Les réseaux de neurones capturent le monde. Ils comptent les visiteurs, contrôlent la qualité, tiennent des statistiques et évaluent la sécurité. Un tas de startups, à usage industriel.
Grands cadres. Qu'est-ce que PyTorch, quel est le deuxième TensorFlow. Tout devient de plus en plus pratique et pratique, de plus en plus simple ...
Mais il y a un côté sombre. Ils essaient de garder le silence sur elle. Il n'y a rien de joyeux là-dedans, seulement de l'obscurité et du désespoir. Chaque fois que vous voyez un article positif, vous soupirez tristement, car vous comprenez que seule une personne n'a pas compris quelque chose. Ou je l'ai caché.
Parlons de la production sur les appareils embarqués.

Quel est le problème.
Il semblerait. Examinez les performances de l'appareil, assurez-vous qu'il est suffisant, exécutez-le et réalisez un profit.
Mais, comme toujours, il y a quelques nuances. Mettons-les dans des étagères:
- Production. Si votre appareil n'est pas fabriqué en copies uniques, vous devez vous assurer que le système ne se bloque pas, que les appareils ne surchaufferont pas, qu'en cas de panne de courant, tout démarrera automatiquement. Et c'est sur une grande fête. Cela ne donne que deux options - soit l'appareil doit être entièrement conçu en tenant compte de tous les problèmes possibles. Ou vous devez surmonter les problèmes de l'appareil source. Eh bien, par exemple, ce sont ( 1 , 2 ). Ce qui est bien sûr de l'étain. Pour résoudre les problèmes de l'appareil de quelqu'un d'autre en grandes quantités, il est nécessaire de dépenser une quantité d'énergie irréaliste.
- De vrais repères. Beaucoup d'escroqueries et de trucs. NVIDIA dans la plupart des exemples surestime les performances de 30 à 40%. Mais non seulement elle s'amuse. Ci-dessous, je donne de nombreux exemples où la productivité peut être 4 à 5 fois inférieure à celle que vous souhaitez. Vous ne pouvez pas vous faire "tout fonctionnait bien sur l'ordinateur, ce sera proportionnellement pire ici."
- Prise en charge très limitée de l'architecture de réseau neuronal. Il existe de nombreuses plates-formes matérielles intégrées qui limitent considérablement les réseaux qui peuvent y être exécutés (Coral, gyrfalcone, snapdragon). Le portage sur de telles plateformes sera pénible.
- Support. Quelque chose ne fonctionne pas pour vous, mais le problème est du côté de l'appareil? .. C'est le destin, cela ne fonctionnera pas. Pour RPi uniquement, la communauté ferme la plupart des bogues. Et, en partie, pour Jetson.
- Prix Il semble à beaucoup que l'embarqué est bon marché. Mais, en réalité, avec la croissance des performances des appareils, le prix augmentera de façon presque exponentielle. RPi-4 est 5 fois moins cher que Jetson Nano / Google Coral et 2-3 fois plus faible. Jetson Nano est 5 fois moins cher que Jetson TX2 / Intel NUC, et 2-3 fois plus faible qu'eux.
- Lorgus. Rappelez-vous cette conception de Zhelyazny?
Il semble que je l'ai défini comme image de titre ... " le Logrus est un labyrinthe tridimensionnel mouvant qui représente les forces du Chaos dans le multivers. " Tout cela est une abondance de bugs et de trous, tous ces différents morceaux de fer, tous les cadres changeants ... C'est normal lorsque l'image du marché change complètement en 2-3 mois. Au cours de cette année, il a changé 3-4 fois. Vous ne pouvez pas entrer deux fois dans la même rivière. Donc, toutes les pensées actuelles sont vraies pour l'été 2019.
Qu'est-ce que
Prenons-le dans l'ordre, il n'a pas un goût sucré ... Qu'est-ce qui existe maintenant et convient aux neurones? Il n'y a pas tant d'options, malgré leur variabilité. Quelques mots généraux pour limiter la recherche:
- Je n'analyserai pas les neurones / inférences sur les téléphones. C'est en soi un sujet énorme. Mais comme les téléphones sont des plates-formes intégrées avec un ajustement par interférence, je ne pense pas que ce soit mauvais.
- Je vais parler de Jetson TX1 | TX2. Dans les conditions actuelles, ce ne sont pas les plateformes les plus optimales pour le prix, mais il y a des situations où elles sont toujours pratiques à utiliser.
- Je ne garantis pas que la liste inclura toutes les plateformes qui existent aujourd'hui. Peut-être que j'ai oublié quelque chose, peut-être que je ne sais pas quelque chose. Si vous connaissez des plateformes plus intéressantes - écrivez!
Alors. Les principales choses qui sont clairement intégrées. Dans l'article, nous les comparerons précisément:

- Plateforme Jetson . Il existe plusieurs appareils pour cela:
- Jetson Nano - un jouet pas cher et assez moderne (printemps 2019)
- Jetson Tx1 | Tx2 - assez cher mais bon sur les plates-formes de performance et de polyvalence
- Raspberry Pi . En réalité, seul RPi4 a les performances pour les réseaux de neurones. Mais certaines tâches distinctes peuvent être effectuées sur la troisième génération. J'ai même commencé par créer des grilles très simples.
- Google Coral Platform. En fait, pour intégrer des appareils, il n'y a qu'une seule puce et deux appareils - la carte de développement et l'accélérateur USB
- Plateforme Intel Movidius . Si vous n'êtes pas une grande entreprise, alors seuls les bâtons Movidius 1 | Movidius 2 seront à votre disposition.
- Plateforme Gyrfalcone . Le miracle de la technologie chinoise. Il y a déjà deux générations - 2801, 2803
Divers Nous en parlerons après les principales comparaisons:
- Processeurs Intel. Tout d'abord, les assemblages NUC.
- GPU Nvidia Mobile. Les solutions prêtes à l'emploi peuvent être considérées comme non intégrées. Et si vous collectez l'incorporation, cela se passera décemment sur les finances.
- Téléphones portables. Android se caractérise par le fait que pour utiliser des performances maximales, il est nécessaire d'utiliser exactement le matériel d'un fabricant particulier. Ou utilisez quelque chose d'universel, comme la lumière tensorflow. Pour Apple, la même chose.
- Jetson AGX Xavier est une version chère de Jetson avec plus de performances.
- GAP8 - processeurs basse consommation pour des appareils super bon marché.
- Chapeau AI Mysterious Grove
Jetson
Nous travaillons avec Jetson depuis très longtemps. En 2014,
Vasyutka a inventé les mathématiques pour le
Swift alors précisément sur Jetson. En 2015, lors d'une réunion avec Artec 3D, nous avons parlé de ce qu'est une plate-forme cool, après quoi ils ont suggéré que nous construisions un prototype basé sur elle. Après quelques mois, le prototype était prêt. Juste quelques années de travail de toute l'entreprise, quelques années de malédictions sur la plate-forme et le paradis ... Et
Artec Leo est né - le scanner le plus cool de sa catégorie. Même Nvidia lors de la présentation de TX2 l'a
montré comme l'un des projets les plus intéressants créés sur la plateforme.
Depuis lors, TX1 / TX2 / Nano nous avons utilisé quelque part dans 5-6 projets.
Et, probablement, nous connaissons tous les problèmes qui étaient avec la plate-forme. Prenons-le dans l'ordre.
Jetson tk1
Je ne parlerai pas spécialement de lui. La plate-forme était très efficace en termes de puissance de calcul à son époque. Mais elle n'était pas à l'épicerie. NVIDIA a vendu les puces
TegraTK1 qui
soutenaient Jetson. Mais ces puces étaient impossibles à utiliser pour les petits et moyens fabricants. En réalité, seuls Google / HTC / Xiaomi / Acer / Google pourraient faire quelque chose sur eux en plus de Nvidia. Tous les autres intégrés dans la prod, soit des cartes de débogage, soit pillé d'autres appareils.
Jetson TX1 | TX2
Nvidia a tiré les bonnes conclusions, et la génération suivante a été faite de manière impressionnante. TX1 | TX2, ce ne sont plus des puces, mais une puce sur la carte.


Ils sont plus chers, mais ont un niveau d'épicerie complet. Une petite entreprise peut les intégrer dans son produit, ce produit est prévisible et stable. J'ai personnellement vu comment 3-4 produits ont été mis en production - et tout s'est bien passé.
Je vais parler de TX2, car à partir de la ligne actuelle, c'est la carte principale.
Mais, bien sûr, tous ne remercient pas Dieu. Quel est le problème:
- Jetson TX2 est une plate-forme coûteuse. Dans la plupart des produits, vous utiliserez le module principal (si je comprends bien, compte tenu de la taille du lot, le prix sera compris entre 200-250 et 350-400 cu chacun). Il a besoin d'un CarrierBoard. Je ne connais pas le marché actuel, mais auparavant c'était environ 100-300 cu selon la configuration. Eh bien, et en plus de votre kit carrosserie.
- Jetson TX2 n'est pas la plateforme la plus rapide. Ci-dessous, nous discuterons des vitesses comparatives, là, je montrerai pourquoi ce n'est pas la meilleure option.
- Il est nécessaire d'éliminer beaucoup de chaleur. Cela est probablement vrai pour presque toutes les plateformes dont nous parlerons. Le boîtier doit résoudre le problème de dissipation thermique. Les fans
- C'est une mauvaise plateforme pour les petits partis. Beaucoup de centaines d'appareils - env. Commander des cartes mères, développer des designs et des emballages est la norme. Beaucoup de milliers d'appareils? Concevez votre carte mère - et chic. Si vous avez besoin de 5-10 - mauvais. Vous devrez probablement prendre DevBoard. Ils sont gros, ils sont un peu dégoûtants à flasher. Ce n'est pas une plate-forme compatible RPi.
- Support technique médiocre de Nvidia. J'ai entendu beaucoup de jurons que les réponses sont répondues que ce sont des informations secrètes ou des réponses mensuelles.
- Mauvaise infrastructure en Russie. Il est difficile de commander, cela prend beaucoup de temps. Mais en même temps, les concessionnaires fonctionnent bien. Je suis récemment tombé sur un Jetson nano qui a grillé le jour du lancement - changé sans question. Sam ramassé par courrier / a apporté un nouveau. WAH! De plus, il a lui-même constaté que le bureau de Moscou donne de bons conseils. Mais dès que leur niveau de connaissance ne permet pas de répondre à la question et nécessite une demande auprès du bureau international - ils devront attendre longtemps pour obtenir des réponses.
Ce qui est génial:
- Beaucoup d'informations, une très grande communauté.
- Autour de Nvidia, de nombreuses petites entreprises fabriquent des accessoires. Ils sont ouverts aux négociations, vous pouvez régler leur décision. Et CarierBoard, et le firmware, et les systèmes de refroidissement.
- Prise en charge de tous les frameworks normaux (TensorFlow | PyTorch) et prise en charge complète de tous les réseaux. La seule conversion que vous pourriez avoir à faire est de transférer le code vers TensorRT. Cela permettra d'économiser de la mémoire, voire d'accélérer. Comparé à ce qui sera sur d'autres plateformes, c'est ridicule.
- Je ne sais pas comment élever des planches. Mais de ceux qui ont fait cela pour Nvidia, j'ai entendu que TX2 est une bonne option. Il existe des manuels qui correspondent à la réalité.
- Bonne consommation d'énergie. Mais de tout cela, exactement «intégré» sera avec nous - le pire :)
- Pied à coulisse en Russie (expliqué ci-dessus pourquoi)
- Contrairement à movidius | RPi | Corail | Gyrfalcon est un vrai GPU. Vous pouvez y conduire non seulement des grilles, mais aussi des algorithmes normaux
En conséquence, c'est une bonne plate-forme pour vous si vous avez des appareils à pièce, mais pour une raison quelconque, vous ne pouvez pas fournir un ordinateur à part entière. Quelque chose d'énorme? Biométrie - probablement pas. La reconnaissance des nombres est à la limite, selon le flux. Appareils portables avec un prix de plus de 5 000 dollars - possible. Voitures - non, il est plus facile de mettre une plate-forme plus puissante un peu plus cher.
Il me semble qu'avec la sortie d'une nouvelle génération d'appareils bon marché, TX2 mourra avec le temps.
Les cartes mères pour Jetson TX1 | TX2 | TX2i et d'autres ressemblent à ceci:

Et
ici ou
ici, il y a plus de variations.
Jetson nano

Jetson Nano est une chose très intéressante. Pour Nvidia, il s'agit d'un nouveau facteur de forme qui, en termes de révolution, devrait être comparé au TK1. Mais les concurrents s'épuisent déjà. Il y a d'autres appareils dont nous allons parler. Il est 2 fois plus faible que TX2, mais 4 fois moins cher. Plus précisément ... Les mathématiques sont compliquées. Jetson Nano sur la carte de démonstration coûte 100 dollars (en Europe). Mais si vous n'achetez qu'une puce, ce sera plus cher. Et vous devrez l'élever (il n'y a pas encore de carte mère pour lui). Et Dieu ne plaise que ce sera 2 fois moins cher sur une grande fête que TX2.
En fait, Jetson Nano, sur sa carte de base, est un tel produit publicitaire pour les instituts / revendeurs / amateurs, ce qui devrait stimuler l'intérêt et l'application commerciale. Par avantages et inconvénients (intersecte partiellement avec TX2):
- La conception est faible et non déboguée:
- Il surchauffe, avec une charge constante se bloque périodiquement / vole. Une entreprise familière essaie de résoudre tous les problèmes depuis 3 mois - cela ne fonctionne pas.
- J'en ai un grillé lorsqu'il est alimenté par USB. J'ai entendu dire qu'un ami avait une sortie USB grillée et que la fiche fonctionnait. Très probablement quelques problèmes avec l'alimentation USB.
- Si vous emballez la carte d'origine, alors il n'y aura pas assez de radiateur de NVIDIA, par exemple, il surchauffera.
- La vitesse n'est en quelque sorte pas suffisante. Presque 2 fois moins que TX2 (en réalité, il peut être 1,5, mais cela dépend de la tâche).
- Beaucoup de 5 à 10 appareils sont généralement très bons. 50-200 - c'est difficile, vous devrez compenser tous les bugs du fabricant, le suspendre à vos chiens, si vous avez besoin d'ajouter quelque chose comme POE, ça fera mal. Grands partis. Aujourd'hui, je n'ai pas entendu parler de projets réussis. Mais il me semble que des difficultés peuvent surgir comme avec TK1. Pour être honnête, j'espère que l'année prochaine, Jetson Nano 2 sortira, où ces maladies infantiles seront corrigées.
- Le support est mauvais, identique à TX2
- Mauvaise infrastructure
Bon:
- Un budget suffisant par rapport aux concurrents. Surtout pour les petites fêtes. Prix avantageux / performance
- Contrairement à movidius | RPi | Corail | Gyrfalcon est un vrai GPU. Vous pouvez y conduire non seulement des grilles, mais aussi des algorithmes normaux
- Il suffit de démarrer n'importe quel réseau (identique à tx2)
- Consommation électrique (identique à tx2)
- Pied à coulisse en Russie (identique au tx2)
Nano lui-même est sorti au début du printemps, quelque part en avril / mai, je l'ai poussé activement. Nous avons déjà réussi à faire deux projets dessus. En général, les problèmes identifiés ci-dessus. En tant que produit de loisir / produit pour les petits lots - très cool. Mais il n'est pas encore clair s'il est possible de faire glisser la production et comment le faire.
Parlez de la vitesse de Jetson.
Nous comparerons avec d'autres appareils beaucoup plus tard. En attendant, il suffit de parler de Jetson et de la vitesse. Pourquoi Nvidia nous ment. Comment optimiser vos projets.
Ci-dessous, tout est écrit sur TensorRT-5.1. TensorRT-6.0.1 a été publié le 17 septembre 2019, toutes les déclarations doivent y être revérifiées.
Supposons que nous croyons Nvidia. Ouvrons leur
site Web et voyons le temps d'inférence de SSD-mobilenet-v2 à 300 * 300:
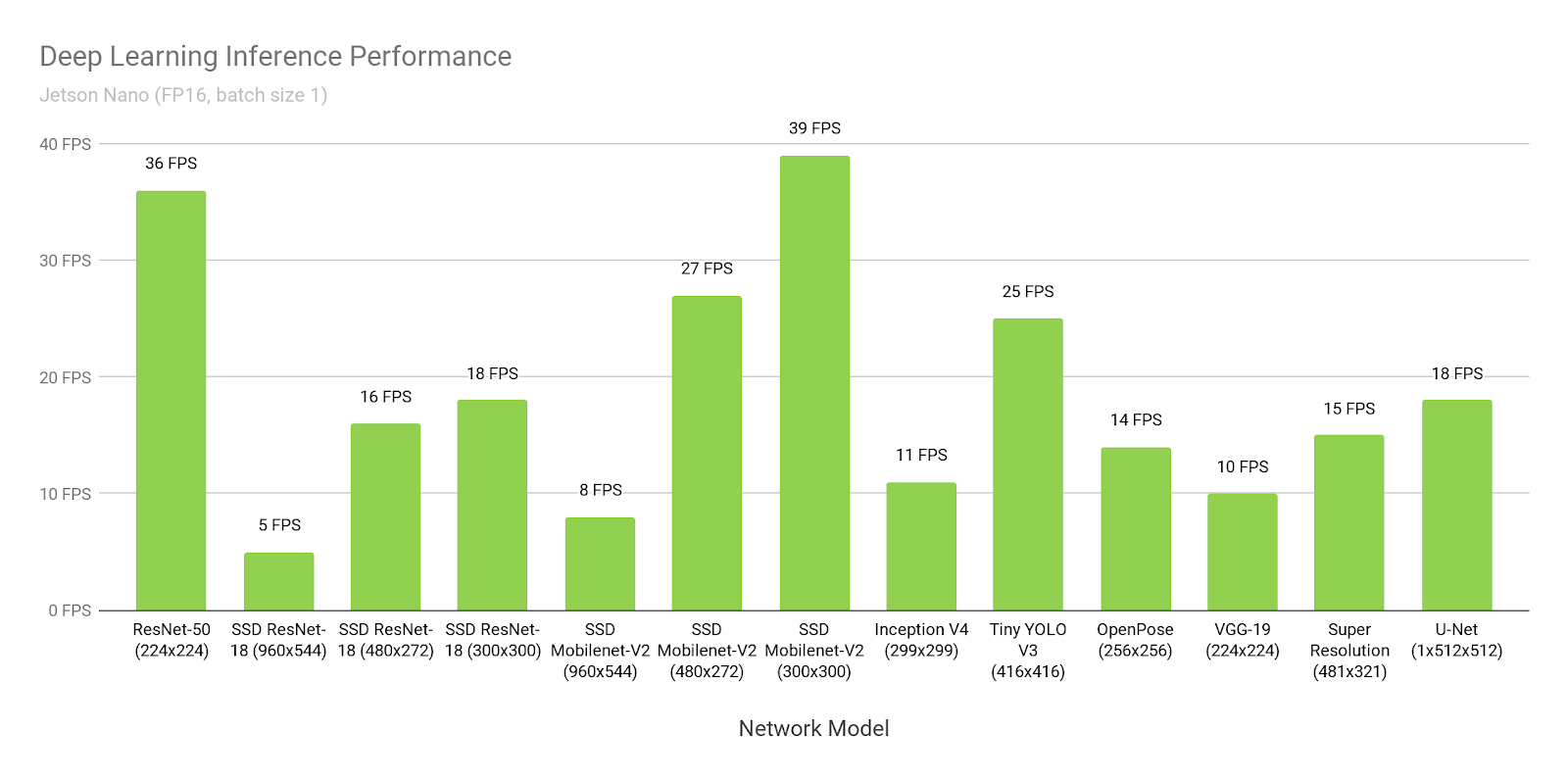
Wow, 39 images par seconde (25 ms). Oui, et le code source est
présenté !
Hmm ... Mais pourquoi est-il écrit
ici à propos de 46 ms?
Attendez ... Et ici,
ils écrivent que 309 ms est natif, et 72ms est porté ...
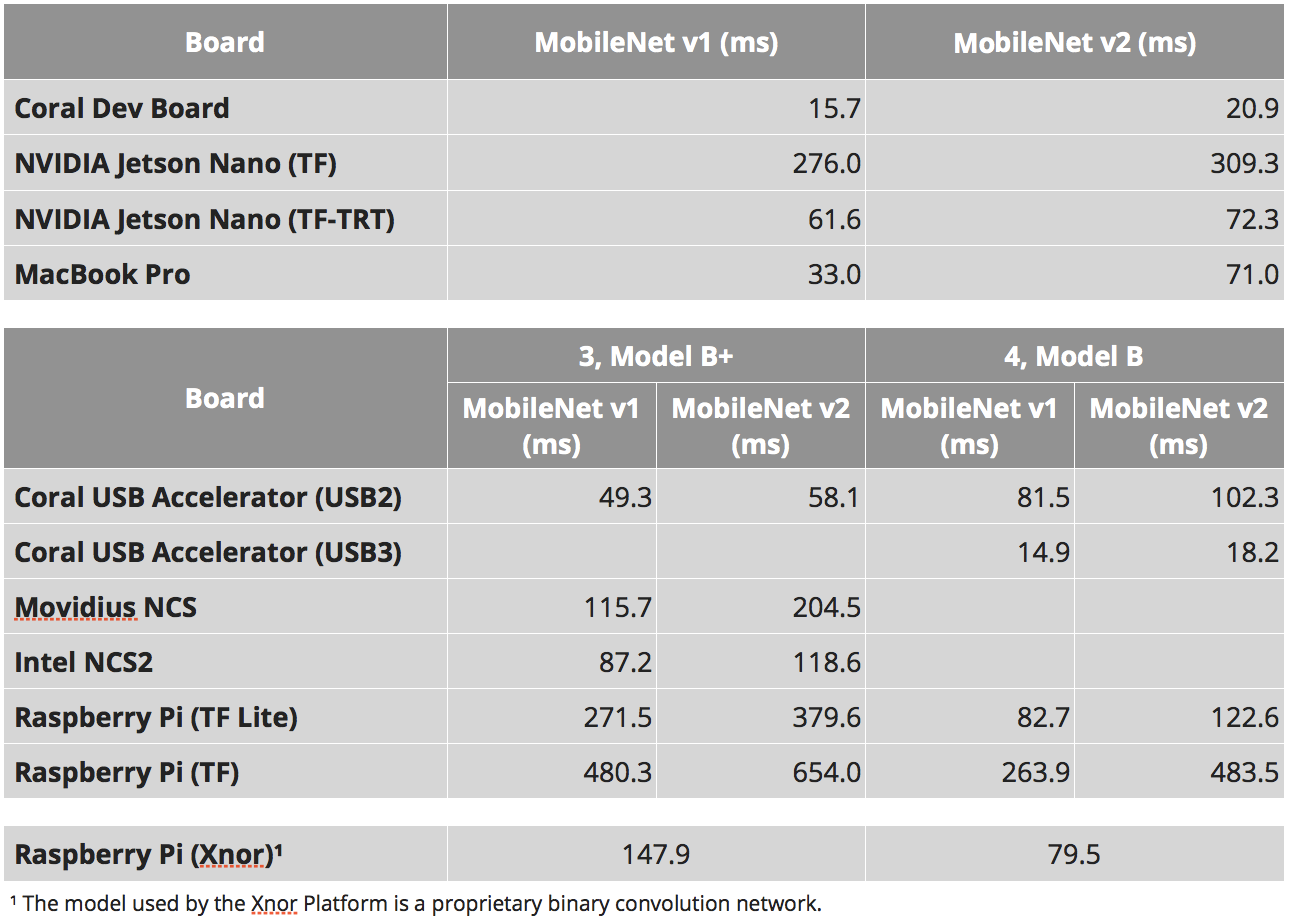
Où est la vérité?
La vérité est que tout le monde pense très différemment:
- Le SSD se compose de deux parties. Une partie est le neurone. La deuxième partie est le post-traitement de ce que le neurone a produit (suppression non maximale) + le pré-traitement de ce qui est chargé en entrée.
- Comme je l'ai dit plus tôt, sous Jetson, tout doit être converti en TensorRT. Il s'agit d'un tel framework natif de NVIDIA. Sans cela, tout sera mauvais. Seulement, il y a un problème. Tout n'y est pas porté, surtout depuis TensorFlow. À l'échelle mondiale, il existe deux approches:
- Google, réalisant que c'est un problème, a publié pour TensorFlow une chose appelée "tf-trt". En fait, c'est un add-on sur tf, qui vous permet de convertir n'importe quelle grille en tensorrt. Les parties qui ne sont pas prises en charge sont déduites sur le CPU, le reste sur le GPU.
- Réécrire tous les calques / trouver leurs analogues
Dans les exemples ci-dessus:
- Dans ce lien, le temps de 300 ms est le flux tensoriel habituel sans optimisation.
- Là, 72ms est la version tf-trt. Là, tous les nms se font essentiellement sur le processus.
- Il s'agit d'une version fan, où une personne a transféré tous les nms et l'a écrite sur gpu lui-même.
- Et ceci ... Ce NVIDIA a décidé de mesurer toutes les performances sans post-traitement, sans le mentionner explicitement n'importe où.
Vous devez comprendre par vous-même que s'il s'agissait de votre neurone, que personne n'aurait converti avant vous, alors sans problème, vous seriez en mesure de le lancer à une vitesse de 72 ms. Et à une vitesse de 46 ms, assis sur les manuels et sorsa jour-semaine.
Comparé à de nombreuses autres options, c'est très bien. Mais n'oubliez pas que quoi que vous fassiez - ne croyez jamais aux références de NVIDIA!
FramboisePI 4
Production? .. Et j'entends comment des dizaines d'ingénieurs se mettent à rire à la mention des mots «RPI» et «production» tout près. Mais, je dois dire - RPI est toujours plus stable que Jetson Nano et Google Coral. Mais, bien sûr, TX2 perd et, apparemment, le gyrfalcone.

(L'image vient
d'ici . Il me semble que la fixation de ventilateurs au RPi4 est un amusement folklorique distinct.)
De toute la liste, c'est le seul appareil que je n'ai pas tenu entre les mains / que je n'ai pas testé. Mais il a démarré des neurones sur Rpi, Rpi2, Rpi3 (par exemple, il me l'a dit
ici ). En général, Rpi4, si je comprends bien, ne diffère que par les performances. Il me semble que les avantages et les inconvénients de RPi savent tout, mais quand même. Inconvénients:
- Autant que je ne voudrais pas, ce n'est pas une solution d'épicerie. Surchauffe . Gel périodique. Mais en raison de l'immense communauté, il existe des centaines de solutions à chaque problème. Cela ne rend pas Rpi bon pour des milliers de tirages. Mais des dizaines / centaines - des notes wai.
- La vitesse. C'est l'appareil le plus lent de tous les principaux dont nous parlons.
- Il n'y a presque aucun support du fabricant. Ce produit s'adresse aux passionnés.
Avantages:
- Prix Non, bien sûr, si vous élevez la planche vous-même, alors en utilisant du gyrfalcone, vous pouvez le rendre moins cher par milliers. Mais ce n'est probablement pas réaliste. Là où les performances RPi sont suffisantes, ce sera la solution la moins chère.
- Popularité. Lorsque Caffe2 est sorti, il y avait une version pour Rpi dans la version de base. Lumière Tensorflow? Bien sûr, cela fonctionne. I.T.D., I.T.P. Ce que le fabricant ne fait pas, c'est transférer des utilisateurs. J'ai couru sur différents RPi et Caffe et Tensorflow et PyTorch, et un tas de choses plus rares.
- Commodité pour les petites fêtes / pièces. Il suffit de flasher le lecteur flash et de courir. Il y a le WiFi à bord, contrairement à JetsonNano. Vous pouvez simplement l'alimenter via PoE (il semble que vous ayez besoin d'acheter un adaptateur vendu activement).
Nous parlerons de la vitesse Rpi à la fin. Étant donné que le fabricant ne postule que son produit pour les neurones, il existe peu de repères. Tout le monde comprend que Rpi n'est pas parfait en vitesse. Mais même lui convient à certaines tâches.
Nous avions quelques tâches semi-produit que nous avons mises en œuvre chez Rpi. L'impression était agréable.
Movidius 2

À partir d'ici et ci-dessous, pas de processeurs à part entière, mais des processeurs conçus spécifiquement pour les réseaux de neurones. C'est comme si leurs forces et leurs faiblesses étaient en même temps.
Alors. Movidius. La société a été achetée par Intel en 2016. Dans le segment qui nous intéresse, la société a sorti deux produits, Movidius et Movidius 2. Le second est plus rapide, nous ne parlerons que du second.
Non, pas comme ça. La conversation ne devrait pas commencer avec Movidius, mais avec Intel
OpenVino . Je dirais que c'est de l'idéologie. Plus précisément, le cadre. En fait, il s'agit d'un ensemble de neurones pré-entraînés et d'inférences qui sont optimisés pour les produits Intel (processeurs, GPU, ordinateurs spéciaux). Intégré avec OpenCV, avec le Raspberry Pi, avec un tas d'autres sifflets et pets.
L'avantage d'OpenVino est qu'il a beaucoup de neurones. Tout d'abord, les détecteurs les plus connus. Neurones pour la reconnaissance des personnes, des personnes, des chiffres, des lettres, des poses, etc., etc. (
1 ,
2 ,
3 ). Et ils sont formés. Pas par des ensembles de données ouverts, mais par des ensembles de données compilés par Intel lui-même. Ils sont beaucoup plus grands / plus diversifiés et mieux ouverts. Ils peuvent être recyclés en fonction de vos cas, puis ils fonctionneront généralement cool.
Est-il possible de faire mieux? Bien sûr que vous le pouvez. Par exemple, la reconnaissance des chiffres que nous avons faits - a fonctionné beaucoup mieux. Mais nous avons passé de nombreuses années à le développer et à comprendre comment le rendre parfait. , .
OpenVino, , . . - — . . GAN . . , , , - , .
, :

, Intel OpenVino . . , . — . 70% OpenVino.
Movidius . . ( , ).
. USB , , !!! USB. . Intel
. - (
1 ,
2 )
. -. - .
?.. :)
, . OpenVino, , , ( Computer Vision ). :
( AI 2.0, OpenVino ).
, . Movidius 2. :
- . Rpi Jetson Nano. — . . Third Party ?
- . . .
- . .
- . USB 3.0
- , . -. . Movidius . .
Avantages:
- . . .
- ,
- ,
. — .
, “ 20-30 , , ” — Movidius.
Intel
. , .
 UPD
UPD. . embedded . PCI-e . . — 200 .. . …
Google Coral
Je suis déçu. Non, il n'y a rien que je ne prédis. Mais je suis déçu que Google ait décidé de publier cela. Les tests sont un miracle au début de l'été. Peut-être que quelque chose a changé depuis, mais je vais décrire mon expérience de cette époque.
Mise en place ... Pour flasher Jetson Tk-Tx1-Tx2, vous deviez le brancher sur l'ordinateur hôte et sur l'alimentation. Et c'était suffisant. Pour flasher Jetson Nano et RPi, il vous suffit de pousser l'image sur la clé USB.
Et pour flasher Coral, vous devez coller trois fils dans le
bon ordre :

Et n'essayez pas de vous tromper! Soit dit en passant, il y a des erreurs / un comportement indescriptible dans le guide. Je ne vais probablement pas les décrire, car depuis le début de l'été, ils auraient pu réparer quelque chose. Je me souviens qu'après l'installation de Mendel, tout accès via ssh a été perdu, y compris celui décrit par eux, j'ai dû modifier manuellement certaines configurations Linux.
Il m'a fallu 2-3 heures pour terminer ce processus.
Ok Lancé. Pensez-vous qu'il est facile de faire fonctionner votre grille dessus? Presque rien :)
Voici une liste de ce que vous pouvez laisser aller.
Pour être honnête, je ne suis pas arrivé à ce point rapidement. Nous avons passé une demi-journée. Non vraiment. Vous ne pouvez pas télécharger le modèle à partir
du référentiel TF et l'exécuter sur l'appareil. Ou là, il est nécessaire de recouper toutes les couches. Je n'ai pas trouvé d'instructions.
Alors voilà. Il est nécessaire de prendre le modèle du référentiel d'en haut. Ils sont peu nombreux (3 modèles ont été ajoutés depuis le début de l'été). Et comment la former? Ouvrir dans TensorFlow dans un pipeline standard? HAHAHAHAHAHAHAHAHA. Bien sûr que non !!!
Vous avez un
conteneur Doker spécial et le modèle ne s'y entraînera que. (Probablement, vous pouvez également vous moquer de votre TF ... Mais il y a des instructions, des instructions ... qui ne l'étaient pas et ne semblent pas l'être.)
Télécharger / installer / lancer. Qu'est-ce que c'est ... Pourquoi le GPU est-il à zéro? .. PARCE QUE LA FORMATION SERA SUR LE CPU. Docker n'est que pour lui !!! Vous voulez plus de plaisir? Le manuel indique «basé sur un processeur à 6 cœurs avec station de travail à mémoire 64G». Il semble que ce ne soit qu'un conseil? Peut-être. Ce n'est que maintenant que je n'avais pas assez de mes 8 concerts sur ce serveur où la plupart des modèles s'entraînent. L'entraînement à la 4 e heure les a tous consommés. Un fort sentiment qu'ils avaient quelque chose qui coule. J'ai essayé quelques jours avec différents paramètres sur différentes machines, l'effet était un.
Je n'ai pas revérifié cela avant de poster l'article. Pour être honnête, cela m'a suffi une fois.
Quoi d'autre à ajouter? Que ce code ne génère pas de modèle? Pour le générer, vous devez:
- Nombre de retards
- Le convertir en tflite
- Compiler vers TPU Edge formel. Dieu merci, cela se fait sur un ordinateur. Au printemps, cela ne pouvait se faire qu'en ligne. Et là, il fallait cocher «Je ne l'utiliserai pas pour le mal / je ne viole aucune loi avec ce modèle». Maintenant, Dieu merci, il n'y a rien de tout cela.

C'est le plus grand dégoût que j'ai connu à l'égard d'un produit informatique au cours de la dernière année ...
Globalement, Coral devrait avoir la même idéologie qu'OpenVino avec Movidius. Ce n'est que maintenant qu'Intel est sur cette voie depuis plusieurs années. Avec d'excellents manuels, support et bons produits ... Et Google. Eh bien, c'est juste Google ...
Inconvénients:
- Ce tableau n'est pas une épicerie au niveau AD. Je n'ai pas entendu parler de la vente de chips => la production est irréaliste
- Le niveau de développement est aussi terrible que possible. Tout bazhet. Le pipeline de développement ne rentre pas dans les schémas traditionnels.
- Le ventilateur. Sur la «puce énergétiquement optimale», ils l'ont mis. D'accord, je ne parlerai plus de production.
- Coût. Plus cher que TX2.
- Deux grilles ne peuvent pas être conservées en mémoire en même temps. Il est nécessaire d'effectuer un téléchargement-téléchargement. Ce qui ralentit l'inférence de plusieurs réseaux.
Avantages:
- De tout ce dont nous parlons, le corail est le plus rapide
- Potentiellement, si la puce est élevée, elle est plus productive que Movidius. Et il semble que son architecture soit plus justifiée pour les neurones.
Faucon gerfaut

Les derniers un an et demi ont parlé de cette bête chinoise. Il y a encore un
an, je parlais de lui. Mais parler est une chose et donner des informations en est une autre. J'ai parlé avec 3-4 grandes entreprises, où les chefs de projet / directeurs m'ont dit à quel point ce Girfalkon était cool. Mais ils n'avaient aucune documentation. Et ils ne l'ont pas vu vivant. Le
site ne contient presque aucune information.
Télécharger à partir du site au moins quelque chose ne peut que les partenaires (développeurs de matériel). De plus, les informations sur le site sont très contradictoires. Dans un endroit, ils écrivent qu'ils ne prennent en charge que
VGG , dans un autre que seuls leurs neurones sont basés sur GNet (qui, selon
leurs assurances, sont très petits et vraiment sans perte de précision). Dans le troisième, il est écrit que tout est converti avec TF | Caffe | PyTorch, et dans le quatrième, il est écrit sur le téléphone portable et d'autres charmes.
Comprendre la vérité est presque impossible. Une fois que je creusais et creusais quelques vidéos dans lesquelles au moins certains chiffres glissaient:
Si cela est vrai, cela signifie SSD (sur mobile?) Sous 224 * 224 sur la puce GTI2801, ils ont ~ 60 ms, ce qui est assez comparable à movidius.
Il semble qu'ils aient une puce 2803 beaucoup plus rapide, mais les informations à ce sujet sont encore moins:
Cet été, nous avons entre nos mains une
carte Firefly (
ce module y est installé pour les calculs).
Il y avait un espoir que nous pourrions enfin voir en vie. Mais ça n'a pas marché. Le tableau était visible, mais ne fonctionnait pas. En parcourant des phrases anglaises individuelles dans la documentation chinoise, ils ont même presque compris quel était le problème (le système moleté initial ne supportait pas le module neuronal, il était nécessaire de reconstruire et de tout relancer nous-mêmes). Mais cela n'a tout simplement pas fonctionné, et on soupçonnait déjà que la carte ne correspondrait pas à notre tâche (2 Go de RAM est très petit pour les réseaux + systèmes neuronaux. De plus, il n'y avait pas de support pour deux réseaux en même temps).
Mais j'ai réussi à voir la documentation d'origine. On en comprend trop peu (chinois). Pour de bon il fallait tester et regarder la source.
Le support technique de RockChip a bêtement marqué pour nous.
Malgré cette horreur, il est clair pour moi qu'ici, tout de même, les jambages de RockChip sont ici avant tout. Et j'ai l'espoir que dans une planche normale, Gyrfalcon peut être assez utilisé. Mais en raison du manque d'informations, il m'est difficile de le dire.
Inconvénients:
- Pas de ventes ouvertes, interagissez uniquement avec les entreprises
- Peu d'informations, pas de communauté. Les informations existantes sont souvent en chinois. Les fonctionnalités de la plateforme ne peuvent pas être prédites à l'avance
- Il est très probable que l'inférence ne concerne pas plus d'un réseau à la fois.
- Seuls les fabricants de fer peuvent interagir avec l'autogire lui-même. Les autres doivent rechercher des intermédiaires / fabricants de cartes.
Avantages:
- Si je comprends bien, le prix d'une puce girfcon est beaucoup moins cher que le reste. Même sous forme de lecteurs flash.
- Il existe déjà des appareils tiers avec une puce intégrée. Par conséquent, le développement est un peu plus facile que movidius.
- Ils assurent qu'il existe de nombreuses grilles pré-formées, le transfert de grilles est beaucoup plus facile que Movidius | Coral. Mais je ne garantirais pas cela comme la vérité. Nous n'avons pas réussi.
En bref, la conclusion est la suivante: très peu d'informations. Vous ne pouvez pas seulement vous allonger sur cette plateforme. Et avant de faire quelque chose, vous devez faire un examen approfondi.
Vitesses
J'aime vraiment la façon dont 90% des comparaisons d'appareils intégrés se réduisent à des comparaisons de vitesse. Comme vous l'avez compris plus haut, cette caractéristique est très arbitraire. Pour Jetson Nano, vous pouvez exécuter des neurones en tant que tensorflow pur, vous pouvez utiliser tensorflow-tensorrt, ou vous pouvez utiliser du tensorrt pur. Les appareils avec une architecture tenseur spéciale (movidius | coral | gyrfalcone) - peuvent être rapides, mais en premier lieu, ils ne peuvent fonctionner qu'avec des architectures standard. Même pour le Raspberry Pi, tout n'est pas si simple. Les neurones de
xnor.ai accélèrent une fois et demie. Mais je ne sais pas à quel point ils sont honnêtes et ce qui a été gagné en passant à l'int8 ou à d'autres blagues.
En même temps, une autre chose intéressante est un tel moment. Plus le neurone est complexe, plus le dispositif d'inférence est complexe - plus l'accélération finale qui peut être retirée est imprévisible. Prenez de l'OpenPose. Il existe un réseau non trivial, un post-traitement complexe. Ceci et cela peuvent être optimisés grâce à:
- Migration de post-traitement GPU
- Optimiser le post-traitement
- Optimisation du réseau neuronal pour les fonctionnalités de la plateforme, par exemple:
- Utilisation de réseaux optimisés pour la plate-forme
- Utilisation de modules réseau pour la plateforme
- Portage vers int8 | int16 | binarisation
- Utilisation de plusieurs calculatrices (GPU | CPU | etc.). Je me souviens que sur Jetson TX1, nous avons une fois bien accéléré lorsque nous avons transféré toutes les fonctionnalités liées au streaming vidéo aux accélérateurs intégrés à ces fins. Trite, mais le réseau s'est accéléré. Lors de l'équilibrage, de nombreuses combinaisons intéressantes apparaissent
Parfois, quelqu'un essaie d'évaluer quelque chose pour toutes les combinaisons possibles. Mais vraiment, comme il me semble, c'est vain. Vous devez d'abord décider de la plate-forme, puis essayer ensuite de retirer complètement tout ce qui est possible.
Pourquoi suis-je tout cela. En outre, le test «
combien de temps MobileNet » est un très mauvais test. Il peut dire que la plateforme X est optimale. Mais lorsque vous essayez de déployer votre neurone et de post-traiter là-bas, vous pouvez être très déçu.
Mais comparer mobilnet'ov donne quand même quelques informations sur la plateforme. Pour des tâches simples. Pour les situations où vous comprenez que de toute façon la tâche est plus facile à réduire à des approches standard. Lorsque vous souhaitez évaluer la vitesse de la calculatrice.
Le tableau ci-dessous est extrait de plusieurs endroits:
- Ces études sont: 1 , 2 , 3
- Pour les SSD, il existe un tel paramètre «nombre de classes de sortie». Et à partir de ce paramètre, le taux d'inférence peut varier considérablement. J'ai essayé de choisir des études avec le même nombre de classes. Mais ce n'est peut-être pas le cas partout.
- Notre expérience avec TensorRT. Je savais quels types fonctionnent, lesquels ne fonctionnent pas.
- Pour le faucon gerfaut, ces vidéos sont basées sur le fait que mobilnet v2 est là + une estimation du coût du changement de zone. Cette vidéo dit que 2803 peut être 3-4 fois plus rapide. Mais pour 2803, il n'y a pas de classification SSD. En général, je doute le plus des vitesses à ce stade.
- J'ai essayé de choisir l'étude qui donnait la vraie vitesse maximale (je n'ai pas pris la version de Nvidia sans NMS par exemple)
- Pour Jetson TX2, j'ai utilisé ces notes, mais il y a 5 classes, sur le même nombre de classes que le reste sera plus lent. J'ai en quelque sorte compris à partir de l'expérience / comparaison avec Nano dans les noyaux ce qui devrait être là
- Je n'ai pas pris en compte les blagues à débit binaire. Je ne sais pas sur quoi ont travaillé les témoins Movidius et Gyrfalcon.
En conséquence, nous avons:

Comparaison des plateformes
Je vais essayer de rassembler tout ce que j'ai dit ci-dessus dans une seule table. J'ai souligné en jaune les endroits où mes connaissances ne suffisent pas pour tirer une conclusion sans ambiguïté. Et, en fait 1-6 - c'est une évaluation comparative des plates-formes. Le plus proche de 1, mieux c'est.

Je sais que la consommation d'énergie est critique pour beaucoup. Mais il me semble que tout ici est quelque peu ambigu, et je le comprends trop mal - donc je n'y suis pas entré. De plus, l'idéologie elle-même semble être la même partout.
Étape latérale
Ce dont nous parlions n'est qu'un petit point dans le vaste espace de variations de votre système. Probablement les mots communs qui peuvent caractériser ce domaine:
- Faible consommation d'énergie
- Petite taille
- Puissance de calcul élevée
Mais, globalement, si vous réduisez l'importance d'un des critères, vous pouvez ajouter de nombreux autres appareils à la liste. Ci-dessous, je vais passer en revue toutes les approches que j'ai rencontrées.
Intel
Comme nous l'avons dit lorsque nous avons discuté de Movidius, Intel a une plate-forme OpenVino. Il permet un traitement très efficace des neurones sur les processeurs Intel. De plus, la plate-forme vous permet de prendre en charge même toutes sortes d'intel-gpu sur une puce. J'ai maintenant peur de dire exactement quel type de performance existe pour quelles tâches. Mais, si je comprends bien, une bonne pierre avec un GPU à bord quite donne une performance de 1080. Pour certaines tâches, cela peut même être plus rapide.

Dans ce cas, le facteur de forme, par exemple Intel NUC, est assez compact. Bon refroidissement, emballage, etc. La vitesse sera plus rapide que celle du Jetson TX2. Par disponibilité / facilité d'achat - beaucoup plus facile. La stabilité de la plate-forme hors de la boîte est plus élevée.
Deux contre - consommation d'énergie et prix. Le développement est un peu plus compliqué.
Jetson agx

Ceci est un autre jetson. Essentiellement la version la plus ancienne. La vitesse est environ 2 fois plus rapide que celle du Jetson TX2, et les calculs int8 sont pris en charge, ce qui vous permet d'overclocker encore 4 fois. Au fait, regardez cette
photo de Nvidia:
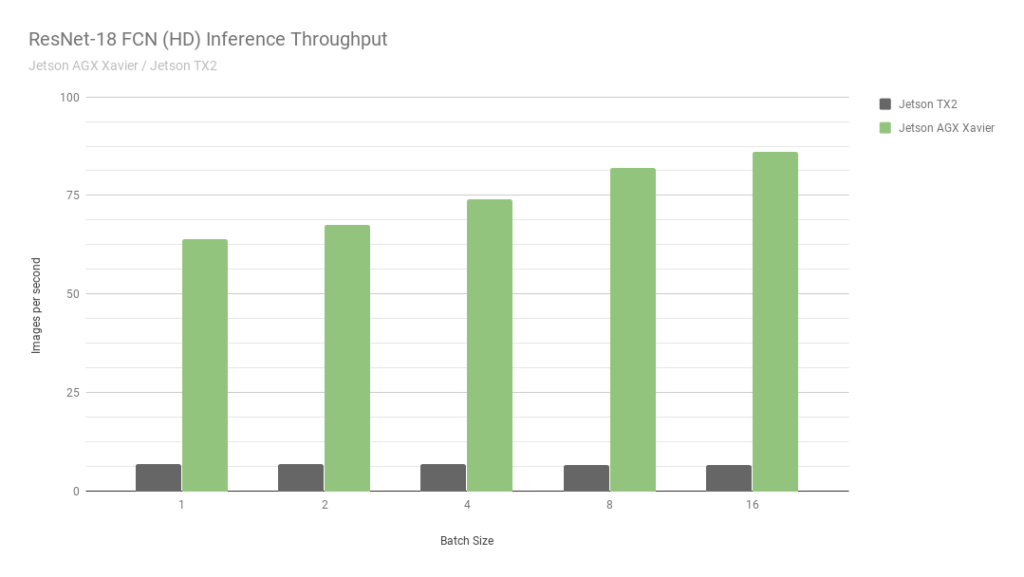
Ils comparent deux de leurs propres Jetson. Un en int8, le second en int32. Je ne sais même pas quels mots dire ici ... En bref: "NE JAMAIS CROIRE À NVIDIA GRAPHICS".
Malgré le fait que AGX est bon - il n'atteint pas les GPU normaux de Nvidia en termes de puissance de calcul. Néanmoins, en termes d'efficacité énergétique - ils sont très cool. Le principal moins le prix.
Nous-mêmes n'avons pas travaillé avec eux, il m'est donc difficile de dire quelque chose de plus détaillé, de décrire la gamme de tâches où elles sont les plus optimales.
Nvidia gpu | version portable
Si vous supprimez la restriction stricte de la consommation d'énergie, le Jetson TX2 ne semble pas optimal. Comme l'AGX. Habituellement, les gens ont peur d'utiliser le GPU en production. Paiement séparé, tout ça.
Mais il y a des millions d'entreprises qui vous proposent d'assembler une solution personnalisée sur une seule carte. Ce sont généralement des cartes pour ordinateurs portables / mini-ordinateurs. Ou, à la fin, comme
ceci :

L'une des startups dans lesquelles je travaille depuis 2,5 ans (
CherryHome ) a
emprunté cette voie. Et nous en sommes très satisfaits.
Moins, comme d'habitude, de consommation d'énergie, ce qui n'était pas critique pour nous. Eh bien, le prix mord un peu.
Téléphones portables
Je ne veux pas approfondir ce sujet. Pour dire tout ce qui se trouve dans les téléphones portables modernes pour les neurones / quels frameworks / quel matériel, etc., vous aurez besoin de plus d'un article avec cette taille. Et compte tenu du fait que nous n'avons poussé dans cette direction que 2-3 fois, je me considère comme incompétent pour cela. Donc, juste quelques observations:
- Il existe de nombreux accélérateurs matériels sur lesquels les neurones peuvent être optimisés.
- Il n'y a pas de solution générale qui va bien partout. Il y a maintenant une tentative de faire de Tensorflow lite une telle solution. Mais, si je comprends bien, il n'est pas encore devenu un.
- Certains fabricants ont leurs propres fermes spécifiques. Il y a un an, nous avons aidé à optimiser le cadre de Snapdragon. Et c'était terrible. La qualité des neurones y est beaucoup plus faible que sur tout ce dont j'ai parlé aujourd'hui. Il n'y a pas de prise en charge pour 90% des calques, même les plus basiques, tels que «addition».
- Puisqu'il n'y a pas de python, l'inférence des réseaux est très étrange, illogique et peu pratique.
- En termes de performances, il arrive que tout soit très bon (par exemple, sur certains iphone).
Il me semble que pour les téléphones portables embarqués n'est pas la meilleure solution (l'exception est certains systèmes de reconnaissance faciale à petit budget). Mais j'ai vu quelques cas lorsqu'ils ont été utilisés comme premiers prototypes.
Gap8
Était récemment à une conférence
Usedata . Et là, l'un des rapports portait sur l'inférence des neurones aux pourcentages les moins chers (GAP8). Et, comme on dit, le besoin d'inventions est rusé. Dans l'histoire, un exemple était très tiré par les cheveux. Mais l'auteur a expliqué comment ils avaient pu faire une déduction par visage en une seconde environ. Sur une grille très simple, essentiellement sans détecteur. Par des optimisations folles et longues et des économies sur les matchs.
Je n'aime toujours pas de telles tâches. Aucune recherche, seulement du sang.
Mais, il convient de reconnaître que je peux imaginer des puzzles où des pourcentages à faible consommation donnent un résultat cool. Probablement pas pour la reconnaissance faciale. Mais quelque part où vous pouvez reconnaître l'image d'entrée en 5 à 10 secondes ...
Grove AI HAT

Lors de la préparation de cet article, je suis tombé sur
cette plateforme embarquée. Il y a très peu d'informations à ce sujet. Si je comprends bien, aucun soutien. La productivité est également à zéro ... Et pas un seul test de vitesse ...
Reconnaissance serveur / à distance
Chaque fois qu'ils viennent nous voir pour des conseils sur une plateforme embarquée, je veux crier «cours, imbéciles!». Il est nécessaire d'évaluer soigneusement la nécessité d'une telle solution. Découvrez toutes les autres options. Je conseille toujours à tout le monde de faire un prototype avec une architecture serveur. Et lors de son fonctionnement, c'est à vous de décider de mettre en œuvre ou non un véritable embarqué. Après tout, embarqué c'est:
- Augmentation du temps de développement, souvent 2-3 fois.
- Support et débogage sophistiqués en production. Tout développement avec ML est une révision constante, une mise à jour des neurones, des mises à jour du système. L'embarqué est encore plus difficile. Comment recharger le firmware? Et si vous avez déjà accès à toutes les unités, alors pourquoi calculer sur elles alors que vous pouvez calculer sur un seul appareil?
- Complexité du système / risque accru. Plus de points d'échec. Dans le même temps, alors que le système ne fonctionne pas dans son ensemble, on peut ne pas comprendre: la plateforme est-elle adaptée à cette tâche?
- Augmentation des prix. C'est une chose de mettre une planche simple comme nano pi. Et l'autre est d'acheter TX2.
Oui, je sais qu'il y a des tâches où les décisions du serveur ne peuvent pas être prises. Mais, curieusement, ils sont beaucoup plus petits qu'on ne le croit généralement.
Conclusions
Dans l'article, j'ai essayé de me passer de conclusions évidentes. C'est plutôt une histoire sur ce qui est maintenant. Pour tirer des conclusions - il est nécessaire d'enquêter dans chaque cas. Et pas seulement les plateformes. Mais la tâche elle-même. Toute tâche peut être légèrement simplifiée / légèrement modifiée / légèrement aiguisée sous l'appareil.
Le problème avec ce sujet est que le sujet change. De nouveaux dispositifs / cadres / approches arrivent. Par exemple, si NVIDIA active le support int8 pour Jetson Nano demain, la situation changera radicalement. Lorsque j'écris cet article, je ne peux pas être sûr que les informations n'ont pas changé il y a deux jours. Mais j'espère que ma courte histoire vous aidera à mieux naviguer dans votre prochain projet.
Ce serait cool si vous avez des informations supplémentaires / J'ai raté quelque chose / J'ai dit quelque chose de mal - écrivez les détails ici.
ps
Déjà quand j'ai presque fini d'écrire l'article,
snakers4 a laissé tomber un récent
post de sa chaîne de télégramme Spark en moi, qui est à peu près les mêmes problèmes avec Jetson. Mais, comme je l'ai écrit ci-dessus, - dans les conditions de toute consommation d'énergie - je mettrais quelque chose comme des zotacs ou IntelNUC. Et comme jetson intégré n'est pas la pire plateforme.
