Salut, Khabrovites! Félicitations à tous le jour de la programmation et partagez la traduction de l'article, qui a été spécialement préparé pour les étudiants du cours "High Load Architect" . "Sharding. Ou ne pas éclater. Sans essayer. "
"Sharding. Ou ne pas éclater. Sans essayer. "
- YodaAujourd'hui, nous allons plonger dans la séparation des données entre plusieurs serveurs MySQL. Nous avons terminé le sharding début 2012, et ce système est toujours utilisé pour stocker nos données de base.
Avant de discuter de la façon de partager des données, apprenons à mieux les connaître. Installez une belle lumière, obtenez des fraises au chocolat, souvenez-vous des citations de Star Trek ...
Pinterest est un moteur de recherche pour tout ce qui vous intéresse. En termes de données, Pinterest est le plus grand graphique des intérêts humains dans le monde. Il contient plus de 50 milliards de broches qui ont été enregistrées par les utilisateurs sur plus d'un milliard de cartes. Les gens gardent des épingles pour eux-mêmes et, comme d'autres épingles, s'abonnent à d'autres épingles, tableaux et intérêts, consultent le flux d'accueil de tous les épingles, tableaux et intérêts auxquels ils sont abonnés. Super! Rendons-le maintenant évolutif!
Croissance douloureuse
En 2011, nous avons commencé à prendre de l'ampleur. Selon certaines
estimations , nous avons progressé plus rapidement que n'importe quelle startup connue à l'époque. Vers septembre 2011, chaque composant de notre infrastructure était surchargé. Nous avions plusieurs technologies NoSQL à notre disposition, et toutes ont échoué de manière catastrophique. Nous avions également de nombreux esclaves MySQL, que nous avions l'habitude de lire, ce qui provoquait de nombreuses erreurs extraordinaires, en particulier lors de la mise en cache. Nous avons reconstruit l'ensemble de notre modèle de stockage. Pour travailler efficacement, nous avons soigneusement abordé le développement des exigences.
Prérequis
- L'ensemble du système doit être très stable, facile à utiliser et évoluer de la taille d'une petite boîte à la taille de la lune à mesure que le site se développe.
- Tout le contenu généré par le pinner doit être disponible sur le site à tout moment.
- Le système doit prendre en charge la demande de N broches sur la carte dans un ordre déterministe (par exemple, dans l'ordre inverse de l'heure de création ou dans l'ordre spécifié par l'utilisateur). Il en va de même pour les broches similaires, leurs broches, etc.
- Par souci de simplicité, vous devez vous efforcer d'obtenir des mises à jour de toutes les manières possibles. Pour obtenir la cohérence nécessaire, des jouets supplémentaires, tels qu'un journal des transactions distribué, seront nécessaires. C'est amusant et (pas trop) facile!
Philosophie de l'architecture et des notes
Comme nous voulions que ces données s'étendent sur plusieurs bases de données, nous ne pouvions pas utiliser uniquement une jointure, des clés étrangères et des index pour collecter toutes les données, bien qu'elles puissent être utilisées pour des sous-requêtes qui ne s'étendent pas sur la base de données.
Nous devions également maintenir l'équilibrage de charge sur les données. Nous avons décidé que le déplacement de données, élément par élément, rendrait le système inutilement complexe et provoquerait de nombreuses erreurs. Si nous devions déplacer des données, il était préférable de déplacer le nœud virtuel entier vers un autre nœud physique.
Pour que notre implémentation soit rapidement mise en circulation, nous avions besoin de la solution la plus simple et la plus pratique et de nœuds très stables dans notre plate-forme de données distribuées.
Toutes les données ont dû être répliquées sur la machine esclave pour créer une sauvegarde, avec une haute disponibilité et un vidage sur S3 pour MapReduce. Nous interagissons avec le maître uniquement sur la production. En production, vous ne voudrez pas écrire ou lire en esclave. Slave lag, et cela provoque d'étranges bugs. Si le partage est effectué, il est inutile d'interagir avec un esclave en production.
Enfin, nous avons besoin d'un bon moyen de générer des identificateurs uniques universels (UUID) pour tous nos objets.
Comment nous avons fait le sharding
Ce que nous allions créer devait répondre aux exigences, fonctionner de manière stable, en général, être réalisable et maintenable. C'est pourquoi nous avons choisi la
technologie MySQL déjà assez mature comme
technologie sous-jacente. Nous nous méfions intentionnellement des nouvelles technologies de mise à l'échelle automatique MongoDB, Cassandra et Membase, car elles étaient suffisamment éloignées de la maturité (et dans notre cas, elles se sont cassées de manière impressionnante!).
De plus: je recommande toujours les startups pour éviter de nouvelles choses bizarres - essayez simplement d'utiliser MySQL. Faites-moi confiance. Je peux le prouver avec des cicatrices.
MySQL - la technologie est éprouvée, stable et simple - cela fonctionne. Non seulement nous l'utilisons, mais il est populaire dans d'autres entreprises avec des balances encore plus impressionnantes. MySQL répond pleinement à notre besoin de rationaliser les requêtes de données, de sélectionner des plages de données spécifiques et des transactions au niveau des lignes. En fait, dans son arsenal, il y a beaucoup plus de possibilités, mais nous n'en avons pas tous besoin. Mais MySQL est une solution «en boîte», donc les données ont dû être partagées. Voici notre solution:
Nous avons commencé avec huit serveurs EC2, une instance de MySQL sur chacun:
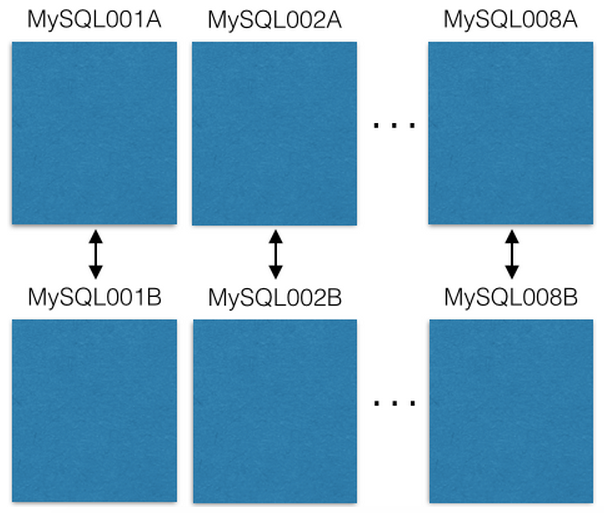
Chaque serveur maître-maître MySQL est répliqué sur l'hôte de sauvegarde en cas de défaillance principale. Nos serveurs de production lisent ou écrivent uniquement au maître. Je vous recommande de faire de même. Cela simplifie considérablement et évite les erreurs avec des retards de réplication.
Chaque entité MySQL possède de nombreuses bases de données:

Notez que chaque base de données porte un nom unique: db00000, db00001 à dbNNNNN. Chaque base de données est un fragment de nos données. Nous avons pris une décision architecturale, sur la base de laquelle seule une partie des données tombe dans le fragment, et cela ne va jamais au-delà de ce fragment. Cependant, vous pouvez obtenir plus de capacité en déplaçant des fragments vers d'autres machines (nous en parlerons plus tard).
Nous travaillons avec une table de configuration qui indique quelles machines ont des fragments:
[{“range”: (0,511), “master”: “MySQL001A”, “slave”: “MySQL001B”}, {“range”: (512, 1023), “master”: “MySQL002A”, “slave”: “MySQL002B”}, ... {“range”: (3584, 4095), “master”: “MySQL008A”, “slave”: “MySQL008B”}]
Cette configuration ne change que lorsque nous devons déplacer des fragments ou remplacer l'hôte. Si le
master meurt, nous pouvons utiliser l'
slave existant, puis en prendre un nouveau. La configuration se trouve dans
ZooKeeper et, lorsqu'elle est mise à jour, est envoyée aux services qui desservent le fragment MySQL.
Chaque fragment a le même ensemble de tables:
pins ,
boards ,
users_has_pins ,
users_likes_pins ,
pin_liked_by_user , etc. J'en parlerai un peu plus tard.
Comment distribuons-nous les données pour ces fragments?
Nous créons un ID 64 bits qui contient l'ID du fragment, le type de données qu'il contient et l'endroit où ces données se trouvent dans la table (ID local). L'ID de fragment se compose de 16 bits, l'ID de type est de 10 bits et l'ID local de 36 bits. Les mathématiciens avancés remarqueront qu'il n'y a que 62 bits. Mon expérience passée en tant que compilateur et développeur de circuits imprimés m'a appris que les bits de sauvegarde valent leur pesant d'or. Donc, nous avons deux de ces bits (mis à zéro).
ID = (shard ID << 46) | (type ID << 36) | (local ID<<0)
Prenons cette épingle:
https://www.pinterest.com/pin/241294492511762325/ , analysons son ID 241294492511762325:
Shard ID = (241294492511762325 >> 46) & 0xFFFF = 3429 Type ID = (241294492511762325 >> 36) & 0x3FF = 1 Local ID = (241294492511762325 >> 0) & 0xFFFFFFFFF = 7075733
Ainsi, l'objet épingle vit dans un éclat de 3429. Son type est «1» (c'est-à-dire «Pin») et il est en ligne 7075733 dans le tableau des broches. Par exemple, imaginons que ce fragment se trouve dans MySQL012A. Nous pouvons y accéder comme suit:
conn = MySQLdb.connect(host=”MySQL012A”) conn.execute(“SELECT data FROM db03429.pins where local_id=7075733”)
Il existe deux types de données: les objets et les mappages. Les objets contiennent des parties, telles que des données de broche.
Tables d'objets
Les tables d'objets telles que les broches, les utilisateurs, les tableaux et les commentaires ont un ID (ID local, avec une clé primaire augmentant automatiquement) et un blob qui contient JSON avec toutes les données d'objet.
CREATE TABLE pins ( local_id INT PRIMARY KEY AUTO_INCREMENT, data TEXT, ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP ) ENGINE=InnoDB;
Par exemple, les objets d'épingle ressemblent à ceci:
{“details”: “New Star Wars character”, “link”: “http://webpage.com/asdf”, “user_id”: 241294629943640797, “board_id”: 241294561224164665, …}
Pour créer une nouvelle épingle, nous collectons toutes les données et créons un blob JSON. Ensuite, nous sélectionnons l'ID de fragment (nous préférons choisir le même ID de fragment que la carte sur laquelle il est placé, mais ce n'est pas nécessaire). Pour le type de broche 1. Nous nous connectons à cette base de données et insérons JSON dans la table des broches. MySQL renverra un ID local automatiquement augmenté. Nous avons maintenant un fragment, un type et un nouvel identifiant local, nous pouvons donc compiler un identifiant 64 bits complet!
Pour éditer la broche, nous lisons-modifions-écrivons JSON en utilisant la
transaction MySQL :
> BEGIN > SELECT blob FROM db03429.pins WHERE local_id=7075733 FOR UPDATE [Modify the json blob] > UPDATE db03429.pins SET blob='<modified blob>' WHERE local_id=7075733 > COMMIT
Pour supprimer une épingle, vous pouvez supprimer sa ligne dans MySQL. Cependant, il est préférable d'ajouter le champ
«actif» dans JSON et de le définir sur
«faux» , ainsi que de filtrer les résultats côté client.
Tables de correspondance
La table de mappage relie un objet à un autre, par exemple une carte avec des broches dessus. La table MySQL pour les mappages contient trois colonnes: 64 bits pour l'ID "de", 64 bits pour l'ID "où" et l'ID de séquence. Dans ce triple (d'où, où, séquence) il y a des clés d'index, et elles sont sur le fragment de l'identifiant "de".
CREATE TABLE board_has_pins ( board_id INT, pin_id INT, sequence INT, INDEX(board_id, pin_id, sequence) ) ENGINE=InnoDB;
Les tables de mappage sont unidirectionnelles, par exemple, comme la table
board_has_pins . Si vous avez besoin de la direction opposée, vous aurez besoin d'une table
pin_owned_by_board distincte. L'ID de séquence définit la séquence (nos ID ne peuvent pas être comparés entre les fragments, car les nouveaux ID locaux sont différents). Habituellement, nous insérons de nouvelles broches sur une nouvelle carte avec un ID de séquence égal au temps dans unix (horodatage unix). N'importe quel nombre peut être dans la séquence, mais le temps unix est un bon moyen de stocker séquentiellement de nouveaux matériaux, car cet indicateur augmente de façon monotone. Vous pouvez consulter les données de la table de mappage:
SELECT pin_id FROM board_has_pins WHERE board_id=241294561224164665 ORDER BY sequence LIMIT 50 OFFSET 150
Cela vous donnera plus de 50 pin_id, que vous pouvez ensuite utiliser pour rechercher des objets pin.
Ce que nous venons de faire est une jointure de couche d'application (board_id -> pin_id -> pin objects). L'une des propriétés étonnantes des connexions au niveau de l'application est que vous pouvez mettre l'image en cache séparément de l'objet. Nous stockons pin_id dans le cache de l'objet pin dans le cluster memcache, mais nous enregistrons board_id dans pin_id dans le cluster redis. Cela nous permet de choisir la bonne technologie qui convient le mieux à l'objet mis en cache.
Augmenter la capacité
Il existe trois façons principales d'augmenter la capacité de notre système. Le moyen le plus simple de mettre à jour la machine (pour augmenter l'espace, mettre des disques durs plus rapides, plus de RAM).
La prochaine façon d'augmenter la capacité est d'ouvrir de nouvelles gammes. Initialement, nous avons créé un total de 4096 fragments, malgré le fait que l'ID de fragment était composé de 16 bits (un total de 64 000 fragments). De nouveaux objets ne peuvent être créés que dans ces premiers fragments 4k. À un moment donné, nous avons décidé de créer de nouveaux serveurs MySQL avec des fragments de 4096 à 8191 et avons commencé à les remplir.
La dernière façon d'augmenter notre capacité est de déplacer des fragments vers de nouvelles machines. Si nous voulons augmenter la capacité de MySQL001A (avec des fragments de 0 à 511), nous créons une nouvelle paire maître-maître avec les noms maximum possibles suivants (disons MySQL009A et B) et commençons la réplication à partir de MySQL001A.
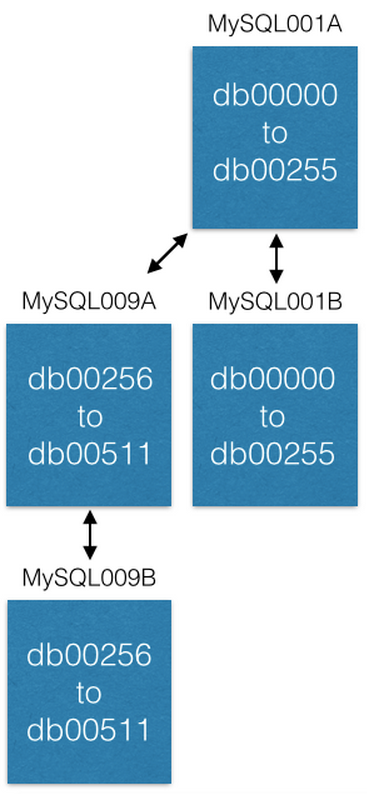
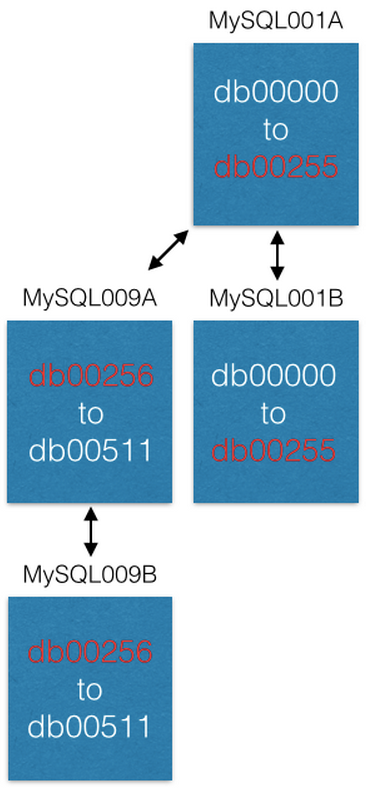
Dès que la réplication est terminée, nous changeons notre configuration de sorte que dans MySQL001A il n'y a que des fragments de 0 à 255, et dans MySQL009A de 256 à 511. Maintenant, chaque serveur ne doit traiter que la moitié des fragments qu'il a traités auparavant.
Quelques fonctionnalités intéressantes
Ceux qui avaient déjà des systèmes pour générer de nouveaux
UUID comprendront que dans ce système, nous les obtenons gratuitement! Lorsque vous créez un nouvel objet et l'insérez dans la table des objets, il renvoie un nouvel identifiant local. Cet ID local, combiné avec l'ID de fragment et l'ID de type, vous donne un UUID.
Ceux d'entre vous qui ont effectué des ALTER pour ajouter plus de colonnes aux tables MySQL savent qu'ils peuvent fonctionner extrêmement lentement et devenir un gros problème. Notre approche ne nécessite aucune modification de niveau MySQL. Sur Pinterest, nous n'avons probablement fait qu'un seul ALTER au cours des trois dernières années. Pour ajouter de nouveaux champs aux objets, dites simplement à vos services qu'il existe plusieurs nouveaux champs dans le schéma JSON. Vous pouvez modifier la valeur par défaut afin que lors de la désérialisation de JSON d'un objet sans nouveau champ, vous obteniez la valeur par défaut. Si vous avez besoin d'une table de mappage, créez une nouvelle table de mappage et commencez à la remplir quand vous le souhaitez. Et une fois terminé, vous pouvez envoyer!
Éclat de mod
C'est presque comme une
équipe de mods , mais complètement différent.
Certains objets doivent être trouvés sans ID. Par exemple, si un utilisateur se connecte avec un compte Facebook, nous devons mapper l'ID Facebook à l'ID Pinterest. Pour nous, les identifiants Facebook ne sont que des bits, nous les stockons donc dans un système de partition séparé appelé mod shard.
D'autres exemples incluent les adresses IP, le nom d'utilisateur et l'adresse e-mail.
Mod Shard est très similaire au système de partitionnement décrit dans la section précédente, à la seule différence que vous pouvez rechercher des données à l'aide de données d'entrée arbitraires. Cette entrée est hachée et modifiée en fonction du nombre total de fragments dans le système. En conséquence, un fragment sera obtenu sur lequel les données seront ou sont déjà situées. Par exemple:
shard = md5(“1.2.3.4") % 4096
Dans ce cas, le fragment sera égal à 1524. Nous traitons le fichier de configuration correspondant à l'ID de fragment:
[{“range”: (0, 511), “master”: “msdb001a”, “slave”: “msdb001b”}, {“range”: (512, 1023), “master”: “msdb002a”, “slave”: “msdb002b”}, {“range”: (1024, 1535), “master”: “msdb003a”, “slave”: “msdb003b”}, …]
Ainsi, afin de trouver des données sur l'adresse IP 1.2.3.4, nous devrons procéder comme suit:
conn = MySQLdb.connect(host=”msdb003a”) conn.execute(“SELECT data FROM msdb001a.ip_data WHERE ip='1.2.3.4'”)
Vous perdez de bonnes propriétés de l'ID de fragment, telles que la localité spatiale. Vous devrez commencer par tous les fragments créés au tout début et créer la clé vous-même (elle ne sera pas générée automatiquement). Il est toujours préférable de représenter les objets sur votre système avec des ID immuables. Ainsi, vous n'avez pas besoin de mettre à jour de nombreux liens lorsque, par exemple, l'utilisateur change son "nom d'utilisateur".
Dernières pensées
Ce système fonctionne sur Pinterest depuis 3,5 ans et devrait y rester pour toujours. Son implémentation était relativement simple, mais sa mise en service et le déplacement de toutes les données de vieilles machines étaient difficiles. Si vous rencontrez un problème lorsque vous venez de créer un nouveau fragment, envisagez de créer un cluster de machines de traitement de données en arrière-plan (astuce: utilisez
pyres ) pour déplacer vos données avec des scripts d'anciennes bases de données vers votre nouveau fragment. Je garantis qu'une partie des données sera perdue, peu importe vos efforts (ce sont tous des gremlins, je le jure), alors répétez le transfert de données encore et encore jusqu'à ce que la quantité de nouvelles informations dans le fragment devienne très petite ou pas du tout.
Tous les efforts ont été faits pour ce système. Mais il n'apporte en aucune façon atomicité, isolement ou cohérence. Ouah! Ça sonne mal! Mais ne vous inquiétez pas. Vous vous sentirez sûrement excellent sans eux. Vous pouvez toujours construire ces couches avec d'autres processus / systèmes, si nécessaire, mais par défaut et sans frais, vous obtenez déjà beaucoup: la capacité de travail. Fiabilité obtenue grâce à la simplicité et fonctionne même rapidement!
Mais qu'en est-il de la tolérance aux pannes? Nous avons créé un service de maintenance des fragments MySQL, enregistré la table de configuration des fragments dans ZooKeeper. Lorsque le serveur maître tombe en panne, nous élevons la machine esclave puis relevons la machine qui la remplacera (toujours à jour). À ce jour, nous n'utilisons pas de traitement automatique des pannes.