Je vais essayer de vous dire à quel point il est facile d'obtenir des résultats intéressants en appliquant simplement une approche complètement standard du tutoriel du cours de machine learning aux données qui ne sont pas les plus utilisées en Deep Learning. L'essence de mon article est qu'il peut s'agir de chacun de nous, il vous suffit de regarder l'ensemble des informations que vous connaissez bien. Pour cela, en effet, il est beaucoup plus important de bien comprendre vos données que d'être un expert des dernières structures de réseaux de neurones. C'est, à mon avis, que nous sommes à ce point d'or dans le développement du DL, quand d'un côté c'est déjà un outil qui peut être utilisé sans avoir besoin d'être un doctorant, et de l'autre il y a encore beaucoup de domaines où personne ne l'a vraiment utilisé, si vous regardez Un peu plus loin que les thèmes traditionnels.

En lisant des articles et en passant en regardant comment le machine learning se développe, vous et moi pouvons facilement avoir l'impression que ce train passe. En effet, si vous suivez les cours les plus connus (par exemple, Andrew Ng ) ou la plupart des articles sur Habré de la même excellente communauté d' Open Data Science, vous vous rendez très vite compte que sans creuser les profondeurs de la mémoire du savoir universitaire en mathématiques supérieures il n'y a rien à faire, enfin, du moins certains des résultats raisonnables (même dans des exemples de « jouets ») ne peuvent être obtenus qu'après plusieurs semaines d'étude de la théorie de l'éponge et des différentes manières de la mettre en œuvre. Mais souvent, vous en voulez un autre, vous voulez avoir un outil qui remplit sa fonction, qui résout une certaine classe de problèmes, de sorte que, en l'appliquant dans votre domaine, obtenez le résultat. En effet, dans d'autres domaines, tout est exactement le cas, si vous, par exemple, écrivez un jeu et que votre tâche est d'assurer le transfert d'informations d'un joueur vers un serveur, alors vous n'étudiez pas la théorie des graphes, ne savez pas comment optimiser la connectivité pour que vos paquets atteignent plus rapidement - vous prenez un outil (bibliothèque, framework) qui le fait pour vous et se concentre sur ce qui est unique à une tâche particulière (par exemple, quel type d'informations vous devez transférer dans les deux sens). Pourquoi n'en est-il pas ainsi pour l'apprentissage en profondeur?
En fait, nous sommes maintenant au bord du temps où cela devient presque comme ça . Et pour moi, j'ai presque trouvé cet outil oh - fast.ai. Une excellente bibliothèque et un cours encore plus raide, dont le principe entier est juste construit de haut en bas: d'abord résoudre des problèmes réels, souvent au niveau de la précision de la prédiction des modèles State Of The Art, jusqu'à la structure interne de la bibliothèque et la théorie qui la sous-tend.
Bien sûr, tout n'est pas si simple.Anticipant les accusations de manque de professionnalisme et la superficialité de mes connaissances (ce qui, bien sûr, est plus vrai qu'improbable), je veux faire une réserve tout de suite. Faut-il étudier la théorie, regarder ces conférences très fondamentales, se souvenir du calcul matriciel, etc.? Bien sûr que oui. Et plus vous approfondissez le sujet, plus vous en aurez besoin et vous devrez vous accrocher aux sources primaires. Mais plus l'immersion sera consciente, plus il sera facile de comprendre exactement comment ces principes fondamentaux affectent le résultat. Tout l'intérêt du principe descendant est précisément qu'il doit être fait après. Après avoir écrit quelque chose de tangible que vous pouvez montrer à vos amis. Après vous être plongé suffisamment dans le sujet et cela vous a fasciné. Et la théorie du savoir vous dépassera, elle est juste présentée au moment même où il sera plus facile pour vous de la corréler avec ce que vous avez déjà fait. Pour expliquer pourquoi et comment cela fonctionne réellement.
Je suis plus que sûr que quelqu'un est plus à l'aise avec l'approche ascendante traditionnelle. Et c'est bien qu'il y ait les deux façons, l'essentiel est que nous nous rencontrions au milieu
Avec un tel ensemble de connaissances, j'ai décidé d'appliquer DL à un sujet qui m'intéresse depuis longtemps et de voir à quoi cela peut conduire. Et, bien sûr, la première chose qui m'est venue à l'esprit était le football. Et quand j'ai trouvé ces merveilleuses statistiques de transfert sur kaggle, le choix est devenu d'autant plus évident.
Un peu sur ces données. Ils contiennent des informations sur qui et où a évolué vers le football européen au cours des 10 dernières années. Il y a des informations sur les clubs, les statistiques des joueurs, les ligues auxquelles ils participent, les entraîneurs et les agents, et bien plus encore (il y a plus d'une centaine de domaines différents au total). Les données sont très intéressantes, mais est-il possible de déterminer combien un joueur devrait en coûter?
Si vous y réfléchissez, le prix d'un joueur dépend d'un grand nombre de facteurs. En même temps, c'est super, et moi (sinon la plupart) leur part est tout simplement non formalisable. Comment comprendre que le club vient de vendre le joueur à un prix élevé, a besoin d'un attaquant et est tout à fait prêt à payer trop cher pour lui; comment comprendre qu'un nouvel entraîneur est venu et nécessite la mise à jour de la liste; comment comprendre que le principal défenseur du club a remarqué le grand et qu'il a commencé à jouer sans enthousiasme, exigeant un transfert? Tout cela affecte fondamentalement le montant d'une transaction, mais n'est pas présenté dans les données. De là, mes attentes initiales quant à l'exactitude d'une telle prévision étaient faibles.
Je suis un faux programmeurÀ ce stade, il est temps d'insérer la clause de non-responsabilité standard que # ne # pas un # , je ne gagne pas d'argent avec cela, donc mon code est terrible, et il est très probable qu'il puisse (et devrait?) Être réécrit beaucoup mieux, mais puisque la tâche consistait à enquêter sur l'idée et (pas ?) Confirmez la théorie, alors le code est ce qu'il est :)
Modèle
J'ai commencé par exclure les transferts de moins d'un million de dollars, qui sont trop chaotiques. Il a ensuite rassemblé toutes les données dans un grand tableau avec cent et demi champs, dans lequel, pour chaque transfert, il y avait toutes les informations disponibles à son sujet (à la fois sur le transfert lui-même, le joueur et ses statistiques, ainsi que sur les clubs qui y participent, les ligues, etc.). )
Regardons les étapes de la création du modèle :
Après avoir terminé toutes les importations Python et chargé la table de transfert dénormalisée, la première chose que nous devons déterminer est lequel des champs nous considérons comme numériques et lesquels sont catégoriques. C'est un sujet très intéressant en soi, vous pouvez en parler dans les commentaires, mais pour gagner du temps, je décris simplement la règle que j'utilise: par défaut, je considère tous les champs catégoriques, à l'exception de ceux qui sont représentés par des nombres à virgule flottante ou ceux où le nombre de valeurs différentes est suffisamment grand.
Dans ce contexte, par exemple, je considère l'année de transfert comme catégorique, bien qu'il s'agisse initialement d'un nombre, car le nombre de valeurs différentes est faible ici (10 - de 2008 à 2018). Mais, par exemple, la performance du joueur la saison dernière (qui est représentée par le nombre moyen de ses buts par match) est un flottant et peut prendre presque n'importe quelle valeur, donc je la considère comme numérique.
cat_vars_tpl = ('season','trs_year','trs_month','trs_day','trs_till_deadline', 'contract_left_months', 'contract_left_years','age', 'is_midseason','is_loan','is_end_of_loan', 'nat_national_name','plr_position_main', 'plr_other_positions','plr_nationality_name', 'plr_other_nationality_name','plr_place_of_birth_country_name', 'plr_foot','plr_height','plr_player_agent','from_club_name','from_club_is_first_team', 'from_clb_place','from_clb_qualified_to','from_clb_is_champion','from_clb_is_cup_winner', 'from_clb_is_promoted','from_clb_lg_name','from_clb_lg_country','from_clb_lg_group', 'from_coach_name', 'from_sport_dir_name', 'to_club_name','to_club_is_first_team','to_clb_place', 'to_clb_qualified_to', 'to_clb_is_champion','to_clb_is_cup_winner','to_clb_is_promoted', 'to_clb_lg_name','to_clb_lg_country', 'to_clb_lg_group','to_coach_name', 'to_sport_dir_name', 'plr_position_0','plr_position_1','plr_position_2', 'stats_leag_name_0', 'stats_leag_grp_0', 'stats_leag_name_1', 'stats_leag_grp_1', 'stats_leag_name_2', 'stats_leag_grp_2') cont_vars_tpl = ('nat_months_from_debut','nat_matches_played','nat_goals_scored','from_clb_pts_avg', 'from_clb_goals_diff_avg','to_clb_pts_avg','to_clb_goals_diff_avg','plr_apps_0', 'plr_apps_1','plr_apps_2','stats_made_goals_0','stats_conc_gols_0','stats_cards_0', 'stats_minutes_0','stats_team_points_0','stats_made_goals_1','stats_conc_gols_1', 'stats_cards_1','stats_minutes_1','stats_team_points_1','stats_made_goals_2', 'stats_conc_gols_2','stats_cards_2','stats_minutes_2','stats_team_points_2', 'pop_log1p')
Ensuite, après avoir indiqué explicitement ce que nous prévoyons - le montant du transfert ( fee ), nous divisons au hasard nos données en 2 parties de 80% et 20%. Sur le premier d'entre eux, nous enseignerons à notre réseau de neurones, sur l'autre - pour vérifier l'exactitude de la prédiction.
ln = len(df) valid_idx = np.random.choice(ln, int(ln*0.2), replace=False)
Lors de la dernière étape préparatoire, nous devons choisir comment mesurer la plausibilité de nos prévisions. Ensuite, je n'ai pas choisi la métrique la plus standard dans la partie locale de l'univers - la médiane du pourcentage d'erreur ( MdAPE ). Ou, plus simplement, combien de pour cent (le prix absolu d'un transfert peut différer par ordre de grandeur), nous ferons probablement une erreur dans le prix d'un transfert pris au hasard. Il m'a semblé le plus proche de ce que signifie exactement l'expression «précision du système de prédiction de transfert».
Il est maintenant temps, en fait, de commencer à apprendre le réseau.
data = (TabularList.from_df(df, path=path, cat_names=cat_vars, cont_names=cont_vars, procs=procs) .split_by_idx(valid_idx) .label_from_df(cols=dep_var, label_cls=FloatList, log=True) .databunch(bs=BS)) learn = tabular_learner(data, layers=layers, ps=layers_drop, emb_drop=emb_drop, y_range=y_range, metrics=exp_mmape, loss_func=MAELossFlat(), callback_fns=[CSVLogger]) learn.fit_one_cycle(cyc_len=cycles, max_lr=max_lr, wd=w_decay)
Précision de prédiction

Validation Error = 0.3492 signifie qu'après une formation sur un nouvel validation set données ( validation set , validation set ), le modèle en moyenne (médiane) se trompe de 34% par rapport au prix de transfert réel. Et nous l'avons obtenu uniquement à la suite de plusieurs lignes de code tirées du didacticiel.
Erreur 34%, est-ce beaucoup ou un peu? Tout est relatif. La seule source comparable, dont les données peuvent être considérées comme une « prédiction » du montant du transfert, est bien entendu transfermarkt . Heureusement, il y a un champ dans les données de kaggle qui montre comment ce site a évalué un joueur au moment du transfert, et cela peut être comparé. Il convient de noter ici que transfermarkt n'a jamais prétendu que sa market value était le prix de transfert probable. Au contraire, ils ont souligné qu'il s'agit plutôt de la « valeur honnête » de l'un ou l'autre joueur. Et combien d'argent un club particulier paiera pour cela dans une situation particulière est une chose très individuelle et peut fluctuer dans un sens ou dans un autre dans des limites très larges. Mais c'est le meilleur que nous ayons, comparons .

Erreur de Transfermarkt - 35% , notre modèle - 35% . Très étrange et, pour être honnête, très méfiant.
À ce stade, je propose de réfléchir à nouveau. Un site avec une histoire énorme, créé juste pour montrer la `` valeur '' des joueurs, qui repose sur la pleine puissance de l'effet de foule (il tire la valeur des évaluations des visiteurs ordinaires et des professionnels du marché) et la connaissance des experts d'une part, et le modèle, qui ne sait rien du football, ne voit rien à part les données que nous lui avons fournies (et en dehors de ces données dans le monde réel, il y a encore beaucoup de choses que les gens avec transfermarkt prennent en compte), d'autre part, ils montrent la même erreur . De plus, notre modèle permet également de prévoir le prix de location du joueur, ce que la market value , pour des raisons évidentes, ne montre pas (compte tenu de ces transactions, le résultat de transfermarkt était encore pire ).
Honnêtement, je pense toujours que j'ai une sorte d'erreur ici, tout est trop beau pour être vrai. Mais, néanmoins, allons plus loin.
Un moyen facile de vous tester est d'essayer de faire la moyenne des prédictions à partir de 2 sources (modèles et transfermarkt). Si les prédictions sont vraiment indépendantes les unes des autres et qu'il n'y a pas d'erreur gênante, alors le résultat devrait s'améliorer.

En effet, la moyenne des prévisions réduit l'erreur de prédiction à 32% (!). Cela peut sembler un peu, mais nous devons comprendre que nous filtrons un peu plus d'informations à partir des données, qui sont si serrées au maximum.
Mais ce que nous ferons ensuite, à mon avis, est encore plus surprenant et intéressant, bien qu'il dépasse le cadre du tutoriel fast.ai.
Importance des fonctionnalités
Les réseaux de neurones, pour ne pas dire qu'ils ne sont absolument pas mérités, sont souvent considérés comme une «boîte noire». Nous savons quelles données nous pouvons y mettre, nous pouvons obtenir les prédictions du modèle, nous pouvons même évaluer dans quelle mesure ses prédictions sont vraies en moyenne. Mais nous ne pouvons pas expliquer par quels critères le modèle a «pris» telle ou telle décision. La structure interne du réseau lui-même est si complexe, et surtout, non linéaire, qu'il est impossible de retracer directement toute la chaîne de prise de décision et d'en tirer des conclusions significatives du monde réel. Mais je veux vraiment. J'aimerais comprendre ce qui influence le plus le montant du transfert.
Eh bien, nous ne monterons pas à l'intérieur du réseau. Mais que signifie l'importance de chaque champ, appelons-le Feature Importance (FI)? Une option pour comprendre l '«importance» consiste à calculer combien les choses vont empirer si nous n'avions pas ce champ. Et c'est précisément ce que nous pouvons mesurer. Nous avons maintenant un outil qui fournit des prévisions sur n'importe quel ensemble de données. Donc, si nous calculons simplement combien l'erreur de prédiction augmentera lorsque nous substituerons des données aléatoires sur le terrain, alors nous pouvons simplement estimer dans quelle mesure (le champ) affecte le résultat final, ce qui signifie à quel point elle est importante. Pour rester dans la distribution réelle des données, le champ sera rempli non seulement avec des nombres aléatoires, mais avec des valeurs mélangées de manière aléatoire (c'est-à-dire que nous mélangerons simplement la colonne, par exemple, `` année de transfert '', dans le tableau d'origine). Pour la fidélité, ce processus peut être effectué plusieurs fois pour chaque champ en faisant la moyenne du résultat. Tout est assez simple. Voyons maintenant à quel point cela donne le résultat:
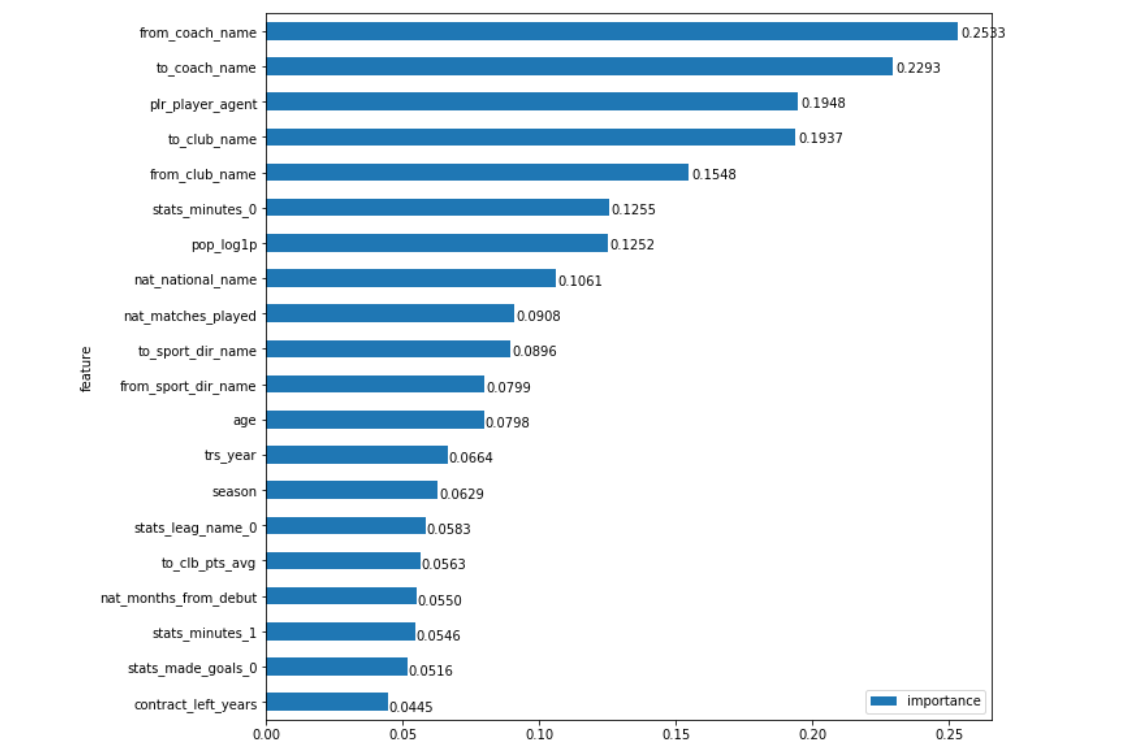
Mon instinct dit: "Oui et non!"
D'un côté, les champs que vous vous attendez à voir étaient en haut: les entraîneurs d'équipe d'où et où from_coach_name allé from_coach_name joueur ( from_coach_name , to_coach_name ), les clubs eux-mêmes qui ont participé au transfert ( from_club_name , to_club_name ), l'agent du joueur ( plr_player_agent ), sa renommée dans les réseaux sociaux ( pop_log1p ) etc. Mais d'un autre côté ... Intuitivement, il ne semble pas que les noms des entraîneurs devraient avoir plus de poids dans le prix de transfert que, par exemple, les clubs eux-mêmes (nous savons bien que le Benfica conditionnel est capable de vendre ses joueurs à un prix élevé). La marque d'un entraîneur influence-t-elle plus fortement le prix que la marque du club? L'arrivée du conditionnel Mancini oblige-t-elle tellement le club à surpayer? Qu'est-ce que c'est, le cas quand les données nous donnent de nouvelles informations, légèrement contre-intuitives, ou juste une erreur dans le modèle?
Faisons les choses correctement. En regardant de près le graphique, l'œil s'accroche rapidement à une chose étrange. Juste en dessous du centre, il y a 2 champs très trs_year et season trs_year , ils représentent l'année du transfert et la saison au cours de laquelle la transition sera effectuée (en général, ils peuvent ne pas coïncider, bien que cela ne se produise pas si souvent). Premièrement, il semble qu'ils devraient être plus élevés, nous savons combien les prix pour les joueurs de football ont augmenté ces dernières années, et deuxièmement, ils signifient évidemment la même chose. Que faire à ce sujet? Résumez simplement leur importance? Pas le fait que cela puisse être fait! Mais ce que nous pouvons certainement faire, c'est appliquer la même approche (mélanger les valeurs) non pas séparément à ces deux domaines, mais en groupe. Autrement dit, mesurez comment l'erreur va changer s'il y a des valeurs aléatoires dans ces 2 colonnes à la fois. Eh bien, puisque nous l'avons fait au fil des ans, nous devons voir si nous avons d'autres domaines qui sont tout aussi «connectés».
Par exemple, pour un club, nous avons plusieurs paramètres: le club lui-même ( club_name ), ainsi qu'un ensemble d'informations à ce sujet - de quelle ligue, pays, etc. ( club_is_first_team , clb_lg_name , clb_lg_country , clb_lg_group ). Ce n'est que dans certains cas que nous voulons savoir dans quelle mesure cela affecte le prix, par exemple, le pays dans clb_lg_country le joueur se rend séparément ( clb_lg_country ), le plus souvent, il est important pour nous de comprendre quel est le poids total du champ `` club '', qui est déjà dans un certain pays, une ligue, etc. .
Ainsi, nous pouvons combiner tous les champs en groupes en fonction du contenu sémantique. Cela nous aidera tout simplement à connaître le domaine et le bon sens, ainsi que la «proximité» calculée des fonctionnalités. Ce dernier montre simplement comment les champs sont en corrélation les uns avec les autres, c'est-à-dire dans quelle mesure il est possible de les considérer comme un seul groupe.
En appliquant cette approche, nous obtenons un graphique encore plus intuitif de l'importance des champs:
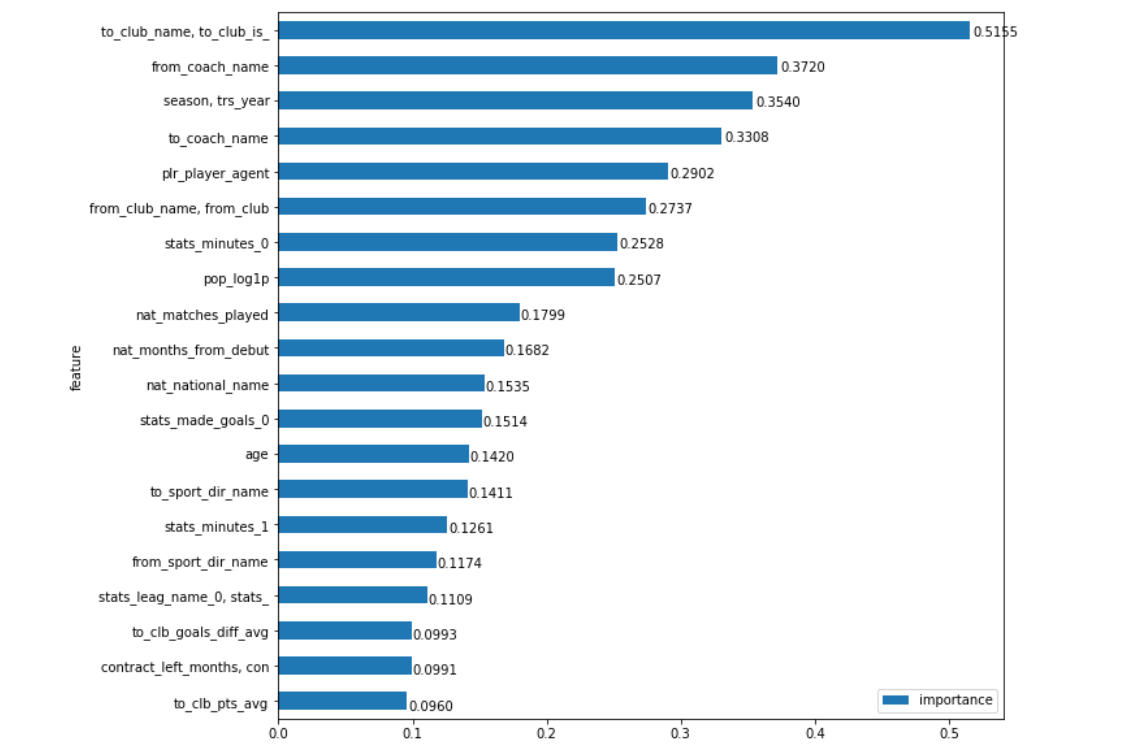
Voilà. Exactement quel club le joueur achète le plus affecte le montant du transfert, avec une très bonne marge. Hi Man City, Barcelone, Zenit et, par exemple, le même Benfica (après tout, « influence fortement » la même chose sur le fait que certains clubs, au contraire, peuvent acheter des joueurs de qualité moins cher que le «marché»). Il me semble que la chose la plus intéressante dans le travail avec les données est que lorsqu'elles sont obtenues, les conclusions sont évidentes d'une part (enfin, je doutais que l'acheteur du club ait eu la plus grande influence sur le montant du transfert), et d'autre part, c'est un peu surprenant (et les candidats pour le premier le lieu, intuitivement, pourrait être quelque peu, et la séparation du second ne semblait pas si importante)
Il y a encore beaucoup de choses intéressantes à découvrir. Par exemple, le nom de l'entraîneur d'où le joueur est acheté, du point de vue du modèle, est encore plus important que le club ... Que la différence soit considérablement réduite. Une explication logique à cela peut être trouvée en principe (bien que parfois elle puisse être trouvée pour n'importe quoi). Il y a des entraîneurs (Guardiola, Klopp, Benitez, Berdyev) qui adhèrent à une certaine idéologie du jeu dans différents clubs, ce qui révèle mieux ou vice versa rend certaines positions sur le terrain moins lumineuses, et la visibilité du joueur affecte considérablement son prix. À propos des clubs, pour ainsi dire, presque impossible. Et le fait que nous voyons des entraîneurs qui ne s'écartent pas radicalement de leurs principes du jeu beaucoup plus souvent que les clubs changent d'entraîneurs, mais en restant dans la même philosophie (par exemple, désinvolte, sauf que l'Ajax vient à l'esprit, et Barcelone est très discutable), parle de que, peut-être, certains managers révèlent des joueurs plus stables que les clubs. Bien qu'ici, je ne tiendrais pas fermement à ma déclaration.
Parmi les indicateurs purement statistiques, le montant le plus élevé est simplement le temps passé par un joueur sur le terrain l'année dernière dans sa compétition principale ( stats_minutes_0 ). C'est juste, tout à fait logique, car combien ce joueur était le «principal» dans son club la saison dernière semble être un indicateur statistique plus universel de son succès que d'autres - par exemple, le nombre de buts marqués ou de cartes reçues.
La popularité du joueur ( pop_log1p ) ferme ce groupe de 8 paramètres les plus importants. Il convient de rappeler que les données que nous avons présentées au cours des 10 dernières années. Je pense que l'importance de ce domaine serait plus élevée si nous considérions les 5 dernières années, et pour la valeur moyenne au cours de la dernière décennie, c'est un résultat tout à fait compréhensible, surtout compte tenu de l'écart par rapport à la prochaine place.
Eh bien, la dernière chose sur laquelle je voudrais attirer l'attention est l'importance du champ agent ( plr_player_agent ). Je laisserai cela sans commentaire, car si vous pouvez casser les marges de copies dans les litiges concernant le (in) besoin d'agents, alors il n'y a aucun doute sur le degré de leur influence sur le marché des transferts moderne (bien que le modèle suggère de ne pas le surestimer).

Soit dit en passant, ce qui est peut-être le plus intéressant dans cette méthode d'analyse est son accessibilité: il n'est pas nécessaire de créer un modèle « idéal » pour obtenir des informations sur l'importance des paramètres. Dans de nombreux cas, il suffit que cela prédit tout au moins, soit statistiquement significativement différent de lancer une pièce, et vous obtiendrez déjà des résultats qui contiennent souvent des informations intéressantes ou vous indiquent de quel côté vous pouvez consulter les données.
Ensuite, il est temps d'arrondir, afin de ne pas augmenter le texte si surchargé. En quittant, je voudrais encore une fois inviter tous ceux qui sont intéressés par le sujet à essayer (le meilleur, à mon avis, pour les débutants) le cours de Deep Learning - fast.ai et à appliquer les connaissances acquises dans `` votre domaine d'expertise '', il est probable que vous serez le premier là-bas :)
Et si vous l'aimez, je vais essayer de maîtriser la deuxième partie du texte sur mes expériences dans lesquelles le modèle utilisant un outil tout aussi puissant - Dépendance partielle vous dira: quel client de l'agence est le mieux pour devenir joueur de football, quels clubs ont la politique de transfert la plus efficace, quel entraîneur augmente le mieux le coût des joueurs (en plus des candidats évidents, il existe de nombreuses «marques» peu promues qui valent clairement le détour) et bien plus encore.
Partie 2 - Modèle de transferts de soccer: creuser plus profondément