Table des matières
Parfois, les bugs eux-mêmes nous trouvent. Nous avons donc poussé une grande rangée de données - et le système s'est bloqué. Est-ce à cause du million de personnages qui sont tombés? Ou n'en aimait-elle pas un en particulier?
Ou le fichier a été téléchargé sur le système et il s'est écrasé. Pourquoi? En raison du nom, de l'extension, des données à l'intérieur ou des tailles? Vous pouvez pousser la localisation sur le développeur, laissez-le penser ce qui est mauvais dans le fichier. Mais souvent, vous pouvez trouver la raison vous-même, puis décrire plus précisément le problème.
Si vous trouvez le minimum de données à jouer, alors:
- Vous gagnerez du temps pour le développeur - il n'aura pas à se connecter au banc d'essai, à charger le fichier lui-même et à faire ses débuts
- Le gestionnaire pourra facilement évaluer la priorité de la tâche - est-il urgent de la corriger ou le bug peut-il attendre? Alors que le nom "certains fichiers tombent, xs why" est difficile à faire ...
- Une description du bug de la compréhension de la cause de la chute sera également bénéfique.
Comment trouver le minimum de données pour jouer un bug? S'il existe des indices dans les journaux, appliquez-les. S'il n'y a aucun indice, alors la meilleure méthode est la méthode de division bisectionnelle (également connue sous le nom de méthode de «bissection» ou de «dichotomie»).
Description de la méthode
La méthode est utilisée pour trouver l'endroit exact de la chute:
- Prenez un paquet de données en baisse.
- Pause en deux.
- Vérifier la moitié 1
- S'il est tombé, alors le problème est là. Nous travaillons plus loin avec elle.
- S'il ne tombe pas → vérifier la moitié 2.
- Répétez les étapes 1 à 3 jusqu'à ce qu'il ne reste qu'une valeur en baisse.

La méthode vous permet de localiser rapidement le problème, surtout si cela se fait par programme. Les développeurs intègrent ces mécanismes dans le traitement des données. Et s'ils ne l'intègrent pas, alors ils souffrent eux-mêmes plus tard, lorsque le testeur vient vers eux et dit: "Cela tombe dans ce dossier, mais je n'ai pas pu trouver la raison exacte."
Application par les testeurs
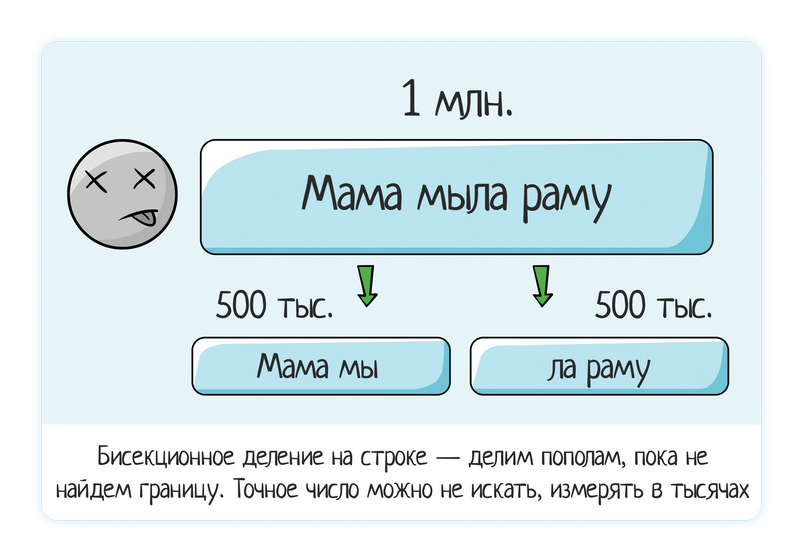
Ligne de données
A chargé une ligne de 1 million de données - le système se bloque.
Nous essayons 500 mille (divisé en deux) - il se bloque toujours.
Nous essayons 250 mille - ça ne pend pas, tout va bien.
↓
D'où la conclusion que le problème se situe entre 250 et 500 000. Encore une fois, nous appliquons la division bisectionnelle.
Nous essayons 350 000 (en le divisant «par l'œil» - c'est tout à fait permis, vous n'avez pas à entrer des chiffres exacts lorsque vous jouez manuellement) - tout va bien
Nous essayons 450 mille - c'est mauvais.
Nous essayons 400 000 - c'est mauvais.
↓
En général, vous pouvez déjà obtenir un bug. Il est très rarement demandé au testeur de signaler que la bordure ou le bug est clairement au numéro 286 586. Il suffit de le localiser environ - 290 000.
C’est juste une chose de vérifier «10» et immédiatement «300 000», et c’est complètement différent de fournir des informations plus complètes: «jusqu’à 10 000 tout est OK, de 10 à 280 000 freins démarrent, ça tombe déjà à 290 000».
Il est clair que lorsque la quantité est mesurée en milliers, il faudra trop de temps pour rechercher manuellement un visage spécifique. Oui, le développeur n'en a pas besoin. Eh bien, personne ne veut perdre son temps en vain.
Bien sûr, si le problème d'origine était sur une ligne de 10 à 30 caractères, vous pouvez trouver la bordure exacte. Tout est dans une relation raisonnable avec le temps - si vous utilisez la conjecture ou la division bissectionnelle, vous pouvez rapidement trouver la valeur exacte et elle est petite (jusqu'à 100 généralement) - nous recherchons à coup sûr. Si les problèmes sont sur une grande ligne, plus de 1000 → recherchez environ.
Fichier
Téléchargement d'un fichier - plantage! Comment, pourquoi? Premièrement, nous essayons d'analyser par nous-mêmes ce qui pourrait affecter ce que notre test a testé? Il s'agit de la puce de règle principale "d'abord positive, puis négative". Si vous n'essayez pas de tout ranger dans un seul test à la fois:
- Vérifié un petit fichier d'exemple
- Nous avons vérifié un énorme fichier de 2 Go, avec un tas de colonnes, un tas de colonnes, ainsi que différentes variations des données internes
Il sera difficile de localiser ici. Et si vous séparez les chèques:
- Beaucoup de lignes (mais les données sont positives et vérifiées plus tôt)
- Beaucoup de colonnes
- Poids lourd
- ...
C'est déjà à peu près compréhensible, quelle est la raison. Par exemple, il tombe sur un grand nombre de lignes - à partir de 100 000. Ok, nous recherchons une frontière plus précise en utilisant la division bisectionnelle:
- Nous avons divisé le dossier en deux par 50 000, vérifié le premier.
- Si tu tombes, divise-le
- Et donc, jusqu'à ce que nous trouvions un endroit précis pour tomber
Si la baisse dépend du nombre de lignes, nous recherchons une bordure approximative: "Après 5000, elle tombe, il n'y en a pas 4000 mille." La recherche d'un lieu spécifique (4589) n'est pas nécessaire. Trop long et ne vaut pas le temps.
Ce bug a été découvert par des étudiants de Dadat . Des fichiers de données peuvent y être chargés, le système traitera et standardisera ces données: corriger les fautes de frappe, déterminer les informations manquantes dans les répertoires (code KLADR, FIAS, coordonnées géographiques, quartier de la ville, code postal ...).
La fille a essayé de télécharger un gros fichier et a obtenu le résultat: le système affiche une barre de progression à 100% de charge et se bloque pendant plus de 30 minutes.
La localisation est allée plus loin - quand le gel commence-t-il? Ceci est important car il affecte la priorité de la tâche. Quelle est la taille de téléchargement typique? À quelle fréquence les utilisateurs expédient-ils directement des LOTS?
Peut-être que le système est conçu pour traiter des milliers de lignes, alors un tel bogue est entassé dans «Fix it un jour». Ou des téléchargements typiques - 10 à 50 000 lignes qui fonctionnent normalement, eh bien, cela signifie que le bogue ne brûle pas, nous le corrigerons un peu plus tard.
Localisation des tâches:
- pour un fichier de 50 000 lignes, 15 secondes de blocage,
- pour un fichier de 100 000 lignes, 30 secondes de blocage,
- pour un fichier de 150 000 lignes, 1 minute se bloque,
- pour un fichier de 165 mille lignes bloque 4 minutes,
- pour un fichier 172 000 lignes avec une barre de progression complète à 100% se bloque pendant plus d'une demi-heure
C'est là que le travail du testeur est déjà effectué qualitativement. Des informations complètes sont fournies sur le fonctionnement du système, sur la base desquelles le gestionnaire peut déjà conclure à l'urgence de corriger le bogue.
La vérification ne prend pas non plus trop de temps. Vous pouvez aller ou de la fin - ici, nous avons téléchargé 200 000 lignes, et quand le problème commence-t-il? Nous utilisons la méthode de division bisectionnelle!
Ou commencez par un nombre relativement petit - 50 000, augmentant progressivement (de moitié, la méthode de division bisectionnelle, juste le contraire). Sachant que tout ira mal à 200 000, on comprend qu'il n'y aura pas beaucoup de tests. Nous avons vérifié 50, 100, 150 - pour trois tests, nous avons trouvé une frontière approximative. Et puis creuser n'est plus nécessaire.
Mais rappelez-vous que vous devez également tester votre théorie. Est-il vrai que le problème réside dans le nombre de lignes et non dans les données du fichier? La vérification est très simple - créez un fichier de 5 000 lignes avec une seule valeur «positive». Cette valeur qui fonctionne exactement que vous avez déjà vérifiée plus tôt. S'il n'y a pas de chute, le problème est impur =)) Il semble que la théorie du nombre de lignes était erronée et le problème se trouve dans les données elles-mêmes.
Bien que vous puissiez essayer 10 000 lignes avec exactement une valeur positive. Il est possible que la chute se reproduise. Seul votre fichier source était sur plusieurs colonnes. Ou il y avait des caractères à l'intérieur qui prenaient plus d'octets qu'une valeur positive ... En général, ne rejetez pas immédiatement la théorie de la taille du fichier ou du nombre de lignes. Essayez la division bisectionnelle au contraire - doublez le fichier.
Mais dans tous les cas, rappelez-vous que plus il y a de contrôles en un, plus il est difficile de localiser le bogue. Par conséquent, il est préférable de tester immédiatement le nombre de lignes ou de colonnes sur une seule valeur positive. Pour être sûr que vous testez la quantité de données, pas les données elles-mêmes. Analyse de test et tout ça =)
Mais que se passe-t-il si le problème n'est pas dans le nombre de lignes, mais dans les données elles-mêmes? Et vous ne savez pas exactement où. Peut-être avez-vous entassé des données de «Guerre et paix» dans un fichier de test, ou téléchargé une grande feuille de calcul quelque part sur Internet ... Ou l'utilisateur a trouvé un problème - il a téléchargé son fichier et tout est tombé. Il est venu au support, le support est venu à vous: le fichier est sur vous, jouez-le.
D'autres actions dépendent de la situation. Si les délais de l'utilisateur sont en cours d'exécution ou que de l'argent lui est débité, puis que le traitement du fichier est tombé, il s'agit d'un bogue bloquant. Et il n'y a pas de temps pour former un testeur de localisation. Il est plus facile de donner le fichier exact au développeur, de le laisser libre et de trouver lui-même la raison.
Mais si vous avez vous-même trouvé une erreur, c'est le temps de la creuser vous-même. Encore une fois, sans oublier le bon sens, comme toujours avec la localisation. Au début, nous avons essayé de tirer des conclusions nous-mêmes, puis nous sommes allés chercher de l'aide. Pour tirer une conclusion vous-même, vous avez besoin de:
- vérifiez les journaux, il peut y avoir la bonne réponse;
- voir le contenu du fichier: quelque chose peut attirer votre attention, c'est la première théorie;
- utiliser la méthode de division bisectionnelle.
Par conséquent, au lieu du bogue «Fichier Fall, xs pourquoi, voici un fichier joint de 2 Go», vous placez un bogue bien pensé et localisé: «Chute le fichier si la date est au format JJ / MM / AAAA». Et puis vous n'avez pas besoin d'un fichier de 2 Go déjà, vous n'avez besoin que d'un fichier pour une ligne et une colonne!

Application par les développeurs
Sur une grande quantité de données, le testeur ne recherche pas de limite claire, car il est déraisonnable de le faire manuellement. Mais les développeurs utilisent la méthode de division bisectionnelle dans le code et peuvent toujours trouver un endroit spécifique pour tomber. Après tout, le système se divisera jusqu'à la victoire, et non une personne!
Par exemple, nous avons un mécanisme pour charger les données dans le système. Il peut charger jusqu'à 10 mille et un million. Mais cela n'a pas d'importance, car le téléchargement se fait par lots de 200 entrées. En cas de problème, le système procède lui-même à une division bisectionnelle. Lui-même. Jusqu'à ce qu'il trouve un endroit problématique. Lisez ensuite dans les journaux:
- Vous avez 1000 entrées
- 200 enregistrements traités
- 400 enregistrements traités
- Oups, tombé sur un pack de 200 disques!
- J'essaie de traiter un pack de taille 100
- J'essaye de traiter un pack de taille 50
- J'essaie de traiter un pack de taille 25
...
- Erreur sur ces identifiants: le champ Email requis n'est pas rempli
- 600 enregistrements traités
...
Ici, bien sûr, la logique dépend également du développeur. Soit le traitement s'arrête après avoir rencontré une erreur, soit va plus loin. Vous êtes tombé sur un pack de 200 entrées? Nous sommes arrivés au point de trouver un goulot d'étranglement, avons marqué l'entrée comme erronée, avons traité les 199 restants et avons continué.
Mais que se passe-t-il si le pack entier s'effondre? Nous avons marqué le dossier comme étant erroné, mais les 199 autres ont également été incapables de traiter. Pourquoi? Nous appliquons la même méthode, à la recherche d'un nouveau problème. L'astuce est que vous devez toujours pouvoir vous arrêter à l'heure.
Si le nombre d'erreurs est supérieur à 10-50-100, il est préférable d'arrêter le téléchargement. Il est possible qu'une erreur de téléchargement se soit produite dans le système d'origine et nous avons reçu un million de «courbes» de données. Si le système divise chaque paquet de 200 enregistrements en deux, puis divise les 199 restants, et ainsi de suite, alors ce sera mauvais pour tout le monde:
- Le journal passe de 15 mb à 3 gb et devient illisible;
- Le système peut planter en essayant de générer un message d'erreur final (j'ai parlé de cette situation dans la section BMW Mnemonics );
- Beaucoup de temps est consacré à la recherche de toutes les erreurs. Oui, le système le fait plus rapidement qu'une personne, mais si vous divisez un million de packs de 200 enregistrements, cela prendra du temps.
Le cerveau doit donc être inclus partout - à la fois dans les tests manuels et lors de l'écriture du code du programme. Vous devez toujours comprendre quand vous arrêter. Ce n'est que dans le cas de tests manuels qu'il sera «sur le point de trouver la frontière», et dans le développement «s'arrêtera s'il y a beaucoup de chutes».
Résumé
La méthode de division bisectionnelle est utilisée pour rechercher l'emplacement exact de la chute et la localisation du bug.
Recherchez le nombre et commencez à le diviser en deux:
- longueur de ligne;
- taille du fichier
- poids du fichier;
- nombre de lignes / colonnes;
- quantité de mémoire libre dans un téléphone mobile;
- ...
Mais souvenez-vous - un jour, vous devez vous arrêter! Pas besoin de s'arrêter et de chercher le nombre exact s'il nécessite des milliers de tests supplémentaires. Mais 5 à 10 minutes peuvent être accordées à la localisation.
PS - recherchez des articles plus utiles sur mon blog par la balise "utile"