Le cours complet de russe se trouve sur ce lien .
Le cours d'anglais original est disponible sur ce lien .

Table des matières
- Entretien avec Sebastian Trun
- Présentation
- Transfert du modèle d'apprentissage
- MobileNet
- CoLab: Cats Vs Dogs with Transfer Training
- Plonger dans des réseaux de neurones convolutifs
- Partie pratique: détermination des couleurs avec transfert de formation
- Résumé
Entretien avec Sebastian Trun
- Il s'agit de la leçon 6 et elle est entièrement dédiée au transfert d'apprentissage. Le transfert d'apprentissage est le processus d'utilisation d'un modèle existant avec peu de raffinement pour de nouvelles tâches. Le transfert de la formation contribue à réduire le temps de formation du modèle en donnant une certaine augmentation de l'efficacité lors de l'apprentissage au tout début. Sébastien, que penses-tu du transfert de formation? Avez-vous déjà pu utiliser la méthodologie de transfert d'enseignement dans votre travail et votre recherche?
- Ma thèse était uniquement consacrée au thème du transfert de formation et s'intitulait " Explication sur la base du transfert de formation ". Lorsque nous travaillions sur une dissertation, l'idée était qu'il était possible d'enseigner à distinguer tous les autres objets de ce type sur un seul objet (ensemble de données, entité) dans diverses variations et formats. Dans le travail, nous avons utilisé l'algorithme développé, qui a distingué les principales caractéristiques (attributs) de l'objet et a pu les comparer avec un autre objet. Les bibliothèques comme Tensorflow sont déjà livrées avec des modèles pré-formés.
- Oui, chez Tensorflow, nous avons un ensemble complet de modèles pré-formés que vous pouvez utiliser pour résoudre des problèmes pratiques. Nous parlerons des sets prêts à l'emploi un peu plus tard.
- Oui, oui! Si vous y réfléchissez, alors les gens sont impliqués dans le transfert de formation tout au long de leur vie.
- Peut-on dire que grâce à la méthode de transfert de la formation, nos nouveaux étudiants n'auront pas à un moment ou à un autre la connaissance de l'apprentissage automatique car il suffira de connecter un modèle déjà préparé et de l'utiliser?
- La programmation consiste à écrire ligne par ligne, nous donnons des commandes à l'ordinateur. Notre objectif est de nous assurer que tout le monde sur la planète est en mesure de programmer en fournissant à l'ordinateur uniquement des exemples de données d'entrée. D'accord, si vous voulez apprendre à un ordinateur à distinguer les chats des chiens, il est assez difficile de trouver 100 000 images différentes de chats et 100 000 images différentes de chiens, et grâce au transfert de formation, vous pouvez résoudre ce problème en plusieurs lignes.
- Oui, c'est vraiment ça! Merci pour les réponses et passons enfin à l'apprentissage.
Présentation
- Bonjour et bon retour!
- La dernière fois, nous avons formé un réseau neuronal convolutif pour classer les chats et les chiens dans l'image. Notre premier réseau de neurones a été recyclé, donc son résultat n'était pas si élevé - une précision d'environ 70%. Après cela, nous avons implémenté l'extension et le décrochage des données (déconnexion arbitraire des neurones), ce qui nous a permis d'augmenter la précision des prédictions jusqu'à 80%.
- Malgré le fait que 80% peut sembler un excellent indicateur, l'erreur de 20% est encore trop importante. Non? Que pouvons-nous faire pour augmenter la précision de la classification? Dans cette leçon, nous utiliserons la technique de transfert de connaissances (transfert du modèle de connaissances), qui nous permettra d'utiliser le modèle développé par des experts et formé sur d'énormes matrices de données. Comme nous le verrons dans la pratique, en transférant le modèle de connaissances, nous pouvons atteindre une précision de classification de 95%. Commençons!
Transfert de modèle d'apprentissage
En 2012, le réseau neuronal AlexNet a révolutionné le monde de l'apprentissage automatique et popularisé l'utilisation des réseaux de neurones convolutifs pour la classification en remportant le défi de reconnaissance visuelle à grande échelle ImageNet.
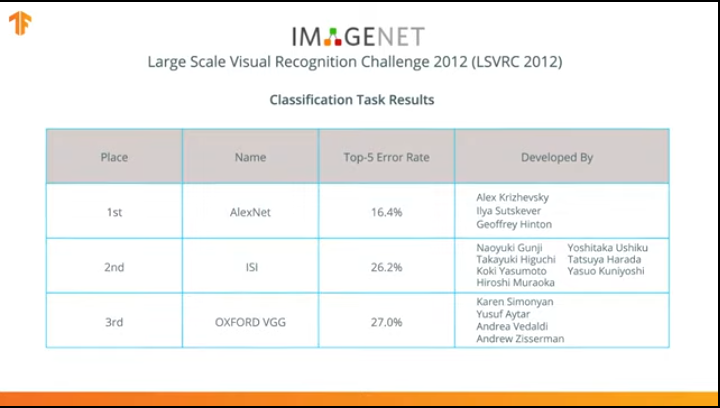
Après cela, la lutte a commencé à développer des réseaux de neurones plus précis et efficaces qui pourraient dépasser AlexNet dans les tâches de classification des images de l'ensemble de données ImageNet.
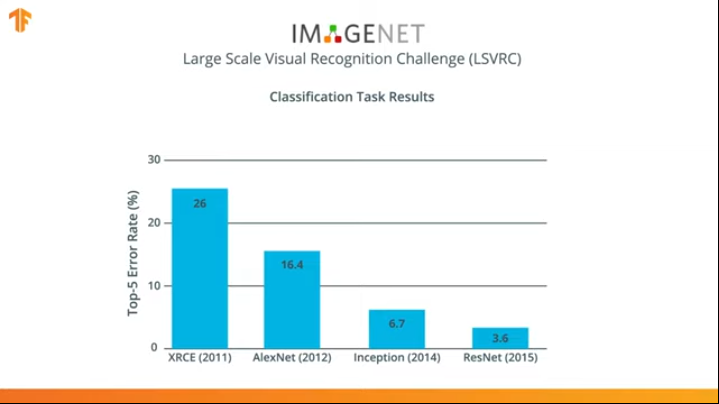
Depuis plusieurs années, des réseaux de neurones ont été développés pour mieux gérer la tâche de classification qu'AlexNet - Inception et ResNet.
Êtes-vous d'accord pour dire que ce serait formidable de pouvoir profiter de ces réseaux de neurones déjà formés sur d'énormes ensembles de données d'ImageNet et de les utiliser dans votre classificateur pour chats et chiens?
Il s'avère que nous pouvons le faire! La technique est appelée apprentissage par transfert. L'idée principale de la méthode de transfert du modèle d'apprentissage est basée sur le fait qu'ayant formé un réseau neuronal sur un grand ensemble de données, nous pouvons appliquer le modèle obtenu à un ensemble de données que ce modèle n'a pas encore rencontré. C'est pourquoi la technique est appelée transfert d'apprentissage - transfert du processus d'apprentissage d'un ensemble de données à un autre.
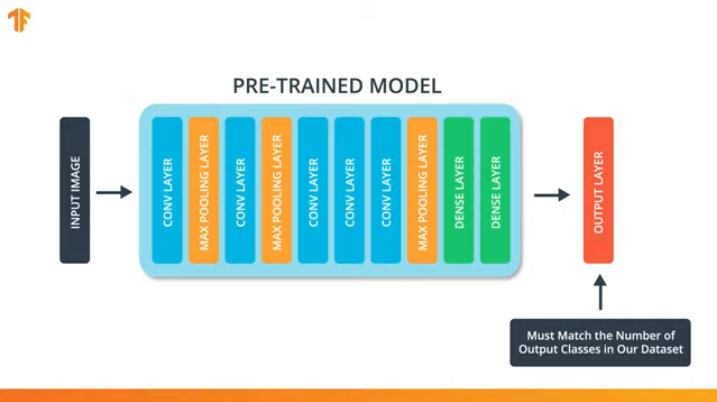
Afin d'appliquer la méthodologie de transfert du modèle d'apprentissage, nous devons changer la dernière couche de notre réseau neuronal convolutionnel:
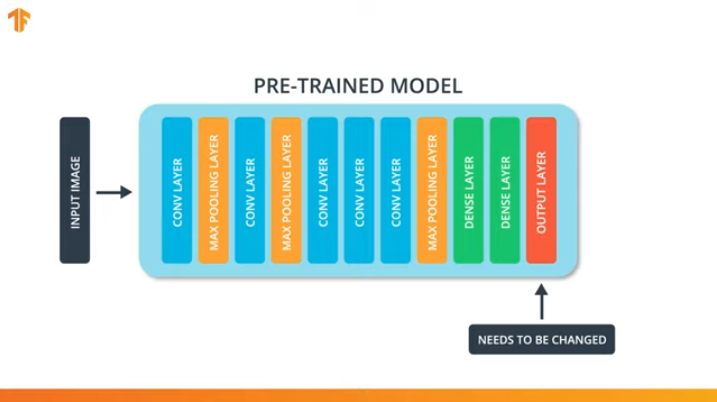
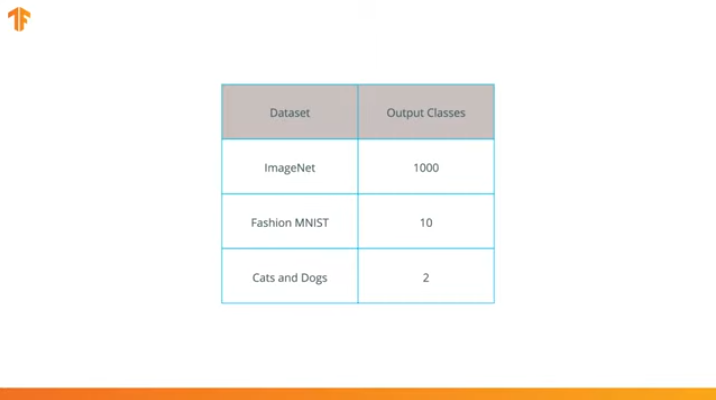
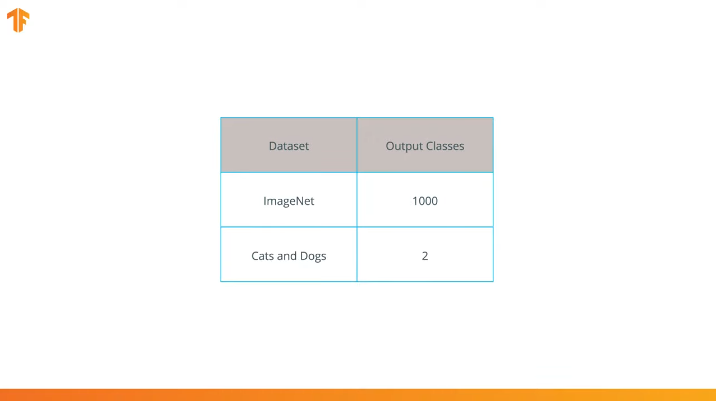
Nous effectuons cette opération car chaque ensemble de données se compose d'un nombre différent de classes de sortie. Par exemple, les ensembles de données dans ImageNet contiennent 1000 classes de sortie différentes. FashionMNIST contient 10 classes. Notre ensemble de données de classification se compose de seulement 2 classes - chats et chiens.
C'est pourquoi il est nécessaire de changer la dernière couche de notre réseau de neurones convolutionnels afin qu'elle contienne le nombre de sorties qui correspondrait au nombre de classes dans le nouvel ensemble.
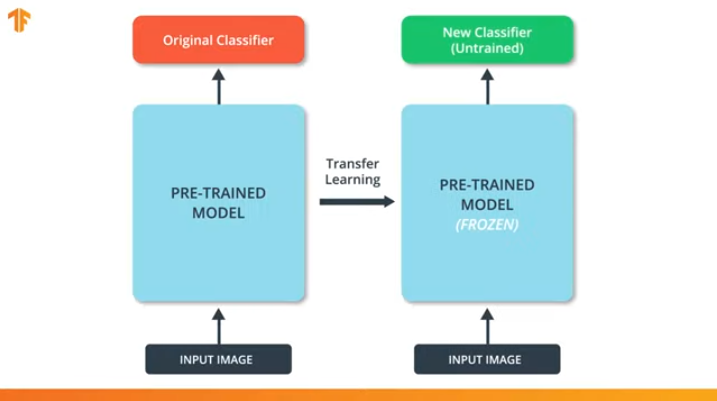
Nous devons également nous assurer de ne pas modifier le modèle pré-formé pendant le processus de formation. La solution consiste à désactiver les variables du modèle pré-formé - nous interdisons simplement à l'algorithme de mettre à jour les valeurs pendant la propagation avant et arrière pour les modifier.
Ce processus est appelé le «gel du modèle».
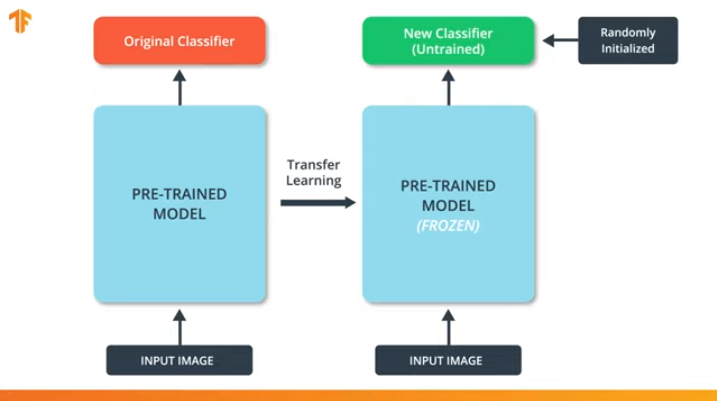
En «gelant» les paramètres du modèle pré-formé, nous permettons d'apprendre uniquement la dernière couche du réseau de classification, les valeurs des variables du pré-formé restent inchangées.
Un autre avantage incontestable des modèles pré-formés est que nous réduisons le temps de formation en formant uniquement la dernière couche avec un nombre de variables significativement plus petit, et non le modèle entier.
Si nous ne «gelons» pas les variables du modèle pré-formé, alors pendant le processus de formation, les valeurs des variables changeront sur le nouvel ensemble de données. En effet, les valeurs des variables de la dernière couche de la classification seront remplies de valeurs aléatoires. En raison de valeurs aléatoires sur la dernière couche, notre modèle fera de grosses erreurs dans la classification, ce qui entraînera à son tour de forts changements dans les poids initiaux du modèle pré-formé, ce qui est extrêmement indésirable pour nous.
C'est pour cette raison que nous devons toujours nous rappeler que lors de l'utilisation de modèles existants, les valeurs des variables doivent être «gelées» et la nécessité de former un modèle pré-formé doit être désactivée.
Maintenant que nous savons comment fonctionne le transfert du modèle de formation, il nous suffit de choisir un réseau neuronal pré-formé à utiliser dans notre propre classificateur! C'est ce que nous ferons dans la partie suivante.
MobileNet
Comme nous l'avons mentionné précédemment, des réseaux de neurones extrêmement efficaces ont été développés qui ont montré des résultats élevés sur les ensembles de données ImageNet - AlexNet, Inception, Resonant. Ces réseaux de neurones sont des réseaux très profonds et contiennent des milliers voire des millions de paramètres. Un grand nombre de paramètres permet au réseau d'apprendre des modèles plus complexes et ainsi d'obtenir une précision de classification accrue. Un grand nombre de paramètres d'apprentissage du réseau neuronal affecte la vitesse d'apprentissage, la quantité de mémoire requise pour stocker le réseau et la complexité des calculs.
Dans cette leçon, nous utiliserons le réseau neuronal convolutionnel moderne MobileNet. MobileNet est une architecture de réseau neuronal convolutif efficace qui réduit la quantité de mémoire utilisée pour le calcul tout en maintenant une grande précision des prédictions. C'est pourquoi MobileNet est idéal pour une utilisation sur des appareils mobiles avec une quantité limitée de mémoire et de ressources informatiques.
MobileNet a été développé par Google et formé sur l'ensemble de données ImageNet.
Étant donné que MobileNet a été formé dans 1 000 classes à partir de l'ensemble de données ImageNet, MobileNet a 1 000 classes de sortie, au lieu des deux dont nous avons besoin - un chat et un chien.
Pour terminer le transfert de la formation, nous préchargeons le vecteur d'entités sans couche de classification:

Dans Tensorflow, un vecteur d'entité chargé peut être utilisé comme une couche Keras régulière avec des données d'entrée d'une certaine taille.
Étant donné que MobileNet a été formé sur l'ensemble de données ImageNet, nous devrons apporter la taille des données d'entrée à celles qui ont été utilisées dans le processus de formation. Dans notre cas, MobileNet a été formé sur des images RVB de taille fixe 224x224px.
TensorFlow contient un référentiel pré-formé appelé TensorFlow Hub.
TensorFlow Hub contient des modèles pré-formés dans lesquels la dernière couche de classification a été exclue de l'architecture du réseau neuronal pour une réutilisation ultérieure.
Vous pouvez utiliser le TensorFlow Hub dans le code sur plusieurs lignes:

Il suffit de spécifier l'URL du vecteur d'entités du modèle d'apprentissage souhaité, puis d'intégrer le modèle dans notre classificateur avec la dernière couche avec le nombre de classes de sortie souhaité. C'est la dernière couche qui sera soumise à la formation et à la modification des valeurs des paramètres. La compilation et la formation de notre nouveau modèle s'effectuent de la même manière que précédemment:
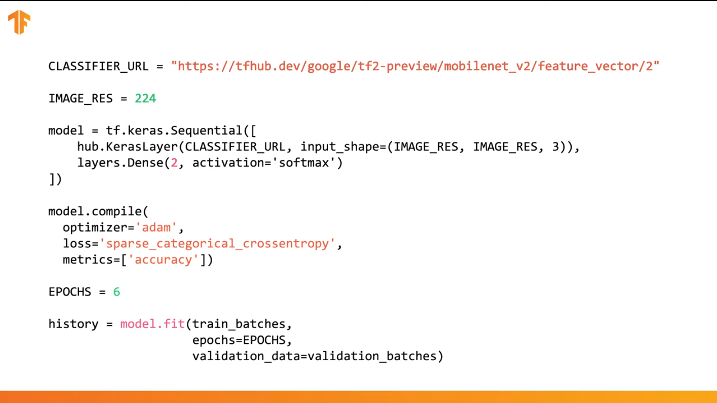
Voyons comment cela fonctionnera réellement et écrivons le code approprié.
CoLab: Cats Vs Dogs with Transfer Training
Lien vers CoLab en russe et CoLab en anglais .
TensorFlow Hub est un référentiel avec des modèles pré-formés que nous pouvons utiliser.
Le transfert d'apprentissage est un processus dans lequel nous prenons un modèle pré-formé et l'élargissons pour effectuer une tâche spécifique. Dans le même temps, nous laissons la partie du modèle pré-formé que nous intégrons dans le réseau neuronal intacte, mais ne formons que les dernières couches de sortie pour obtenir le résultat souhaité.
Dans cette partie pratique, nous allons tester les deux options.
Ce lien vous permet d'explorer la liste complète des modèles disponibles.
Dans cette partie de Colab
- Nous utiliserons le modèle TensorFlow Hub pour les prédictions;
- Nous utiliserons le modèle TensorFlow Hub pour l'ensemble de données des chats et des chiens;
- Transférons la formation en utilisant le modèle du TensorFlow Hub.
Avant de procéder à la mise en œuvre de la partie pratique actuelle, nous vous recommandons de réinitialiser le Runtime -> Reset all runtimes...
Importations de bibliothèque
Dans cette partie pratique, nous utiliserons un certain nombre de fonctionnalités de la bibliothèque TensorFlow qui ne sont pas encore dans la version officielle. C'est pourquoi nous allons d'abord installer les versions TensorFlow et TensorFlow Hub pour les développeurs.
L'installation de la version de développement de TensorFlow active automatiquement la dernière version installée. Après avoir fini de traiter cette partie pratique, nous vous recommandons de restaurer les paramètres TensorFlow et de revenir à la version stable via l'élément de menu Runtime -> Reset all runtimes... L'exécution de cette commande réinitialisera tous les paramètres d'environnement aux paramètres d'origine.
!pip install tf-nightly-gpu !pip install "tensorflow_hub==0.4.0" !pip install -U tensorflow_datasets
Conclusion:
Requirement already satisfied: absl-py>=0.7.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.8.0) Requirement already satisfied: protobuf>=3.6.1 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (3.7.1) Requirement already satisfied: google-pasta>=0.1.6 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.1.7) Collecting tf-estimator-nightly (from tf-nightly-gpu) Downloading https://files.pythonhosted.org/packages/ea/72/f092fc631ef2602fd0c296dcc4ef6ef638a6a773cb9fdc6757fecbfffd33/tf_estimator_nightly-1.14.0.dev2019092201-py2.py3-none-any.whl (450kB) |████████████████████████████████| 450kB 45.9MB/s Requirement already satisfied: numpy<2.0,>=1.16.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (1.16.5) Requirement already satisfied: wrapt>=1.11.1 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (1.11.2) Requirement already satisfied: astor>=0.6.0 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.8.0) Requirement already satisfied: opt-einsum>=2.3.2 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (3.0.1) Requirement already satisfied: wheel>=0.26 in /usr/local/lib/python3.6/dist-packages (from tf-nightly-gpu) (0.33.6) Requirement already satisfied: h5py in /usr/local/lib/python3.6/dist-packages (from keras-applications>=1.0.8->tf-nightly-gpu) (2.8.0) Requirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python3.6/dist-packages (from tb-nightly<1.16.0a0,>=1.15.0a0->tf-nightly-gpu) (3.1.1) Requirement already satisfied: setuptools>=41.0.0 in /usr/local/lib/python3.6/dist-packages (from tb-nightly<1.16.0a0,>=1.15.0a0->tf-nightly-gpu) (41.2.0) Requirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python3.6/dist-packages (from tb-nightly<1.16.0a0,>=1.15.0a0->tf-nightly-gpu) (0.15.6) Installing collected packages: tb-nightly, tf-estimator-nightly, tf-nightly-gpu Successfully installed tb-nightly-1.15.0a20190911 tf-estimator-nightly-1.14.0.dev2019092201 tf-nightly-gpu-1.15.0.dev20190821 Collecting tensorflow_hub==0.4.0 Downloading https://files.pythonhosted.org/packages/10/5c/6f3698513cf1cd730a5ea66aec665d213adf9de59b34f362f270e0bd126f/tensorflow_hub-0.4.0-py2.py3-none-any.whl (75kB) |████████████████████████████████| 81kB 5.0MB/s Requirement already satisfied: protobuf>=3.4.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_hub==0.4.0) (3.7.1) Requirement already satisfied: numpy>=1.12.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_hub==0.4.0) (1.16.5) Requirement already satisfied: six>=1.10.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_hub==0.4.0) (1.12.0) Requirement already satisfied: setuptools in /usr/local/lib/python3.6/dist-packages (from protobuf>=3.4.0->tensorflow_hub==0.4.0) (41.2.0) Installing collected packages: tensorflow-hub Found existing installation: tensorflow-hub 0.6.0 Uninstalling tensorflow-hub-0.6.0: Successfully uninstalled tensorflow-hub-0.6.0 Successfully installed tensorflow-hub-0.4.0 Collecting tensorflow_datasets Downloading https://files.pythonhosted.org/packages/6c/34/ff424223ed4331006aaa929efc8360b6459d427063dc59fc7b75d7e4bab3/tensorflow_datasets-1.2.0-py3-none-any.whl (2.3MB) |████████████████████████████████| 2.3MB 4.9MB/s Requirement already satisfied, skipping upgrade: future in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.16.0) Requirement already satisfied, skipping upgrade: wrapt in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.11.2) Requirement already satisfied, skipping upgrade: dill in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.3.0) Requirement already satisfied, skipping upgrade: numpy in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.16.5) Requirement already satisfied, skipping upgrade: requests>=2.19.0 in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (2.21.0) Requirement already satisfied, skipping upgrade: tqdm in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (4.28.1) Requirement already satisfied, skipping upgrade: protobuf>=3.6.1 in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (3.7.1) Requirement already satisfied, skipping upgrade: psutil in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (5.4.8) Requirement already satisfied, skipping upgrade: promise in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (2.2.1) Requirement already satisfied, skipping upgrade: absl-py in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.8.0) Requirement already satisfied, skipping upgrade: tensorflow-metadata in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (0.14.0) Requirement already satisfied, skipping upgrade: six in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.12.0) Requirement already satisfied, skipping upgrade: termcolor in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (1.1.0) Requirement already satisfied, skipping upgrade: attrs in /usr/local/lib/python3.6/dist-packages (from tensorflow_datasets) (19.1.0) Requirement already satisfied, skipping upgrade: idna<2.9,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (2.8) Requirement already satisfied, skipping upgrade: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (2019.6.16) Requirement already satisfied, skipping upgrade: chardet<3.1.0,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (3.0.4) Requirement already satisfied, skipping upgrade: urllib3<1.25,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests>=2.19.0->tensorflow_datasets) (1.24.3) Requirement already satisfied, skipping upgrade: setuptools in /usr/local/lib/python3.6/dist-packages (from protobuf>=3.6.1->tensorflow_datasets) (41.2.0) Requirement already satisfied, skipping upgrade: googleapis-common-protos in /usr/local/lib/python3.6/dist-packages (from tensorflow-metadata->tensorflow_datasets) (1.6.0) Installing collected packages: tensorflow-datasets Successfully installed tensorflow-datasets-1.2.0
Nous avons déjà vu et utilisé quelques importations auparavant. Du nouveau - import tensorflow_hub , que nous avons installé et que nous utiliserons dans cette partie pratique.
from __future__ import absolute_import, division, print_function, unicode_literals import matplotlib.pylab as plt import tensorflow as tf tf.enable_eager_execution() import tensorflow_hub as hub import tensorflow_datasets as tfds from tensorflow.keras import layers
Conclusion:
WARNING:tensorflow: TensorFlow's `tf-nightly` package will soon be updated to TensorFlow 2.0. Please upgrade your code to TensorFlow 2.0: * https://www.tensorflow.org/beta/guide/migration_guide Or install the latest stable TensorFlow 1.X release: * `pip install -U "tensorflow==1.*"` Otherwise your code may be broken by the change.
import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
Partie 1: utilisez TensorFlow Hub MobileNet pour les prévisions
Dans cette partie de CoLab, nous allons prendre un modèle pré-formé, le télécharger sur Keras et le tester.
Le modèle que nous utilisons est MobileNet v2 (au lieu de MobileNet, tout autre modèle de classificateur d'images compatible tf2 avec tfhub.dev peut être utilisé).
Télécharger le classificateur
Téléchargez le modèle MobileNet et créez-en un modèle Keras. MobileNet à l'entrée s'attend à recevoir une image de 224x224 pixels avec 3 canaux de couleur (RVB).
CLASSIFIER_URL = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/classification/2" IMAGE_RES = 224 model = tf.keras.Sequential([ hub.KerasLayer(CLASSIFIER_URL, input_shape=(IMAGE_RES, IMAGE_RES, 3)) ])
Exécutez le classificateur sur une seule image
MobileNet a été formé sur l'ensemble de données ImageNet. ImageNet contient 1000 classes de sortie et l'une de ces classes est un uniforme militaire. Trouvons l'image sur laquelle l'uniforme militaire sera situé et qui ne fera pas partie du kit de formation ImageNet pour vérifier la précision de la classification.
import numpy as np import PIL.Image as Image grace_hopper = tf.keras.utils.get_file('image.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg') grace_hopper = Image.open(grace_hopper).resize((IMAGE_RES, IMAGE_RES)) grace_hopper
Conclusion:
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/grace_hopper.jpg 65536/61306 [================================] - 0s 0us/step

grace_hopper = np.array(grace_hopper)/255.0 grace_hopper.shape
Conclusion:
(224, 224, 3)
Gardez à l'esprit que les modèles reçoivent toujours un ensemble (bloc) d'images à traiter en entrée. Dans le code ci-dessous, nous ajoutons une nouvelle dimension - la taille du bloc.
result = model.predict(grace_hopper[np.newaxis, ...]) result.shape
Conclusion:
(1, 1001)
Le résultat de la prédiction était un vecteur d'une taille de 1 001 éléments, où chaque valeur représente la probabilité que l'objet dans l'image appartient à une certaine classe.
La position de la valeur de probabilité maximale peut être trouvée en utilisant la fonction argmax . Cependant, il y a une question à laquelle nous n'avons toujours pas répondu - comment pouvons-nous déterminer à quelle classe un élément appartient avec une probabilité maximale?
predicted_class = np.argmax(result[0], axis=-1) predicted_class
Conclusion:
653
Déchiffrer les prédictions
Afin de déterminer la classe à laquelle se rapportent les prédictions, nous téléchargeons la liste des balises ImageNet et par l'indice avec une fidélité maximale, nous déterminons la classe à laquelle se rapporte la prédiction.
labels_path = tf.keras.utils.get_file('ImageNetLabels.txt','https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt') imagenet_labels = np.array(open(labels_path).read().splitlines()) plt.imshow(grace_hopper) plt.axis('off') predicted_class_name = imagenet_labels[predicted_class] _ = plt.title("Prediction: " + predicted_class_name.title())
Conclusion:
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/ImageNetLabels.txt 16384/10484 [==============================================] - 0s 0us/step

Bingo! Notre modèle a correctement identifié l'uniforme militaire.
Partie 2: utiliser le modèle TensorFlow Hub pour un jeu de données chat et chien
Nous allons maintenant utiliser la version complète du modèle MobileNet et voir comment il s'adaptera à l'ensemble de données des chats et des chiens.
Jeu de données
Nous pouvons utiliser les jeux de données TensorFlow pour télécharger un jeu de données pour chats et chiens.
splits = tfds.Split.ALL.subsplit(weighted=(80, 20)) splits, info = tfds.load('cats_vs_dogs', with_info=True, as_supervised=True, split = splits) (train_examples, validation_examples) = splits num_examples = info.splits['train'].num_examples num_classes = info.features['label'].num_classes
Conclusion:
Downloading and preparing dataset cats_vs_dogs (786.68 MiB) to /root/tensorflow_datasets/cats_vs_dogs/2.0.1... /usr/local/lib/python3.6/dist-packages/urllib3/connectionpool.py:847: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings InsecureRequestWarning) WARNING:absl:1738 images were corrupted and were skipped Dataset cats_vs_dogs downloaded and prepared to /root/tensorflow_datasets/cats_vs_dogs/2.0.1. Subsequent calls will reuse this data.
Toutes les images d'un jeu de données chat et chien n'ont pas la même taille.
for i, example_image in enumerate(train_examples.take(3)): print("Image {} shape: {}".format(i+1, example_image[0].shape))
Conclusion:
Image 1 shape: (500, 343, 3) Image 2 shape: (375, 500, 3) Image 3 shape: (375, 500, 3)
Par conséquent, les images de l'ensemble de données obtenu doivent être réduites à une seule taille, ce que le modèle MobileNet attend à l'entrée - 224 x 224.
La fonction .repeat() et steps_per_epoch ne sont pas nécessaires ici, mais elles vous permettent d'économiser environ 15 secondes par itération d'entraînement, car le tampon temporaire ne doit être initialisé qu'une seule fois au tout début du processus d'apprentissage.
def format_image(image, label): image = tf.image.resize(image, (IMAGE_RES, IMAGE_RES)) / 255.0 return image, label BATCH_SIZE = 32 train_batches = train_examples.shuffle(num_examples//4).map(format_image).batch(BATCH_SIZE).prefetch(1) validation_batches = validation_examples.map(format_image).batch(BATCH_SIZE).prefetch(1)
Exécutez le classificateur sur les ensembles d'images
Permettez-moi de vous rappeler qu'à ce stade, il existe toujours une version complète du réseau MobileNet pré-formé, qui contient 1 000 classes de sortie possibles. ImageNet contient un grand nombre d'images de chiens et de chats, essayons donc de saisir l'une des images de test de notre ensemble de données et de voir quelle prédiction le modèle nous donnera.
image_batch, label_batch = next(iter(train_batches.take(1))) image_batch = image_batch.numpy() label_batch = label_batch.numpy() result_batch = model.predict(image_batch) predicted_class_names = imagenet_labels[np.argmax(result_batch, axis=-1)] predicted_class_names
Conclusion:
array(['Persian cat', 'mink', 'Siamese cat', 'tabby', 'Bouvier des Flandres', 'dishwasher', 'Yorkshire terrier', 'tiger cat', 'tabby', 'Egyptian cat', 'Egyptian cat', 'tabby', 'dalmatian', 'Persian cat', 'Border collie', 'Newfoundland', 'tiger cat', 'Siamese cat', 'Persian cat', 'Egyptian cat', 'tabby', 'tiger cat', 'Labrador retriever', 'German shepherd', 'Eskimo dog', 'kelpie', 'mink', 'Norwegian elkhound', 'Labrador retriever', 'Egyptian cat', 'computer keyboard', 'boxer'], dtype='<U30')
Les étiquettes sont similaires aux noms des races de chats et de chiens. Voyons maintenant quelques images de notre jeu de données chats et chiens et plaçons une étiquette prédite sur chacun d'eux.
plt.figure(figsize=(10, 9)) for n in range(30): plt.subplot(6, 5, n+1) plt.subplots_adjust(hspace=0.3) plt.imshow(image_batch[n]) plt.title(predicted_class_names[n]) plt.axis('off') _ = plt.suptitle("ImageNet predictions")

Partie 3: implémenter le transfert d'apprentissage avec le concentrateur TensorFlow
Utilisons maintenant le TensorFlow Hub pour transférer l'apprentissage d'un modèle à un autre.
Dans le processus de transfert de la formation, nous réutilisons un modèle pré-formé en modifiant sa dernière couche, ou plusieurs couches, puis recommençons le processus de formation sur un nouvel ensemble de données.
Dans le TensorFlow Hub, vous pouvez trouver non seulement des modèles pré-formés complets (avec la dernière couche), mais aussi des modèles sans la dernière couche de classification. Ce dernier peut être facilement utilisé pour transférer la formation. Nous continuerons d'utiliser MobileNet v2 pour la simple raison que dans les parties suivantes de notre cours, nous transférerons ce modèle et le lancerons sur un appareil mobile à l'aide de TensorFlow Lite.
Nous continuerons également à utiliser l'ensemble de données sur les chats et les chiens, nous aurons donc la possibilité de comparer les performances de ce modèle avec celles que nous avons mises en œuvre à partir de zéro.
Notez que nous avons appelé le modèle partiel avec le TensorFlow Hub (sans la dernière couche de classification) feature_extractor . Ce nom s'explique par le fait que le modèle accepte les données en entrée et les transforme en un ensemble fini de propriétés (caractéristiques) sélectionnées. Ainsi, notre modèle a fait le travail d'identification du contenu de l'image, mais n'a pas produit la distribution de probabilité finale sur les classes de sortie. Le modèle a extrait un ensemble de propriétés de l'image.
URL = 'https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/2' feature_extractor = hub.KerasLayer(URL, input_shape=(IMAGE_RES, IMAGE_RES, 3))
Exécutons un ensemble d'images via feature_extractor et examinons le formulaire résultant (format de sortie). 32 - le nombre d'images, 1280 - le nombre de neurones dans la dernière couche du modèle pré-formé avec le TensorFlow Hub.
feature_batch = feature_extractor(image_batch) print(feature_batch.shape)
Conclusion:
(32, 1280)
Nous «figons» les variables dans la couche d'extraction des propriétés de sorte que seules les valeurs des variables de la couche de classification changent au cours du processus d'apprentissage.
feature_extractor.trainable = False
Ajouter une couche de classification
Enveloppez maintenant la couche du TensorFlow Hub dans le modèle tf.keras.Sequential et ajoutez une couche de classification.
model = tf.keras.Sequential([ feature_extractor, layers.Dense(2, activation='softmax') ]) model.summary()
Conclusion:
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer_1 (KerasLayer) (None, 1280) 2257984 _________________________________________________________________ dense (Dense) (None, 2) 2562 ================================================================= Total params: 2,260,546 Trainable params: 2,562 Non-trainable params: 2,257,984 _________________________________________________________________
Modèle de train
Maintenant, nous entraînons le modèle résultant comme nous le faisions avant d'appeler la compile suivi de l' fit pour la formation.
model.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'] ) EPOCHS = 6 history = model.fit(train_batches, epochs=EPOCHS, validation_data=validation_batches)
Conclusion:
Epoch 1/6 582/582 [==============================] - 77s 133ms/step - loss: 0.2381 - acc: 0.9346 - val_loss: 0.0000e+00 - val_acc: 0.0000e+00 Epoch 2/6 582/582 [==============================] - 70s 120ms/step - loss: 0.1827 - acc: 0.9618 - val_loss: 0.1629 - val_acc: 0.9670 Epoch 3/6 582/582 [==============================] - 69s 119ms/step - loss: 0.1733 - acc: 0.9660 - val_loss: 0.1623 - val_acc: 0.9666 Epoch 4/6 582/582 [==============================] - 69s 118ms/step - loss: 0.1677 - acc: 0.9676 - val_loss: 0.1627 - val_acc: 0.9677 Epoch 5/6 582/582 [==============================] - 68s 118ms/step - loss: 0.1636 - acc: 0.9689 - val_loss: 0.1634 - val_acc: 0.9675 Epoch 6/6 582/582 [==============================] - 69s 118ms/step - loss: 0.1604 - acc: 0.9701 - val_loss: 0.1643 - val_acc: 0.9668
Comme vous l'avez probablement remarqué, nous avons pu atteindre une précision d'environ 97% des prévisions sur l'ensemble de données de validation. Génial! L'approche actuelle a considérablement augmenté la précision de classification par rapport au premier modèle que nous avons nous-mêmes formé et a obtenu une précision de classification de ~ 87%. La raison en est que MobileNet a été conçu par des experts et soigneusement développé sur une longue période de temps, puis formé sur un ensemble de données ImageNet incroyablement grand.
Vous pouvez voir comment créer votre propre MobileNet dans Keras à ce lien .
Construisons des graphiques des changements dans les valeurs de précision et de perte sur les ensembles de données de formation et de validation.
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8, 8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label=' ') plt.plot(epochs_range, val_acc, label=' ') plt.legend(loc='lower right') plt.title(' ') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label=' ') plt.plot(epochs_range, val_loss, label=' ') plt.legend(loc='upper right') plt.title(' ') plt.show()
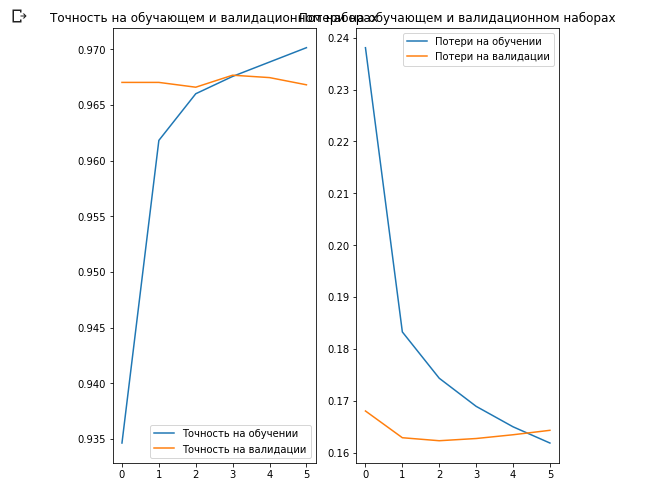
Ce qui est intéressant ici, c'est que les résultats sur l'ensemble de données de validation sont meilleurs que les résultats sur l'ensemble de données de formation du tout début à la fin du processus d'apprentissage.
L'une des raisons de ce comportement est que la précision de l'ensemble de données de validation est mesurée à la fin de l'itération d'apprentissage et que l'exactitude de l'ensemble de données d'apprentissage est considérée comme la valeur moyenne parmi toutes les itérations d'apprentissage.
La principale raison de ce comportement est l'utilisation du sous-réseau MobileNet pré-formé, qui était auparavant formé sur un grand ensemble de données de chats et de chiens. Dans le processus d'apprentissage, notre réseau continue d'élargir l'ensemble de données de formation d'entrée (la même augmentation), mais pas l'ensemble de validation. Cela signifie que les images générées sur l'ensemble de données d'apprentissage sont plus difficiles à classer que les images normales de l'ensemble de données validé.
Vérifier les résultats de prédiction
Pour répéter le graphique de la section précédente, vous devez d'abord obtenir une liste triée des noms de classe:
class_names = np.array(info.features['label'].names) class_names
Conclusion:
array(['cat', 'dog'], dtype='<U3')
Passez le bloc avec des images à travers le modèle et convertissez les index résultants en noms de classe:
predicted_batch = model.predict(image_batch) predicted_batch = tf.squeeze(predicted_batch).numpy() predicted_ids = np.argmax(predicted_batch, axis=-1) predicted_class_names = class_names[predicted_ids] predicted_class_names
Conclusion:
array(['cat', 'cat', 'cat', 'cat', 'dog', 'cat', 'dog', 'cat', 'cat', 'cat', 'cat', 'cat', 'dog', 'cat', 'cat', 'dog', 'cat', 'cat', 'cat', 'cat', 'cat', 'cat', 'dog', 'dog', 'dog', 'dog', 'cat', 'cat', 'dog', 'cat', 'cat', 'dog'], dtype='<U3')
Jetons un coup d'œil aux véritables étiquettes et prédit:
print(": ", label_batch) print(": ", predicted_ids)
Conclusion:
: [0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 1 1 1 0 1 1 0 0 1] : [0 0 0 0 1 0 1 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 1 1 1 1 0 0 1 0 0 1]
plt.figure(figsize=(10, 9)) for n in range(30): plt.subplot(6, 5, n+1) plt.subplots_adjust(hspace=0.3) plt.imshow(image_batch[n]) color = "blue" if predicted_ids[n] == label_batch[n] else "red" plt.title(predicted_class_names[n].title(), color=color) plt.axis('off') _ = plt.suptitle(" (: , : )")

Plonger dans des réseaux de neurones convolutifs
À l'aide de réseaux de neurones convolutifs, nous avons réussi à nous assurer qu'ils répondent bien à la tâche de classification des images. Cependant, pour le moment, nous pouvons à peine imaginer comment ils fonctionnent vraiment. Si nous pouvions comprendre comment se déroule le processus d'apprentissage, alors, en principe, nous pourrions encore améliorer le travail de classification. Une façon de comprendre le fonctionnement des réseaux de neurones convolutifs est de visualiser les couches et les résultats de leur travail. Nous vous recommandons fortement d'étudier les matériaux ici pour mieux comprendre comment visualiser les résultats des couches convolutives.

Le champ de la vision par ordinateur a vu le jour au bout du tunnel et a fait des progrès significatifs depuis l'avènement des réseaux de neurones convolutifs. La vitesse incroyable avec laquelle les recherches sont menées dans ce domaine et les énormes matrices d'images publiées sur Internet ont donné des résultats incroyables au cours des dernières années. La montée en puissance des réseaux de neurones convolutifs a commencé avec AlexNet en 2012, créé par Alex Krizhevsky, Ilya Sutskever et Jeffrey Hinton et a remporté le célèbre défi de reconnaissance visuelle à grande échelle ImageNet. Depuis lors, il n'y avait aucun doute dans un avenir brillant en utilisant des réseaux de neurones convolutifs, et le domaine de la vision par ordinateur et les résultats de son travail ne faisaient que confirmer ce fait. Commençant par reconnaître votre visage sur un téléphone mobile et se terminant par la reconnaissance d'objets dans des voitures autonomes, les réseaux de neurones convolutionnels ont déjà réussi à montrer et à prouver leur force et à résoudre de nombreux problèmes du monde réel.
Malgré le grand nombre d'ensembles de données volumineux et de modèles pré-formés de réseaux de neurones convolutionnels, il est parfois extrêmement difficile de comprendre comment le réseau fonctionne et à quoi exactement ce réseau est formé, en particulier pour les personnes qui n'ont pas suffisamment de connaissances dans le domaine de l'apprentissage automatique. , , , Inception, . . , , , , .
" Python"
François Chollet. , . Keras, , " " TensorFlow, MXNET Theano. , , . , .
, , .
(training accuracy) . , , , , Inception, .
, , . Inception v3 ( ImageNet) , Kaggle. Inception, , Inception v3 .
10 () 32 , 2292293. 0.3195, — 0.6377. ImageDataGenerator , . GitHub .
, "" , . .
, Inception v3 , .

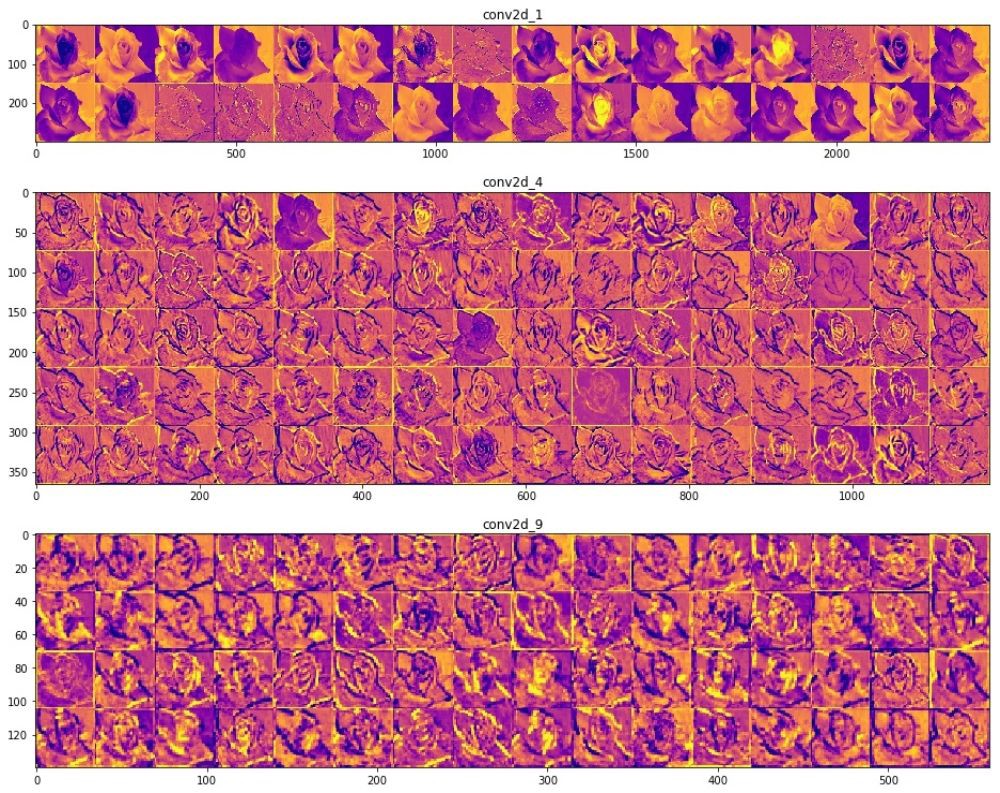
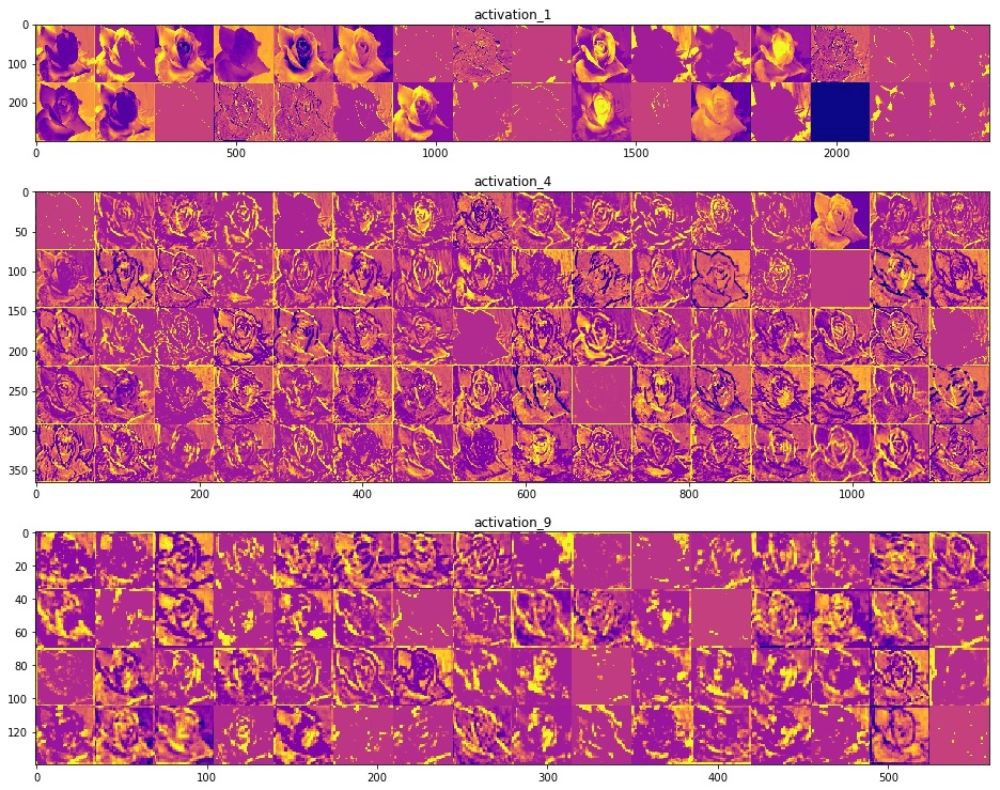
— . .
, () . (), , , , . , , , , .
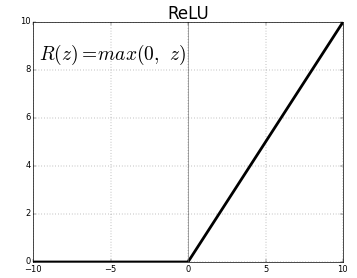
ReLU- . , ReLU(z) = max(0, z) .
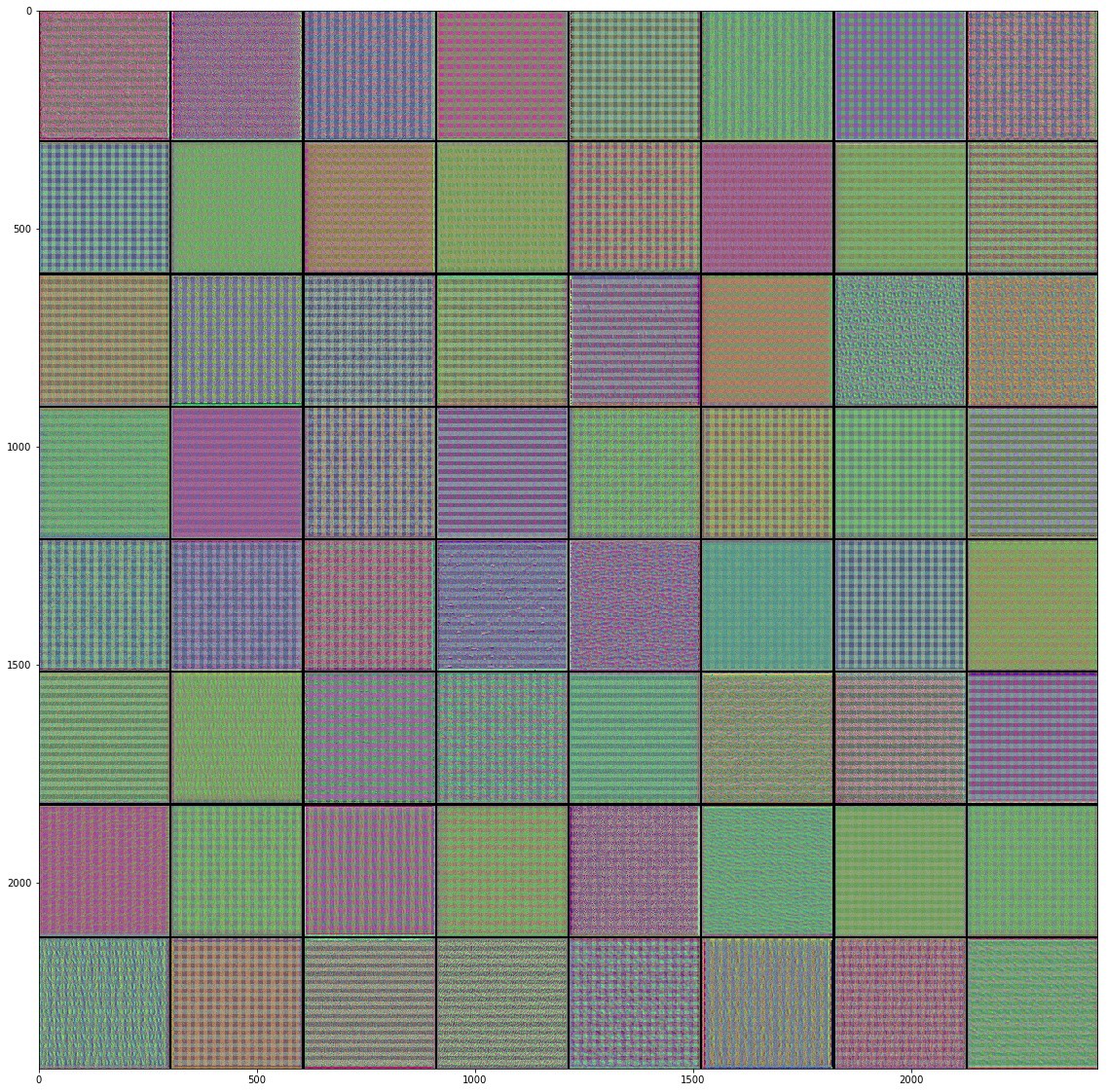
, , , , , , , , .. , . "" () , , , .
"" . .
, Inveption V3 :
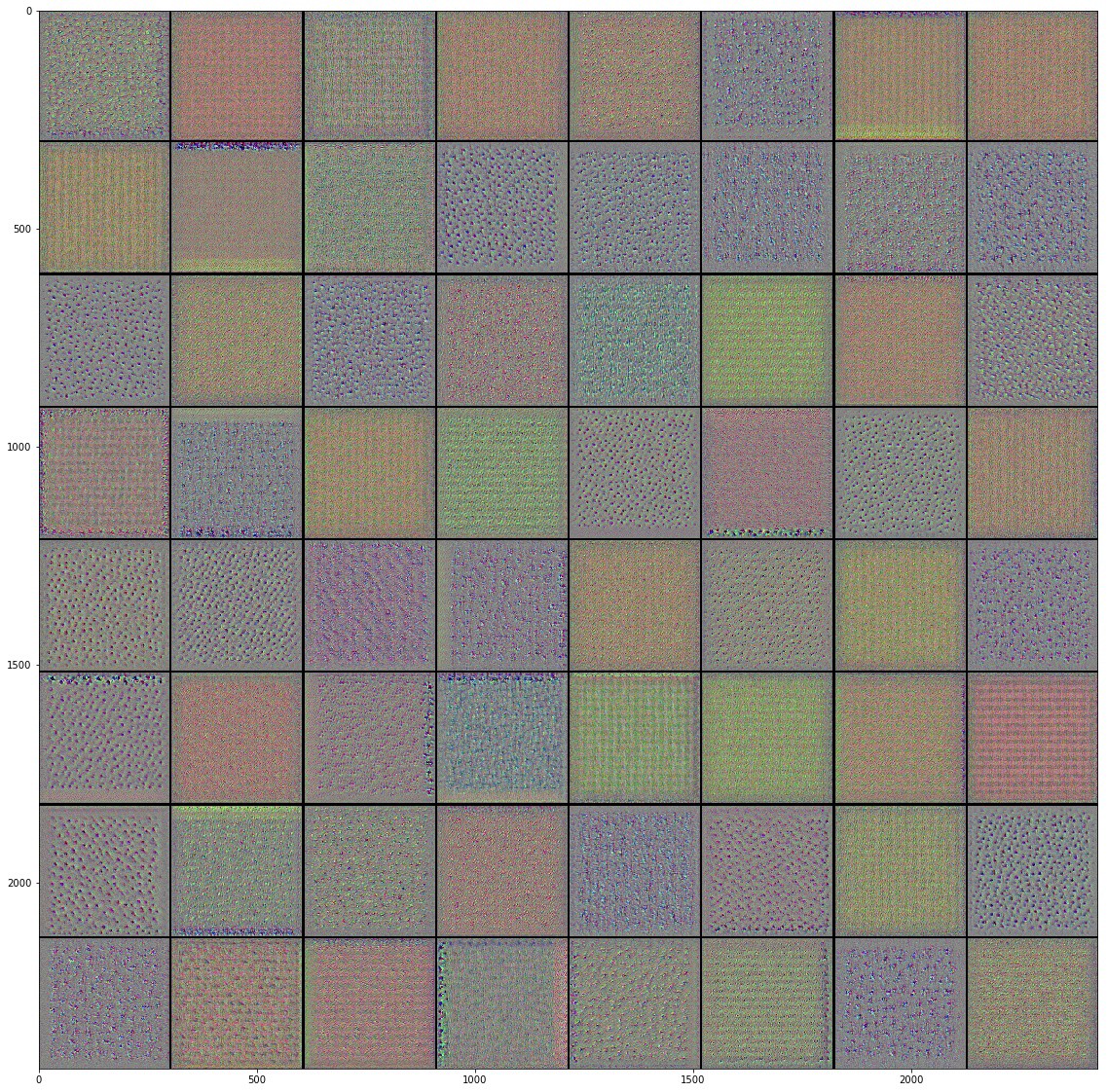

, . , , , , .. , , . , , , "" ( , ).
, , , . , .
Class Activation Map ( ). CAM . 2D , .
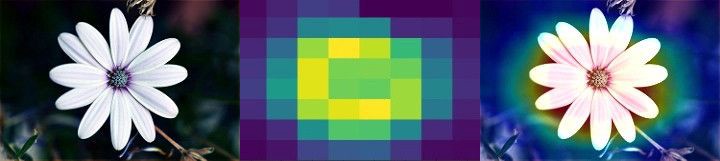

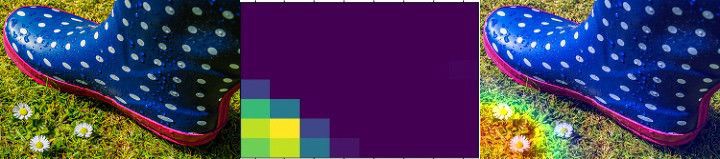
, . , , Mixed- Inception V3-, . () , .
, , . , , . , . , , , , .
, "" - . . .
, , .
:
Colab Colab .
TensorFlow Hub
TensorFlow Hub , .
. , , , .
.
Runtime -> Reset all runtimes...
, :
from __future__ import absolute_import, division, print_function, unicode_literals import numpy as np import matplotlib.pyplot as plt import tensorflow as tf tf.enable_eager_execution() import tensorflow_hub as hub import tensorflow_datasets as tfds from tensorflow.keras import layers
:
WARNING:tensorflow: The TensorFlow contrib module will not be included in TensorFlow 2.0. For more information, please see: * https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md * https://github.com/tensorflow/addons * https://github.com/tensorflow/io (for I/O related ops) If you depend on functionality not listed there, please file an issue.
import logging logger = tf.get_logger() logger.setLevel(logging.ERROR)
TensorFlow Datasets
TensorFlow Datasets. , — tf_flowers . , . tfds.splits (70%) (30%). tfds.load . tfds.load , , .
splits = tfds.Split.TRAIN.subsplit([70, 30]) (training_set, validation_set), dataset_info = tfds.load('tf_flowers', with_info=True, as_supervised=True, split=splits)
:
Downloading and preparing dataset tf_flowers (218.21 MiB) to /root/tensorflow_datasets/tf_flowers/1.0.0... Dl Completed... 1/|/100% 1/1 [00:07<00:00, 3.67s/ url] Dl Size... 218/|/100% 218/218 [00:07<00:00, 30.69 MiB/s] Extraction completed... 1/|/100% 1/1 [00:07<00:00, 7.05s/ file] Dataset tf_flowers downloaded and prepared to /root/tensorflow_datasets/tf_flowers/1.0.0. Subsequent calls will reuse this data.
, , () , , — .
num_classes = dataset_info.features['label'].num_classes num_training_examples = 0 num_validation_examples = 0 for example in training_set: num_training_examples += 1 for example in validation_set: num_validation_examples += 1 print('Total Number of Classes: {}'.format(num_classes)) print('Total Number of Training Images: {}'.format(num_training_examples)) print('Total Number of Validation Images: {} \n'.format(num_validation_examples))
:
Total Number of Classes: 5 Total Number of Training Images: 2590 Total Number of Validation Images: 1080
— .
for i, example in enumerate(training_set.take(5)): print('Image {} shape: {} label: {}'.format(i+1, example[0].shape, example[1]))
:
Image 1 shape: (226, 240, 3) label: 0 Image 2 shape: (240, 145, 3) label: 2 Image 3 shape: (331, 500, 3) label: 2 Image 4 shape: (240, 320, 3) label: 0 Image 5 shape: (333, 500, 3) label: 1
— , MobilNet v2 — 224224 (grayscale). image () label () .
IMAGE_RES = 224 def format_image(image, label): image = tf.image.resize(image, (IMAGE_RES, IMAGE_RES))/255.0 return image, label BATCH_SIZE = 32 train_batches = training_set.shuffle(num_training_examples//4).map(format_image).batch(BATCH_SIZE).prefetch(1) validation_batches = validation_set.map(format_image).batch(BATCH_SIZE).prefetch(1)
TensorFlow Hub
TensorFlow Hub . , , .
feature_extractor MobileNet v2. , TensorFlow Hub ( ) . . tf2-preview/mobilenet_v2/feature_vector , URL MobileNet v2 . feature_extractor hub.KerasLayer input_shape .
URL = "https://tfhub.dev/google/tf2-preview/mobilenet_v2/feature_vector/4" feature_extractor = hub.KerasLayer(URL, input_shape=(IMAGE_RES, IMAGE_RES, 3))
, :
feature_extractor.trainable = False
, . . .
model = tf.keras.Sequential([ feature_extractor, layers.Dense(num_classes, activation='softmax') ]) model.summary()
:
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer (KerasLayer) (None, 1280) 2257984 _________________________________________________________________ dense (Dense) (None, 5) 6405 ================================================================= Total params: 2,264,389 Trainable params: 6,405 Non-trainable params: 2,257,984
, .
model.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) EPOCHS = 6 history = model.fit(train_batches, epochs=EPOCHS, validation_data=validation_batches)
:
Epoch 1/6 81/81 [==============================] - 17s 216ms/step - loss: 0.7765 - acc: 0.7170 - val_loss: 0.0000e+00 - val_acc: 0.0000e+00 Epoch 2/6 81/81 [==============================] - 12s 147ms/step - loss: 0.3806 - acc: 0.8757 - val_loss: 0.3485 - val_acc: 0.8833 Epoch 3/6 81/81 [==============================] - 12s 146ms/step - loss: 0.3011 - acc: 0.9031 - val_loss: 0.3190 - val_acc: 0.8907 Epoch 4/6 81/81 [==============================] - 12s 147ms/step - loss: 0.2527 - acc: 0.9205 - val_loss: 0.3031 - val_acc: 0.8917 Epoch 5/6 81/81 [==============================] - 12s 148ms/step - loss: 0.2177 - acc: 0.9371 - val_loss: 0.2933 - val_acc: 0.8972 Epoch 6/6 81/81 [==============================] - 12s 146ms/step - loss: 0.1905 - acc: 0.9456 - val_loss: 0.2870 - val_acc: 0.9000
~90% 6 , ! , , ~76% 80 . , MobilNet v2 .
.
acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs_range = range(EPOCHS) plt.figure(figsize=(8, 8)) plt.subplot(1, 2, 1) plt.plot(epochs_range, acc, label='Training Accuracy') plt.plot(epochs_range, val_acc, label='Validation Accuracy') plt.legend(loc='lower right') plt.title('Training and Validation Accuracy') plt.subplot(1, 2, 2) plt.plot(epochs_range, loss, label='Training Loss') plt.plot(epochs_range, val_loss, label='Validation Loss') plt.legend(loc='upper right') plt.title('Training and Validation Loss') plt.show()
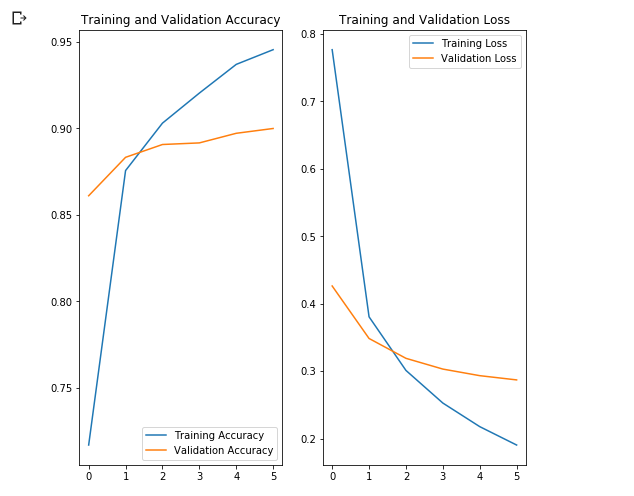
, , .
, , .
- MobileNet, . ( augmentation), . .
NumPy. , .
class_names = np.array(dataset_info.features['label'].names) print(class_names)
:
['dandelion' 'daisy' 'tulips' 'sunflowers' 'roses']
next() image_batch ( ) label_batch ( ). image_batch label_batch NumPy .numpy() . .predict() . np.argmax() . .
image_batch, label_batch = next(iter(train_batches)) image_batch = image_batch.numpy() label_batch = label_batch.numpy() predicted_batch = model.predict(image_batch) predicted_batch = tf.squeeze(predicted_batch).numpy() predicted_ids = np.argmax(predicted_batch, axis=-1) predicted_class_names = class_names[predicted_ids] print(predicted_class_names)
:
['sunflowers' 'roses' 'tulips' 'tulips' 'daisy' 'dandelion' 'tulips' 'sunflowers' 'daisy' 'daisy' 'tulips' 'daisy' 'daisy' 'tulips' 'tulips' 'tulips' 'dandelion' 'dandelion' 'tulips' 'tulips' 'dandelion' 'roses' 'daisy' 'daisy' 'dandelion' 'roses' 'daisy' 'tulips' 'dandelion' 'dandelion' 'roses' 'dandelion']
print("Labels: ", label_batch) print("Predicted labels: ", predicted_ids)
:
Labels: [3 4 2 2 1 0 2 3 1 1 2 1 1 2 2 2 0 0 2 2 0 4 1 1 0 4 1 2 0 0 4 0] Predicted labels: [3 4 2 2 1 0 2 3 1 1 2 1 1 2 2 2 0 0 2 2 0 4 1 1 0 4 1 2 0 0 4 0]
plt.figure(figsize=(10,9)) for n in range(30): plt.subplot(6,5,n+1) plt.subplots_adjust(hspace = 0.3) plt.imshow(image_batch[n]) color = "blue" if predicted_ids[n] == label_batch[n] else "red" plt.title(predicted_class_names[n].title(), color=color) plt.axis('off') _ = plt.suptitle("Model predictions (blue: correct, red: incorrect)")

Inception-
TensorFlow Hub tf2-preview/inception_v3/feature_vector . Inception V3 . , Inception V3 . , Inception V3 299299 . Inception V3 MobileNet V2.
IMAGE_RES = 299 (training_set, validation_set), dataset_info = tfds.load('tf_flowers', with_info=True, as_supervised=True, split=splits) train_batches = training_set.shuffle(num_training_examples//4).map(format_image).batch(BATCH_SIZE).prefetch(1) validation_batches = validation_set.map(format_image).batch(BATCH_SIZE).prefetch(1) URL = "https://tfhub.dev/google/tf2-preview/inception_v3/feature_vector/4" feature_extractor = hub.KerasLayer(URL, input_shape=(IMAGE_RES, IMAGE_RES, 3), trainable=False) model_inception = tf.keras.Sequential([ feature_extractor, tf.keras.layers.Dense(num_classes, activation='softmax') ]) model_inception.summary()
:
Model: "sequential_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= keras_layer_1 (KerasLayer) (None, 2048) 21802784 _________________________________________________________________ dense_1 (Dense) (None, 5) 10245 ================================================================= Total params: 21,813,029 Trainable params: 10,245 Non-trainable params: 21,802,784
model_inception.compile( optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) EPOCHS = 6 history = model_inception.fit(train_batches, epochs=EPOCHS, validation_data=validation_batches)
:
Epoch 1/6 81/81 [==============================] - 44s 541ms/step - loss: 0.7594 - acc: 0.7309 - val_loss: 0.0000e+00 - val_acc: 0.0000e+00 Epoch 2/6 81/81 [==============================] - 35s 434ms/step - loss: 0.3927 - acc: 0.8772 - val_loss: 0.3945 - val_acc: 0.8657 Epoch 3/6 81/81 [==============================] - 35s 434ms/step - loss: 0.3074 - acc: 0.9120 - val_loss: 0.3586 - val_acc: 0.8769 Epoch 4/6 81/81 [==============================] - 35s 434ms/step - loss: 0.2588 - acc: 0.9282 - val_loss: 0.3385 - val_acc: 0.8796 Epoch 5/6 81/81 [==============================] - 35s 436ms/step - loss: 0.2252 - acc: 0.9375 - val_loss: 0.3256 - val_acc: 0.8824 Epoch 6/6 81/81 [==============================] - 35s 435ms/step - loss: 0.1996 - acc: 0.9440 - val_loss: 0.3164 - val_acc: 0.8861
Résumé
. :
- : , . .
- : . "" , , .
- MobileNet: Google, . MobileNet .
MobileNet . . MobileNet .
… call-to-action — , share :)
YouTube
Télégramme
VKontakte
Ojok .