Depuis près d'un an, j'utilise le service Yandex Music et tout me convient. Mais il y a une page intéressante dans ce service - l'histoire. Il stocke toutes les pistes qui ont été écoutées dans l'ordre chronologique. Et bien sûr, je voulais le télécharger et analyser ce que j'avais entendu là tout le temps.

Premières tentatives
Commençant à traiter cette page, j'ai immédiatement rencontré un problème. Le service ne télécharge pas toutes les pistes à la fois, mais uniquement lorsque vous faites défiler. Je ne voulais pas télécharger le renifleur et comprendre le trafic, et je n'avais aucune compétence en la matière à ce moment-là. J'ai donc décidé d'aller plus simplement en émulant le navigateur en utilisant du sélénium.
Le script a été écrit. Mais il a travaillé très instable et pendant longtemps. Mais il a réussi à charger l'histoire. Après une analyse simple, j'ai quitté le script sans modifications, jusqu'à ce que je ne veuille plus télécharger l'histoire après un certain temps. Espérant le meilleur, je l'ai lancé. Et, bien sûr, il a fait une erreur. Puis j'ai réalisé qu'il était temps de tout faire humainement.
Option de travail
Pour l'analyse du trafic, j'ai choisi Fiddler pour moi en raison d'une interface plus puissante pour le trafic http, contrairement à Wireshark. En exécutant le renifleur, je m'attendais à voir des demandes d'api avec un jeton. Mais non. Notre objectif était music.yandex.ru/handlers/library.jsx . Et les demandes nécessitaient une autorisation complète sur le site. Nous allons commencer avec elle.
Se connecter
Rien de compliqué ici. Nous allons sur passport.yandex.ru/auth , trouvons les paramètres des demandes et faisons deux demandes d'autorisation.
auth_page = self.get('/auth').text csrf_token, process_uuid = self.find_auth_data(auth_page) auth_login = self.post( '/registration-validations/auth/multi_step/start', data={'csrf_token': csrf_token, 'process_uuid': process_uuid, 'login': self.login} ).json() auth_password = self.post( '/registration-validations/auth/multi_step/commit_password', data={'csrf_token': csrf_token, 'track_id': auth_login['track_id'], 'password': self.password} ).json()
Et donc nous nous sommes connectés.
Historique de téléchargement
Ensuite, nous allons sur music.yandex.ru/user/<user>/history , où nous music.yandex.ru/user/<user>/history également quelques paramètres qui nous sont utiles lors de la réception d'informations sur les pistes. Vous pouvez maintenant télécharger l'histoire. Nous obtenons les music.yandex.ru/handlers/library.jsx sur music.yandex.ru/handlers/library.jsx avec les paramètres {'owner': <user>, 'filter': 'history', 'likeFilter': 'favorite', 'lang': 'ru', 'external-domain': 'music.yandex.ru', 'overembed': 'false', 'ncrnd': '0.9546193023464256'} . J'étais intéressé par le paramètre ncrnd ici. Lors des requêtes, Yandex attribue toujours des valeurs différentes à ce paramètre, mais tout fonctionne de la même manière. De retour, nous obtenons l'historique sous la forme de pistes d'identification et d'informations détaillées sur les dix meilleures pistes. À partir des informations détaillées sur la piste, vous pouvez enregistrer de nombreuses données intéressantes pour une analyse ultérieure. Par exemple, l'année de sortie, la durée du morceau et le genre. Les informations sur le reste des pistes sont obtenues à partir de music.yandex.ru/handlers/track-entries.jsx . Nous sauvegardons toutes ces affaires en csv et nous passons à l'analyse.
Analyse
Pour l'analyse, nous utilisons des outils standard sous forme de pandas et de matplotlib.
import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv('statistics.csv') df.head(3)
Remplacez None par python par NaN et jetez-les.
df = df.replace('None', pd.np.nan).dropna()
Commençons par un simple. Voyons le temps que nous avons passé à écouter toutes les pistes
duration_sec = df['duration_sec'].astype('int64').sum() ss = duration_sec % 60 m = duration_sec // 60 mm = m % 60 h = m // 60 hh = h % 60 f'{h // 24} {hh}:{mm}:{ss}'
'15 15:30:14'
Mais ici, vous pouvez discuter de l'exactitude de ce chiffre, car il n'est pas clair quelle partie de la piste vous devez écouter, Yandex l'a ajouté à l'histoire.
Voyons maintenant la répartition des morceaux par année de sortie.
plt.rcParams['figure.figsize'] = [15, 5] plt.hist(df['year'].sort_values(), bins=len(df['year'].unique())) plt.xticks(rotation='vertical') plt.show()
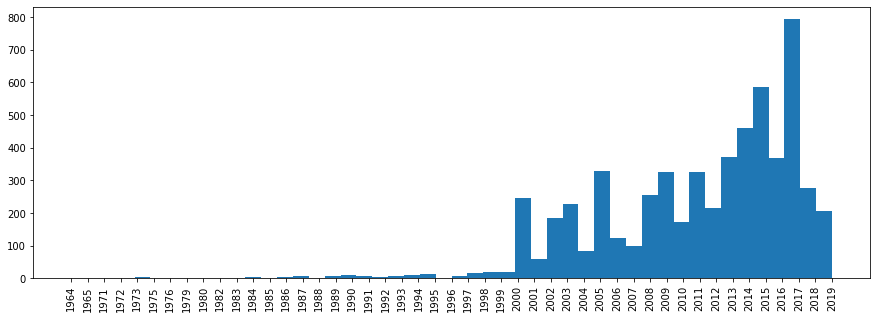
Ici, ce n'est pas aussi simple, car les diverses collections de «Best Hits» auront une année plus tard.
D'autres statistiques seront construites sur un principe très similaire. Je vais donner un exemple des morceaux les plus écoutés
df.groupby(['track_id', 'artist','track'])['track_id'].count().sort_values(ascending=False).head()
et morceaux les plus joués de l'artiste
artist_name = 'Coldplay' df.groupby([ 'artist_id', 'track_id', 'artist', 'track' ])['artist_id'].count().sort_values(ascending=False)[:,:,artist_name].head(5)
Le code complet peut être trouvé ici.