
Reconnaissant l'importance de l'intelligence artificielle, Intel fait un autre pas dans cette direction. Il y a un mois, lors de la conférence Hot Chips 2019, la société a officiellement présenté deux puces spécialisées conçues pour la formation et l'inférence des réseaux de neurones. Les puces ont été nommées Intel Nervana NNP-
T (Processeur de réseau neuronal) et Intel Nervana NNP-
I, respectivement. Sous la coupe, vous trouverez les caractéristiques et les schémas de nouveaux produits.
Intel Nervana NNP-T (Spring Crest)
Le temps de formation du réseau de neurones, ainsi que l'efficacité énergétique, est l'un des paramètres clés du système d'IA, qui détermine la portée de son application. La puissance de calcul utilisée dans les plus grands modèles et ensembles d'entraînement double tous les trois mois. Dans le même temps, un ensemble limité de calculs est utilisé dans les réseaux de neurones, principalement les convolutions et la multiplication matricielle, ce qui ouvre de grandes perspectives d'optimisation. Idéalement, l'appareil dont nous avons besoin doit être équilibré en termes de consommation, de communications, de puissance de calcul et d'évolutivité.
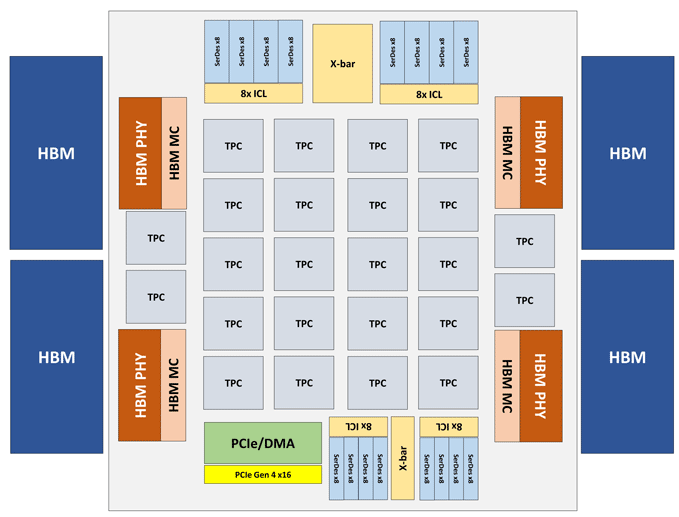
Le module Intel Nervana NNP-T se présente sous la forme d'une carte PCIe 4.0 x16 ou OAM. L'élément de calcul NNP-T principal est le cluster de traitement de tenseur (TPC) de 24 pièces, offrant jusqu'à 119 performances TOPS. Un total de 32 Go de mémoire HBM2-2400 est connecté via 4 ports HBM. A bord il y a aussi une unité de sérialisation / désérialisation sur 64 lignes, interfaces SPI, I2C, GPIO. La quantité de mémoire distribuée sur la puce est de 60 Mo (2,5 Mo par TPC).
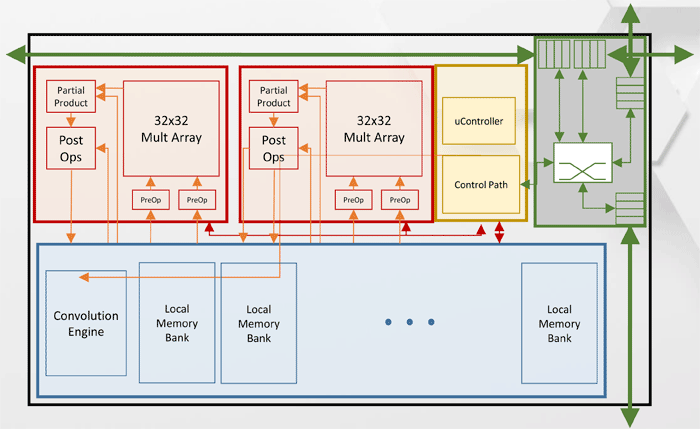 Architecture du cluster de traitement des tenseurs (TPC)
Architecture du cluster de traitement des tenseurs (TPC)Autres spécifications de performances Intel Nervana NNP-T.
Comme vous pouvez le voir sur le diagramme, chaque TPC a deux cœurs de multiplication de matrice 32x32 avec prise en charge de BFloat16. D'autres opérations sont effectuées au format BFloat16 ou FP32. Au total, jusqu'à 8 cartes peuvent être installées sur un hôte, l'évolutivité maximale - jusqu'à 1024 nœuds.
Intel Nervana NNP-I (Spring Hill)
Lors de la conception d'Intel Nervana NNP-I, l'objectif était de fournir une efficacité énergétique maximale avec une inférence à l'échelle des grands centres de données - environ 5 TOP / W.
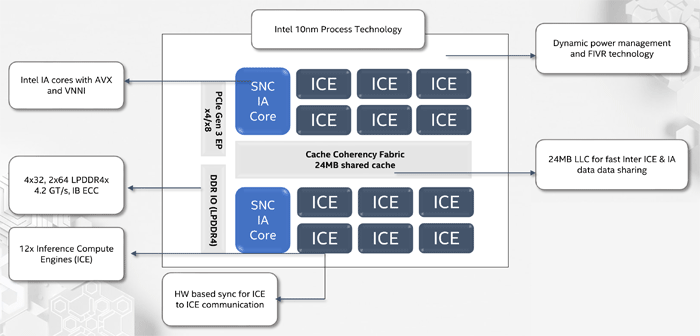
NNP-I est un SoC, fabriqué selon la technologie de processus 10 nm et comprend deux cœurs x86 standard avec prise en charge d'AVX et VNNI, ainsi que 12 cœurs spécialisés ICE (Inference Compute Engine). La performance maximale est de 92 TORS, TDP - 50 watts. La quantité de mémoire interne est de 75 Mo. Structurellement, le dispositif se présente sous la forme d'une carte d'extension M.2.
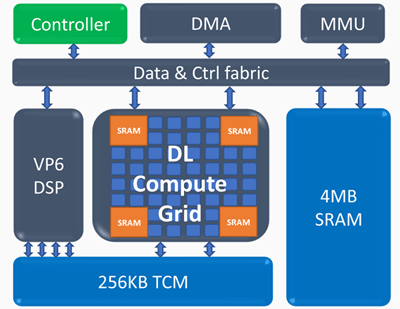 Architecture du moteur de calcul d'inférence (ICE)
Architecture du moteur de calcul d'inférence (ICE)Éléments clés du moteur de calcul d'inférence:
Grille de calcul Deep Learning- 4k MAC (int8) par cycle
- support évolutif pour FP16, INT8, INT 4/2/1
- grande quantité de mémoire interne
- opérations non linéaires et mise en commun
Processeur vectoriel programmable- haute performance - 5 VLIW 512 b
- prise en charge NN étendue - FP16 / 16b / 8b
Les indicateurs de performance d'Intel Nervana NNP-I suivants ont été obtenus: sur un réseau ResNet à 50 couches, une vitesse de 3600 inférences par seconde a été obtenue avec une consommation d'énergie de 10 W, c'est-à-dire que l'efficacité énergétique est de 360 images par seconde en termes de Watt.