L'article précédent a examiné l'architecture d'un réseau virtualisé, la superposition de sous-couches, le chemin du package entre les machines virtuelles et plus encore.
Roman Gorge a été inspiré par elle et a décidé d'écrire un numéro de revue sur la virtualisation en général.
Dans cet article, nous aborderons (ou essayerons de toucher) les questions: comment la virtualisation des fonctions réseau se produit réellement, comment le backend des principaux produits pour le lancement et la gestion des VM est implémenté, et comment fonctionne la commutation virtuelle (pont OVS et Linux).
Le sujet de la virtualisation est large et profond, il est impossible d'expliquer tous les détails du travail de l'hyperviseur (et ce n'est pas nécessaire). Nous nous limiterons à l'ensemble minimal de connaissances nécessaires pour comprendre le fonctionnement de toute solution virtualisée, pas nécessairement Telco.

Table des matières
- Introduction et bref historique de la virtualisation
- Types de ressources virtuelles - calcul, stockage, réseau
- Commutation virtuelle
- Outils de virtualisation - libvirt, virsh et plus
- Conclusion
Introduction et bref historique de la virtualisation
L'histoire des technologies de virtualisation modernes remonte à 1999, lorsque la jeune entreprise VMware a lancé un produit appelé VMware Workstation. Il s'agissait d'un produit de virtualisation pour les applications de bureau / client. La virtualisation côté serveur est venue un peu plus tard sous la forme du produit ESX Server, qui a évolué plus tard vers ESXi (je veux dire intégré) - c'est le même produit qui est utilisé universellement dans les TI et les télécommunications comme hyperviseur d'application de serveur.
Côté opensource, deux projets majeurs ont apporté la virtualisation à Linux:
- KVM (Kernel-based Virtual Machine) est un module de noyau Linux qui permet au noyau de fonctionner comme un hyperviseur (crée l'infrastructure nécessaire pour démarrer et gérer des machines virtuelles). Il a été ajouté dans la version 2.6.20 du noyau en 2007.
- QEMU (Quick Emulator) - émule directement le matériel d'une machine virtuelle (CPU, disque, RAM, tout ce qui inclut un port USB) et est utilisé en conjonction avec KVM pour obtenir des performances presque "natives".
En fait, pour le moment, toutes les fonctionnalités de KVM sont disponibles dans QEMU, mais ce n'est pas important, car la plupart des utilisateurs de virtualisation Linux n'utilisent pas directement KVM / QEMU, mais y accèdent via au moins un niveau d'abstraction, mais plus à ce sujet plus tard.
Aujourd'hui, VMware ESXi et Linux QEMU / KVM sont les deux principaux hyperviseurs qui dominent le marché. Ils sont également des représentants de deux types différents d'hyperviseurs:
- Type 1 - l'hyperviseur fonctionne directement sur le matériel (métal nu). Il s'agit de VMware ESXi, Linux KVM, Hyper-V
- Type 2 - l'hyperviseur est lancé dans le système d'exploitation hôte (système d'exploitation). Il s'agit de VMware Workstation ou d'Oracle VirtualBox.
Une discussion de ce qui est mieux et de ce qui est pire dépasse le cadre de cet article.

Les producteurs de fer devaient également faire leur part pour garantir des performances acceptables.
Peut-être le plus important et le plus largement utilisé est Intel VT (Virtualization Technology) - un ensemble d'extensions développées par Intel pour ses processeurs x86 qui sont utilisées pour le fonctionnement efficace de l'hyperviseur (et dans certains cas sont nécessaires, par exemple, KVM ne fonctionnera pas sans VT activé) -x et sans lui, l'hyperviseur est obligé de s'engager dans une émulation purement logicielle, sans accélération matérielle).
Deux de ces extensions sont les plus connues - VT-x et VT-d. Le premier est important pour améliorer les performances du processeur pendant la virtualisation, car il fournit une prise en charge matérielle de certaines de ses fonctions (avec VT-x 99,9%, le code du SE invité est exécuté directement sur le processeur physique, ne produisant des sorties pour l'émulation que dans les cas les plus nécessaires), le second est destiné à connecter directement des périphériques physiques à une machine virtuelle (pour les fonctions virtuelles avancées (VF) SRIOV, par exemple, VT-d
doit être activé ).
Le prochain concept important est la différence entre la virtualisation complète et la para-virtualisation.
La virtualisation complète est bonne, elle vous permet d'exécuter n'importe quel système d'exploitation sur n'importe quel processeur, cependant, elle est extrêmement inefficace et ne convient absolument pas aux systèmes fortement chargés.
La para-virtualisation, en bref, est lorsque le système d'exploitation invité comprend qu'il s'exécute dans un environnement virtuel et coopère avec l'hyperviseur pour atteindre une plus grande efficacité. Autrement dit, l'interface invité-hyperviseur apparaît.
La grande majorité des systèmes d'exploitation utilisés aujourd'hui prennent en charge la para-virtualisation - dans le noyau Linux, cela est apparu depuis la version 2.6.20 du noyau.
Pour qu'une machine virtuelle fonctionne, non seulement un processeur virtuel (vCPU) et une mémoire virtuelle (RAM) sont nécessaires; l'émulation de périphériques PCI est également requise. En fait, un ensemble de pilotes est requis pour gérer les interfaces réseau virtuelles, les disques, etc.
Dans l'hyperviseur KVM Linux, cette tâche a été résolue en implémentant
virtio , un cadre de développement et d'utilisation de périphériques d'E / S virtualisés.
Virtio est un niveau d'abstraction supplémentaire, qui vous permet d'émuler divers périphériques d'E / S dans un hyperviseur para-virtualisé, fournissant une interface unifiée et standardisée sur le côté de la machine virtuelle. Cela vous permet de réutiliser le code du pilote virtio pour divers périphériques intrinsèquement. Virtio se compose de:
- Pilote frontal - contenu de la machine virtuelle
- Pilote principal - contenu de l'hyperviseur
- Pilote de transport - ce qui relie le backend et le frontend
Cette modularité vous permet de changer les technologies utilisées dans l'hyperviseur sans affecter les pilotes de la machine virtuelle (ce point est très important pour les technologies d'accélération réseau et les solutions Cloud en général, mais plus à ce sujet plus tard).
Autrement dit, il existe une connexion invité-hyperviseur lorsque le système d'exploitation invité "sait" qu'il s'exécute dans un environnement virtuel.
Si vous avez déjà écrit une question dans la DP ou répondu à une question dans la DP «La virtio est-elle prise en charge dans votre produit?» Il s'agissait simplement de prendre en charge le pilote virtio frontal.
Types de ressources virtuelles - calcul, stockage, réseau
En quoi consiste une machine virtuelle?
Il existe trois principaux types de ressources virtuelles:
- calcul - processeur et RAM
- stockage - disque système de la machine virtuelle et stockage par blocs
- réseau - cartes réseau et périphériques d'entrée / sortie
Calculer
CPU
Théoriquement, QEMU est capable d'émuler n'importe quel type de processeur et ses indicateurs et fonctionnalités correspondants; en pratique, ils utilisent soit le modèle hôte et désactivent les indicateurs ponctuellement avant de les transférer vers le système d'exploitation invité, soit ils prennent le modèle nommé et activent / désactivent les indicateurs ponctuellement.
Par défaut, QEMU émulera un processeur que le SE invité reconnaîtra comme CPU virtuel QEMU. Ce n'est pas le type de processeur le plus optimal, surtout si une application s'exécutant sur une machine virtuelle utilise des drapeaux CPU pour son travail.
En savoir plus sur les différents modèles de CPU dans QEMU .
QEMU / KVM vous permet également de contrôler la topologie du processeur, le nombre de threads, la taille du cache, de lier vCPU au cœur physique et bien plus encore.
La nécessité ou non d'une machine virtuelle dépend du type d'application exécutée sur le système d'exploitation invité. Par exemple, il est bien connu que pour les applications qui traitent des paquets avec un PPS élevé, il est important de procéder à
l'épinglage du processeur , c'est-à-dire de ne pas permettre le transfert du processeur physique vers d'autres machines virtuelles.
La mémoire
La prochaine ligne est la RAM. Du point de vue de Host OS, une machine virtuelle lancée à l'aide de QEMU / KVM n'est pas différente de tout autre processus exécuté dans l'espace utilisateur du système d'exploitation. En conséquence, le processus d'allocation de mémoire à une machine virtuelle est effectué par les mêmes appels dans le noyau Host OS, comme si vous aviez lancé, par exemple, un navigateur Chrome.
Avant de poursuivre l'histoire de la RAM dans les machines virtuelles, vous devez vous éloigner et expliquer le terme NUMA - Non-Uniform Memory Access.
L'architecture des serveurs physiques modernes implique la présence de deux ou plusieurs processeurs (CPU) et associés à une mémoire vive (RAM). Un tel tas de processeur + mémoire est appelé un nœud ou un nœud. La communication entre les différents nœuds NUMA s'effectue via un bus spécial - QPI (QuickPath Interconnect)
Le nœud NUMA local est alloué - lorsque le processus en cours d'exécution dans le système d'exploitation utilise le processeur et la RAM situés dans le même nœud NUMA, et le nœud NUMA distant - lorsque le processus en cours d'exécution dans le système d'exploitation utilise le processeur et la RAM situés dans différents nœuds NUMA, c'est-à-dire que pour l'interaction du processeur et de la mémoire, un transfert de données via le bus QPI est requis.
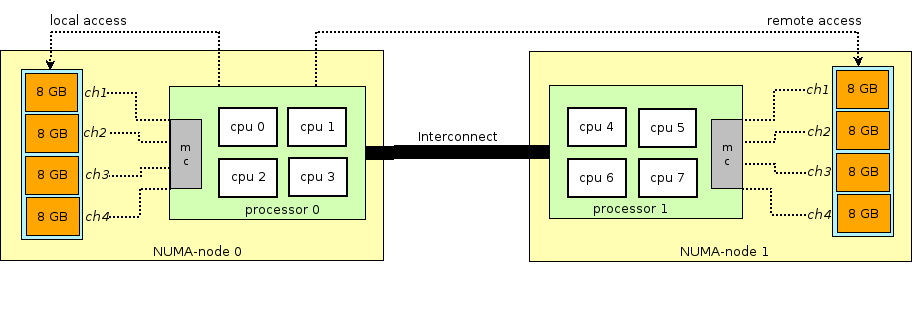
Du point de vue de la machine virtuelle, la mémoire lui était déjà allouée au moment de son lancement, mais en réalité ce n'est pas le cas, et le noyau Host OS alloue de nouvelles sections de mémoire au processus QEMU / KVM car l'application dans Guest OS demande de la mémoire supplémentaire (bien qu'il puisse également y avoir une exception si vous spécifiez directement QEMU / KVM pour allouer toute la mémoire à la machine virtuelle directement au démarrage).
La mémoire est allouée non octet par octet, mais par une certaine taille -
page . La taille de la page est configurable et peut théoriquement être n'importe laquelle, mais en pratique, la taille est de 4 Ko (par défaut), 2 Mo et 1 Go. Les deux dernières tailles sont appelées
HugePages et sont souvent utilisées pour allouer de la mémoire aux machines virtuelles gourmandes en mémoire. La raison d'utiliser HugePages dans le processus de recherche d'une correspondance entre l'adresse virtuelle de la page et la mémoire physique dans
Translation Lookaside Buffer (
TLB ), qui à son tour est limité et stocke des informations uniquement sur les dernières pages utilisées. S'il n'y a aucune information sur la page souhaitée dans le TLB, un processus appelé
miss TLB se produit et vous devez utiliser le processeur Host OS pour trouver la cellule de mémoire physique correspondant à la page souhaitée.
Ce processus est inefficace et lent, donc moins de pages de plus grande taille sont utilisées.
QEMU / KVM vous permet également d'émuler diverses topologies NUMA pour le système d'exploitation invité, de prendre de la mémoire pour une machine virtuelle uniquement à partir d'un système d'exploitation hôte de nœud NUMA spécifique, etc. La pratique la plus courante consiste à extraire la mémoire d'une machine virtuelle d'un nœud NUMA local vers les processeurs alloués à la machine virtuelle. La raison en est le désir d'éviter une charge inutile sur le bus
QPI reliant les sockets CPU du serveur physique (bien sûr, cela est logique si votre serveur a 2 sockets ou plus).
Stockage
Comme vous le savez, la RAM est appelée mémoire opérationnelle car son contenu disparaît lorsque l'alimentation est coupée ou que le système d'exploitation est redémarré. Pour stocker des informations, vous avez besoin d'un périphérique de stockage persistant (ROM) ou d'
un stockage persistant .
Il existe deux principaux types de stockage persistant:
- Stockage de blocs - un bloc d'espace disque qui peut être utilisé pour installer le système de fichiers et créer des partitions. Si c'est grossier, vous pouvez le prendre comme un disque normal.
- Stockage d'objets - les informations ne peuvent être enregistrées qu'en tant qu'objet (fichier), accessible via HTTP / HTTPS. Des exemples typiques de stockage d'objets sont AWS S3 ou Dropbox.
La machine virtuelle a besoin d'
un stockage persistant , cependant, comment faire si la machine virtuelle "vit" dans la RAM du système d'exploitation hôte? En bref, tout appel du système d'exploitation invité au contrôleur de disque virtuel est intercepté par QEMU / KVM et transformé en un enregistrement sur le disque physique du système d'exploitation hôte. Cette méthode est inefficace et, par conséquent, ici comme pour les périphériques réseau, le pilote virtio est utilisé au lieu d'émuler complètement un périphérique IDE ou iSCSI. En savoir plus à ce sujet
ici . Ainsi, la machine virtuelle accède à son disque virtuel via un pilote virtio, puis QEMU / KVM effectue les informations transférées écrites sur le disque physique. Il est important de comprendre que dans Host OS, un backend de disque peut être implémenté en tant que plateau CEPH, NFS ou iSCSI.
La façon la plus simple d'émuler un stockage persistant est d'utiliser le fichier dans un répertoire du système d'exploitation hôte comme espace disque d'une machine virtuelle. QEMU / KVM prend en charge de nombreux formats différents de ce type de fichier - raw, vdi, vmdk et autres. Cependant, le format le plus utilisé est
qcow2 (QEMU copy-on-write version 2). En général, qcow2 est un fichier structuré d'une certaine manière sans aucun système d'exploitation. Un grand nombre de machines virtuelles sont distribuées sous forme d'images qcow2 (images) et sont une copie du disque système d'une machine virtuelle, compressée au format qcow2. Cela présente plusieurs avantages - le codage qcow2 prend beaucoup moins d'espace qu'une copie brute d'un disque d'octet à octet, QEMU / KVM peut redimensionner un fichier qcow2, ce qui signifie qu'il est possible de modifier la taille du disque d'une machine virtuelle, le cryptage AES qcow2 est également pris en charge (cela a du sens, car l'image d'une machine virtuelle peut contenir une propriété intellectuelle).
De plus, lorsque la machine virtuelle démarre, QEMU / KVM utilise le fichier qcow2 comme disque système (j'omet le processus de chargement de la machine virtuelle ici, bien que ce soit également une tâche intéressante), et la machine virtuelle a la capacité de lire / écrire des données dans le fichier qcow2 via virtio chauffeur. Ainsi, le processus de prise d'images de machines virtuelles fonctionne, car à tout moment le fichier qcow2 contient une copie complète du disque système de la machine virtuelle, et l'image peut être utilisée pour la sauvegarde, le transfert vers un autre hôte, etc.
En général, ce fichier qcow2 sera défini dans l'OS invité en tant que
périphérique / dev / vda , et l'OS invité partitionnera l'espace disque en partitions et installera le système de fichiers. De même, les fichiers qcow2 suivants connectés par QEMU / KVM en tant que périphériques
/ dev / vdX peuvent être utilisés comme
stockage de bloc dans une machine virtuelle pour stocker des informations (c'est exactement comment fonctionne le composant Openstack Cinder).
Réseau
Les dernières cartes virtuelles et périphériques d'E / S figurent en dernier sur notre liste de ressources virtuelles. Une machine virtuelle, comme un hôte physique, a besoin d'un
bus PCI / PCIe pour connecter des périphériques d'E / S. QEMU / KVM est capable d'émuler différents types de chipsets - q35 ou i440fx (le premier prend en charge PCIe, le second prend en charge le PCI hérité), ainsi que diverses topologies PCI, par exemple, créent des bus PCI séparés (bus d'extension PCI) pour les nœuds NUMA OS invités.
Après avoir créé le bus PCI / PCIe, vous devez y connecter un périphérique d'E / S. En général, il peut s'agir d'une carte réseau ou d'un GPU physique. Et, bien sûr, une carte réseau, à la fois entièrement virtualisée (interface e1000 entièrement virtualisée, par exemple), et para-virtualisée (virtio, par exemple) ou une carte réseau physique. La dernière option est utilisée pour les machines virtuelles du plan de données où vous devez obtenir des taux de paquets au débit de ligne - routeurs, pare-feu, etc.
Il existe deux approches principales ici -
passthrough PCI et
SR-IOV . La principale différence entre eux est que pour PCI-PT, le pilote est utilisé uniquement à l'intérieur de l'OS invité, et pour SRIOV, le pilote de l'OS hôte (pour créer
VF - Fonctions virtuelles ) et le pilote de l'OS invité sont utilisés pour contrôler SR-IOV VF.
Juniper a écrit d' excellents détails sur PCI-PT et SRIOV.

Pour plus de précision, il convient de noter que le passthrough PCI et SR-IOV sont des technologies complémentaires. SR-IOV découpe une fonction physique en fonctions virtuelles. Cela se fait au niveau du système d'exploitation hôte. Dans le même temps, Host OS voit les fonctions virtuelles comme un autre périphérique PCI / PCIe. Ce qu'il fait ensuite avec eux n'est pas important.
Et PCI-PT est un mécanisme de transfert de tout périphérique PCI OS hôte dans le système d'exploitation invité, y compris la fonction virtuelle créée par le périphérique SR-IOV
Ainsi, nous avons examiné les principaux types de ressources virtuelles et la prochaine étape consiste à comprendre comment la machine virtuelle communique avec le monde extérieur via un réseau.
Commutation virtuelle
S'il y a une machine virtuelle, et qu'il y a une interface virtuelle dedans, alors, évidemment, le problème se pose de transférer un paquet d'une VM à une autre. Dans les hyperviseurs basés sur Linux (KVM, par exemple), ce problème peut être résolu en utilisant le pont Linux, cependant, le projet
Open vSwitch (OVS) a été largement accepté.
Plusieurs fonctionnalités de base ont permis à OVS de se répandre largement et de devenir de facto la méthode de commutation de paquets de base utilisée par de nombreuses plates-formes de cloud computing (telles que Openstack) et des solutions virtualisées.
- Transfert d'état du réseau - lors de la migration d'une machine virtuelle entre hyperviseurs, la tâche se pose de transférer les listes de contrôle d'accès, les QoS, les tables de transfert L2 / L3, etc. Et OVS peut le faire.
- Implémentation du mécanisme de transfert de paquets (datapath) à la fois dans le noyau et dans l'espace utilisateur
- Architecture CUPS (Control / User-plane separation) - vous permet de transférer les fonctionnalités du traitement des paquets vers un chipset spécialisé (les chipsets Broadcom et Marvell, par exemple, peuvent le faire), en le contrôlant via l'OVS du plan de contrôle.
- Prise en charge des méthodes de contrôle du trafic à distance - protocole OpenFlow (hi, SDN).
L'architecture OVS à première vue semble assez effrayante, mais ce n'est qu'à première vue.
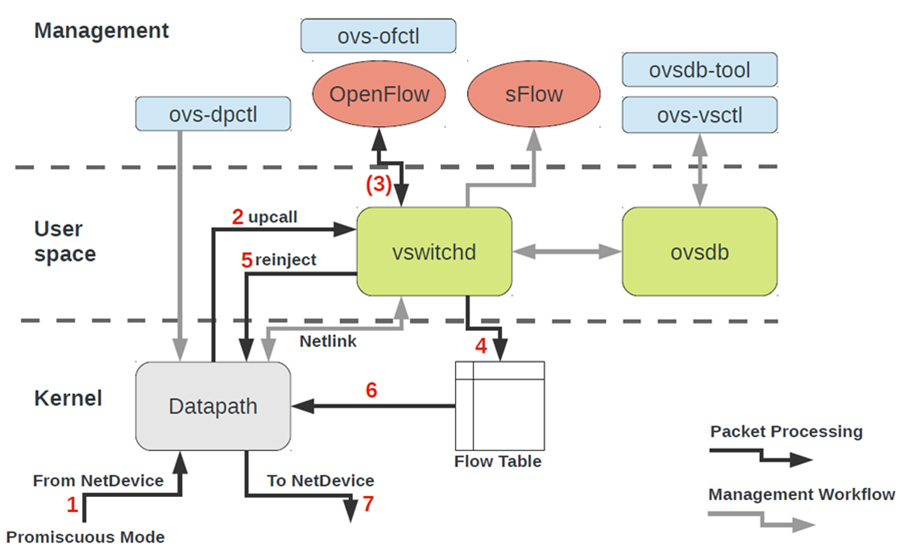
Pour travailler avec OVS, vous devez comprendre les éléments suivants:
- Chemin de données - les packages sont traités ici. L'analogie est la structure de commutation d'un interrupteur en fer. Datapath comprend la réception de paquets, le traitement des en-têtes, les correspondances dans la table de flux, qui est déjà programmée dans Datapath. Si OVS s'exécute dans le noyau, il est implémenté en tant que module du noyau. Si OVS s'exécute dans l'espace utilisateur, il s'agit d'un processus dans Linux espace utilisateur.
- vswitchd et ovsdb sont des démons dans l'espace utilisateur, qui implémentent directement la fonctionnalité du commutateur, stockent la configuration, définissent le flux vers le chemin de données et le programment.
- Boîte à outils de configuration et de dépannage OVS - ovs-vsctl, ovs-dpctl, ovs-ofctl, ovs-appctl . Tout ce qui est nécessaire pour enregistrer la configuration des ports dans ovsdb, enregistrer le flux vers lequel basculer, collecter des statistiques, etc. Les bonnes personnes ont écrit un article à ce sujet.
Comment le périphérique réseau d'une machine virtuelle se retrouve-t-il dans OVS?Pour résoudre ce problème, nous devons en quelque sorte interconnecter l'interface virtuelle située dans l'espace utilisateur du système d'exploitation avec le chemin de données OVS situé dans le noyau.
Dans le système d'exploitation Linux, les paquets sont transférés entre le noyau et les processus de l'espace utilisateur via deux interfaces spéciales.
Les deux interfaces sont utilisées pour écrire / lire un paquet vers / depuis un fichier spécial pour transférer des paquets du processus de l'espace utilisateur vers le noyau et vice versa - descripteur de fichier (FD) (c'est l'une des raisons des mauvaises performances de commutation virtuelle si le chemin de données OVS est dans le noyau - chaque paquet besoin d'écrire / lire FD)- TUN (tunnel) - un appareil qui fonctionne en mode L3 et vous permet d'écrire / lire uniquement des paquets IP vers / depuis FD.
- TAP (tap réseau) - identique à l'interface tun + peut effectuer des opérations avec des trames Ethernet, c.-à-d. travailler en mode L2.
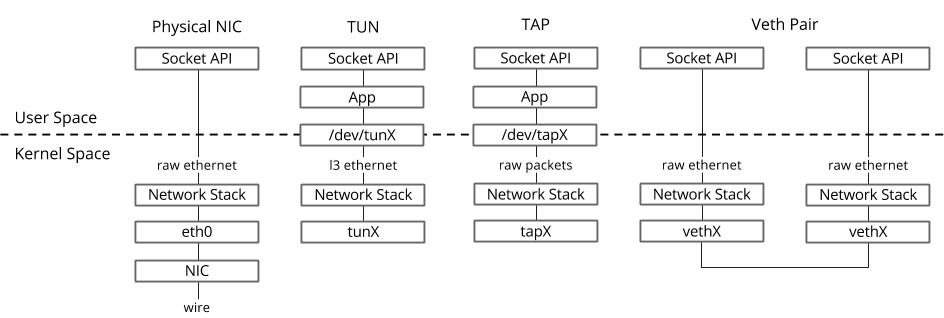 C'est pourquoi lorsque la machine virtuelle s'exécute dans Host OS, vous pouvez voir les interfaces TAP créées avec le lien ip ou la commande ifconfig - c'est la partie «réponse» de virtio, qui est «visible» dans le noyau Host OS. Il convient également de noter que l'interface TAP a la même adresse MAC que l'interface virtio dans la machine virtuelle.L'interface TAP peut être ajoutée à OVS à l'aide des commandes ovs-vsctl - puis tout package commuté par OVS vers l'interface TAP sera transféré vers la machine virtuelle via un descripteur de fichier.
C'est pourquoi lorsque la machine virtuelle s'exécute dans Host OS, vous pouvez voir les interfaces TAP créées avec le lien ip ou la commande ifconfig - c'est la partie «réponse» de virtio, qui est «visible» dans le noyau Host OS. Il convient également de noter que l'interface TAP a la même adresse MAC que l'interface virtio dans la machine virtuelle.L'interface TAP peut être ajoutée à OVS à l'aide des commandes ovs-vsctl - puis tout package commuté par OVS vers l'interface TAP sera transféré vers la machine virtuelle via un descripteur de fichier.La procédure réelle de création d'une machine virtuelle peut être différente, c'est-à-dire Tout d'abord, vous pouvez créer un pont OVS, puis dire à la machine virtuelle de créer une interface connectée à cet OVS, ou vice versa.
Maintenant, si nous devons être en mesure de transférer des paquets entre deux ou plusieurs machines virtuelles qui s'exécutent sur le même hyperviseur, il nous suffit de créer un pont OVS et d'y ajouter des interfaces TAP à l'aide des commandes ovs-vsctl. Quelles équipes sont nécessaires pour cela sont facilement googlé.Il peut y avoir plusieurs ponts OVS sur l'hyperviseur, par exemple, c'est ainsi que Openstack Neutron fonctionne, ou les machines virtuelles peuvent se trouver dans des espaces de noms différents pour implémenter l'hébergement multiple.Et si les machines virtuelles sont dans des ponts OVS différents?Pour résoudre ce problème, il existe un autre outil - paire veth. La paire Veth peut être représentée comme une paire d'interfaces réseau connectées par un câble - tout ce qui «vole» dans une interface, «vole» d'une autre. La paire Veth est utilisée pour connecter plusieurs ponts OVS ou ponts Linux entre eux. Un autre point important est que des parties de la paire veth peuvent se trouver dans un système d'exploitation Linux d'espace de noms différent, c'est-à-dire que la paire veth peut également être utilisée pour communiquer l'espace de noms entre elles au niveau du réseau.Outils de virtualisation - libvirt, virsh et plus
Dans les chapitres précédents, nous avons examiné les fondements théoriques de la virtualisation, dans ce chapitre, nous parlerons des outils disponibles pour l'utilisateur directement pour démarrer et modifier des machines virtuelles sur l'hyperviseur KVM.Arrêtons-nous sur trois composants principaux qui couvrent 90% de toutes sortes d'opérations avec des machines virtuelles:- libvirt
- virsh CLI
- virt-install
, CLI-, , , qemu_system_x86_64 virt manager, . Cloud-, Openstack, , libvirt.
libvirt
libvirt est un projet open source à grande échelle qui développe un ensemble d'outils et de pilotes pour la gestion des hyperviseurs. Il prend en charge non seulement QEMU / KVM, mais également ESXi, LXC et bien plus encore.La principale raison de sa popularité est une interface structurée et intuitive pour interagir via un ensemble de fichiers XML, ainsi que la possibilité d'automatiser via une API. Il convient de noter que libvirt ne décrit pas toutes les fonctions possibles de l'hyperviseur, il ne fournit qu'une interface pratique pour utiliser les fonctions d'hyperviseur qui sont utiles , du point de vue des participants au projet.Et oui, libvirt est le standard de facto dans le monde de la virtualisation aujourd'hui. Jetez un œil à la liste des applications qui utilisent libvirt. La bonne nouvelle à propos de libvirt est que tous les packages nécessaires sont déjà préinstallés dans tous les OS hôtes les plus fréquemment utilisés - Ubuntu, CentOS et RHEL, donc vous n'aurez probablement pas à compiler les packages nécessaires et compiler libvirt. Dans le pire des cas, vous devrez utiliser le programme d'installation par lots approprié (apt, yum et similaires).Lors de l'installation et du démarrage initiaux, libvirt crée par défaut le pont Linux virbr0 et sa configuration minimale.
La bonne nouvelle à propos de libvirt est que tous les packages nécessaires sont déjà préinstallés dans tous les OS hôtes les plus fréquemment utilisés - Ubuntu, CentOS et RHEL, donc vous n'aurez probablement pas à compiler les packages nécessaires et compiler libvirt. Dans le pire des cas, vous devrez utiliser le programme d'installation par lots approprié (apt, yum et similaires).Lors de l'installation et du démarrage initiaux, libvirt crée par défaut le pont Linux virbr0 et sa configuration minimale.C'est pourquoi lors de l'installation d'Ubuntu Server, par exemple, vous verrez dans la sortie de la commande ifconfig Linux bridge virbr0 - c'est le résultat de l'exécution du démon libvirtd
Ce pont Linux ne sera connecté à aucune interface physique, mais il peut être utilisé pour communiquer des machines virtuelles au sein d'un seul hyperviseur. Libvirt peut certainement être utilisé avec OVS, cependant, pour cela, l'utilisateur doit créer indépendamment des ponts OVS en utilisant les commandes OVS appropriées.Toute ressource virtuelle nécessaire pour créer une machine virtuelle (calcul, réseau, stockage) est représentée comme un objet dans libvirt. Un ensemble de différents fichiers XML est responsable du processus de description et de création de ces objets.Il n'est pas très logique de décrire en détail le processus de création de réseaux virtuels et de stockages virtuels, car cette application est bien décrite dans la documentation de libvirt:La machine virtuelle elle-même avec tous les périphériques PCI connectés est appelée domaine dans la terminologie libvirt. Il s'agit également d' un objet à l'intérieur de libvirt , qui est décrit par un fichier XML distinct.Ce fichier XML est, à proprement parler, une machine virtuelle avec toutes les ressources virtuelles - RAM, processeur, périphériques réseau, disques, etc. Souvent, ce fichier XML est appelé libvirt XML ou dump XML.Il est peu probable qu'il y ait une personne qui comprenne tous les paramètres de libvirt XML, cependant, cela n'est pas requis en cas de documentation.En général, libvirt XML pour Ubuntu Desktop Guest OS sera assez simple - 40-50 lignes. Étant donné que toute optimisation des performances est également décrite dans libvirt XML (topologie NUMA, topologies CPU, épinglage CPU, etc.), pour les fonctions réseau, libvirt XML peut être très complexe et contenir plusieurs centaines de lignes. Tout fabricant de périphériques réseau qui expédie leurs logiciels sous forme de machines virtuelles a recommandé des exemples de libvirt XML.virsh CLI
L'utilitaire virsh est une ligne de commande «native» pour gérer libvirt. Son objectif principal est de gérer les objets libvirt décrits comme des fichiers XML. Les exemples typiques sont démarrer, arrêter, définir, détruire, etc. Autrement dit, le cycle de vie des objets - la gestion du cycle de vie.Une description de toutes les commandes et drapeaux virsh est également disponible dans la documentation de libvirt .virt-install
Un autre utilitaire utilisé pour interagir avec libvirt. L'un des principaux avantages est que vous n'avez pas à gérer le format XML, mais que vous vous en sortez avec les indicateurs disponibles dans virsh-install. Le deuxième point important est la mer d'exemples et d'informations sur le Web.Ainsi, quel que soit l'utilitaire que vous utilisez, ce sera finalement libvirt qui contrôlera l'hyperviseur, il est donc important de comprendre l'architecture et les principes de son fonctionnement.
Conclusion
Dans cet article, nous avons examiné l'ensemble minimal de connaissances théoriques nécessaires pour travailler avec des machines virtuelles. Je n'ai pas intentionnellement donné d'exemples et de conclusions pratiques des commandes, car de tels exemples peuvent être trouvés autant que vous le souhaitez sur le Web, et je ne me suis pas fixé pour tâche d'écrire un «guide étape par étape». Si vous êtes intéressé par un sujet ou une technologie spécifique, laissez vos commentaires et écrivez des questions.
Liens utiles
Merci
- Alexander Shalimov , mon collègue et expert dans le développement de réseaux virtuels. Pour commentaires et modifications.
- Yevgeny Yakovlev, mon collègue et expert dans le domaine de la virtualisation, pour commentaires et corrections.