La capacité de travailler à l'intérieur d'un système de contrôle de version est une compétence dont chaque programmeur a besoin. Souvent, il peut sembler que creuser dans Git et comprendre ses composants internes est une perte de temps supplémentaire et les tâches de base peuvent être résolues grâce à un ensemble de commandes de base.
L'équipe AppsCast, bien sûr, voulait en savoir plus, et pour des conseils sur l'application pratique de toutes les fonctionnalités de Git, les gars se sont tournés vers
Yegor Andreyevich de Square.
 Daniil Popov
Daniil Popov : Bonjour à tous. Aujourd'hui, Yegor Andreyevich de Square s'est joint à nous.
Egor Andreyevich : Bonjour à tous. Je vis au Canada et je travaille pour Square, une entreprise de logiciels et de matériel informatique pour l'industrie financière. Nous avons commencé avec des terminaux pour accepter les paiements par carte de crédit, maintenant nous offrons des services aux propriétaires d'entreprise. Je travaille sur un produit Cash App. Il s'agit d'une banque mobile qui vous permet d'échanger de l'argent avec des amis, de commander une carte de débit pour le paiement en magasin. L'entreprise possède de nombreux bureaux dans le monde et le bureau canadien compte environ 60 programmeurs.
Daniil Popov : Dans l'environnement des développeurs Android,
Square est connu pour ses projets open source qui sont devenus les standards de l'industrie: OkHttp, Picasso, Retrofit. Il est logique qu'en développant de tels outils ouverts à tous, vous travaillez beaucoup avec Git. Nous aimerions en parler.
Qu'est-ce que Git
Egor Andreevich : J'utilise Git depuis longtemps comme outil, et à un moment donné, il est devenu intéressant pour moi d'en savoir plus.
Git est un système de fichiers simplifié, au-dessus duquel se trouve un ensemble d'opérations pour travailler avec le contrôle de version.
Git vous permet d'enregistrer des fichiers dans un format spécifique. Chaque fois que vous écrivez un fichier, Git renvoie la clé de votre objet -
hachage .
Daniil Popov : Beaucoup de gens ont remarqué que le référentiel a un répertoire caché magique
.git . Pourquoi est-il nécessaire? Puis-je le supprimer ou le renommer?
Egor Andreevich : La création d'un référentiel est possible via la commande
git init . Il crée le répertoire
.git que Git utilise pour contrôler les fichiers.
.Git stocke tout ce que vous faites dans votre projet, uniquement dans un format compressé. Par conséquent, vous pouvez restaurer le référentiel à partir de ce répertoire.
Alexei Kudryavtsev : Il s'avère que votre dossier de projet est l'une des versions du dossier Git développé?
Egor Andreevich : Selon la branche sur laquelle vous vous trouvez, git restaure un projet avec lequel vous pouvez travailler.
Alexei Kudryavtsev : Que contient le dossier?
Egor Andreevich : Git crée des dossiers et fichiers spécifiques. Le dossier le plus important est .git / objects, où tous les objets sont stockés. L'objet le plus simple est un blob, essentiellement le même qu'un fichier, mais dans un format que git comprend. Lorsque vous souhaitez enregistrer un fichier texte dans le référentiel, Git le compresse, l'archive, ajoute des données et crée un blob.
Il existe des répertoires - ce sont des dossiers avec des sous-dossiers, c'est-à-dire Git a un type d'objet
arbre qui contient des références à blob, à d'autres arbres.
Fondamentalement, une arborescence est un instantané qui décrit l'état de votre répertoire à un certain point.
Lors de la création d'un commit, un lien vers le répertoire de travail est à arborescence fixe.
Un commit est un lien vers une arborescence avec des informations sur qui l'a créé: email, nom, heure de création, lien vers le parent (branche parent) et message. Git compresse et écrit également les validations dans le répertoire des objets.
Pour voir comment tout cela fonctionne, vous devez répertorier les sous-répertoires à partir de la ligne de commande.
Avantages de travailler avec Git
Daniil Popov : Comment fonctionne Git? Pourquoi l'algorithme d'action est-il si compliqué?
Egor Andreevich : Si vous comparez Git avec Subversion (SVN), alors dans le premier système il y a un certain nombre de fonctions que vous devez comprendre. Je vais commencer par la
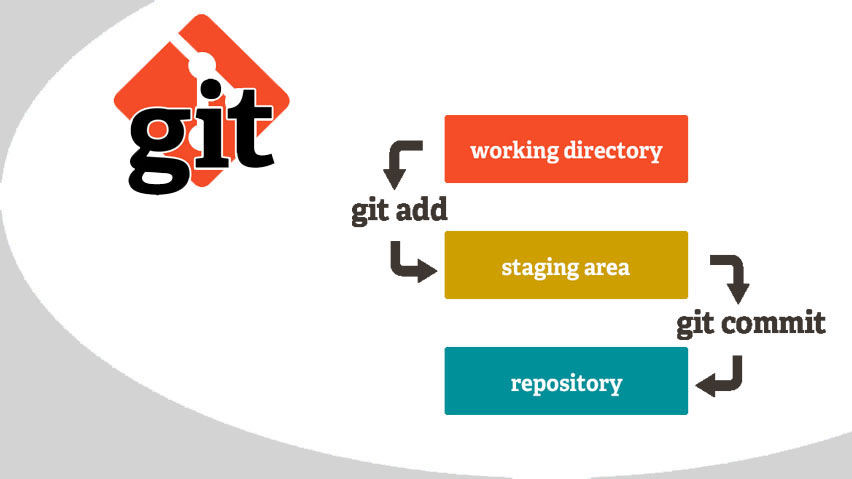
zone de transfert , qui ne doit pas être considérée comme une limitation de Git, mais plutôt des fonctionnalités.
Il est bien connu que lorsque vous travaillez avec du code, tout ne se passe pas tout de suite: quelque part, vous devez changer la mise en page, quelque part pour corriger les bugs. Par conséquent, après une session de travail, un certain nombre de fichiers affectés apparaissent qui ne sont pas interconnectés. Si vous effectuez toutes les modifications en une seule validation, cela ne sera pas pratique, car les modifications sont de nature différente. Ensuite, une série de validations arrive à la sortie, qui peut être créée simplement grâce à la zone de transfert. Par exemple, toutes les modifications apportées au fichier de disposition sont envoyées à une série, par exemple, fixent les tests unitaires à une autre. Nous prenons plusieurs fichiers, les déplaçons vers la zone de transit et créons un commit uniquement avec leur participation. Les autres fichiers du répertoire de travail n'y entrent pas. Ainsi, vous décomposez tout le travail effectué dans le répertoire de travail en plusieurs validations, chacune représentant un travail spécifique.
Alexei Kudryavtsev : En quoi Git est-il différent des autres systèmes de contrôle de version?
Egor Andreevich : Personnellement, j'ai commencé avec SVN, puis je suis immédiatement passé à Git. Surtout, Git est un système de contrôle de version décentralisé. Toutes les copies du référentiel Git sont exactement les mêmes. Chaque entreprise a un serveur où se trouve la version principale, mais il n'est pas différent de celui que le développeur a sur l'ordinateur.
SVN possède un référentiel central et des copies locales. Cela signifie que tout développeur peut interrompre seul le référentiel central.
À Git, cela ne se produira pas. Si le serveur central perd les données du référentiel, elles peuvent être restaurées à partir de n'importe quelle copie locale. Git est conçu différemment et offre les avantages de la vitesse.
Daniil Popov : Git est célèbre pour sa ramification, qui fonctionne sensiblement plus vite que SVN. Comment le fait-il?
Egor Andreevich : Dans SVN, une branche est une copie complète de la branche précédente. Il n'y a pas de représentation physique de branche dans Git. Il s'agit d'un lien vers le dernier commit d'une ligne de développement particulière. Lorsque Git enregistre des objets, lors de la création d'un commit, il crée un fichier avec des informations spécifiques sur le commit. Git crée un fichier symbolique - un lien symbolique avec un lien vers un autre fichier. Lorsque vous avez plusieurs branches, vous faites référence à différentes validations dans le référentiel. Pour suivre l'historique d'une branche, vous devez passer de chaque commit en utilisant le lien vers le commit parent.
Branches de Merjim
Daniil Popov : Il y a deux façons de fusionner deux branches en une - c'est fusionner et rebaser. Comment les utilisez-vous?
Egor Andreevich : Chaque méthode a ses avantages et ses inconvénients.
La fusion est l'option la plus simple. Par exemple, il existe deux branches: maître et l'entité sélectionnée dans celui-ci.
Pour la fusion, vous pouvez utiliser l'avance rapide. Cela est possible si, à partir du moment où le travail a commencé dans la branche de fonction, aucune nouvelle validation n'a été effectuée dans master. Autrement dit, la première fonctionnalité de validation dans est la dernière validation dans le maître.
Dans ce cas, le pointeur est fixé sur la branche principale et passe au commit le plus récent dans la branche de fonction. Ainsi, la ramification est éliminée en connectant la branche de fonctionnalité au thread principal principal et en supprimant la branche inutile. Il se révèle une histoire linéaire où tous les commits se succèdent. Dans la pratique, cette option se produit rarement, car en permanence quelqu'un fusionne les commits en master.
Il peut en être autrement. Git crée un nouveau commit - merge commit, qui a deux liens vers les commit parents: un en master, l'autre en feature. Avec le nouveau commit, deux branches sont connectées et la fonctionnalité peut être supprimée à nouveau.
Après le commit de fusion, vous pouvez regarder l'histoire et voir qu'elle est bifurquée. Si vous utilisez un outil qui rend graphiquement des validations, il ressemblera visuellement à un arbre de Noël. Cela ne casse pas Git, mais il est difficile pour un développeur de regarder une telle histoire.
Un autre outil est le
rebasage . Conceptuellement, vous prenez toutes les modifications de la branche de fonction et les retournez sur la branche principale. La première validation de fonctionnalité devient la nouvelle validation en plus de la dernière validation principale.
Il y a un hic - Git ne peut pas changer les commits. Il y avait une validation dans la fonctionnalité et nous ne pouvons pas simplement envelopper le master, car chaque validation a un horodatage.
Dans le cas d'un rebase, Git lit toutes les validations dans la fonctionnalité, l'enregistre temporairement, puis le recrée dans le même ordre dans master. Après le rebase, les validations initiales disparaissent et de nouvelles validations avec le même contenu apparaissent en haut de master. Il y a des problèmes. Lorsque vous essayez de rebaser une branche avec laquelle d'autres personnes travaillent, vous pouvez casser le référentiel. Par exemple, si quelqu'un a démarré sa branche à partir d'une validation qui figurait dans la fonctionnalité et que vous avez détruit et recréé cette validation. Rebase est plus adapté aux succursales locales.
Daniil Popov : Si vous introduisez des restrictions selon lesquelles strictement une personne travaille sur une branche de fonctionnalité, convenez que vous ne pouvez pas jumeler une branche de fonctionnalité d'une autre, alors ce problème ne se pose pas. Mais quelle approche pratiquez-vous?
Egor Andreevich : Nous n'utilisons pas de branches de fonction au sens direct de ce terme. Chaque fois que nous apportons un changement, créons une nouvelle branche, y travaillons et la versons immédiatement dans master. Il n'y a pas de branches qui jouent depuis longtemps.
Cela résout un grand nombre de problèmes de fusion et de rebase, en particulier les conflits. Les succursales existent pendant une heure et il y a une forte probabilité d'utiliser l'avance rapide, car personne n'a ajouté quoi que ce soit à maîtriser. Lorsque nous fusionnons dans la demande de tirage, fusionnons uniquement avec la création d'un commit de fusion
Daniil Popov : Comment n'avez-vous pas peur de fusionner une fonction principale inactive, car la décomposition d'une tâche en intervalles horaires est souvent irréaliste?
Egor Andreevich : Nous utilisons l'approche des
indicateurs de fonctionnalité . Ce sont des indicateurs dynamiques, une caractéristique spécifique avec différents états. Par exemple, la fonction d'envoi de paiements entre eux est activée ou désactivée. Nous avons un service qui fournit dynamiquement cet état aux clients. Vous, du serveur, obtenez ou non la fonction de valeur. Vous pouvez utiliser cette valeur dans le code - désactivez le bouton qui va à l'écran. Le code lui-même est dans l'application, et il peut être publié, mais il n'y a pas accès à cette fonctionnalité, car il est derrière l'indicateur de fonctionnalité.
Daniil Popov : Souvent, les nouveaux arrivants à Git sont informés qu'après le rebase, vous devez pousser avec force. D'où vient-il?
Egor Andreevich : Lorsque vous poussez simplement, un autre référentiel peut générer une erreur: vous essayez d'exécuter une branche, mais vous avez des commits complètement différents sur cette branche. Git vérifie toutes les informations afin de ne pas casser accidentellement le référentiel. Lorsque vous dites
git push force , désactivez cette vérification, croyant que vous savez mieux que lui, et exigez de réécrire la branche.
Pourquoi est-ce nécessaire après le rebase? Rebase recrée les commits. Il s'avère que la branche est également appelée, mais s'y engage avec d'autres hachages, et Git vous jure. Dans cette situation, il est tout à fait normal de faire une poussée de force, puisque vous contrôlez la situation.
Daniil Popov : Il y a toujours le concept de
rebase interactif , et beaucoup en ont peur.
Egor Andreevich : Il n'y a rien de terrible. Du fait que Git recrée l'histoire pendant le rebase, il la stocke temporairement avant de la lancer. Lorsqu'il dispose d'un stockage temporaire, il peut tout faire avec les validations.
Rebase en mode interactif suppose que Git avant rebase jette une fenêtre d'un éditeur de texte dans laquelle vous pouvez spécifier ce qui doit être fait avec chaque commit individuel. Il ressemble à plusieurs lignes de texte, où chaque ligne est l'un des commits qui se trouvent dans la branche. Avant chaque validation, il y a une indication de l'opération qui mérite d'être effectuée. L'opération par défaut la plus simple est
pick , c'est-à-dire à prendre et à inclure dans le rebasage. Le plus courant est le
squash , puis Git prendra les modifications de ce commit et les fusionnera avec les changements du précédent.
Il existe souvent un tel scénario. Vous avez travaillé localement dans votre branche et créé des commits pour la sauvegarde. Le résultat est une longue histoire de commits, ce qui est intéressant pour vous, mais de la même manière il ne faut pas le verser dans l'histoire principale. Ensuite, vous donnez squash à renommer le commit général.
La liste des équipes est longue. Vous pouvez lancer le commit -
drop et il disparaît, vous pouvez changer le message de commit, etc.
Alexei Kudryavtsev : Lorsque vous avez des conflits dans le rebase interactif, vous traversez tous les cercles de l'enfer.
Egor Andreevich : Je suis très loin de comprendre toute la sagesse du rebase interactif, mais c'est un outil puissant et complexe.
Application Git pratique
Daniil Popov : Passons à la pratique. Lors de l'entretien, je demande souvent: «Vous avez mille commits. Sur le premier tout va bien, sur le millième test a éclaté. Comment trouver le changement qui a conduit à cela à l'aide d'une gita? »
Egor Andreevich : Dans cette situation, vous devez utiliser la
bissecte , bien qu'il soit plus facile de blâmer.
Commençons par l'intéressant. Git bisect est applicable à une situation où vous avez une régression - c'était fonctionnel, cela a fonctionné, mais il s'est soudainement arrêté. Pour savoir quand la fonctionnalité est cassée, vous pouvez théoriquement revenir aléatoirement à la version précédente de l'application, regardez le code, mais il existe un outil qui vous permettra d'approcher de manière structurée le problème.
Git bisect est un outil interactif. Il existe une commande git bisect bad par laquelle vous signalez la présence d'un commit rompu et git bisect good - pour un commit qui fonctionne. Chaque fois que l'application est publiée, nous nous souvenons du hachage du commit à partir duquel la libération a été effectuée. Ce hachage peut également être utilisé pour indiquer de bons et de mauvais commits. Bisect reçoit des informations sur l'intervalle pendant lequel l'un des validations a interrompu la fonctionnalité et démarre la session de
recherche binaire , où il émet progressivement des validations pour vérifier si elles fonctionnent ou non.
Vous avez démarré la session, Git passe à l'une des validations de l'intervalle, signale cela. Dans le cas de mille commits, il n'y aura pas beaucoup d'itérations.
La vérification devra être effectuée manuellement: via des tests unitaires ou exécutez l'application et cliquez manuellement. Git bisect est facilement scriptable. Chaque fois qu'il émet un commit, vous lui donnez un script pour vérifier que le code fonctionne.
Blame est un outil plus simple qui, d'après son nom, vous permet de trouver le «coupable» d'une défaillance fonctionnelle. En raison de cette définition négative, de nombreux membres de la communauté du blâme ne l'aiment pas.
Que fait-il? Si vous blâmez git pour un fichier spécifique, alors il montrera linéairement dans ce fichier quel commit a changé telle ou telle ligne. Je n'ai jamais utilisé git blame depuis la ligne de commande. En règle générale, cela se fait dans IDEA ou Android Studio - cliquez et voyez qui a changé quelle ligne du fichier et dans quel commit.
Daniil Popov : Au fait, dans Android Studio, cela s'appelait Annotate. La connotation négative de blâme a été supprimée.
Alexei Kudryavtsev : Exactement, dans xCode, ils l'ont renommé Auteurs.
Egor Andreevich : J'ai également lu qu'il y a une louange utilitaire git - pour trouver celui qui a écrit cet excellent code.
Daniil Popov : Il convient de noter que sur le blâme des suggestions des examinateurs sur le travail de demande de traction. Il regarde qui a touché le plus un fichier particulier et suggère que cette personne pourra bien réviser votre code.
Dans le cas de l'exemple d'un millier de commits, le blâme dans 99% des cas montrera ce qui a mal tourné. Bisect est déjà le dernier recours.
Egor Andreevich : Oui, je recourt très rarement à la bissecte, mais j'utilise régulièrement l'annotation. Bien qu'il soit parfois impossible de comprendre pourquoi il est vérifié par la ligne de code, il est clair tout au long de la validation ce que l'auteur voulait faire.
Comment travailler avec des RP empilés?
Daniil Popov : J'ai entendu dire que Square utilise les demandes d'extraction empilées (PR).
Egor Andreevich : Au moins dans notre équipe Android, nous les utilisons souvent.
Nous consacrons beaucoup de temps à rendre chaque demande de tirage facile à examiner. Parfois, il y a une tentation de nourrir, de nourrir rapidement et de faire comprendre aux examinateurs. Nous essayons de créer de petites demandes de tirage et une courte description - le code devrait parler de lui-même. Lorsque les demandes de tirage sont petites, il est facile et rapide de brailler.
C'est là que le problème se pose. Vous travaillez sur une fonctionnalité qui nécessitera un grand nombre de modifications dans la base de code. Que pouvez-vous faire? Vous pouvez le mettre en une seule requête, mais ce sera énorme. Vous pouvez travailler en créant progressivement une demande de tirage, mais le problème sera que vous avez créé une branche, ajouté quelques modifications et soumis une demande de tirage, retourné au maître et le code que vous aviez dans la demande de tirage n'est pas disponible dans le maître jusqu'à la fusion n'aura pas lieu. Si vous dépendez des modifications de ces fichiers, il est difficile de continuer à travailler car il n'existe pas de code de ce type.
Comment contourner cela? Après avoir créé la première demande d'extraction, nous continuons à travailler, à créer une nouvelle branche à partir de la branche existante, que nous avons utilisée avant la demande d'extraction. Chaque branche ne provient pas du maître, mais de la branche précédente. Lorsque nous avons terminé de travailler sur cette fonctionnalité, nous soumettons une autre demande d'extraction et indiquons à nouveau qu'avec la fusion, elle ne fusionne pas dans le maître, mais dans la branche précédente. Il s'avère qu'une telle chaîne de demandes de tirage - des prs empilés. Lorsqu'une personne révise, elle voit les modifications qui ont été apportées uniquement par cette fonctionnalité, mais pas la précédente.
La tâche consiste à rendre chaque demande d'extraction aussi petite et claire que possible afin qu'il n'y ait pas besoin de la modifier. Parce que si vous devez changer le code dans les branches qui sont au milieu de la pile, tout ce qui se trouve en haut se cassera, car vous devez faire un rebase. Si les demandes de tirage sont petites, nous essayons de les geler dès que possible, puis toutes les fusionnements empilés étape par étape dans le maître.
Daniil Popov : Je comprends bien qu'à la fin, il y aura une dernière demande d'extraction contenant toutes les petites demandes d'extraction. Vous versez ce fil sans regarder?
Egor Andreevich : La fusion vient de la source empilée: premièrement, la toute première demande de pull est fusionnée dans master, dans la suivante, la base passe de la branche à master et, en conséquence, Git calcule qu'il y a déjà quelques changements dans master, moins de snapshot.
Alexei Kudryavtsev : Avez-vous une condition de course lorsque la première branche s'est déjà arrêtée, et seulement après que la seconde s'est arrêtée dans la première parce qu'elle n'a pas été changée de cible en maître?
Egor Andreevich : Nous le tenons à la main, il n'y a donc pas de telles situations. J'ouvre une demande de tirage, note les collègues dont je veux obtenir un avis, et lorsqu'ils sont prêts, allez sur bitbucket, appuyez sur fusion.
Alexei Kudryavtsev : Mais qu'en est-il des contrôles sur CI que rien n'est cassé?
Egor Andreevich : Nous ne faisons pas cela. CI s'exécute sur la branche, qui est la base de la demande d'extraction, et après vérification, nous changeons la base. Techniquement, cela ne change pas, puisque vous ciblez également le nombre de changements.
Daniil Popov :
Poussez -vous directement au master ou développez-vous? Et lorsque vous relâchez, indiquez explicitement le commit à partir duquel collecter?
Egor Andreevich : Nous n'avons pas de développement, seulement maître. Nous sortirons certainement toutes les deux semaines. Lorsque nous commençons à préparer une version, nous ouvrons une branche de version et quelques derniers correctifs vont à la fois au master et à cette branche. Nous utilisons des balises - des liens permanents vers un commit spécifique, éventuellement avec quelques informations. Si une sorte de commit est une release release, alors ce serait bien de garder dans l'historique que nous avons fait une release à partir de ce commit. Une balise est créée, Git enregistre les informations de version et vous pourrez y revenir plus tard.
Alexei Kudryavtsev : Où enseigner Git, que lire?
Egor Andreevich : Git a un
livre officiel . J'aime la façon dont il est écrit, il y a de bons exemples. Il y a un chapitre sur l'intérieur, vous pouvez l'étudier à fond. Vous pouvez trouver de nombreuses situations et solutions ésotériques sur StackOverflow. Ils peuvent également être utilisés.
Nous n'allons pas parler de Git lors du prochain Saint AppsConf . Mais d'un autre côté, nous avons décidé d'une expérience et ajouté des rapports d'introduction au programme de conférence mouvementé, dans lequel des conférenciers d'industries de développement connexes partagent leurs connaissances pour élargir les horizons d'un développeur mobile. Nous vous conseillons de faire attention à la présentation de Nikolai Golov d'Avito sur les bases de données : comment ne pas se tromper et choisir la bonne base de données, comment se préparer à la croissance et ce qui est pertinent en 2019.
AppsCast sort toutes les deux semaines le mercredi, et si vous préférez la version audio à la version texte, abonnez-vous à SoundCloud , aimez et discutez des sujets dans notre chat .