Habr, bonjour.
Cet article est un bref aperçu des algorithmes généraux d'apprentissage automatique. Chacun est accompagné d'une brève description, de guides et de liens utiles.
Méthode des composants principaux (PCA) / SVD
Il s'agit de l'un des algorithmes d'apprentissage machine de base. Vous permet de réduire la dimensionnalité des données, en perdant le moins d'informations. Il est utilisé dans de nombreux domaines, tels que la reconnaissance d'objets, la vision par ordinateur, la compression de données, etc. Le calcul des principaux composants se réduit au calcul des vecteurs propres et des valeurs propres de la matrice de covariance des données sources ou à la décomposition singulière de la matrice de données.
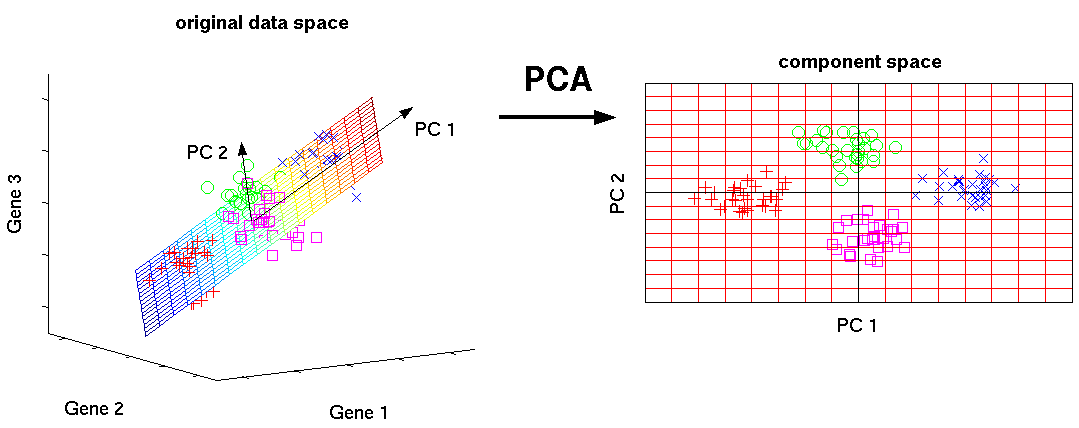
SVD est un moyen de calculer les composants ordonnés.
Liens utiles:
Guide d'introduction:
Méthode des moindres carrés
La méthode des moindres carrés est une méthode mathématique utilisée pour résoudre divers problèmes, basée sur la minimisation de la somme des carrés des écarts de certaines fonctions par rapport aux variables souhaitées. Il peut être utilisé pour «résoudre» des systèmes d'équations surdéterminés (lorsque le nombre d'équations dépasse le nombre d'inconnues), pour trouver une solution dans le cas de systèmes d'équations non linéaires ordinaires (non redéfinis), et aussi pour approximer les valeurs ponctuelles d'une fonction.
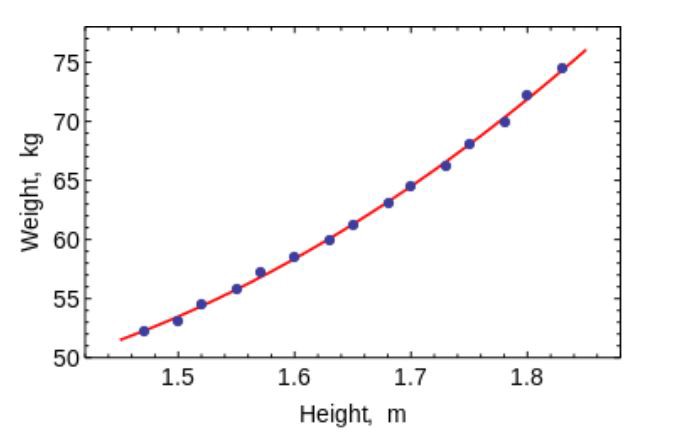
Utilisez cet algorithme pour ajuster des courbes / régressions simples.
Liens utiles:
Guide d'introduction:
Régression linéaire limitée
La méthode des moindres carrés peut confondre les valeurs aberrantes, les faux champs, etc. Des contraintes sont nécessaires pour réduire la variance de la ligne que nous mettons dans l'ensemble de données. La bonne solution consiste à adapter un modèle de régression linéaire qui garantit que les poids ne se comportent pas «mal». Les modèles peuvent avoir la norme L1 (LASSO) ou L2 (Ridge Regression) ou les deux (régression élastique).
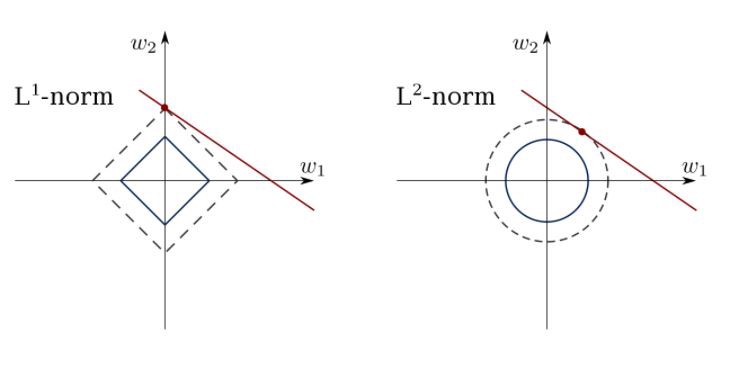
Utilisez cet algorithme pour faire correspondre les lignes de régression contraintes, en évitant de remplacer.
Lien utile:
Guides d'introduction:
Méthode K-means
Algorithme de clustering incontrôlé préféré de tous. Étant donné un ensemble de données sous forme de vecteurs, nous pouvons créer des groupes de points en fonction des distances entre eux. Il s'agit de l'un des algorithmes d'apprentissage automatique qui déplace séquentiellement les centres des grappes, puis regroupe les points avec chaque centre de la grappe. L'entrée est le nombre de clusters à créer et le nombre d'itérations.
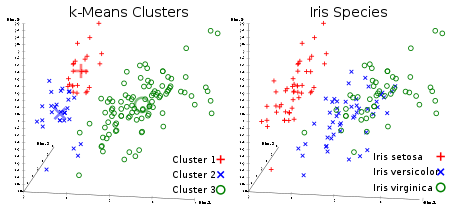
Lien utile:
Guides d'introduction:
Régression logistique
La régression logistique est limitée par une régression linéaire avec non-linéarité (principalement en utilisant la fonction sigmoïde ou tanh) après application des poids, par conséquent, la limitation de sortie est proche des classes +/- (qui sont 1 et 0 dans le cas d'un sigmoïde). Les fonctions de perte d'entropie croisée sont optimisées en utilisant la méthode de descente de gradient.
Remarque pour les débutants: la régression logistique est utilisée pour la classification, pas la régression. En général, il est similaire à un réseau neuronal monocouche. Formé en utilisant des techniques d'optimisation telles que la descente de gradient ou le L-BFGS. Les développeurs de NLP l'utilisent souvent, l'appelant «classification d'entropie maximale».

Utilisez LR pour former des classificateurs simples mais très «solides».
Lien utile:
Guide d'introduction:
SVM (Support Vector Method)
SVM est un modèle linéaire tel que la régression linéaire / logistique. La différence est qu'il a une fonction de perte basée sur la marge. Vous pouvez optimiser la fonction de perte à l'aide de méthodes d'optimisation telles que L-BFGS ou SGD.

Une chose unique que SVM peut faire est d'apprendre les classificateurs de classe.
SVM peut être utilisé pour former des classificateurs (même des régresseurs).
Lien utile:
Guides d'introduction:
Réseaux de neurones à distribution directe
Fondamentalement, ce sont des classificateurs multiniveaux de régression logistique. De nombreuses couches de poids sont séparées par des non-linéarités (sigmoïde, tanh, relu + softmax et cool new selu). Ils sont également appelés perceptrons multicouches. Les FFNN peuvent être utilisés pour la classification et la «formation sans enseignant» comme auto-encodeurs.

FFNN peut être utilisé pour entraîner le classificateur ou extraire des fonctions en tant qu'encodeurs automatiques.
Liens utiles:
Guides d'introduction:
Réseaux de neurones convolutifs
Presque toutes les réalisations modernes dans le domaine de l'apprentissage automatique ont été obtenues en utilisant des réseaux de neurones convolutionnels. Ils sont utilisés pour classer des images, détecter des objets ou même segmenter des images. Inventés par Jan Lekun au début des années 90, les réseaux ont des couches convolutionnelles qui agissent comme des extracteurs hiérarchiques d'objets. Vous pouvez les utiliser pour travailler avec du texte (et même pour travailler avec des graphiques).
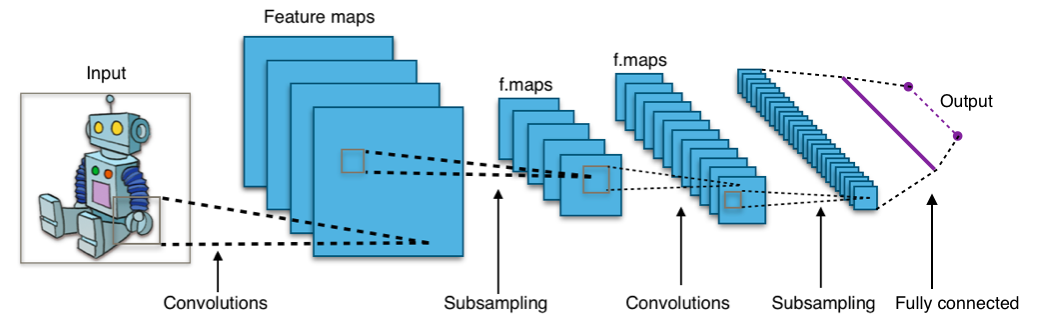
Liens utiles:
Guides d'introduction:
Réseaux de neurones récurrents (RNN)
Les RNN modélisent les séquences en appliquant récursivement le même ensemble de poids à l'état de l'agrégateur au temps t et à l'entrée au temps t. Les RNN purs sont rarement utilisés actuellement, mais ses analogues, par exemple, LSTM et GRU, sont les plus modernes dans la plupart des tâches de modélisation de séquence. LSTM, qui est utilisé à la place d'une simple couche dense en RNN pur.

Utilisez RNN pour toute tâche de classification de texte, de traduction automatique, de modélisation de langage.
Liens utiles:
Guides d'introduction:
Champs aléatoires conditionnels (CRF)
Ils sont utilisés pour la modélisation de séquences, comme les RNN, et peuvent être utilisés en combinaison avec des RNN. Ils peuvent également être utilisés dans d'autres tâches de prévision structurée, par exemple, dans la segmentation d'images. CRF modélise chaque élément d'une séquence (par exemple, une phrase) de sorte que les voisins influencent l'étiquette d'un composant dans la séquence, et non toutes les étiquettes qui sont indépendantes les unes des autres.
Utilisez CRF pour lier des séquences (dans le texte, l'image, les séries chronologiques, l'ADN, etc.).
Lien utile:
Guides d'introduction:
Arbres de décision et forêts aléatoires
L'un des algorithmes d'apprentissage automatique les plus courants. Utilisé dans les statistiques et l'analyse des données pour les modèles de prévision. La structure est «feuilles» et «branches». Les attributs dont dépend la fonction objectif sont enregistrés sur les «branches» de l'arbre de décision, les valeurs de la fonction objectif sont écrites dans les «feuilles» et les attributs qui distinguent les cas sont enregistrés dans les nœuds restants.
Pour classer un nouveau cas, vous devez descendre l'arborescence jusqu'à la feuille et émettre la valeur correspondante. L'objectif est de créer un modèle qui prédit la valeur de la variable cible en fonction de plusieurs variables d'entrée.
Liens utiles:
Guides d'introduction:
Vous en apprendrez plus sur l'apprentissage automatique et la science des données en vous abonnant à mon compte sur
Habré et sur la chaîne Telegram
Neuron . Ne sautez pas les futurs articles.
Toutes les connaissances!