Présentation
Il y a quelques années, nous avons décidé qu'il était temps de prendre en charge le code SIMD dans .NET . Nous avons introduit l'espace de noms System.Numerics avec les types Vector2 , Vector3 , Vector4 et Vector<T> . Ces types représentent une API à usage général pour créer, accéder et manipuler des instructions vectorielles dans la mesure du possible. Ils offrent également une compatibilité logicielle dans les cas où le matériel ne prend pas en charge les instructions appropriées. Cela a permis, avec un refactoring minimal, de vectoriser un certain nombre d'algorithmes. Quoi qu'il en soit, la généralité de cette approche rend son application difficile afin de tirer pleinement parti de toutes les instructions vectorielles disponibles, sur du matériel moderne. De plus, le matériel moderne fournit un certain nombre d'instructions spécialisées, non vectorielles, qui peuvent améliorer considérablement les performances. Dans cet article, je vais vous expliquer comment nous avons contourné ces limitations dans .NET Core 3.0.

Remarque: Il n'y a pas encore de terme établi pour la traduction Intrisics . À la fin de l'article, il y a un vote pour l'option de traduction. Si nous choisissons une bonne option, nous changerons l'article
Quelles sont les fonctions intégrées
Dans .NET Core 3.0, nous avons ajouté de nouvelles fonctionnalités appelées fonctions intégrées spécifiques au matériel (loin WF). Cette fonctionnalité donne accès à de nombreuses instructions matérielles spécifiques qui ne peuvent pas être simplement représentées par des mécanismes plus généraux. Ils diffèrent des instructions SIMD existantes en ce qu'ils n'ont pas un usage général (les nouveaux WF ne sont pas multiplateformes et leur architecture ne fournit pas de compatibilité logicielle). Au lieu de cela, ils fournissent directement des fonctionnalités spécifiques à la plateforme et au matériel pour les développeurs .NET. Les fonctions SIMD existantes, par exemple multiplateforme, offrent une compatibilité logicielle et sont légèrement abstraites du matériel sous-jacent. Cette abstraction peut être coûteuse, en plus, elle peut empêcher la divulgation de certaines fonctionnalités (lorsque, par exemple, la fonctionnalité n'existe pas ou est difficile à émuler sur toutes les plates-formes cibles).
Les nouvelles fonctions intégrées et les types pris en charge se trouvent sous l' System.Runtime.Intrinsics . Pour .NET Core 3.0, il existe actuellement un System.Runtime.Intrinsics.X86 . Nous travaillons sur la prise en charge des fonctions intégrées pour d'autres plates-formes telles que System.Runtime.Intrinsics.Arm .
Dans les espaces de noms spécifiques à la plate-forme, les WF sont regroupés en classes qui représentent des groupes d'instructions matérielles intégrées logiquement (souvent appelées architecture de jeu d'instructions (ISA)). Chaque classe fournit une propriété IsSupported indique si le matériel sur lequel le code s'exécute prend en charge cet ensemble d'instructions. En outre, chacune de ces classes contient un ensemble de méthodes mappées à un ensemble d'instructions correspondant. Parfois, il existe une sous-classe supplémentaire qui correspond à une partie du même jeu d'instructions, qui peut être limitée (prise en charge) par du matériel spécifique. Par exemple, la classe Lzcnt donne accès aux instructions pour compter les zéros non Lzcnt . Il possède une sous-classe appelée X64 , qui contient la forme de ces instructions utilisées uniquement sur les machines à architecture 64 bits.
Certaines de ces classes sont naturellement de nature hiérarchique. Par exemple, si Lzcnt.X64.IsSupported renvoie true, alors Lzcnt.IsSupported doit également renvoyer true, car il s'agit d'une sous-classe explicite. Ou, par exemple, si Sse2.IsSupported renvoie true, alors Sse.IsSupported doit retourner true, car Sse2 hérite explicitement de Sse . Cependant, il convient de noter que la similitude des noms de classe n'est pas un indicateur de leur appartenance à la même hiérarchie d'héritage. Par exemple, Bmi2 pas hérité de Bmi1 , donc les valeurs renvoyées par IsSupported pour ces deux ensembles d'instructions seront différentes. Le principe fondamental du développement de ces classes était la présentation explicite des spécifications ISA. SSE2 nécessite la prise en charge de SSE1, de sorte que les classes qui les représentent sont liées par héritage. Dans le même temps, BMI2 ne nécessite pas de prise en charge pour BMI1, nous n'avons donc pas utilisé d'héritage. Ce qui suit est un exemple de l'API ci-dessus.
namespace System.Runtime.Intrinsics.X86 { public abstract class Sse { public static bool IsSupported { get; } public static Vector128<float> Add(Vector128<float> left, Vector128<float> right); // Additional APIs public abstract class X64 { public static bool IsSupported { get; } public static long ConvertToInt64(Vector128<float> value); // Additional APIs } } public abstract class Sse2 : Sse { public static new bool IsSupported { get; } public static Vector128<byte> Add(Vector128<byte> left, Vector128<byte> right); // Additional APIs public new abstract class X64 : Sse.X64 { public static bool IsSupported { get; } public static long ConvertToInt64(Vector128<double> value); // Additional APIs } } }
Vous pouvez en voir plus dans le code source sur les liens suivants source.dot.net ou dotnet / coreclr sur GitHub
IsSupported vérifications IsSupported traitées par le compilateur JIT en tant que constantes d'exécution (lorsque l'optimisation est activée), vous n'avez donc pas besoin de compilation croisée pour prendre en charge plusieurs ISA, plates-formes ou architectures. Au lieu de cela, il vous suffit d'écrire le code à l'aide d'expressions if , à la suite de quoi les branches de code inutilisées (c'est-à-dire les branches qui ne sont pas accessibles en raison de la valeur de la variable dans l'instruction conditionnelle) seront ignorées lors de la génération du code natif.
Il est important que la vérification du IsSupported correspondant précède l'utilisation des commandes matérielles intégrées. S'il n'y a pas une telle vérification, le code qui utilise des commandes spécifiques à la plate-forme s'exécutant sur des plates-formes / architectures où ces commandes ne sont pas prises en charge lèvera une exception d'exécution PlatformNotSupportedException .
Quels avantages offrent-ils?
Bien sûr, les fonctions intégrées spécifiques au matériel ne sont pas pour tout le monde, mais elles peuvent être utilisées pour améliorer les performances des opérations chargées de calculs. CoreFX et ML.NET utilisent ces méthodes pour accélérer des opérations telles que la copie en mémoire, la recherche de l'index d'un élément dans un tableau ou une chaîne, le redimensionnement d'une image ou le travail avec des vecteurs / matrices / tenseurs. La vectorisation manuelle d'un code qui s'est avéré être un goulot d'étranglement peut également être plus simple qu'il n'y paraît. La vectorisation du code, en effet, consiste à effectuer plusieurs opérations à la fois, en général, à l'aide d'instructions SIMD (un flux d'instructions, plusieurs flux de données).
Avant de décider de vectoriser du code, vous devez effectuer un profilage pour vous assurer que ce code fait vraiment partie du «point chaud» (et, par conséquent, votre optimisation augmentera considérablement les performances). Il est également important d'effectuer un profilage à chaque étape de la vectorisation, car la vectorisation de tout le code n'entraîne pas une productivité accrue.
Vectorisation d'un algorithme simple
Pour illustrer l'utilisation des fonctions intégrées, nous prenons l'algorithme pour additionner tous les éléments d'un tableau ou d'une plage. Ce type de code est un candidat idéal pour la vectorisation, car à chaque itération, la même opération triviale est effectuée.
Un exemple d'implémentation d'un tel algorithme peut ressembler à ceci:
public int Sum(ReadOnlySpan<int> source) { int result = 0; for (int i = 0; i < source.Length; i++) { result += source[i]; } return result; }
Ce code est assez simple et direct, mais en même temps assez lent pour les données d'entrée volumineuses, comme ne fait qu'une seule opération triviale par itération.
BenchmarkDotNet=v0.11.5, OS=Windows 10.0.18362 AMD Ryzen 7 1800X, 1 CPU, 16 logical and 8 physical cores .NET Core SDK=3.0.100-preview9-013775 [Host] : .NET Core 3.0.0-preview9-19410-10 (CoreCLR 4.700.19.40902, CoreFX 4.700.19.40917), 64bit RyuJIT [AttachedDebugger] DefaultJob : .NET Core 3.0.0-preview9-19410-10 (CoreCLR 4.700.19.40902, CoreFX 4.700.19.40917), 64bit RyuJIT
Augmentez la productivité grâce aux cycles de déploiement
Les processeurs modernes ont diverses options pour améliorer les performances du code. Pour les applications monothread, une de ces options consiste à effectuer plusieurs opérations primitives en un seul cycle de processeur.
La plupart des processeurs modernes peuvent effectuer quatre opérations d'addition en un seul cycle d'horloge (dans des conditions optimales), ce qui permet, avec la «mise en page» correcte du code, d'améliorer parfois les performances, même dans une implémentation à un seul thread.
Bien que JIT puisse effectuer le déroulement de boucle seul, JIT est prudent dans ce type de décision, en raison de la taille du code généré. Par conséquent, il peut être avantageux de déployer une boucle, en code, manuellement.
Vous pouvez développer la boucle dans le code ci-dessus comme suit:
public unsafe int SumUnrolled(ReadOnlySpan<int> source) { int result = 0; int i = 0; int lastBlockIndex = source.Length - (source.Length % 4); // Pin source so we can elide the bounds checks fixed (int* pSource = source) { while (i < lastBlockIndex) { result += pSource[i + 0]; result += pSource[i + 1]; result += pSource[i + 2]; result += pSource[i + 3]; i += 4; } while (i < source.Length) { result += pSource[i]; i += 1; } } return result; }
Ce code est un peu plus compliqué, mais il fait un meilleur usage des fonctionnalités matérielles.
Pour les très petites boucles, ce code s'exécute un peu plus lentement. Mais cette tendance est déjà en train de changer pour les données d'entrée de huit éléments, après quoi la vitesse d'exécution commence à augmenter (le temps d'exécution du code optimisé, pour 32 mille éléments, est 26% inférieur à celui de la version originale). Il convient de noter qu'une telle optimisation n'augmente pas toujours la productivité. Par exemple, lorsque vous travaillez avec des collections avec des éléments de type float version "déployée" de l'algorithme a presque la même vitesse que celle d'origine. Par conséquent, il est très important d'effectuer un profilage.

Augmentez la productivité grâce à la vectorisation de boucle
Quoi qu'il en soit, mais nous pouvons encore optimiser légèrement ce code. Les instructions SIMD sont une autre option fournie par les processeurs modernes pour améliorer les performances. À l'aide d'une seule instruction, ils vous permettent d'effectuer plusieurs opérations en un seul cycle d'horloge. Cela peut être mieux que le dépliage de boucle directe, car, en fait, la même chose se fait, mais avec une plus petite quantité de code généré.
Pour clarifier, chaque opération d'ajout, dans un cycle déployé, prend 4 octets. Ainsi, nous avons besoin de 16 octets pour 4 opérations d'addition sous forme développée. Dans le même temps, l'instruction d'addition SIMD effectue également 4 opérations d'addition, mais ne prend que 4 octets. Cela signifie que nous avons moins d'instructions pour le CPU. De plus, dans le cas d'une instruction SIMD, le CPU peut faire des hypothèses et effectuer des optimisations, mais cela dépasse le cadre de cet article. Ce qui est encore mieux, c'est que les processeurs modernes peuvent exécuter plus d'une instruction SIMD à la fois, c'est-à-dire que, dans certains cas, vous pouvez appliquer une stratégie mixte, en même temps effectuer un balayage de cycle partiel et une vectorisation.
En général, vous devez commencer par regarder la classe polyvalente Vector<T> pour vos tâches. Comme les nouveaux WF , il intégrera des instructions SIMD, mais en même temps, étant donné la polyvalence de cette classe, il peut réduire le nombre de codage «manuel».
Le code pourrait ressembler à ceci:
public int SumVectorT(ReadOnlySpan<int> source) { int result = 0; Vector<int> vresult = Vector<int>.Zero; int i = 0; int lastBlockIndex = source.Length - (source.Length % Vector<int>.Count); while (i < lastBlockIndex) { vresult += new Vector<int>(source.Slice(i)); i += Vector<int>.Count; } for (int n = 0; n < Vector<int>.Count; n++) { result += vresult[n]; } while (i < source.Length) { result += source[i]; i += 1; } return result; }
Ce code fonctionne plus rapidement, mais nous sommes obligés de faire référence à chaque élément séparément lors du calcul du montant final. En outre, le Vector<T> n'a pas de taille définie avec précision et peut varier en fonction de l'équipement sur lequel le code s'exécute. Les fonctions intégrées spécifiques au matériel fournissent des fonctionnalités supplémentaires qui peuvent légèrement améliorer ce code et le rendre un peu plus rapide (au prix d'une complexité de code supplémentaire et d'exigences de maintenance).

REMARQUE Pour cet article, j'ai forcé la taille Vector<T> égale à 16 octets en utilisant le paramètre de configuration interne ( COMPlus_SIMD16ByteOnly=1 ). Ce réglage a normalisé les résultats lors de la comparaison de SumVectorT avec SumVectorizedSse , et nous a permis de garder le code simple. En particulier, il a évité d'écrire un saut conditionnel if (Avx2.IsSupported) { } . Ce code est presque identique au code pour Sse2 , mais traite avec Vector256<T> (32 octets) et traite encore plus d'éléments en une seule itération de la boucle.
Ainsi, en utilisant les nouvelles fonctions intégrées , le code peut être réécrit comme suit:
public int SumVectorized(ReadOnlySpan<int> source) { if (Sse2.IsSupported) { return SumVectorizedSse2(source); } else { return SumVectorT(source); } } public unsafe int SumVectorizedSse2(ReadOnlySpan<int> source) { int result; fixed (int* pSource = source) { Vector128<int> vresult = Vector128<int>.Zero; int i = 0; int lastBlockIndex = source.Length - (source.Length % 4); while (i < lastBlockIndex) { vresult = Sse2.Add(vresult, Sse2.LoadVector128(pSource + i)); i += 4; } if (Ssse3.IsSupported) { vresult = Ssse3.HorizontalAdd(vresult, vresult); vresult = Ssse3.HorizontalAdd(vresult, vresult); } else { vresult = Sse2.Add(vresult, Sse2.Shuffle(vresult, 0x4E)); vresult = Sse2.Add(vresult, Sse2.Shuffle(vresult, 0xB1)); } result = vresult.ToScalar(); while (i < source.Length) { result += pSource[i]; i += 1; } } return result; }
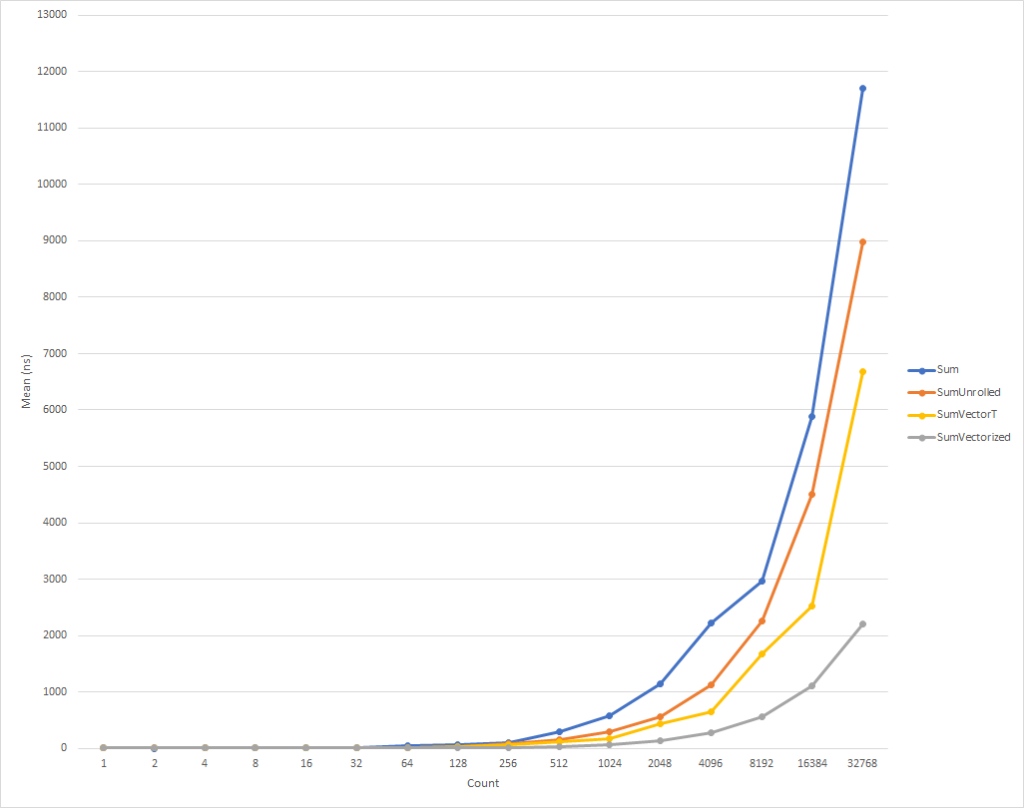
Ce code, encore une fois, est un peu plus compliqué, mais il est beaucoup plus rapide pour tout le monde, sauf les plus petits ensembles d'entrée. Pour 32 000 éléments, ce code s'exécute 75% plus rapidement que le cycle étendu et 81% plus rapidement que le code source de l'exemple.
Vous avez remarqué que nous avons rédigé des chèques IsSupported . Le premier vérifie si le matériel actuel prend en charge l'ensemble requis de fonctions intégrées , sinon, l'optimisation est effectuée par une combinaison de balayage et de Vector<T> . Cette dernière option sera sélectionnée pour les plates-formes comme ARM / ARM64 qui ne prennent pas en charge le jeu d'instructions requis, ou si le jeu a été désactivé pour la plate-forme. Le deuxième test IsSupported , dans la méthode SumVectorizedSse2 , est utilisé pour une optimisation supplémentaire si le matériel prend en charge le Ssse3 instructions Ssse3 .
Sinon, la majeure partie de la logique est essentiellement la même que pour la boucle étendue. Vector128<T> est un type de 128 bits contenant des éléments Vector128<T>.Count . Dans ce cas, uint , qui est lui-même 32 bits, peut avoir 4 éléments (128/32), c'est ainsi que nous avons lancé la boucle.
Conclusion
Les nouvelles fonctions intégrées vous permettent de tirer parti des fonctionnalités spécifiques au matériel de la machine sur laquelle vous exécutez le code. Il existe environ 1 500 API pour X86 et X64 réparties sur 15 ensembles, il y en a trop pour les décrire dans un seul article. En profilant le code pour identifier les goulots d'étranglement, vous pouvez déterminer la partie du code qui bénéficie de la vectorisation et observer une très bonne augmentation des performances. Il existe de nombreux scénarios où la vectorisation peut être appliquée et le déroulement de la boucle n'est que le début.
Quiconque veut voir plus d'exemples peut rechercher l'utilisation de fonctions intégrées dans le cadre (voir dotnet et aspnet ), ou dans d'autres articles de la communauté. Et bien que les WF actuels soient vastes, il reste encore beaucoup de fonctionnalités à introduire. Si vous avez la fonctionnalité que vous souhaitez introduire, n'hésitez pas à enregistrer votre demande d'API via dotnet / corefx sur GitHub . Le processus de révision de l'API est décrit ici et il existe un bon exemple de modèle de demande d'API spécifié à l'étape 1.
Remerciements spéciaux
Je tiens à exprimer une gratitude particulière aux membres de notre communauté Fei Peng (@fiigii) et Jacek Blaszczynski (@ 4creators) pour leur aide dans la mise en œuvre du WF , ainsi qu'à tous les membres de la communauté pour leurs précieux commentaires concernant le développement, la mise en œuvre et la facilité d'utilisation de cette fonctionnalité.
Postface à la traduction
J'aime observer le développement de la plateforme .NET, et en particulier le langage C #. Venant du monde du C ++ et ayant peu d'expérience en développement en Delphi et Java, j'étais très à l'aise pour écrire des programmes en C #. En 2006, ce langage de programmation (le langage lui-même) m'a paru plus concis et pratique que Java dans le monde de la gestion des ordures et du cross-platform. Par conséquent, mon choix s'est porté sur C #, et je ne l'ai pas regretté. La première étape de l'évolution d'une langue a été simplement son apparition. En 2006, C # a absorbé tout le meilleur qui était à l'époque dans les meilleurs langages et plateformes: C ++ / Java / Delphi. En 2010, F # est devenue publique. C'était une plate-forme expérimentale pour étudier le paradigme fonctionnel dans le but de l'introduire dans le monde de .NET. Le résultat des expériences a été la prochaine étape de l'évolution de C # - l'expansion de ses capacités vers le FP, grâce à l'introduction de fonctions anonymes, d'expressions lambda et, finalement, de LINQ. Cette extension du langage a fait de C # le langage le plus avancé, de mon point de vue, à usage général. L'étape évolutive suivante était liée à la prise en charge de la concurrence et de l'asynchronie. Tâche / Tâche <T>, tout le concept de TPL, le développement de LINQ - PLINQ, et, enfin, async / wait. , - , .NET C# — . Span<T> Memory<T>, ValueTask/ValueTask<T>, IAsyncDispose, ref readonly struct in, foreach, IO.Streams. GC . , — . , .NET C#, , . ( ) .