Bonjour à tous! Dans cet article, je vous dirai quelles approches nous utilisons dans Mail.ru Search pour comparer les textes. À quoi ça sert? Dès que nous apprendrons à bien comparer différents textes, le moteur de recherche pourra mieux comprendre les demandes des utilisateurs.
De quoi avons-nous besoin pour cela? Pour commencer, définissez strictement la tâche. Vous devez déterminer par vous-même les textes que nous considérons similaires et ceux que nous ne considérons pas, puis formuler une stratégie pour déterminer automatiquement la similitude. Dans notre cas, les textes des requêtes des utilisateurs seront comparés aux textes des documents.
La tâche de déterminer la pertinence du texte comprend trois étapes. Tout d'abord, le plus simple: recherchez les mots correspondants dans deux textes et tirez des conclusions sur la similitude en fonction des résultats. La tâche suivante, plus difficile, consiste à rechercher la connexion entre différents mots, à comprendre les synonymes. Et enfin, la troisième étape: l'analyse de l'ensemble de la phrase / du texte, l'isolement du sens et la comparaison des phrases / textes par les significations.

Une façon de résoudre ce problème consiste à trouver un mappage de l'espace de texte à un autre plus simple. Par exemple, vous pouvez traduire des textes dans un espace vectoriel et comparer des vecteurs.
Revenons au début et considérons l'approche la plus simple: trouver des mots correspondants dans les requêtes et les documents. Une telle tâche en elle-même est déjà assez compliquée: pour bien le faire, nous devons apprendre à obtenir la forme normale des mots, ce qui en soi n'est pas trivial.
Le modèle de cartographie directe peut être considérablement amélioré. Une solution consiste à faire correspondre les synonymes conditionnels. Par exemple, vous pouvez saisir des hypothèses probabilistes sur la distribution des mots dans les textes. Vous pouvez travailler avec des représentations vectorielles et isoler implicitement les connexions entre les mots incompatibles, et le faire automatiquement.
Puisque nous sommes engagés dans la recherche, nous avons beaucoup de données sur le comportement des utilisateurs lors de la réception de certains documents en réponse à certaines requêtes. Sur la base de ces données, nous pouvons tirer des conclusions sur la relation entre différents mots.
Prenons deux phrases:

Attribuez à chaque paire de mots de la requête et du titre un certain poids, ce qui signifie combien le premier mot est associé au second. Nous prédirons le clic comme une transformation sigmoïdale de la somme de ces poids. Autrement dit, nous définissons la tâche de régression logistique, dans laquelle les attributs sont représentés par un ensemble de paires de la forme (mot de la requête, mot du titre / texte du document). Si nous pouvons former un tel modèle, alors nous comprendrons quels mots sont des synonymes, plus précisément, peuvent être connectés et lesquels ne le sont probablement pas.
textbfClickprobabilité= sigma left( sum varphii right) textbf,où varphii textbf−poidsd′uncoupledemots(motderequête,motdedocument)
Vous devez maintenant créer un bon ensemble de données. Il s'avère qu'il suffit de prendre l'historique des clics des utilisateurs, d'ajouter des exemples négatifs. Comment mélanger dans des exemples négatifs? Il est préférable de les ajouter à l'ensemble de données dans un rapport 1: 1. De plus, les exemples eux-mêmes au premier stade de la formation peuvent être effectués de manière aléatoire: pour une paire requête-document, nous trouvons un autre document aléatoire, et nous considérons une telle paire comme négative. Aux stades ultérieurs de la formation, il est avantageux de donner des exemples plus complexes: ceux qui ont des intersections, ainsi que des exemples aléatoires que le modèle considère comme similaires (minage dur négatif).
Exemple: Synonymes du mot "triangle".
À ce stade, nous pouvons déjà distinguer une bonne fonction qui correspond aux mots, mais ce n'est pas ce que nous recherchons. Cette fonction nous permet de faire une correspondance indirecte des mots, et nous voulons comparer des phrases entières.
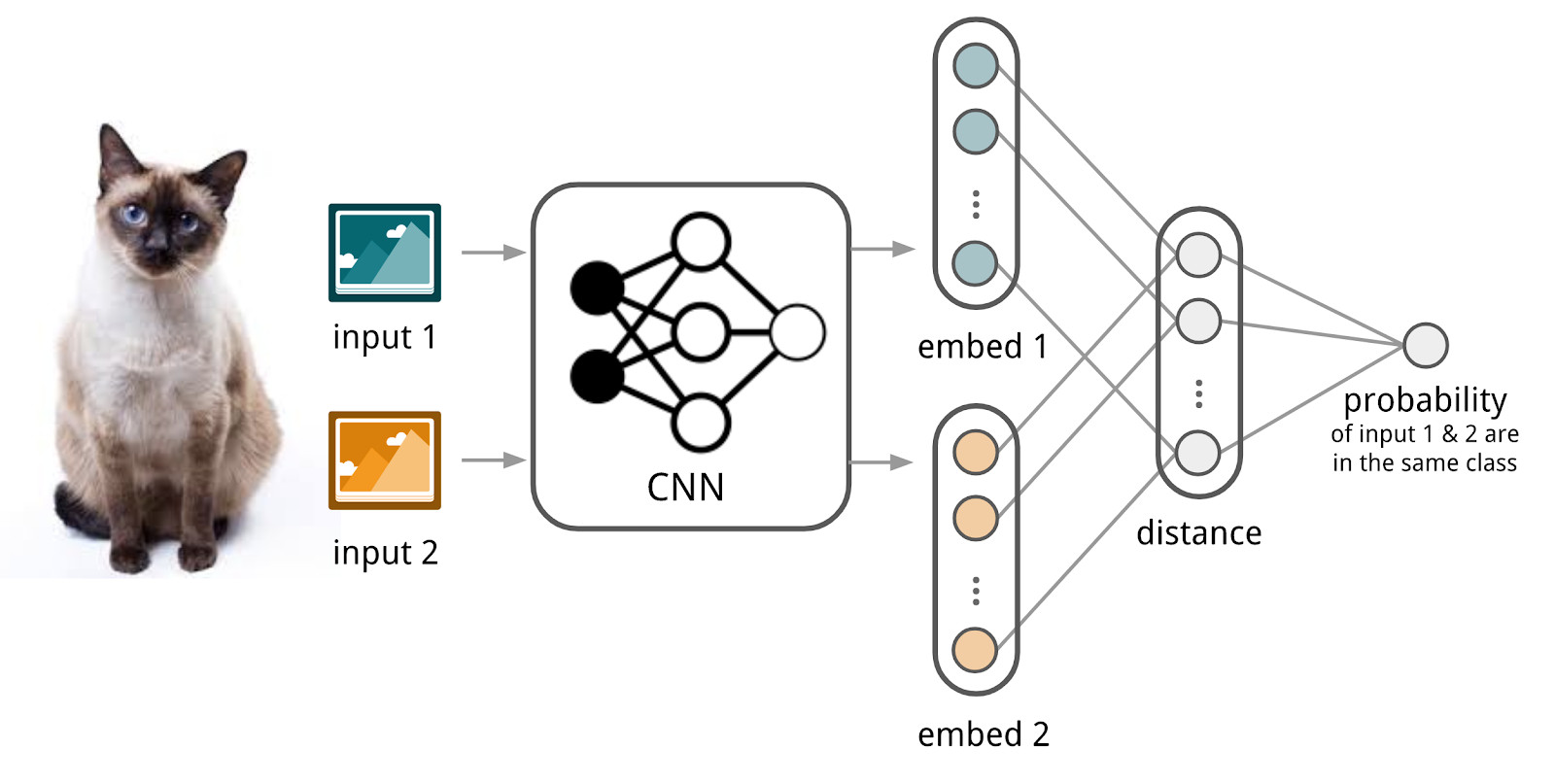
Ici, les réseaux de neurones nous aideront. Faisons un encodeur qui accepte du texte (une requête ou un document) et produit une représentation vectorielle telle que des textes similaires ont des vecteurs proches et distants. Par exemple, vous pouvez utiliser la distance cosinus comme mesure de similitude.
Ici, nous utiliserons l'appareil des réseaux siamois, car ils sont beaucoup plus faciles à former. Le réseau siamois se compose d'un codeur, qui est appliqué pour échantillonner les données de deux familles ou plus et d'une opération de comparaison (par exemple, la distance cosinus). Lors de l'application de l'encodeur à des éléments de différentes familles, les mêmes poids sont utilisés; cela en soi donne une bonne régularisation et réduit considérablement le nombre de facteurs nécessaires à la formation.
L'encodeur produit des représentations vectorielles à partir de textes et apprend de sorte que le cosinus entre les représentations de textes similaires est maximum et entre les représentations de textes différents est minimal.
Un réseau de complexité sémantique profonde DSSM convient à notre tâche. Nous l'utilisons avec des modifications mineures, dont je parlerai ci-dessous.
Fonctionnement du DSSM classique: les requêtes et les documents sont présentés sous la forme d'un sac de trigrammes, à partir duquel une représentation vectorielle standard est obtenue. Il passe à travers plusieurs couches entièrement connectées et le réseau est formé de manière à maximiser la probabilité conditionnelle du document sur demande, ce qui équivaut à maximiser la distance cosinusoïdale entre les représentations vectorielles obtenues par un passage complet à travers le réseau.
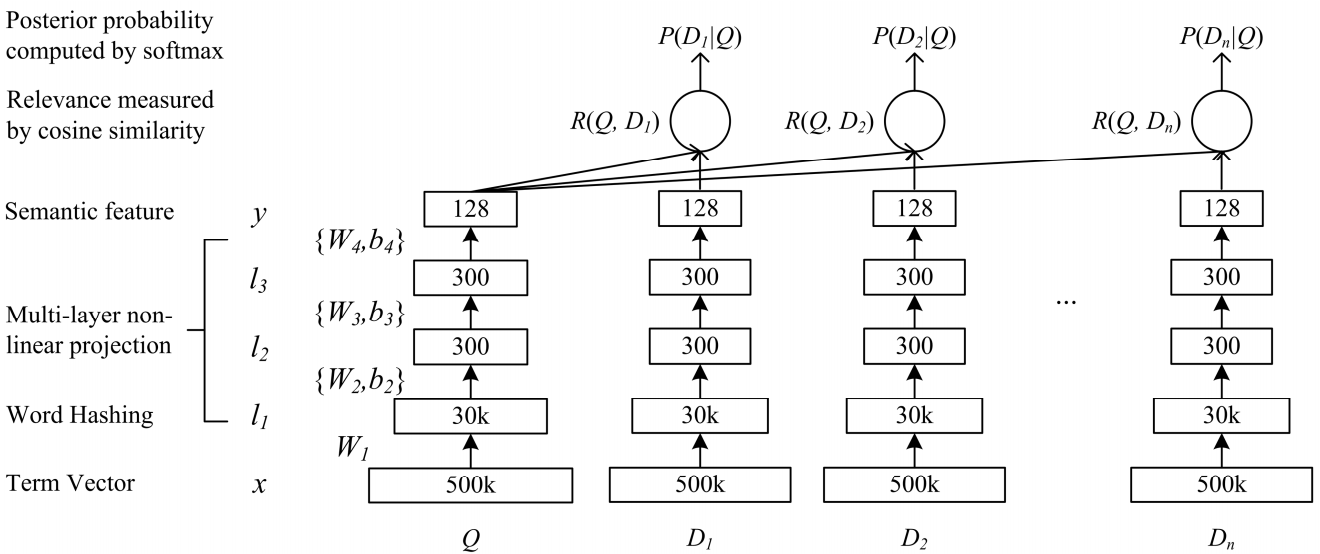 Po-Sen Huang Xiaodong He Jianfeng Gao Li Deng Alex Acero Larry Heck. 2013 Apprentissage de modèles sémantiques structurés en profondeur pour la recherche sur le Web à l'aide de données de clics
Po-Sen Huang Xiaodong He Jianfeng Gao Li Deng Alex Acero Larry Heck. 2013 Apprentissage de modèles sémantiques structurés en profondeur pour la recherche sur le Web à l'aide de données de clicsNous avons fait presque le même chemin. A savoir, chaque mot de la requête est représenté comme un vecteur de trigrammes et le texte comme un vecteur de mots, laissant ainsi des informations sur le mot où il se trouvait. Ensuite, nous utilisons des convolutions unidimensionnelles à l'intérieur des mots, lissant la représentation de ceux-ci, et l'opération de traction maximale globale pour agréger des informations sur la phrase dans une représentation vectorielle simple.

L'ensemble de données que nous avons utilisé pour la formation coïncide presque complètement avec celui utilisé pour le modèle linéaire.
Nous ne nous sommes pas arrêtés là. Tout d'abord, ils ont proposé un mode de pré-formation. Nous prenons une liste de requêtes pour le document, saisissons quels utilisateurs interagissent avec ce document et formons le réseau de neurones pour intégrer de telles paires. Comme ces paires appartiennent à la même famille, un tel réseau est plus facile à apprendre. De plus, il est plus facile de le recycler sur des exemples de combat lorsque nous comparons des demandes et des documents.
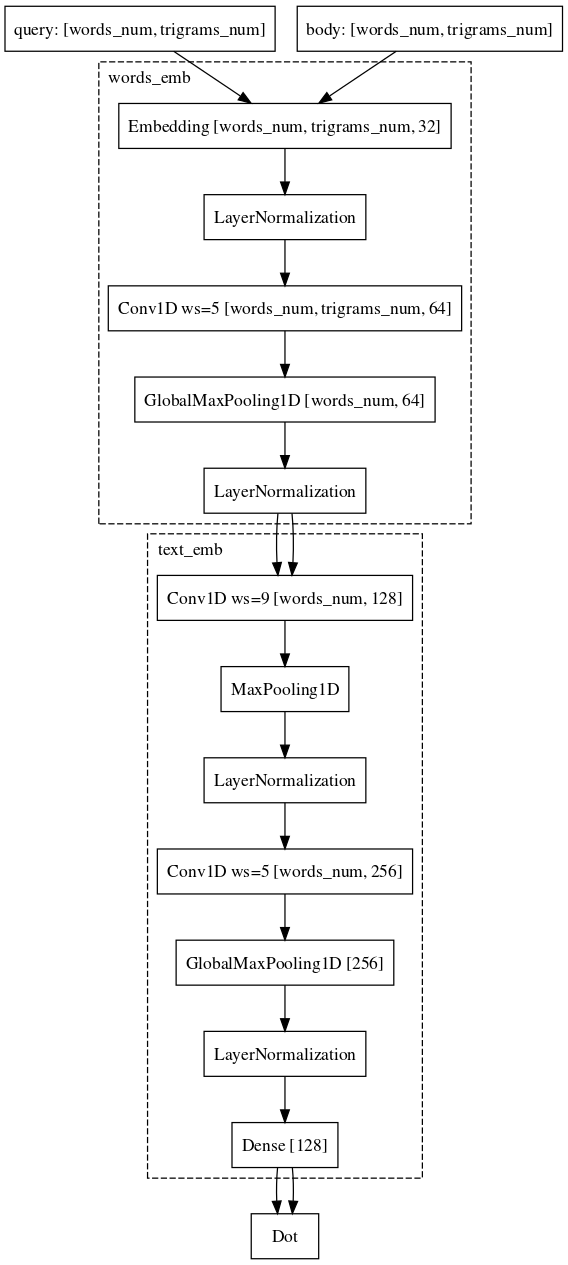
Exemple: les utilisateurs se rendent sur e.mail.ru/login avec des demandes: e-mail, saisie e-mail, adresse e-mail, ...Enfin, la dernière partie difficile, avec laquelle nous avons encore du mal et dans laquelle nous avons presque réussi, est de comparer la demande avec un long document. Pourquoi cette tâche est-elle plus difficile? Ici, la machinerie des réseaux siamois est déjà plus mal adaptée, car la demande et le long document appartiennent à différentes familles d'objets. Néanmoins, nous pouvons nous permettre de changer à peine l'architecture. Il suffit d'ajouter des convolutions également par des mots, ce qui permettra d'économiser plus d'informations sur le contexte de chaque mot pour la représentation vectorielle finale du texte.
À l'heure actuelle, nous continuons d'améliorer la qualité de nos modèles en modifiant les architectures et en expérimentant les sources de données et les mécanismes d'échantillonnage.