Salut, Habr.
Dans la
partie précédente , la fréquentation de Habr a été analysée par les principaux paramètres - le nombre d'articles, leurs opinions et leurs notes. Cependant, la question de la popularité des sections du site n'a pas été examinée. Il est devenu intéressant d'examiner cela plus en détail et de trouver les hubs les plus populaires et les plus impopulaires. Enfin, j'examinerai plus en détail «l'effet geektimes» et, à la fin, les lecteurs recevront une nouvelle sélection des meilleurs articles sur les nouvelles cotes.
Peu importe ce qui s'est passé, a continué sous la coupe.
Je vous rappelle encore une fois que les statistiques et les notes ne sont pas officielles, je n'ai pas d'informations privilégiées. Il n'est pas non plus garanti que je ne me sois pas trompé quelque part ou que je n'ai rien manqué. Mais quand même, je pense que cela s'est avéré intéressant. Nous allons commencer par le code, pour qui cela n'est pas pertinent, les premières sections peuvent être ignorées.
Collecte de données
Dans la première version de l'analyseur, seuls le nombre de vues, de commentaires et la note des articles étaient pris en compte. C'est déjà bien, mais cela ne vous permet pas de faire des requêtes plus complexes. Il est temps d'analyser les sections thématiques du site, cela vous permettra de faire des recherches assez intéressantes, par exemple, de voir comment la popularité de la section "C ++" a changé au fil des ans.
L'analyseur d'article a été amélioré, il renvoie maintenant les hubs auxquels l'article appartient, ainsi que le surnom de l'auteur et sa note (ici, vous pouvez également faire beaucoup de choses intéressantes, mais plus tard). Les données sont enregistrées dans un fichier csv d'environ le type suivant:
2018-12-18T12:43Z,https://habr.com/ru/post/433550/," Slack — , , ",votes:7,votesplus:8,votesmin:1,bookmarks:32, views:8300,comments:10,user:ReDisque,karma:5,subscribers:2,hubs:productpm+soft ...
Obtenez une liste des principaux centres thématiques du site.
def get_as_str(link: str) -> Str: try: r = requests.get(link) return Str(r.text) except Exception as e: return Str("") def get_hubs(): hubs = [] for p in range(1, 12): page_html = get_as_str("https://habr.com/ru/hubs/page%d/" % p)
La fonction find_between et la classe Str mettent en évidence une ligne entre deux balises, je les ai utilisées plus
tôt . Les hubs thématiques sont marqués d'un "*", donc ils sont faciles à mettre en évidence, vous pouvez également décommenter les lignes correspondantes pour obtenir des sections d'autres catégories.
À la sortie de la fonction get_hubs, nous obtenons une liste assez impressionnante, que nous enregistrons sous forme de dictionnaire. Je cite spécialement toute la liste pour que son volume puisse être estimé.
hubs_profile = {'infosecurity', 'programming', 'webdev', 'python', 'sys_admin', 'it-infrastructure', 'devops', 'javascript', 'open_source', 'network_technologies', 'gamedev', 'cpp', 'machine_learning', 'pm', 'hr_management', 'linux', 'analysis_design', 'ui', 'net', 'hi', 'maths', 'mobile_dev', 'productpm', 'win_dev', 'it_testing', 'dev_management', 'algorithms', 'go', 'php', 'csharp', 'nix', 'data_visualization', 'web_testing', 's_admin', 'crazydev', 'data_mining', 'bigdata', 'c', 'java', 'usability', 'instant_messaging', 'gtd', 'system_programming', 'ios_dev', 'oop', 'nginx', 'kubernetes', 'sql', '3d_graphics', 'css', 'geo', 'image_processing', 'controllers', 'game_design', 'html5', 'community_management', 'electronics', 'android_dev', 'crypto', 'netdev', 'cisconetworks', 'db_admins', 'funcprog', 'wireless', 'dwh', 'linux_dev', 'assembler', 'reactjs', 'sales', 'microservices', 'search_technologies', 'compilers', 'virtualization', 'client_side_optimization', 'distributed_systems', 'api', 'media_management', 'complete_code', 'typescript', 'postgresql', 'rust', 'agile', 'refactoring', 'parallel_programming', 'mssql', 'game_promotion', 'robo_dev', 'reverse-engineering', 'web_analytics', 'unity', 'symfony', 'build_automation', 'swift', 'raspberrypi', 'web_design', 'kotlin', 'debug', 'pay_system', 'apps_design', 'git', 'shells', 'laravel', 'mobile_testing', 'openstreetmap', 'lua', 'vs', 'yii', 'sport_programming', 'service_desk', 'itstandarts', 'nodejs', 'data_warehouse', 'ctf', 'erp', 'video', 'mobileanalytics', 'ipv6', 'virus', 'crm', 'backup', 'mesh_networking', 'cad_cam', 'patents', 'cloud_computing', 'growthhacking', 'iot_dev', 'server_side_optimization', 'latex', 'natural_language_processing', 'scala', 'unreal_engine', 'mongodb', 'delphi', 'industrial_control_system', 'r', 'fpga', 'oracle', 'arduino', 'magento', 'ruby', 'nosql', 'flutter', 'xml', 'apache', 'sveltejs', 'devmail', 'ecommerce_development', 'opendata', 'Hadoop', 'yandex_api', 'game_monetization', 'ror', 'graph_design', 'scada', 'mobile_monetization', 'sqlite', 'accessibility', 'saas', 'helpdesk', 'matlab', 'julia', 'aws', 'data_recovery', 'erlang', 'angular', 'osx_dev', 'dns', 'dart', 'vector_graphics', 'asp', 'domains', 'cvs', 'asterisk', 'iis', 'it_monetization', 'localization', 'objectivec', 'IPFS', 'jquery', 'lisp', 'arvrdev', 'powershell', 'd', 'conversion', 'animation', 'webgl', 'wordpress', 'elm', 'qt_software', 'google_api', 'groovy_grails', 'Sailfish_dev', 'Atlassian', 'desktop_environment', 'game_testing', 'mysql', 'ecm', 'cms', 'Xamarin', 'haskell', 'prototyping', 'sw', 'django', 'gradle', 'billing', 'tdd', 'openshift', 'canvas', 'map_api', 'vuejs', 'data_compression', 'tizen_dev', 'iptv', 'mono', 'labview', 'perl', 'AJAX', 'ms_access', 'gpgpu', 'infolust', 'microformats', 'facebook_api', 'vba', 'twitter_api', 'twisted', 'phalcon', 'joomla', 'action_script', 'flex', 'gtk', 'meteorjs', 'iconoskaz', 'cobol', 'cocoa', 'fortran', 'uml', 'codeigniter', 'prolog', 'mercurial', 'drupal', 'wp_dev', 'smallbasic', 'webassembly', 'cubrid', 'fido', 'bada_dev', 'cgi', 'extjs', 'zend_framework', 'typography', 'UEFI', 'geo_systems', 'vim', 'creative_commons', 'modx', 'derbyjs', 'xcode', 'greasemonkey', 'i2p', 'flash_platform', 'coffeescript', 'fsharp', 'clojure', 'puppet', 'forth', 'processing_lang', 'firebird', 'javame_dev', 'cakephp', 'google_cloud_vision_api', 'kohanaphp', 'elixirphoenix', 'eclipse', 'xslt', 'smalltalk', 'googlecloud', 'gae', 'mootools', 'emacs', 'flask', 'gwt', 'web_monetization', 'circuit-design', 'office365dev', 'haxe', 'doctrine', 'typo3', 'regex', 'solidity', 'brainfuck', 'sphinx', 'san', 'vk_api', 'ecommerce'}
À titre de comparaison, les sections geektimes semblent plus modestes:
hubs_gt = {'popular_science', 'history', 'soft', 'lifehacks', 'health', 'finance', 'artificial_intelligence', 'itcompanies', 'DIY', 'energy', 'transport', 'gadgets', 'social_networks', 'space', 'futurenow', 'it_bigraphy', 'antikvariat', 'games', 'hardware', 'learning_languages', 'urban', 'brain', 'internet_of_things', 'easyelectronics', 'cellular', 'physics', 'cryptocurrency', 'interviews', 'biotech', 'network_hardware', 'autogadgets', 'lasers', 'sound', 'home_automation', 'smartphones', 'statistics', 'robot', 'cpu', 'video_tech', 'Ecology', 'presentation', 'desktops', 'wearable_electronics', 'quantum', 'notebooks', 'cyberpunk', 'Peripheral', 'demoscene', 'copyright', 'astronomy', 'arvr', 'medgadgets', '3d-printers', 'Chemistry', 'storages', 'sci-fi', 'logic_games', 'office', 'tablets', 'displays', 'video_conferencing', 'videocards', 'photo', 'multicopters', 'supercomputers', 'telemedicine', 'cybersport', 'nano', 'crowdsourcing', 'infographics'}
De même, les hubs restants ont été enregistrés. Maintenant, il est facile d'écrire une fonction qui renvoie le résultat, l'article fait référence à des geektimes ou à un hub de profil.
def is_geektimes(hubs: List) -> bool: return len(set(hubs) & hubs_gt) > 0 def is_geektimes_only(hubs: List) -> bool: return is_geektimes(hubs) is True and is_profile(hubs) is False def is_profile(hubs: List) -> bool: return len(set(hubs) & hubs_profile) > 0
Des fonctions similaires ont été faites pour d'autres sections («développement», «administration», etc.).
Traitement
Il est temps de commencer l'analyse. Téléchargez l'ensemble de données et traitez les données à partir des concentrateurs.
def to_list(s: str) -> List[str]:
Nous pouvons maintenant regrouper les données par jour et afficher le nombre de publications par différents hubs.
g = df.groupby(['date']) days_count = g.size().reset_index(name='counts') year_days = days_count['date'].values grouped = g.sum().reset_index() profile_per_day_avg = grouped['is_profile'].rolling(window=20, min_periods=1).mean() geektimes_per_day_avg = grouped['is_geektimes'].rolling(window=20, min_periods=1).mean() geektimesonly_per_day_avg = grouped['is_geektimes_only'].rolling(window=20, min_periods=1).mean() admin_per_day_avg = grouped['is_admin'].rolling(window=20, min_periods=1).mean() develop_per_day_avg = grouped['is_develop'].rolling(window=20, min_periods=1).mean()
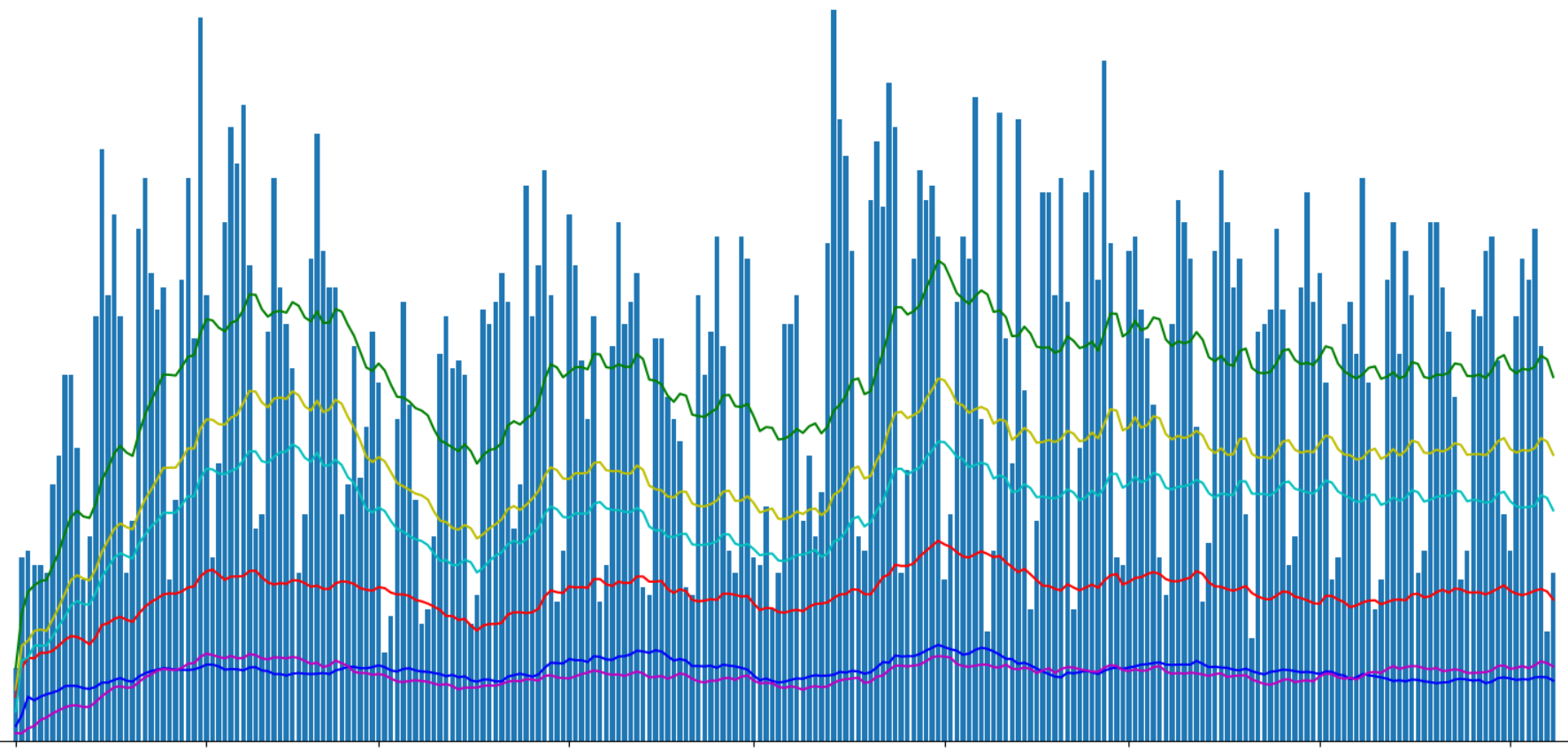
Affichez le nombre d'articles publiés à l'aide de Matplotlib:

J'ai divisé les articles «geektimes» et «geektimes only» dans le graphique, car un article peut appartenir aux deux sections simultanément (par exemple, "DIY" + "microcontrôleurs" + "C ++"). Avec la désignation «profile», j'ai mis en évidence les articles de profil du site, bien qu'il soit possible que le terme anglais profile ne soit pas tout à fait correct pour cela.
Dans la partie précédente, nous avons posé des questions sur «l'effet geektimes» associé au changement des règles de paiement des articles pour les geektimes à partir de cet été. Nous dérivons des articles geektimes distincts:
df_gt = df[(df['is_geektimes_only'] == True)] group_gt = df_gt.groupby(['date']) days_count_gt = group_gt.size().reset_index(name='counts') grouped = group_gt.sum().reset_index() year_days_gt = days_count_gt['date'].values view_gt_per_day_avg = grouped['views'].rolling(window=20, min_periods=1).mean()
Le résultat est intéressant. Le rapport approximatif des vues des articles geektimes au total quelque part autour de 1: 5. Mais si le nombre total de vues fluctuait sensiblement, alors le visionnage d'articles "divertissants" était maintenu à peu près au même niveau.

Vous pouvez également remarquer que le nombre total de vues d'articles dans la section "geektimes" après avoir changé les règles a encore baissé, mais "à l'oeil nu", pas plus de 5% des valeurs totales.
Il est intéressant de voir le nombre moyen de vues par article:

Pour les articles "divertissants", il est supérieur d'environ 40% à la moyenne. Ce n'est probablement pas surprenant. L'échec au début du mois d'avril n'est pas clair pour moi, peut-être que c'était, ou est-ce une sorte d'erreur d'analyse, ou peut-être qu'un des auteurs geektimes est parti en vacances;).
Soit dit en passant, sur le graphique, il y a deux pics plus visibles dans le nombre de vues d'articles - Nouvel an et vacances de mai.
Hubs
Passons à l'analyse promise des hubs. Nous afficherons les 20 principaux hubs par le nombre de vues:
hubs_info = [] for hub_name in hubs_all: mask = df['hubs'].apply(lambda x: hub_name in x) df_hub = df[mask] count, views = df_hub.shape[0], df_hub['views'].sum() hubs_info.append((hub_name, count, views))
Résultat:

Étonnamment, le hub «Sécurité de l'information» s'est avéré être le plus populaire en termes de visualisation, également «Programmation» et «Science populaire» sont dans le top 5 des leaders.
Antitope prend Gtk et Cocoa.

Je vais vous dire un secret, les hubs supérieurs peuvent également être vus
ici , bien que le nombre de vues n'y soit pas affiché.
Évaluation
Et enfin, la note promise. En utilisant les données de l'analyse des hubs, nous pouvons afficher les articles les plus populaires sur les hubs les plus populaires pour cette année 2019.
Sécurité de l'information- Comment je n'ai pas travaillé pendant un an chez Sberbank 304000 vues, 599 commentaires, note + 457.0 / -14.0
- Les ampoules intelligentes jetées à la poubelle sont une source précieuse d'informations personnelles 232 000 vues, 147 commentaires, note + 75,0 / -11,0
- Fraudsters et EDS - tout va très mal 176 000 vues, 778 commentaires, note + 356,0 / -0,0
- Comment Megafon a dormi sur les abonnements mobiles 166 000 vues, 676 commentaires, note + 624,0 / -2,0
- Le piratage VK, l'authentification à deux facteurs ne sauvera pas 148 000 vues, 332 commentaires, note + 124,0 / -17,0
- Comment le navigateur aide le camarade Major 132 000 vues, 321 commentaires, note + 246,0 / -19,0
- Le plus grand dépotoir de l'histoire: 2,7 milliards de comptes, dont 773 millions uniques 123 000 vues, 154 commentaires, note + 86,0 / -5,0
- Chérie, nous tuons Internet 121 000 vues, 933 commentaires, note + 392,0 / -83,0
- «Contenu mobile» gratuitement, sans SMS et inscriptions. Détails sur la fraude Megafon 114 000 vues, 478 commentaires, note + 488,0 / -8,0
- Scanner de port dans le compte personnel de Rostelecom 111 000 vues, 194 commentaires, note + 300,0 / -8,0
Programmation- Environ un gars 167 000 vues, 249 commentaires, note + 239,0 / -33,0
- Plus vite vous oubliez la POO, mieux c'est pour vous et vos programmes 129 000 vues, 1271 commentaires, note + 131,0 / -63,0
- Pourquoi les développeurs seniors ne peuvent pas obtenir un emploi 119 000 vues, 901 commentaires, note + 151,0 / -14,0
- Les personnes âgées n'appartiennent pas ici? Nous programmons après trente-cinq 116 000 vues, 649 commentaires, note + 222,0 / -16,0
- De nouveaux langages de programmation tuent imperceptiblement notre connexion avec la réalité 106 000 vues, 764 commentaires, note + 164,0 / -52,0
- Ce que j'ai appris de mon amère expérience (plus de 30 ans dans le développement de logiciels) 101 000 vues, 128 commentaires, note + 178,0 / -9,0
- Les langages de programmation les plus rares et les plus chers 82900 vues, 119 commentaires, note + 38,0 / -10,0
- Cours magistral en JavaScript et Node.js dans le KPI 80300 vues, 14 commentaires, note + 34.0 / -2.0
- Termes informatiques sur l'exemple du processus de culture des pommes de terre 78000 vues, 86 commentaires, note + 84.0 / -14.0
- 256 lignes de C ++ nu: écrire un traceur de rayons à partir de zéro en quelques heures 77600 vues, 124 commentaires, note + 241.0 / -0.0
Science populaire- Ce que le créateur a fumé: une arme à feu inhabituelle 236 000 vues, 123 commentaires, note + 119,0 / -9,0
- Les scientifiques ont trouvé le plus vieux vertébré vivant sur Terre 234 000 vues, 212 commentaires, note + 82,0 / -14,0
- La série 'Tchernobyl': regardez et pensez 173 000 vues, 803 commentaires, note + 164,0 / -25,0
- Un adolescent de 12 ans a effectué une réaction de fusion nucléaire dans son laboratoire d'origine 145 000 vues, 280 commentaires, note + 126,0 / -29,0
- The Tale of the Rose Alloy and the Fallen Krenka 134 000 vues, 244 commentaires, note + 217,0 / -1,0
- Augmentez-le! Augmentation moderne de la résolution 134000 vues, 235 commentaires, note + 377,0 / -1,0
- Le logiciel du Boeing-737 Max a été écrit par des sous-traitants gagnant 9 $ de l'heure ; 126 000 vues; 560 commentaires; note + 153,0 / -6,0
- Ne soyez pas nerveux, ne vous précipitez pas, n'interrompez pas: l'histoire d'une tragédie 121 000 vues, 384 commentaires, note + 242,0 / -4,0
- Les mathématiciens ont trouvé le moyen idéal pour multiplier les nombres 108 000 vues, 222 commentaires, note + 173,0 / -10,0
- De nouveaux langages de programmation tuent imperceptiblement notre connexion avec la réalité 106 000 vues, 764 commentaires, note + 164,0 / -52,0
Carrière- Comment je n'ai pas travaillé pendant un an chez Sberbank 304000 vues, 599 commentaires, note + 457.0 / -14.0
- Je ruine la vie des développeurs avec mes critiques de code et je suis désolé 187 000 vues, 21 commentaires, note + 37,0 / -3,0
- Development King 179 000 vues, 668 commentaires, note + 315,0 / -60,0
- Environ un gars 167 000 vues, 249 commentaires, note + 239,0 / -33,0
- Retired at 22,158,000 views, 927 comments, rating + 259.0 / -100.0
- Comment remplacer une ampoule sur le lieu de travail pour ne pas être licencié? 139000 vues, 762 commentaires, note + 200,0 / -20,0
- Innovation en russe 128 000 vues, 612 commentaires, note + 480,0 / -33,0
- Pourquoi les développeurs seniors ne peuvent pas obtenir un emploi 119 000 vues, 901 commentaires, note + 151,0 / -14,0
- Employés «brûlés»: y a-t-il une issue? 117000 vues, 398 commentaires, note + 210,0 / -14,0
- Les personnes âgées n'appartiennent pas ici? Nous programmons après trente-cinq 116 000 vues, 649 commentaires, note + 222,0 / -16,0
Législation informatique- Fraudsters et EDS - tout va très mal 176 000 vues, 778 commentaires, note + 356,0 / -0,0
- Comment Megafon a dormi sur les abonnements mobiles 166 000 vues, 676 commentaires, note + 624,0 / -2,0
- Innovation en russe 128 000 vues, 612 commentaires, note + 480,0 / -33,0
- «Contenu mobile» gratuitement, sans SMS et inscriptions. Détails sur la fraude Megafon 114 000 vues, 478 commentaires, note + 488,0 / -8,0
- Alors que les autorités du Kazakhstan tentent de couvrir leur échec avec l'introduction du certificat 111 000 vues, 77 commentaires, note + 122,0 / -14,0
- Comment Protonmail est bloqué en Russie 102000 vues, 398 commentaires, note + 418,0 / -7,0
- La loi sur l'isolement du runet a été adoptée par la Douma d'État en trois lectures, 88 200 vues, 878 commentaires, note + 73,0 / -18,0
- En tant que programmeur, la banque a choisi et lu le contrat 87 200 vues, 611 commentaires, note + 166,0 / -9,0
- Le ministère des Communications et des Médias de masse a approuvé le projet de loi sur l'isolement de Runet 83600 vues, 364 commentaires, note + 79,0 / -9,0
- Une réponse détaillée au commentaire, ainsi qu'un peu sur la vie des prestataires en Fédération de Russie, 74700 vues, 389 commentaires, note + 290.0 / -1.0
Développement Web- Les personnes âgées n'appartiennent pas ici? Nous programmons après trente-cinq 116 000 vues, 649 commentaires, note + 222,0 / -16,0
- Comment faire des sites en 2019110 000 vues, 278 commentaires, note + 233,0 / -11,0
- Learning Docker, Part 1: Basics 91300 vues, 24 commentaires, note + 52,0 / -10,0
- Cours magistral en JavaScript et Node.js dans le KPI 80300 vues, 14 commentaires, note + 34.0 / -2.0
- Stagiaire Vasya et ses histoires sur l'API idempotency 68900 vues, 160 commentaires, note + 216,0 / -3,0
- La compréhension des jointures est rompue. Ce n'est certainement pas l'intersection des cercles, honnêtement 65 900 vues, 223 commentaires, note + 138,0 / -41,0
- Pourquoi vous n'avez pas besoin de passer votre temps à créer des sites thématiques de niche 62700 vues, 243 commentaires, note + 179,0 / -13,0
- Nous créons une application web moderne à partir de zéro 62200 vues, 122 commentaires, note + 56.0 / -8.0
- Un jour sombre pour Vue.js 60 800 vues, 133 commentaires, note + 77,0 / -6,0
- Pourquoi le développement web moderne est-il si compliqué? Partie 1577700 vues, 319 commentaires, note + 101,0 / -6,0
GTKEt enfin, pour ne choquer personne, je vais vous donner la note du hub le moins visité "gtk". Dans ce document,
un article a été publié au cours de l'année, il occupe également «automatiquement» la première ligne de la note.
Conclusion
Il n'y aura aucune conclusion. Bonne lecture à tout le monde.