujours à l'entrée du programme.
L'indice réside dans la cache
En fait, la solution à ce problème réside dans le cache. Notre programme est stocké dans SDRAM. La récupération de code à partir de la SDRAM n'est pas rapide. Il est nécessaire de donner une commande de lecture, il est nécessaire de donner une adresse, et l'adresse se compose de deux parties. Il faut attendre un peu. Ce n'est qu'alors que le microcircuit donnera les données. Afin d'éviter de tels retards à chaque fois, le microcircuit peut émettre non pas un, mais plusieurs mots consécutifs. Nous ne considérerons pas les chronogrammes aujourd'hui, nous le reporterons pour les articles suivants.
Eh bien, côté processeur, un cache a été créé par défaut. Voici ses paramètres:
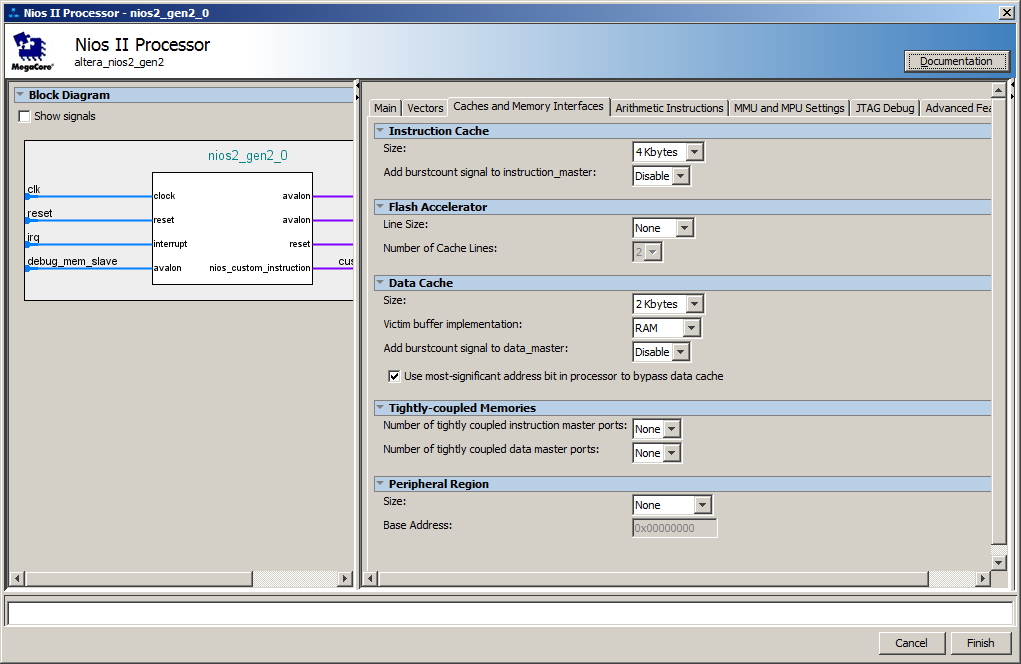
En fait, des retards se produisent au moment où le chargement par lots des instructions de la SDRAM vers le cache est en cours. Aux prochaines itérations, le code est déjà dans le cache, donc le chargement n'est plus requis.
L'oscillogramme montre une moyenne de 8 entrées par port (une unité est écrite 4 fois et zéro est écrite 4 fois) par opération de chargement. Un enregistrement - une commande d'assembleur, qui peut être trouvée en choisissant l'élément de menu Fenêtre-> Afficher la vue-> Autre:
puis Debug-> Disassembly:
Voici nos chaînes et le code d'assemblage correspondant:
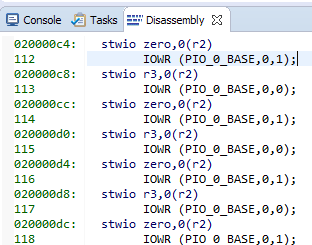
8 équipes de 4 octets chacune. Nous obtenons 32 octets par ligne de cache ... Nous regardons notre fichier d'aide préféré C: \ Work \ CachePlay \ software \ CachePlay_bsp \ system.h et voyons:
#define ALT_CPU_ICACHE_LINE_SIZE 32 #define ALT_CPU_ICACHE_LINE_SIZE_LOG2 5
Les données pratiquement calculées coïncidaient avec la théorie. De plus, il ressort de la documentation que la taille de la chaîne ne peut pas être modifiée. Il est toujours égal à trente-deux octets.
Expérience un peu plus compliquée
Essayons de provoquer un cache pour redémarrer pendant le travail établi. Modifions un peu le programme de test. Nous créons deux fonctions et les appelons à partir de la fonction
main () , en y plaçant une boucle. Je ne définirai pas de point d'arrêt. Soit dit en passant, si vous rendez les fonctions complètement identiques, l'optimiseur le remarquera et supprimera l'une d'entre elles, donc au moins une ligne, mais elles devraient différer ... C'est ce que j'ai écrit au début: les optimiseurs sont très intelligents maintenant.
Code de programme de test modifié. extern "C" { #include "sys/alt_stdio.h" #include <system.h> #include <io.h> } void MagicFunction1() { IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); } void MagicFunction2() { IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); } int main() { while (1) { MagicFunction1(); MagicFunction2(); } /* Event loop never exits. */ while (1); return 0; }
On obtient un très beau résultat, tourné déjà dans le mode établi du programme.
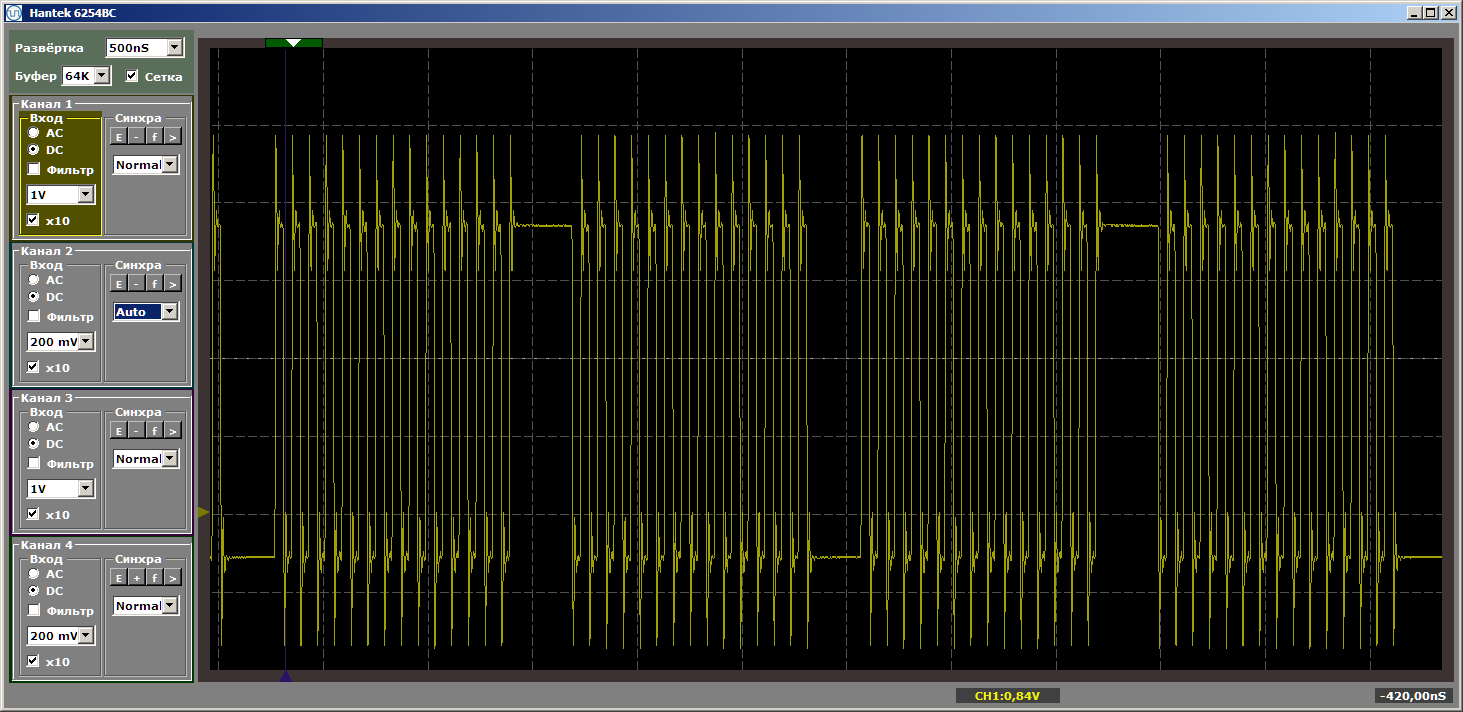
Et maintenant, nous allons placer une nouvelle fonction entre cette paire de fonctions, et nous ne l'appellerons pas, elle sera simplement placée entre elles en mémoire. Maintenant, je vais essayer de lui faire prendre plus de place ... La taille du cache est de 4 kilo-octets, nous allons donc la rendre égale à quatre kilo-octets ... Il suffit d'insérer 1024 NOP, chacun de 4 octets. Je vais montrer la fin de la première fonction, la nouvelle fonction et le début de la seconde, pour que l'on comprenne bien comment le programme change:
... IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); } #define Nops4 __asm__ volatile ("nop");__asm__ volatile ("nop");__asm__ volatile ("nop");__asm__ volatile ("nop"); #define Nops16 Nops4 Nops4 Nops4 Nops4 #define Nops64 Nops16 Nops16 Nops16 Nops16 #define Nops256 Nops64 Nops64 Nops64 Nops64 #define Nops1024 Nops256 Nops256 Nops256 Nops256 volatile void FuncBetween() { Nops1024 } void MagicFunction2() { IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); ...
La logique du programme n'a pas changé, mais lorsqu'il est exécuté maintenant, nous obtenons des impulsions déchirées
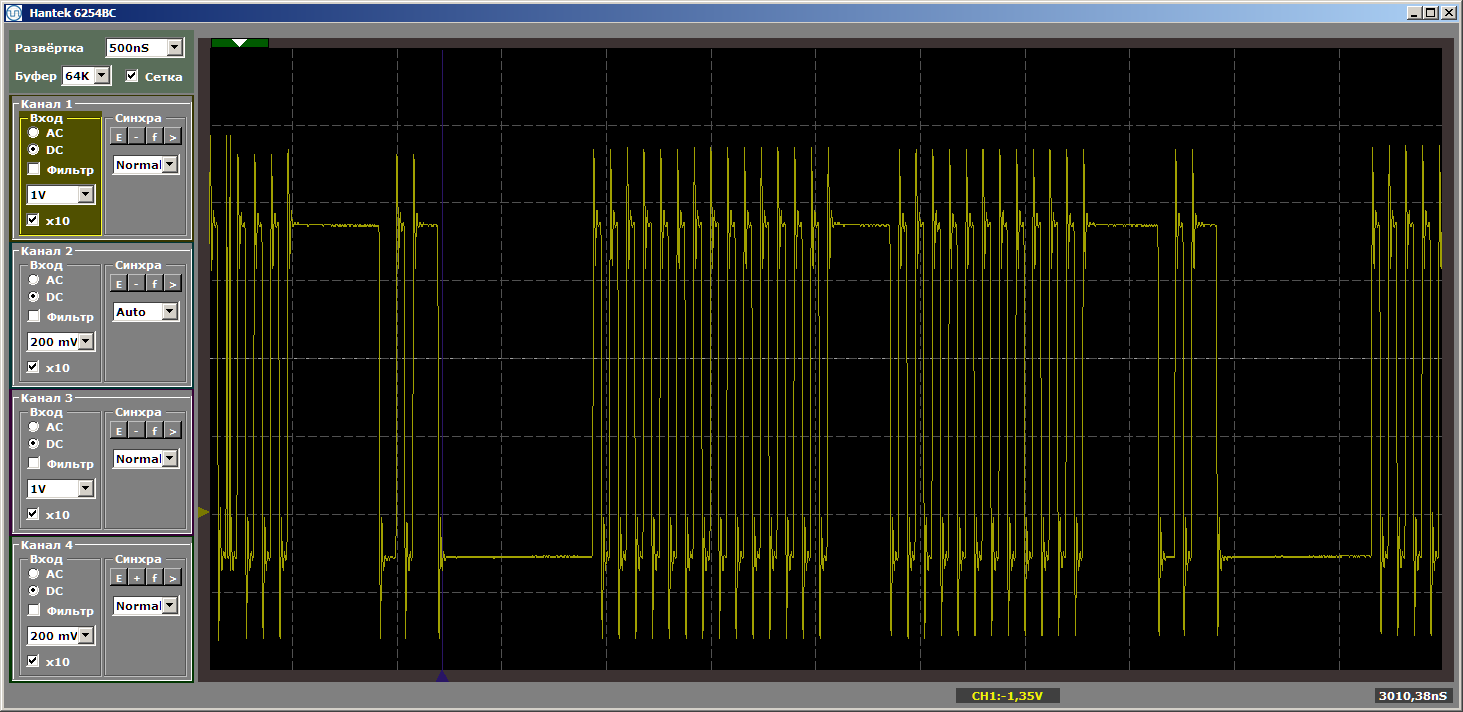
Je vais poser une question naïve: nous avons volé hors du cache, et maintenant, comme l'écart s'élargit, y aura-t-il toujours du chargement? Pas du tout! Modifiez la taille de la «mauvaise» fonction, en la rendant égale, disons, à cinq kilo-octets. Cinq de plus que quatre, volons-nous toujours? Ou pas? Remplacez l'insert par ceci:
volatile void FuncBetween() { Nops1024 Nops256 }
Et encore une fois, nous obtenons la beauté:
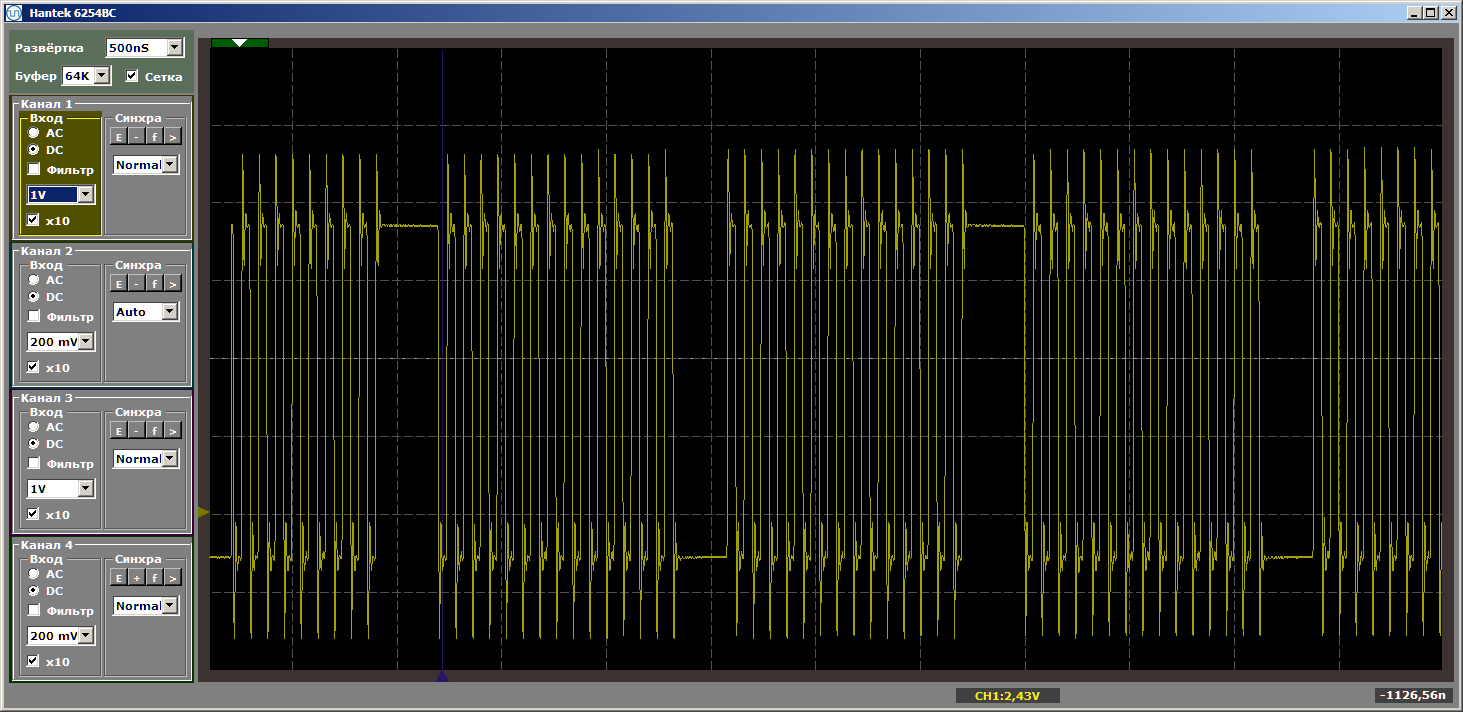
Qu'est-ce qui détermine la nécessité de charger du code dans le cache? Pouvons-nous prévoir quelque chose, ou chaque fois que nous devons examiner le fait? Plongeons-nous dans la théorie, avec laquelle le
Guide de référence du processeur Nios II nous aide.
Un peu de théorie
Voici comment le champ d'adresse se divise dans le processeur:
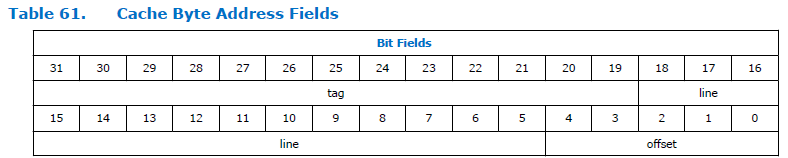
Comme vous pouvez le voir, l'adresse est divisée en trois parties. Tag, ligne et décalage. La dimension du champ de décalage est constante pour le processeur Nios II et est toujours de cinq bits, c'est-à-dire qu'il peut adresser 32 octets. La dimension du champ "ligne" dépend de la taille du cache spécifié lors de la configuration du processeur. Dans la figure ci-dessus, elle est assez grande. Je ne sais pas pourquoi le document a une si grande dimension. Nous avons une taille de cache de 4 kilo-octets, ce qui signifie que la profondeur de bits totale et le décalage sont de 12 bits. 5 bits prennent un décalage, pour une ligne il reste 12-5 = 7 bits.
Nous obtenons une certaine table de 128 lignes, chacune de 32 octets de long. Je vais donner, disons, les 6 premières lignes:
Et donc nous nous sommes tournés vers l'adresse 0x123
004 . Si vous jetez la partie «non importante», la paire «ligne + décalage» est 0x004. Il s'agit de la plage de lignes zéro. Les données seront chargées sur cette ligne. Et travailler davantage avec des données de la plage 0x123
000 à 0x123
01F fonctionnera via le cache. Dans quelles conditions la chaîne sera-t-elle surchargée? Lors de l'accès à toute autre adresse se terminant dans la plage de 0x000 à 0x01F. Eh bien, c'est-à-dire que si nous nous tournons vers l'adresse 0xABC
204 , tout restera en place, car la plage d'adresses inférieures ne chevauche pas la nôtre. Et 0xABC
804 ne gâchera rien. Mais lors de l'exécution du code à partir de l'adresse 0xABC
004, cela entraînera le chargement de nouveaux contenus dans la ligne de cache. Et déjà, la transition vers l'adresse 0x123
004 entraînera à nouveau une surcharge. Si vous sautez constamment entre 0xABC
004 et 0x123
004 , une surcharge se produit en continu.
Essayons de représenter cela sous la forme d'une image. Supposons que nous ne disposions que de 8 lignes dans le cache, il est plus pratique de les colorier de différentes couleurs. Je vais faire la taille de la ligne 0x10, il est plus pratique de peindre les adresses dans l'image (rappelez-vous que dans le vrai Nios II, la taille de la ligne est toujours 0x20 octets). La mémoire bat sur les pages conditionnelles de la même taille que les lignes de cache. La page rouge de la mémoire ira toujours sur la ligne rouge du cache, l'orange sur l'orange, etc. En conséquence, l'ancien contenu sera déchargé.

Eh bien, en fait, le comportement du programme pendant l'expérience est maintenant clair. Lorsque les fonctions étaient strictement séparées par 4 kilo-octets, elles frappaient des pages de couleurs similaires. Par conséquent, le code
while (1) { MagicFunction1(); MagicFunction2(); }
conduit au chargement du cache pour le bien de l'un, puis pour le bien d'une autre fonction. Et lorsque l'espacement n'était pas de 4, mais de 5 kilo-octets, les fonctions étaient espacées en blocs de couleurs différentes. Il n'y a pas eu de conflit, tout a fonctionné sans délai.
Conclusions
Quand j'ai lu il y a de nombreuses années qu'il y avait des gammes de cœurs Cortex A, Cortex R et Cortex M conçues pour des choses productives, pour travailler en temps réel et pour travailler dans des systèmes bon marché, respectivement, au début je ne comprenais pas, mais quelle est, en fait, la différence . Non, les systèmes bon marché sont compréhensibles, mais les deux premiers sont quelles sont les différences? Cependant, après avoir joué le noyau Cortex A9 disponible dans le FPGA Cyclone V SoC, j'ai ressenti tous les inconvénients du cache lorsque je travaillais avec du fer. Il existe de nombreux caches au cœur du Cortex A ... Et la prévisibilité du comportement du système est presque nulle. Mais le cache améliore les performances. Parfois, il vaut mieux que tout fonctionne de façon non prévisible au rythme, mais rapide plutôt que prévisible. Cela est particulièrement vrai pour l'informatique ou, par exemple, l'affichage de graphiques.
Mais le problème principal n'est pas que les choses décrites dans l'article surviennent, mais que le comportement du système changera d'un assemblage à l'autre, car personne ne sait quelles adresses la fonction tombera après l'ajout ou la suppression de code. Il y a 15 ans, dans le projet de l'émulateur de console de jeu Sega pour un décodeur de télévision par câble, nous devions faire un préprocesseur entier qui, après chaque édition, déplaçait des fonctions qui émulaient des commandes d'assembleur Motorola sur le cœur SPARC-8 afin que leur temps d'exécution soit toujours le même (là à cause du cache, sinon tout nageait beaucoup).
Mais quand avons-nous besoin de prévisibilité? Bien sûr, lors de la formation des chronogrammes par programmation (rappelez-vous qu'en général dans les FPGA, il est possible de confier cela également à l'équipement, mais il y a des détails avec un développement rapide). Mais lorsque vous travaillez avec des algorithmes de calcul, ce n'est pas si important. À moins que l'algorithme ne soit complexe, vous devez vous assurer que les sections critiques ne provoquent pas une surcharge constante du cache. Dans la plupart des cas, le cache ne crée pas de problèmes et la productivité augmente.
Dans le prochain article, nous verrons comment prédire les fonctions critiques dans la mémoire non-cache, qui s'exécute toujours à la vitesse maximale, et discuter des avantages implicites des FPGA par rapport aux systèmes standard découlant des technologies utilisées dans ce processus.
Pour les plus attentifs
Un lecteur corrosif peut demander: «Pourquoi l'oscillogramme a-t-il été insuffisamment déchiré lors de l'insertion de quatre kilo-octets de code?» Tout est simple. Si vous insérez exactement 4 kilo-octets, nous obtenons les adresses suivantes pour placer les fonctions en mémoire:
MagicFunction1(): 0200006c: movhi r2,1024 02000070: movi r4,1 02000074: addi r2,r2,4096 02000078: stwio r4,0(r2) 92 IOWR (PIO_0_BASE,0,0); 0200007c: mov r3,zero 02000080: stwio r3,0(r2) 93 IOWR (PIO_0_BASE,0,1); ... 120 IOWR (PIO_0_BASE,0,0); 020000f0: stwio r3,0(r2) 020000f4: ret 131 Nops1024 FuncBetween(): 020000f8: nop 020000fc: nop 02000100: nop 02000104: nop ... 020010ec: nop 020010f0: nop 020010f4: nop 020010f8: ret 135 IOWR (PIO_0_BASE,0,0); MagicFunction2(): 020010fc: movhi r2,1024 02001100: mov r4,zero 02001104: addi r2,r2,4096
Pour une forme d'onde parfaitement mauvaise, vous devez insérer des NOP de sorte que 4 kilo-octets correspondent à leur volume et à la longueur de la fonction
MagicFunction1 () . Peu importe ce que vous allez pour une belle photo! Remplacez l'insert par ceci:
volatile void FuncBetween() { Nops256 Nops256 Nops256 Nops64 Nops64 Nops64 Nops16 Nops16 }
Je fais encore et encore attention que l'insert ne reçoive pas de contrôle. Il modifie simplement la position des fonctions en mémoire les unes par rapport aux autres. Avec cet encart, nous obtenons l'horreur terrible souhaitée:
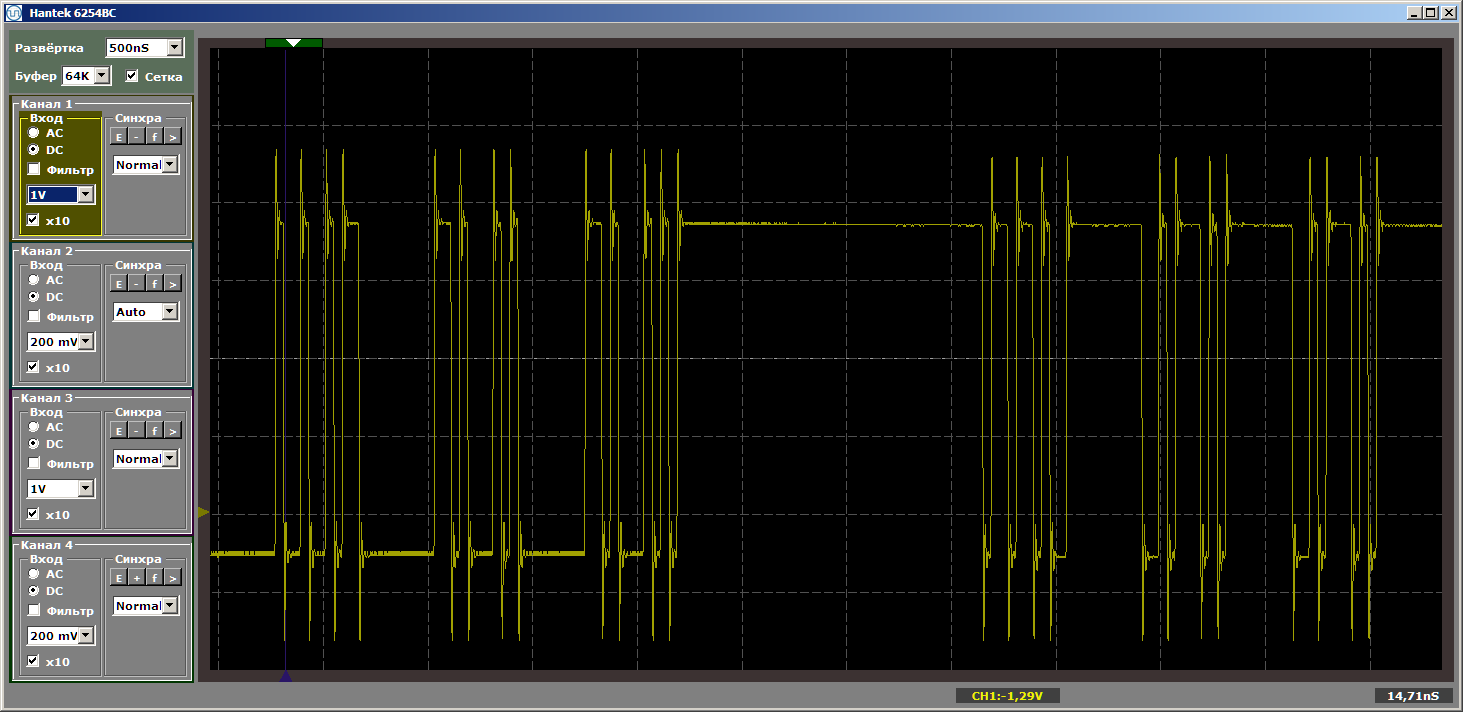
Il me semblait que de tels détails insérés dans le texte principal distraireaient tout le monde du texte principal, alors je les ai mis dans un post-scriptum.