Dans le
dernier article, nous avons découvert que le cache est certainement une chose utile, mais en ce qui concerne la logique du contrôleur, cela crée parfois des difficultés. En particulier, il introduit l'imprévisibilité des durées d'impulsion ou d'autres retards dans la formation programmatique des chronogrammes. Eh bien, et dans le plan "programmatique général", le mauvais emplacement de la fonction peut réduire à néant le gain du cache, le provoquant constamment à redémarrer à partir d'une mémoire lente. J'ai mentionné qu'il y a 15 ans, nous devions faire un préprocesseur spécial qui corrigeait les problèmes qui se posaient pour le processeur SPARC-8, et j'ai promis de dire à quel point il serait facile de résoudre ces difficultés lors du développement d'un processeur Nios II synthétisé recommandé pour une utilisation dans le package Redd. Le moment est venu de tenir la promesse.

Articles précédents de la série:
- Développement du «firmware» le plus simple pour les FPGA installés dans Redd, et débogage en utilisant le test de mémoire comme exemple.
- Développement du «firmware» le plus simple pour les FPGA installés dans Redd. Partie 2. Code de programme.
- Développement de son propre noyau pour l'intégration dans un système de processeur FPGA.
- Développement de programmes pour le processeur central Redd sur l'exemple d'accès au FPGA.
- Les premières expériences utilisant le protocole de streaming sur l'exemple de la connexion du CPU et du processeur dans le FPGA du complexe Redd.
- Joyeux Quartusel, ou comment le processeur est arrivé à une telle vie.
- Méthodes d'optimisation de code pour Redd. Partie 1: effet de cache.
Aujourd'hui, notre livre de référence sera le
Manuel de conception intégrée , ou plutôt sa section
7.5. Utilisation de la mémoire étroitement couplée avec le didacticiel du processeur Nios II . La section elle-même est colorée. Aujourd'hui, nous concevons des systèmes de processeur pour les FPGA Intel dans le programme Platform Designer. À l'époque d'Altera, il s'appelait QSys (d'où l'extension
.qsys du fichier projet). Mais avant l'apparition de QSsys, tout le monde utilisait son ancêtre, SOPC Builder (en mémoire duquel l'extension de fichier
.sopcinfo était
restée ). Donc, bien que le document soit marqué du logo Intel, mais les images qu'il contient sont des captures d'écran de ce SOPC Builder. Il a été clairement rédigé il y a plus de dix ans et, depuis lors, seuls des termes y ont été corrigés. Certes, les textes sont assez modernes, donc ce document est très utile comme manuel de formation.
Préparation de l'équipement
Alors. Nous voulons ajouter de la mémoire à notre système de processeur Spartan, qui n'est jamais mis en cache et fonctionne en même temps à la vitesse la plus élevée possible. Bien sûr, ce sera la mémoire FPGA interne. Nous ajouterons de la mémoire pour le code et les données, mais ce seront des blocs différents. Commençons par la mémoire de données comme la plus simple. Nous
ajoutons la mémoire OnChip déjà connue au système.
Eh bien, disons que son volume sera de 2 kilo-octets (le principal problème avec la mémoire interne du FPGA est qu'elle est petite, vous devez donc la sauvegarder). Le reste est une mémoire ordinaire, que nous avons déjà ajoutée.

Mais nous ne le connecterons pas au bus de données, mais à un bus spécial. Pour le faire apparaître, on va dans les propriétés du processeur, on va dans l'onglet
Caches et Interfaces mémoire et dans la liste de sélection
Nombre de ports maître de données étroitement coulpés sélectionner la valeur 1.
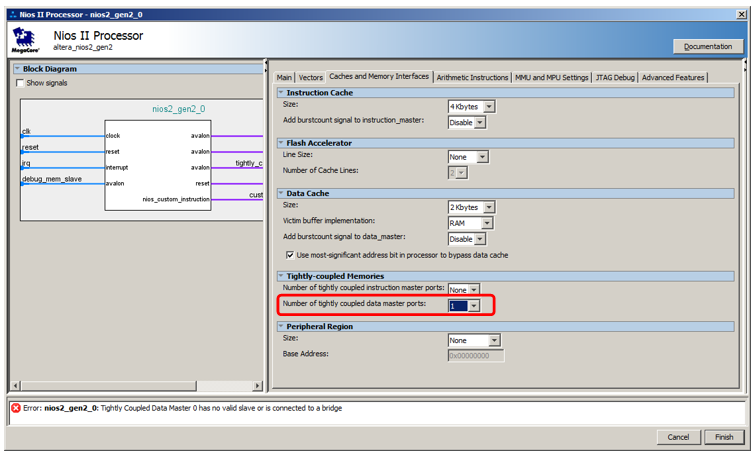
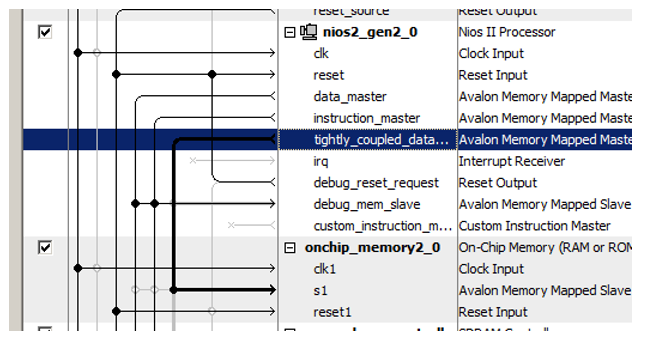
Voici un nouveau port pour le processeur:

Nous y avons récemment connecté le bloc de mémoire nouvellement ajouté!
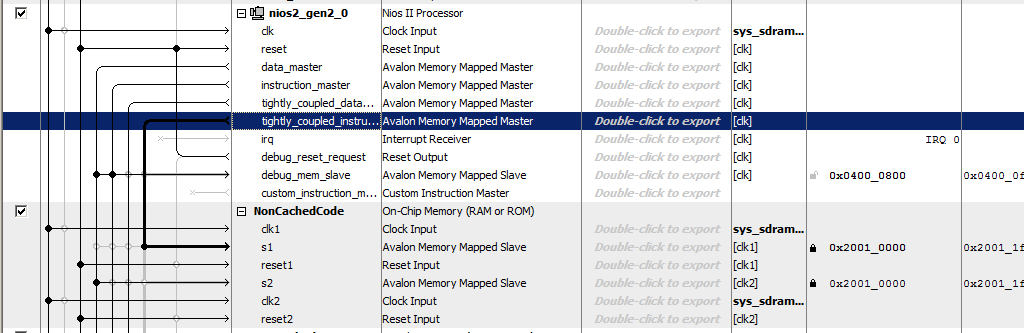
Une autre astuce consiste à attribuer des adresses à cette nouvelle mémoire. Le document a une longue ligne de raisonnement sur l'optimalité du décodage d'adresse. Il indique que la mémoire non mise en cache doit être distinguée de tous les autres types de mémoire par un bit clairement exprimé de l'adresse. Par conséquent, dans le document, toute la mémoire non-cache appartient à la plage 0x2XXXXXXX. Entrez donc manuellement l'adresse 0x2000000 et verrouillez-la afin qu'elle ne change pas avec les affectations automatiques suivantes.

Eh bien, et purement pour l'esthétique, renommer le bloc ... Appelons-le, disons,
NonCachedData .

Avec du matériel pour la mémoire de données non mise en cache, c'est tout. Nous passons en mémoire pour le stockage du code. Tout est presque le même ici, mais un peu plus compliqué. En fait, tout peut être fait de façon complètement identique, seul le port maître du bus s'ouvre dans la liste
Nombre de ports maîtres d'instruction étroitement coulpés , cependant, il ne sera pas possible de déboguer un tel système. Lorsque le programme est rempli avec le débogueur, il y circule via le bus de données. A l'arrêt, le code désassemblé est également lu par le débogueur via le bus de données. Et même si le programme est chargé depuis un chargeur externe (nous n'avons pas encore envisagé une telle méthode, d'autant plus que dans la version gratuite de l'environnement de développement nous sommes obligés de travailler uniquement avec le débogueur JTAG connecté, mais en général, personne n'interdit de le faire), le remplissage passe également par le bus les données. Par conséquent, la mémoire devra faire double port. À un port, connectez un assistant d'instructions non mis en cache qui fonctionne en temps principal, et à l'autre - un bus de données auxiliaire à temps plein. Il sera utilisé pour télécharger le programme de l'extérieur, ainsi que pour obtenir le contenu de la RAM par le débogueur. Le reste du temps, ce pneu sera inactif. Voici à quoi cela ressemble dans la partie théorique du document:

Notez que le document n'explique pas pourquoi, mais il est à noter que même avec une mémoire à deux ports, un seul port peut être connecté à un maître non mis en cache. Le second doit être connecté à l'habituel.
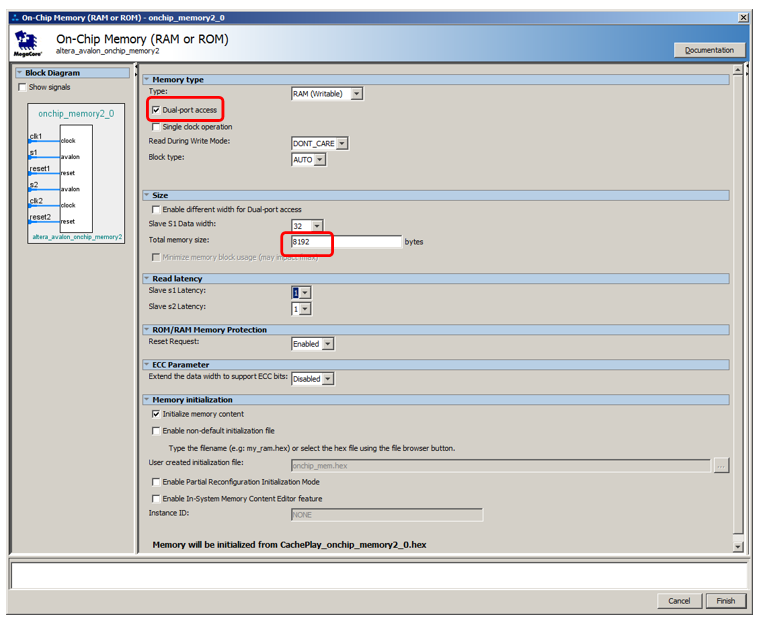
Ajoutons 8 kilo-octets de mémoire, faisons-en double port, laissons le reste par défaut:
Ajoutez un port d'instructions non-cache au processeur:

Nous appelons la mémoire
NonCachedCode , connectons la mémoire aux bus, lui attribuons l'adresse 0x20010000 et la verrouillons (pour les deux ports). Total, nous obtenons quelque chose comme ceci:
C’est tout. Nous sauvegardons et générons le système, collectons le projet. Le matériel est prêt. Nous passons à la partie logiciel.
Préparation du BSP dans la partie logicielle
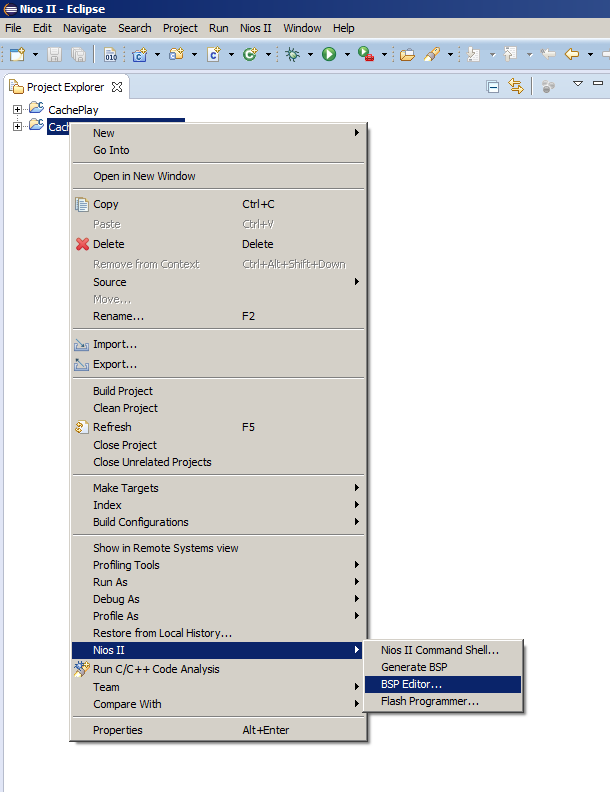
Habituellement, après avoir changé le système de processeur, il suffit de sélectionner l'élément de menu
Générer BSP , mais aujourd'hui, nous devons ouvrir l'éditeur BSP. Comme nous le faisons rarement, permettez-moi de vous rappeler où se trouve l'élément de menu correspondant:
Là, nous allons à l'onglet
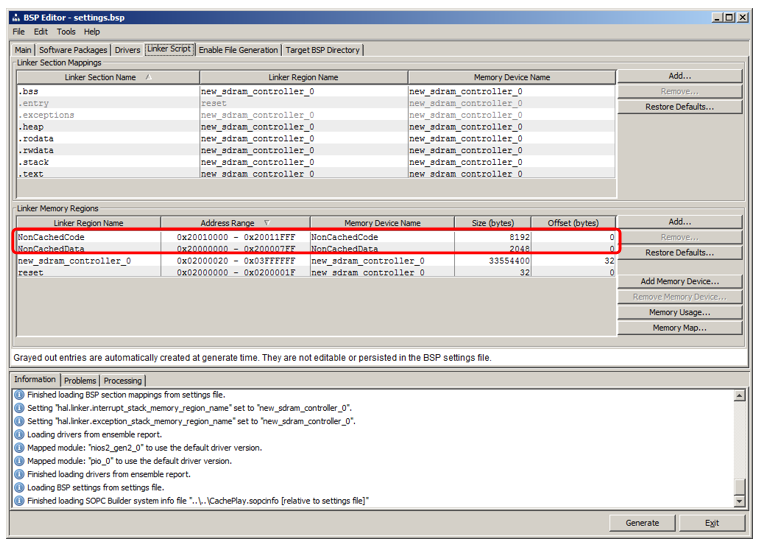
Script de l'
éditeur de liens . Nous voyons que nous avons ajouté des régions qui héritent des noms des blocs de RAM:
Je vais montrer comment ajouter une section dans laquelle le code sera placé. Dans la section section, cliquez sur Ajouter:
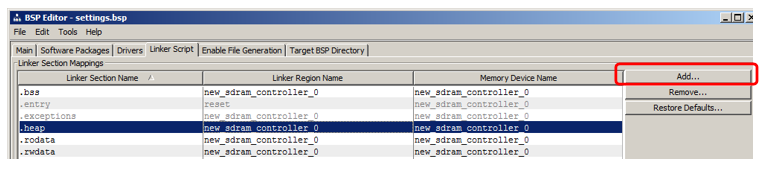
Dans la fenêtre qui apparaît, donnez le nom de la section (afin d'éviter toute confusion dans l'article, je vais l'appeler très différent du nom de la région, à savoir nccode) et l'associer à la région (j'ai sélectionné
NonCachedCode dans la liste):

Voilà, générez le BSP et fermez l'éditeur.
Placer du code dans une nouvelle section mémoire
Permettez-moi de vous rappeler que nous avons deux fonctions dans le programme hérité de l'article précédent:
MagicFunction1 () et
MagicFunction2 () . Au premier passage, les deux ont chargé leur corps dans la cache, visible sur l'oscilloscope. De plus - selon la situation dans l'environnement, ils travaillaient à vitesse maximale ou se frottaient constamment avec leur corps, provoquant des téléchargements constants de la SDRAM.
Déplaçons la première fonction vers un nouveau segment non mis en cache, laissons la seconde en place, puis effectuons quelques exécutions.
Pour placer une fonction dans une nouvelle section, ajoutez-lui l'attribut de section .
Avant de définir la fonction
MagicFunction1 () ,
nous plaçons également sa déclaration avec cet attribut:
void MagicFunction1()__attribute__ ((section("nccode"))); void MagicFunction1() { IOWR (PIO_0_BASE,0,1); IOWR (PIO_0_BASE,0,0); ...
Nous effectuons la première exécution d'une itération de la boucle (j'ai mis un point d'arrêt sur la ligne while):
while (1) { MagicFunction1(); MagicFunction2(); }
Nous voyons le résultat suivant:
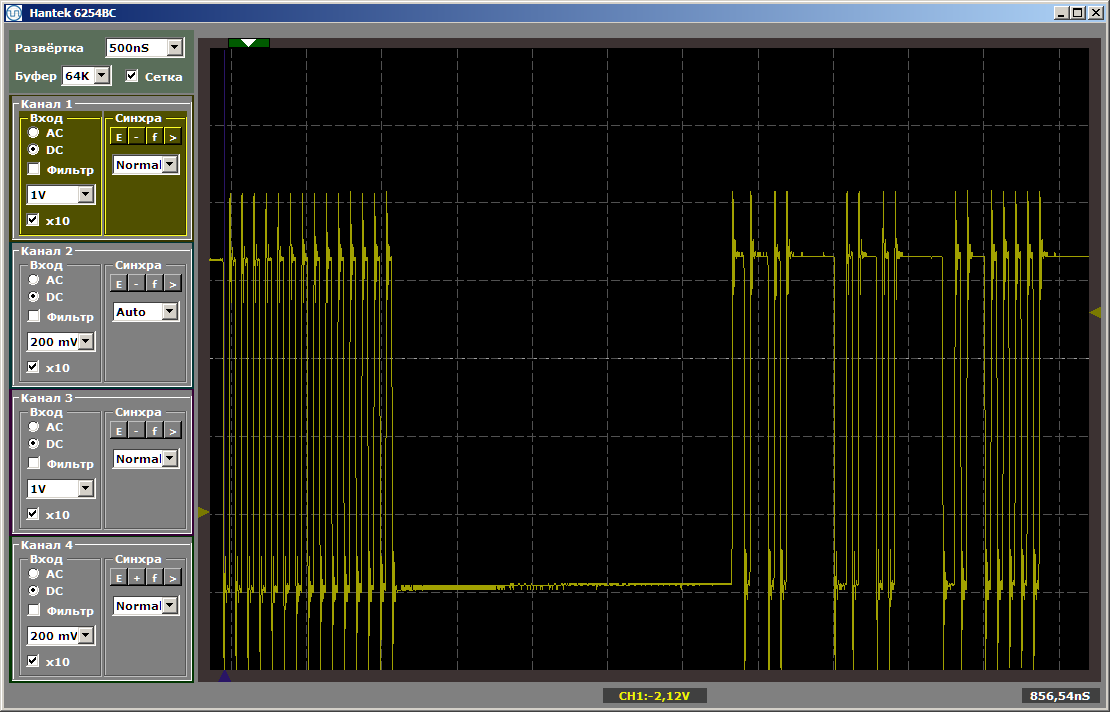
Comme vous pouvez le voir, la première fonction est vraiment exécutée à vitesse maximale, la seconde est chargée depuis la SDRAM. Exécutez la deuxième exécution:
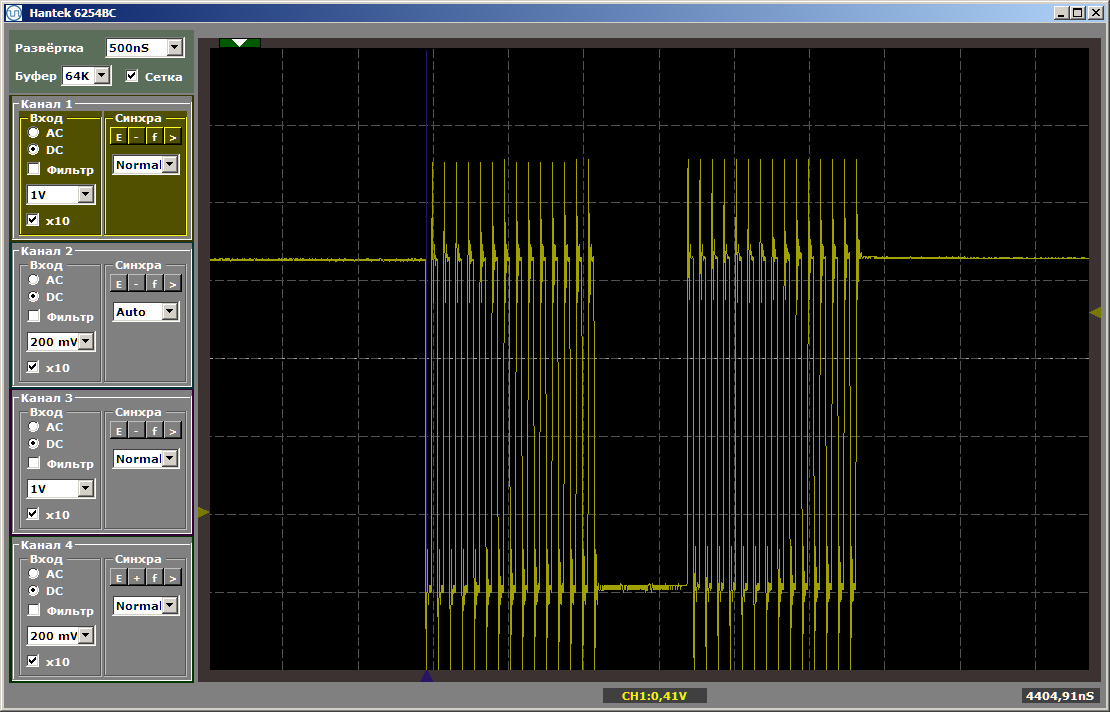
Les deux fonctions fonctionnent à vitesse maximale. Et la première fonction ne décharge pas la seconde du cache, malgré le fait qu'entre eux se trouve l'insert que j'ai laissé après avoir écrit le dernier article:
volatile void FuncBetween() { Nops256 Nops256 Nops256 Nops64 Nops64 Nops64 Nops16 Nops16 }
Cette insertion n'affecte plus la position relative des deux fonctions, car la première d'entre elles est partie dans une zone de mémoire complètement différente.
Quelques mots sur les données
De même, vous pouvez créer une section de données non mises en cache et y placer des variables globales, en leur attribuant le même attribut, mais pour économiser de l'espace, je ne donnerai pas de tels exemples.
Nous avons créé une région pour une telle mémoire, le mappage à la section peut être fait de la même manière que pour la section de code. Il ne reste plus qu'à comprendre comment affecter l'attribut correspondant à une variable. Voici le premier exemple de déclaration de telles données trouvées dans les entrailles du code généré automatiquement:
volatile alt_u32 alt_log_boot_on_flag \ __attribute__ ((section (".sdata"))) = ALT_LOG_BOOT_ON_FLAG_SETTING;
Qu'est-ce que cela nous donne
Eh bien, en fait, à partir de choses évidentes: maintenant nous pouvons placer la partie principale du code dans SDRAM, et dans la section non cacheable, nous pouvons mettre en place ces fonctions qui forment des diagrammes de temps par programme, ou dont les performances devraient être maximales, ce qui signifie qu'elles ne devraient pas ralentir en raison de qu'une autre fonction vide constamment le code correspondant du cache.
Examinez de près les pneus.
Examinez maintenant de près les pneus du système de processeur résultant. Nous en avons eu près de quatre. J'ai encerclé en rouge le bus principal (qui est l'union des deux, c'est pourquoi j'ai écrit «presque»: physiquement - il y a deux pneus, mais logiquement - un). J'ai mis en évidence en vert le bus menant à la mémoire d'instructions non mise en cache, en bleu - à la mémoire de données non mise en cache.
Ces trois pneus fonctionnent en parallèle et indépendamment les uns des autres!
Rappelez-vous, dans l'
article sur le DMA, j'ai soutenu que l'un des facteurs limitant les performances est que les données sont transmises sur le même bus? Le bloc DMA lit les données du bus, y écrit des données et, en même temps, le cœur du processeur utilise le même bus. Comme vous pouvez le voir, cet inconvénient des systèmes fermés est complètement éliminé dans le FPGA. Dans les contrôleurs prêts à l'emploi, les fabricants, lorsqu'ils établissent des connexions, sont obligés de déchirer entre les besoins et les capacités. Le programmeur peut avoir besoin de cette option. Et tel. Et tel. Et donc ... Beaucoup de choses peuvent être nécessaires. Mais les ressources coûtent de l'argent, et il n'y a pas toujours assez d'espace pour elles sur le cristal sélectionné. Vous ne pouvez pas tout publier. Nous devons choisir ce dont tout le monde a vraiment besoin et ce qui est nécessaire dans des cas isolés. Et quels cas isolés devraient être introduits et lesquels devraient être oubliés. Et puis des solutions de compromis apparaissent, toutes les subtilités dont, s'il y a un désir de les utiliser, le programmeur doit garder à l'esprit. Dans notre cas, nous pouvons agir sans plus attendre. Ce dont nous avons besoin aujourd'hui est posé aujourd'hui. Notre ressource est flexible. Nous le dépensons pour que l'équipement soit optimal pour notre tâche d'aujourd'hui. Pour les tâches de demain et d'hier, les ressources n'ont pas besoin d'être réservées. Mais dans le cadre d'aujourd'hui, nous mettrons tout en place pour que le programme fonctionne aussi efficacement que possible, sans nécessiter de délices de programmation spéciaux.
Il était une fois, dans une université, dans un cours sur les processeurs de signaux, nous avons appris l'art d'utiliser deux bus en parallèle avec une équipe. Pour autant que je sache, dans les contrôleurs ARM modernes, une connaissance détaillée de la matrice de bus permet également une optimisation. Mais tout cela est bien quand un développeur travaille avec le même système depuis des années. Si vous devez piloter des pièces de matériel complètement différentes d'un projet à l'autre, vous ne pouvez pas tout mémoriser. Dans le cas des FPGA, nous n'étudions pas les caractéristiques de l'environnement, nous sommes libres de personnaliser l'environnement pour nous-mêmes.
En ce qui concerne l'approche «nous ne consacrons pas beaucoup de temps au développement», cela ressemble à ceci:
Nous n'avons pas besoin de faire des efforts pour optimiser l'utilisation de pneus standard prêts à l'emploi, nous pouvons rapidement les poser de la manière la plus optimale pour la tâche à résoudre, terminer rapidement ce développement auxiliaire et assurer rapidement le processus de débogage ou de test du projet principal.
Jetons un coup d'œil à un exemple d'inclusion d'un bloc DMA du
guide de l'utilisateur IP des périphériques intégrés pour consolider le matériel.
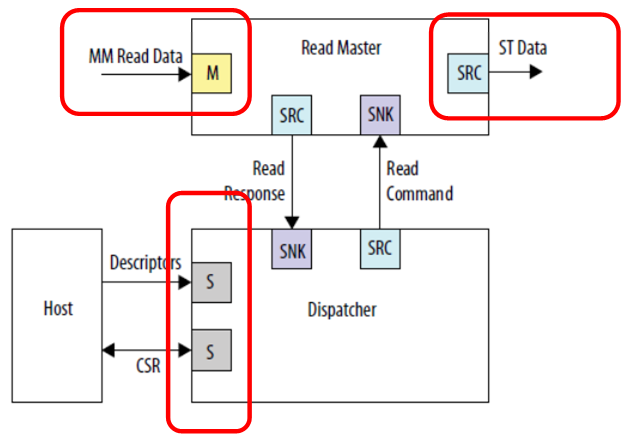
Nous voyons trois connexions indépendantes. Données d'entrée (sur cette figure, il s'agit d'un bus projeté sur la mémoire), données de sortie (sur cette figure, il s'agit d'un type de bus complètement différent - une interface de flux) et de communication avec le processeur de contrôle. Personne ne se soucie de tout connecter à différents bus, alors le travail se fera en parallèle. Les données d'entrée (par exemple, à partir de la SDRAM) iront dans un flux, auquel personne n'interfère; la sortie ira dans un flux différent, par exemple, vers le canal FT245-FIFO, que nous avons déjà considéré; et le processeur central ne rongera pas ces bus d'horloge, car le bus principal est isolé. Bien que dans ce cas, bien sûr, la mémoire en SDRAM, se trouvant sur un bus séparé, ne sera pas disponible par programme. Mais personne ne l'empêchera d'être lu par DMA. Si l'objectif est d'atteindre des performances élevées avec le tampon, il doit être atteint à tout prix. À moins que l'ensemble du programme ne doive tenir dans la mémoire intégrée au FPGA, car il n'y a pas d'autres unités de stockage dans le matériel Redd.
Pour paralléliser les pneus, vous pouvez également utiliser des pneus non mis en cache, car nous avons vu qu'il peut y en avoir plusieurs. Un certain nombre de restrictions sont imposées aux esclaves connectés à ces bus:
- l'esclave est toujours un sur le bus;
- l'esclave n'utilise pas le mécanisme de retard du bus;
- la latence d'écriture est toujours nulle; la latence de lecture est toujours une.
Si ces conditions sont remplies, un tel appareil esclave peut être connecté à un bus non mis en cache. Bien sûr, ce sera probablement un bus de données.
En général, connaissant ces principes de base, vous pouvez certainement les utiliser dans des tâches réelles. Mais, en général, vous le pouvez. Vous pouvez vous en passer si le résultat est obtenu par des moyens conventionnels. Mais gardez cela à l'esprit. Parfois, l'optimisation d'un système à travers ces mécanismes est plus simple que le réglage fin du programme.
Conclusion
Nous avons examiné une technique pour transférer des sections de code essentielles aux performances ou à la prévisibilité de l'exécution du traitement dans la mémoire non-cache. En cours de route, nous avons examiné la possibilité d'optimiser les performances grâce à l'utilisation de plusieurs pneus fonctionnant en parallèle et indépendamment les uns des autres.
Pour terminer le sujet, nous devons encore apprendre à augmenter la fréquence d'horloge du système (maintenant elle est limitée au composant générant des impulsions d'horloge pour la puce SDRAM). Mais comme les articles suivent le principe «une chose - un article», nous le ferons la prochaine fois.