
Avec l'avènement des téléphones portables avec des caméras de haute qualité, nous avons commencé à faire de plus en plus de photos et de vidéos de moments lumineux et mémorables dans nos vies. Beaucoup d'entre nous ont des archives photographiques qui remontent à des décennies et comprennent des milliers d'images, ce qui les rend de plus en plus difficiles à parcourir. N'oubliez pas combien de temps il a fallu pour trouver une photo intéressante il y a quelques années à peine.
L'un des objectifs de Mail.ru Cloud est de fournir les moyens les plus pratiques pour accéder et rechercher vos propres archives photo et vidéo. À cette fin, nous, à Mail.ru Computer Vision Team, avons créé et mis en œuvre des systèmes de traitement intelligent des images: recherche par objet, par scène, par visage, etc. Une autre technologie spectaculaire est la reconnaissance historique. Aujourd'hui, je vais vous dire comment nous en avons fait une réalité grâce au Deep Learning.
Imaginez la situation: vous revenez de vos vacances avec un tas de photos. En discutant avec vos amis, vous êtes invité à montrer une image d'un endroit qui vaut le détour, comme un palais, un château, une pyramide, un temple, un lac, une cascade, une montagne, etc. Vous vous précipitez pour faire défiler le dossier de votre galerie en essayant d'en trouver un qui est vraiment bon. Très probablement, il est perdu parmi des centaines d'images, et vous dites que vous le montrerez plus tard.
Nous résolvons ce problème en regroupant les photos des utilisateurs dans des albums. Cela vous permettra de trouver les images dont vous avez besoin en quelques clics. Nous avons maintenant des albums compilés par visage, par objet et par scène, ainsi que par point de repère.
Les photos avec des points de repère sont essentielles car elles capturent souvent les moments forts de notre vie (voyages, par exemple). Il peut s'agir d'images avec une architecture ou une nature sauvage en arrière-plan. C'est pourquoi nous cherchons à localiser ces images et à les rendre facilement accessibles aux utilisateurs.
Particularités de la reconnaissance des monuments
Il y a une nuance ici: on ne se contente pas d'enseigner un modèle et de le faire reconnaître immédiatement des points de repère - il y a un certain nombre de défis.
Premièrement, nous ne pouvons pas dire clairement ce qu'est réellement un «point de repère». Nous ne pouvons pas dire pourquoi un bâtiment est un point de repère, alors qu'un autre à côté ne l'est pas. Ce n'est pas un concept formalisé, ce qui complique la formulation de la tâche de reconnaissance.
Deuxièmement, les points de repère sont incroyablement diversifiés. Il peut s'agir de bâtiments ayant une valeur historique ou culturelle, comme un temple, un palais ou un château. Alternativement, il peut s'agir de toutes sortes de monuments. Ou des caractéristiques naturelles: lacs, canyons, cascades, etc. En outre, il existe un modèle unique qui devrait être en mesure de trouver tous ces points de repère.
Troisièmement, les images avec des repères sont extrêmement rares. Selon nos estimations, elles ne représentent que 1 à 3% des photos des utilisateurs. C'est pourquoi nous ne pouvons pas nous permettre de faire des erreurs de reconnaissance, car si nous montrons à quelqu'un une photographie sans repère, ce sera assez évident et provoquera une réaction indésirable. Ou, à l'inverse, imaginez que vous montrez une photo avec un lieu d'intérêt à New York à une personne qui n'est jamais allée aux États-Unis. Ainsi, le modèle de reconnaissance devrait avoir un FPR faible (taux de faux positifs).
Quatrièmement, environ 50% des utilisateurs, voire plus, désactivent généralement la sauvegarde des données géographiques. Nous devons en tenir compte et utiliser uniquement l'image elle-même pour identifier l'emplacement. Aujourd'hui, la plupart des services capables de gérer les repères utilisent d'une manière ou d'une autre les géodonnées des propriétés de l'image. Cependant, nos exigences initiales étaient plus strictes.
Permettez-moi maintenant de vous montrer quelques exemples.
Voici trois objets qui se ressemblent, trois cathédrales gothiques en France. A gauche se trouve la cathédrale d'Amiens, celle du milieu est la cathédrale de Reims, et Notre-Dame de Paris est à droite.

Même un humain a besoin d'un certain temps pour regarder de près et voir qu'il s'agit de cathédrales différentes, mais le moteur devrait être capable de faire de même, et encore plus rapidement qu'un humain.
Voici un autre défi: les trois photos ici présentent Notre-Dame de Paris prises sous des angles différents. Les photos sont assez différentes, mais elles doivent encore être reconnues et récupérées.

Les caractéristiques naturelles sont entièrement différentes de l'architecture. À gauche, Césarée en Israël, à droite, Englischer Garten à Munich.

Ces photos donnent au modèle très peu d'indices à deviner.
Notre méthode
Notre méthode est entièrement basée sur des réseaux neuronaux convolutionnels profonds. La stratégie de formation que nous avons choisie était ce qu'on appelle l'apprentissage curriculaire, ce qui signifie l'apprentissage en plusieurs étapes. Pour atteindre une plus grande efficacité avec et sans données géographiques disponibles, nous avons fait une inférence spécifique. Permettez-moi de vous parler de chaque étape plus en détail.
Ensemble de données
Les données sont le carburant de l'apprentissage automatique. Tout d'abord, nous avons dû rassembler un ensemble de données pour enseigner le modèle.
Nous avons divisé le monde en 4 régions, chacune étant utilisée à une étape spécifique du processus d'apprentissage. Ensuite, nous avons sélectionné des pays dans chaque région, choisi une liste de villes pour chaque pays et collecté une banque de photos. Voici quelques exemples.

Tout d'abord, nous avons tenté de faire apprendre notre modèle à partir de la base de données obtenue. Les résultats ont été médiocres. Notre analyse a montré que les données étaient sales. Il y avait trop de bruit gênant la reconnaissance de chaque point de repère. Qu'allions-nous faire? Il serait coûteux, encombrant et pas trop sage d'examiner manuellement la majeure partie des données. Nous avons donc conçu un processus de nettoyage automatique de la base de données où la manipulation manuelle n'est utilisée qu'en une seule étape: nous avons trié sur le volet 3 à 5 photographies de référence pour chaque point de repère qui montraient définitivement l'objet souhaité sous un angle plus ou moins approprié. Cela fonctionne assez rapidement car la quantité de ces données de référence est faible par rapport à l'ensemble de la base de données. Ensuite, un nettoyage automatique basé sur des réseaux de neurones convolutionnels profonds est effectué.
Plus loin, je vais utiliser le terme «intégration» par lequel je veux dire ce qui suit. Nous avons un réseau neuronal convolutif. Nous l'avons formé pour classer les objets, puis nous avons coupé la dernière couche de classification, sélectionné quelques images, les avons analysées par le réseau et obtenu un vecteur numérique en sortie. C'est ce que j'appellerai l'intégration.
Comme je l'ai déjà dit, nous avons organisé notre processus d'apprentissage en plusieurs étapes correspondant à des parties de notre base de données. Donc, tout d'abord, nous prenons soit le réseau neuronal de l'étape précédente, soit le réseau d'initialisation.
Nous avons des photos de référence d'un point de repère, les traitons par le réseau et obtenons plusieurs plongements. Nous pouvons maintenant procéder au nettoyage des données. Nous prenons toutes les photos de l'ensemble de données pour le point de repère et les faisons également traiter par le réseau. Nous obtenons quelques plongements et déterminons la distance par rapport aux plongements de référence pour chacun. Ensuite, nous déterminons la distance moyenne et, si elle dépasse un certain seuil qui est un paramètre de l'algorithme, traitons l'objet comme non-repère. Si la distance moyenne est inférieure au seuil, nous conservons la photo.
En conséquence, nous avions une base de données qui contenait plus de 11 mille monuments de plus de 500 villes dans 70 pays, plus de 2,3 millions de photos. N'oubliez pas que la majeure partie des photographies n'a aucun repère. Nous devons le dire à nos modèles d'une manière ou d'une autre. Pour cette raison, nous avons ajouté 900 000 photos sans repères à notre base de données et formé notre modèle avec l'ensemble de données résultant.
Nous avons introduit un test hors ligne pour mesurer la qualité de l'apprentissage. Étant donné que les points de repère n'apparaissent que dans 1 à 3% de toutes les photos, nous avons compilé manuellement un ensemble de 290 images qui montraient un point de repère. Ces photos étaient assez diverses et complexes, avec un grand nombre d'objets pris sous différents angles pour rendre le test aussi difficile que possible pour le modèle. En suivant le même schéma, nous avons choisi 11 000 photographies sans repères, plutôt compliquées également, et nous avons essayé de trouver des objets qui ressemblaient beaucoup aux repères dans notre base de données.
Pour évaluer la qualité de l'apprentissage, nous mesurons la précision de notre modèle à l'aide de photos avec et sans repères. Ce sont nos deux principales mesures.
Approches existantes
Il existe relativement peu d'informations sur la reconnaissance des points de repère dans la littérature. La plupart des solutions sont basées sur des fonctionnalités locales. L'idée principale est que nous avons une image de requête et une image de la base de données. Les caractéristiques locales - points clés - sont trouvées puis mises en correspondance. Si le nombre de correspondances est suffisamment important, nous concluons que nous avons trouvé un point de repère.
Actuellement, la meilleure méthode est le DELF (fonctionnalités locales approfondies) proposé par Google, qui combine des fonctionnalités locales correspondant à un apprentissage en profondeur. En ayant une image d'entrée traitée par le réseau convolutionnel, nous obtenons certaines fonctionnalités DELF.
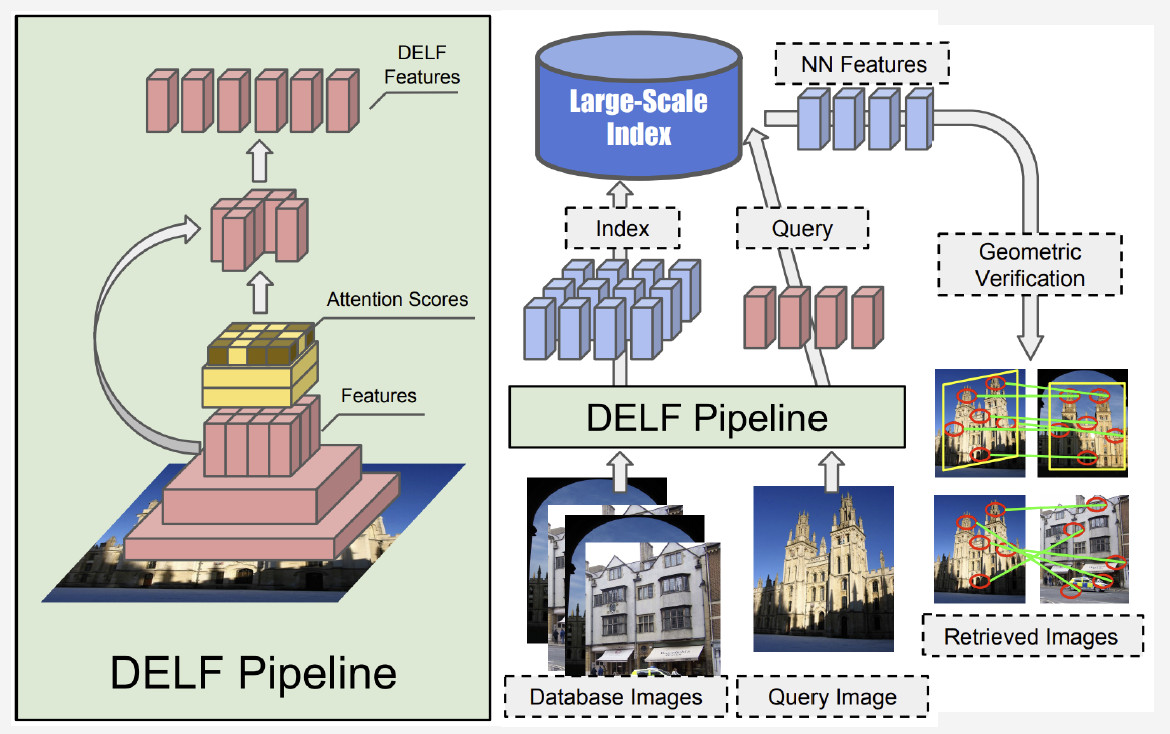
Comment fonctionne la reconnaissance des points de repère? Nous avons une banque de photos et une image d'entrée, et nous voulons savoir si elle montre un point de repère ou non. En exécutant le réseau DELF de toutes les photos, les fonctionnalités correspondantes pour la base de données et l'image d'entrée peuvent être obtenues. Ensuite, nous effectuons une recherche par la méthode du plus proche voisin et obtenons des images candidates avec des caractéristiques en sortie. Nous utilisons la vérification géométrique pour faire correspondre les caractéristiques: en cas de succès, nous concluons que l'image montre un point de repère.
Réseau de neurones convolutifs
La pré-formation est cruciale pour le Deep Learning. Nous avons donc utilisé une base de données de scènes pour pré-former notre réseau de neurones. Pourquoi de cette façon? Une scène est un objet multiple qui comprend un grand nombre d'autres objets. Landmark est une instance d'une scène. En pré-entraînant le modèle avec une telle base de données, nous pouvons lui donner une idée de certaines fonctionnalités de bas niveau qui peuvent ensuite être généralisées pour une reconnaissance réussie des points de repère.
Nous avons utilisé un réseau neuronal de la famille des réseaux résiduels comme modèle. La différence critique de ces réseaux est qu'ils utilisent un bloc résiduel qui inclut une connexion par saut qui permet à un signal de sauter par-dessus des couches avec des poids et de passer librement. Une telle architecture permet de former des réseaux profonds avec un haut niveau de qualité et de contrôler l'effet de gradient de fuite, ce qui est essentiel pour la formation.
Notre modèle est Wide ResNet-50-2, une version de ResNet-50 où le nombre de convolutions dans le bloc d'étranglement interne est doublé.

Le réseau fonctionne très bien. Nous l'avons testé avec notre base de données de scènes, et voici les résultats:
Wide ResNet fonctionnait presque deux fois plus vite que ResNet-200. Après tout, c'est la vitesse de rotation qui est cruciale pour la production. Compte tenu de toutes ces considérations, nous avons choisi Wide ResNet-50-2 comme notre principal réseau de neurones.
La formation
Nous avons besoin d'une fonction de perte pour former notre réseau. Nous avons décidé d'utiliser l'approche d'apprentissage métrique pour le choisir: un réseau de neurones est formé de sorte que les éléments de la même classe affluent vers un cluster, tandis que les clusters pour différentes classes doivent être espacés autant que possible. Pour les points de repère, nous avons utilisé la perte centrale qui tire les éléments d'une classe vers un centre. Une caractéristique importante de cette approche est qu'elle ne nécessite pas d'échantillonnage négatif, ce qui devient une chose assez difficile à faire à des époques ultérieures.
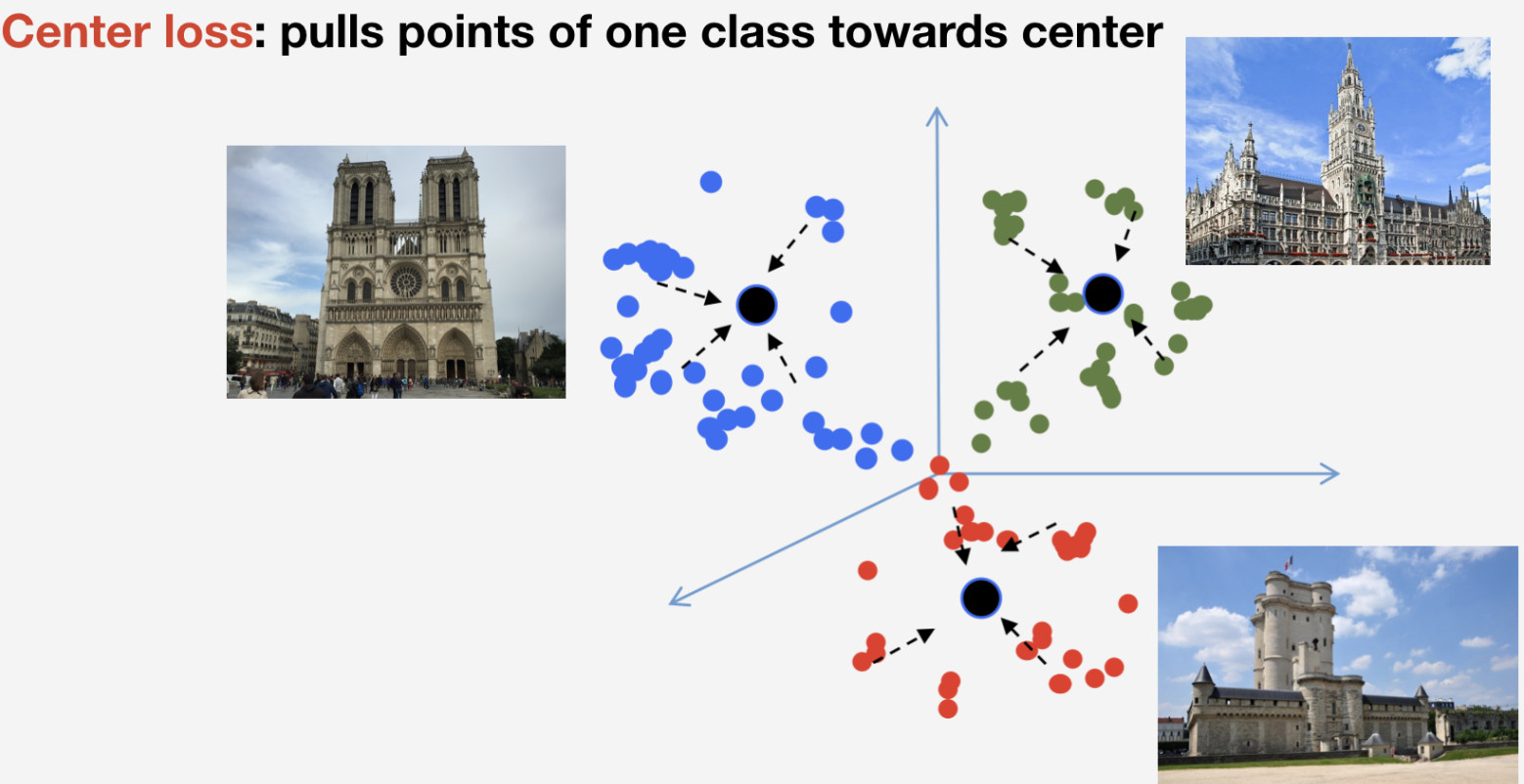
N'oubliez pas que nous avons n classes de points de repère et une autre classe «non-repère» pour laquelle la perte centrale n'est pas utilisée. Nous supposons qu'un point de repère est un seul et même objet, et qu'il a une structure, il est donc logique de déterminer son centre. Quant au non-repère, il peut se référer à n'importe quoi, donc cela n'a aucun sens de déterminer son centre.
Nous avons ensuite mis tout cela ensemble, et il y a notre modèle de formation. Il comprend trois parties principales:
- Large réseau neuronal convolutionnel ResNet 50-2 pré-formé avec une base de données de scènes;
- Partie d’incorporation comprenant une couche entièrement connectée et une couche normalisée par lots;
- Classificateur qui est une couche entièrement connectée, suivie d'une paire composée de la perte Softmax et de la perte centrale.

Comme vous vous en souvenez, notre base de données est divisée en 4 parties par région. Nous utilisons ces 4 parties dans un paradigme d'apprentissage curriculaire. Nous avons un ensemble de données actuel, et à chaque étape de l'apprentissage, nous ajoutons une autre partie du monde pour obtenir un nouvel ensemble de données pour la formation.
Le modèle comprend trois parties et nous utilisons un taux d'apprentissage spécifique pour chacune dans le processus de formation. Cela est nécessaire pour que le réseau puisse à la fois apprendre les points de repère d'une nouvelle partie de l'ensemble de données que nous avons ajoutée et se souvenir des données déjà apprises. De nombreuses expériences ont prouvé que cette approche était la plus efficace.
Nous avons donc formé notre modèle. Maintenant, nous devons comprendre comment cela fonctionne. Utilisons la carte d'activation de classe pour trouver la partie de l'image à laquelle notre réseau de neurones réagit le plus facilement. L'image ci-dessous montre les images d'entrée dans la première ligne, et les mêmes images superposées avec la carte d'activation de classe du réseau que nous avons formée à l'étape précédente sont affichées dans la deuxième ligne.

La carte thermique montre quelles parties de l'image sont les plus fréquentées par le réseau. Comme le montre la carte d'activation de classe, notre réseau de neurones a appris avec succès le concept de point de repère.
Inférence
Maintenant, nous devons utiliser ces connaissances d'une manière ou d'une autre pour faire avancer les choses. Puisque nous avons utilisé la perte de centre pour la formation, dans le cas de l'inférence, il semble tout à fait logique de déterminer également les centroïdes pour les points de repère.
Pour ce faire, nous prenons une partie des images de l'ensemble d'entraînement pour un monument, disons le Cavalier de bronze à Saint-Pétersbourg. Ensuite, nous les faisons traiter par le réseau, obtenons les plongements, calculons la moyenne et dérivons un centroïde.
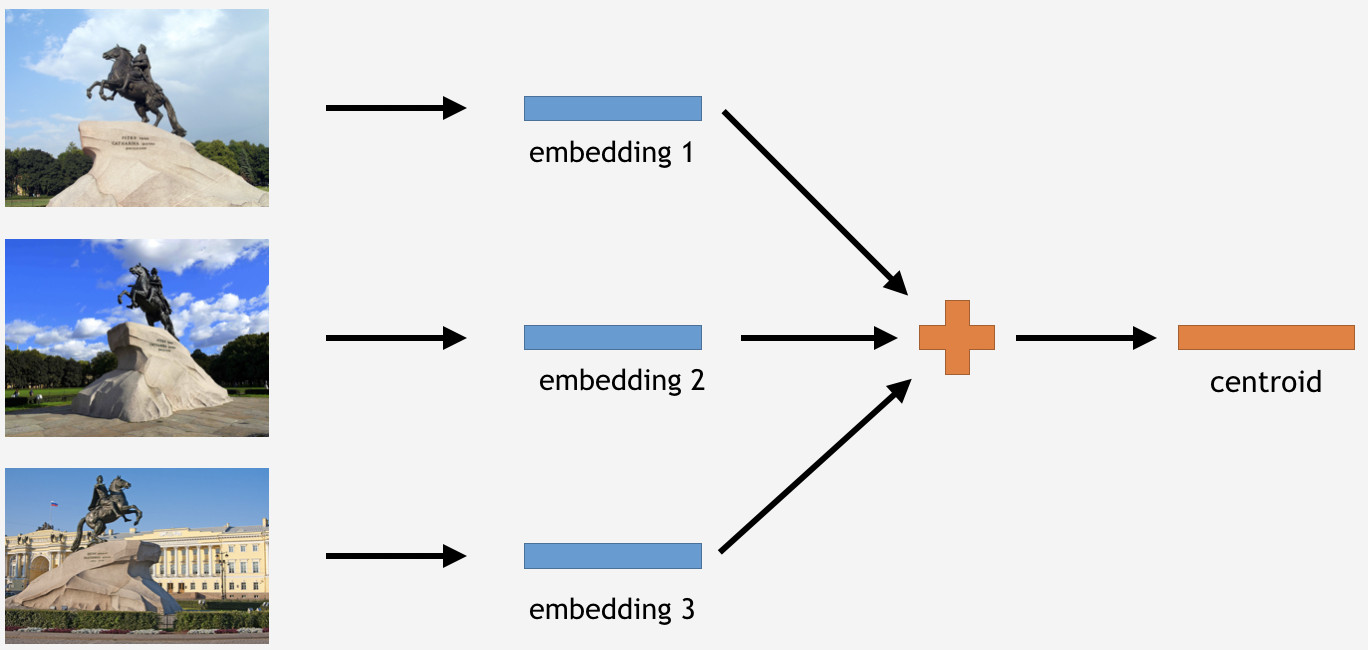
Cependant, voici une question: combien de centroïdes par point de repère il est logique de dériver? Au début, il semblait clair et logique de dire: un centroïde. Pas exactement, comme il s'est avéré. Nous avons d'abord décidé de faire un seul centroïde aussi, et le résultat n'était pas mauvais. Alors pourquoi plusieurs centroïdes?
Premièrement, les données dont nous disposons ne sont pas aussi propres. Bien que nous ayons nettoyé l'ensemble de données, nous n'avons supprimé que les données évidentes sur les déchets. Cependant, il pourrait toujours y avoir des images qui ne sont pas manifestement des déchets mais qui nuisent au résultat.
Par exemple, j'ai un palais d'hiver de classe historique à Saint-Pétersbourg. Je veux en dériver un centroïde. Cependant, son jeu de données comprend des photos de la place du Palais et de l'arc du siège général, car ces objets sont proches les uns des autres. Si le centroïde doit être déterminé pour toutes les images, le résultat ne sera pas aussi stable. Ce que nous devons faire est de regrouper d'une manière ou d'une autre leurs incorporations dérivées du réseau de neurones, de ne prendre que le centroïde qui traite avec le Palais d'Hiver et de faire la moyenne en utilisant les données résultantes.

Deuxièmement, les photographies peuvent avoir été prises sous différents angles.
Voici un exemple d'un tel comportement illustré par le Beffroi de Bruges. Deux centroïdes ont été dérivés pour cela. Dans la rangée supérieure de l'image, il y a ces photos qui sont plus proches du premier centroïde, et dans la deuxième rangée - celles qui sont plus proches du deuxième centroïde.

Le premier centroïde traite de photographies plus «grandioses» qui ont été prises à courte distance au marché de Bruges. Le deuxième centroïde traite de photographies prises à distance dans des rues particulières.
En fait, en dérivant plusieurs centroïdes par classe de points de repère, nous pouvons réfléchir à l'inférence de différents angles de caméra pour ce point de repère.
Alors, comment obtenir ces ensembles pour dériver les centroïdes? Nous appliquons un regroupement hiérarchique (lien complet) aux ensembles de données pour chaque point de repère. Nous l'utilisons pour trouver des clusters valides dont les centroïdes doivent être dérivés. Par grappes valides, nous entendons celles comprenant au moins 50 photographies à la suite de grappes. Les autres clusters sont rejetés. En conséquence, nous avons obtenu environ 20% des repères avec plus d'un centroïde.
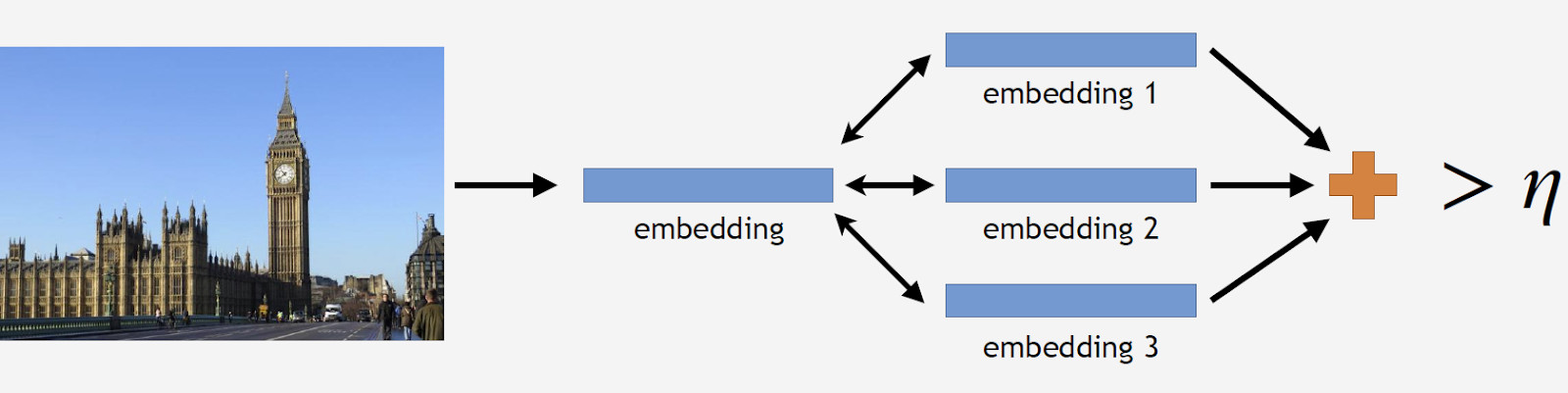
Passons maintenant à l'inférence. Il est obtenu en deux étapes: premièrement, nous alimentons l'image d'entrée à notre réseau de neurones convolutionnels et obtenons l'intégration, puis nous associons l'intégration avec les centroïdes en utilisant le produit scalaire. Si les images ont des données géographiques, nous limitons la recherche aux centroïdes, qui se réfèrent aux points de repère situés dans un carré de 1 x 1 km de l'emplacement de l'image. Cela permet une recherche plus précise et un seuil inférieur pour la correspondance ultérieure. Si la distance résultante dépasse le seuil qui est un paramètre de l'algorithme, alors nous concluons qu'une photo a un point de repère avec la valeur maximale du produit scalaire. Si c'est moins, alors c'est une photo sans repère.
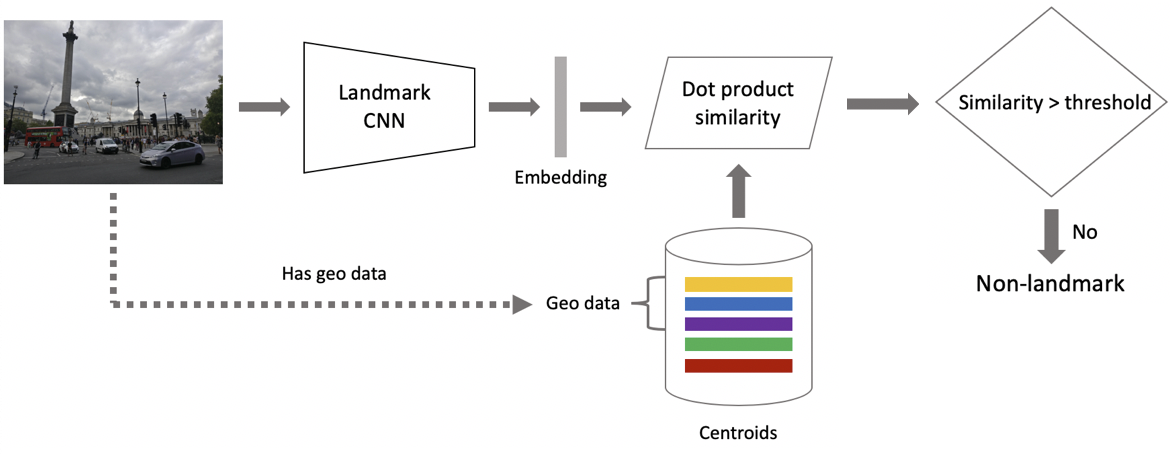
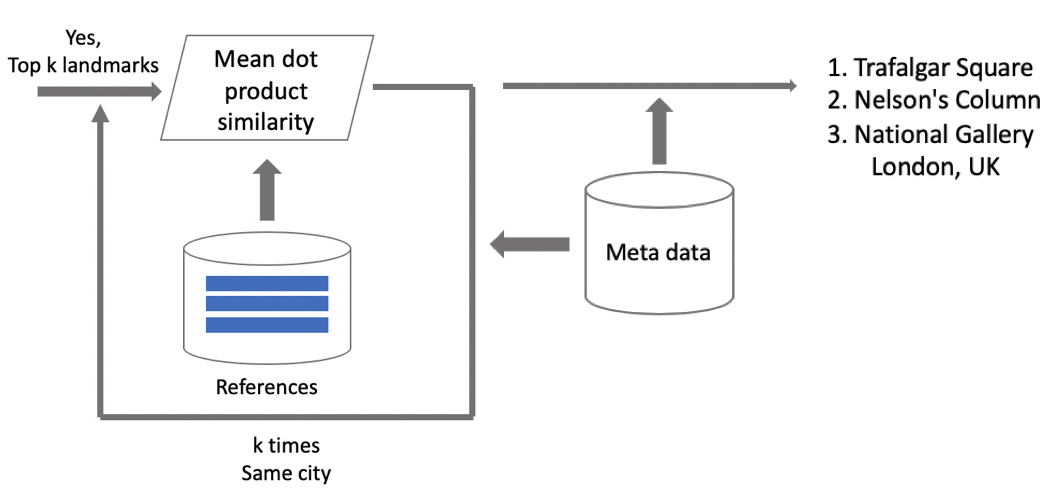
Supposons qu'une photo ait un repère. Si nous avons des données géographiques, nous les utilisons et obtenons une réponse. Si les données géographiques ne sont pas disponibles, nous effectuons une vérification supplémentaire. Lorsque nous nettoyions l'ensemble de données, nous avons créé un ensemble d'images de référence pour chaque classe. Nous pouvons déterminer les plongements pour eux, puis obtenir la distance moyenne entre eux et l'incorporation de l'image de requête. S'il dépasse un certain seuil, la vérification est réussie et nous introduisons des métadonnées et obtenons un résultat. Il est important de noter que nous pouvons exécuter cette procédure pour plusieurs points de repère qui ont été trouvés dans une image.
Résultats des tests
Nous avons comparé notre modèle avec DELF, pour lequel nous avons pris des paramètres avec lesquels il montrerait les meilleures performances dans notre test. Les résultats sont presque identiques.
Nous avons ensuite classé les repères en deux types: fréquents (plus de 100 photographies dans la base de données), qui représentaient 87% de tous les repères du test, et rares. Notre modèle fonctionne bien avec les plus fréquents: 85,3% de précision. Avec des points de repère rares, nous avions 46%, ce qui n'était pas mal non plus du tout, ce qui signifie que notre approche fonctionnait assez bien même avec peu de données.
Ensuite, nous avons exécuté un test A / B avec des photos d'utilisateurs. En conséquence, le taux de conversion d'achat d'espace cloud a augmenté de 10%, le taux de conversion de désinstallation d'applications mobiles a diminué de 3% et le nombre de vues d'album a augmenté de 13%.
Comparons notre vitesse à celle du DELF. Avec le GPU, DELF nécessite 7 exécutions réseau car il utilise 7 échelles d'image, tandis que notre approche n'en utilise que 1. Avec le CPU, DELF utilise une recherche plus longue par la méthode du plus proche voisin et une très longue vérification géométrique. Au final, notre méthode était 15 fois plus rapide avec le CPU. Notre approche montre une vitesse plus élevée dans les deux cas, ce qui est crucial pour la production.
Résultats: souvenirs de vacances
Au début de cet article, j'ai mentionné une solution pour faire défiler et trouver les images de repère souhaitées. Ça y est.
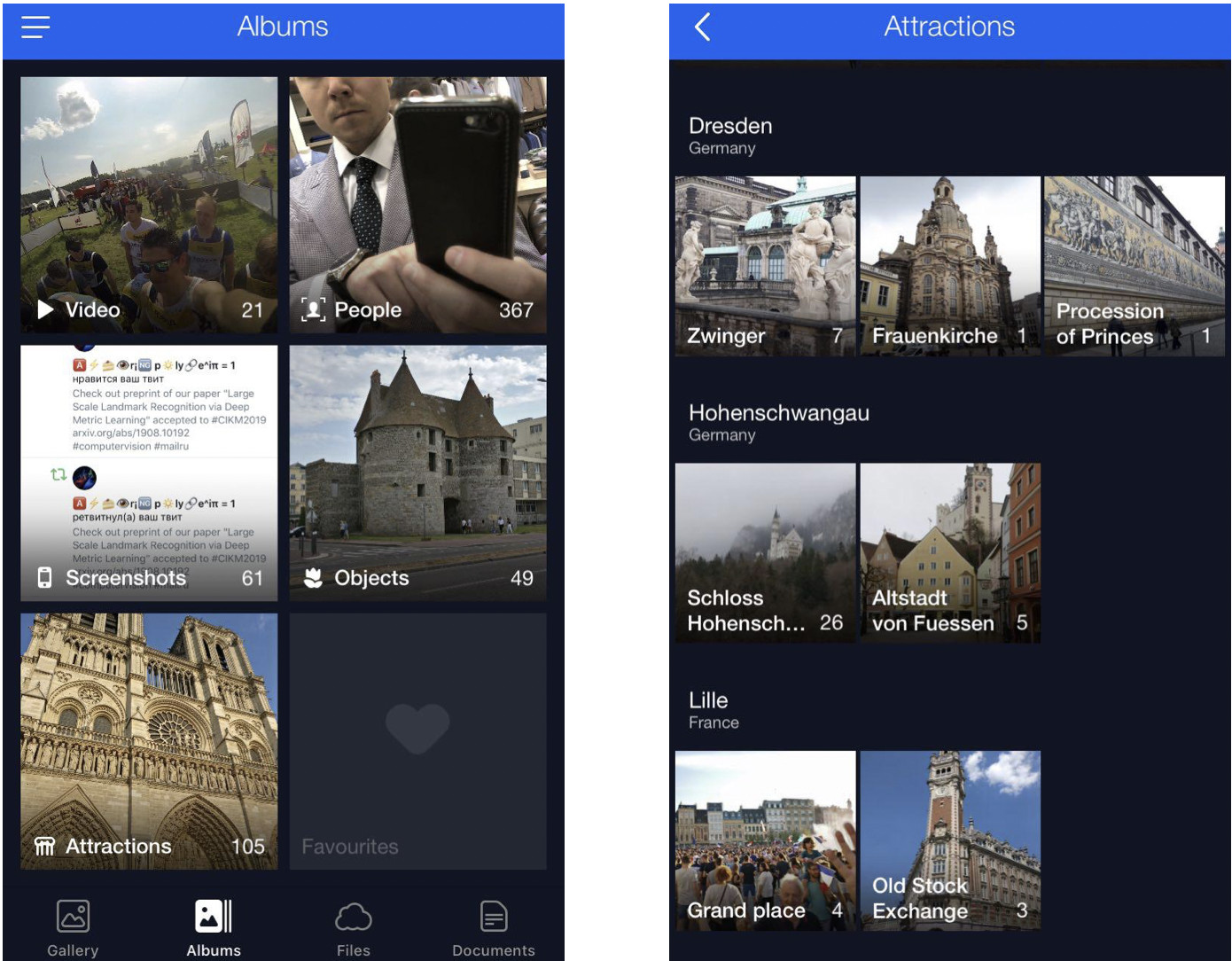
C'est mon nuage où toutes les photos sont classées dans des albums. Il existe des albums «People», «Objects» et «Attractions». Dans l'album Attractions, les points de repère sont classés en albums regroupés par ville. Un clic sur Dresdner Zwinger ouvre un album avec des photos de ce monument seulement.
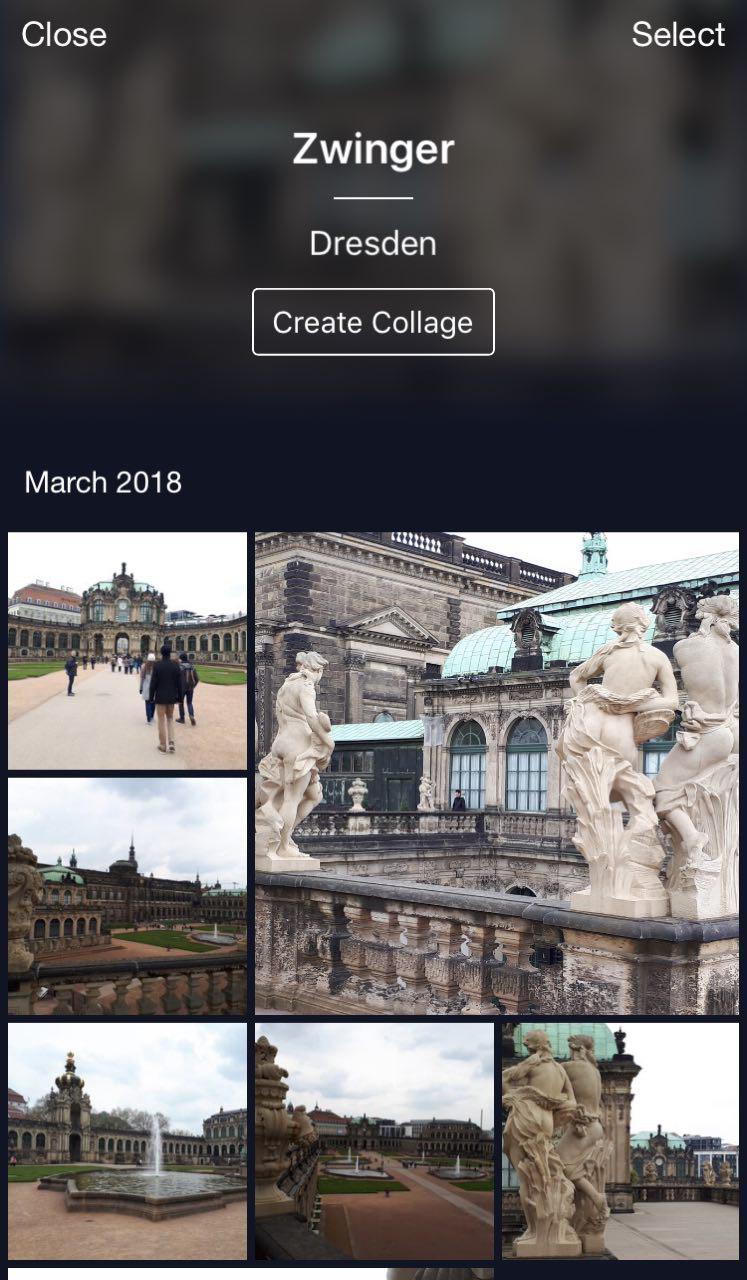
Une fonctionnalité pratique: vous pouvez partir en vacances, prendre des photos et les stocker dans votre cloud. Plus tard, lorsque vous souhaitez les télécharger sur Instagram ou les partager avec vos amis et votre famille, vous n'aurez pas à chercher et à choisir trop longtemps - les photos souhaitées seront disponibles en quelques clics.
Conclusions
Permettez-moi de vous rappeler les principales caractéristiques de notre solution.
- Nettoyage de base de données semi-automatique. Un peu de travail manuel est nécessaire pour la cartographie initiale, puis le réseau neuronal fera le reste. Cela permet de nettoyer rapidement les nouvelles données et de les utiliser pour recycler le modèle.
- Nous utilisons des réseaux de neurones convolutionnels profonds et un apprentissage métrique profond qui nous permet d'apprendre efficacement la structure en classe.
- Nous avons utilisé l'apprentissage curriculaire, c'est-à-dire la formation en plusieurs parties, comme paradigme de formation. Cette approche nous a été très utile. Nous utilisons plusieurs centroïdes sur l'inférence, qui permettent d'utiliser des données plus propres et de trouver différentes vues des points de repère.
Il peut sembler que la reconnaissance d'objets est une tâche banale. Cependant, en explorant les besoins réels des utilisateurs, nous découvrons de nouveaux défis comme la reconnaissance des points de repère. Cette technique permet de dire aux gens quelque chose de nouveau sur le monde en utilisant des réseaux de neurones. C'est très encourageant et motivant!