
Aujourd'hui, mercredi, la prochaine version de Kubernetes
aura lieu - 1.16. Selon la tradition qui s'est développée pour notre blog, pour le dixième anniversaire, nous parlons des changements les plus importants de la nouvelle version.
Les informations utilisées pour préparer ce matériel sont tirées du
tableau de suivi des améliorations de Kubernetes , de
CHANGELOG-1.16 et des problèmes connexes, des demandes d'extraction, ainsi que des propositions d'amélioration de Kubernetes (KEP). Alors allons-y! ..
Noeuds
Un très grand nombre d'innovations notables (dans l'état de la version alpha) sont présentées du côté des nœuds des clusters K8s (Kubelet).
Tout d'abord, les soi-disant
« conteneurs éphémères » (conteneurs éphémères) sont présentés
, conçus pour simplifier le processus de débogage dans les pods . Le nouveau mécanisme vous permet d'exécuter des conteneurs spéciaux qui démarrent dans l'espace de noms des pods existants et vivent pendant une courte période. Leur but est d'interagir avec d'autres pods et conteneurs afin de résoudre tout problème et débogage. Pour cette fonctionnalité, une nouvelle commande de
kubectl debug est
kubectl debug , similaire en substance à
kubectl exec : seulement au lieu de démarrer le processus dans le conteneur (comme dans le cas de
exec ), il démarre le conteneur dans pod. Par exemple, une telle commande connectera un nouveau conteneur au pod:
kubectl debug -c debug-shell --image=debian target-pod -- bash
Des détails sur les conteneurs éphémères (et des exemples de leur utilisation) peuvent être trouvés dans le
KEP correspondant . L'implémentation actuelle (dans K8s 1.16) est la version alpha, et parmi les critères pour son transfert vers la version bêta, il y a "tester l'API Ephemeral Containers pour au moins 2 versions [Kubernetes]".
NB : En substance et même le nom de la fonctionnalité ressemble au plugin kubectl-debug déjà existant, dont nous avons déjà parlé . On suppose qu'avec l'avènement des conteneurs éphémères, le développement d'un plug-in externe séparé s'arrêtera.Une autre innovation,
PodOverhead est conçue pour fournir un
mécanisme de calcul des frais généraux des pods , qui peuvent varier considérablement en fonction du temps d'exécution utilisé. À titre d'exemple, les auteurs de
ce KEP citent les conteneurs Kata, qui nécessitent le lancement du noyau invité, de l'agent kata, du système init, etc. Lorsque les frais généraux deviennent si importants, ils ne peuvent pas être ignorés, ce qui signifie qu'un moyen est nécessaire pour les prendre en compte pour d'autres quotas, la planification, etc. Pour l'implémenter, le champ
Overhead *ResourceList a été ajouté à
PodSpec (par rapport aux données de
RuntimeClass , le cas échéant).
Une autre innovation notable est le
Node Topology Manager , conçu pour unifier l'approche permettant d'affiner l'allocation des ressources matérielles pour divers composants dans Kubernetes. Cette initiative est causée par la demande croissante de divers systèmes modernes (du domaine des télécommunications, de l'apprentissage automatique, des services financiers, etc.) pour le calcul parallèle haute performance et la minimisation des retards dans l'exécution des opérations, pour lesquels ils utilisent les capacités avancées d'accélération CPU et matérielle. De telles optimisations dans Kubernetes ont été réalisées jusqu'à présent grâce à des composants disparates (gestionnaire de CPU, gestionnaire de périphériques, CNI), et maintenant elles ajouteront une interface interne unique qui unifie l'approche et simplifie la connexion de nouveaux composants similaires - appelés soi-disant topologiques - côté Kubelet. Les détails sont dans le
KEP correspondant .
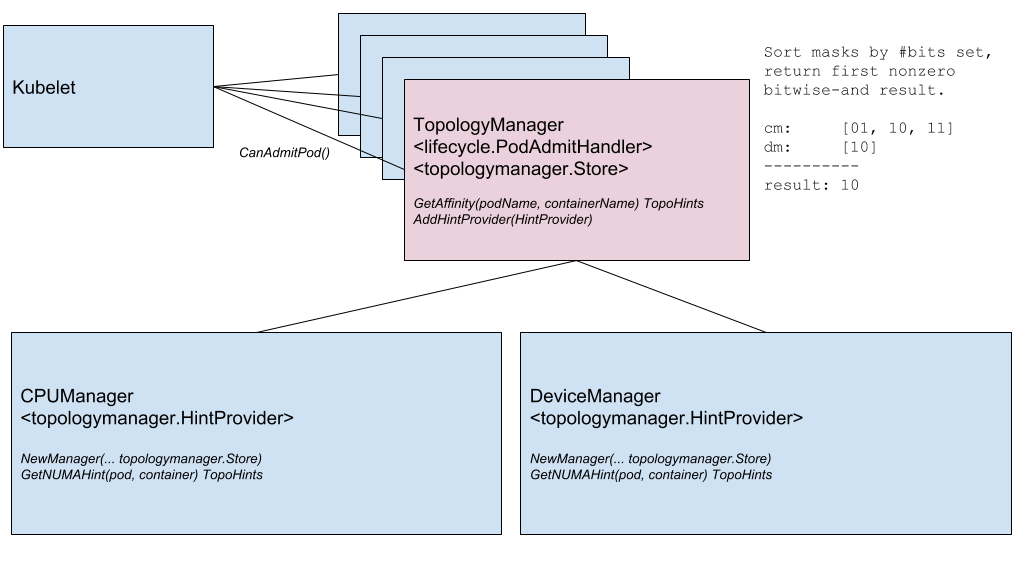 Diagramme des composants du gestionnaire de topologie
Diagramme des composants du gestionnaire de topologieLa fonctionnalité suivante
vérifie les conteneurs lors du démarrage ( sonde de démarrage ) . Comme vous le savez, pour les conteneurs qui fonctionnent longtemps, il est difficile d'obtenir l'état actuel: ils sont soit "tués" avant le début réel de l'opération, soit ils se retrouvent dans une impasse pendant longtemps. Une nouvelle vérification (activée via la porte de fonctionnalité appelée
StartupProbeEnabled ) annule - ou plutôt
StartupProbeEnabled - l'action de toute autre vérification jusqu'au moment où le pod a terminé son lancement. Pour cette raison, la fonctionnalité était à l'origine appelée
holdoff de sonde de vie de pod-startup . Pour les pods dont le démarrage est long, vous pouvez interroger l'état à des intervalles de temps relativement courts.
De plus, immédiatement en version bêta, une amélioration de RuntimeClass est ajoutée, ajoutant la prise en charge des «clusters hétérogènes». Avec
RuntimeClass Scheduling, il n'est plus nécessaire que chaque nœud prenne en charge chaque RuntimeClass: pour les pods, vous pouvez choisir RuntimeClass sans penser à la topologie du cluster. Auparavant, pour y parvenir - afin que les pods apparaissent sur les nœuds avec la prise en charge de tout ce dont ils avaient besoin - ils devaient attribuer des règles appropriées à NodeSelector et des tolérances.
KEP parle d'exemples d'utilisation et, bien sûr, de détails d'implémentation.
Réseau
Deux fonctionnalités réseau importantes qui sont apparues pour la première fois (dans la version alpha) dans Kubernetes 1.16 sont:
- Prise en charge d'une double pile réseau - IPv4 / IPv6 - et sa "compréhension" correspondante au niveau des pods, nœuds, services. Il comprend l'interaction d'IPv4 à IPv4 et d'IPv6 à IPv6 entre les pods, des pods aux services externes, les implémentations de référence (dans le cadre des ponts Bridge CNI, PTP CNI et Host-Local IPAM), ainsi que l'inverse Compatible avec les clusters Kubernetes qui fonctionnent uniquement sur IPv4 ou IPv6. Les détails d'implémentation sont dans KEP .
Un exemple de la sortie de deux types d'adresses IP (IPv4 et IPv6) dans la liste des pods:
kube-master
- La nouvelle API pour Endpoint est l' API EndpointSlice . Il résout les problèmes de l'API Endpoint existante avec des performances / évolutivité qui affectent divers composants dans le plan de contrôle (apiserver, etcd, endpoints-controller, kube-proxy). La nouvelle API sera ajoutée au groupe Discovery API et pourra servir des dizaines de milliers de points de terminaison principaux sur chaque service dans un cluster composé d'un millier de nœuds. Pour ce faire, chaque service est mappé à N objets
EndpointSlice , dont chacun par défaut n'a pas plus de 100 points de terminaison (la valeur est configurable). L'API EndpointSlice offrira également des opportunités pour son développement futur: prise en charge de nombreuses adresses IP pour chaque module, nouveaux états pour les points de terminaison (non seulement Ready et NotReady ), sous-ensemble dynamique pour les points de terminaison.
Le
finaliseur présenté dans la dernière version appelée
service.kubernetes.io/load-balancer-cleanup et attaché à chaque service avec le type
LoadBalancer passé à la version bêta. Au moment de la suppression d'un tel service, il empêche la suppression effective de la ressource jusqu'à ce que le "nettoyage" de toutes les ressources correspondantes de l'équilibreur soit terminé.
Machines API
Le véritable «jalon de stabilisation» est fixé dans la zone du serveur API Kubernetes et l'interaction avec lui. À bien des égards, cela s'est produit en raison du
transfert au statut stable de CustomResourceDefinitions (CRD) qui
n'avait pas besoin d'une présentation spéciale , qui avait un statut bêta depuis le lointain Kubernetes 1.7 (et c'est juin 2017!). La même stabilisation est venue aux caractéristiques qui leur sont liées:
- "Sous-ressources" avec
/status et /scale pour CustomResources; - conversion de version pour CRD, basée sur un webhook externe;
- récemment introduit (dans K8s 1.15) les valeurs par défaut (par défaut) et la suppression automatique des champs (élagage) pour CustomResources;
- la possibilité d' utiliser le schéma OpenAPI v3 pour créer et publier la documentation OpenAPI utilisée pour valider les ressources CRD côté serveur.
Un autre mécanisme qui est depuis longtemps familier aux administrateurs de Kubernetes: l'
admission webhook - est également en version bêta depuis longtemps (depuis K8s 1.9) et a maintenant été déclaré stable.
Deux autres fonctionnalités ont atteint la version bêta:
appliquer côté serveur et
regarder les signets .
Et la seule innovation significative dans la version alpha a été le
rejet de SelfLink - un URI spécial qui représente l'objet spécifié et fait partie d'
ListMeta et de
ListMeta (c'est-à-dire une partie de tout objet dans Kubernetes). Pourquoi le refuser? La motivation «simple»
sonne comme l'absence de raisons réelles (insurmontables) pour que ce domaine continue d'exister. Des raisons plus formelles sont d'optimiser les performances (supprimer un champ inutile) et de simplifier le travail de generic-apiserver, qui est obligé de traiter un tel champ d'une manière spéciale (c'est le seul champ qui est défini juste avant la sérialisation de l'objet). La véritable «obsolescence» (dans la version bêta) de
SelfLink arrivera à la version 1.20 de Kubernetes, et la dernière - 1.21.
Stockage de données
Le travail principal dans le domaine du stockage, comme dans les versions précédentes, est observé dans le domaine du
support pour CSI . Les principaux changements sont les suivants:
- pour la première fois (dans la version alpha) , la prise en charge des plug-ins CSI pour les nœuds de travail Windows est apparue : la manière actuelle de travailler avec les référentiels remplacera les plug-ins dans l'arborescence du noyau Kubernetes et les plug-ins FlexVolume basés sur Powershell de Microsoft;
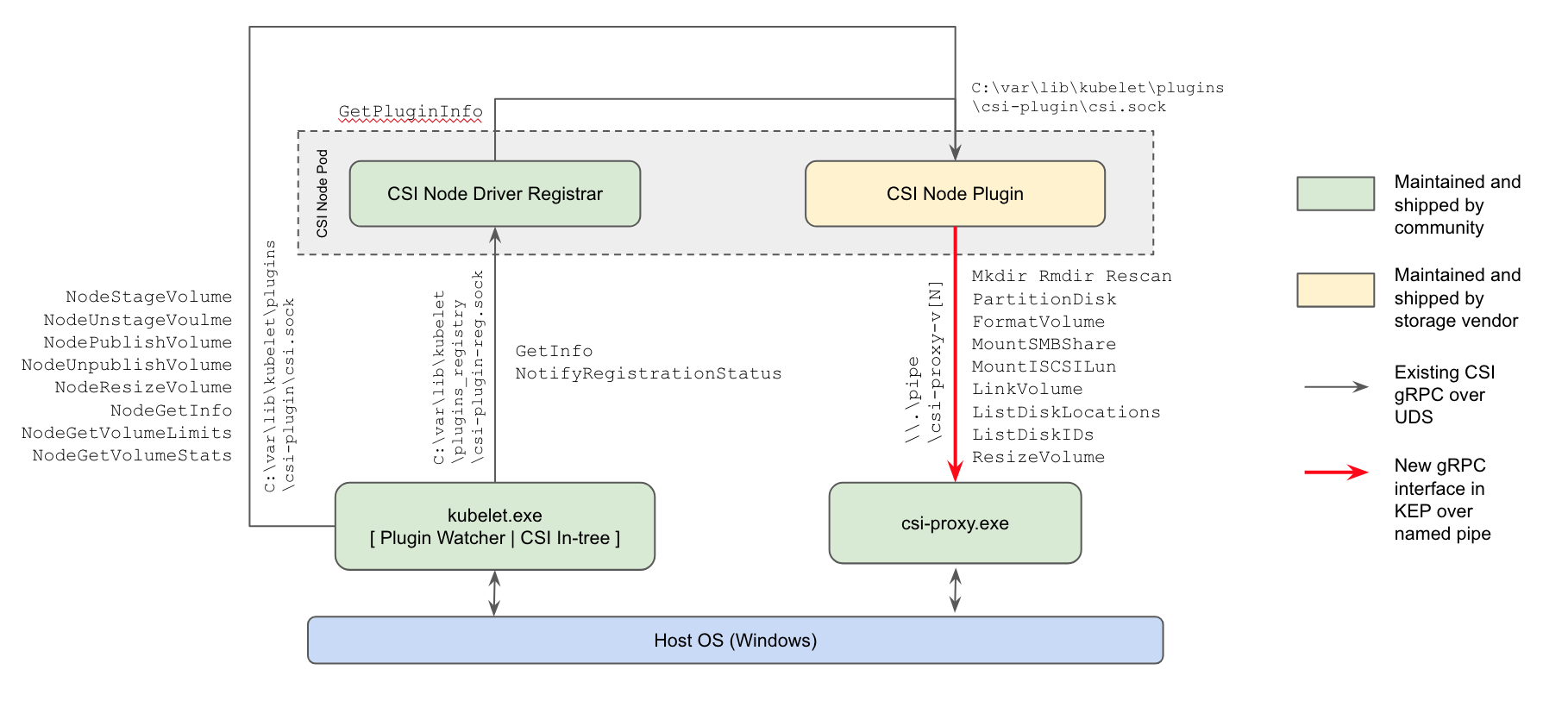
Schéma d'implémentation du plug-in CSI Windows Kubernetes
- la possibilité de redimensionner les volumes CSI , introduite dans K8s 1.12, est devenue une version bêta;
- la possibilité d'utiliser CSI pour créer des volumes éphémères locaux ( CSI Inline Volume Support ) a atteint une «augmentation» similaire (de l'alpha à la bêta).
La
fonction de clonage de volumes apparue dans la version précédente de Kubernetes (utilisant des PVC existants comme
DataSource pour créer de nouveaux PVC) a également reçu le statut bêta.
Planificateur
Deux changements notables dans la planification (tous deux en version alpha):
EvenPodsSpreading est la possibilité d' utiliser des EvenPodsSpreading pour "répartir équitablement" des charges de charges au lieu d'unités logiques d'application (comme Deployment et ReplicaSet) et d'ajuster cette distribution (comme une exigence stricte ou comme une condition modérée, c'est-à-dire une priorité). Cette fonctionnalité étendra les capacités de distribution existantes des pods prévus, désormais limitées par les PodAntiAffinity PodAffinity et PodAntiAffinity , offrant aux administrateurs un contrôle plus fin dans ce domaine, ce qui signifie une meilleure accessibilité et une consommation de ressources optimisée. Les détails sont dans le KEP .- Utilisation de la stratégie BestFit dans la fonction de priorité RequestedToCapacityRatio lors de la planification des pods, qui permet à l' emballage bin («emballage dans des conteneurs») d'être utilisé à la fois pour les ressources de base (processeur, mémoire) et étendues (comme le GPU). Voir KEP pour plus de détails.

Planification des pods: avant d'utiliser la politique de meilleur ajustement (directement via le planificateur par défaut) et de l'utiliser (via l'extension du planificateur)
De plus,
l' opportunité
est présentée de créer vos propres plugins pour le planificateur en dehors de l'arbre de développement principal de Kubernetes (hors arborescence).
Autres changements
Également dans la version Kubernetes 1.16, vous pouvez noter l'
initiative visant à mettre les métriques existantes en ordre complet , ou plus précisément, conformément aux
exigences officielles pour l'instrumentation K8. Ils s'appuient essentiellement sur la
documentation Prometheus pertinente. Les incohérences ont été formulées pour diverses raisons (par exemple, certaines mesures ont été simplement créées avant que les instructions actuelles n'apparaissent), et les développeurs ont décidé qu'il était temps de tout mettre à un seul standard, "en ligne avec le reste de l'écosystème Prometheus". La mise en œuvre actuelle de cette initiative a le statut de la version alpha, qui augmentera progressivement dans les futures versions de Kubernetes en beta (1.17) et stable (1.18).
De plus, les changements suivants peuvent être notés:
- Développement de la prise en charge de Windows avec l' avènement de l'utilitaire Kubeadm pour ce système d'exploitation (version alpha), la possibilité de
RunAsUserName pour les conteneurs Windows (version alpha), l' amélioration de la prise en charge du compte de service géré de groupe (gMSA) vers la version bêta, le support de montage / attachement pour les volumes vSphere. - Mécanisme de compression des données repensé dans les réponses API . Auparavant, un filtre HTTP était utilisé à ces fins, ce qui imposait un certain nombre de restrictions qui empêchaient son inclusion par défaut. Maintenant, la "compression transparente des requêtes" fonctionne: les clients qui envoient
Accept-Encoding: gzip dans l'en-tête reçoivent une réponse compressée dans GZIP si sa taille dépasse 128 Ko. Les clients en déplacement prennent automatiquement en charge la compression (envoient l'en-tête souhaité), de sorte qu'ils remarquent immédiatement une diminution du trafic. (Pour d'autres langues, des modifications mineures peuvent être nécessaires.) - Il est devenu possible de faire évoluer HPA de / vers zéro pods sur la base de mesures externes . Si la mise à l'échelle est basée sur des objets / mesures externes, alors lorsque les charges de travail sont inactives, vous pouvez automatiquement mettre à l'échelle 0 répliques pour économiser les ressources. Cette fonctionnalité devrait être particulièrement utile dans les cas où les travailleurs demandent des ressources GPU et que le nombre de types différents de travailleurs inactifs dépasse le nombre de GPU disponibles.
- Un nouveau client -
k8s.io/client-go/metadata.Client - pour un accès "généralisé" aux objets. Il est conçu pour obtenir facilement des métadonnées (c'est-à-dire la sous-section des metadata ) à partir des ressources du cluster et effectuer des opérations avec elles dans la catégorie de collecte de déchets et des quotas. - Kubernetes peut désormais être construit sans fournisseurs de cloud obsolètes (dans l'arborescence «intégrée») (version alpha).
- La capacité expérimentale (version alpha) d'appliquer des correctifs kustomize pendant les opérations d'
init , de join et de upgrade a été ajoutée à l' utilitaire kubeadm. Pour plus de détails sur l'utilisation de l' --experimental-kustomize , voir KEP . - Le nouveau noeud final pour apiserver est
readyz , ce qui vous permet d'exporter des informations de préparation. Le serveur API a également un indicateur --maximum-startup-sequence-duration , qui vous permet d'ajuster ses redémarrages. - Deux fonctionnalités pour Azure sont déclarées stables: la prise en charge des zones de disponibilité et le groupe de ressources croisées (RG). De plus, Azure a ajouté:
- AWS prend en charge EBS sur Windows et l'API EC2 optimisée appelle
DescribeInstances . - Kubeadm migre désormais lui-même sa configuration CoreDNS lors de la mise à niveau vers CoreDNS.
- Les fichiers binaires etcd dans l'image Docker correspondante sont exécutables dans le monde entier, ce qui vous permet d'exécuter cette image sans avoir besoin des privilèges root. De plus, l'image de migration etcd a supprimé la prise en charge de la version etcd2.
- Cluster Autoscaler 1.16.0 est passé à l'utilisation de l'image sans distraction comme image de base, a amélioré les performances et a ajouté de nouveaux fournisseurs de cloud (DigitalOcean, Magnum, Packet).
- Mises à jour du logiciel utilisé / dépendant: Go 1.12.9, etcd 3.3.15, CoreDNS 1.6.2.
PS
Lisez aussi dans notre blog: