De nos jours, les mots «intelligence artificielle» signifient beaucoup de systèmes différents - d'un réseau neuronal pour la reconnaissance d'image à un bot pour jouer à Quake. Wikipedia donne une merveilleuse définition de l'IA - c'est "la propriété des systèmes intelligents pour effectuer des fonctions créatives qui sont traditionnellement considérées comme la prérogative de l'homme." Autrement dit, cela ressort clairement de la définition - si une certaine fonction a été automatisée avec succès, elle cesse d'être considérée comme une intelligence artificielle.
Cependant, lorsque la tâche de «créer l'intelligence artificielle» a été définie pour la première fois, l'IA signifiait quelque chose de différent. Cet objectif s'appelle désormais Strong AI ou AI à usage général.
Énoncé du problème
Il existe maintenant deux formulations bien connues du problème. Le premier est Strong AI. La seconde est une IA à usage général (alias Artifical General Intelligence, en abrégé AGI).
Upd. Dans les commentaires, ils me disent que cette différence est plus probable au niveau de la langue. En russe, le mot «intelligence» ne signifie pas exactement ce que le mot «intelligence» en anglais
Une IA forte est une IA hypothétique qui pourrait faire tout ce qu'une personne pourrait faire. Il est généralement mentionné qu'il doit réussir le test de Turing dans le cadre initial (hmm, les gens le réussissent-ils?), Être conscient de lui-même en tant que personne distincte et être capable d'atteindre ses objectifs.
Autrement dit, c'est quelque chose comme une personne artificielle. À mon avis, l'utilité d'une telle IA est principalement la recherche, car les définitions d'une IA forte ne disent nulle part quels seront ses objectifs.
L'AGI ou l'IA polyvalente est une «machine à résultats». Elle reçoit un certain objectif fixé à l'entrée - et donne quelques actions de contrôle sur les moteurs / lasers / carte réseau / moniteurs. Et l'objectif est atteint. Dans le même temps, AGI ne possède initialement aucune connaissance de l'environnement, mais uniquement des capteurs, des actionneurs et du canal par lequel elle définit ses objectifs. Le système de gestion sera considéré comme une AGI s'il peut atteindre des objectifs dans n'importe quel environnement. Nous lui avons demandé de conduire une voiture et d'éviter les accidents - elle s'en chargera. Nous lui avons mis le contrôle d'un réacteur nucléaire pour qu'il y ait plus d'énergie, mais n'explose pas - elle peut le gérer. Nous donnerons une boîte aux lettres et demanderons de vendre des aspirateurs - nous nous en occuperons également. AGI est un résolveur de «problèmes inverses». Vérifier combien d'aspirateurs sont vendus est une question simple. Mais comprendre comment convaincre une personne d'acheter cet aspirateur est déjà une tâche pour l'intellect.
Dans cet article, je vais parler d'AGI. Pas de tests de Turing, pas de conscience de soi, pas de personnalités artificielles - IA exceptionnellement pragmatique et opérateurs non moins pragmatiques.
Situation actuelle
Il existe maintenant une classe de systèmes tels que l'apprentissage par renforcement ou l'apprentissage renforcé. C'est quelque chose comme AGI, mais sans polyvalence. Ils sont capables d'apprendre et, par conséquent, d'atteindre des objectifs dans une variété d'environnements. Mais ils sont encore très loin d'atteindre des objectifs dans n'importe quel environnement.
En général, comment sont organisés les systèmes d'apprentissage par renforcement et quels sont leurs problèmes?
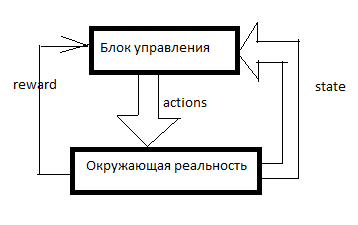
Tout RL est organisé comme ceci. Il existe un système de contrôle, certains signaux sur la réalité environnante y pénètrent à travers les capteurs (état) et à travers les organes directeurs (actions) il agit sur la réalité environnante. La récompense est un signal de renforcement. Dans les systèmes RL, le renforcement est formé de l'extérieur de l'unité de contrôle et indique dans quelle mesure l'IA parvient à atteindre l'objectif. Combien d'aspirateurs vendus à la dernière minute, par exemple.
Ensuite, une table est formée de quelque chose comme ça (je l'appellerai la table SAR):

L'axe du temps est dirigé vers le bas. Le tableau montre tout ce que l'IA a fait, tout ce qu'il a vu et tous les signaux de renforcement. Habituellement, pour que RL fasse quelque chose de significatif, il doit d'abord faire des mouvements aléatoires pendant un certain temps, ou regarder les mouvements de quelqu'un d'autre. En général, RL démarre lorsqu'il y a déjà au moins quelques lignes dans la table SAR.
Que se passe-t-il ensuite?
Sarsa
La forme la plus simple d'apprentissage par renforcement.
Nous prenons une sorte de modèle d'apprentissage automatique et, en utilisant une combinaison de S et A (état et action), nous prédisons le R total pour les prochains cycles d'horloge. Par exemple, nous verrons que (sur la base du tableau ci-dessus) si vous dites à une femme "soyez un homme, achetez un aspirateur!", Alors la récompense sera faible, et si vous dites la même chose à un homme, alors élevée.
Quels modèles spécifiques peuvent être utilisés - je décrirai plus tard, pour l'instant je dirai seulement qu'il ne s'agit pas uniquement de réseaux de neurones. Vous pouvez utiliser des arbres de décision ou même définir une fonction sous forme de tableau.
Et puis ce qui suit se produit. AI reçoit un autre message ou un lien vers un autre client. Toutes les données client sont entrées dans l'IA de l'extérieur - nous considérerons la base de clients et le compteur de messages comme faisant partie du système de capteurs. Autrement dit, il reste à affecter un A (action) et à attendre des renforts. L'IA prend toutes les actions possibles et à son tour prédit (en utilisant le même modèle d'apprentissage automatique) - que se passera-t-il si je fais cela? Et si c'est le cas? Et quel renforcement y aura-t-il? Et puis RL effectue l'action pour laquelle la récompense maximale est attendue.
J'ai introduit un système si simple et maladroit dans l'un de mes jeux. SARSA embauche des unités dans le jeu et s'adapte en cas de changement des règles du jeu.
De plus, dans tous les types de formation renforcée, il y a une remise de récompenses et un dilemme d'exploration / exploitation.
L'actualisation des récompenses est une telle approche lorsque RL essaie de maximiser non pas le montant de la récompense pour les N mouvements suivants, mais le montant pondéré selon le principe "100 roubles est maintenant meilleur que 110 en un an". Par exemple, si le facteur d'actualisation est de 0,9 et l'horizon de planification est de 3, alors nous formerons le modèle non pas sur le total R pour les 3 prochains cycles d'horloge, mais sur R1 * 0,9 + R2 * 0,81 + R3 * 0,729. Pourquoi est-ce nécessaire? Ensuite, cette IA, créant un profit quelque part là-bas à l'infini, nous n'en avons pas besoin. Nous avons besoin d'une IA qui génère un profit ici et maintenant.
Explorez / exploitez le dilemme. Si RL fait ce que son modèle considère comme optimal, il ne saura jamais s'il y avait de meilleures stratégies. L'exploit est une stratégie dans laquelle RL fait ce qui promet un maximum de récompenses. Explore est une stratégie dans laquelle RL fait quelque chose pour explorer l'environnement à la recherche de meilleures stratégies. Comment mettre en œuvre une intelligence efficace? Par exemple, vous pouvez effectuer une action aléatoire toutes les quelques mesures. Ou vous pouvez créer non pas un modèle prédictif, mais plusieurs avec des paramètres légèrement différents. Ils produiront des résultats différents. Plus la différence est grande, plus le degré d'incertitude de cette option est élevé. Vous pouvez effectuer l'action de sorte qu'elle ait la valeur maximale: M + k * std, où M est la prévision moyenne de tous les modèles, std est l'écart-type des prévisions et k est le coefficient de curiosité.
Quels sont les inconvénients?Disons que nous avons des options. Allez au but (qui est à 10 km de nous, et la route est bonne) en voiture ou à pied. Et puis, après ce choix, nous avons des options - bougez prudemment ou essayez de vous écraser dans chaque pilier.
La personne dira immédiatement qu'il est généralement préférable de conduire une voiture et de se comporter avec prudence.
Mais SARSA ... Il se penchera sur ce à quoi la décision d'aller en voiture a mené auparavant. Mais cela a conduit à cela. Au stade de la première série de statistiques, l'IA a conduit imprudemment et s'est écrasé quelque part dans la moitié des cas. Oui, il sait bien conduire. Mais quand il choisit d'aller en voiture, il ne sait pas ce qu'il choisira au prochain coup. Il a des statistiques - puis dans la moitié des cas, il a choisi l'option appropriée, et dans la moitié - suicidaire. Par conséquent, en moyenne, il vaut mieux marcher.
SARSA estime que l'agent suivra la même stratégie qui a été utilisée pour remplir la table. Et agit sur cette base. Mais que se passe-t-il si nous supposons le contraire - que l'agent suivra la meilleure stratégie dans les prochains mouvements?
Q-learning
Ce modèle calcule pour chaque état la récompense totale maximale pouvant en être obtenue. Et il l'écrit dans une colonne spéciale Q. Autrement dit, si à partir de l'état S, vous pouvez obtenir 2 points ou 1, selon le mouvement, alors Q (S) sera égal à 2 (avec une profondeur de prédiction de 1). Quelle récompense peut être obtenue de l'état S, nous apprenons du modèle prédictif Y (S, A). (État S, action A).
Ensuite, nous créons un modèle prédictif Q (S, A) - c'est-à-dire à quel état Q ira si nous effectuons l'action A à partir de S. Et créons la colonne suivante dans le tableau - Q2. Autrement dit, le Q maximum qui peut être obtenu à partir de l'état S (nous trions tous les A possibles).
Ensuite, nous créons un modèle de régression Q3 (S, A) - c'est-à-dire à l'état avec lequel Q2 nous irons si nous effectuons l'action A à partir de S.
Et ainsi de suite. Ainsi, nous pouvons atteindre une profondeur de prévision illimitée.
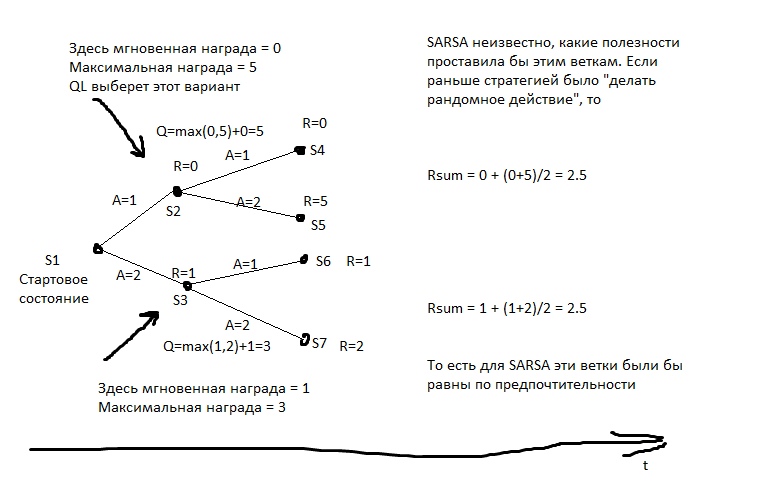
Dans l'image, R est le renfort.
Et puis à chaque mouvement, nous sélectionnons l'action qui promet le plus grand Qn. Si nous appliquions cet algorithme aux échecs, nous obtiendrions quelque chose comme un minimax idéal. Quelque chose de presque équivalent à des erreurs de calcul vers de grandes profondeurs.
Un exemple courant de comportement d'apprentissage q. Le chasseur a une lance, et il l'accompagne à l'ours, de sa propre initiative. Il sait que la grande majorité de ses futurs mouvements ont une très grande récompense négative (il y a beaucoup plus de façons de perdre que de gagner), il sait qu'il y a des mouvements avec une récompense positive. Le chasseur pense qu'à l'avenir il fera les meilleurs mouvements (et on ne sait pas lesquels comme dans SARSA), et s'il fait les meilleurs mouvements, il vaincra l'ours. Autrement dit, pour aller à l'ours, il lui suffit de pouvoir fabriquer tous les éléments nécessaires à la chasse, mais il n'est pas nécessaire d'avoir une expérience de réussite immédiate.
Si le chasseur agissait dans le style SARSA, il supposerait que ses actions à l'avenir seraient à peu près les mêmes qu'avant (malgré le fait qu'il a maintenant un bagage de connaissances différent), et il n'irait à l'ours que s'il était déjà allé à et il a gagné, par exemple, dans> 50% des cas (enfin, ou si d'autres chasseurs ont gagné dans plus de la moitié des cas, s'il apprend de leur expérience).
Quels sont les inconvénients?- Le modèle ne fait pas face à la réalité changeante. Si toute notre vie nous avons été récompensés pour avoir appuyé sur le bouton rouge, et maintenant ils nous punissent, et aucun changement visible ne s'est produit ... QL maîtrisera ce modèle pendant très longtemps.
- Qn peut être une fonction très complexe. Par exemple, pour le calculer, vous devez faire défiler un cycle de N itérations - et cela ne fonctionnera pas plus rapidement. Un modèle prédictif a généralement une complexité limitée - même un grand réseau de neurones a une limite de complexité, et presque aucun modèle d'apprentissage automatique ne peut faire tourner les cycles.
- La réalité a généralement des variables cachées. Par exemple, quelle heure est-il maintenant? Il est facile de savoir si nous regardons la montre, mais dès que nous regardons ailleurs, il s'agit déjà d'une variable cachée. Pour prendre en compte ces valeurs non observables, il est nécessaire que le modèle tienne compte non seulement de l'état actuel, mais aussi d'une sorte d'histoire. Dans QL, vous pouvez le faire - par exemple, pour alimenter non seulement le S actuel, mais aussi plusieurs précédents dans le neurone ou ce que nous avons là. Cela se fait dans RL, qui joue aux jeux Atari. De plus, vous pouvez utiliser un réseau de neurones récurrent pour la prévision - laissez-le s'exécuter séquentiellement sur plusieurs trames d'historique et calculez Qn.
Systèmes basés sur des modèles
Mais que se passe-t-il si nous prédisons non seulement R ou Q, mais généralement toutes les données sensorielles? Nous aurons constamment une copie de poche de la réalité et nous pourrons vérifier nos plans à ce sujet. Dans ce cas, nous sommes beaucoup moins préoccupés par la difficulté de calculer la fonction Q. Oui, il faut beaucoup d'horloges pour calculer - enfin, de toute façon, pour chaque plan, nous exécuterons à plusieurs reprises le modèle de prévision. La planification de 10 va de l'avant? Nous lançons le modèle 10 fois, et chaque fois que nous alimentons ses sorties à son entrée.
Quels sont les inconvénients?- Intensité des ressources. Supposons que nous devons faire un choix de deux alternatives à chaque mesure. Ensuite, pour 10 cycles d'horloge, nous aurons 2 ^ 10 = 1024 plans possibles. Chaque plan comprend 10 lancements de modèles. Si nous contrôlons un avion avec des dizaines d'organes directeurs? Et simulons-nous la réalité avec une période de 0,1 seconde? Voulez-vous avoir un horizon de planification d'au moins quelques minutes? Nous devrons exécuter le modèle plusieurs fois, il y a beaucoup de cycles d'horloge du processeur pour une solution. Même si vous optimisez d'une manière ou d'une autre l'énumération des plans, il y a des ordres de grandeur plus de calculs qu'en QL.
- Le problème du chaos. Certains systèmes sont conçus de sorte que même une petite imprécision de la simulation d'entrée entraîne une énorme erreur de sortie. Pour contrer cela, vous pouvez exécuter plusieurs simulations de la réalité - un peu différentes. Ils produiront des résultats très différents, et à partir de cela, il sera possible de comprendre que nous sommes dans la zone d'une telle instabilité.
Méthode d'énumération de la stratégie
Si nous avons accès à l'environnement de test pour l'IA, si nous l'exécutons non pas en réalité, mais dans une simulation, alors nous pouvons écrire sous une forme ou une autre la stratégie du comportement de notre agent. Et puis choisissez - avec évolution ou autre chose - une telle stratégie qui mène à un profit maximum.
«Choisir une stratégie» signifie que nous devons d'abord apprendre à écrire une stratégie de telle manière qu'elle puisse être poussée dans l'algorithme d'évolution. Autrement dit, nous pouvons écrire la stratégie avec le code du programme, mais à certains endroits, laissez les coefficients et laissez l'évolution les ramasser. Ou nous pouvons écrire une stratégie avec un réseau de neurones - et laisser l'évolution prendre le poids de ses connexions.
Autrement dit, il n'y a aucune prévision ici. Pas de table SAR. Nous sélectionnons simplement une stratégie, et elle donne immédiatement des actions.
C'est une méthode puissante et efficace, si vous voulez essayer RL et ne savez pas par où commencer, je le recommande. C'est une façon très bon marché de «voir un miracle».
Quels sont les inconvénients?- La capacité d'exécuter plusieurs fois les mêmes expériences est requise. Autrement dit, nous devrions être en mesure de rembobiner la réalité au point de départ - des dizaines de milliers de fois. Pour essayer une nouvelle stratégie.
La vie offre rarement de telles opportunités. Habituellement, si nous avons un modèle du processus qui nous intéresse, nous ne pouvons pas créer une stratégie astucieuse - nous pouvons simplement élaborer un plan, comme dans une approche basée sur un modèle, même avec une force brute brutale. - Intolérance à l'expérience. Avons-nous une table SAR pour des années d'expérience? On peut l'oublier, ça ne rentre pas dans le concept.
Une méthode d'énumération des stratégies, mais «en direct»
La même énumération des stratégies, mais sur la réalité vivante. Nous essayons 10 mesures d'une stratégie. Ensuite, 10 mesures un autre. Puis 10 mesures du troisième. Ensuite, nous sélectionnons celui où il y avait le plus de renfort.
Les meilleurs résultats pour la marche des humanoïdes ont été obtenus par cette méthode.

Pour moi, cela semble quelque peu inattendu - il semblerait que l'approche basée sur le modèle QL + soit mathématiquement idéale. Mais rien de tel. Les avantages de l'approche sont à peu près les mêmes que les précédents - mais ils sont moins prononcés, car les stratégies ne sont pas testées très longtemps (enfin, nous n'avons pas des millénaires d'évolution), ce qui signifie que les résultats sont instables. De plus, le nombre de tests ne peut pas non plus être porté à l'infini - ce qui signifie que la stratégie devra être recherchée dans un espace d'options peu compliqué. Non seulement elle aura des «stylos» qui peuvent être «tordus». Eh bien, l'intolérance vécue n'a pas été annulée. Et, par rapport à QL ou Model-Based, ces modèles utilisent l'expérience de manière inefficace. Ils ont besoin de beaucoup plus d'interactions avec la réalité que les approches qui utilisent l'apprentissage automatique.
Comme vous pouvez le voir, toute tentative de création d'un AGI en théorie devrait contenir soit un apprentissage automatique pour prévoir les récompenses, soit une forme de notation paramétrique d'une stratégie - afin que vous puissiez reprendre cette stratégie avec quelque chose comme l'évolution.
Il s'agit d'une forte attaque contre les personnes qui proposent de créer une IA basée sur des bases de données, une logique et des graphiques conceptuels. Si vous, les partisans de l'approche symbolique, lisez ceci - bienvenue dans les commentaires, je serai heureux de savoir ce que AGI peut faire sans la mécanique décrite ci-dessus.
Modèles d'apprentissage automatique pour RL
Presque tous les modèles ML peuvent être utilisés pour un apprentissage renforcé. Les réseaux de neurones sont bien sûr bons. Mais il y a, par exemple, KNN. Pour chaque paire S et A, nous recherchons les plus similaires, mais dans le passé. Et nous cherchons ce que sera R. Stupide après ça? Oui, mais ça marche. Il y a des arbres décisifs - ici, il vaut mieux se promener sur les mots-clés "renforcement du gradient" et "forêt décisive". Les arbres sont-ils pauvres pour capturer des dépendances complexes? Utilisez l'ingénierie des fonctionnalités. Vous voulez que votre IA soit plus proche du général? Utilisez FE automatique! Parcourez un tas de formules différentes, soumettez-les en tant que fonctionnalités pour votre boost, jetez les formules qui augmentent l'erreur et laissez les formules qui améliorent la précision. Soumettez ensuite les meilleures formules comme arguments pour les nouvelles formules, et ainsi de suite, évoluez.
Vous pouvez utiliser des régressions symboliques pour la prévision - c'est-à-dire simplement trier des formules pour essayer d'obtenir quelque chose qui se rapproche de Q ou R. Il est possible d'essayer de trier des algorithmes - puis vous obtenez une chose appelée induction de Solomonov, qui est théoriquement optimale, mais presque très difficile à former approximations des fonctions.
Mais les réseaux de neurones sont généralement un compromis entre l'expressivité et la complexité d'apprentissage. La régression algorithmique détecte idéalement toute dépendance - pendant des centaines d'années. L'arbre de décision fonctionnera très rapidement - mais il ne pourra pas extrapoler y = a + b. Un réseau de neurones est quelque chose entre les deux.
Perspectives de développement
Quelles sont les façons de faire exactement AGI maintenant? Du moins théoriquement.
Évolution
Nous pouvons créer de nombreux environnements de test différents et démarrer l'évolution de certains réseaux de neurones.
Les configurations qui marquent plus de points au total pour tous les essais se multiplieront.Le réseau neuronal doit avoir de la mémoire et il serait souhaitable d'avoir au moins une partie de la mémoire sous forme de bande, comme une machine de Turing ou similaire sur un disque dur.Le problème est qu'avec l'aide de l'évolution, vous pouvez bien sûr développer quelque chose comme RL. Mais à quoi devrait ressembler le langage dans lequel RL a l'air compact - pour que l'évolution le trouve - et en même temps, l'évolution ne trouve pas de solutions comme "mais je vais créer un neurone pour cent cinquante couches afin que vous deveniez tous fous pendant que je l'enseigne!" . L'évolution est comme une foule d'utilisateurs analphabètes - elle trouvera tous les défauts dans le code et abandonnera tout le système.Aixi
Vous pouvez créer un système basé sur un modèle basé sur un ensemble de nombreuses régressions algorithmiques. L'algorithme est garanti comme étant Turing complet - ce qui signifie qu'il n'y aura aucun motif qui ne pourra pas être détecté. L'algorithme est écrit en code - ce qui signifie que sa complexité peut être facilement calculée. Cela signifie qu'il est possible d'affiner mathématiquement correctement vos hypothèses sur la complexité du dispositif mondial. Avec les réseaux de neurones, par exemple, cette astuce ne fonctionnera pas - là, la pénalité pour la complexité est très indirecte et heuristique.Il ne reste plus qu'à apprendre à former rapidement des régressions algorithmiques. Jusqu'à présent, le meilleur pour cette évolution est l'évolution et elle est impardonnablement longue.Seed AI
Ce serait cool de créer une IA qui s'améliorera. Améliorez votre capacité à résoudre des problèmes. Cela peut sembler une idée étrange, mais ce problème a déjà été résolu pour les systèmes d'optimisation statique, tels que l'évolution . Si vous parvenez à le réaliser ... Tout sur l'exposant est-il au courant? Nous aurons une IA très puissante en très peu de temps.Comment faire
Vous pouvez essayer d'arranger cela dans RL certaines des actions affectent les paramètres de RL lui-même.Ou donnez au système RL un outil pour créer de nouveaux processeurs de pré et post-données pour vous-même. Laissez RL être stupide, mais il pourra créer des calculatrices, des cahiers et des ordinateurs pour lui-même.Une autre option consiste à créer une sorte d'IA en utilisant l'évolution, dans laquelle une partie des actions affectera son appareil au niveau du code.Mais pour le moment, je n'ai pas vu d'options réalisables pour Seed AI - bien que très limitées. Les développeurs se cachent-ils? Ou ces options sont-elles si faibles qu'elles ne méritaient pas l'attention générale et m'ont dépassé?Cependant, Google et DeepMind fonctionnent désormais principalement avec des architectures de réseaux de neurones. Apparemment, ils ne veulent pas s'impliquer dans l'énumération combinatoire et essayer de rendre leurs idées adaptées à la méthode de propagation de l'erreur.J'espère que cet article a été utile =) Les commentaires sont les bienvenus, en particulier les commentaires comme «Je sais comment améliorer AGI»!