Ceux qui travaillent avec des données sont bien conscients que le bonheur n'est pas dans le réseau neuronal, mais dans la façon de traiter les données correctement. Mais pour les traiter, vous devez d'abord analyser les corrélations, sélectionner les données nécessaires, éliminer les inutiles, etc. À ces fins, la visualisation à l'aide de la bibliothèque matplotlib est souvent utilisée.

Rencontrez-moi "à l'intérieur"!
Personnalisation
Exécutez le code suivant pour configurer. Cependant, les graphiques individuels remplacent eux-mêmes leurs paramètres.
Corrélation
Les graphiques de corrélation sont utilisés pour visualiser la relation entre 2 variables ou plus. C'est-à-dire, comment une variable change par rapport à une autre.
1. Nuage de points
Scatteplot est une vue graphique classique et fondamentale utilisée pour examiner la relation entre deux variables. Si vous avez plusieurs groupes dans vos données, vous pouvez visualiser chaque groupe dans une couleur différente. Dans matplotlib, vous pouvez facilement le faire en utilisant plt.scatterplot ().

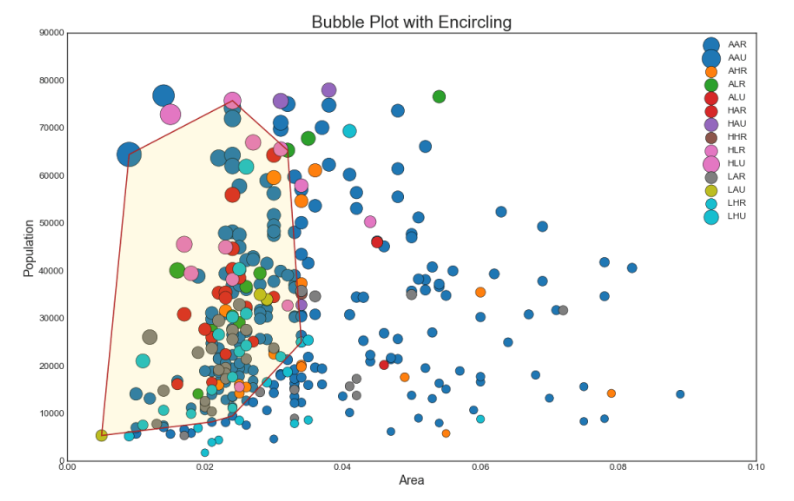
2. Graphique à bulles avec capture de groupe
Parfois, vous voulez montrer un groupe de points à l'intérieur de la bordure pour souligner leur importance. Dans cet exemple, nous obtenons les enregistrements de la trame de données qui doivent être alloués et les transmettons à encircle () décrit dans le code ci-dessous.
Afficher le code from matplotlib import patches from scipy.spatial import ConvexHull import warnings; warnings.simplefilter('ignore') sns.set_style("white")
3. Graphique de régression linéaire le mieux adapté
Si vous voulez comprendre comment deux variables changent l'une par rapport à l'autre, la ligne de meilleur ajustement est la meilleure. Le graphique ci-dessous montre la meilleure adaptation entre les différents groupes de données. Pour désactiver les regroupements et dessiner simplement une ligne qui correspond le mieux à l'ensemble de données, supprimez le paramètre hue = 'cyl' de sns.lmplot () ci-dessous.

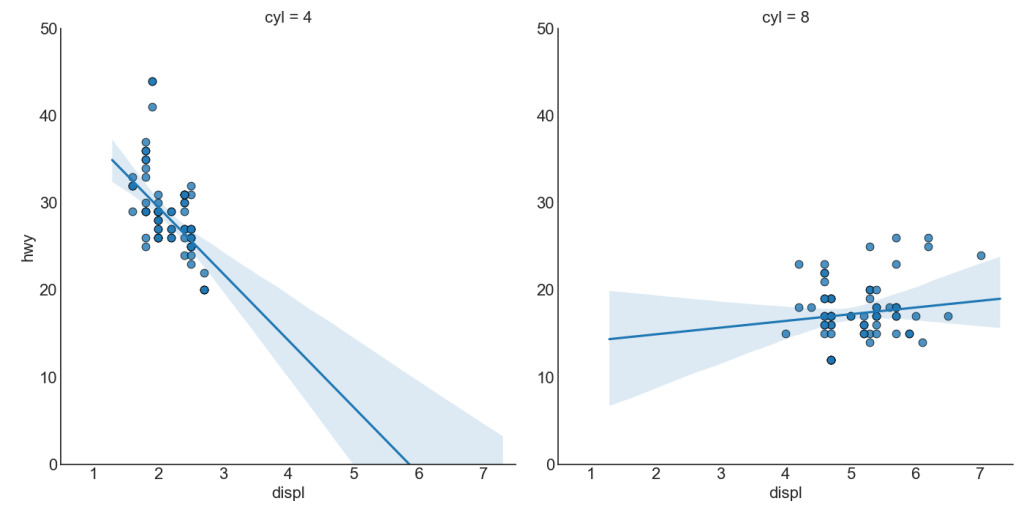
Chaque ligne de régression dans sa propre colonne
De plus, vous pouvez afficher la ligne la mieux adaptée à chaque groupe dans une colonne distincte. Pour ce faire, définissez le paramètre col = groupingcolumn dans sns.lmplot ().
4. Stripplot
Souvent, plusieurs points de données ont les mêmes valeurs X et Y. Par conséquent, plusieurs points de données sont tracés les uns sur les autres et masqués. Pour éviter cela, écartez légèrement les points afin de les voir visuellement. Ceci est commodément fait en utilisant stripplot ().
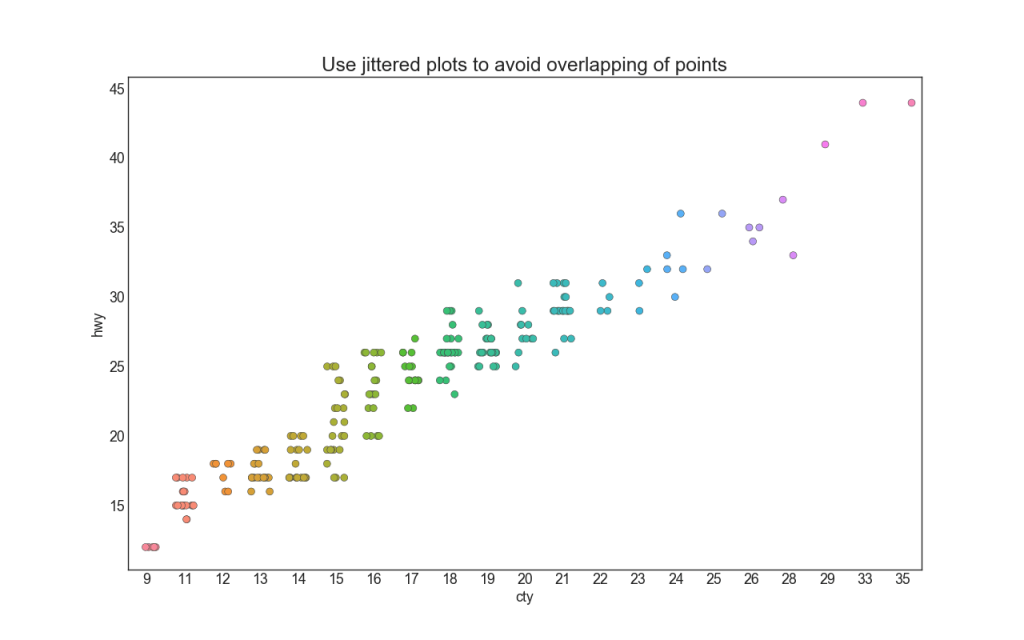
5. Parcelle de comptage
Une autre option qui évite le problème de chevauchement des points consiste à augmenter la taille du point, en fonction du nombre de points se trouvant à cet endroit. Ainsi, plus la taille du point est grande, plus la concentration des points autour de lui est importante.

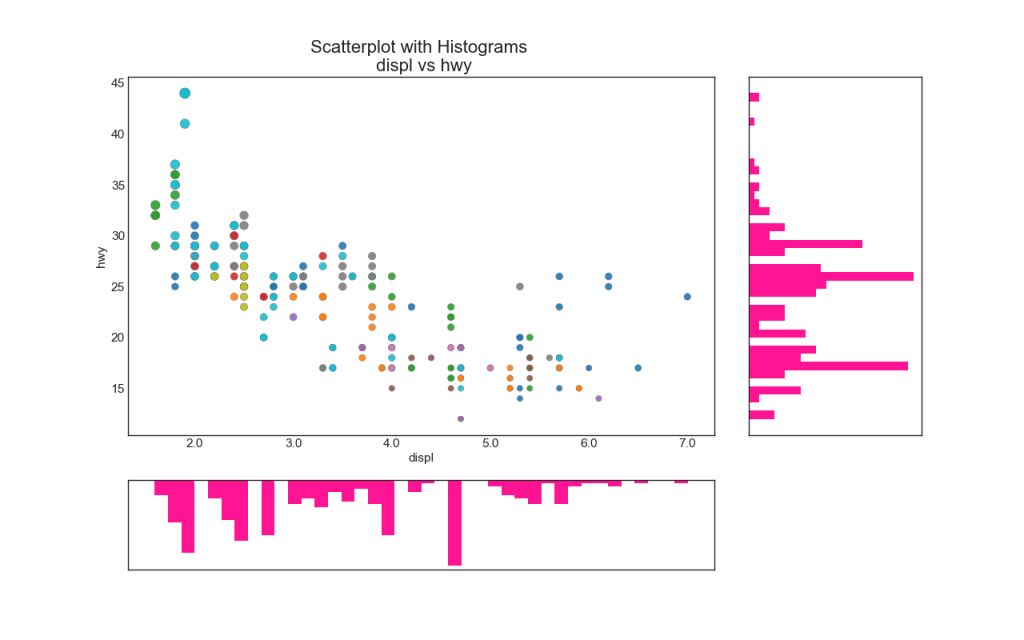
6. Un graphique à barres
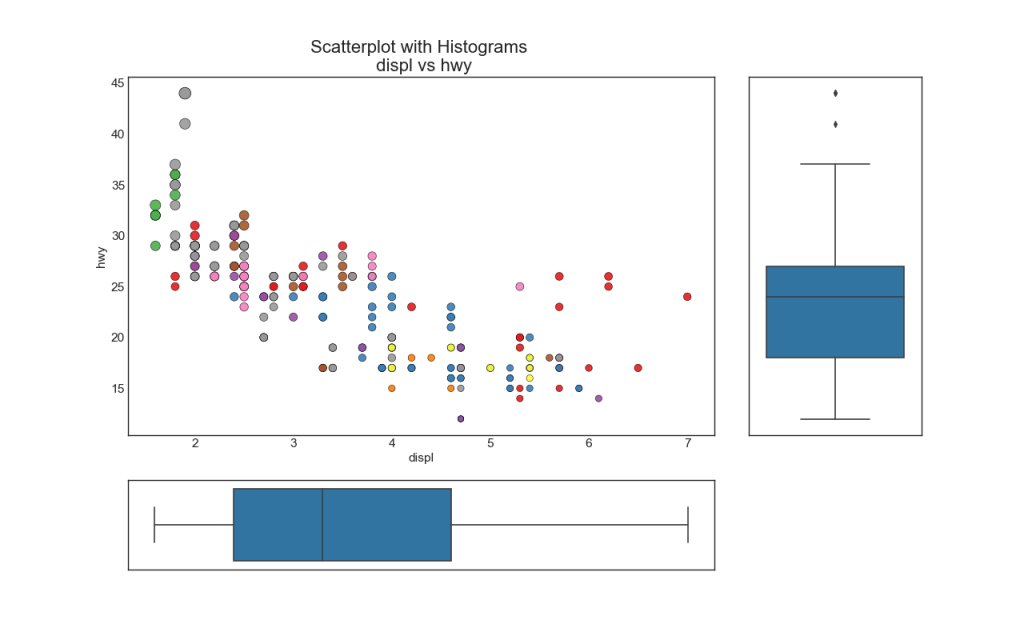
Les histogrammes linéaires ont un histogramme le long des variables des axes X et Y. Il est utilisé pour visualiser la relation entre X et Y ainsi que la distribution unidimensionnelle de X et Y individuellement. Ce graphique est souvent utilisé dans l'analyse des données (EDA).
7. Boxplot
Boxplot a la même fonction qu'un histogramme ligne par ligne. Cependant, ce graphique permet de déterminer la médiane, les 25e et 75e centiles de X et Y.
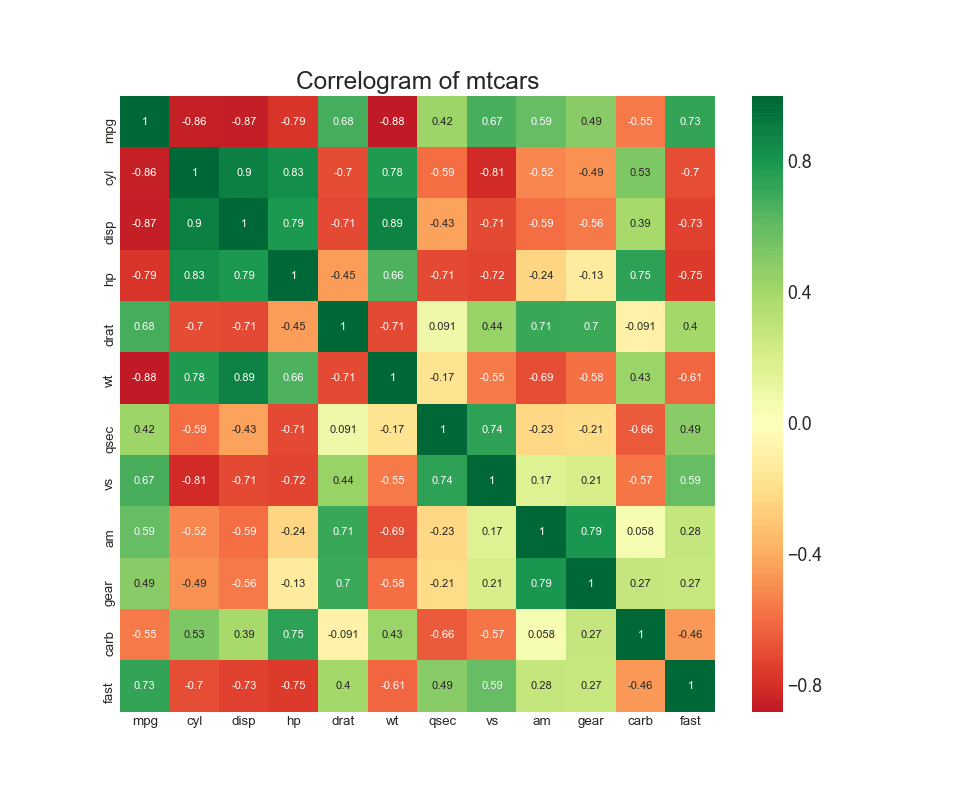
8. Le diagramme de corrélation
Le diagramme de corrélation est utilisé pour visualiser visuellement la métrique de corrélation entre toutes les paires possibles de variables numériques dans un ensemble de données donné (ou tableau bidimensionnel).
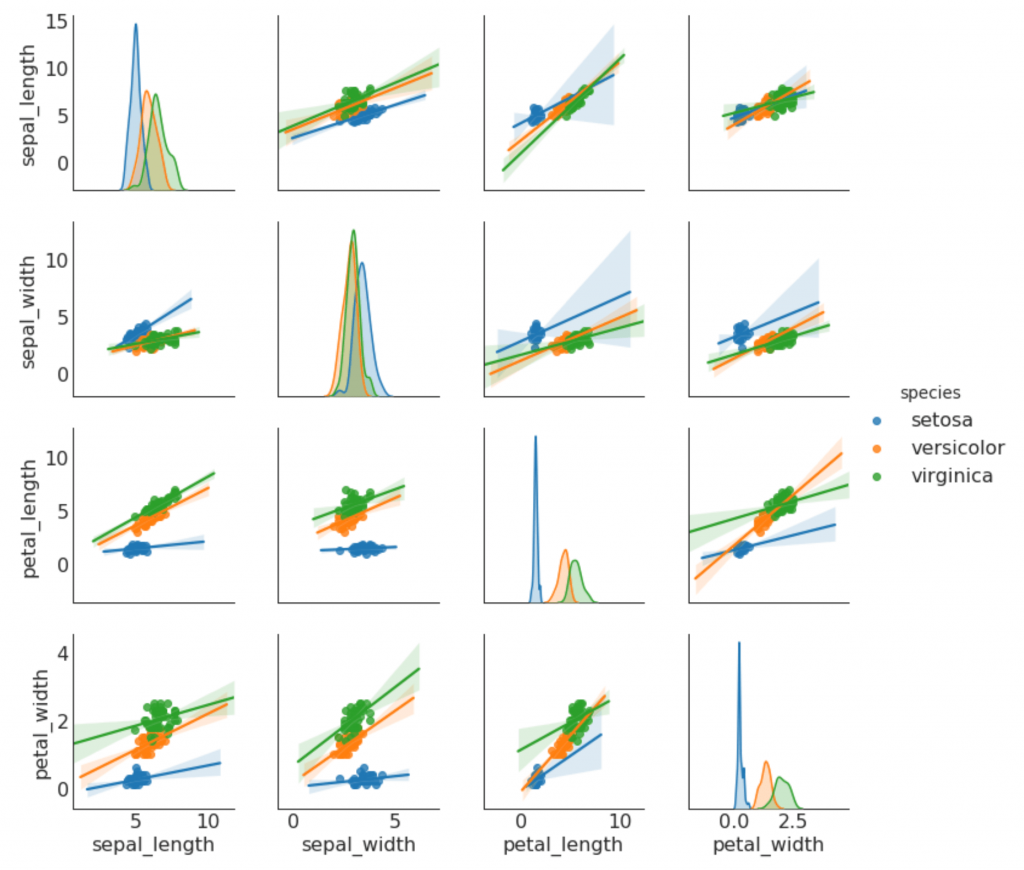
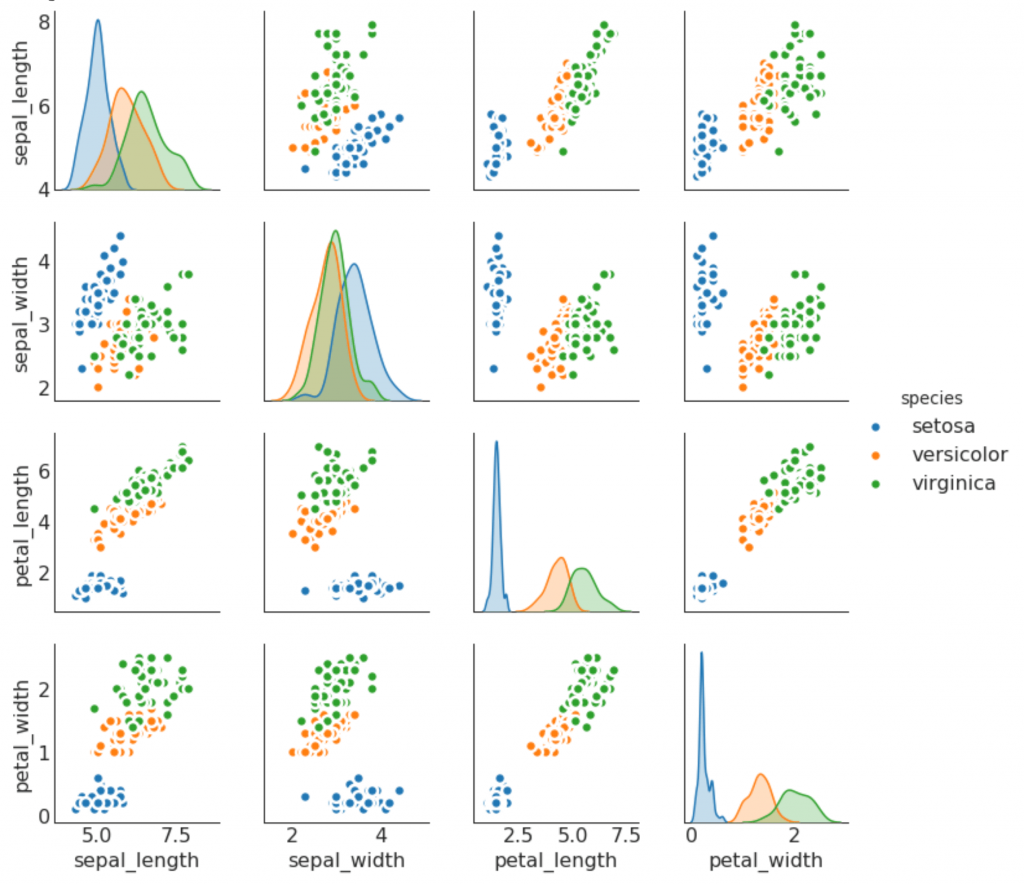
9. Calendrier des paires
Souvent utilisé en analyse de recherche pour comprendre la relation entre toutes les paires possibles de variables numériques. Il s'agit d'un outil indispensable pour l'analyse bidimensionnelle.
Déviation
10. Colonnes divergentes
Si vous voulez voir comment les éléments changent en fonction d'une métrique et visualiser l'ordre et l'ampleur de cette dispersion, les colonnes divergentes sont un excellent outil. Il permet de différencier rapidement les performances des groupes dans vos données, est assez intuitif et transmet instantanément du sens.

11. Colonnes divergentes avec du texte
- ressembler à des colonnes divergentes, et c'est préférable si vous voulez montrer la signification de chaque élément dans le graphique d'une manière bonne et présentable.
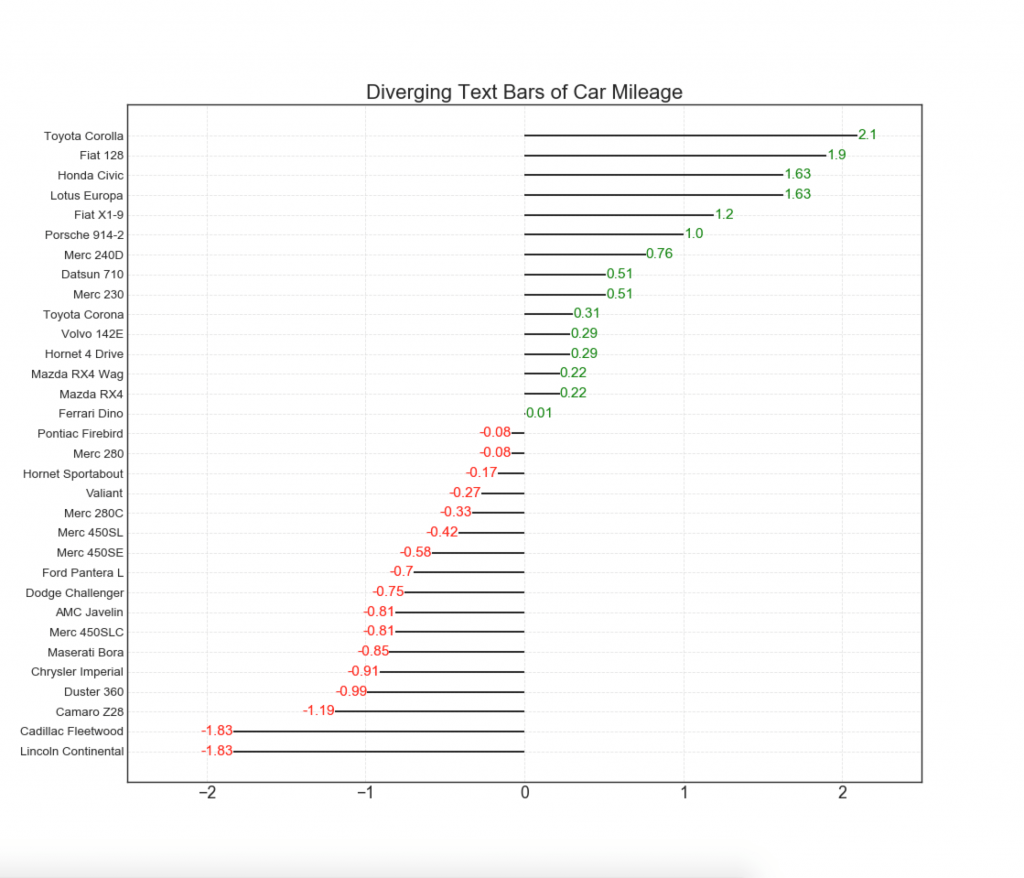
12. Points divergents
Le graphique des points divergents est également similaire aux colonnes divergentes. Cependant, par rapport aux colonnes divergentes, l'absence de colonnes réduit le degré de contraste et de divergence entre les groupes.
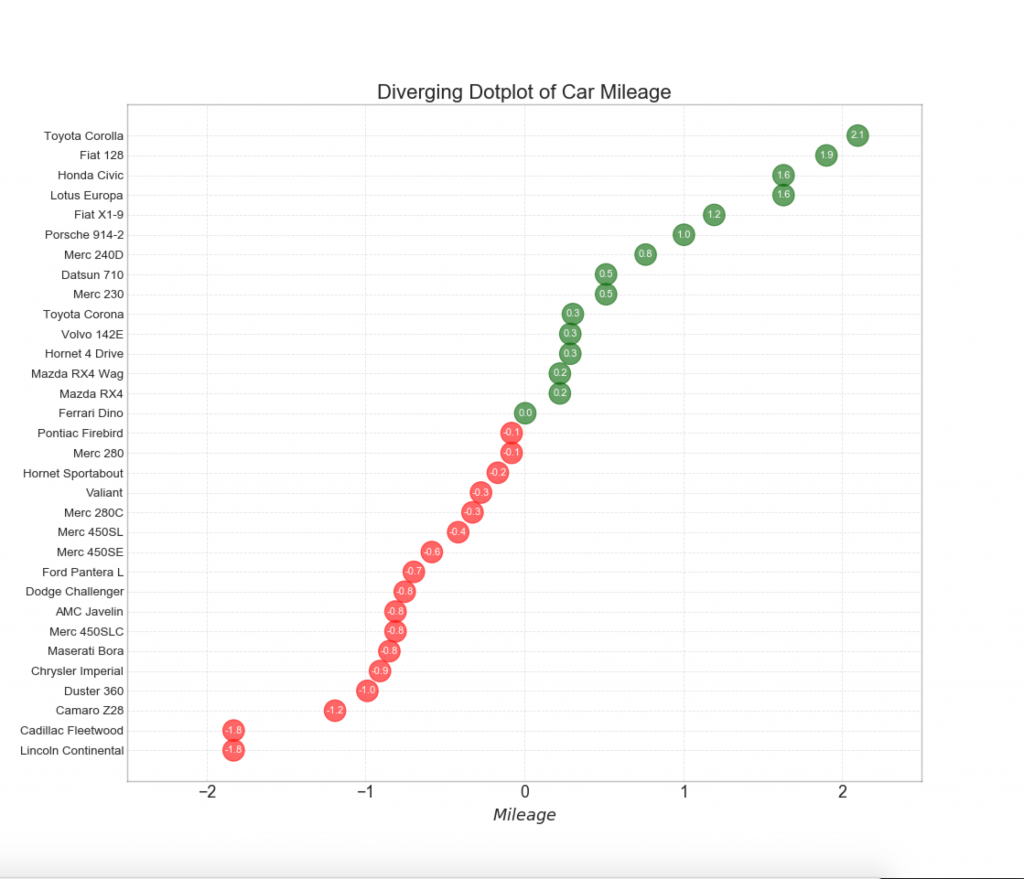
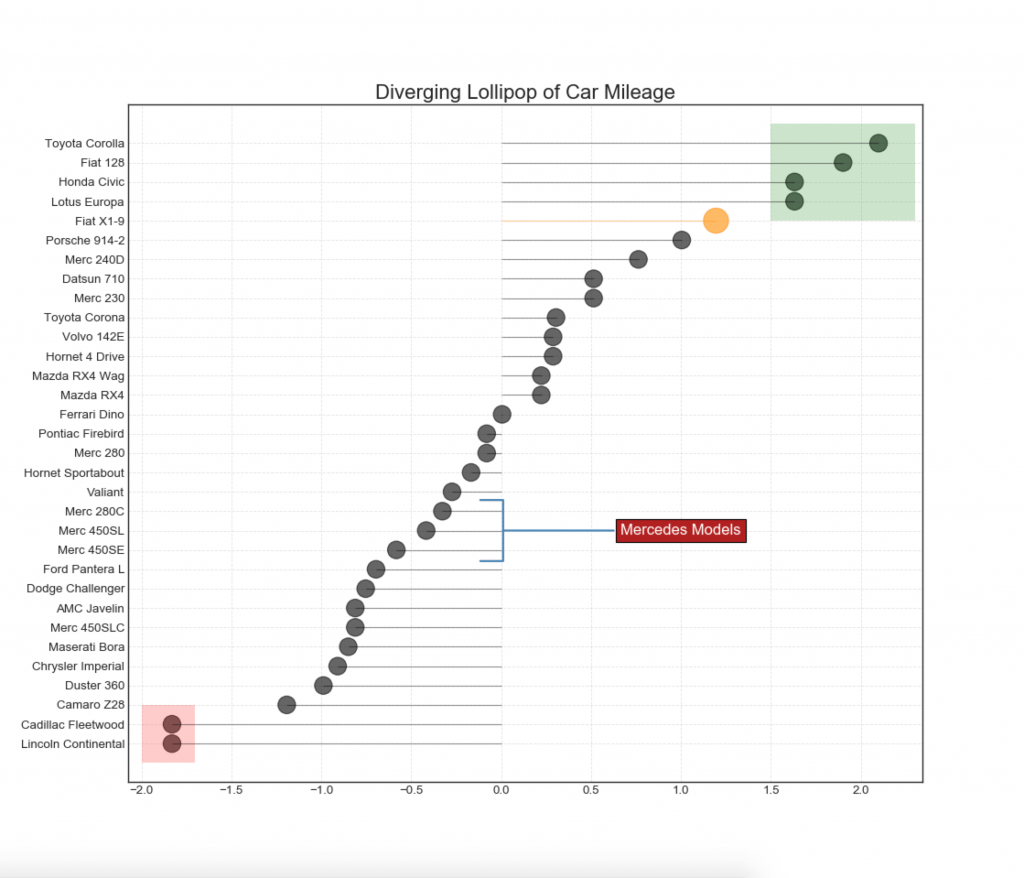
13. Tableau des sucettes divergentes avec des marqueurs
Lollipop fournit un moyen flexible de visualiser les écarts, en se concentrant sur les points de données pertinents auxquels vous souhaitez prêter attention.
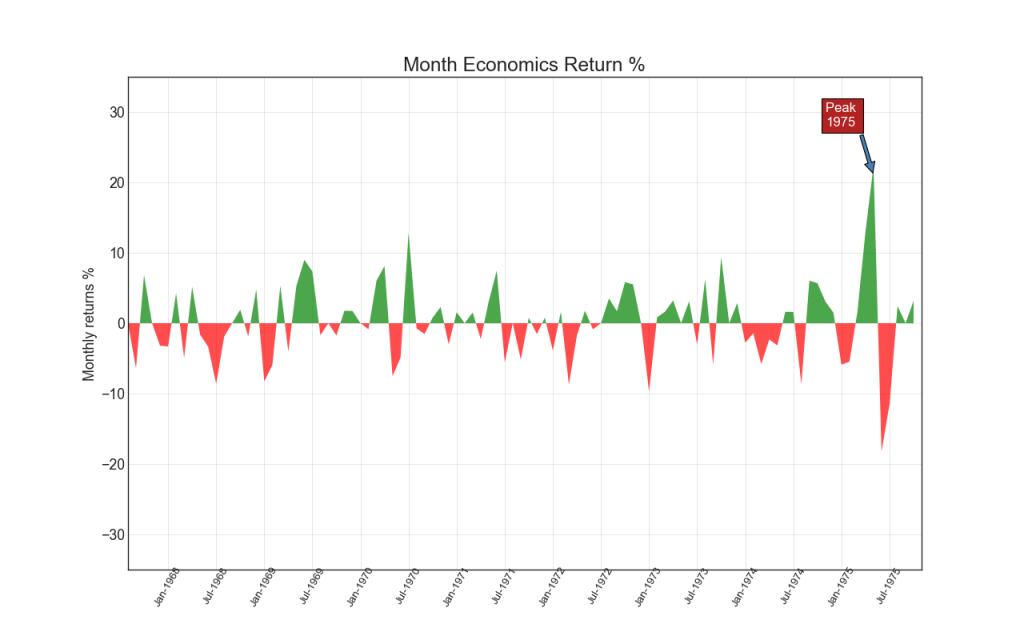
14. Tableau des aires
En coloriant la zone entre l'axe et les lignes, le diagramme de zone met l'accent sur les pics et les creux, mais aussi sur la durée des hauts et des bas. Plus les sommets sont longs, plus la zone sous la ligne est grande.
Afficher le code import numpy as np import pandas as pd
Classement
15. Histogramme ordonné
Un histogramme ordonné transmet efficacement l'ordre de classement des éléments. Mais en ajoutant une valeur métrique au-dessus du graphique, l'utilisateur reçoit des informations précises du graphique lui-même.
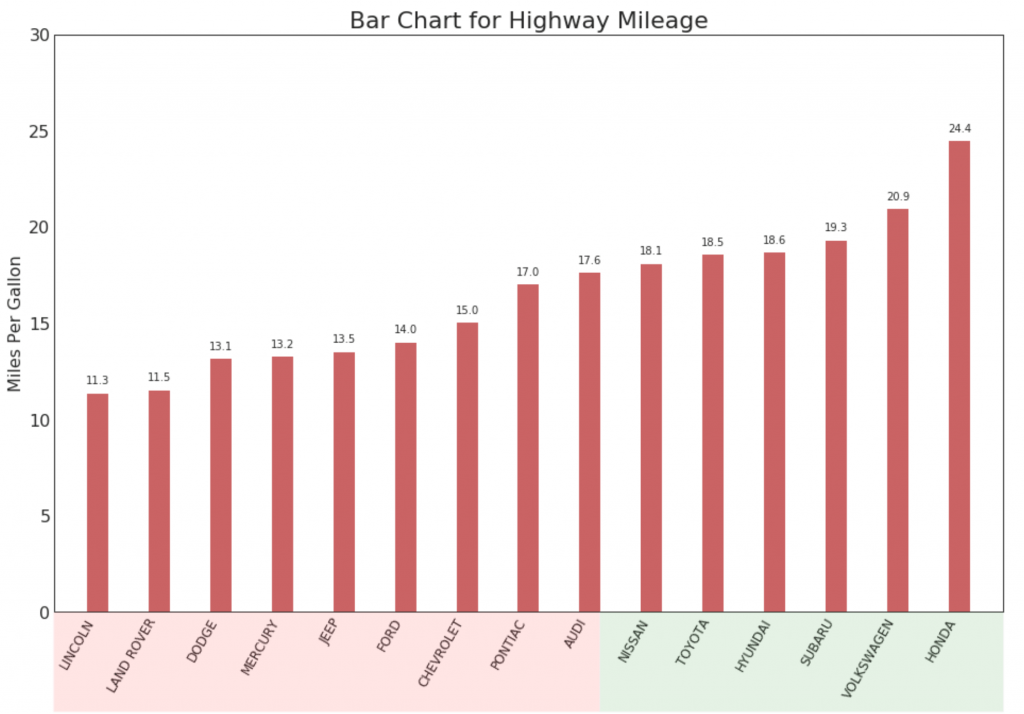
16. Tableau des sucettes
Le graphique Lollipop sert un objectif similaire à un histogramme ordonné d'une manière visuellement agréable.
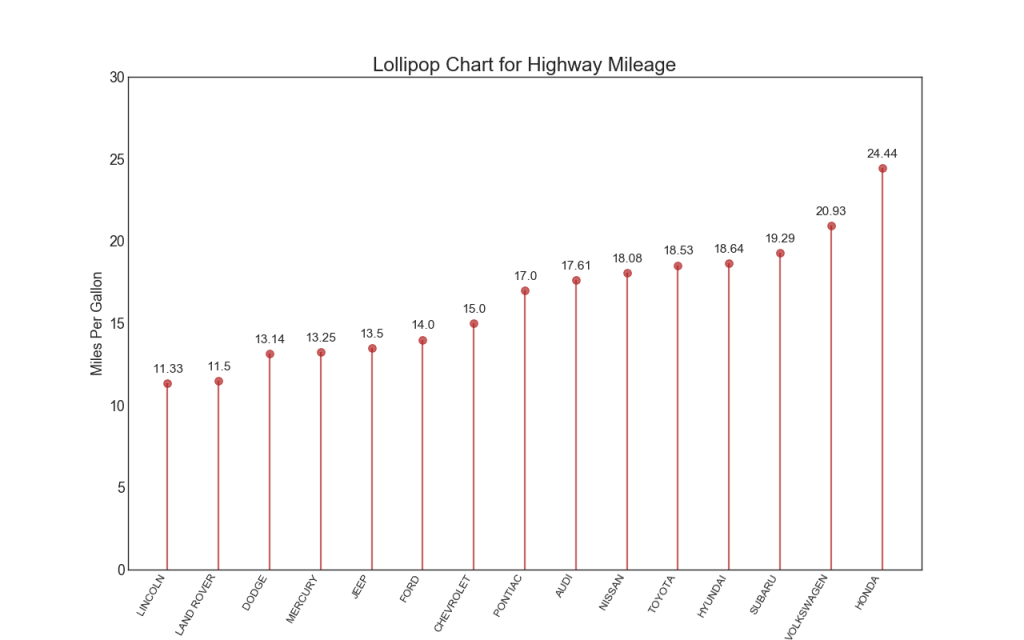
17. Tableau en pointillé avec signatures
Un nuage de points transmet le classement des éléments. Et comme il est aligné le long de l'axe horizontal, vous pouvez évaluer visuellement la distance entre les points les uns des autres.
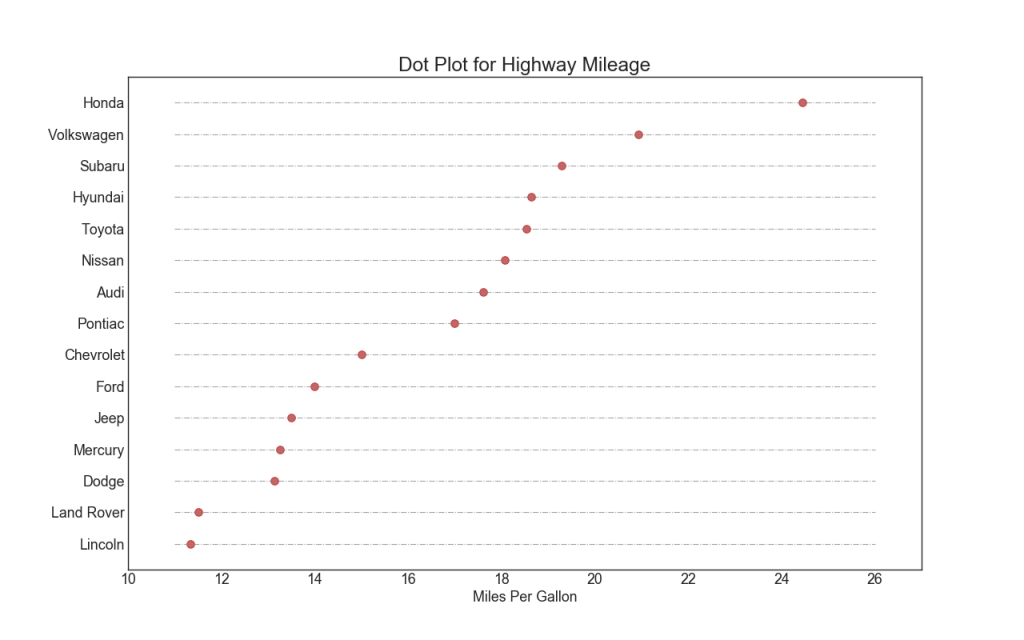
18. Carte inclinée
Le tableau des pentes est le plus approprié pour comparer les positions «avant» et «après» d'une personne / d'un sujet donné.
Afficher le code import matplotlib.lines as mlines

19. "Haltères"
Le graphique «Haltère» indique les positions «avant» et «après» de diverses influences, ainsi que l'ordre de classement des éléments. Ceci est très utile si vous souhaitez visualiser l'effet de quelque chose sur différents objets.
Afficher le code import matplotlib.lines as mlines
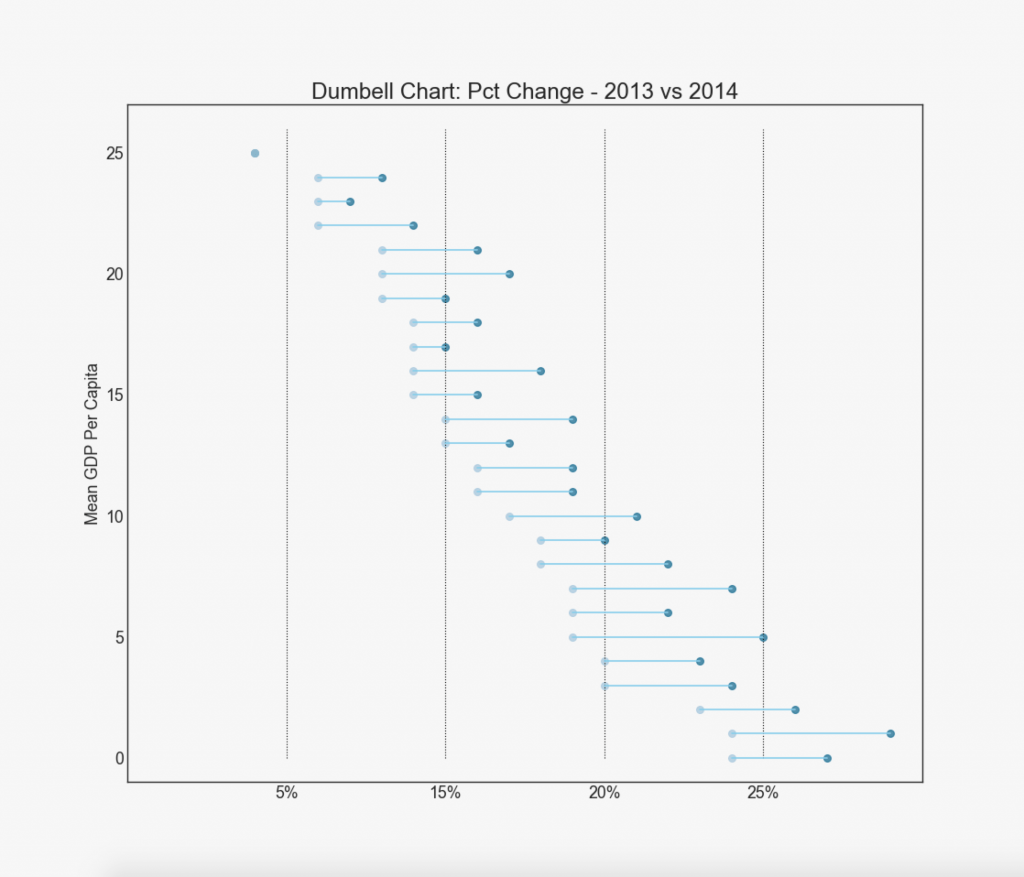
Distribution
20. Histogramme pour une variable continue
L'histogramme montre la distribution de fréquence de cette variable. La présentation suivante regroupe les bandes de fréquences en fonction d'une variable catégorielle.
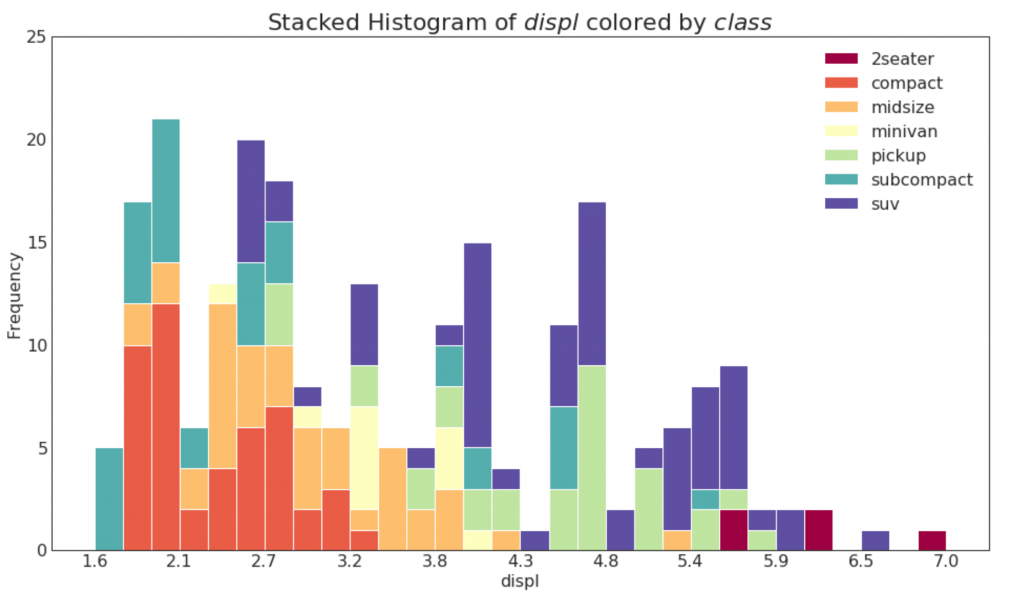
21. Histogramme d'une variable catégorielle
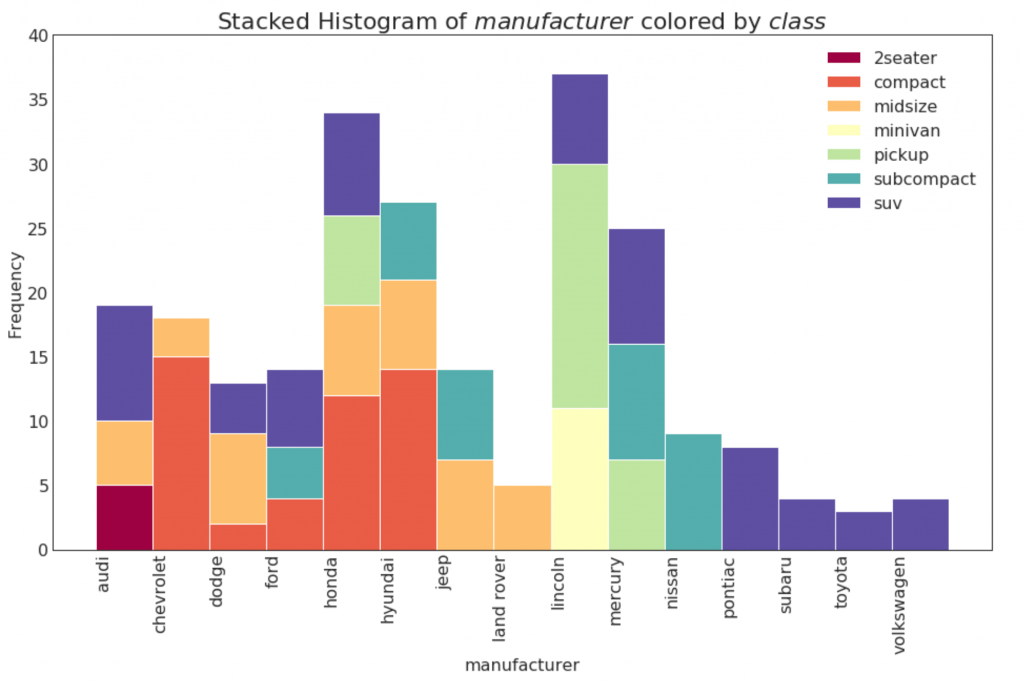
L'histogramme d'une variable catégorielle montre la distribution de fréquence de cette variable. En coloriant les colonnes, vous pouvez visualiser la distribution par rapport à une autre variable catégorielle représentant les couleurs.
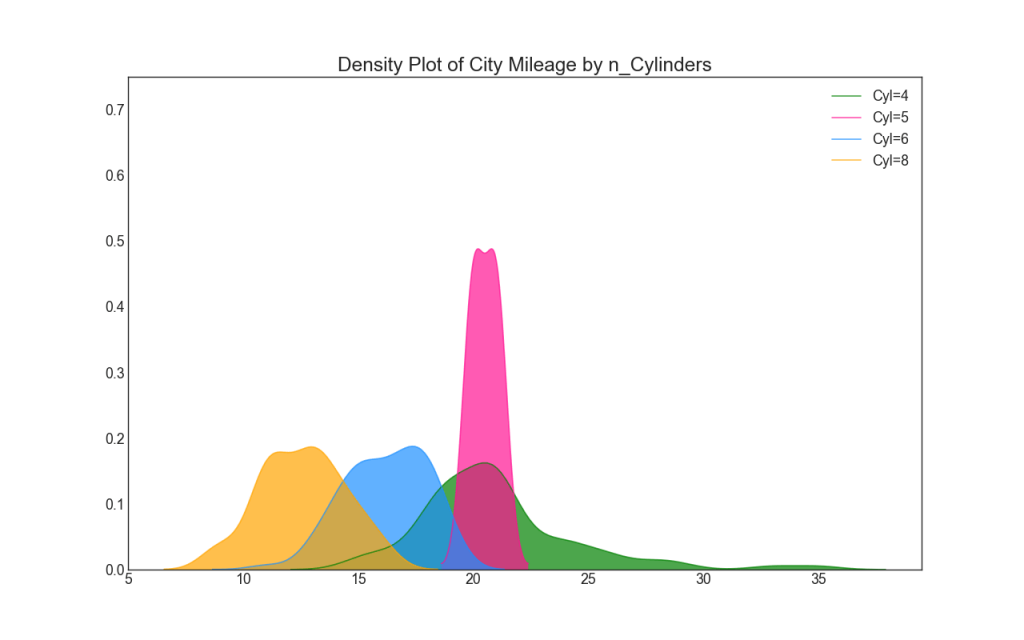
22. Graphique de densité
Les graphiques de densité sont un outil largement utilisé pour visualiser la distribution d'une variable continue. Après les avoir regroupés par la variable «réponse», vous pouvez vérifier la relation entre X et Y. Voici un exemple si, pour plus de clarté, nous décrivons comment la distribution du kilométrage dans la ville varie en fonction du nombre de cylindres.
23. Courbes de densité avec un histogramme
La courbe de densité avec un histogramme combine les informations récapitulatives transmises par les deux graphiques afin que vous puissiez voir les deux au même endroit.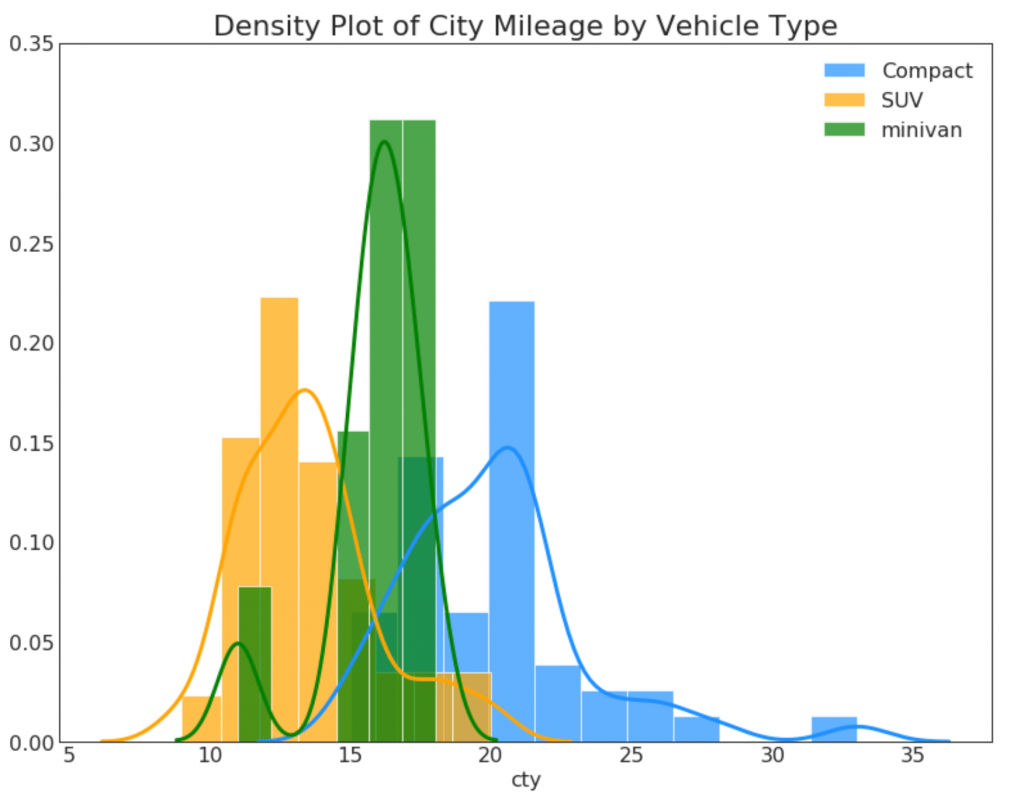
24. Tableau de joie
Le graphique Joy vous permet de chevaucher les courbes de densité de différents groupes, c'est un excellent moyen de visualiser la distribution d'un grand nombre de groupes les uns par rapport aux autres. Il semble agréable à l'œil et ne transmet clairement que les informations correctes.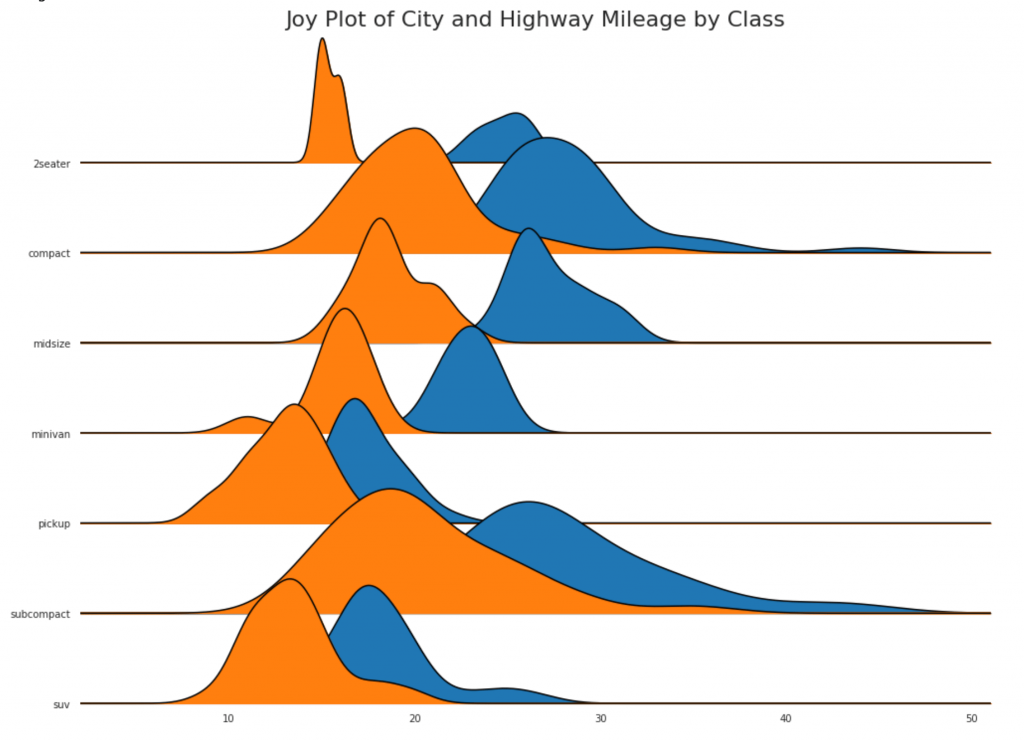
25. Diagramme de dispersion distribué
Le nuage de points distribué montre une distribution unidimensionnelle de points segmentés en groupes. Plus les points sont sombres, plus la concentration de points de données dans cette région est importante. En colorant la médiane de différentes manières, l'arrangement réel des groupes devient instantanément apparent.Afficher le code import matplotlib.patches as mpatches

26. Graphiques avec rectangles
Ces graphiques sont un excellent moyen de visualiser la distribution, en connaissant la médiane, les 25e, 75e quartiles et les hauts avec des bas. Cependant, vous devez être prudent lors de l'interprétation de la taille des champs, ce qui peut potentiellement fausser le nombre de points contenus dans ce groupe. Ainsi, l'indication manuelle du nombre d'observations dans chaque cellule aidera à surmonter cet inconvénient.Par exemple, les deux premiers rectangles de gauche ont la même taille, bien qu'ils aient respectivement 5 et 47 éléments de données. Par conséquent, il est nécessaire de noter le nombre d'observations.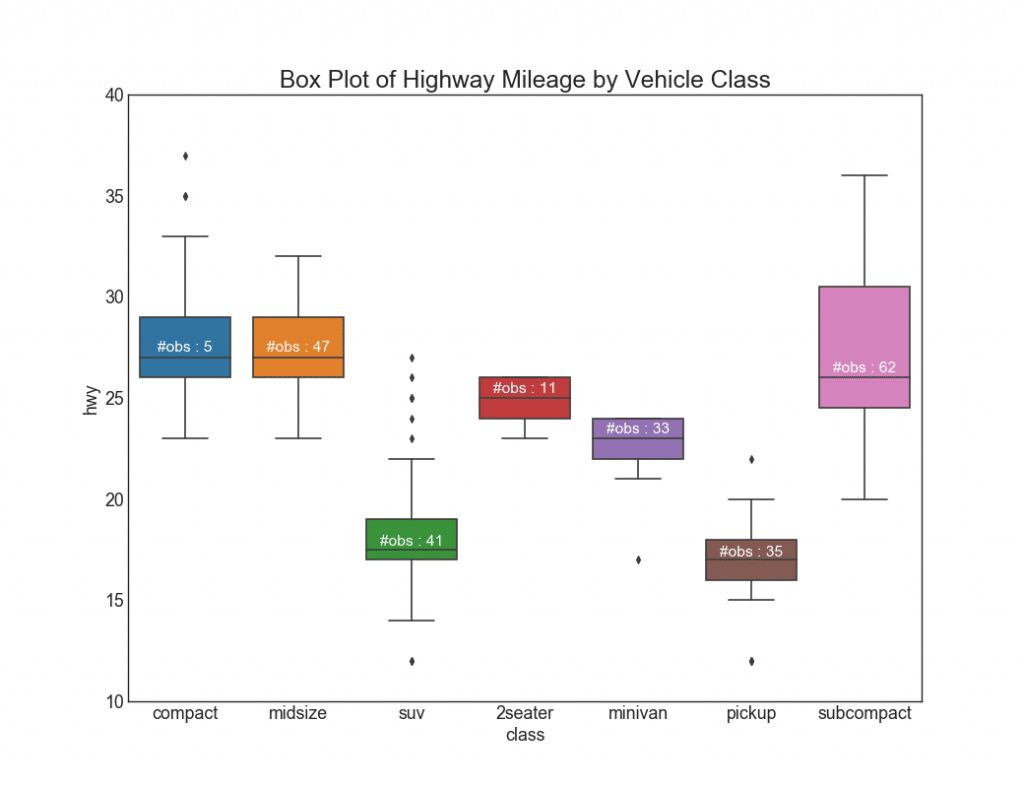
27. Graphiques avec des rectangles et des points
Le tracé Dot + Box transmet des informations similaires, comme le tracé, divisées en groupes. De plus, les points donnent une idée du nombre d'éléments de données dans chaque groupe.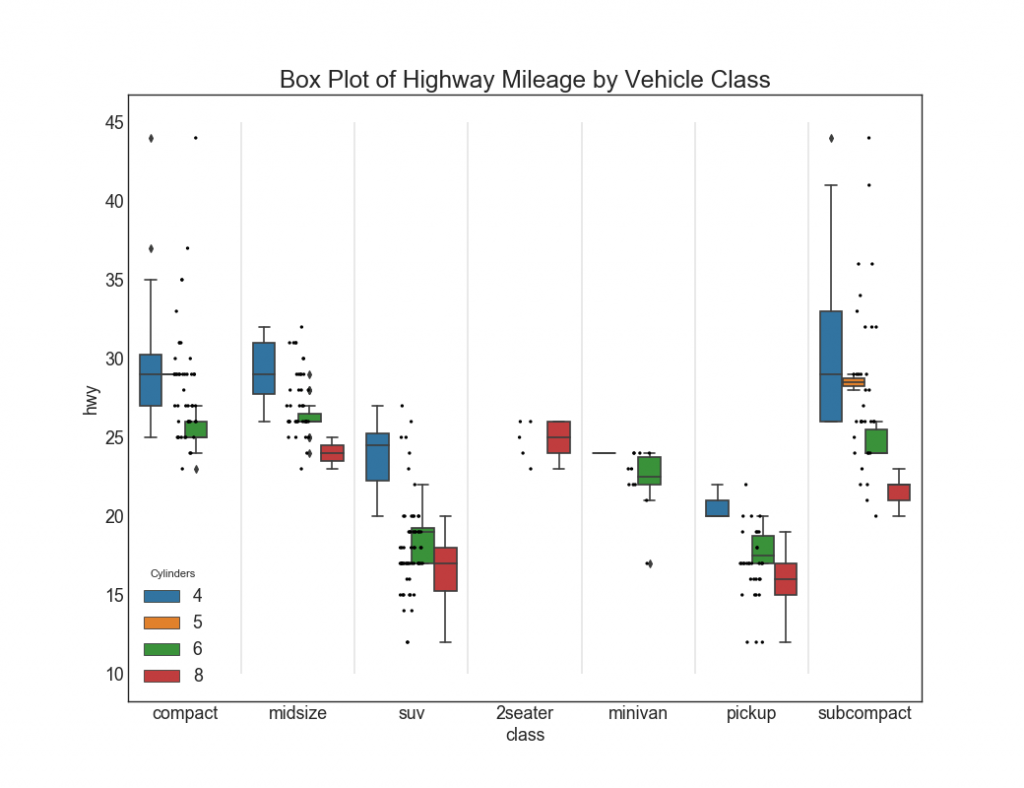
28. Annexe «violons»
Un tel calendrier est une alternative visuellement agréable au boxplot. La forme ou la zone du «violon» dépend de la quantité de données dans ce groupe. Cependant, de tels graphiques peuvent être plus difficiles à lire et ils ne sont généralement pas utilisés dans des environnements professionnels.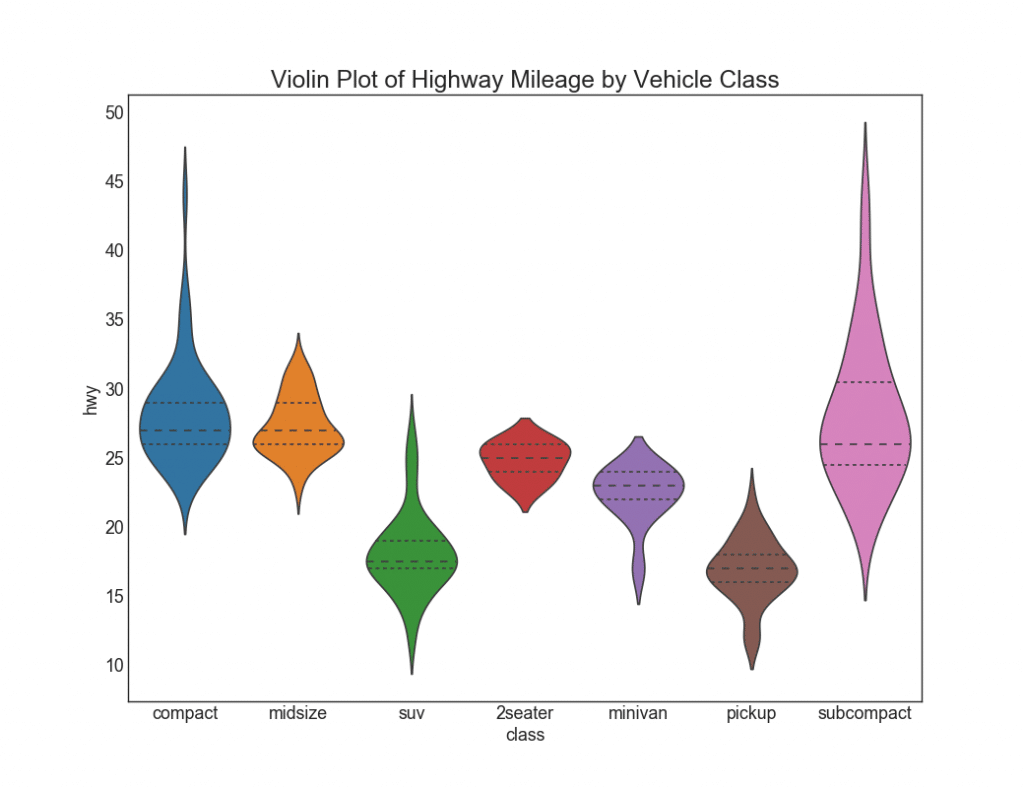
29. Pyramide de population
Une pyramide des âges peut être utilisée pour montrer la distribution des groupes classés par volume, ou pour montrer le filtrage progressif de la population, comme indiqué ci-dessous, pour visualiser combien de personnes passent par chaque étape de l'entonnoir marketing.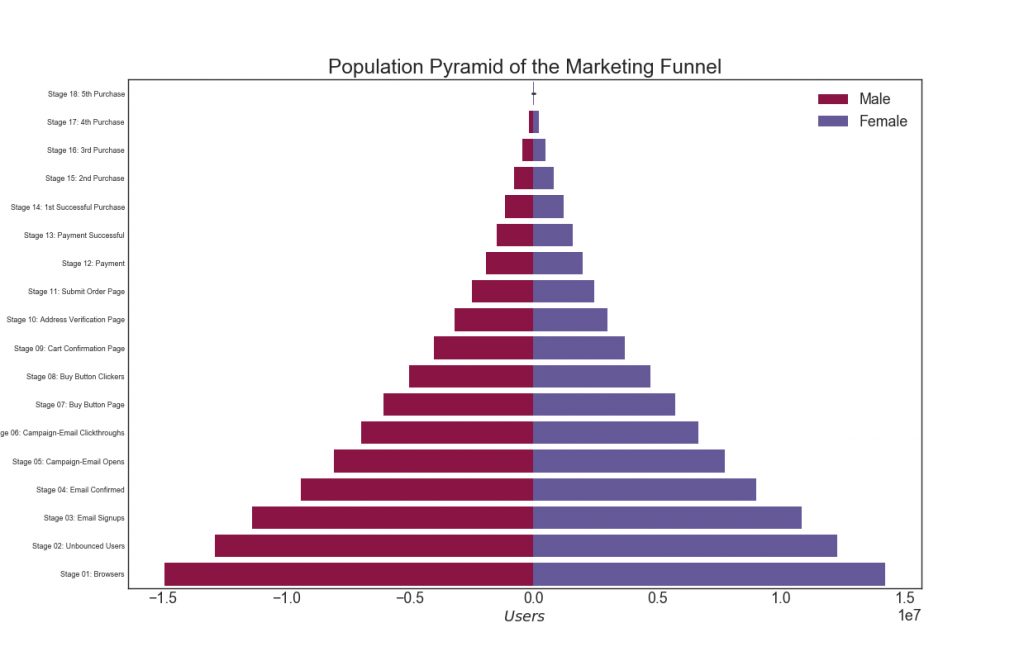
30. Cartes catégorielles
Les graphiques catégoriels fournis par la bibliothèque Seaborn peuvent être utilisés pour visualiser la distribution du nombre de deux variables catégorielles ou plus l'une par rapport à l'autre.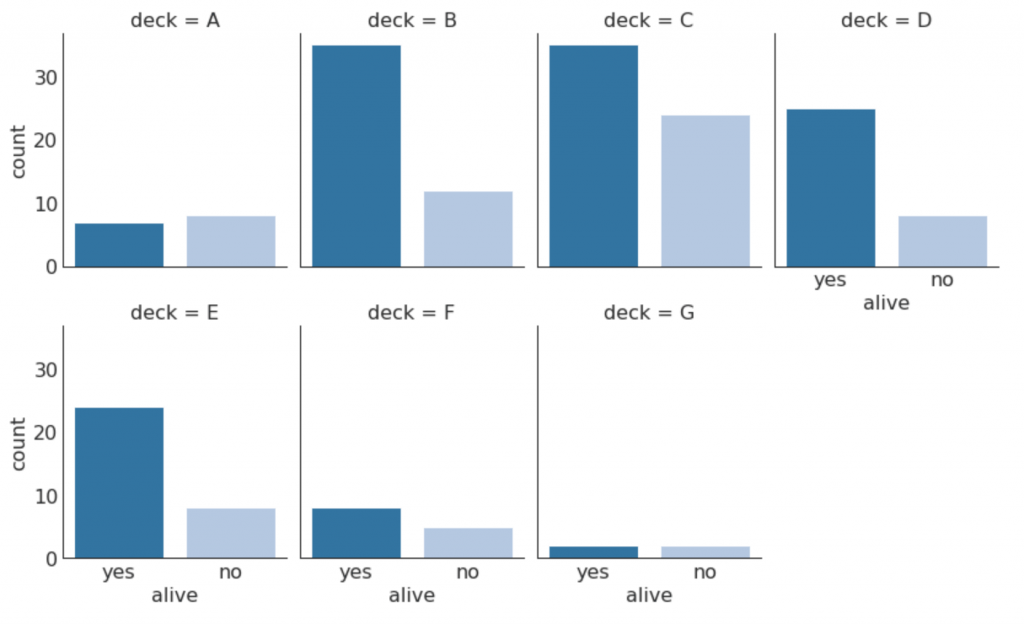
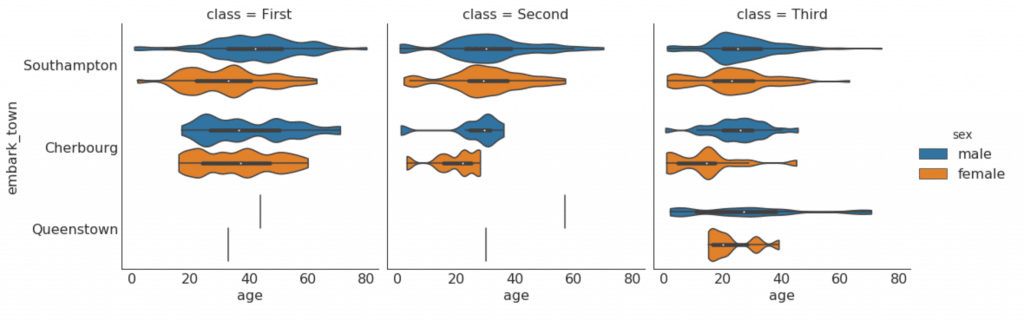
Assemblage, composition
31. Diagramme gaufré
Un graphique gaufré peut être créé à l'aide du package pywaffle et est utilisé pour afficher les compositions des groupes dans la plupart de la population.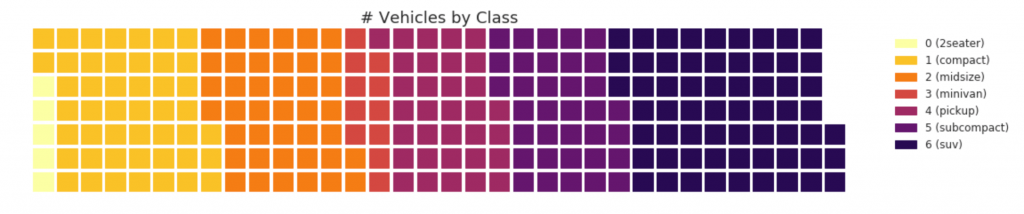
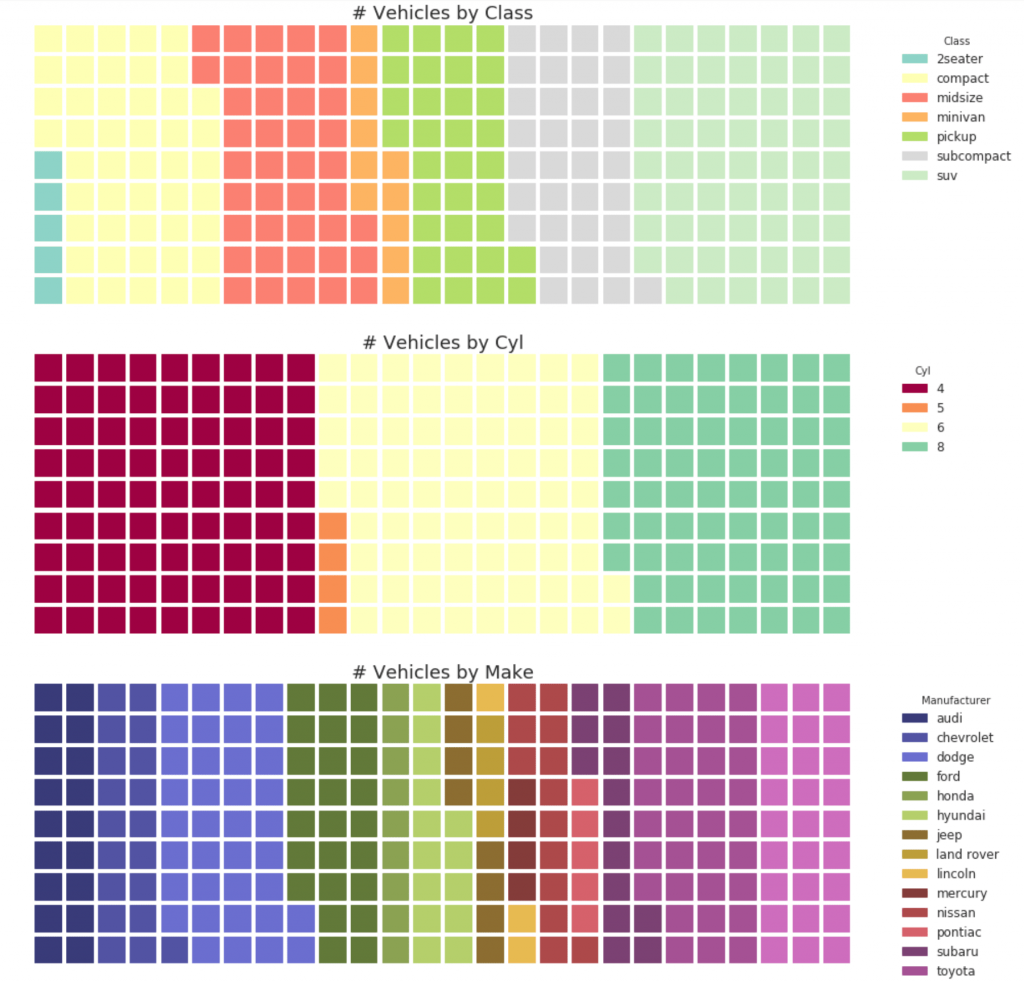
32. Graphique circulaire
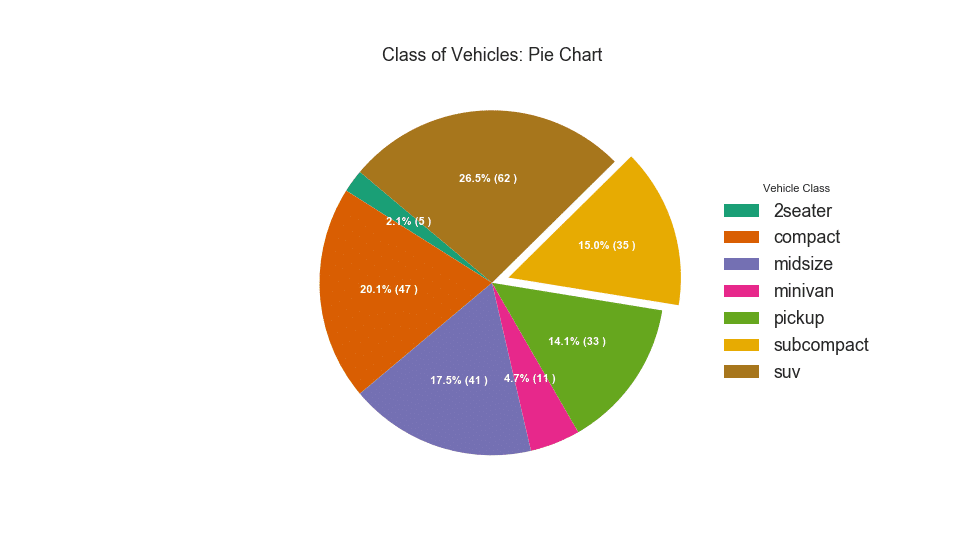
Un camembert est un moyen classique de montrer la composition des groupes. Cependant, il n'est actuellement généralement pas recommandé d'utiliser ce graphique car la zone des segments peut parfois être trompeuse. Par conséquent, si vous souhaitez utiliser un graphique à secteurs, il est fortement recommandé d'enregistrer explicitement le pourcentage ou le nombre pour chaque partie du graphique à secteurs.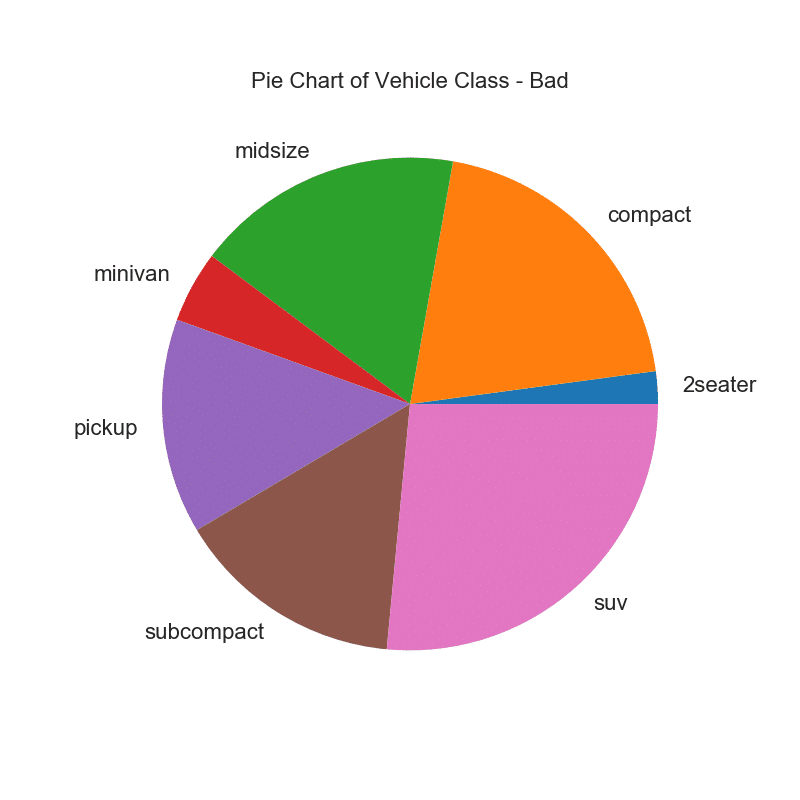
33. Carte des arbres
La carte arborescente ressemble à un graphique circulaire et fonctionne mieux sans induire en erreur la part de chaque groupe.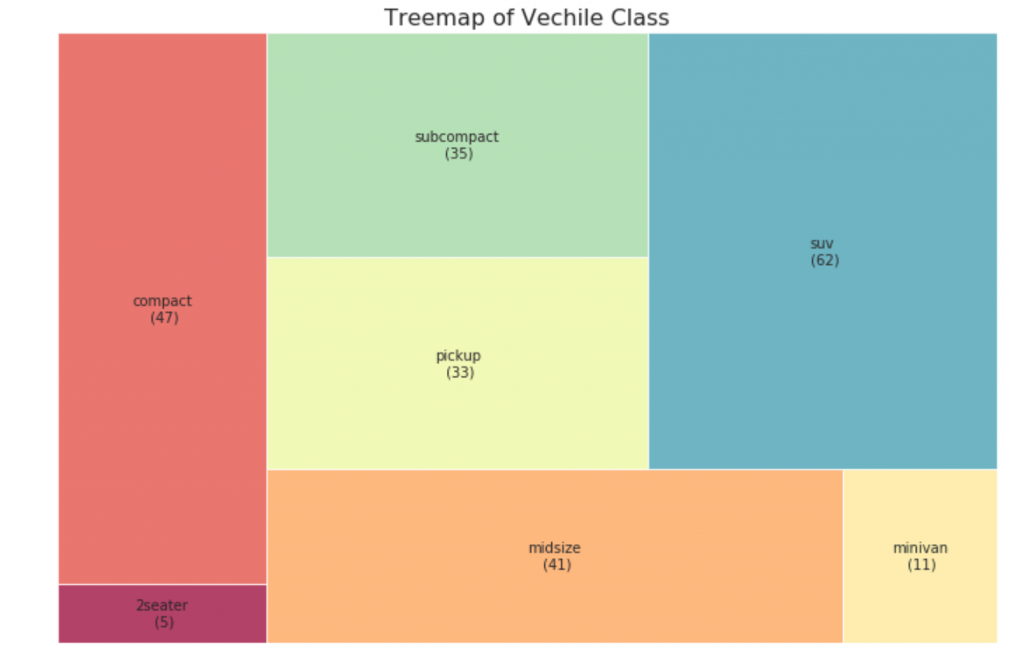
34. Histogramme
Un histogramme est un moyen classique de visualiser des éléments en fonction de la quantité ou de toute métrique donnée. Dans le diagramme ci-dessous, j'ai utilisé des couleurs différentes pour chaque élément, mais vous pouvez choisir une couleur pour tous les éléments si vous ne souhaitez pas les coloriser en groupes. Les noms de couleur sont stockés dans all_colors dans le code ci-dessous. Vous pouvez changer la couleur des rayures en définissant le paramètre de couleur dans .plt.plot ()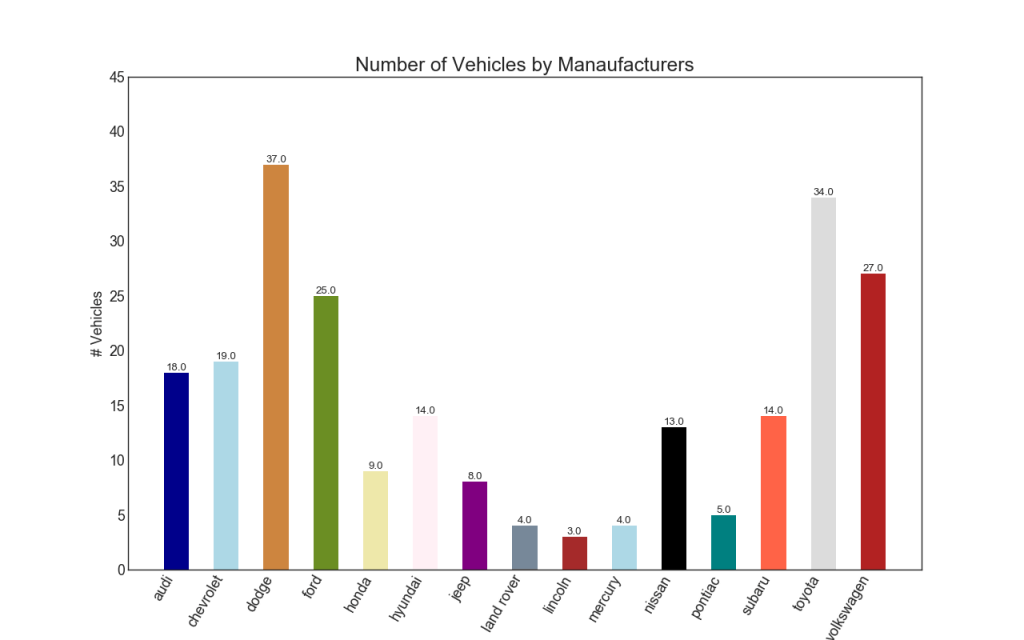
Suivi des modifications
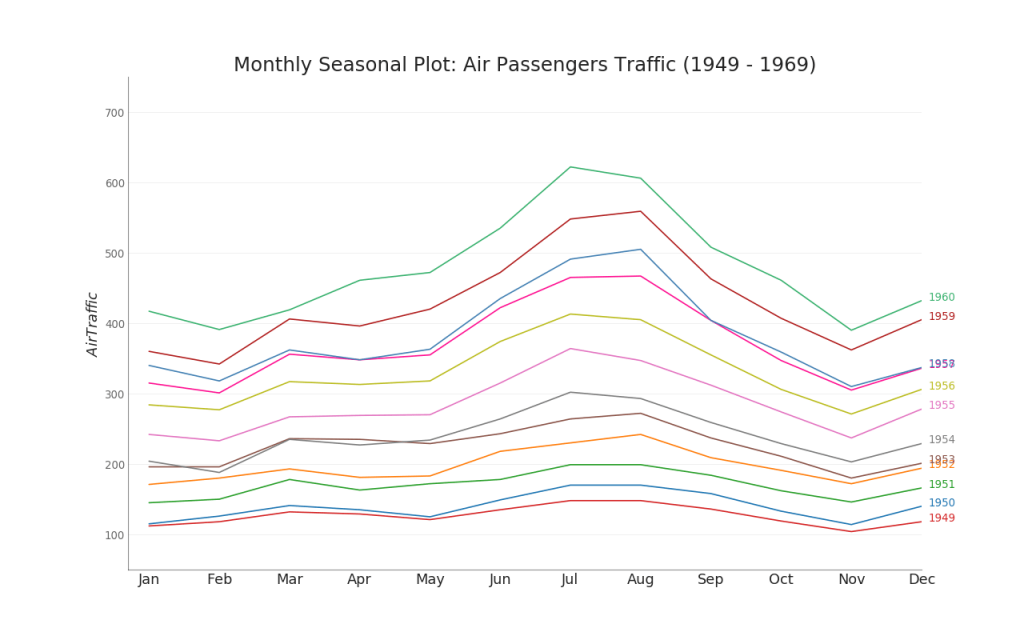
35. Graphique des séries chronologiques
Un graphique de séries chronologiques est utilisé pour visualiser comment un indicateur donné change au fil du temps. Ici, vous pouvez voir comment le flux de passagers a changé de 1949 à 1969.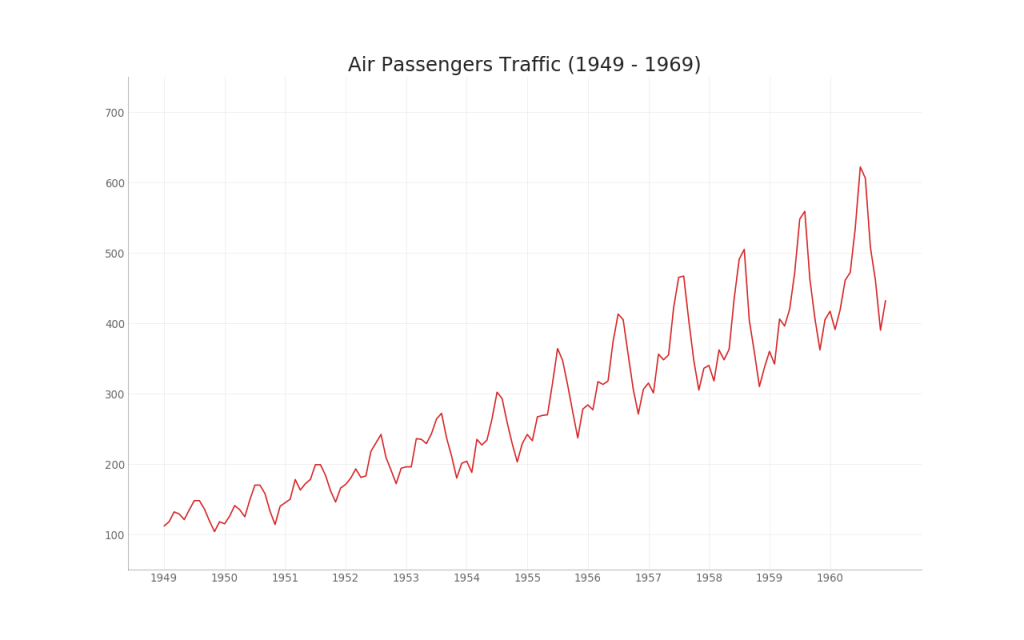
36. Séries chronologiques avec pics et creux
La série chronologique ci-dessous affiche tous les pics et creux et marque l'occurrence d'événements spéciaux individuels.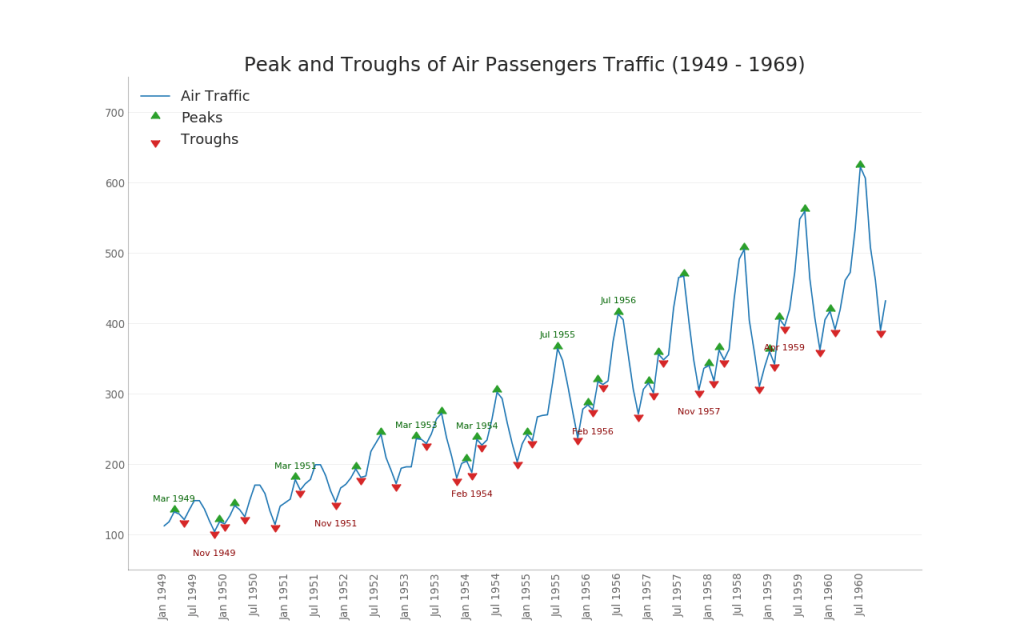
37. (ACF) (PACF)
Le graphique ACF montre la corrélation d'une série chronologique avec son propre temps. Chaque ligne verticale (sur le graphique d'autocorrélation) représente une corrélation entre la série et son heure, à partir de l'instant 0. La zone ombrée bleue sur le graphique est un niveau de signification. Ces moments qui se trouvent au-dessus de la ligne bleue sont significatifs.Alors, comment interprétez-vous cela?Pour les AirPassengers, on voit qu'à x = 14, les «sucettes» ont franchi la ligne bleue et sont donc d'une grande importance. Cela signifie que le trafic de passagers observé il y a jusqu'à 14 ans a un impact sur le trafic observé aujourd'hui.Le PACF, d'autre part, montre l'autocorrélation de tout temps donné (série temporelle) avec la série actuelle, mais avec la suppression des influences entre eux.Afficher le code from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
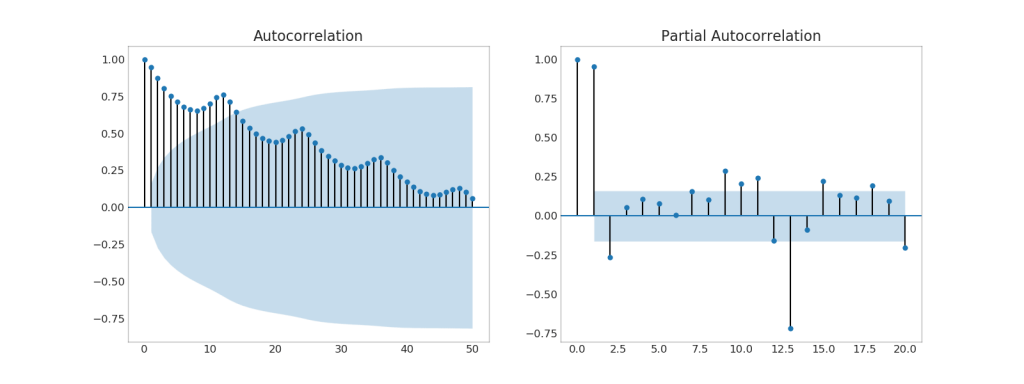
38. Graphique de corrélation croisée
Le graphique de corrélation croisée montre les retards de deux séries temporelles entre elles.Afficher le code import statsmodels.tsa.stattools as stattools
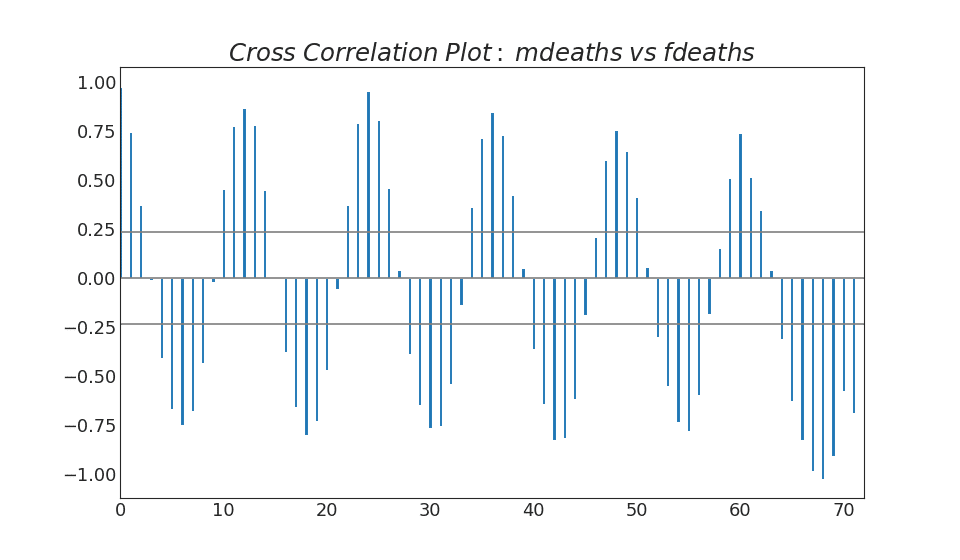
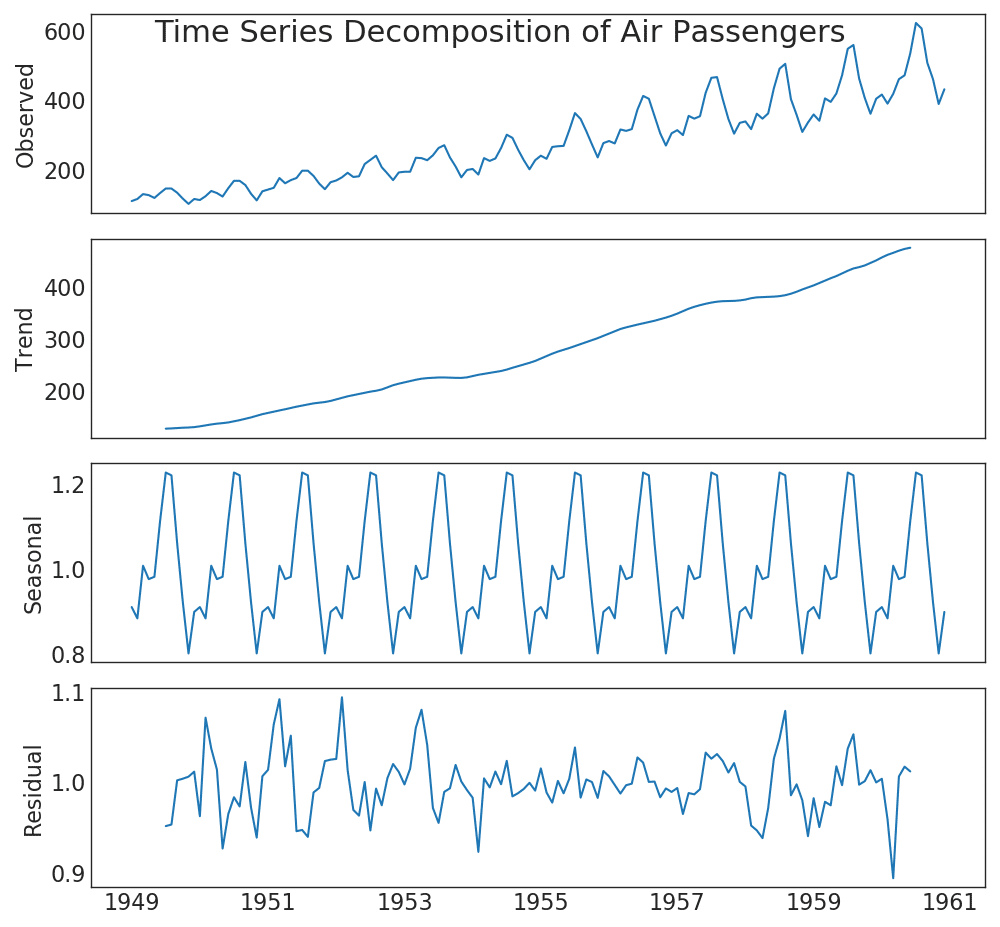
39. Extension des séries chronologiques
Le graphique d'expansion des séries chronologiques montre la répartition des séries chronologiques en composantes de tendance, saisonnières et résiduelles.Afficher le code from statsmodels.tsa.seasonal import seasonal_decompose from dateutil.parser import parse
40. Plusieurs séries chronologiques
Vous pouvez créer plusieurs séries chronologiques qui mesurent la même valeur sur un seul graphique, comme illustré ci-dessous.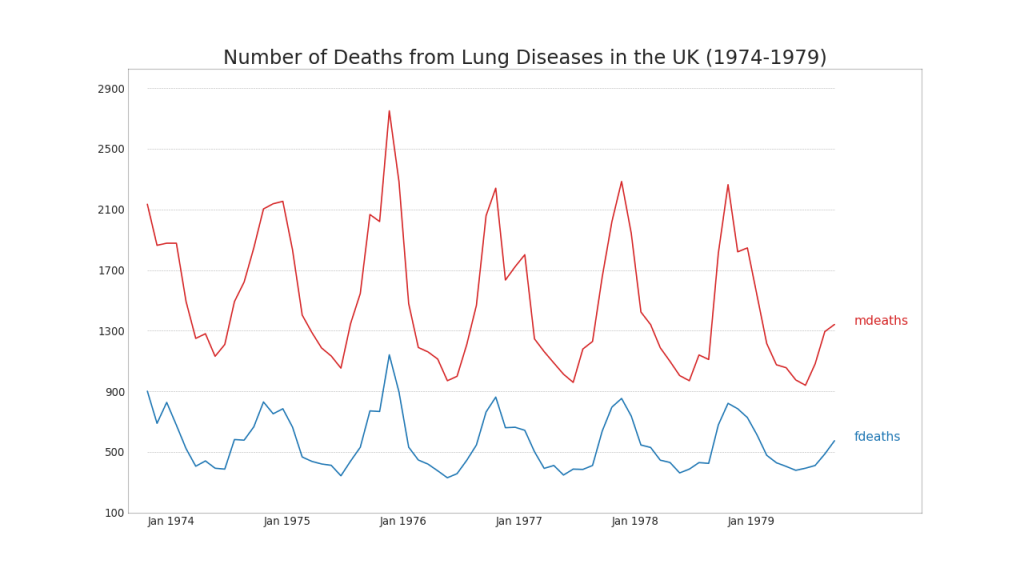
41. Construire à différentes échelles en utilisant l'axe Y secondaire
Si vous souhaitez afficher deux séries temporelles qui mesurent deux valeurs différentes en même temps, vous pouvez reconstruire la deuxième série sur l'axe Y secondaire à droite.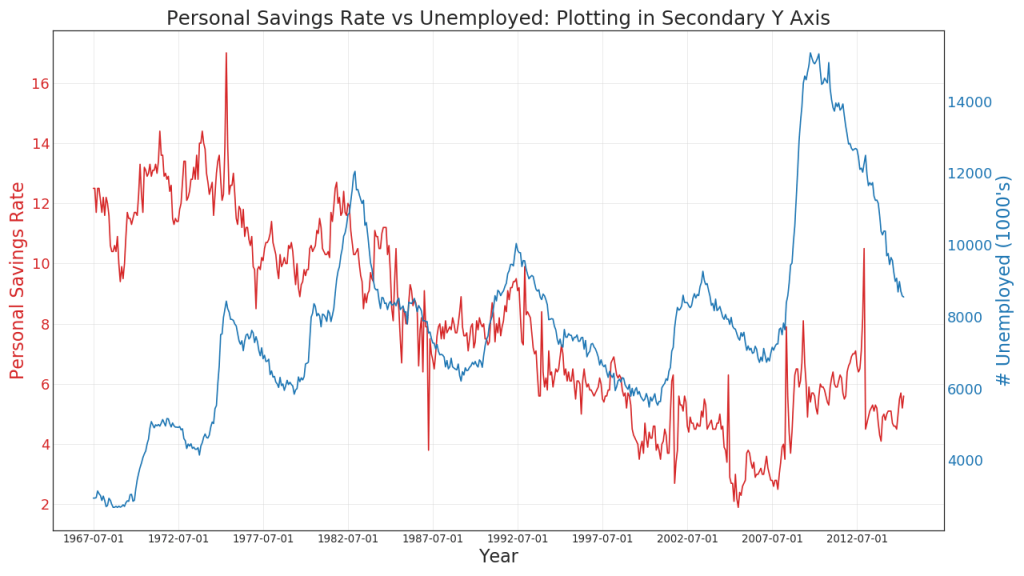
42. Séries chronologiques avec barres d'erreur
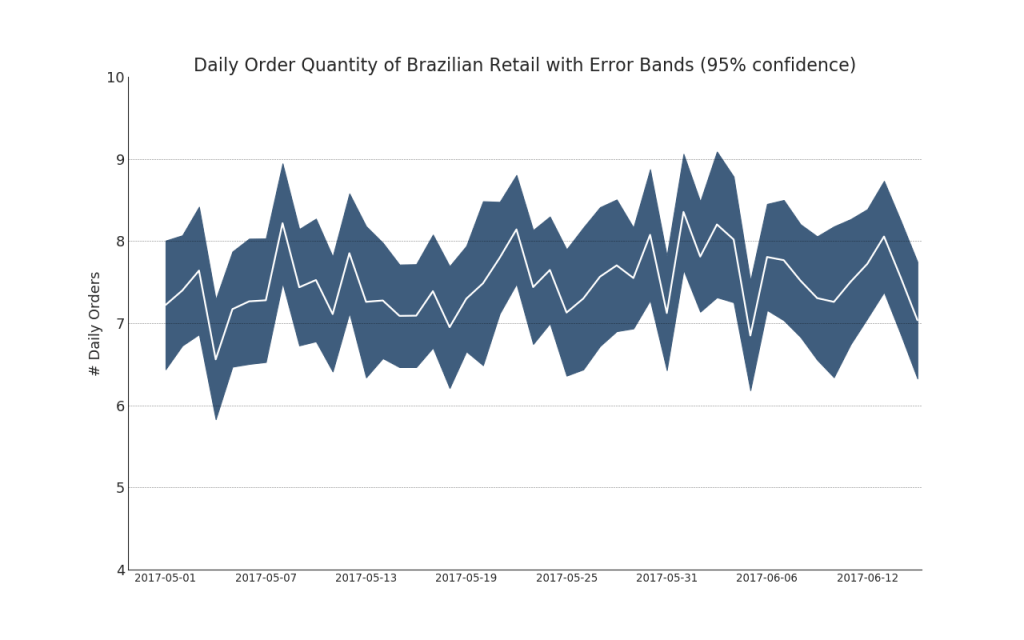
Des séries chronologiques avec barres d'erreur peuvent être construites si vous disposez d'un ensemble de données chronologiques avec plusieurs observations pour chaque point temporel (horodatage). Ci-dessous, vous pouvez voir quelques exemples basés sur la réception de commandes à différents moments de la journée. Et un autre exemple du nombre de commandes reçues dans les 45 jours.Avec cette approche, le nombre moyen de commandes est indiqué par une ligne blanche. Et des intervalles de 95% sont calculés et tracés autour de la moyenne.Afficher le code from scipy.stats import sem
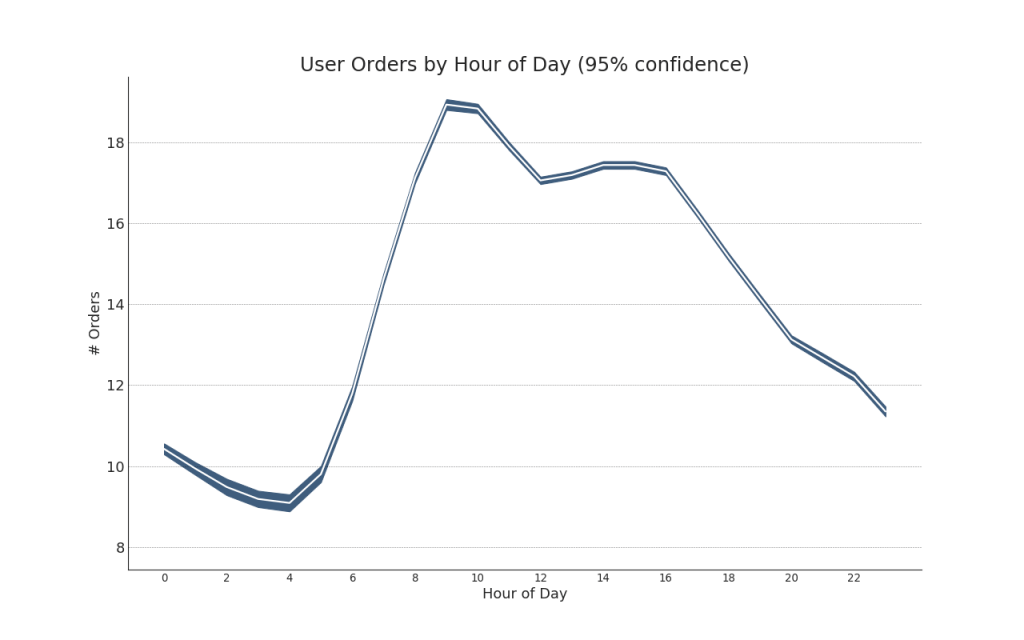
Afficher le code "Data Source: https://www.kaggle.com/olistbr/brazilian-ecommerce#olist_orders_dataset.csv" from dateutil.parser import parse from scipy.stats import sem
43. Graphique avec accumulation
Le graphique à aires empilées fournit une représentation visuelle du taux de cotisation de plusieurs séries chronologiques.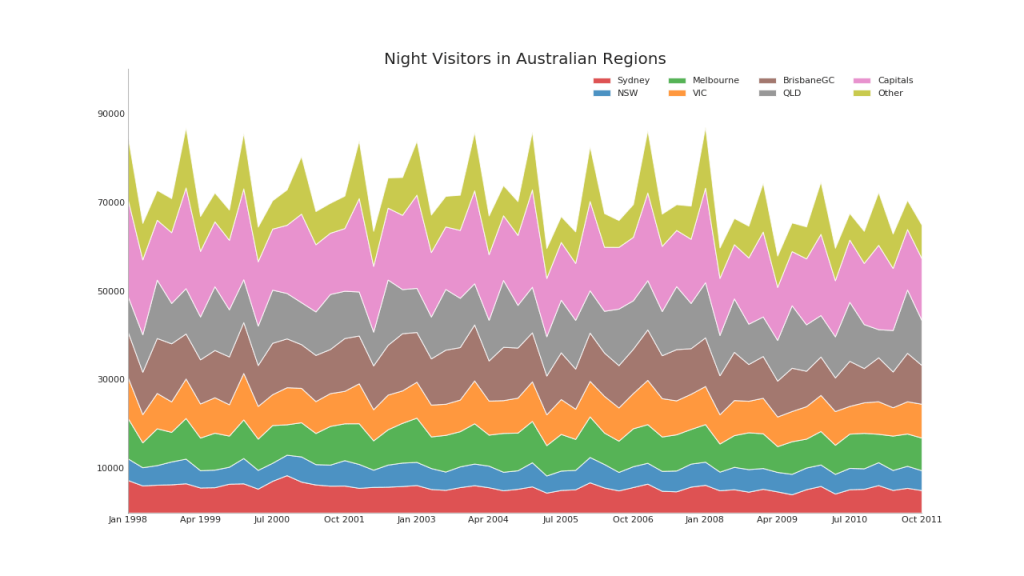
44. Carte de zone non empilée
Un graphique à aire ouverte est utilisé pour visualiser la progression (hauts et bas) de deux lignes ou plus l'une par rapport à l'autre. Dans le diagramme ci-dessous, vous pouvez clairement voir comment le taux d'épargne personnelle diminue avec une augmentation de la durée moyenne du chômage. Un diagramme avec des sections ouvertes montre bien ce phénomène.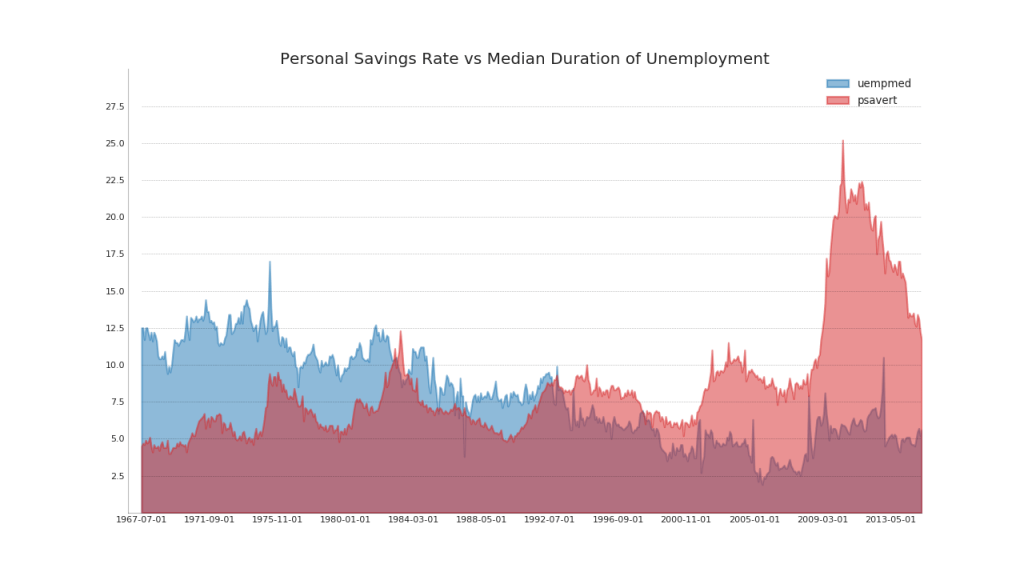
45. Calendrier thermique du calendrier
Une carte de calendrier est une option alternative et moins préférée pour visualiser les données en fonction du temps par rapport à une série chronologique. Bien qu'elles puissent être visuellement attrayantes, les valeurs numériques ne sont pas entièrement évidentes.Afficher le code import matplotlib as mpl import calmap

46. Diagramme saisonnier
L'horaire saisonnier peut être utilisé pour comparer des séries chronologiques réalisées le même jour de la saison précédente (année / mois / semaine, etc.).Afficher le code from dateutil.parser import parse
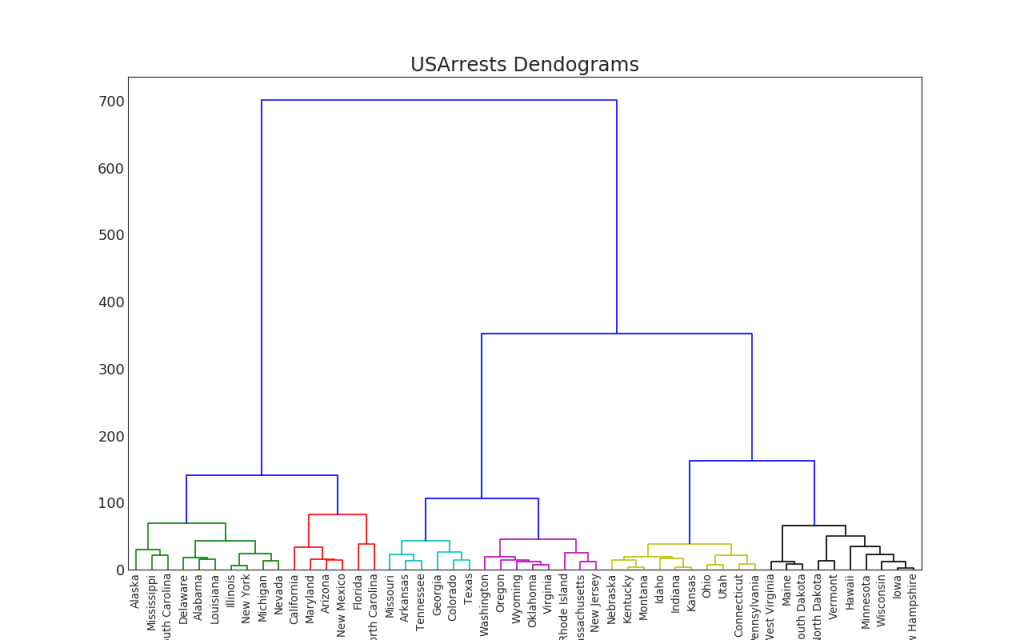
Les groupes
47. Dendrogramme
Le dendrogramme regroupe des points similaires sur la base d'une métrique de distance donnée et les organise sous forme de liens arborescents basés sur la similitude des points.Afficher le code import scipy.cluster.hierarchy as shc
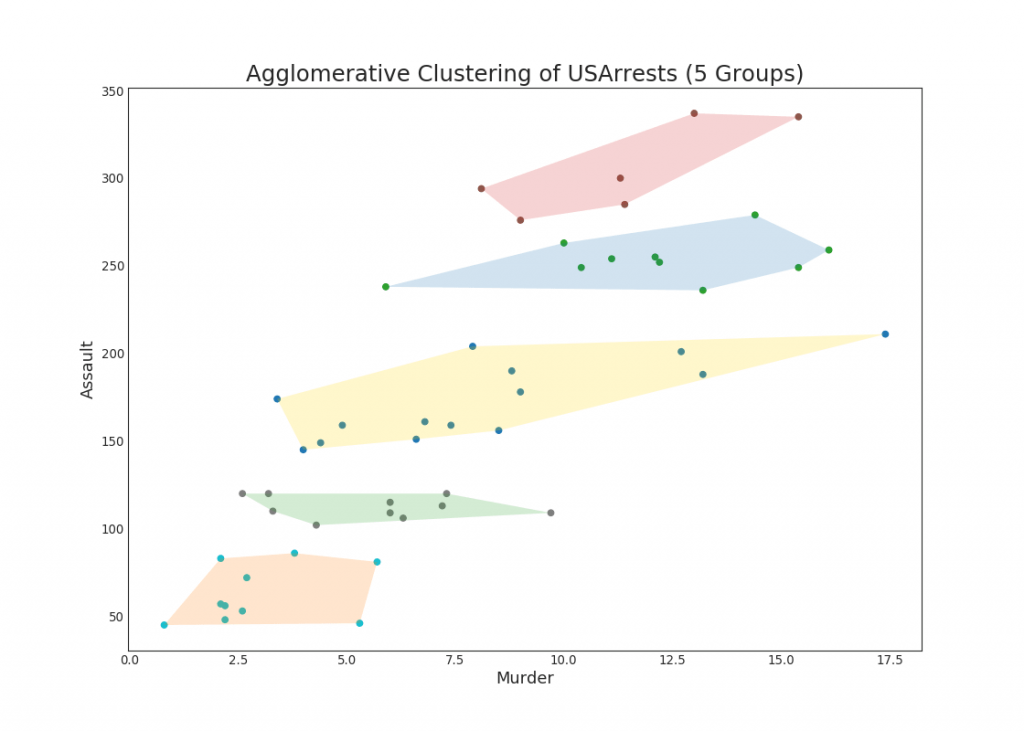
48. Diagramme de cluster
Le graphique de cluster peut être utilisé pour distinguer les points appartenant à un cluster. Ce qui suit est un exemple illustratif de regroupement des États américains en 5 groupes sur la base de l'ensemble de données USArrests. Ce graphique en grappes utilise les colonnes «tuer» et «attaquer» comme axes X et Y. Alternativement, vous pouvez utiliser le premier composant principal comme axes X et Y.Afficher le code from sklearn.cluster import AgglomerativeClustering from scipy.spatial import ConvexHull
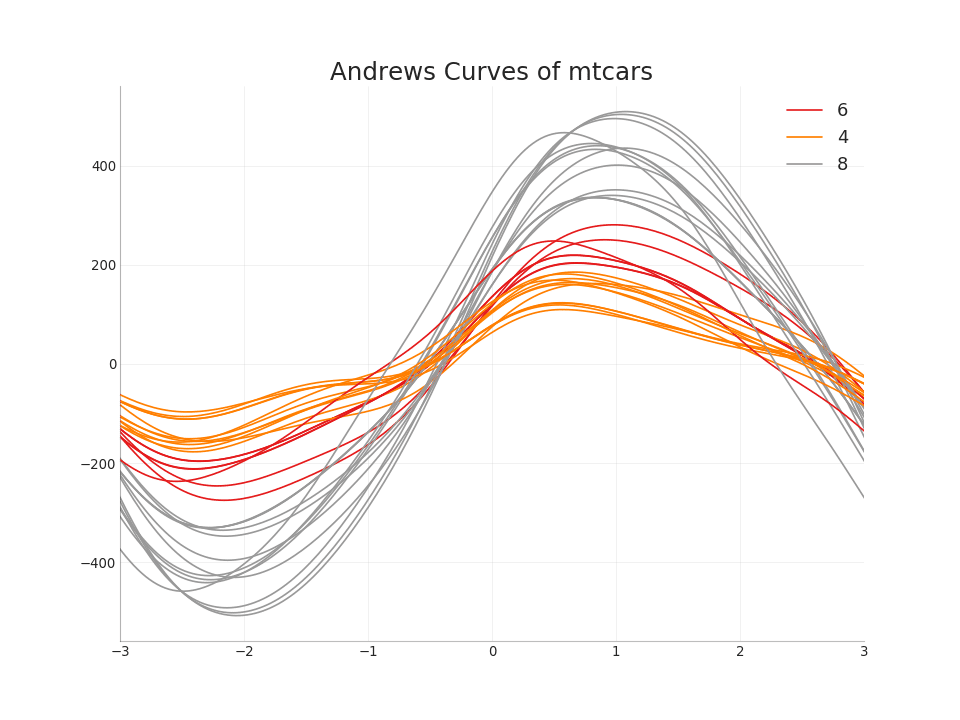
49. Andrews Curve
La courbe d'Andrews permet de visualiser si des caractéristiques numériques inhérentes à un regroupement existent en fonction d'un regroupement donné. Si les objets (colonnes du jeu de données) ne permettent pas de distinguer le groupe, les lignes ne seront pas bien séparées, comme illustré ci-dessousAfficher le code from pandas.plotting import andrews_curves
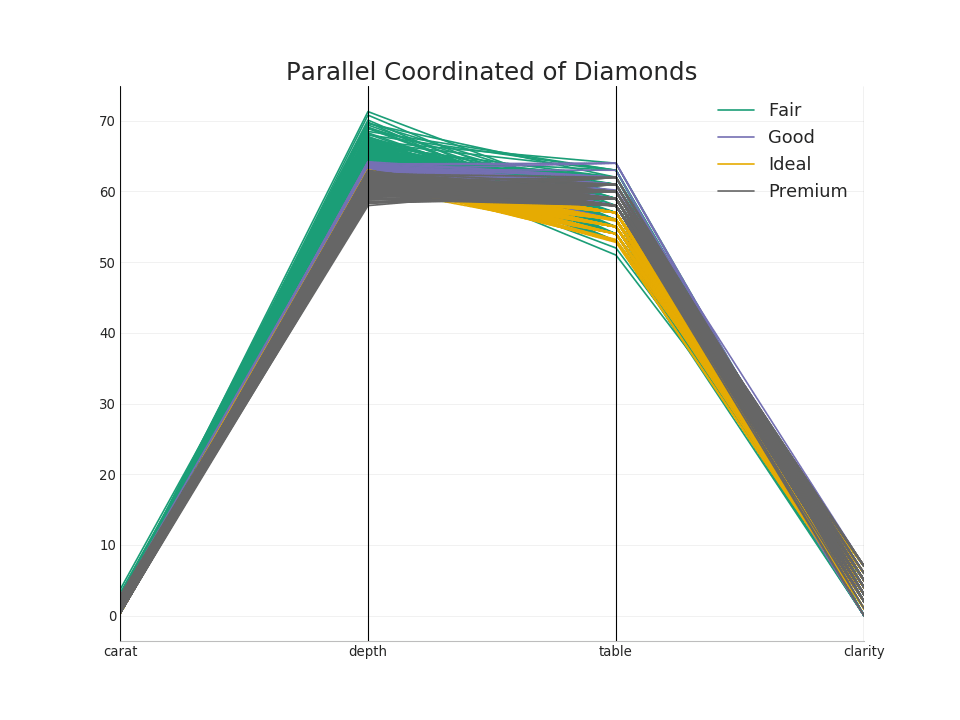
50. Coordonnées parallèles
Les coordonnées parallèles permettent de visualiser si une fonction aide à séparer efficacement les groupes. Si une ségrégation se produit, cette fonction sera probablement très utile pour prédire ce groupe.Afficher le code from pandas.plotting import parallel_coordinates
 Code bonus dans Jupiter
Code bonus dans JupiterOie, tu as promis des vibes!