Bonjour à tous!
J'ai déjà parlé dans ce blog de l' organisation d'un système de surveillance modulaire pour l'architecture de microservices et de la transition de Graphite + Whisper à Graphite + ClickHouse pour stocker des métriques sous des charges élevées. Après cela, mon collègue Sergey Noskov a écrit sur le tout premier lien de notre système de surveillance - le Bioyino développé par nous, un agrégateur de métriques évolutives distribuées.
Le moment est venu de rafraîchir les informations sur la façon dont nous préparons la surveillance dans Avito - notre dernier article était déjà de retour en 2018, et pendant ce temps, il y a eu plusieurs changements intéressants dans l'architecture de surveillance, la gestion des déclencheurs et des notifications, diverses optimisations de données dans ClickHouse et d'autres innovations, dont je veux juste vous parler.

Mais commençons dans l'ordre.
En 2017, j'ai montré un diagramme de l'interaction des composants qui était pertinent à ce moment-là, et je voudrais le démontrer à nouveau afin que vous n'ayez pas à changer d'onglet à nouveau.

À partir de ce moment, les événements suivants se sont produits.
Le nombre de serveurs dans le cluster Graphite est passé de 3 à 6.
( 56 CPU 2.60GHz, 384GB RAM, 10 SSD SAS 745GB, Raid 6, 10GBit/s Net ).
Nous avons remplacé brubeck par bioyino - notre propre implémentation de StatsD avec Rust, et avons même écrit un article entier à ce sujet . Cependant, après la publication de l'article, nous avons mis en place un support pour les tags (Graphite) et Raft pour sélectionner un leader.
Nous avons étudié la possibilité d'utiliser le bioyino comme agent StatsD et placé ces agents à côté des instances de monolithes, ainsi que là où ils étaient nécessaires dans les k8.
Nous nous sommes finalement débarrassés de l'ancien système de surveillance de Munin (formellement, nous l'avons toujours, mais ses données ne sont plus utilisées).
La collecte de données à partir des clusters Kubernetes a été organisée via Prometheus / Federations, car Heapster n'était pas pris en charge dans les nouvelles versions de Kubernetes.
Suivi
Au cours des deux dernières années, le nombre de mesures acceptées et traitées a augmenté d'environ 9 fois.
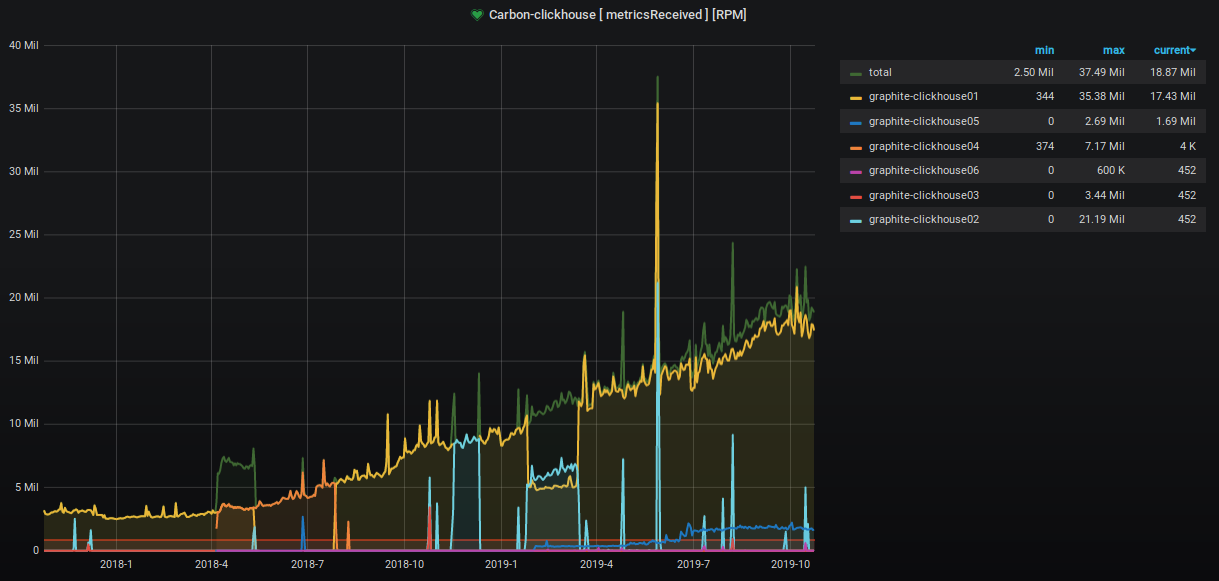
Le pourcentage d'espace serveur occupé augmente également inexorablement, et nous prenons diverses mesures pour le réduire. Ceci est clairement visible sur le graphique.
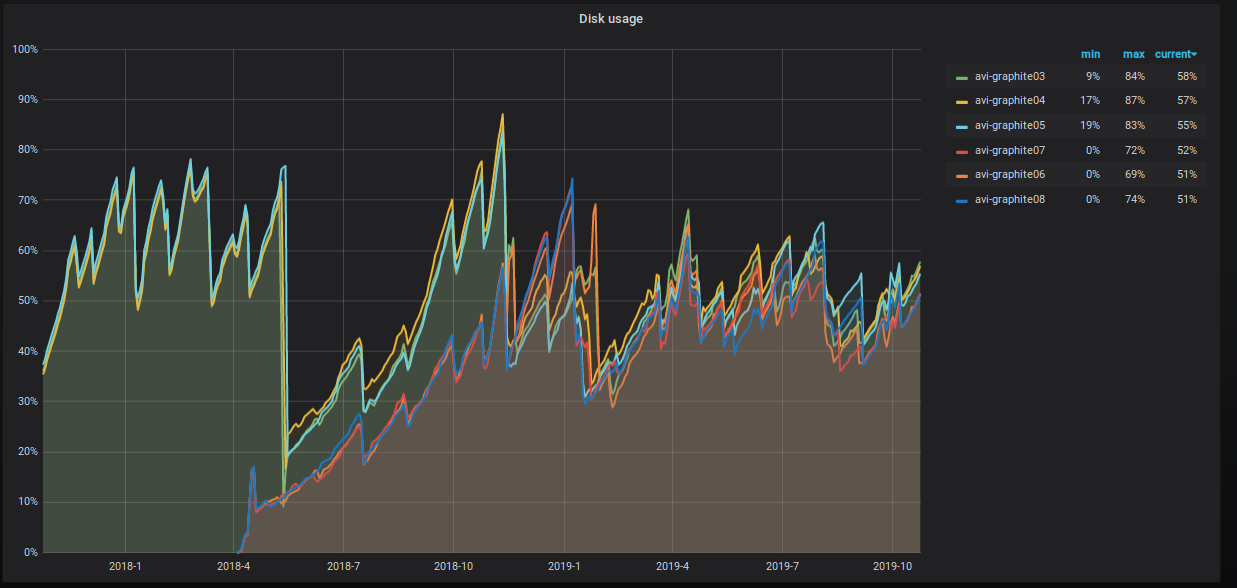
Que faisons-nous exactement?
10 10 10 * * clickhouse-client -q "select distinct partition from system.parts where active=1 and database='graphite' and table='data' and max_date between today()-55 AND today()-35;" | while read PART; do clickhouse-client -u systemXXX --password XXXXXXX -q "OPTIMIZE TABLE graphite.data PARTITION ('"$PART"') FINAL";done
- Nous avons partagé des tableaux de données. Nous avons maintenant trois fragments avec deux répliques chacun avec une clé de partitionnement de hachage au nom de la métrique. Cette approche nous donne la possibilité d'effectuer des procédures de cumul , car toutes les valeurs d'une métrique spécifique se trouvent dans le même fragment et l'espace disque sur tous les fragments est utilisé de manière uniforme.
Le schéma de table distribué est le suivant.
CREATE TABLE graphite.data_all ( `Path` String, `Value` Float64, `Time` UInt32, `Date` Date, `Timestamp` UInt32 ) ENGINE = Distributed ( 'graphite_cluster', 'graphite', 'data', jumpConsistentHash(cityHash64(Path), 3) )
Nous avons également attribué à l'utilisateur des droits en lecture seule par défaut et jeté l'exécution des procédures d'écriture sur les tables vers un système utilisateur distinct systemXXX .
La configuration du cluster Graphite dans ClickHouse est la suivante.
<remote_servers> <graphite_cluster> <shard> <internal_replication>true</internal_replication> <replica> <host>graphite-clickhouse01</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> <replica> <host>graphite-clickhouse04</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>graphite-clickhouse02</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> <replica> <host>graphite-clickhouse05</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>graphite-clickhouse03</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> <replica> <host>graphite-clickhouse06</host> <port>9000</port> <user>systemXXX</user> <password>XXXXXX</password> </replica> </shard> </graphite_cluster> </remote_servers>
En plus de la charge d'écriture, le nombre de demandes de lecture de données depuis Graphite a augmenté. Ces données sont utilisées pour:
- déclencher le traitement et la génération des alertes;
- afficher des graphiques sur les moniteurs du bureau et les écrans d'ordinateur portable et de PC d'un nombre croissant d'employés de l'entreprise.
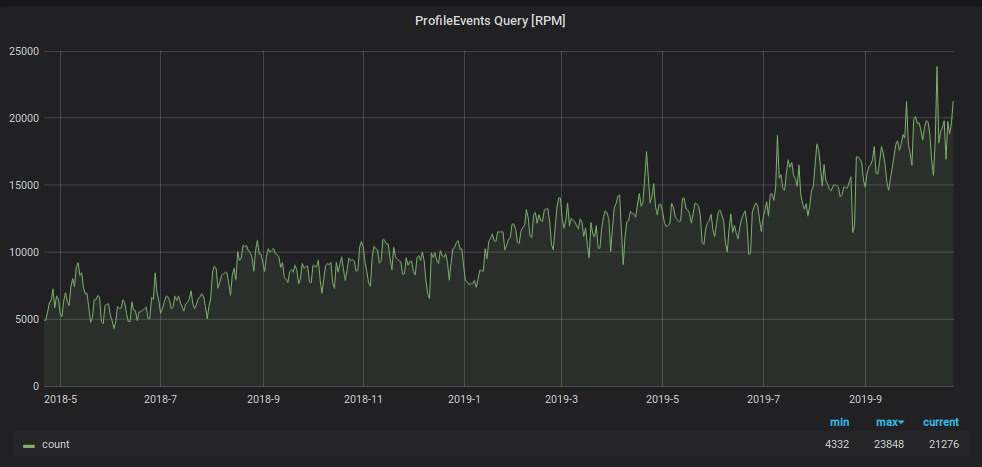
Pour éviter que la surveillance ne se noie sous cette charge, nous avons utilisé un autre hack: nous stockons les données des deux derniers jours dans une «petite» plaque séparée, et nous y envoyons toutes les demandes de lecture des deux derniers jours, ce qui réduit la charge sur la table principale des fragments. De plus, pour cette «petite» tablette, nous avons utilisé un schéma de stockage métrique inverse, qui a considérablement accéléré la recherche des données qu'il contient et organisé une partition quotidienne pour celui-ci. Le schéma de cette plaque est le suivant.
CREATE TABLE graphite.data_reverse ( `Path` String, `Value` Float64, `Time` UInt32 CODEC(Delta(4), ZSTD(1)), `Date` Date, `Timestamp` UInt32 ) ENGINE = ReplicatedGraphiteMergeTree ( '/clickhouse/tables/{cluster}/data_reverse', '{replica}', 'graphite_rollup' ) PARTITION BY Date ORDER BY (Path, Time) SETTINGS index_granularity = 4096
Pour y diriger les données, nous avons ajouté une nouvelle section au fichier de configuration de l'application carbon-clickhouse .
[upload.graphite_reverse] type = "points-reverse" table = "graphite.data_reverse" threads = 2 url = "http://systemXXX:XXXXXXX@localhost:8123/" timeout = "60s" cache-ttl = "6h0m0s" zero-timestamp = true
Pour supprimer des partitions de plus de deux jours, nous avons écrit une tâche cron. Cela ressemble à ceci.
1 12 * * * clickhouse-client -q "select distinct partition from system.parts where active=1 and database='graphite' and table='data_reverse' and max_date<today()-2;" | while read PART; do clickhouse-client -u systemXXX --password XXXXXXX -q "ALTER TABLE graphite.data_reverse DROP PARTITION ('"$PART"')";done
Pour lire les données du tableau, dans le fichier de configuration graphite-clickhouse , une section a été ajoutée:
[[data-table]] table = "graphite.data_reverse" max-age = "48h" reverse = true
En conséquence, nous avons une table avec 100% des données répliquées sur les six serveurs qui traitent l'intégralité de la charge de lecture des demandes avec une fenêtre de moins de deux jours (et nous en avons 95%). Et nous avons également un tableau fragmenté avec 1/3 des données sur chaque fragment, qui permet la lecture de toutes les données historiques. Et même si ces demandes sont beaucoup plus petites, leur charge est beaucoup plus élevée.
Que se passe-t-il avec le CPU?! En raison de l'augmentation du volume des données enregistrées et lues dans le cluster Graphite, la charge totale du processeur sur les serveurs a également augmenté. Cela ressemble à ceci.
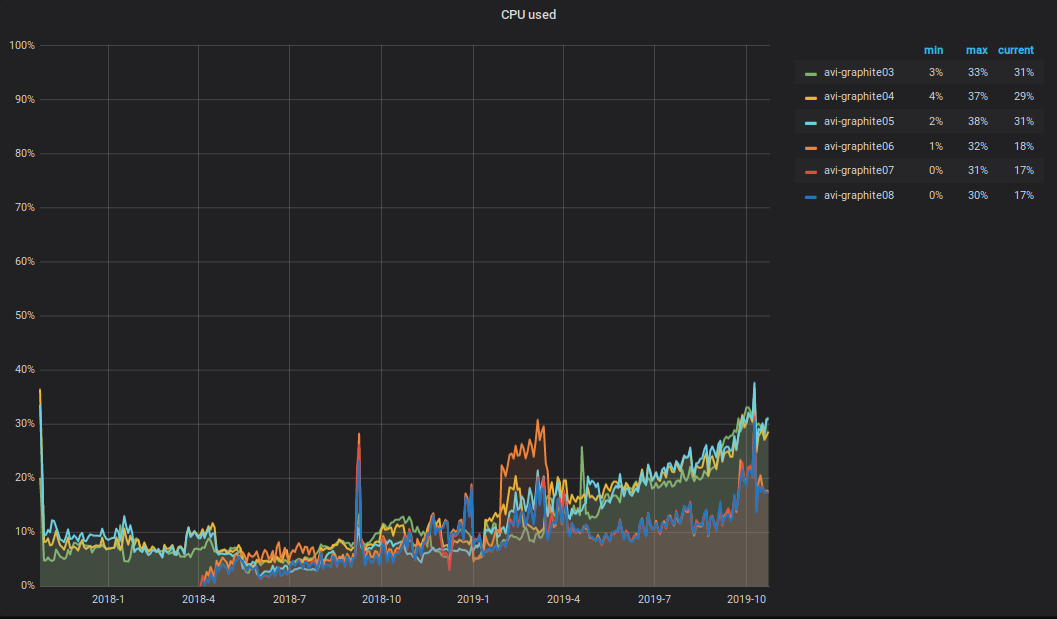
Je voudrais attirer l'attention sur la nuance suivante: la moitié du processeur est consacrée à l'analyse et au traitement principal des métriques dans le relais carbone-c (v3.2 du 2018-09-05, qui est responsable du transport des métriques), qui se trouve sur trois serveurs sur six. Comme vous pouvez le voir sur le graphique, ce sont ces trois serveurs qui sont dans le TOP.
Alerte
En tant que système d'alerte, Moira et le client moira sont toujours écrits pour cela. Pour une gestion flexible des déclencheurs, des notifications et des escalades, nous utilisons une description déclarative appelée alert.yaml. Il est généré automatiquement lorsqu'un service est créé via PaaS (vous trouverez plus d'informations à ce sujet dans l'article de Vadim Madison «Ce que nous savons sur les microservices» ) et est placé dans son référentiel. Pour travailler avec alert.yaml, nous avons créé une liaison sur moira-client et l'avons appelé alert-autoconf (nous prévoyons de l'ouvrir). Il y a une étape dans l'assemblage du service dans TeamCity avec l'exportation des déclencheurs et des notifications vers Moira via alert-autoconf. Lors de la validation des modifications dans alert.yaml, des tests automatiques sont exécutés qui vérifient la validité du fichier yaml et font également des demandes à Graphite pour chaque modèle de mesure afin de vérifier leur exactitude.
Pour les équipes d'infrastructure n'utilisant pas PaaS, nous avons organisé un référentiel distinct appelé Alerting. Il a fait la structure du formulaire: Team / Project / alert.yaml. Pour chaque alert.yaml, nous générons un assembly séparé dans TeamCity, qui exécute des tests et envoie le contenu de alert.yaml dans Moira.
Ainsi, tous nos employés peuvent gérer leurs déclencheurs, notifications et escalades en utilisant une approche unique.
Comme auparavant, nous avions déjà déclenché des déclencheurs via l'interface graphique, nous avons implémenté la possibilité de les télécharger au format yaml. Le contenu du document yaml reçu peut être inséré dans alert.yaml sans pratiquement aucune transformation supplémentaire, puis envoyer les modifications à l'assistant. Pendant la construction, alert-autoconf comprendra qu'un tel déclencheur existe déjà et l'enregistrera dans notre registre de Redis.
Et il n'y a pas si longtemps, nous avons obtenu un quart de travail d'ingénieurs 24h / 24 et 7j / 7. Afin de leur transférer des déclencheurs pour le service, il suffit dans votre alert.yaml de remplir correctement la description de «que faire si vous le voyez», de mettre la balise [24x7] et de pousser les modifications dans l'assistant. Après avoir lancé alert.yaml, tous les déclencheurs qui y sont décrits tomberont automatiquement sous une surveillance de poste 24 heures sur 24, 7 jours sur 7. U - Simplifiez! La beauté!
Collection de métriques commerciales
Depuis le dernier article sur la collecte et le traitement des métriques commerciales, notre bioyino est devenu encore meilleur.
- Au lieu de choisir un chef par le biais du consul , le radeau intégré est utilisé .
- Les balises sont correctement traitées au format Graphite .
- Vous pouvez maintenant utiliser bioyino (serveur StatsD) comme agent.
- Pour compter les valeurs uniques, le format "set" est pris en charge.
- L'agrégation finale des métriques peut être effectuée dans plusieurs threads.
- Les données peuvent être envoyées à des blocs Graphite dans plusieurs connexions parallèles.
- Correction de tous les bugs trouvés.
Maintenant, ça fonctionne comme ça.
Nous avons commencé à introduire activement les agents StatsD à côté de tous les grands et grands générateurs métriques: dans des conteneurs avec des instances monolithiques, dans des pods k8s à côté des services, sur des hôtes avec des composants d'infrastructure, etc.
L'agent Statsd est situé à côté de l'application. Il prend tout de même des métriques de cette application sur UDP, mais n'utilise plus le sous-système réseau (en raison des optimisations du noyau Linux). Tous les événements sont pré-agrégés et les données collectées chaque seconde (l'intervalle peut être configuré) sont envoyées au cluster principal des serveurs StatsD (bioyino0 [1-3]) au format Cap'n Proto.
Le traitement ultérieur et l'agrégation des métriques, le choix d'un leader dans le cluster StatsD et l'envoi des métriques par le leader à Graphite n'ont pratiquement pas changé. Vous pouvez en savoir plus à ce sujet dans notre dernier article .
Quant aux chiffres, ils sont les suivants.
Graphique des événements StatsD reçus
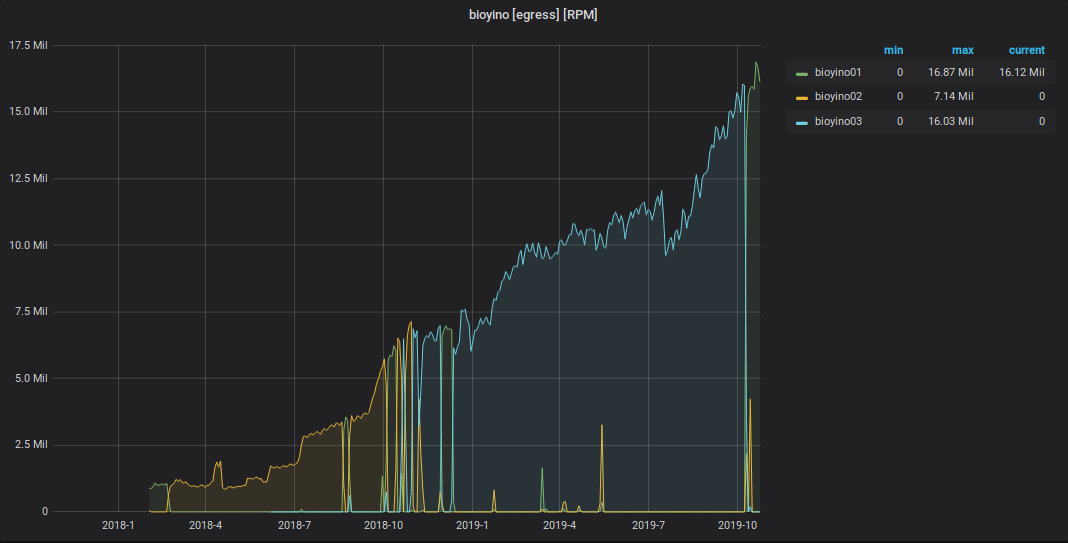

Graphique des métriques envoyées de StatsD à Graphite
Total
Le schéma général d'interaction entre les composants de surveillance à l'heure actuelle ressemble à ceci.
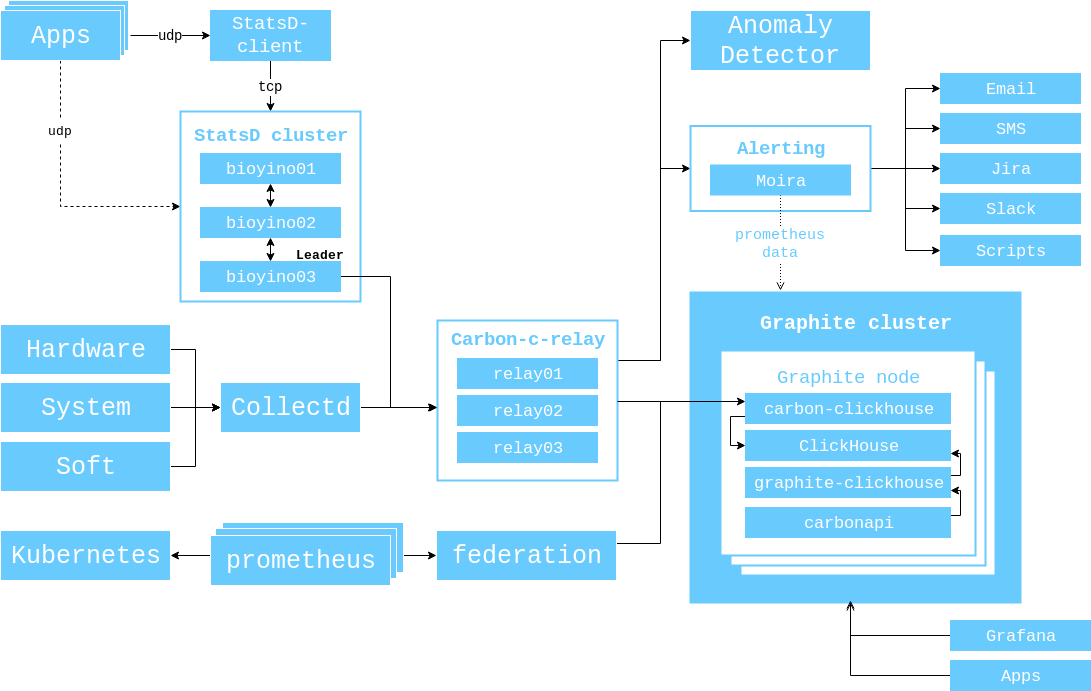
Nombre total de métriques: 2 189 484 898 474.
Profondeur totale de stockage des métriques: 3 ans.
Le nombre de noms métriques uniques: 6 585 413 171.
Nombre de déclencheurs: 1053, ils servent de 1 à 15 000 métriques.
Plans pour le proche avenir:
- commencer à déplacer les services de produits vers un système de stockage métrique étiqueté;
- ajouter trois serveurs supplémentaires au cluster Graphite;
- se faire des amis de Moira avec des tissus persistants ;
- Trouvez un autre développeur dans l'équipe de surveillance.
Je serai heureux de faire des commentaires et des questions ici - écrivez. Et je jouerai également sur Highload ++ le 7 novembre , si vous êtes là, on peut parler.