
Les problèmes dans l'environnement de travail sont toujours une catastrophe. Cela arrive quand vous rentrez chez vous, et la raison semble toujours stupide. Récemment, nous avons manqué de mémoire sur les nœuds du cluster Kubernetes, bien que le nœud se soit immédiatement rétabli, sans interruption visible. Aujourd'hui, nous parlerons de cette affaire, des dommages que nous avons subis et de la manière dont nous avons l'intention d'éviter un problème similaire à l'avenir.
Premier cas
Samedi 15 juin 2019 17 h 12
Blue Matador (oui, nous nous surveillons!) Génère une alerte: un événement sur l'un des noeuds du cluster de production de Kubernetes - SystemOOM.
17:16
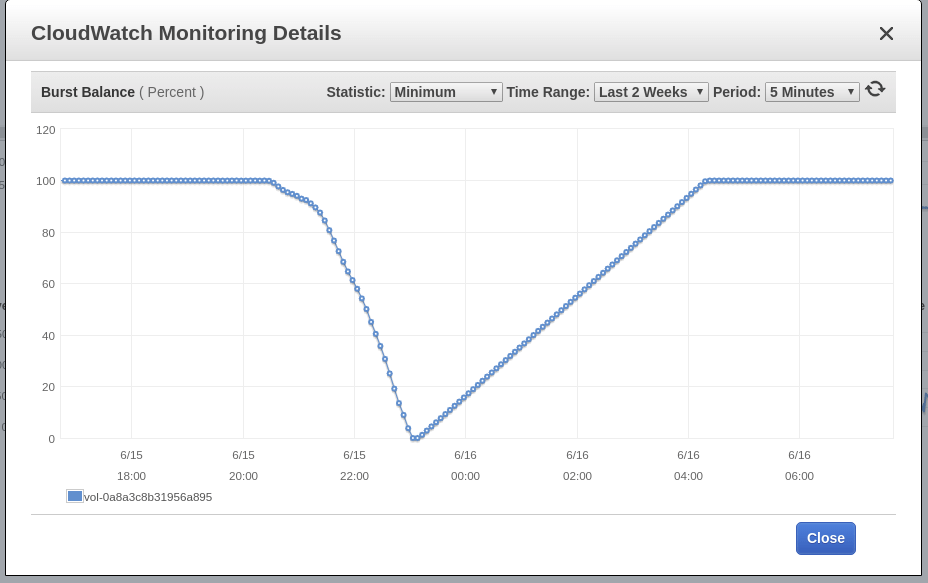
Blue Matador génère un avertissement: EBS Burst Balance est faible sur le volume racine du nœud - celui où l'événement SystemOOM a eu lieu. Bien qu'un avertissement concernant le Burst Balance soit venu après une notification concernant SystemOOM, les données CloudWatch réelles montrent que le Burst Balance a atteint un niveau minimum à 17:02. La raison de ce retard est que les métriques EBS sont constamment en retard de 10 à 15 minutes, et notre système ne capture pas tous les événements en temps réel.
17:18
En ce moment, j'ai vu une alerte et un avertissement. Je lance rapidement kubectl get pods pour voir les dommages que nous avons subis, et je suis surpris de constater que les pods dans l'application sont morts exactement à 0. J'exécute kubectl top nodes , mais cette vérification montre également que le nœud suspect a un problème de mémoire; Certes, il a déjà récupéré et utilise environ 60% de sa mémoire. Il est 17 heures et la bière artisanale se réchauffe déjà. Après m'être assuré que le nœud était opérationnel et qu'aucun pod n'était endommagé, j'ai décidé qu'un accident s'était produit. Si quoi que ce soit, je le découvrirai lundi.
Voici notre correspondance avec la station-service de Slack ce soir-là:

Deuxième cas
Samedi 16 juin 2019 18h02
Blue Matador génère une alerte: l'événement est déjà sur un autre noeud, également SystemOOM. Il devait être que la station-service à ce moment-là ne faisait que regarder l'écran du smartphone, car elle m'écrivait et me faisait immédiatement reprendre l'événement, je ne peux pas moi-même allumer l'ordinateur (est-il temps de réinstaller Windows?). Et encore une fois, tout semble normal. Pas un seul pod n'est tué, et le nœud consomme à peine 70% de la mémoire.
18:06
Blue Matador génère à nouveau un avertissement: EBS Burst Balance. La deuxième fois en une journée, ce qui signifie que je ne peux pas libérer ce problème sur les freins. Avec CloudWatch inchangé, Burst Balance a dévié de la norme 2 heures ou plus avant que le problème ne soit identifié.
18:11
Je vais à Datalog et regarde les données sur la consommation de mémoire. Je vois que juste avant l'événement SystemOOM, le nœud suspect prend vraiment beaucoup de mémoire. Le sentier mène à nos pods fluentd-sumologic.

Vous pouvez clairement voir une forte déviation de la consommation de mémoire, à peu près au même moment que les événements SystemOOM se sont produits. Ma conclusion: ce sont ces pods qui ont pris toute la mémoire, et quand SystemOOM s'est produit, Kubernetes s'est rendu compte que ces pods pouvaient être tués et redémarrés pour retourner la mémoire nécessaire sans affecter mes autres pods. Bien joué, Kubernetes!
Alors, pourquoi n'ai-je pas vu cela samedi lorsque j'ai compris quels modules ont redémarré? Le fait est que j'exécute des pods fluentd-sumologic dans un espace de noms séparé et pressé je n'ai tout simplement pas pensé à y jeter un œil.
Conclusion 1: Lorsque vous recherchez des pods redémarrés, vérifiez tous les espaces de noms.
Ayant reçu ces données, j'ai calculé que le lendemain, la mémoire sur les autres nœuds ne se terminerait pas, cependant, j'ai continué et redémarré tous les pods sumologic afin qu'ils commencent à travailler avec une faible consommation de mémoire. Le lendemain matin, je prévois de concocter comment intégrer le travail sur le problème dans un plan pour la semaine et de ne pas trop charger le dimanche soir.
23h00
J'ai regardé la prochaine série de "Black Mirror" (soit dit en passant, j'ai aimé Miley) et j'ai décidé de regarder comment allait le cluster. La consommation de mémoire est normale, alors n'hésitez pas à tout laisser comme pour la nuit.
Fix
Lundi, j'ai pris du temps pour ce problème. Ça ne fait pas de mal de chasser avec elle tous les soirs. Ce que je sais en ce moment:
- Les conteneurs Fluentd-sumologic engloutissaient une tonne de mémoire;
- L'événement SystemOOM est précédé d'une activité élevée du disque, mais je ne sais pas lequel.
Au début, je pensais que les conteneurs fluentd-sumologic sont acceptés pour manger de la mémoire lors d'un afflux soudain de journaux. Cependant, après avoir vérifié Sumologic, j'ai vu que les journaux étaient utilisés de manière stable, et en même temps qu'il y avait des problèmes, il n'y avait pas d'augmentation de ces journaux.
Un peu sur Google, j'ai trouvé cette tâche sur github , ce qui suggère d'ajuster certains paramètres Ruby - pour réduire la consommation de mémoire. J'ai décidé de l'essayer, d'ajouter une variable d'environnement à la spécification du pod et de l'exécuter:
env: - name: RUBY_GC_HEAP_OLDOBJECT_LIMIT_FACTOR value: "0.9"
En parcourant le manifeste fluentd-sumologic, j'ai remarqué que je n'avais pas défini de demandes de ressources et de restrictions. Je commence à soupçonner que le correctif RUBY_GCP_HEAP fera une sorte de miracle, alors maintenant il est logique de définir des limites de consommation de mémoire. Même si je ne règle pas le problème de mémoire, il sera au moins possible de limiter sa consommation à cet ensemble de pods. Utilisation des pods supérieurs de kubectl | grep fluentd-sumologic , je sais déjà combien de ressources demander:
resources: requests: memory: "128Mi" cpu: "100m" limits: memory: "1024Mi" cpu: "250m"
Conclusion 2: définir des limites de ressources, en particulier pour les applications tierces.
Vérification d'exécution
Après quelques jours, je confirme que la méthode ci-dessus fonctionne. La consommation de mémoire était stable et - aucun problème avec aucun composant de Kubernetes, EC2 et EBS. Maintenant, il est clair à quel point il est important de déterminer les demandes de ressources et les restrictions pour tous les pods que j'exécute, et voici ce qui doit être fait: appliquer une combinaison de limites de ressources par défaut et de quotas de ressources .
Le dernier mystère non résolu est EBS Burst Balance, qui a coïncidé avec l'événement SystemOOM. Je sais que lorsqu'il y a peu de mémoire, le système d'exploitation utilise l'espace de swap pour ne pas être laissé complètement sans mémoire. Mais je ne suis pas né hier et je suis conscient que Kubernetes ne démarrera même pas sur les serveurs où le fichier d'échange est activé. Je voulais juste m'assurer, j'ai grimpé dans mes nœuds via SSH - pour vérifier si le fichier d'échange a été activé; J'ai utilisé à la fois de la mémoire libre et celle de la zone de swap. Le fichier n'a pas été activé.
Et puisque l'échange n'est pas au travail, j'ai plus d'indices sur ce qui a provoqué la croissance des flux d'E / S, c'est pourquoi le nœud a failli manquer de mémoire, non. En général, j'ai une intuition: le pod fluentd-sumologic lui-même écrivait une tonne de messages de journal à ce moment-là, peut-être même un message de journal lié à la configuration de Ruby GC. Il est également possible qu'il existe d'autres sources de messages Kubernetes ou journald qui deviennent excessivement productifs lorsque la mémoire est épuisée, et je les ai éliminés lors de la configuration de fluentd. Malheureusement, je n'ai plus accès aux fichiers journaux enregistrés immédiatement avant le dysfonctionnement, et maintenant je ne peux plus creuser.
Conclusion 3: Bien qu'il y ait une opportunité, approfondissez votre analyse des causes profondes, quel que soit le problème.
Conclusion
Et bien que je ne sois pas allé à la racine des causes, je suis sûr qu'elles ne sont pas nécessaires pour éviter les mêmes dysfonctionnements à l'avenir. Le temps, c'est de l'argent, mais je suis occupé depuis trop longtemps, et après cela, j'ai également écrit ce post pour vous. Et puisque nous utilisons Blue Matador , de tels dysfonctionnements sont traités en détail, donc je me permets de libérer quelque chose sur les freins, sans être distrait du projet principal.