Salut Je m'appelle Antonina, je suis développeur Oracle de la division IT de Sportmaster Lab. Je travaille ici depuis seulement deux ans, mais grâce à une équipe sympathique, une équipe soudée, un système de mentorat, une formation en entreprise, la masse critique s'est accumulée lorsque je veux non seulement consommer des connaissances, mais aussi partager mon expérience.

Donc, redéfinition basée sur l'édition. Pourquoi avons-nous même eu un tel besoin d'étudier cette technologie, d'ailleurs, le terme «haute disponibilité» et comment la redéfinition basée sur l'édition nous aide-t-elle en tant que développeurs Oracle à gagner du temps?
Qu'est-ce qui est proposé comme solution par Oracle? Que se passe-t-il dans l'arrière-cour lors de l'application de cette technologie, quels problèmes nous avons rencontrés ... En général, il y a beaucoup de questions. J'essaierai d'y répondre dans deux articles sur le sujet, et le premier d'entre eux est déjà sous la coupe.
Chaque équipe de développeurs, en créant sa propre application, s'efforce de créer l'algorithme le plus abordable, le plus tolérant aux pannes et le plus fiable. Pourquoi cherchons-nous tous à cela? Probablement pas parce que nous sommes si bons et que nous voulons sortir un produit cool. Plus précisément, non seulement parce que nous sommes si bons. C'est également important pour les entreprises. Malgré le fait que nous pouvons écrire un algorithme sympa, le couvrir de tests unitaires, voir qu'il est tolérant aux pannes, nous avons toujours (les développeurs Oracle) un problème - nous sommes confrontés à la nécessité de mettre à niveau nos applications. Par exemple, nos collègues du système de fidélité sont obligés de le faire la nuit.
Si cela se produisait à la volée, les utilisateurs verraient une image: "Veuillez m'excuser!", "Ne soyez pas triste!", "Attendez, nous avons des mises à jour et du travail technique ici." Pourquoi est-ce si important pour les entreprises? Mais c’est très simple - depuis longtemps, les entreprises subissent non seulement des pertes de certains biens réels, des valeurs matérielles, mais aussi des pertes dues aux immobilisations des infrastructures. Par exemple, selon le magazine Forbes, en 13 ans, une minute de panne de service Amazon a coûté 66 mille dollars. Autrement dit, en une demi-heure, les gars ont perdu près de 2 millions de dollars.
Il est clair que pour les moyennes et petites entreprises, et non pour un géant comme Amazon, ces caractéristiques quantitatives seront bien moindres, mais néanmoins, en termes relatifs, cela reste une caractéristique d'évaluation importante.
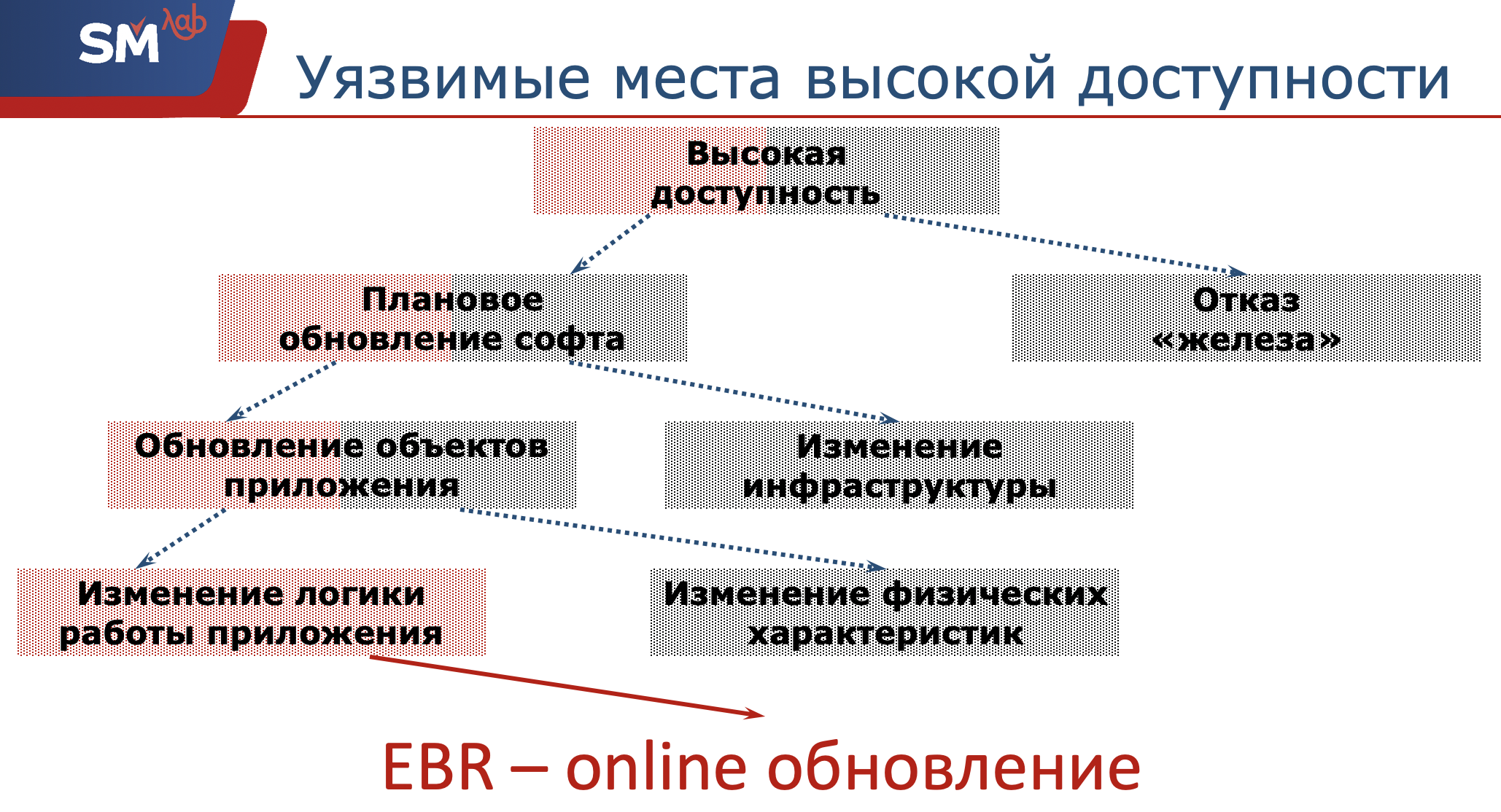
Nous devons donc garantir la haute disponibilité de notre application. Quels sont les endroits potentiellement dangereux pour les développeurs Oracle pour cette accessibilité?
Tout d'abord, notre matériel peut échouer. En tant que développeurs, nous ne sommes pas responsables de cela. Les administrateurs réseau doivent s'assurer que le serveur et les objets structurels sont opérationnels. Nous aboutissons à une mise à niveau logicielle. Encore une fois, les mises à jour logicielles planifiées peuvent être divisées en deux classes. Ou nous changeons une sorte d'infrastructure, par exemple, en mettant à jour le système d'exploitation sur lequel tourne le serveur. Soit nous avons décidé de passer à la nouvelle version d'Oracle (ce serait bien si nous y arrivions avec succès :)) ... Ou, la deuxième classe, c'est à cela que nous avons le plus de relations - c'est la mise à jour des objets d'application que nous développons avec vous.
Encore une fois, cette mise à jour peut être divisée en deux classes supplémentaires.
Ou nous changeons certaines caractéristiques physiques de cet objet (je pense que chaque développeur Oracle a parfois rencontré le fait que son index tombait, il a dû reconstruire l'index à la volée). Ou, disons que nous avons introduit de nouvelles sections dans nos tableaux, c'est-à-dire qu'aucun arrêt ne se produira. Et cet endroit très problématique est un changement dans la logique de l'application.
Alors, qu'est-ce que la redéfinition basée sur l'édition a à voir avec cela? Et cette technologie - il s'agit simplement de mettre à jour l'application en ligne, à la volée, sans affecter le travail des utilisateurs.

Quelles sont les exigences pour cette mise à jour en ligne? Nous devons le faire inaperçu par l'utilisateur, c'est-à-dire que tout doit rester en état de fonctionnement, toutes les applications. À condition qu'une telle situation puisse se produire lorsque l'utilisateur s'est assis, a commencé à travailler et se souvenait très bien qu'il avait une réunion urgente ou qu'il devait amener la voiture au service. Il s'est levé, s'est enfui à cause de son lieu de travail. Et à ce moment-là, nous avons en quelque sorte mis à jour notre application, la logique du travail a changé, de nouveaux utilisateurs se sont déjà connectés à nous, les données ont commencé à être traitées d'une nouvelle manière. Il nous faut donc à terme assurer l'échange de données entre la version originale de l'application et la nouvelle version de l'application. Les voici, deux exigences qui sont mises en avant pour les mises à jour en ligne.

Qu'est-ce qui est proposé comme solution? À partir de la version 11.2 de la version Oracle, la technologie de redéfinition basée sur l'édition est introduite et des concepts tels que l'édition, les objets éditables, la vue d'édition, le déclencheur interédition sont introduits. Nous nous sommes permis une traduction comme «versioning». En général, la technologie EBR avec une certaine extension pourrait être appelée versioning des objets SGBD à l'intérieur du SGBD lui-même.
Alors, quelle est l'édition en tant qu'entité?
Il s'agit d'une sorte de conteneur à l'intérieur duquel vous pouvez modifier et définir le code. À l'intérieur de votre propre portée, à l'intérieur de votre propre version. Dans ce cas, les données seront modifiées et écrites uniquement dans les structures visibles dans l'édition actuelle. Les représentations de versioning seront responsables de cela, et nous examinerons leur travail plus loin.

Voilà à quoi ressemble la technologie à l'extérieur. Comment ça marche? Pour commencer - au niveau du code. Nous aurons notre application d'origine, la version 1, dans laquelle il existe des algorithmes qui traitent nos données. Lorsque nous comprenons que nous devons mettre à niveau, lors de la création d'une nouvelle édition, les événements suivants se produisent: tous les objets qui traitent le code sont hérités de la nouvelle édition ... En même temps, dans ce bac à sable nouvellement créé, nous pouvons nous amuser comme nous voulons, de manière invisible pour l'utilisateur: nous pouvons changer quel travail fonctions, procédures; changer le paquet; nous pouvons même refuser d'utiliser n'importe quel objet.
Que va-t-il se passer? La version originale reste inchangée, elle reste disponible pour l'utilisateur et toutes les fonctionnalités sont disponibles. Dans la version que nous avons créée, dans la nouvelle édition, les objets qui n'ont pas été modifiés sont restés inchangés, c'est-à-dire hérités de la version d'origine de l'application. Avec le bloc que nous avons abordé, les objets sont mis à jour dans la nouvelle version. Et bien sûr, lorsque vous supprimez un objet, il ne nous est pas disponible dans la nouvelle version de notre application, mais il reste fonctionnel dans la version d'origine. C'est aussi simple que cela fonctionne au niveau du code.

Qu'arrive-t-il aux structures de données et qu'est-ce que la vue de versioning a à voir avec cela?

Étant donné que par structures de données, nous entendons une table et une vue de versionnage, il s'agit en fait d'un shell (j'ai appelé moi-même la «recherche» éthologique de notre table), qui est une projection sur les colonnes d'origine. Lorsque nous comprenons que nous devons modifier le fonctionnement de notre application et, par exemple, ajouter des colonnes à la table, ou même interdire leur utilisation, nous créons une nouvelle vue de gestion des versions dans notre nouvelle version.

En conséquence, nous n'y utiliserons que l'ensemble des colonnes dont nous avons besoin, que nous traiterons. Ainsi, dans la version d'origine de l'application, les données sont écrites dans l'ensemble défini dans cette étendue. La nouvelle application écrit dans l'ensemble de colonnes défini dans sa portée.

Les structures sont claires, mais qu'advient-il des données? Et comment tout cela est interconnecté, nous avions des données stockées dans les structures d'origine. Lorsque nous comprenons que nous avons un certain algorithme qui nous permet de convertir les données de la structure d'origine et de décomposer ces données en une nouvelle structure, cet algorithme peut être placé dans les déclencheurs dits de version croisée. Ils visent simplement à voir les structures de différentes versions de l'application. Autrement dit, sous réserve de la disponibilité d'un tel algorithme, nous pouvons l'accrocher sur une table. Dans ce cas, les données seront transformées des structures d'origine vers de nouvelles, et les déclencheurs progressifs en seront responsables. À condition que nous devions assurer le transfert des données vers l'ancienne version, là encore, sur la base d'un certain type d'algorithme, les déclencheurs inverses seront responsables de cela.
Que se passe-t-il lorsque nous décidons que notre structure de données a changé et que nous sommes prêts à travailler en mode parallèle à la fois pour l'ancienne version de l'application et pour la nouvelle version de l'application? Nous pouvons simplement initialiser le remplissage de nouvelles structures avec une mise à jour inactive. Après cela, nos deux versions de l'application deviennent disponibles pour être utilisées par l'utilisateur. La fonctionnalité reste pour les anciens utilisateurs de l'ancienne version de l'application; pour les nouveaux utilisateurs, la fonctionnalité proviendra de la nouvelle version de l'application.
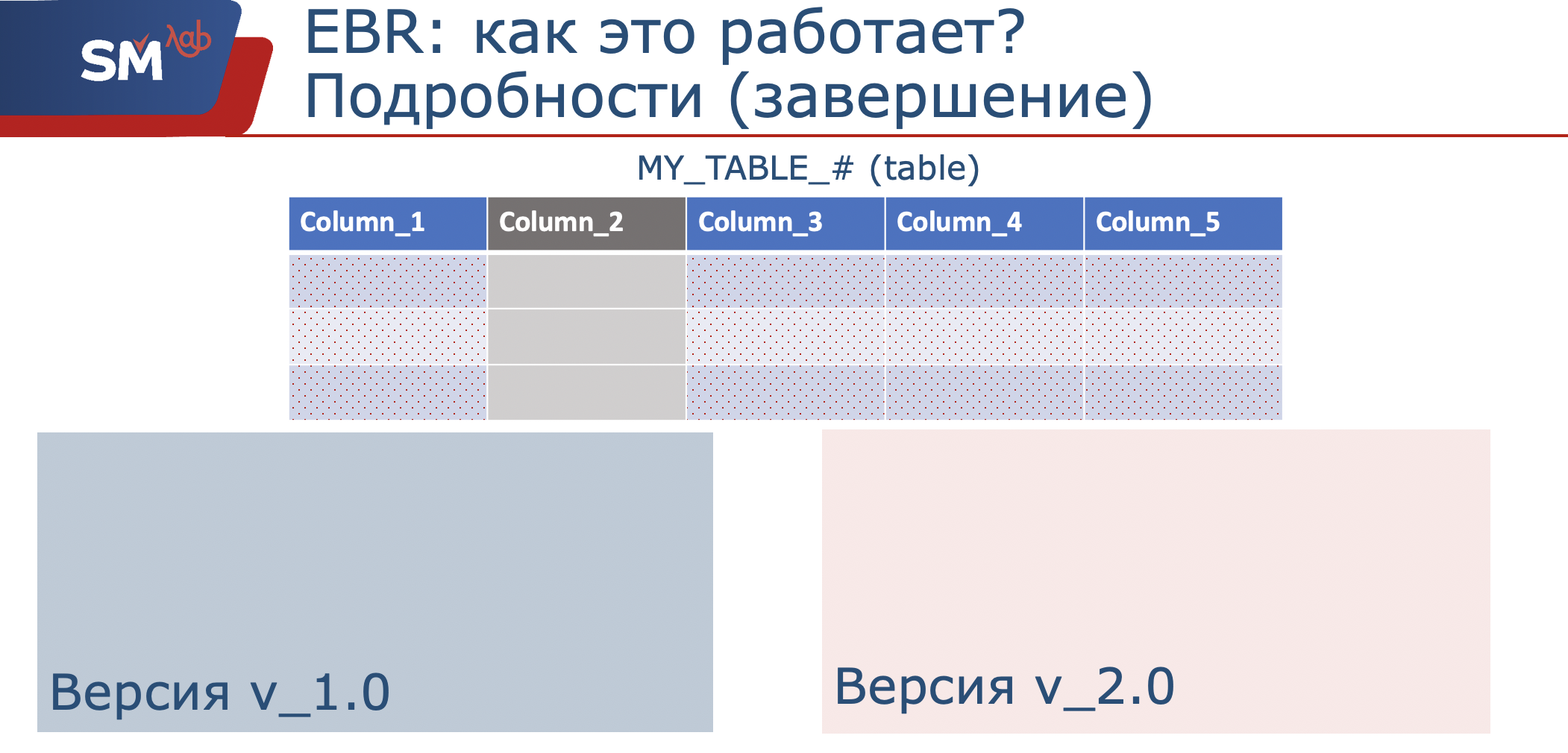
Lorsque nous avons réalisé que les utilisateurs de l'ancienne application étaient tous déconnectés, cette version pouvait être masquée. Peut-être même que la structure des données a été modifiée. Nous nous souvenons qu'avec nous, la vue de gestion des versions dans la nouvelle version ne regardera déjà que l'ensemble des colonnes 1, 3, 4, 5. Eh bien et en conséquence, si nous n'avons pas besoin de cette structure, elle peut être supprimée. Voici un bref résumé de son fonctionnement.

Quelles sont les restrictions imposées? C'est-à-dire, bravo Oracle, excellent Oracle, excellent Oracle: ils ont trouvé une chose cool. La première limitation pour le moment concerne les objets de type versionné, ce sont des objets PL / SQL, c'est-à-dire des procédures, des packages, des fonctions, des déclencheurs, etc. Les synonymes sont versionnés et les vues sont versionnées.
Ce qui n'est pas versionné et ne le sera jamais, ce sont les tables et les index, les vues matérialisées. Autrement dit, dans la première version, vous et moi ne modifions que les métadonnées et pouvons en stocker des copies autant que vous le souhaitez ... en fait, un nombre limité de copies de ces métadonnées, mais plus à ce sujet plus tard. Le second concerne les données utilisateur, et leur réplication nécessiterait beaucoup d'espace disque, ce qui n'est pas logique et est très coûteux.

La prochaine limitation est que les objets de schéma seront entièrement versionnés si et seulement s'ils appartiennent à l'utilisateur autorisé par la version. En fait, ces privilèges pour l'utilisateur ne sont qu'une sorte de marque dans la base de données. Vous pouvez accorder ces autorisations avec la commande habituelle. Mais j'attire votre attention sur le fait que cette action est irréversible. Par conséquent, ne retroussons pas immédiatement nos manches, saisissons tout cela sur le serveur de combat, et nous allons d'abord tester.
La prochaine limitation est que les objets non versionnés ne peuvent pas dépendre des objets versionnés. Eh bien, c'est assez logique. Au minimum, nous ne comprendrons pas quelle édition, quelle version de l'objet à regarder. Sur ce point, je voudrais attirer l'attention, car nous avons dû rivaliser avec ce moment.
Ensuite. Les vues versionnées appartiennent au propriétaire du schéma, au propriétaire de la table et uniquement dans chaque version. À la base, une vue versionnée est un wrapper de table, il est donc clair qu'elle doit être unique dans chaque version de l'application.
Ce qui est également important, le nombre de versions dans la hiérarchie peut être 2000. Très probablement, cela est dû au fait que vous ne chargez pas le dictionnaire d'une manière ou d'une autre. J'ai dit initialement que les objets, lors de la création d'une nouvelle édition, sont hérités. Maintenant, cette hiérarchie est construite exclusivement linéaire - un parent, un descendant. Il y aura peut-être une sorte d'arborescence, je vois certaines conditions préalables à cela dans le fait que vous pouvez définir la commande de création de version comme héritier d'une édition particulière. Il s'agit actuellement d'une hiérarchie strictement linéaire et le nombre de maillons de cette chaîne est de 2000.
Il est clair qu'avec certaines mises à jour fréquentes de notre application, ce nombre pourrait être épuisé ou dépassé, mais à partir de la 12ème version d'Oracle, les éditions extrêmes créées dans cette chaîne peuvent être supprimées à condition qu'elles ne soient plus utilisées.

J'espère que vous comprenez maintenant à peu près comment cela fonctionne. Si vous décidez - «Oui, nous voulons y toucher» - que faut-il faire pour passer à l'utilisation de cette technologie?
Tout d'abord, vous devez déterminer la stratégie d'utilisation. De quoi s'agit-il? Comprenez à quelle fréquence nos structures de table changent, si nous devons utiliser des vues versionnées, en particulier si nous avons besoin de déclencheurs multi-versions pour assurer les changements de données. Ou nous ne ferons que la version de notre code PL / SQL. Dans notre cas, lorsque nous testions, nous avons vu que des tables changeaient toujours, donc nous utiliserons probablement aussi des vues versionnées.
En outre, naturellement, le schéma sélectionné bénéficie de privilèges versionnés.
Après cela, nous renommons la table. Pourquoi est-ce fait? Juste pour protéger nos objets de code PL / SQL de la modification des tables.
Nous avons décidé de lancer un symbole pointu à la fin de nos tableaux, étant donné la limite de 30 caractères. Après cela, les vues de version sont créées avec le nom de la table d'origine. Et déjà, ils seront utilisés dans le code. Il est important que dans la première version vers laquelle nous passons, la vue versionnée soit un ensemble complet de colonnes dans la table source, car les objets de code PL / SQL peuvent accéder à toutes ces colonnes exactement de la même manière.
Après cela, nous l'emportons sur les déclencheurs DML des tables aux vues versionnées (oui, les vues versionnées nous permettent d'y accrocher des déclencheurs). Peut-être que nous retirons les concessions des tables et les donnons aux vues nouvellement créées ... En théorie, tous ces points suffisent, il suffit de recompiler le code PL / SQL et les vues dépendantes.
Je-et-et-et-et ... Naturellement, des tests, des tests et autant de tests que possible. Pourquoi des tests? Cela ne pouvait pas être aussi simple. De quoi avons-nous trébuché?
C'est de cela que parlera
mon deuxième article .