CQM est un regard différent dans l'apprentissage en profondeur pour optimiser les recherches en langage naturel
Brève description: Le maillage quantique calibré (CQM) est la prochaine étape de RNN / LSTM (réseaux de neurones récurrents) / mémoire à long terme à court terme (LSTM). Il existe un nouvel algorithme appelé Calibration Quantum Mesh (CQM), qui promet d'augmenter la précision des recherches en langage naturel sans utiliser de données d'entraînement étiquetées.
Un tout nouvel algorithme de recherche en langage naturel (NLS) et de compréhension du langage naturel (NLU) a été créé, qui surpasse non seulement les algorithmes traditionnels RNN / LSTM ou même CNN, mais est également auto-apprentissage et ne nécessite pas de données marquées pour la formation.
Cela semble trop beau pour être vrai, mais les premiers résultats sont impressionnants. CQM - développé par Praful Krishna et son équipe de Coseer (San Francisco).
Bien que l'entreprise soit encore petite, ils travaillent avec plusieurs sociétés du Fortune 500 et ont commencé à organiser des conférences techniques.
C'est là qu'ils espèrent faire leurs preuves:
Précision: Selon Krishna, la fonction NLS moyenne dans un chatbot moins sérieux, en règle générale, n'a une précision que d'environ 70%.
Les demandes initiales de Coseer ont atteint une précision de plus de 95% en renvoyant les informations pertinentes pertinentes. Les mots clés ne sont pas requis.
Les données de formation étiquetées ne sont pas nécessaires: nous savons tous que les données de formation étiquetées sont une dépense financière et de temps qui limite la précision de nos robots de discussion.
Il y a quelques années, M.D. Anderson a abandonné son expérience coûteuse et longue avec IBM Watson pour l'oncologie en raison de la précision.
Ce qui retenait la précision, c'était la nécessité pour les chercheurs en cancérologie très expérimentés d'annoter les documents dans l'enceinte. Ils auraient dû faire cela au lieu de faire leurs recherches.
Rapidité de mise en œuvre: Coseer dit que sans données de formation, la plupart des déploiements peuvent être lancés en 4 à 12 semaines. C'est beaucoup moins que lorsque l'utilisateur commence à utiliser un système pré-formé, dont le fonctionnement commence par le chargement préalable des documents balisés.
De plus, contrairement aux grands fournisseurs actuels utilisant des algorithmes traditionnels d'apprentissage en profondeur, Coseer préfère les déployer dans un cloud sécurisé et privé pour garantir la sécurité des données.
Toutes les «preuves» utilisées pour arriver à une conclusion sont stockées dans un journal qui peut être utilisé pour démontrer la transparence et le respect des règles de sécurité des données telles que le RGPD.
Comment ça marche
Coseer parle des trois principes qui définissent le CQM:
1. Les mots (variables) ont des significations différentes.
Considérez le mot «four», qui peut être un nom ou un verbe. Par exemple, «vers», qui peut signifier «poème» ou le verbe «vent de vers» - ce sont les mots homonymes.
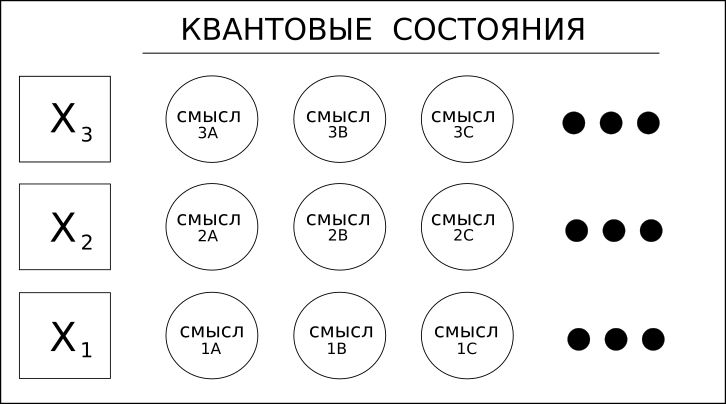
Les solutions d'apprentissage en profondeur, y compris RNN / LSTM ou même CNN pour le texte, ne peuvent que regarder en avant ou en arrière pour déterminer le "contexte" d'un mot et ainsi déterminer sa signification.
Coseer prend en compte toutes les significations possibles du mot et applique une probabilité statistique à chacune d'entre elles sur la base de l'ensemble du document ou du corpus.
L'utilisation du terme "quantique" dans ce cas se réfère uniquement à la possibilité de valeurs multiples, et non à une superposition plus exotique de l'informatique quantique.
2. Tout est interconnecté dans une grille de valeurs:
Extraire de tous les mots (variables) disponibles toutes leurs relations possibles est le deuxième principe.
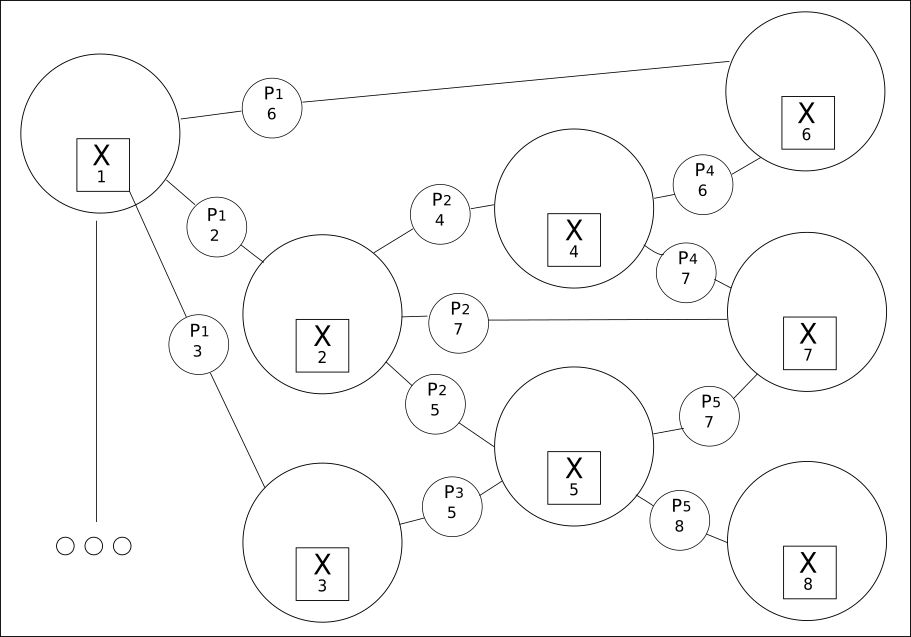
CQM crée une grille de valeurs possibles, parmi lesquelles une valeur réelle sera trouvée. L'utilisation de cette approche révèle une relation beaucoup plus large entre les phrases précédentes ou suivantes que celle du Deep Learning traditionnel.
Bien que le nombre de mots puisse être limité, leurs relations peuvent être de plusieurs centaines de milliers.
3. Toutes les informations disponibles sont utilisées séquentiellement pour combiner la grille en une seule valeur. Ce processus d'étalonnage identifie rapidement les mots ou concepts manquants et fournit une formation très rapide et précise.
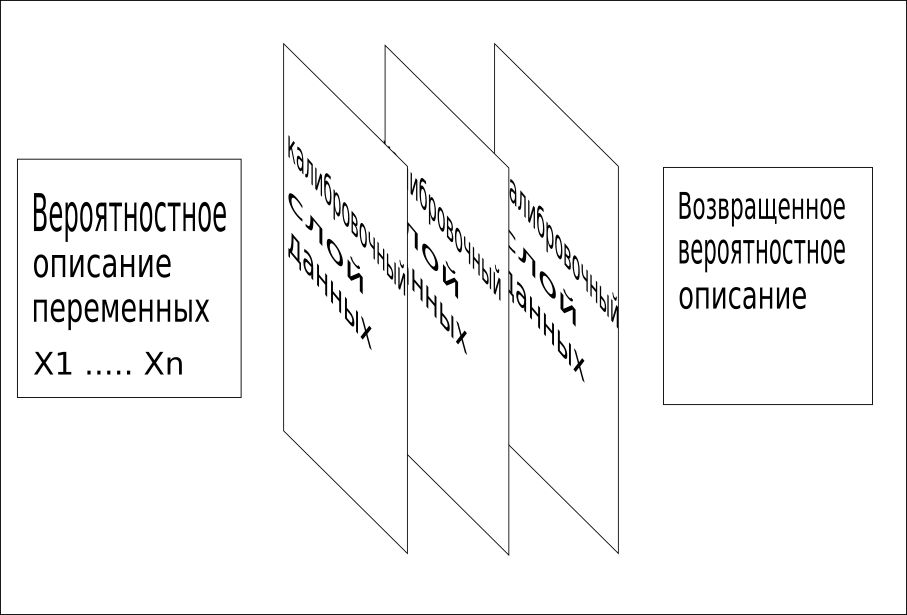
Les modèles CQM utilisent des données d'apprentissage, des données de contexte, des données de référence et d'autres faits connus sur le problème pour identifier ces couches de données d'étalonnage.
Malheureusement, Coseer a publié très peu dans le domaine public pour expliquer les aspects techniques de l'algorithme.
Toute percée dans l'élimination des données marquées pendant la formation doit être saluée et, bien sûr, l'amélioration de la précision entraînera le fait que des clients beaucoup plus satisfaits utiliseront votre bot de chat.