Salut Nous avons plus de 15 260 objets et 38 000 périphériques réseau qui doivent être configurés, mis à jour et vérifiés pour être opérationnels. Le maintien d'une telle flotte d'équipements est assez difficile et nécessite beaucoup de temps, d'efforts et de personnes. Par conséquent, nous devions automatiser le travail avec les équipements réseau et nous avons décidé d'adapter le concept de réseau en tant que code pour gérer le réseau dans notre entreprise. Sous la coupe, lisez notre historique d'automatisation, les erreurs commises et un autre plan pour les systèmes de construction.
Pour faire court, nous voulons automatiser le réseau
Salut Je m'appelle Alexander Prokhorov et, avec l'équipe d'ingénieurs réseau de notre département, nous
travaillons sur un réseau en
#IT X5 . Notre département développe l'infrastructure réseau, la surveillance, l'automatisation du réseau et la direction tendance de Network as a Code.
Au départ, je ne croyais pas vraiment à une quelconque automatisation de notre réseau en principe. Il y avait beaucoup d'erreurs héritées et de configuration - pas partout où il y avait une autorisation centrale, pas tout le matériel SSH pris en charge, pas partout
SNMP était configuré. Tout cela a grandement ébranlé la croyance en l'automatisation. Par conséquent, tout d'abord, nous mettons en ordre ce qui est nécessaire pour démarrer l'automatisation, à savoir: la normalisation de la connexion SSH, l'autorisation unique (
AAA ) et les profils SNMP. Toute cette fondation vous permet d'écrire un outil pour la livraison en masse de configurations sur un appareil, mais la question se pose: puis-je en obtenir plus? Nous en sommes donc arrivés à la nécessité d'élaborer un plan de développement de l'automatisation et du concept de Réseau en tant que Code en particulier.
Le concept de réseau en tant que code, selon Cisco, signifie les principes suivants:
- Stocker les configurations cibles dans le référentiel, contrôle de source
- Les modifications de configuration passent par le référentiel, Single Source of Truth
- Incorporation de configurations via l' API

Les deux premiers points vous permettent d'appliquer l'approche DevOps ou NetDevOps à la gestion de votre infrastructure réseau. Avec le troisième paragraphe, il y a des difficultés, par exemple, que faire s'il n'y a pas d'API? Bien sûr, SSH et CLI, nous sommes des networkers!
Et est-ce tout ce dont nous avons besoin?L'application de ces principes ne résout pas à elle seule tous les problèmes de l'infrastructure réseau, tout comme leur application nécessite une certaine base de données réseau.
Questions qui se sont posées lorsque nous y avons réfléchi:
- OK, je stocke la configuration sous forme de code, comment dois-je l'appliquer sur un objet spécifique?
- Ok, j'ai un modèle de configuration dans le référentiel, mais comment puis-je configurer automatiquement une configuration pour un objet basé dessus?
- Comment savoir quel modèle et quel fournisseur doit être sur cet objet? Puis-je le faire automatiquement?
- Comment puis-je vérifier si les paramètres actuels de l'objet correspondent aux paramètres du référentiel?
- Comment travailler avec les modifications du référentiel et les répliquer sur un réseau productif?
- De quel ensemble de données et de quels systèmes ai-je besoin pour penser au Zero Touch Provisioning?
- Qu'en est-il des différences entre les fournisseurs, et même les modèles du même fournisseur?
- Comment stocker des sous-réseaux pour une configuration automatique?
Sur la base de toutes les questions ci-dessus, il est devenu clair que nous avons besoin d'un ensemble de systèmes qui résolvent divers problèmes, travaillent ensemble et nous donnent des informations complètes sur l'infrastructure du réseau.

En plus d'essayer d'appliquer de nouvelles approches à la gestion de réseau, nous voulions résoudre certains problèmes plus aigus dans l'infrastructure de réseau, tels que l'intégrité des données, la mise à jour et, bien sûr, l'automatisation. Par automatisation, nous entendons non seulement la livraison en masse de configurations aux équipements, mais également la configuration automatique, la collecte automatique des données d'inventaire des équipements de réseau, l'intégration avec les systèmes de surveillance. Mais tout d'abord.
La fonctionnalité que nous visions est:
- Base de données d'équipements réseau (+ découverte, + mise à jour automatique)
- Adresses réseau de base (IPAM + contrôles de validation)
- Intégration de systèmes de surveillance avec des données d'inventaire
- Stockage des normes de configuration dans le système de contrôle de version
- Formation automatique de configurations cibles pour un objet
- Livraison en vrac des configurations à l'équipement réseau
- Mettre en œuvre un processus CI / CD pour gérer les modifications de configuration réseau
- Test des configurations réseau avec CI / CD
- ZTP (Zero Touch Provisioning) - configuration automatique de l'équipement pour un objet
Longue histoire, nous avons essayé l'automatisationNous avons commencé à essayer d'automatiser le travail de configuration du réseau il y a 2 ans. Pourquoi cette question a-t-elle refait surface et mérite-t-elle l'attention?
C'est fastidieux et ennuyeux de configurer plus de quelques dizaines d'appareils avec vos mains. Parfois, la main de l'ingénieur tressaute et il fait des erreurs. Pour plusieurs dizaines, un script écrit par un ingénieur suffit généralement, ce qui transfère les paramètres mis à jour à l'équipement réseau.
Pourquoi ne pas en rester là? En fait, de nombreux ingénieurs réseau savent déjà comment faire toutes sortes de pythons, et ceux qui ne savent pas comment le feront déjà très bientôt (Natalya Samoilenko, cependant, a publié
un excellent travail sur Python , en particulier pour les networkers). Quiconque est chargé de configurer n + 1 routeurs est capable d'écrire un script et de déployer les paramètres très rapidement. Beaucoup plus rapide qu'alors capable de tout ramener. Selon l'expérience de l'automatisation «chacun pour soi», des erreurs se produisent lorsque vous ne pouvez rétablir la communication qu'avec vos mains, et seulement avec de grandes souffrances pour toute l'équipe.

Exemple
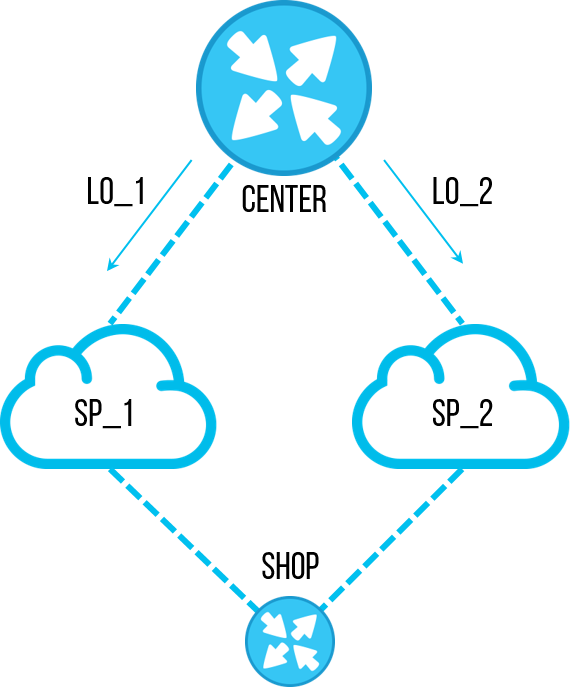
Une fois, l'un des ingénieurs a décidé d'effectuer une tâche importante - rétablir l'ordre dans les configurations des routeurs. À la suite de l'audit de plusieurs objets, une
liste de préfixes obsolètes avec des sous-réseaux spécifiques a été trouvée, dont nous n'avions plus besoin. Auparavant, il était utilisé pour filtrer les adresses de
bouclage des sites centraux afin qu'ils ne transitent que par un seul canal, et nous pouvions tester la connexion sur ce canal. Mais le mécanisme a été optimisé, et ils ont cessé d'utiliser un tel schéma de test de canal. L'employé a décidé de supprimer cette
liste de préfixes afin qu'elle ne se profile pas dans la configuration et ne crée pas de confusion à l'avenir. Tout le monde a accepté de supprimer la
liste de préfixes inutilisée, la tâche est simple, ils ont immédiatement oublié. Mais supprimer la même
liste de préfixes avec vos mains sur des dizaines d'objets est assez ennuyeux et prend du temps. Et l'ingénieur a écrit un script qui va rapidement parcourir l'équipement, faire
«pas de liste de préfixes pl-cisco-primer» et enregistrer solennellement la configuration.
Quelque temps après la discussion, quelques heures ou une journée, je ne me souviens pas, un objet est tombé. Après quelques minutes, une autre, similaire. Le nombre d'objets inaccessibles a continué de croître, en une demi-heure à 10, et toutes les 2-3 minutes, un nouveau a été ajouté. Tous les ingénieurs ont été connectés pour le diagnostic. 40-50 minutes après le début de l'accident, tout le monde a été interrogé sur les changements et l'employé a arrêté le script. A cette époque, il y avait déjà une vingtaine d'objets avec des canaux cassés. Une restauration complète a pris 7 ingénieurs pendant plusieurs heures.
Côté technique
La liste des préfixes a été utilisée pour filtrer les
bouclages - l'un a été filtré sur un canal, le second sur la sauvegarde. Cela a été utilisé pour tester la communication sans commuter le trafic productif entre les canaux. Par conséquent, la première règle d'une
route-map entrante sur un voisin
BGP était
DENY avec
"match ip address prefix list" . Les autres règles de la
carte d'itinéraire étaient toutes
PERMISES .
Il convient de noter plusieurs nuances:
- La règle de route-map dans laquelle il n'y a pas de correspondance - saute tout
- À la fin de la liste des préfixes , il y a un refus implicite , mais seulement s'il n'est pas vide
- Une liste de préfixes vide est un permis implicite
Tout ce qui précède est vrai pour
Cisco IOS . Une
liste de préfixes vide peut apparaître lorsque vous déclarez une
carte d'itinéraire , faites-la
"correspondre à la liste de préfixes d'adresse IP pl-test-cisco" . Cette
liste de préfixes ne sera pas explicitement déclarée dans la configuration (en plus de la ligne avec
match ), mais elle peut être trouvée dans
show ip prefix-list .
2901-NOC-4.2(config)#route-map rm-test-in 2901-NOC-4.2(config-route-map)#match ip address prefix-list pl-test-in 2901-NOC-4.2(config-route-map)#do sh run | i prefix match ip address prefix-list pl-test-in 2901-NOC-4.2(config-route-map)#do sh ip prefix ip prefix-list pl-test-in: 0 entries 2901-NOC-4.2(config-route-map)#
Pour revenir à ce qui s'est passé, lorsque la
liste des
préfixes a été supprimée par le script, elle est devenue vide, car elle se trouvait toujours dans la première règle
DENY de la
route-map . Une
liste de préfixes vide autorise tous les sous-réseaux, donc tout ce qu'un pair
BGP nous a transmis est tombé dans la première règle
DENY .
Pourquoi l'ingénieur n'a-t-il pas immédiatement remarqué qu'il avait rompu la connexion? Ici a joué le rôle de temporisateurs
BGP dans Cisco.
BGP lui-même n'échange pas de routes sur une planification, et si vous avez mis à jour la stratégie de routage
BGP , vous devez réinitialiser la session BGP pour appliquer les modifications,
"clear ip bgp <peer-ip>" à Cisco.
Afin de ne pas réinitialiser la session, il existe deux mécanismes:
- Cisco Soft-Reconfiguration
- Actualiser l'itinéraire en tant que RFC2918
La reconfiguration en douceur contient les informations reçues dans
UPDATE du voisin sur les routes jusqu'à ce que les politiques soient appliquées dans la table locale
adj-RIB-in . Lors de la mise à jour des politiques, il devient possible d'émuler
UPDATE à partir d'un voisin.
L'actualisation de l'itinéraire est la «capacité» des pairs à envoyer
UPDATE sur demande. La disponibilité de cette opportunité est convenue lors de la création d'un quartier. Avantages - Pas besoin de stocker une copie de
UPDATE localement. Inconvénients - en pratique, après une demande
UPDATE d'un voisin, vous devez attendre qu'il l'envoie. Par ailleurs, vous pouvez désactiver la fonctionnalité sur Cisco avec une commande cachée:
neighbor <peer-ip> dont-capability-negotiate
Il existe une fonctionnalité non documentée de Cisco - un temporisateur de 30 secondes, qui est déclenché par un changement dans les politiques
BGP . Après avoir modifié les politiques, le processus de mise à jour des itinéraires à l'aide de l'une des technologies ci-dessus démarre dans 30 secondes. Je n'ai pas pu trouver une description documentée de ce temporisateur, mais il en est fait mention dans le
BUG CSCvi91270 . Vous pouvez en apprendre davantage sur sa disponibilité dans la pratique,

après avoir apporté des modifications dans le laboratoire et recherché dans le
débogage des demandes
UPDATE au voisin ou le
processus de reconfiguration en douceur . (S'il y a des informations supplémentaires sur le sujet - vous pouvez laisser dans les commentaires)
Pour la
reconfiguration en douceur , le minuteur fonctionne comme ceci:
2901-NOC-4.2(config)#no ip prefix-list pl-test seq 10 permit 10.5.5.0/26 2901-NOC-4.2(config)#do sh clock 16:53:31.117 Tue Sep 24 2019 Sep 24 16:53:59.396: BGP(0): start inbound soft reconfiguration for Sep 24 16:53:59.396: BGP(0): process 10.5.5.0/26, next hop 10.0.0.1, metric 0 from 10.0.0.1 Sep 24 16:53:59.396: BGP(0): Prefix 10.5.5.0/26 rejected by inbound route-map. Sep 24 16:53:59.396: BGP(0): update denied, previous used path deleted Sep 24 16:53:59.396: BGP(0): no valid path for 10.5.5.0/26 Sep 24 16:53:59.396: BGP(0): complete inbound soft reconfiguration, ran for 0ms Sep 24 16:53:59.396: BGP: topo global:IPv4 Unicast:base Remove_fwdroute for 10.5.5.0/26 2901-NOC-4.2(config)#
Pour
Route-Refresh du côté du voisin comme ceci:
2801-RTR (config-router)# *Sep 24 20:57:29.847 MSK: BGP: 10.0.0.2 rcv REFRESH_REQ for afi/sfai: 1/1 *Sep 24 20:57:29.847 MSK: BGP: 10.0.0.2 start outbound soft reconfig for afi/safi: 1/1
Si
Route-Refresh n'est pas pris en charge par l'un des homologues et que
la reconfiguration logicielle entrante n'est pas activée, la mise à jour des itinéraires par la nouvelle stratégie ne se fera pas automatiquement.
Ainsi, la
liste des préfixes a été supprimée, la connexion est restée, après 30 secondes, elle a disparu. Le script a réussi à modifier la configuration, à vérifier la connexion et à enregistrer la configuration. La chute du script n'était pas immédiatement liée, sur fond d'un grand nombre d'objets.
Tout cela pourrait facilement être évité par des tests, une réplication partielle des paramètres. Il était entendu que l'automatisation devrait être centralisée et contrôlée.

Les systèmes dont nous avons besoin et leurs connexions
Une brève conclusion du spoiler - il est préférable de systématiser et de contrôler le processus de livraison en masse des configurations afin de ne pas arriver à la livraison en masse des erreurs dans les configurations.
- DevOps: 50ms 4 - : ", !@#$%"
Le schéma auquel nous sommes arrivés consiste en des blocs de données de base «métier», des blocs de données de base «réseau», des systèmes de surveillance d'infrastructure de réseau, des systèmes de livraison de configuration, des systèmes de contrôle de version avec une unité de test.
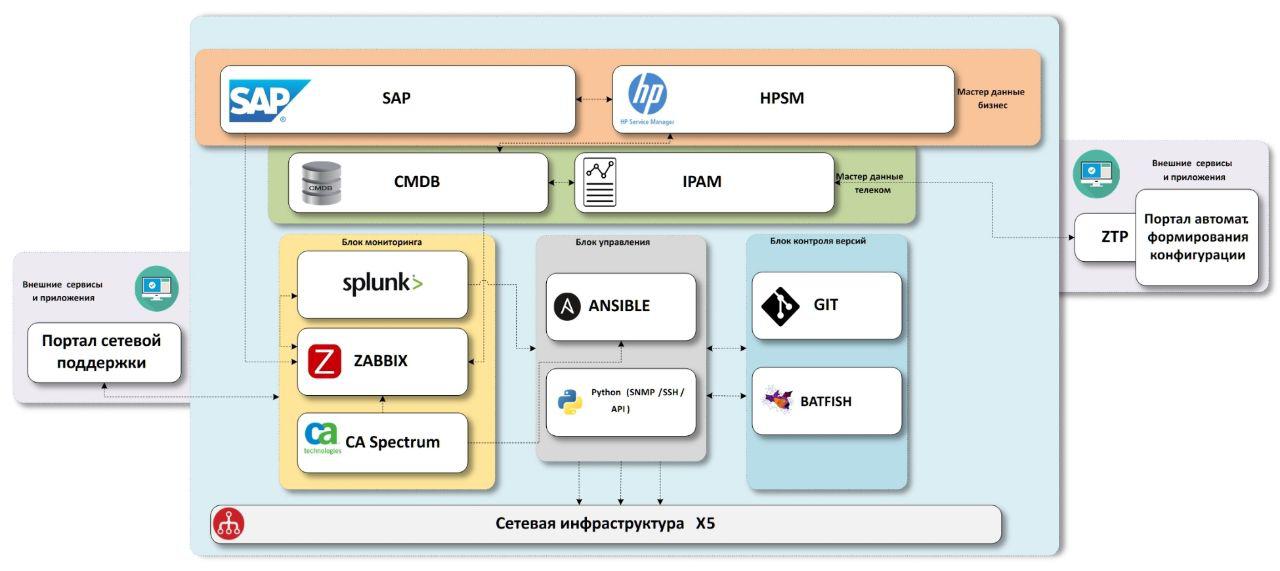
Tout ce dont nous avons besoin, c'est de données
Nous devons d'abord savoir quels sont les objets dans l'entreprise.
SAP - Système d'entreprise
ERP . Il existe des données sur presque toutes les installations, et plus précisément sur tous les magasins et centres de distribution. De plus, il existe des données sur les équipements qui ont transité par un entrepôt informatique avec des numéros d'inventaire, qui nous seront également utiles à l'avenir. Seuls les bureaux manquent, ils ne sont pas démarrés dans le système. Nous essayons de résoudre ce problème dans un processus séparé, à partir du moment de l'ouverture, nous avons besoin d'une connexion sur chaque objet, et nous sélectionnons les paramètres de communication, donc quelque part à ce moment, nous devons créer des données de base. Mais l'insuffisance des données est un sujet distinct, il est préférable de mettre cette description dans un article séparé si cela vous intéresse.
HPSM - un système contenant une
CMDB commune pour l'informatique, la gestion des incidents, la gestion du changement. Étant donné que le système est commun à tous les services informatiques, il doit disposer de tous les équipements informatiques, y compris les équipements réseau. C'est l'endroit où nous ajouterons toutes les données finales sur le réseau. Avec la gestion des incidents et des changements, nous prévoyons d'interagir à partir des systèmes de surveillance à l'avenir.
Nous savons quels objets nous avons, les enrichir avec des données sur le réseau. À cette fin, nous avons deux systèmes -
IPAM de
SolarWinds et notre propre système CMDB.noc.
IPAM est un référentiel de sous-réseaux IP, les données les plus correctes et correctes sur la propriété des adresses IP dans l'entreprise devraient être ici.
CMDB.noc est une base de données avec une interface WEB où sont stockées des données statiques sur l'équipement réseau - routeurs, commutateurs, points d'accès, ainsi que les fournisseurs et leurs caractéristiques. Dans le cadre de moyens statiques, leur changement ne s'effectue qu'avec la participation de l'homme. En d'autres termes, la découverte automatique ne modifie pas cette base de données, nous en avons besoin pour comprendre ce qui «devrait» être installé sur l'objet. Sa base est nécessaire comme tampon entre les systèmes productifs avec lesquels toute l'entreprise travaille et les outils réseau internes. Accélère le développement, en ajoutant les champs nécessaires, de nouvelles relations, en ajustant les paramètres, etc. De plus, cette solution est non seulement dans la vitesse de développement, mais aussi en présence de ces relations entre les données dont nous avons besoin, sans compromis. Comme mini-exemple, nous utilisons plusieurs
exid dans la base de données pour la communication entre IPAM, SAP et HPSM.
En conséquence, nous avons reçu des données complètes sur tous les objets, avec l'équipement réseau connecté et les adresses IP. Nous avons maintenant besoin de modèles de configuration ou de services réseau que nous fournissons sur ces sites.

Source unique de vérité
Ici, nous venons d'atteindre l'application du premier principe NaaC - le stockage des configurations cibles dans le référentiel. Dans notre cas, c'est Gitlab. Le choix pour nous était simple:
- Premièrement, nous avons déjà cet outil dans notre entreprise, nous n'avons pas eu besoin de le déployer à partir de zéro
- Deuxièmement, il convient parfaitement à toutes nos tâches actuelles et futures sur l'infrastructure réseau
La principale partie intéressante de l'automatisation se produira dans Gitlab - le processus de modification de la norme de configuration ou, plus simplement, du modèle.
Exemple de processus de changement standard
L'un des types d'objets que nous avons est le magasin Pyaterochka. Là, une topologie typique se compose d'un routeur et d'un / deux commutateurs. Le fichier de configuration du modèle est stocké dans Gitlab, dans cette partie tout est simple. Mais ce n'est pas tout à fait NaaC.
Supposons maintenant qu'un nouveau projet nous arrive. Les tâches du nouveau projet informatique sont de réaliser un pilote dans un certain volume de magasins. Selon les résultats du pilote - en cas de succès, effectuez une réplication pour tous les objets de ce type; sinon réduisez le pilote sans effectuer de réplication.
Ce processus s'intègre très bien dans la logique Git:
- Pour un nouveau projet, nous créons une branche, où nous apportons des modifications aux configurations.
- Dans Branch, nous conservons également une liste des objets sur lesquels ce projet est piloté.
- En cas de succès, nous faisons une demande de fusion dans la branche principale, qui devra être répliquée sur le prod-network
- En cas d'échec, quittez Branch pour l'historique, ou supprimez simplement

En première approximation - même sans automatisation, c'est un outil très pratique pour travailler ensemble sur une configuration réseau. Surtout si vous imaginez que trois projets ou plus sont arrivés en même temps. Lorsque le moment sera venu de publier les projets dans prod, vous devrez résoudre tous les conflits de configuration dans les demandes de fusion et vérifier que les modifications apportées aux paramètres ne s'excluent pas mutuellement. Et c'est très pratique à faire dans git.
De plus, cette approche nous ajoute la flexibilité d'utiliser les outils Gitlab CI / CD pour tester virtuellement des configurations, pour automatiser la livraison de configurations à un banc de test ou à un groupe pilote d'objets. // Et même sur prod si vous voulez.
Déployer la configuration dans n'importe quel environnement
Initialement, l'objectif principal était précisément la livraison en masse de configurations, en tant qu'outil qui permet très clairement de gagner du temps aux ingénieurs et d'accélérer l'exécution des tâches de configuration. Pour ce faire, avant même le début de la grande activité «Network as a Code», nous avons écrit une solution
python pour se connecter à des équipements soit pour collecter des configurations d'équipements, soit pour les configurer. C'est
netmiko , c'est
pysnmp , c'est
jinja2 , etc.
Mais il est temps pour nous de diviser la configuration en bloc en plusieurs sous-espèces:
Livraison de configurations pour tester et zones pilotesCet élément est basé sur Gitlab CI, qui vous permet d'activer la remise de la configuration aux zones pilote et de test dans le pipeline.
Duplication de configurations dans prod- Un élément distinct, le plus souvent la réplication vers des appareils 38k a lieu en plusieurs vagues - augmentant le volume - pour surveiller la situation en prod. De plus, un travail de cette ampleur nécessite une coordination du travail, il est donc préférable de démarrer ce processus à la main. Pour cela, il est pratique d'utiliser Ansible + -AWX et d'y fixer la compilation dynamique de l'inventaire de nos systèmes de données de base.
- En outre, il s'agit d'une solution pratique lorsque vous devez donner à la deuxième ligne le lancement de playbooks préconfigurés qui effectuent des opérations complexes et importantes, telles que la commutation du trafic entre les sites.
Collecte de données- Découverte automatique des périphériques réseau
- Configurations de sauvegarde
- Vérifier la connectivité
Nous avons attribué cette tâche dans un bloc séparé, car il y a des moments où quelqu'un a soudainement démonté un commutateur ou installé un nouvel appareil, mais nous ne le savions pas à l'avance. En conséquence, cet appareil ne sera pas dans nos données de base et tombera du processus de livraison de configuration, de surveillance et, en général, de travail opérationnel. Il arrive que l'équipement ait été installé légitimement, mais la configuration y a été "mal" versée et, pour une raison quelconque,
ssh ,
snmp ,
aaa ou des mots de passe non standard pour l'accès n'y fonctionnent pas. Pour ce faire, nous avons python pour essayer toutes les méthodes de connexion
héritées possibles que nous pourrions avoir dans l'entreprise, faire de la force brute pour tous les anciens mots de passe, et tout cela pour obtenir le morceau de fer et le préparer à travailler avec
ansible et à surveiller .
Il existe un moyen simple - de créer plusieurs fichiers d'
inventaire pour ansible, où décrire toutes les données possibles pour les connexions (tous les types de fournisseurs avec toutes les paires nom d'utilisateur / mot de passe possibles) et exécuter un
playbook pour chaque variante d'
inventaire . Nous espérions une meilleure solution, mais lors de la conférence RedHat, l'architecte Ansible a conseillé la même chose. Il est généralement admis que vous savez à l'avance à quoi vous vous connectez.
Nous voulions une solution universelle - lorsque vous supprimez une sauvegarde, recherchez un nouvel équipement et, s'il est trouvé, ajoutez-le à tous les systèmes nécessaires. Par conséquent, nous choisissons une solution en python - sachez ce qui pourrait être plus beau qu'un programme qui lui-même peut détecter un matériel réseau pour s'y connecter, indépendamment de ce qui y est configuré (dans des limites raisonnables, bien sûr), configurer selon les besoins, supprimer la configuration et, en même temps, Ajoutez des données API aux systèmes requis.
Vérification comme la surveillance
L'une des tâches de l'automatisation est, bien sûr, de découvrir ce qui est tombé de cette automatisation. Les 38k ne sont pas tous parfaitement configurés la première fois, il arrive même que quelqu'un installe l'équipement avec ses mains. Et il est nécessaire de suivre ces changements et de rendre
justice à la configuration cible.
Il existe trois approches pour vérifier la conformité de la configuration avec la norme:
- Faites une vérification une fois par période - déchargez l'état actuel, comparez avec la cible et corrigez les lacunes identifiées.
- Sans rien vérifier, une fois par période - déployez les configurations cibles. Certes, il y a un risque de casser quelque chose - peut-être qu'il n'y avait pas tout dans la configuration cible.
- Une approche pratique consiste à considérer les différences par rapport à la configuration cible dans Single Source of Truth comme des alertes et à les surveiller par le système de surveillance. Cela comprend: une incompatibilité avec la norme de configuration actuelle, une différence entre le matériel et celui spécifié dans les données de base, une incompatibilité avec les données dans IPAM .
Dans le troisième cas, une option semble transférer ce travail à la gestion des incidents (OS), afin que les incohérences soient éliminées par petites portions tout au long du temps plus d'une fois par urgence.
Zabbix , dont j'ai parlé plus tôt dans l'article
«Comment nous avons surveillé 14 000 objets», est notre système de surveillance des objets distribués où nous pouvons effectuer tous les déclencheurs et alertes auxquels nous pouvons penser. Depuis la rédaction du dernier article, nous avons mis à niveau vers Zabbix 4.0
LTS .
Sur la base de
Web Zabbix, nous avons mis à jour notre portail de support réseau, où vous pouvez désormais trouver toutes les informations sur un objet de tous nos systèmes sur un seul écran, ainsi que exécuter des scripts pour vérifier les problèmes fréquents.
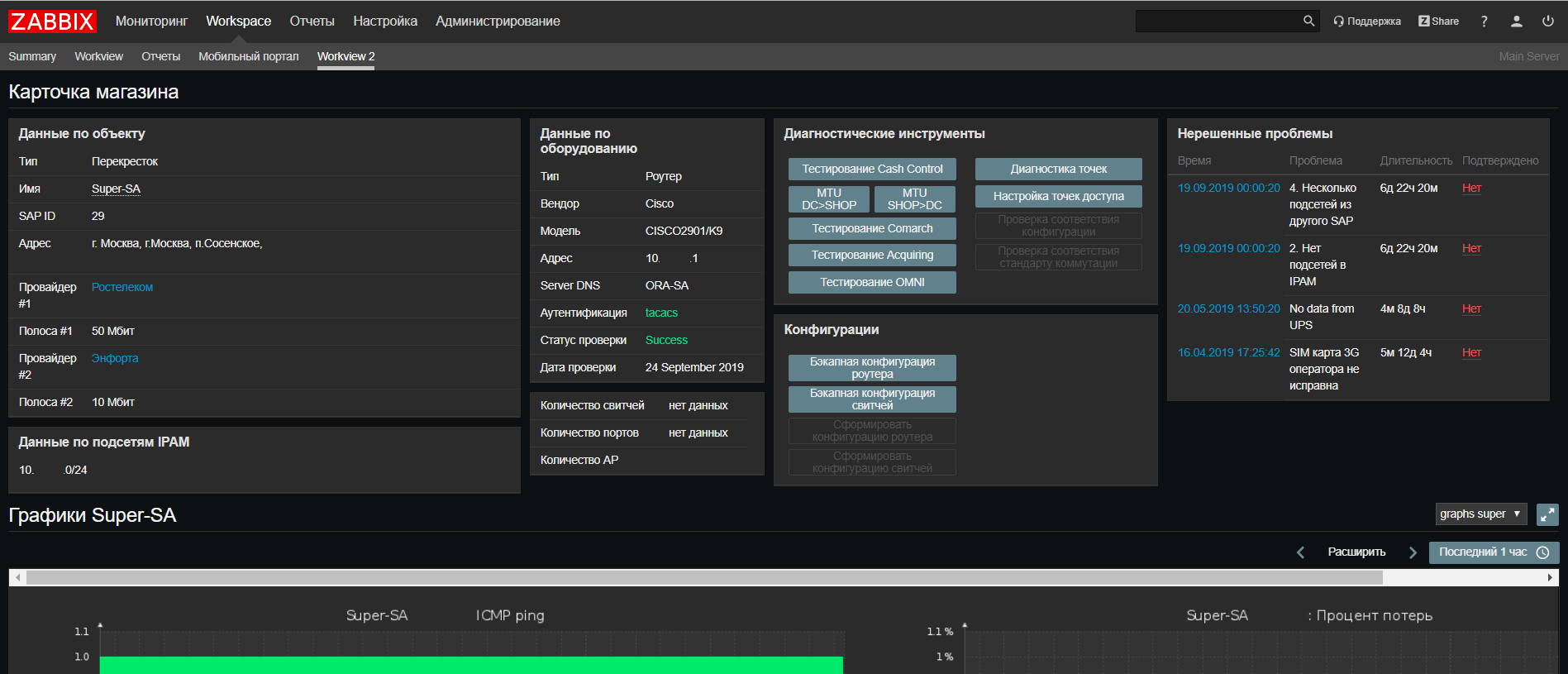
Nous avons également introduit une nouvelle fonctionnalité - pour nous, Zabbix est devenu, en quelque sorte, un
CRON pour le lancement de scripts programmés, tels que les scripts d'intégration système, les scripts de
découverte automatique . C'est très pratique lorsque vous devez regarder les scripts actuels et quand et où ils s'exécutent sans vérifier tous les serveurs. Certes, pour les scripts qui s'exécutent pendant plus de 30 secondes, vous aurez besoin d'un
lanceur qui les lance sans attendre la fin. Heureusement, c'est simple:
 Splunk
Splunk est une solution qui vous permet de collecter des journaux d'événements à partir de l'équipement réseau, et cela peut également être utilisé pour surveiller l'automatisation. Par exemple, lors de la collecte d'une sauvegarde de configuration, un script
python génère un message
LOG CFG-5-BACKUP , un routeur ou un commutateur envoie un message à Splunk, dans lequel nous comptons le nombre de messages de ce type provenant de l'équipement réseau. Cela nous permet de suivre la quantité d'équipement que le script a détecté. Et nous voyons combien de morceaux de fer ont pu signaler cela à
Splunk et vérifier que les messages de tous les morceaux de fer sont arrivés.
Spectrum est un système complet que nous utilisons pour surveiller les objets critiques, un outil plutôt puissant qui nous aide beaucoup à résoudre les incidents réseau critiques. Dans l'automatisation, nous l'utilisons uniquement en extrayant des données, ce n'est pas
open-source , donc les possibilités sont quelque peu limitées.
La cerise sur le gâteau

En utilisant des systèmes avec des données de base sur l'équipement, nous pouvons penser à créer ZTP, ou Zero Touch Provisioning. Comme un bouton "auto-tuning", mais seulement sans bouton.
Nous avons toutes les données nécessaires des blocs précédents - nous connaissons l'objet, son type, quel équipement est là (fournisseur et modèle), quelles adresses sont là (IPAM), quelle est la norme de configuration actuelle (Git). En les rassemblant tous, nous pouvons au moins préparer un modèle de configuration pour le téléchargement sur l'appareil, ce sera plus comme One Touch Provisioning, mais parfois plus n'est pas nécessaire.
True Zero Touch a besoin d'un moyen de fournir automatiquement la configuration à du matériel non configuré. De plus, il est souhaitable quel que soit le fournisseur. Il existe plusieurs options de travail - un serveur de console, si tout l'équipement passe par l'entrepôt central, des solutions de console mobile, si l'équipement arrive immédiatement. Nous travaillons simplement sur ces solutions, mais dès qu'il y a une option de travail, nous pouvons la partager.
Conclusion
Au total, dans notre concept de
réseau en tant que code , il y avait 5 étapes principales:
- Données de base (communication des systèmes et des données entre eux, API des systèmes, suffisance des données pour le support et le lancement)
- Surveillance des données et des configurations (découverte automatique des périphériques réseau, vérification de la pertinence de la configuration dans l'installation)
- Contrôle de version, tests et configurations de pilotage (Gitlab CI / CD appliqué au réseau, outils de test de configuration réseau)
- Livraison de la configuration (Ansible, AWX, scripts python pour se connecter)
- Zero Touch Provisioning (quelles données sont nécessaires, comment construire un processus pour qu'il soit, comment se connecter à un matériel non configuré)
Cela n'a pas fonctionné de tout intégrer dans un seul article, chaque élément mérite une discussion distincte, nous pouvons parler de quelque chose maintenant, de quelque chose lorsque nous vérifions les solutions dans la pratique. Si vous êtes intéressé par l'un des sujets - à la fin, il y aura un sondage où vous pourrez voter pour le prochain article. Si le sujet n'est pas inclus dans la liste, mais qu'il est intéressant de le lire, laissez un commentaire dès que possible, assurez-vous de partager notre expérience.
Un merci spécial à Virilin Alexander (
xscrew ) et Sibgatulin Marat (
eucariot ) pour la visite de référence à l'automne 2018 sur le cloud yandex et l'histoire de l'automatisation dans l'infrastructure de réseau cloud. Après lui, nous avons trouvé l'inspiration et beaucoup d'idées sur l'utilisation de l'automatisation et de NetDevOps dans l'infrastructure du X5 Retail Group.